







IP地址和IP协议
一、认识IP地址
1.概念
IP地址是指互联网协议地址,又翻译为网际协议地址
2.作用
IP地址是IP协议提供的一种统一的地址格式,它为每一台参与通信的主机分配一个逻辑地址,从而屏蔽物理地址的差异

实际上,IP地址并非根据主机台数来配置,而是每一台主机上的每一块网卡都可以设置IP地址,通常情况下,一个网卡只能设置一个地址,但是其实可以配置多个IP地址。此外。一台路由器通常会配置两个以上的网卡,因此可以设置两个以上的IP地址
3.格式
IP地址(IPv4地址)是由32位正整数来表示的,IP地址在计算机内部以二进制方式被处理,但是在实际标记中,不使用二进制方式,而是采用点分十进制的方式来表示,将32位的IP地址以每8位为一组。分成4组,以下图为例:

注:IP协议有两个版本,IPV4和IPV6,本文所讲的是IPV4
4.组成
IP地址由"网络标识(网络地址)"和"主机标识(主机地址)"两部分组成
| 名称 | 作用 |
|---|---|
| 网络标识 | 标识网段, 保证相互连接的每个网段的地址不相重复,但是相同网段内相连的主机必须有相同网络地址 |
| 主机标识 | 标识主机,同一网段内,主机之间具有相同的网络号,但是必须要有不同的主机号 |
如下图所示:

