







@[TOC]Hadoop
一、Hadoop是什么?
(1) Hadoop是一个分布式系统基础架构
(2) Hadoop主要解决海量数据的存储和海量数据的分析问题
(3) Hadoop可以指一个更广泛的概念——Hadoop生态圈
二、Hadoop的优势
(1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分布任务数据,可以方便的扩展数以千计的节点
(3)高效性:在MapRfeduce的思想下,Hadoop是并行工作的,以加快任务的处理速度。
(4)高容错性:能够在后台自动将失败的任务重新进行分配。
三、Hadoop的组成(3.x)
MapReduce(计算)、Yarn(资源调度)、HDFS(数据存储)、Common(辅助工具)
四、HDFS架构概述
HDFS,是一个分布式文件系统。
(1) NomeNode(简称nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2) DataNode(dn):在本地文件系统存储数据块数据,以及数据块的校验和。
(3) Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
五、YARN架构概述
YARN,另一种资源协调者,是Hadoop的资源管理器。
(1) ResourceManager(RM):整个集群资源(内存、CPU等)的老大。
(2) NodeManager(NM):整个节点服务器资源的老大。
(3) ApplicationMaster(AM):单个任务运行的老大。
(4) Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
注意:(1)客户端可以有多个
(2)集群上可以运行多个ApplicationMaster
(3)每个NodeManager上可以有多个Container
六、MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce。
(1)Map阶段并行处理事务
(2)Reduce阶段对Map结果进行汇总
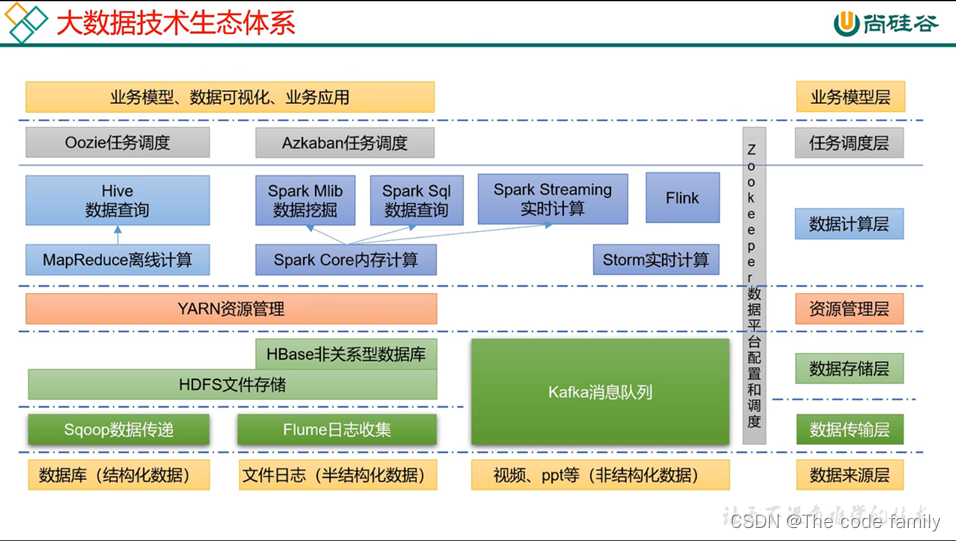
七、 大数据生态体系
八、创建虚拟机
1.创建一个新的虚拟机
方法一:

