







1、Kafka的架构:

1、producer:消息的生产者
2、consumer:消息的消费者
3、broker:kafka集群的服务者,一个broker就是一个节点,主要是负责处理消息的读、写的请求和存储消息。在kafka cluster中包含很多的broker。
4、topic:消息的队列/分类,就类似一张表,里面用来接收数据,数据的格式可以随意,但是一般都会统一。
5、zookeeper:负责存储元数据。
2、kafka的分区和副本:

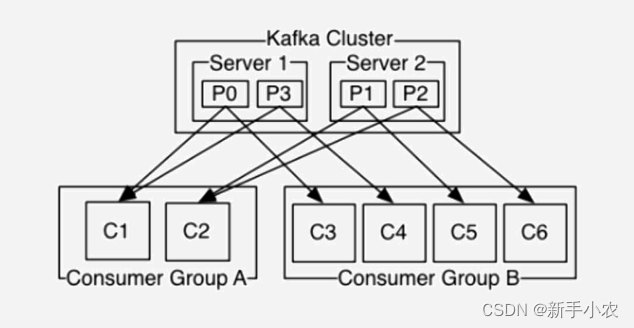
1、每一个topic可以分成多个partition,每一个分区一张表数据,在Kafka底层中就是一个以log结尾的文件,分别存在对应的data目录下(通过配置文件指定的)
使用分区的原因是实现分布式,一个topic中的数据非常大的时候,如果只存在一个分区那么数据压力就比较大。

2、每个partition内部消息强有序,其中的每个消息都有一个序号叫offset(消费偏移量),再取数据的时候就会根据这个偏移量来取数据
3、一个partition只对应一个broker,一个broker可以管多个partition
4、消息不经过内存缓冲,是直接写入磁盘中。
5、根据时间策略删除数据,并不是数据消费完成就删除数据。默认是7天删除一次数据,删除的一整个文件,默认是1G左右生成一个文件。对于存储的时间可以通过修改配置文件来决定存储的日期。



6、producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
轮询的负载均衡:数据数循环的向每一partition中写,数据比较均衡
基于hash的partition策略:数据会根据hash值据欸的那个进入哪个partition,可以根据相同的key进入同一个partition中。但是可能会造成一个问题:数据倾斜的问题。
7、consumer(消费者)自己维护消费到哪个offset,每一个用户都记录自己所消费的offset,这些数据都是默认存在--toppic:__consumer_offsetsL中

8、每一个consumer都有对应的group,一个组中可以是一个用户,也可以是多个用户。
group内是queue消费模型
各个consumer消费不同的partition,因此一个消息在group内只消费一次,这样能保证消费数据不重复
group间是publish-subscribe消费模型
各个group各自独立消费,互不影响,因此一个消息在被每个group消费一次














 2917
2917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









