









文章目录
🙋♂️ 作者:@ IT小灵通 🙋♂️
👀 专栏:@Ceph 👀
💥 标题:Owncloud+Ceph实战💥
❣️ 寄语:与其忙着诉苦,不如低头赶路,奋路前行,终将遇到一番好风景 ❣️
Ceph分布式存储服务
课程目标
- 掌握Ceph分布式存储系统的概念及优势
- 掌握如何安装Ceph分布式存储系统
- Ceph存储集群管理命令
- Owncloud对接ceph分布式系统演练
- Ceph集群高可用管理实战
一、Ceph分布式存储概述
1、任务背景
Ceph是一个开源的分布式文件系统。因它支持块存储、对象存储,以及优秀的性能、可靠性和可扩展性,所以很自然的被用做owncloud、openstack、cloudstack等云计算框架的整个存储后端。当然也可以单独作为存储,例如部署一套集群作为对象存储、SAN存储、NAS存储等。 Ceph 官方文档 http://docs.ceph.org.cn/ ceph 中文开源社区 http://ceph.org.cn/
2、Ceph存储架构
英文版
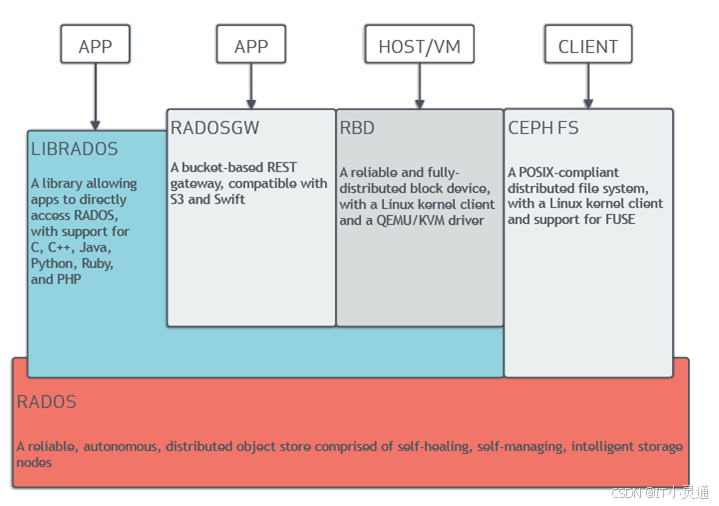
中文版
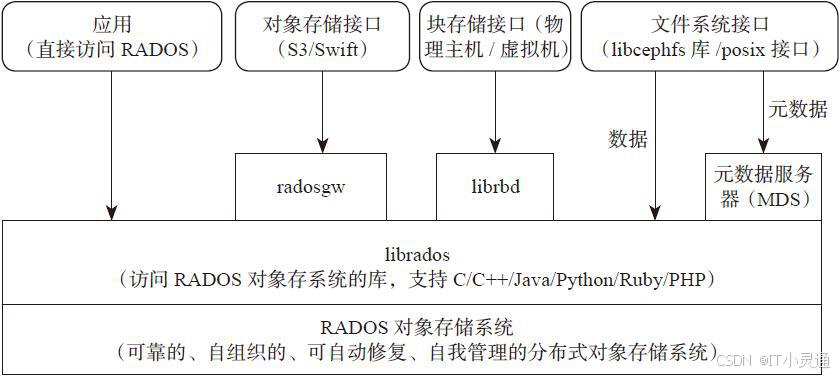
1)RADOS
Ceph的高可靠,高可拓展,高性能,高自动化都是由这一层来提供的, 用户数据的存储最终也都是通过这一层来进行存储的。可以说RADOS就是ceph底层原生的数据引擎。但实际应用时却不直接使用它,而是以上图4种方式。
2)上层内容
对象存储:即RADOSGW,兼容S3(Simple Storage Service 简单存储服务)接口。通过REST API上传、下载文件。 文件系统:即CEPH FS。可以将ceph集群看做一个共享文件系统挂载到本地。此时类似NFS的使用方式。 块存储:即RBD。有kernel rbd和librbd两种使用方式。支持快照、克隆。相当于一块硬盘挂到本地,用法和用途和硬盘一样。 接口库:即LIBRADOS,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言。如Python,C,C++等。简单来说,就是给开发人员使用的接口。
RADOS原生数据
RADOS的全称为(Reliable Autonomic Distributed Object Store),可靠的,自修复分布式对象存储。 其关键特性体现在两方面,一方面是数据是高可靠的;另外一方面是对于故障的自修复能力,比如出现宕机或者磁盘故障问题等情况下实现自动的故障处理,实现集群状态的修复。
Ceph文件存储 要运行Ceph文件系统, 必须先创建至少带一个mds的Ceph存储集群,Ceph文件存储类型是存放与管理元数据metadata的服务
Ceph块存储 类似于LVM逻辑卷
Ceph对象存储 对象存储其实介于块存储和文件存储之间。文件存储的树状结构以及路径访问方式虽然方便人类理解、记忆和访问。
3、Ceph优点
Ceph 相比其它分布式存储有哪些优点
-
统一存储虽然ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口。所以在开源存储软件中,能够一统江湖。至于能不能千秋万代,就不知了。
-
高扩展性扩容方便、容量大。能够管理上千台服务器、EB级的容量。
-
可靠性强支持多份强一致性副本。副本能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自动管理、自动修复。无单点故障,容错性强。
-
高性能因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。另外一点ceph客户端读写数据直接与存储设备(osd) 交互。
4、Ceph功能
Ceph OSD: Ceph OSD(Object Storage Device)守护进程的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息。当Ceph存储集群设定为有2个副本时,至少需要2个OSD守护进程,集群才能达到active+clean状态(Ceph默认有 3 个副本,但你可以调整副本数)。 OSD组件是一个独立的服务,用于实现对磁盘的管理和分布式数据的备份和恢复。这个是数据层面的核心组件。通常来说,一个磁盘对应着一个OSD进程。
Ceph Monitor Ceph Monitor是一个监视器,监视Ceph集群状态和维护集群中的各种关系。维护着展示集群状态的各种图表,包括监视器图、OSD 图、归置组(PG) 图、和 CRUSH 图。 Ceph保存着发生在 Monitors、OSD 和 PG 上的每一次状态变更的历史信息(称为 epoch)。 MON组件是Ceph的元数据服务组件,该组件管理着所有的元数据信息。例如集群的硬件情况、资源映射关系和存储池情况等等。