方法二:右键“库”界面,点击新建虚拟机。
2.选择自定义,点击下一步。
3.不做任何处理,点击下一步
4.选择稍后安装操作系统,然后点击下一步
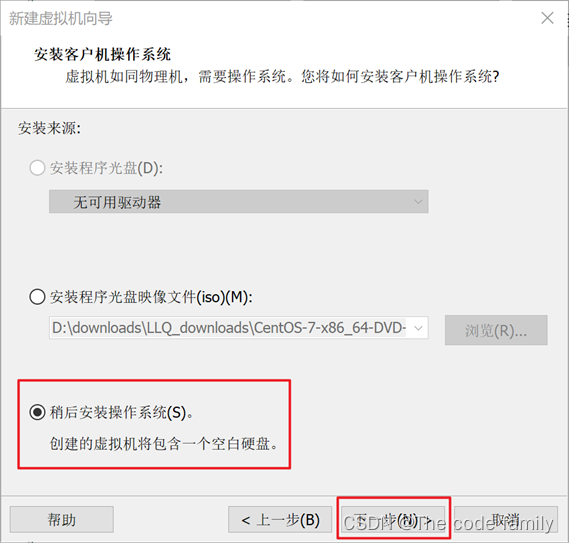
5.客户机操作系统选择选择Linux,版本选择CentOS 7 64位。然后点击下一步。
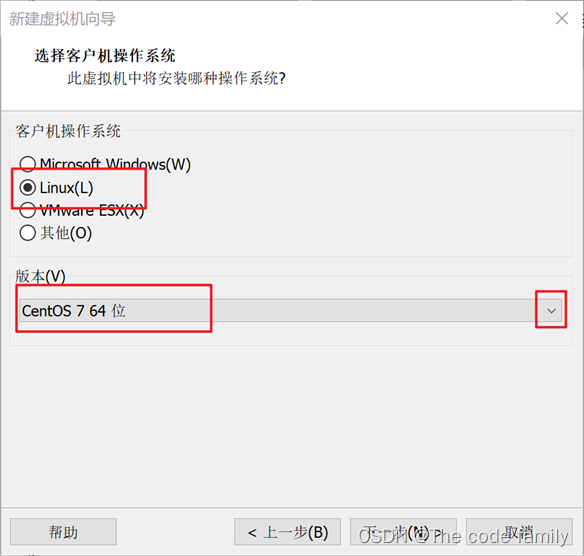
6. 更改虚拟机的名称,选择安装位置,然后点击下一步。
7.保持默认状态即可,点击下一步
8. 保持默认状态即可,点击下一步
9.一定要选择使用网络地址转换(NAT),然后点击下一步
10.保持默认即可
11.保持默认即可,点击下一步

12.选择创建新的虚拟磁盘,然后点击下一步
13.磁盘大小设置为20GB即可,如果是以后有更多用处的,可以多设置一些,然后选择将虚拟磁盘存储为单个文件。点击下一步
14.给磁盘文件命名,默认即可,点击下一步
15.点击自定义硬件