5.IP地址分类
IP地址分为五个类别,分别为A类,B类,C类,D类,E类。它是根据IP地址中从第一位到第四位的比特列对其网络标识和主机标识进行区分。
1.A类地址
A类地址的网络号字段占1个字节(8位),首位以"0"开头的地址,后面7位可供使用。使用十进制表示:0.0.0.0~127.0.0.0是A类的网络地址,这里需要注意的是:
1.网络号为全0(0.0.0.0)的IP地址有特殊用途,它表示"本网络"
2.网络号为127,保留为本地软件环回测试本主机的进程之间的通信用,通常为127.0.0.1
3.主机号全0表示该IP为"本主机"
4.主机号全1表示"所有的",为广播地址
2.B类地址
B类地址的网络号有2个字节(16位),是前两位“10”的地址,后面14位可供使用,使用十进制表示:128.0.0.1~191.255.0.0是B类的网络地址
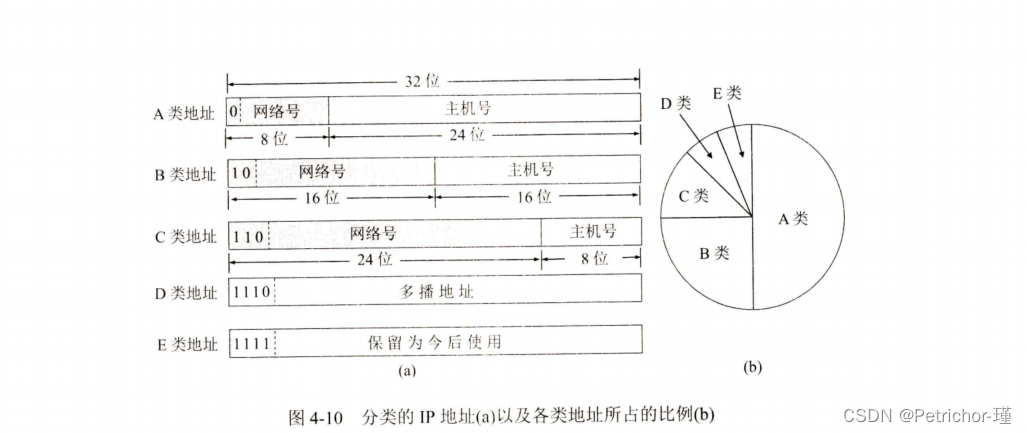
3.C类地址
C类地址网络号有3个字节(24位),是前三位“110”的地址,后面21位可供使用,使用十进制表示:192.168.0.0~239.255.255.0是C类的网络地址
4.D类地址
C类地址网络号有4个字节(32位),是前四位“1110”的地址,后面28位可供使用,使用十进制表示:224.0.0.0~239.255.255.255是D类的网络地址,D类地址没有主机标识,常被用于多播
5.E类地址
为保留地址
二、IP协议(IPv4)
IP协议的首部格式
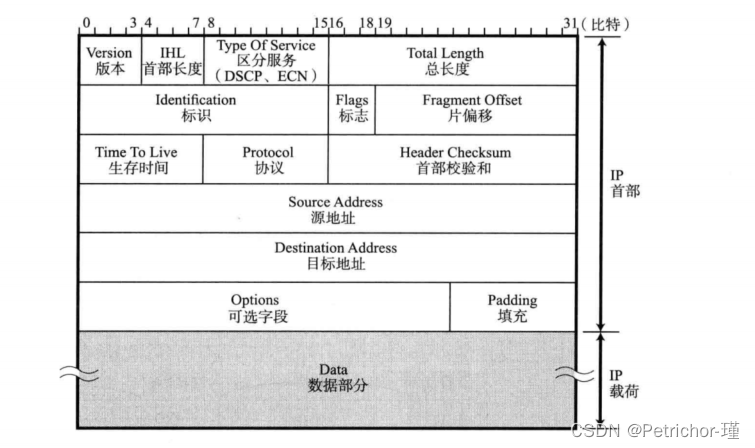
1.版本(Version)
由4个比特构成,此处只有两个取值,分别为4(IPv4)和6(IPv6)
在上面的IP地址中,我们知道一个IP地址32位,只能表示42亿9千万个数字,而地址的期望就是每个设备的地址均不相同,所以42亿是远远不够的
针对IP地址不够用的问题,想了很多办法,以下是典型的两种
1.动态分配IP地址,可以省下一批IP地址,但是没有从根本上增加IP地址,只提高了利用率
2.NAT网络地址转换,本质上使用一个IP代表一批设备,大大提高IP地址的利用率,使用端口号进行区分
NAT网络地址转换:
将IP地址分为两类:
1.内网IP(私有IP) 10.* (172.16.* - 172.31.*) 192.168. *
2.外网IP(公网IP) 除上面三个其他都为公网IP
NAT要求:公网IP必须是唯一,私网IP可以在不同的局域网中重复,如果某个私网里的设备想访问公网的设备,就需要对应的 NAT 设备(路由器),把 IP 地址进映射,从而完成网络访问,反之,公网的设备,无法直接访问私网的设备,不同局域网的私网的设备无法直接相互访问。
但都未从实际上增加IP地址,所以6的出现,根本目的是为了解决版本4不够用的问题,IPv6使用16个字节表示IP地址即128位,是4个版本4相乘,即42亿 * 42亿 * 42亿 * 42亿,这样世界上的每一粒沙子都可以分配到单独的地址,从而解决了IP地址不够用的问题,但是实际上并没有投入使用。
2.首部长度
由4个比特构成,表示IP首部的大小,单位为4个字节。报头中有一个选项部分,是变长的,可有可无。当没有可选项的IP包,首部长度设置为5,因为没有可选项的IP首部长度为20字节(4X5=20)
3.区分服务
由8比特构成,用来表明服务质量
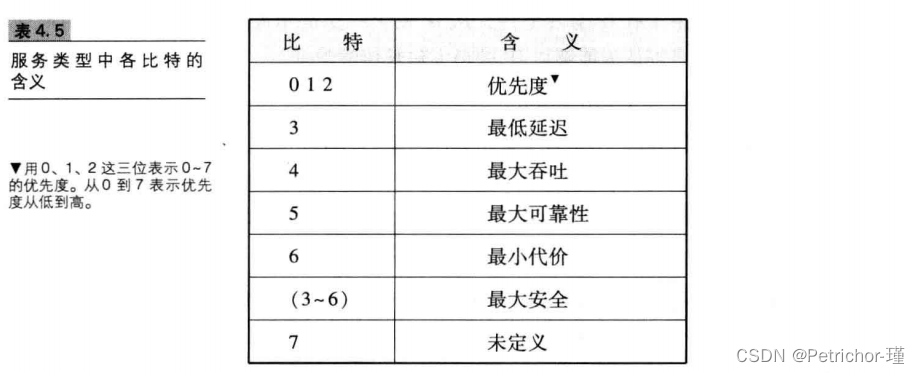
上图虽说有8位,但实际上只有4位有效,并且这4位只有1位可以是1,其他都是0,4位就表示IP协议的四种形态/工作状态,分别为最小延时,最大吞吐量,最高可靠性,最小成本这里的状态就像相当于游戏中的走路状态,跑步状态,可以进行切换,但是在实际开发中很少使用。
4.总长度
由16比特构成,描述了一个IP数据包的长度( 头+载荷 ),将这个长度减去前面的IP报头长度,剩下的就为载荷长度
思考一个问题:16位总长度,是否意味着一个IP数据报最大只能支持64KB,确实是由这个限制,但是IP自身就支持对包的拆分和组装,举个例子,相当于我在某宝上买一个双人床,商家怎么给我寄过来的,难道是一整个床寄过来吗?显然不是,商家把床拆开,以散件的形式一件一件发过来,到家之后,商家派师傅上门安装
拆分过程:
1.发送方:把100KB的数据,交给传输层封装,传输层交给网络层封装,网络层就将这100KB的数据拆包(比如拆成两份)为64K+36K,再将这两份数据交给数据链路层,由以太网分装成两个数据帧
2.接收方:数据链路层,针对这两个数据帧进行分用,获得两个IP数据报,并将这两个数据报交给网络层,网络层针对这两个IP数据报进行解析,将里面的载荷拼成一个交给传输层,传输层再交给接收方
还需要注意的一个点是:虽然上面说的是64KB,但是实际上IP协议不一定按照64KB为单位进行拆分,实际上会更小,取决于数据链路层的情况
5.标识
由16比特构成,同一个数据拆成的多个包标识是一样的,例如上面的拆分过程
6.标志
由3比特构成,为结束标志
7.片偏移
由13比特构成,标识了多个包的先后顺序,用来标识被分片的每一个分段相对于原始数据的位置
标识,标志,片偏移,这三个字段都是辅助拆分/组包的
8.生存时间
由8比特构成,表示一个数据报在网络上能够传输的最大时间,这个时间的单位不是"秒",而是次数。每一个数据报在构造出来的时候,会有一个初始的TTL的数值(比如32/64/128),每当这个数据报经过一个路由器的时候,TTL就会减一,直至减为0,还没有到达目标,则认为永远无法到达,就丢弃该包,仍以发快递为举例,如果该收件地址不存在,那么这个快递永远无法到达。
9.协议
由8比特构成,描述了载荷部分内容属于哪个协议(TCP/UDP或其他)
10.首部校验格式
由16比特构成,只需要针对首部数据进行校验,载荷部分已经校验,如果校验和不一致,直接丢弃,IP不负责重传,如果上层使用的是TCP,那么在TCP未收到ack之后就重传
11.源地址
由32比特构成,表示发送端IP地址
12.目的地址
由32比特构成,表示接收端IP地址
13.可选字段
长度可变
14.填充
在有可选项的情况下,首部长度可能不是32比特的整数,通过字段填充0,调整为32比特的整数倍
15.数据
存入数据,将IP上层协议的首部也作为数据进行处理。















 3260
3260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