二、安装Ceph系统
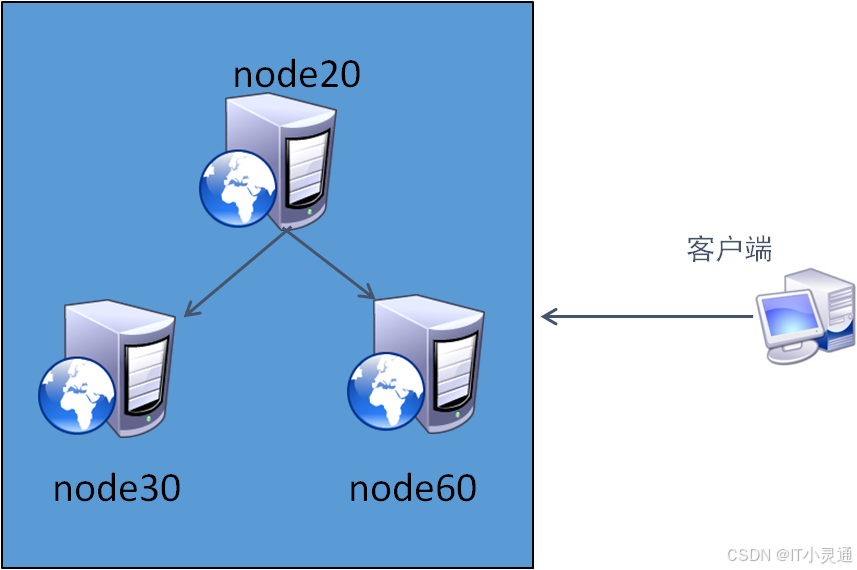
1、案例环境说明
node20:admin,osd,mon作为管理和监控节点 node2和node3拓展节点
每台虚拟机两块磁盘
安装步骤
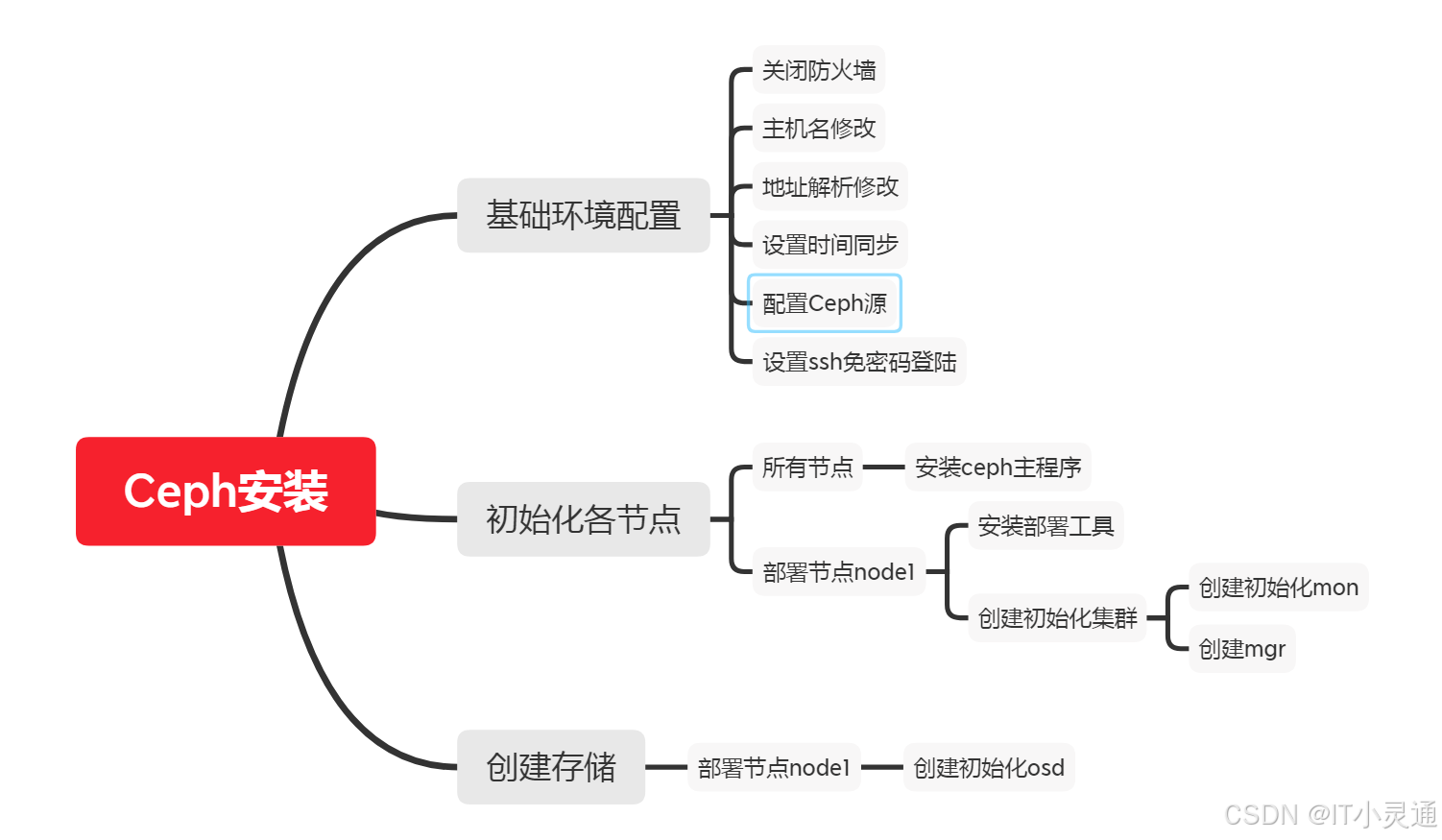
2、基础配置
# 修改主机名 hostnamectl set-hostname node20 hostnamectl set-hostname node30 hostnamectl set-hostname node60 hostnamectl set-hostname agent # 主机名绑定 vim /etc/hosts 192.168.6.20 node20 192.168.6.30 node30 192.168.6.60 node60 192.168.6.40 agent # 关闭防火墙,selinux systemctl stop firewalld systemctl disable firewalld # 时间同步 systemctl restart ntpd systemctl enable ntpd # 配置Ceph的阿里yum源 http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/ http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS # 配置node20到其他节点ssh免密 ssh-keygen ssh-copy-id -i .ssh/id_rsa.pub node20 ssh-copy-id -i .ssh/id_rsa.pub node30 ssh-copy-id -i .ssh/id_rsa.pub node60 # ceph集群所有节点安装ceph yum install ceph ceph-radosgw -y # 客户端安装 ceph -s yum install ceph-common -y # 在node20上安装部署工具 yum install ceph-deploy python2-pip.noarch -y # 在node20上创建集群 ## 在etc上建立一个集群配置目录 mkdir /etc/ceph # 进入到目录 cd /etc/ceph ## 在node20上创建一个ceph集群 ceph-deploy new node20
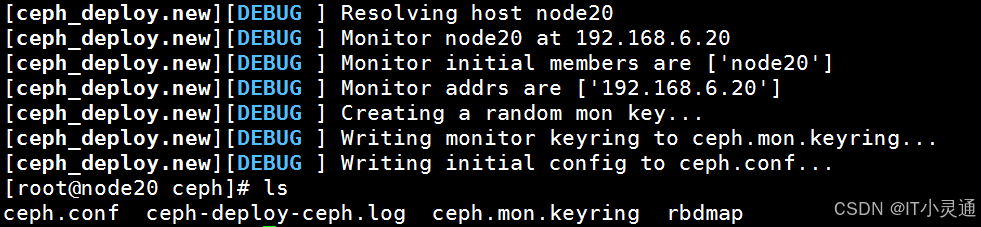
ceph.conf # 集群配置文件 ceph-deploy-ceph.log # 使用ceph-deploy部署的日志记录 ceph.mon.keyring # mon的验证key文件 # 创建mon(监控),增加public网络用于监控 vim /etc/ceph/ceph.conf public network = 192.168.6.0/24 # 监控网络
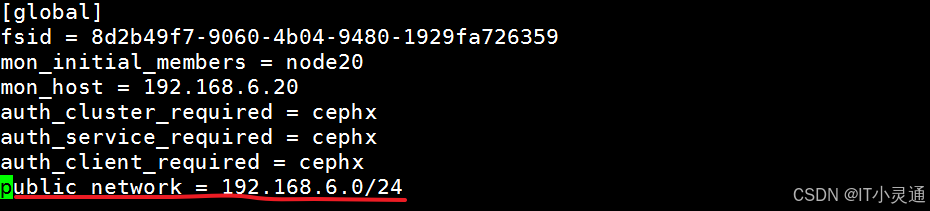
# 监控节点初始化 ceph-deploy mon create-initial # 检测命令 ceph health

# 将配置文件信息同步到所有节点 ceph-deploy admin node20 node30 node60 # 为了防止mon单点故障,你可以加多个mon节点 ceph-deploy mon add node30 && ceph-deploy mon add node60
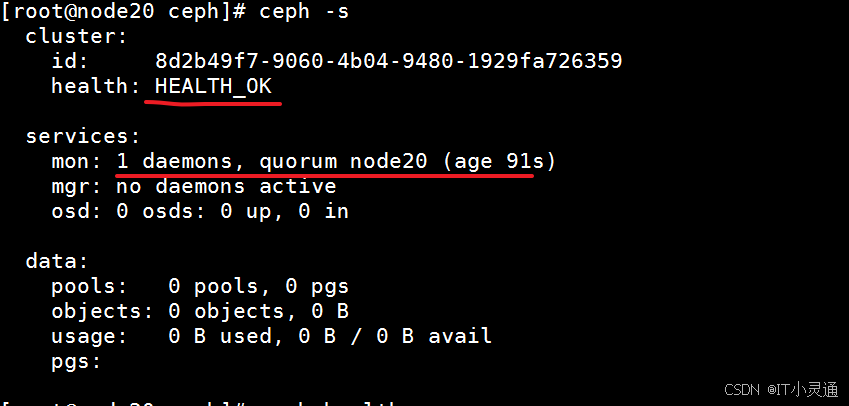
# 创建mgr(管理) # ceph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。 ceph-deploy mgr create node20 # (添加多个mgr可以实现HA)

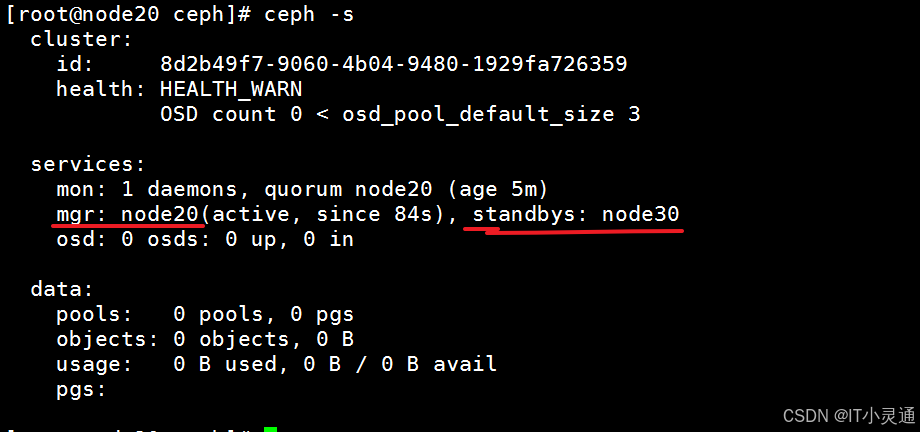
## 查看节点上的磁盘(每台ceph集群都要做)。 ceph-deploy disk list node20

# zap删除磁盘上的数据(每台ceph集群都要做),相当于格式化 ceph-deploy disk zap node20 /dev/sdb

# 创建osd(存储盘),node20,node30,node60执行 ceph-deploy osd create --data /dev/sdb node20 #将磁盘创建为osd
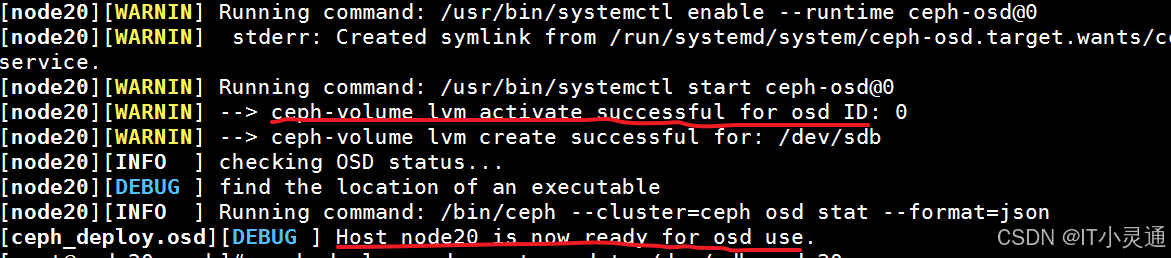