16.点击新 CD/DVD,选择使用ISO映像文件,然后点击右侧的浏览,将下载好的ISO映像文件的路径选入,最后点击关闭即可。
17.点击完成

18.选择中文,点击继续
19. 进入页面

20.点击安装源,进入其页面后不需要做任何处理 ,直接点击左上角完成即可
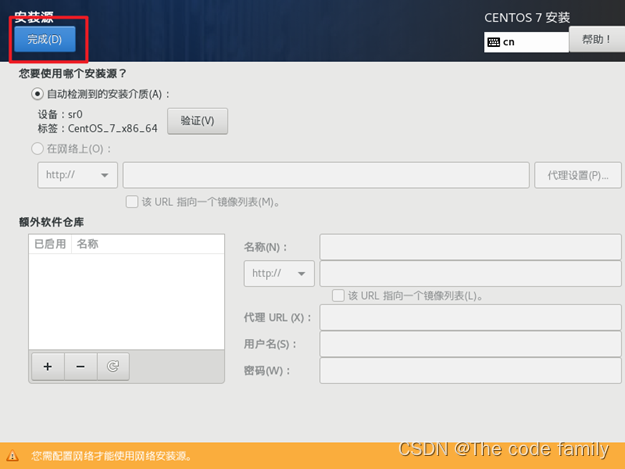
21.选择软件安装,进入其页面后选择带GUI的服务器,然后点击左上角完成
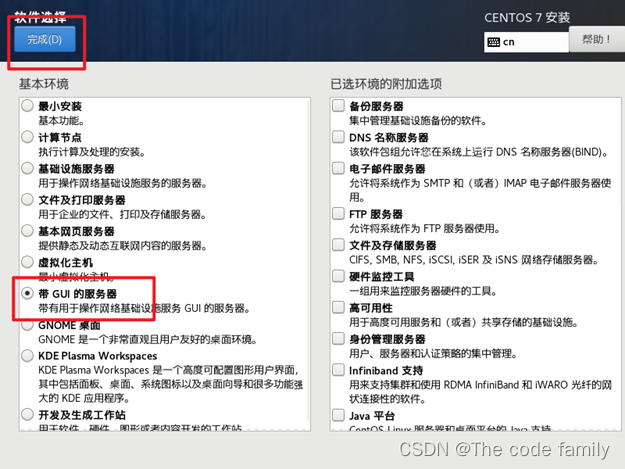
22.选择安装目标位置,进入其界面后不做任何处理,点击左上角完成
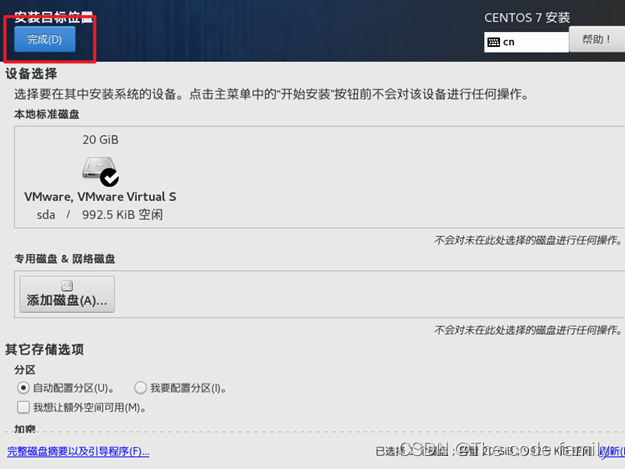
23.点击网络和主机名,打开以太网,然后点击左上角完成
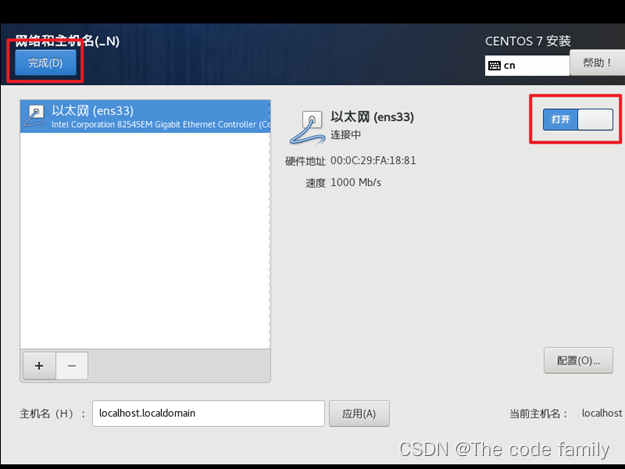
24.点击开始安装
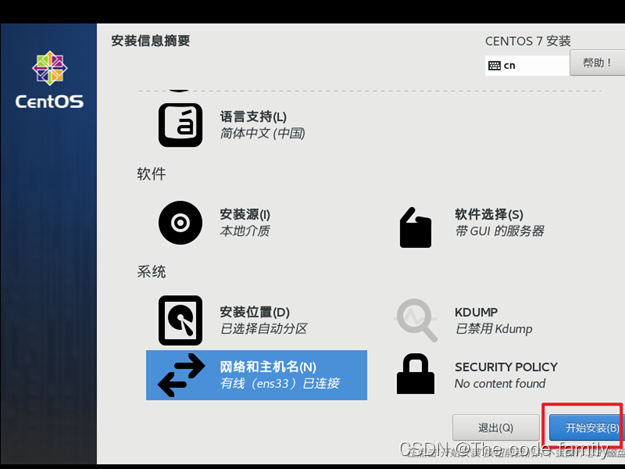
25.设置root用户密码,并创建用户
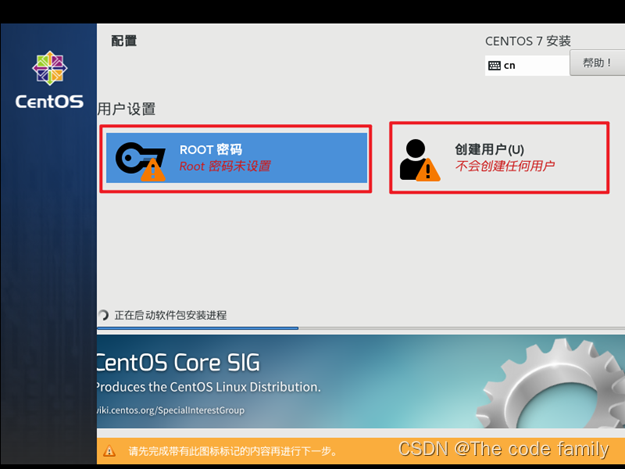
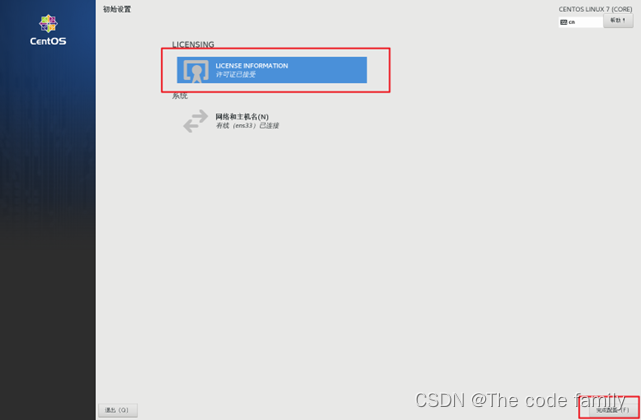
26.点击接受许可证,然后完成配置
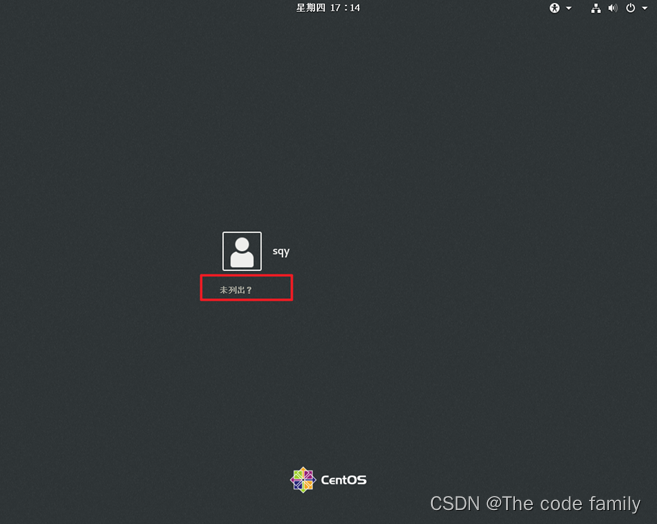
27.第一次登陆最好使用root用户,点击未列出,然后输入用户名root,然后输入密码,即可登录
28.一直点击跳过,然后点击开始使用即可
九、设置静态、更改主机名、设置主机映射
1.点击编辑,虚拟网络编辑器。
2.选择VMnet8,点击更改设置,给予管理员权限
3.选择VMnet8,选择NET模式,进入NET设置
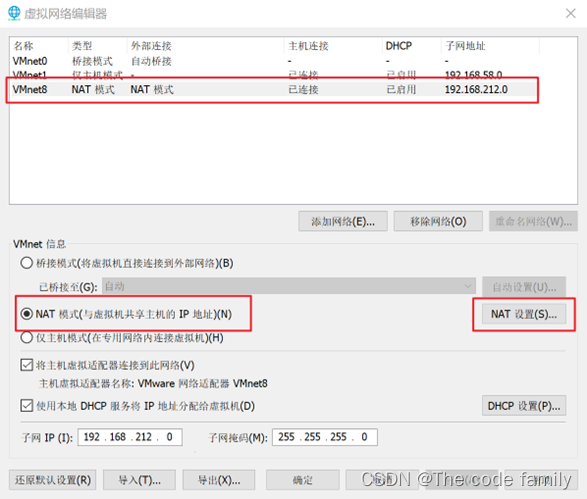
4.记住这三项内容
5.通过 控制面板->网络和Internet->网络连接,来到如下界面,右键VMnet8,点击属性。
6.双击进入IPv4
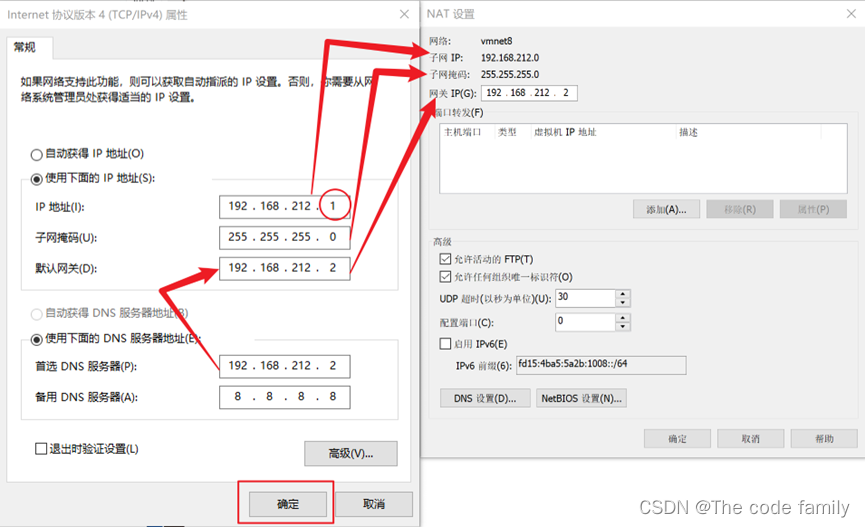
7.箭头所指的需相同,圈中所指 可任意更改,常改为1,然后点击确定
8.打开终端,输入
vim /etc/sysconfig/network-scripts/ifcfg-ens33

9.按键a,进入输入模式,更改一下内容,IP状态、IP地址、网关、域名解释器。然后按键ESC,退出编辑模式,最后输入:wq!进行保存。
在这里插入图片描述
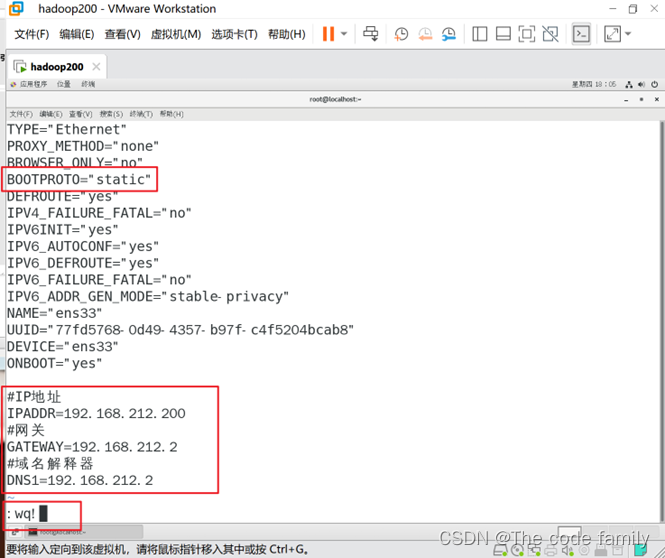
10.打开终端,输入vim /etc/hostname更改主机名