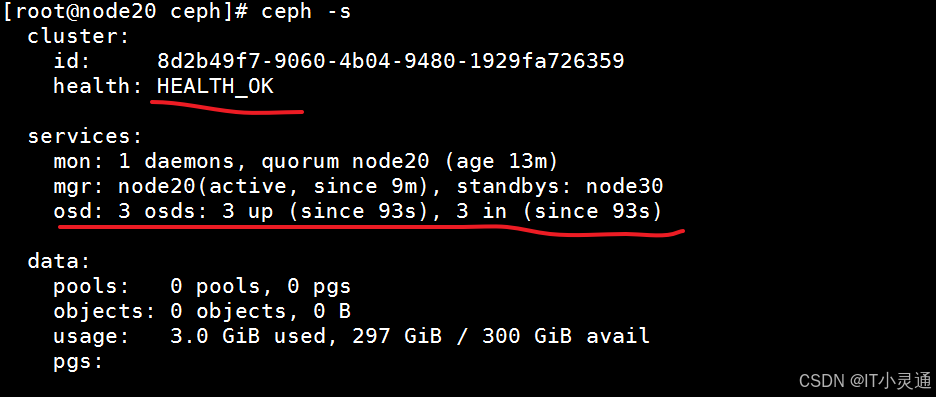
三、Ceph存储集群管理
1、RADOS原生数据存取
原生数据存取过程
-
创建一个pool(池)分配PG
-
PG里可以存放多个对象
-
对象就是由客户端写入的数据分离的单位
-
使用CRUSH算法将客户端写入的数据映射分布到OSD,从而最终存放到物理磁盘上
pool是ceph存储数据时的逻辑分区,它起到namespace的作用。其他分布式存储系统都有pool的概念,只是叫法不同。每个pool包含一定数量的PG,PG里的对象被映射到不同的OSD上,因此pool是分布到整个集群的。 分布式存储对于运维工程师来说就一个可以随时拓展的大硬盘。
1)创建pool,这种方式需要编程手段实现
# 创建test_pool,指定pg数为128,默认的是32个 ceph osd pool create test_pool 128 # 查看pg数量 ceph osd pool get test_pool pg_num # 拓展:pg数与ods数量有关系,pg数为2的倍数,一般5个以下osd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低) ceph osd pool set test_pool pg_num 64 # 存储测试 ## 把本机的/etc/fstab文件上传到test_pool,并命名为newfstab rados put newfstab /etc/fstab -p test_pool # 查看上传的文件 rados ls -p test_pool # 下载newfstab文件到本地并命名为localfstab rados get newfstab localfstab -p test_pool # 删除 rados rm newfstab -p test_pool # 删除pool # 在部署节点node20上增加参数允许ceph删除pool vim /etc/ceph/ceph.conf mon_allow_pool_delete = true #修改了配置, 要同步到其它集群节点 ceph-deploy --overwrite-conf admin node20 node30 node60 systemctl restart ceph-mon.target #重启每台监控服务 ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it #pool名输两次
2、创建Ceph文件存储
1)配置pool格式
# 在node20部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA) ceph-deploy mds create node20 node2 node3 ## 一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。 ceph osd pool create cephfs_pool 128 ceph osd pool create cephfs_metadata 64 # 创建Ceph文件系统,并确认客户端访问的节点 ceph fs new cephfs cephfs_metadata cephfs_pool

# 客户端准备验证key文件 ## ceph默认启用了cephx认证, 所以客户端的挂载必须要验证在集群节点(node20,node2,node3)上任意一台查看密钥字符串 cat /etc/ceph/ceph.client.admin.keyring
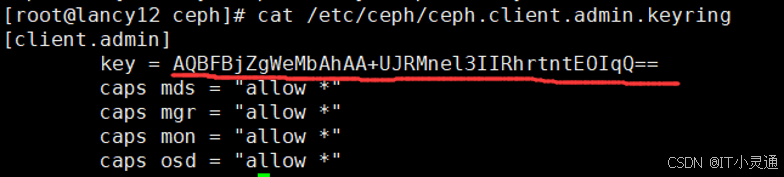
# 在客户端node4上创建一个文件记录密钥字符串,复制粘贴上面红色标出的字符串 vim admin.key ## 挂载ceph集群中运行mon监控的节点, mon监控为6789端口,可以使用两个客户端, 同时挂载此文件存储,可实现同读同写 mount -t ceph node20:6789:/ /mnt -o name=admin,secretfile=/root/admin.key
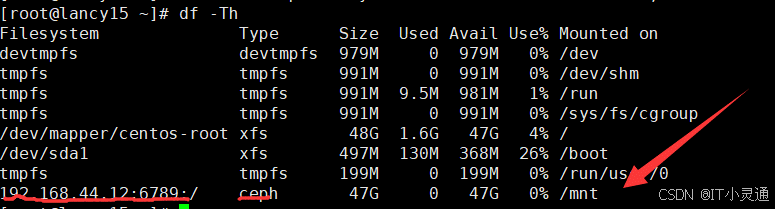
# 删除文件存储 # 在客户端上删除数据,并umount所有挂载 rm -rf /mnt/* umount /mnt/ # 停掉所有节点的mds(只有停掉mds才能删除文件存储,之后启动) systemctl stop ceph-mds.target # 回到集群任意一个节点上(node20,node2,node3其中之一)删除 ceph fs rm cephfs --yes-i-really-mean-it ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
3、创建Ceph块存储
1)配置Ceph块存储
# 在node20上同步配置文件到node4 ceph-deploy admin node4 # 注意:以下操作在客户端node4操作 # 建立存储池(卷组),并初始化 ceph osd pool create rbd_pool 128 rbd pool init rbd_pool # 创建一个存储卷 # 卷名为volume1,大小为5000M rbd create volume1 --pool rbd_pool --size 5000 rbd ls rbd_pool #查看卷列表 rbd info volume1 -p rbd_pool #查看卷信息
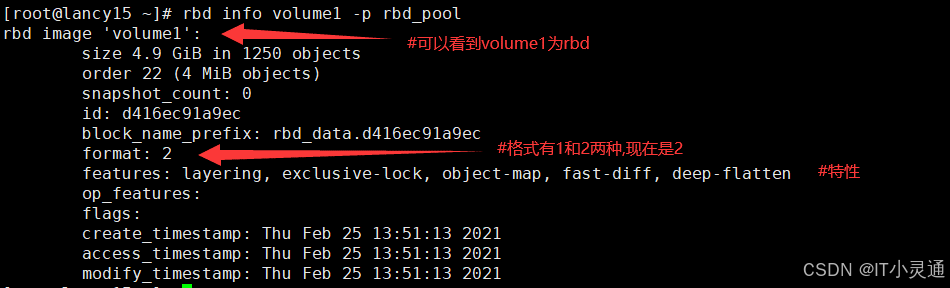
# 创建Ceph块存储 ## 因为rbd镜像的一些特性(object-map fast-diff deep-flatten),OS kernel并不支持,所以映射报错,需要关闭 rbd feature disable rbd_pool/volume1 object-map fast-diff deep-flatten ## 将创建的卷映射成块设备 rbd map rbd_pool/volume1 # 查看映射 rbd showmapped # 格式化,挂载 mkfs.xfs /dev/rbd0 mount /dev/rbd0 /mnt/ ## 注:块存储是不能实现同读同写的,请不要两个客户端同时挂载进行读写 # 块存储扩容 # 在线扩容,扩容成8000M rbd resize --size 8000 rbd_pool/volume1 rbd info rbd_pool/volume1 | grep size # 挂载格式扩容 xfs_growfs -d /dev/rbd0 # 删除块存储 umount /mnt/ rbd unmap /dev/rbd0 ceph osd pool delete rbd_pool rbd_pool --yes-i-really-really-mean-it
4、创建Ceph对象存储
1)测试ceph对象网关的连接
# 在node20上创建rgw ceph-deploy rgw create node20 #监听7480端口 # 客户端创建一个测试用户(access_key与secret_key,用于连接对象存储网关) radosgw-admin user create --uid="testuser" --display-name="First User" # S3连接ceph对象网关 # AmazonS3是一种面向Internet的对象存储服务,我们这里可以使用s3工具连接ceph的对象存储进行操作 # 客户端安装s3cmd工具,并编写ceph连接配置文件 yum install s3cmd -y #创建并编写下面的文件 vim /root/.s3cfg [default] access_key = E9GTLFFZ6D19G3VN9652 secret_key = djvdvqFzawGBW0qt2c3RfVz4X86GB2f2VwnML1EC host_base = node20:7480 host_bucket = node20:7480/%(bucket) cloudfront_host = node20:7480 use_https = False # 命令测试 # 列出bucket,可以查看到先前测试创建的my-new-bucket s3cmd mb s3://test_bucket #创建一个test_bucket s3cmd ls #查看已经有的连接 # 上传文件 s3cmd put /etc/fstab s3://test_bucket/aaa # 下载文件 s3cmd get s3://test_bucket/aaa
四、对象存储案例
1、Owncloud概述
1)Owncloud介绍 OwnCloud是一个PHP开发的开源免费专业的私有云存储项目,类似于百度网盘。 2)为什么需要搭建私有网盘。 公有网盘少,现在国内仅存的网盘——百度网盘。 下载速度慢,不购买SVIP——300K以下。 资料保密,公司的内部文档——禁止离开公司。 3)在哪里使用网盘 网络共享——百度网盘,360网盘,迅雷网盘等 公司内部共享——机密资料不可外泄
2、Owncloud优势