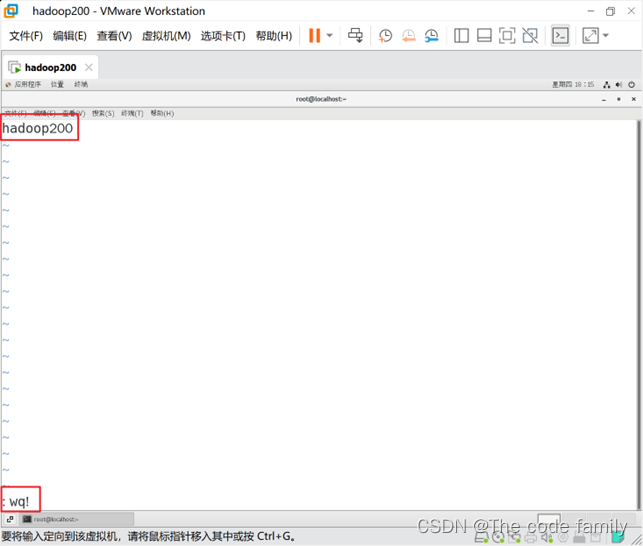
11.输入 vim /etc/hosts设置主机映射,因为后面还需要克隆虚拟机,所以这里我们多设置几台。