它可以帮你快速的在个人电脑或者服务器上假设一套专属的私有云文件同步网盘,也可以像百度网盘一样实现文件跨平台同步,共享等等。 OwnCloud能让你将所以的文件掌握在自己的手中,只要你的设备性能空间充足,那么几乎没有任何的限制。 跨平台性 OwnCloud跨平台支持windows、mac、Android、ios、linux等平台。 使用方式 提供了网页版形式的访问,因此你可以在任何电脑,手机上都可以获取到文件。
3、案例部署
1)案例环境
已经安装好ceph环境 使用ceph的对象存储方式 熟悉对象存储网关
2)案例拓扑图

3)部署步骤
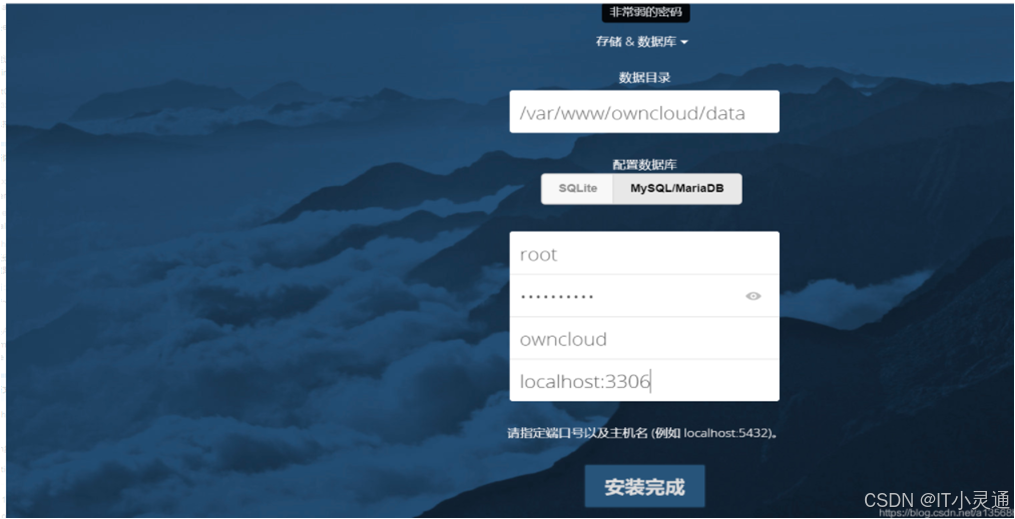
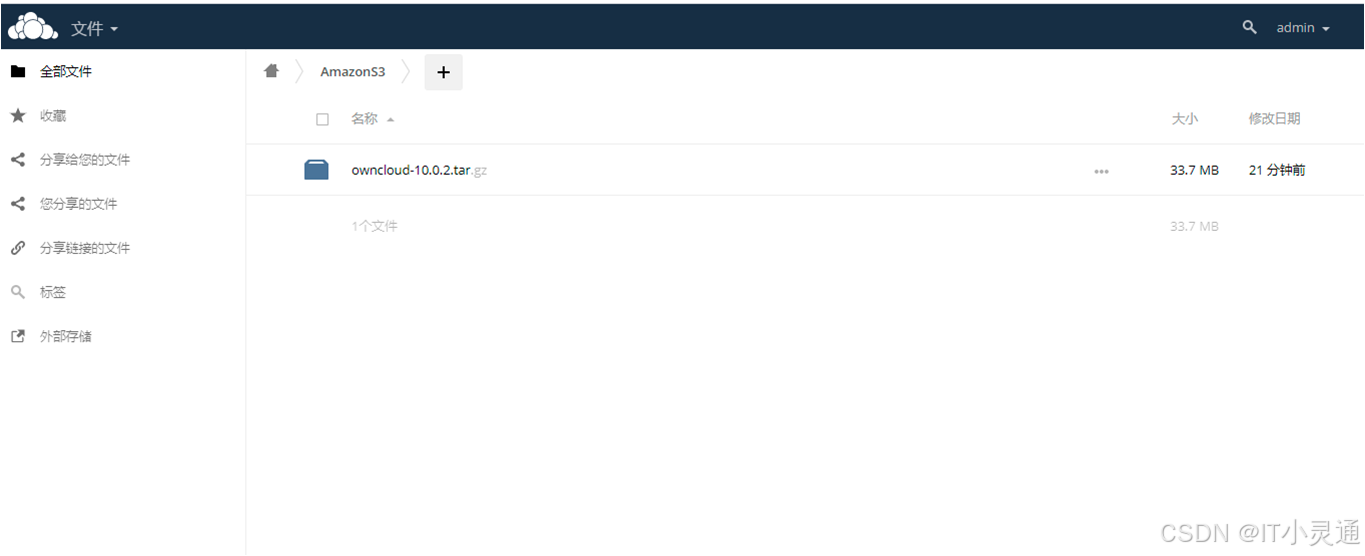
# 在ceph的客户端上准备好bucket和相关的连接key s3cmd mb s3://owncloud ## 在端安装owncloud云盘运行所需要的web环境 ## 配置php5.6阿里云 https://mirrors.aliyun.com/remi/enterprise/$releasever/php56/$basearch/ https://mirrors.aliyun.com/remi/enterprise/$releasever/safe/$basearch/ # 安装LAMP环境 yum install mariadb mariadb-server httpd mod_ssl php-mysql php php-gd php-xml php-mbstring –y # 初始化mariadb systemctl start mariadb #启动服务 systemctl enable mariadb #设置开机自启 mysql_secure_installation #设置安全选项 # 创建数据库owncloud create database owncloud character set utf8 collate utf8_bin; # 初始化httpd,设置ServerName systemctl start httpd #启动httpd systemctl enable httpd #设置开机自启 # 上传owncloud软件包, 并解压到httpd网站根目录 tar xf owncloud-10.0.2.tar.gz -C /var/www/html/ # 赋权 chown apache.apache -R /var/www/html/ #浏览器访问:IP/owncloud,配置数据库
配置S3连接
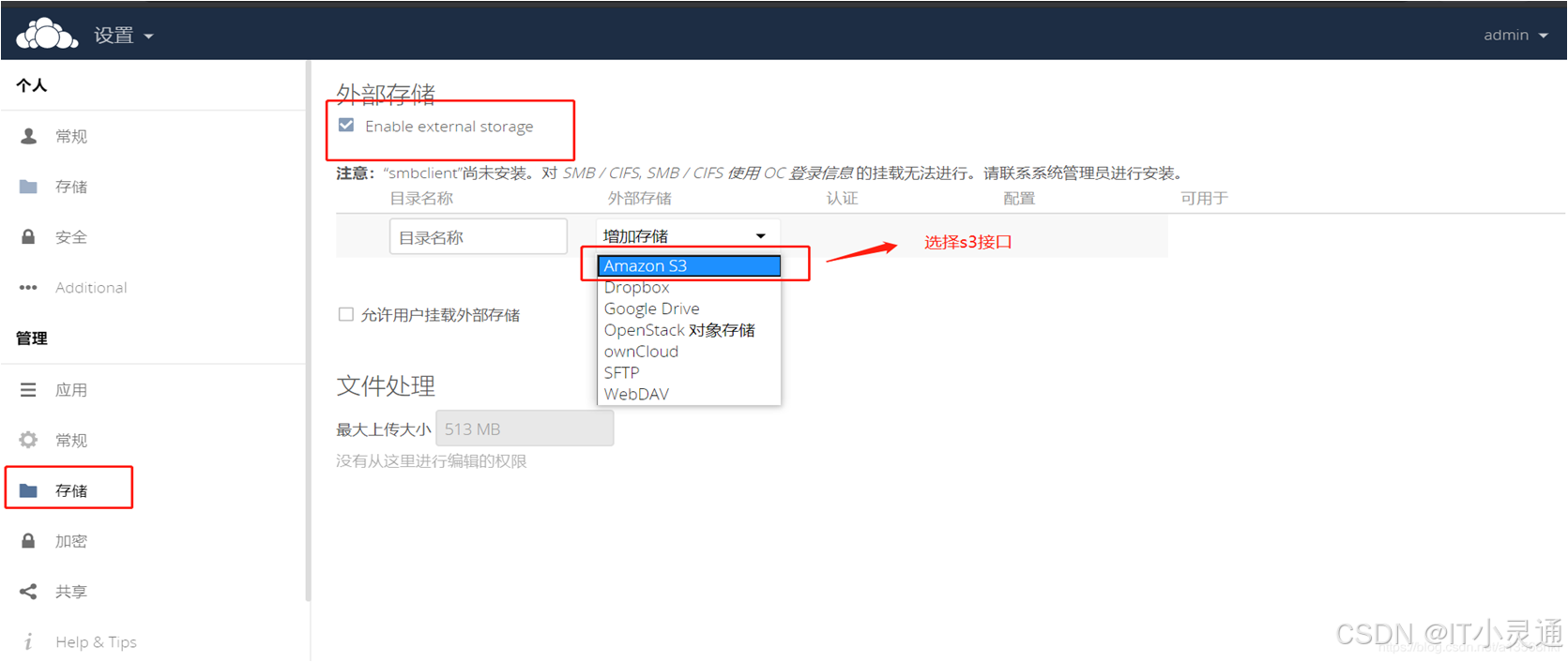
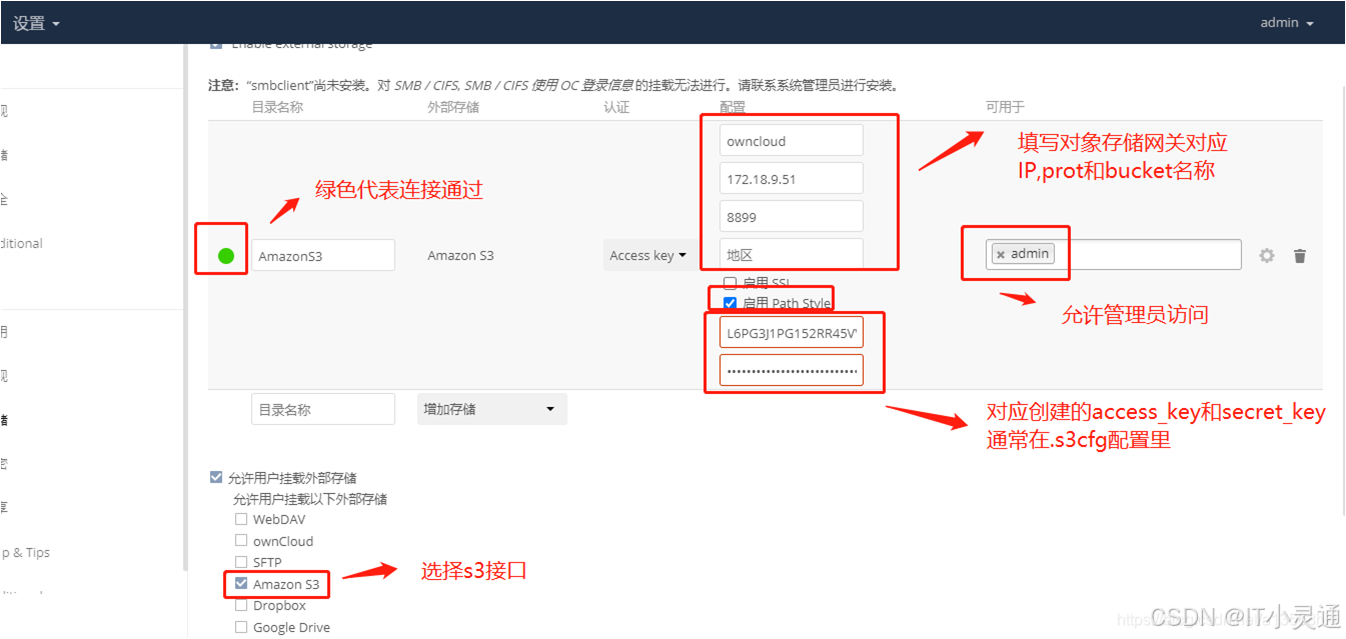
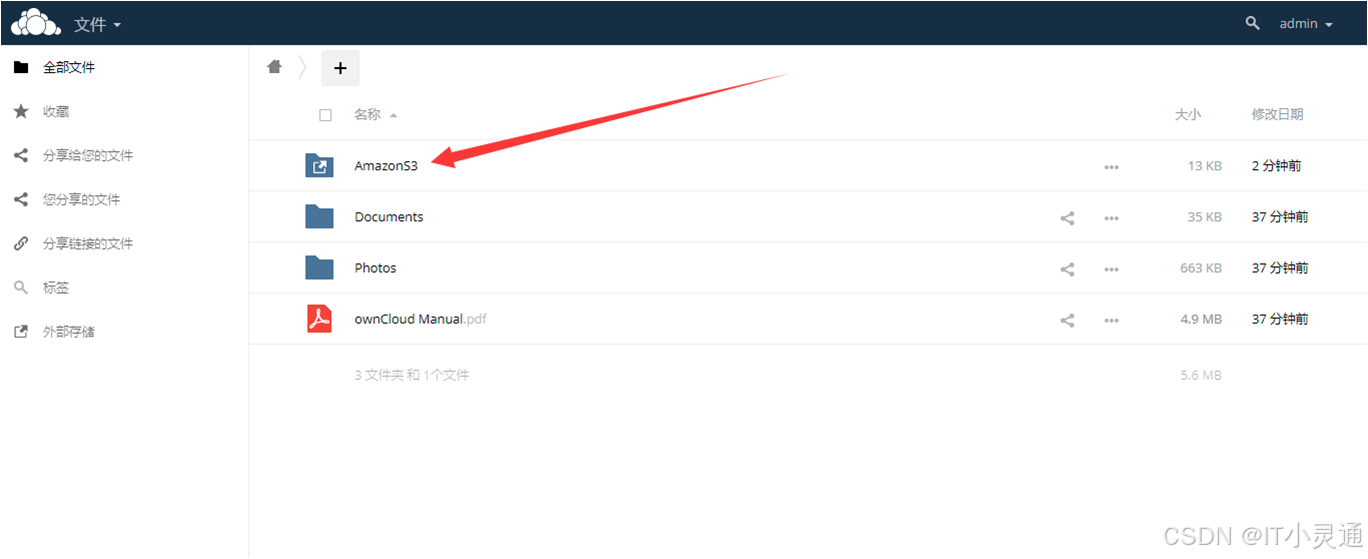
五、Ceph与Python开发
官方开发文档:Librados (Python) — Ceph Documentation
安装开发模块【rados】,开发环境需要在Linux环境中。
# Debian/Ubuntu/deepin sudo apt-get install python3-rados # RHEL/CentOS sudo yum install python-rados
连接ceph集群
# 导入开发模块 import rados # keyring = ceph.client.admin.keyring cluster = rados.Rados(conffile='ceph.conf', conf=dict(keyring='keyring')) cluster.connect()
管理池
# 列出可用的池
pools = cluster.list_pools()
for pool in pools:
print pool
# 创建池test
cluster.create_pool('test')
# 判断是否存在一个池
cluster.pool_exists('test')
# 删除池,需要配置权限
cluster.delete_pool('test')
列出池中所有的文件名
#使用ID方式:ioctx = cluster.open_ioctx2(pool_id)以下为使用池名称
ioctx = cluster.open_ioctx('test')
# 列出test池中的所有文件名
object_iterator = ioctx.list_objects()
while True :
try :
rados_object = object_iterator.__next__()
print ("Object contents = " + rados_object.key)
except StopIteration :
break
# 关闭池链接
ioctx.close()
上传文件
# 连接到test池
ioctx = cluster.open_ioctx('test')
# 读取本地数据
file_name = "yy.mp3"
f = open(file_name, "rb")
file_content = f.read()
f.close()
# 将文件写入池
ioctx.write_full(file_name, file_content)
# 关闭池链接
ioctx.close()
下载文件
# 连接到test池
ioctx = cluster.open_ioctx('test')
# 以二进制方式打开本地文件,没有则创建
f = open("yy.mp3", "wb")
# 将文件下载(写入)到本地
f.write(ioctx.read("yy.mp3"))
# 关闭所有文件链接
f.close()
ioctx.close()
删除文件
ioctx = cluster.open_ioctx('test')
# 删除test池中的yy.mp3文件
ioctx.remove_object("yy.mp3")
ioctx.close()
断开ceph集群连接
cluster.shutdown()
拓展知识:Ceph核心架构之RADOS集群原理及实现
1、核心架构
Ceph分布式存储系统的核心和基座就是RADOS集群。RADOS的全称为Reliable Autonomic Distributed Object Store,也就是可靠的,自修复分布式对象存储。其关键特性体现在两方面,一方面是数据是高可靠的;另外一方面是对于故障的自修复能力,比如出现宕机或者磁盘故障问题等情况下实现自动的故障处理,实现集群状态的修复。
Ceph核心组件有OSD、MON和librados。
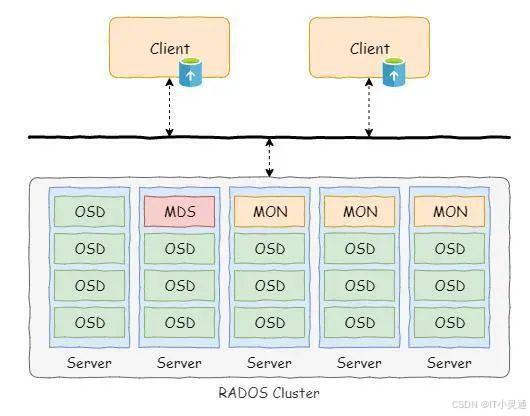
OSD组件是一个独立的服务,用于实现对磁盘的管理和分布式数据的备份和恢复。这个是数据层面的核心组件。通常来说,一个磁盘对应着一个OSD进程。
MON组件是Ceph的元数据服务组件,该组件管理着所有的元数据信息。例如集群的硬件情况、资源映射关系和存储池情况等等。
librados是位于客户端的软件,该软件为上层服务提供访问Ceph集群的接口,同时在该软件内会根据元数据信息进行数据位置的计算,并且实现数据的分发。
2、整体架构介绍
一个存储系统管理着大量的设备和数据。为了保证用户层面可以找到期望的数据,有需要对这些数据进行管理,管理数据的数据称为元数据。因此,任何存储系统的数据都分为用户数据和元数据,Ceph存储系统也不例外。
Ceph存储系统通过两个集群来存储RADOS的数据和元数据。其中MON集群用户存储Ceph存储系统的元数据,而OSD集群用户存储Ceph存储系统的数据。
Ceph的元数据比较简单,其中存储的是OSD集群的拓扑信息和一些资源的逻辑关系信息。这些信息的数量非常少,变化也不频繁。同时,客户端会缓存元数据,并且对于数据的定位是基于元数据计算而来,并不需要从元数据集群查询。基于这些特性,客户端对MON集群的访问非常少,因此不会成为系统的性能瓶颈。
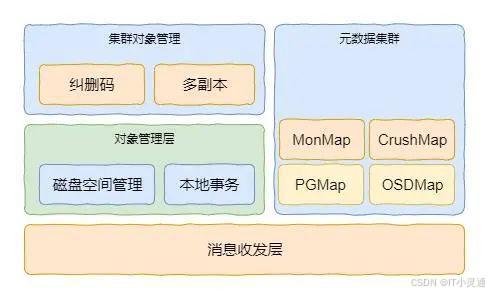
RADOS的整体软件架构如图所示,最底层负责消息的收发,通常是以太网,基于TCP/IP协议。然后是集群对象管理和本地对象管理,集群对象管理负责分布式对象的管理,保证对象数据的可靠性,本地对象管理负责逻辑对象数据与磁盘物理数据的对应关系。另外就是元数据集群,其中维护着各种Map信息,包括MonMap、CrushMap、PGMap和OSDMap。
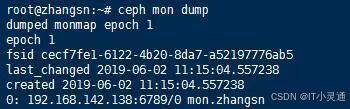
MonMap是对元数据集群的描述,其中包括元数据集群各个物理节点的IP地址等信息。如本专栏创建的集群的Mon信息。
OSDMap是集群中OSD物理节点的信息,包括IP地址、OSD权重和版本等内容。PGMap描述了数据PG与OSD的对应关系。PG在Ceph中成为放置组,它是Ceph存储池的逻辑单元,可以理解为存储池的逻辑分区。
客户端在初始化是会拉取最新的元数据信息,并缓存到客户端。当客户端对某个对象读写数据的时候,根据对象的名称可以计算出一个哈希值。然后,通过对哈希值与PG组取模运算,得到对应所处于的PG。最后根据PG与OSD的映射关系,可以定位到具体的OSD。
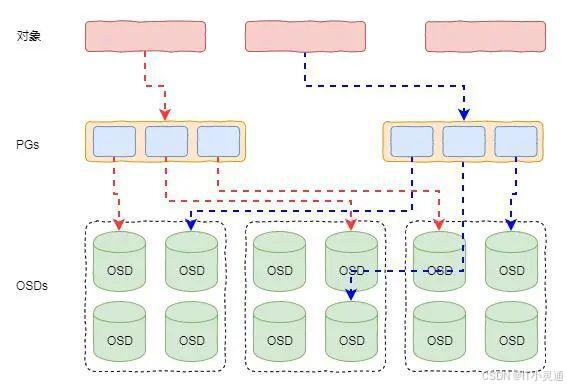
PG与OSD的对应关系是通过Crush算法计算得到的。这个映射关系通常是稳定的,但也是不稳定的,因为任何故障都会导致映射关系的变化,比如磁盘故障、服务器故障或者网卡故障等等。