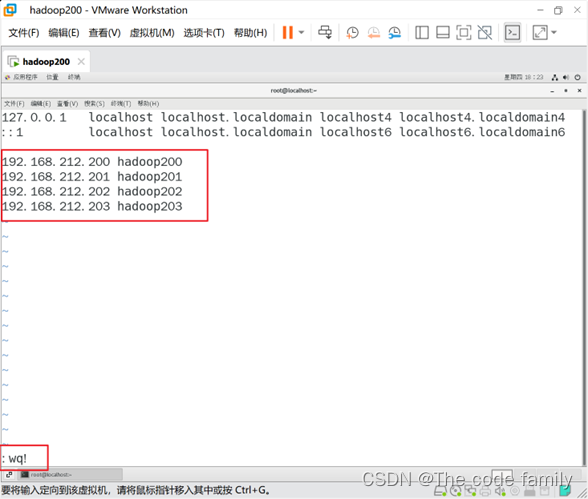
12.输入reboot,进行虚拟机重启
13. 打开终端,查看主机名

14.输入ifconfig,查看IP地址
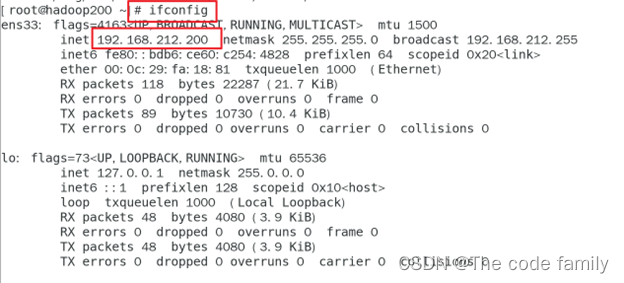
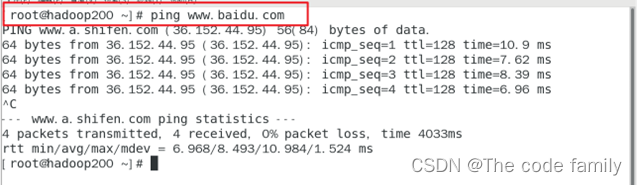
15.输入ping www.baidu.com,如下图所示,既为成功。ctrl+C停止
十、克隆虚拟机的准备工作
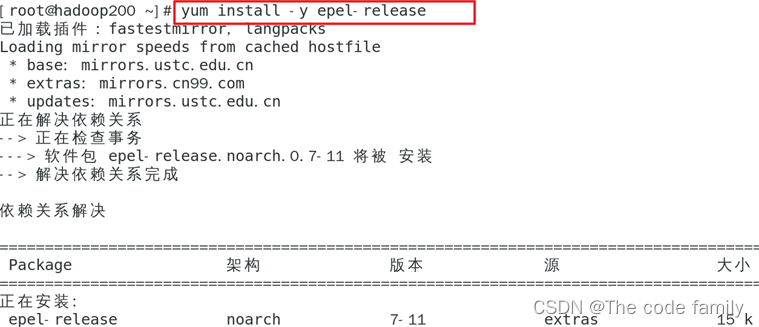
1.输入yum install -y epel-release,用以安装rmp包,显示如下,既为成功

2. 关闭防火墙,输入
systemctl stop firewalld和systemctl disable firewalld.service

检查防火墙状态:systemctl status firewalld.service
3.给sqy用户赋予权限输入vim /etc/sudoers

找到如下位置,添加sqy ALL=(ALL) NOPASSWD:ALL

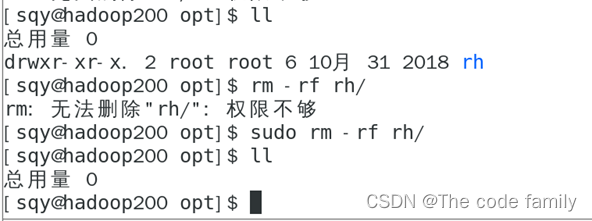
4.切换到sqy用户,输入 su sqy,进入opt目录。

5.尝试删除文件夹,输入 rm -rf rh/,权限不够,输入 sudo rm -rf rh/,成功删除
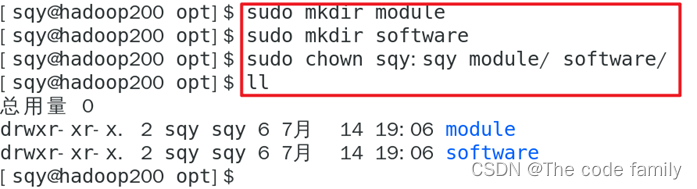
6.创建文件夹module、software,并设置权限
7.卸载虚拟机自带的JDK,需要切换到root用户
查看JDK,输入 rpm -qa | grep -i java