可以看到从逻辑上来看,RADOS集群及组件并不复杂。但实际情况并非如此,RADOS集群的具体实现还是比较复杂的,这主要与其要处理的各种异常情况相关。
3、数据可靠性保证
数据的可靠性保证有两种手段,一种是通过多副本的方式,也就是同一个数据复制多份,并且存储在不同的位置;另一种方式是纠删码的方式,也就是通过类似校验和的方式。本文仅仅介绍多副本的方式。
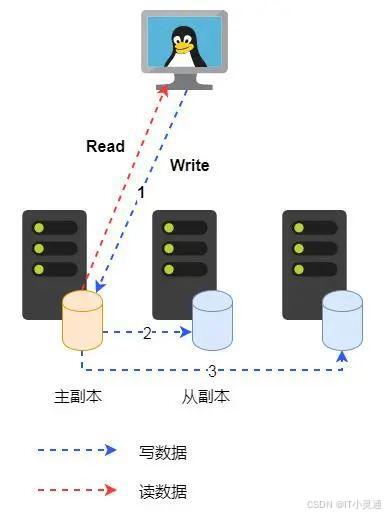
即使是多副本的数据可靠性技术在实现的时候又分为主副本模式和无主副本模式两种形式。所谓主副本模式是指同一个对象的数据请求会经过同一个副本,并且通过该副本复制到其它从副本。待所有副本处理成功后才返回给客户端。
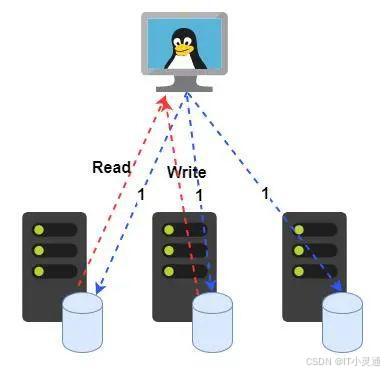
非主副本模式不存在具体的主副本,各个副本是对等的。为了保证数据的可靠性和一致性,客户端需要将数据同时发送到多个副本,保证至少规定的副本成功后才可以返回成功。
4、元数据可靠性保证
元数据的可靠性也是通过多副本保证的。在生产环境下,Ceph存储系统建议元数据服务器的数量最少为3台。也就是说元数据会同时存储在3台服务器上。这样,即使出现某一台服务宕机或者其它故障,仍然可以通过其它服务器访问元数据。
元数据的一致性保证与数据略有不同,它是通过一个名为Paxos的分布式一致性协议来保证的。关于该部分内容本文不再详细介绍,更详细的内容请参考《Paxos算法实例解析之Ceph Monitor》一文。
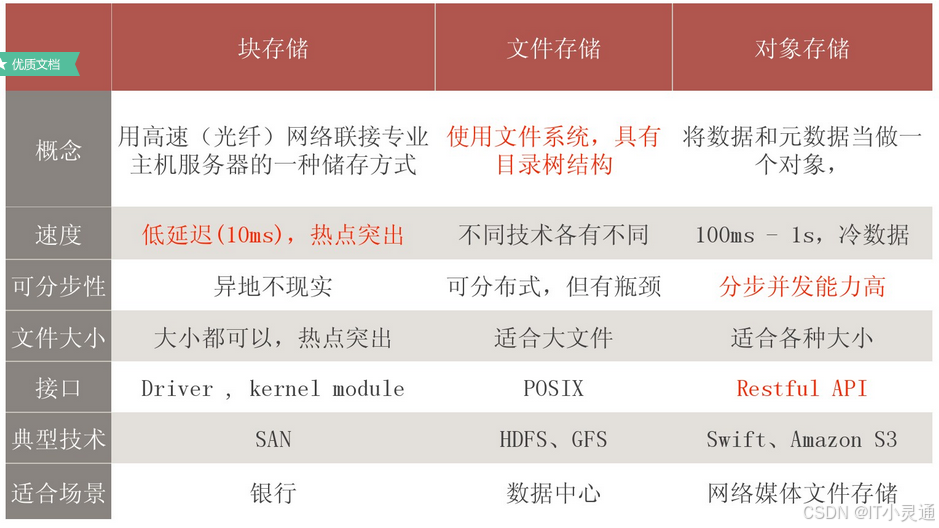
拓展知识: 块存储、文件存储、对象存储意义及差异
文件、块和对象是三种以不同的方式来保存、整理和呈现数据的存储格式。这些格式各有各的功能和限制。 这三者的本质差别是使用数据的“用户”不同:块存储的用户是可以读写块设备的软件系统,将数据拆分到任意划分且大小相同的卷中;文件存储的用户是自然人以文件和文件夹的层次结构来整理和呈现数据;对象存储的用户则是其它计算机软件会管理数据并将其链接至关联的元数据 。
这三个概念都是分布式存储中的概念,由不同的网络存储协议实现。不过“网络”和“存储”的结合本身会对解释这三个概念的本质差异带来不便,下面的解释中我会先解释存储本身,之后再结合网络来说明。
1、块存储
典型设备:磁盘阵列、硬盘 块存储主要是将裸磁盘空间整个映射给主机使用的。 就是说例如:磁盘阵列里面有5块硬盘,然后可以通过划逻辑盘、做Raid、或者LVM等方式逻辑划分出N个逻辑的硬盘。但是逻辑盘和物理盘是两个完全不同的概念。假设每个硬盘100G,共有5个硬盘,划分为逻辑盘也为5个,每个100G,但是这5个逻辑盘和原来的5个物理盘意义完全不同了。例如第一个逻辑盘第一个20G可能来自物理盘1,第二个20G来自物理盘2,所以逻辑盘是多个物理盘逻辑虚构出来的硬盘。 接着块存储会采用映射的方式将这几个逻辑盘映射给主机,主机上面的操作系统会识别到有5块硬盘,但是操作系统是无法区分到底是物理盘还是逻辑盘,它一概就认为只是5块裸的物理硬盘而已,跟直接拿一块物理硬盘挂载到操作系统没区别,至少操作系统感知上没有区别的。 在此方式下,操作系统还需要对挂载的裸硬盘进行分区、格式化后,才能使用,与平常主机内置的硬盘无差异。
优点
-
这种方式的好处当然是因为通过了Raid与LVM等手段,对数据提供了保护;
-
可以将多块廉价的硬盘组合起来,称为一个大容量的逻辑盘对外提供服务,提高了容量;
-
写入数据时,由于是多块磁盘组合出来的逻辑盘,所以几块硬盘可以并行写入的,提升了读写效率;
-
很多时候块存储采用SAN架构组网,传输速度以及封装协议的原因,使得传输速度和读写效率得到提升。
缺点
-
采用SAN架构组网时,需要额外为主机购买光纤通道卡,还要购买光纤交换机,造价成本高;
-
主机之间数据无法共享,在服务器不做集群的情况下,块存储裸盘映射给主机,在格式化使用后,对于主机来说相当于本地盘,那么主机A的本地盘根本不能给主机B去使用,无法共享数据;
-
不利于不同操作系统主机间的数据共享:因为操作系统使用不同的文件系统,格式化后,不同的文件系统间的数据是共享不了的。 例如一台win7,文件系统是FAT32/NTFS,而linux是EXT4,EXT4是无法识别NTFS的文件系统的。
2、文件存储

典型设备:FTP、NFS服务器 为了克服文件无法共享的问题,所以有了文件存储。 文件存储的用户是自然人,最容易理解。文件存储也有软硬一体化的设备,但是其实一台普通的PC机,只要装上合适的操作系统和软件,就可以假设FTP与NFS服务了,架上该类服务之后的服务器,就是文件存储的一种了。 主机A可以直接对文件存储进行文件的上传和下载,与块存储不同,主机A是不需要再对文件存储进行格式化的,因为文件管理功能已经由文件存储自己搞定了。
优点
-
造价低:随便一台机器就可以,另外普通的以太网就可以,根本不需要专用的SAN网络,所以造价低
-
方便文件共享
缺点
-
读写速率低,传输速率慢:以太网,上传下载速度较慢,另外所有读写都要1台服务器里面的硬盘来承受,相比起磁盘阵列动不动就十几上百块硬盘同时读写,速率慢了许多。
3、对象存储
典型设备:内置大容量硬盘的分布式服务器 对象存储最常用的方案,就是多台服务器内置大容量硬盘,再装上对象存储软件,然后再额外搞几台服务作为管理节点,安装上对象存储管理软件。管理节点可以管理其他服务器对外提供读写访问功能。 之所以出现对象存储这种东西,是为了克服块存储与文件存储各自的缺点,发扬各自的优点。简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写块,利于共享的存储出来呢?于是就有了对象存储。
首先,一个文件包含了属性(术语:metadata,元数据,例如该文件的大小、修改时间、存储路径等)以及内容(数据)。 像FAT32这种文件系统,是直接将一份文件与metadata一起存储的,存储过程先将文件按照文件系统的最小块大小来打散(例如4M的文件,假设文件系统要求一个块4K,那么就将文件打散称为1000个小块),再写进硬盘里,过程中没有区分数据和metadata的。而每个块最后会告知你下一个要读取的块地址,然后一直这样顺序的按图索骥,最后完成整份文件的所有块的读取。 这种情况下读写速率很慢,因为就算你有100个机械臂在读写,但是由于你只有读取到第一个块,才能知道下一个块在哪里,其实相当于只能有1个机械臂在实际工作。
而对象存储则将元数据独立出来了,控制节点叫元数据服务器(服务器+对象存储管理软件),里面主要负责存储对象的属性(主要是对象的数据被打散存放到了那几台分布式服务器中的信息)而其他负责存储数据的分布式服务器叫做OSD,主要负责存储文件的数据部分。当用户访问对象,会先访问元数据服务器,元数据服务器只负责反馈对象存储在哪里OSD,假设反馈文件A存储在B、C、D三台OSD,那么用户就会再次直接访问3台OSD服务器去读取数据。 这时候由于是3台OSD同时对外传输数据,所以传输的速度就会加快了,当OSD服务器数量越多,这种读写速度的提升就越大,通过此种方式,实现了读写快的目的。
另一方面,对象存储软件是有专门的文件系统的,所以OSD对外又相当于文件服务器,那么就不存在共享方面的困难了,也解决了文件共享方面的问题 所以对象存储的出现,很好的结合了块存储和文件存储的优点
为什么对象存储兼具块存储和文件存储的好处,还要使用块存储和文件存储呢?
-
有一类应用是需要存储直接裸盘映射的,例如数据库。因为数据需要存储楼盘映射给自己后,再根据自己的数据库文件系统来对裸盘进行格式化的,所以是不能够采用其他已经被格式化为某种文件系统的存储的。此类应用更合适使用块存储。
-
对象存储的成本比起普通的文件存储还要较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
下图简要的总结了三者之间的差异:
对象存储文件系统的关键技术是什么?
-
分布元数据
-
并发数据访问,对象存储体系结构定义了一个新的、更加智能化的磁盘接口OSD
什么是OSD?
存储局域网(SAN)和网络附加存储(NAS)是我们比较熟悉的两种主流网络存储架构,而对象存储是一种新的网络存储架构,基于对象存储技术的设备就是对象存储设备,简称:OSD
在存储对象中通过什么对象方式访问对象?
在存储设备中,所有对象都有一个对象标识,通过对象标识OSD命令访问对象
OSD的主要功能是什么?
-
数据存储。OSD管理对象数据,并将它们放置在标准的磁盘系统上,OSD不提供块接口访问方式,Client请求数据时用对象ID、偏移进行数据读写;
-
智能分布。OSD用其自身的CPU和内存优化数据分布,并支持数据的预取。由于OSD可以智能的支持对象的预取,从而可以优化磁盘的性能;
-
每个对象元数据的管理。OSD管理存储在其上对象的元数据,该元数据与传统的inode元数据相似,通常包括对象的数据块和对象的长度。
4、分布式存储
所谓分布式存储,就是这个底层的存储系统,因为要存放的数据非常多,单一服务器所能连接的物理介质是有限的,提供的IO性能也是有限的,所以通过多台服务器协同工作,每台服务器连接若干物理介质,一起为多个系统提供存储服务。为了满足不同的访问需求,往往一个分布式存储系统,可以同时提供文件存储、块存储和对象存储这三种形式的服务。

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