删除JDK,输入 rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps

8.重启虚拟机
十一、克隆虚拟机
1.右键hadoop200,选择管理,选择克隆
2. 选择下一页
3. 选择虚拟机当前状态,选择下一页
4. 选择创建完整克隆,选择下一页
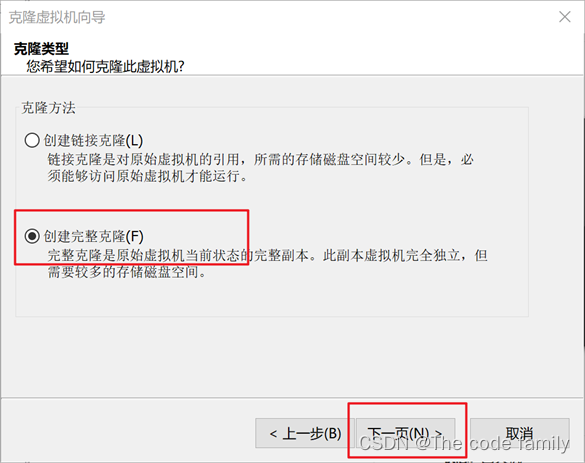
5. 设置虚拟机名称,位置,选择完成
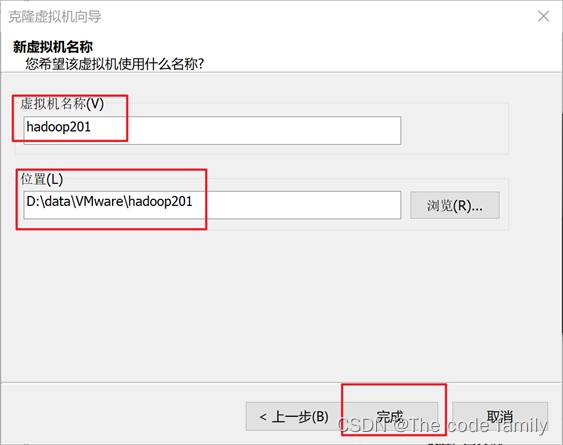
6. 同样操作,共克隆三台
十二、克隆机基础设置
三台机器均执行以下操作
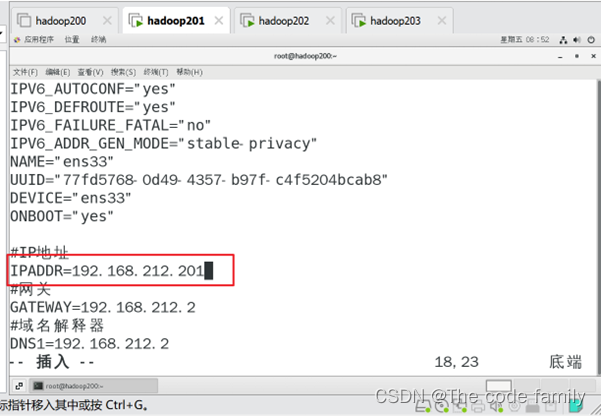
1.输入 vim /etc/sysconfig/network-scripts/ifcfg-ens33
只需修改IP地址即可,IP地址不可重复

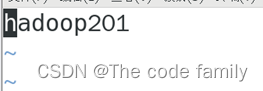
2. 输入 vim /etc/hostname,修改主机名:

3. 输入 vim /etc/hosts,查看主机映射

4. 输入 reboot,进行重启

5. 输入ifconfig,查看IP地址
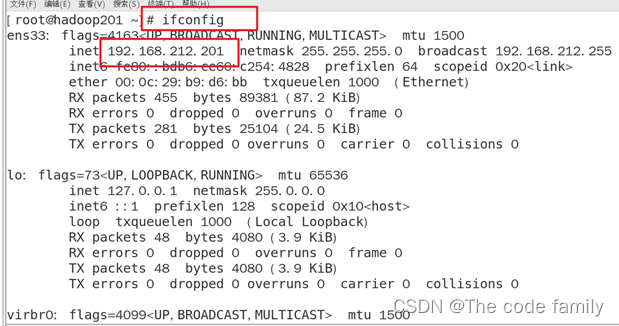
6. 输入 ping www.baidu.com ,验证网络是否连接

7. 输入 hostname,验证主机名是否修改成功
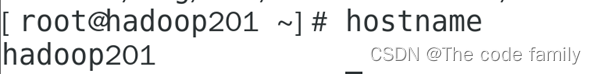
十三、JDK安装
自行安装,使用Xftp将压缩包从主机传输到虚拟机,保存在先前我们创建的文件夹software中
1. 解压JDK安装包
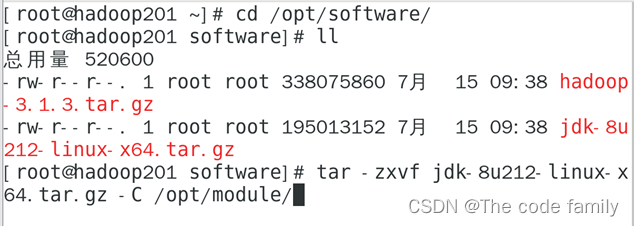
2.查看JDK

3. 配置环境变量
输入 sudo vim /my_env.sh,新建文本
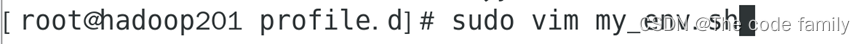
在该新建文本中输入
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin

输入 source /etc/profile,让修改生效
4. 分别输入java、javac、java -version,没有报错,既为JDK配置成功
十四、hadoop安装
自行安装,使用Xftp将压缩包从主机传输到虚拟机,保存在先前我们创建的文件夹software中
1.解压hadoop安装包
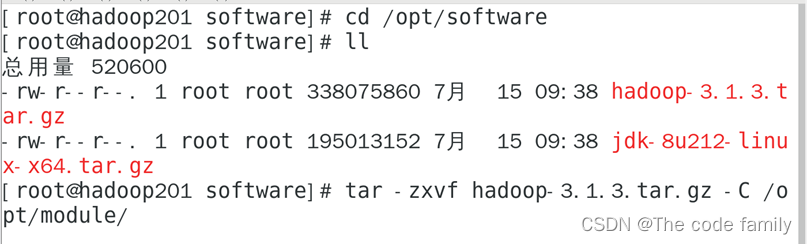
2.查看hadoop,并复制hadoop所在位置的路径
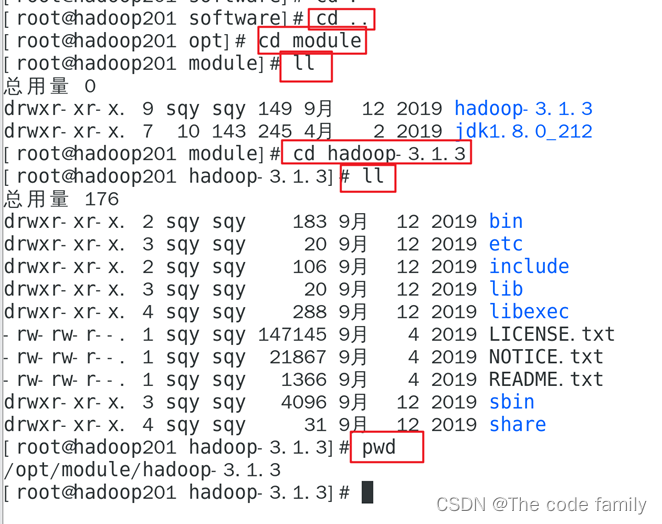
3.输入 sudo vim /etc/profile.d/my_env.sh

在该文本中输入
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

输入 source /etc/profile,让修改生效
















 5120
5120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











