







数字图像处理 第2章-数字图像基础
2.1 视觉感知要素
虽然数字图像处理这一领域建立在数学和概率公式表示的基础之上,但人的直觉和分析在选择一种技术而不选择另一种技术时会起核心作用,这种选择通常是基于主观的视觉判断做出的。因此,将大概了解人类的视觉感知作为学习的起点是合适的。
2.2 图像感知和获取
我们感兴趣的多数图像都是由“照射”源和形成图像的“场景”元素对光能的反射或吸收而产生的。把“照射”和“场景”加上引号是为了强调这样一个事实,即比我们所熟悉的一个可见光源每天照射普通的三维场景情况更一般。例如,照射可能由电磁能源引起,如雷达、红外线或X射线系统。但是,照射也可以由非传统光源(如超声波)甚至由计算机产生的照射模式产生。
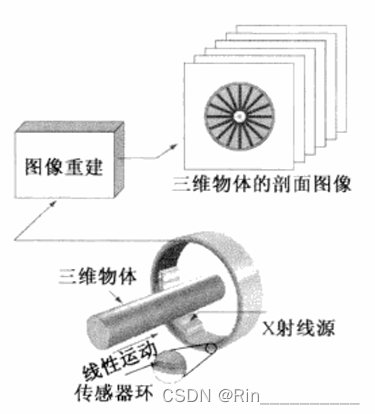
2.2.1 传感器获取图像的例子
最常见的例子如医学上的核磁共振成像(MRI),以得到三维物体的剖面(“切片”)图像。它以一个旋转的X射线源提供照射,射线源对面的传感器则收集穿过物体的 X射线能量(很明显,这些传感器必须对X射线敏感)。而传感器的输出必须由重建算法处理,重建算法的目的是把感知数据转换为有意义的剖面图像。换句话说,图像不可能单靠传感器的运动直接得到,它们需要进一步的处理。
2.2.2 简单的图像形成模型
正像在1.1节中介绍的那样,我们用形如f(x,y)的二维函数来表示图像。在空间坐标(x,y)处,f的值或幅度是一个正的标量,其物理意义由图像源决定。当一幅图像由物理过程产生时,其亮度值正比于物理源(如电磁波)所辐射的能量。因此,f(x,y)一定是非零的和有限的,即
0
<
f
(
x
,
y
)
<
∞
0<f(x,y)<∞
0<f(x,y)<∞
而函数 f(x,y)可由两个分量来表征:
(1)人射到被观察场景的光源照射总量;
(2)场景中物体所反射的光照总量。
这两个分量分别称为入射分量和反射分量,且分别表示为i(x,y)和r(x,y)。
两个函数作为一个乘积合并形成f(x,y),即
f
(
x
,
y
)
=
i
(
x
,
y
)
r
(
x
,
y
)
f(x,y)=i(x,y)r(x,y)
f(x,y)=i(x,y)r(x,y)
其中
0
<
i
(
x
,
y
)
<
∞
0<i(x,y)<∞
0<i(x,y)<∞
0
<
r
(
x
,
y
)
<
1
0<r(x,y)<1
0<r(x,y)<1
对于可见光,下面的平均数值用数字说明了i(x,y)的一些典型范围:(lm为流明,是描述光通量的物理单位)
在晴朗的白天,太阳在地面上可能会产生超过每平方米90000lm的照度。在有云的白天,这个数值下降到每平方米10000lm。在晴朗的夜晚,满月情况下的照度大约为每平方米0.1lm。商用办公室的典型照度约为每平方米1000lm。
类似地,下面是r(x,y)的一些典型值:
黑天鹅绒为0.01,不锈钢为0.65,白色墙为0.80,镀银金属为0.90,雪为0.93。
2.4 图像取样和量化
2.4.1 取样和量化的基本概念
由前一节的讨论,我们看到有多种获取图像的方法,但在所有这些方法中我们的目的是相同的。就是从感知的数据生成数字图像。多数传感器的输出是连续的电压波形,这些波形的幅度和空间特性都与感知的物理现象有关。为了产生一幅数字图像,我们需要把连续的感知数据转换为数字形式。这种转换包括两种处理:取样和量化。
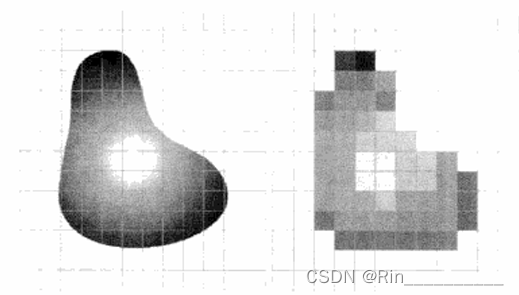
下面四张图说明了取样和量化的基本概念。
图1显示了一幅连续图像f,我们想把它转换为数字形式。一幅图像的x和y坐标及幅度可能都是连续的。为将它转换为数字形式,必须在坐标上和幅度上都进行取样操作。对坐标值进行数字化称为取样,对幅值数字化称为量化。
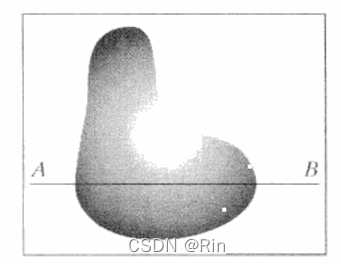
图2中的一维函数是图1中沿线段AB的连续图像幅度值(灰度级)的曲线。随机变化是由图像噪声引起的。
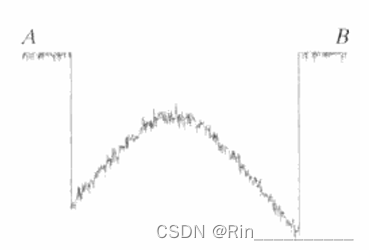
为了对该函数取样,我们沿线段 AB 等间隔地对该函数取样,如图3所示。

每个样本的空间位置由图形底部的垂直刻度指出。样本用放在函数曲线上的白色小方块表示。这样的一组离散位置就给出了取样函数。然而,样本值仍(垂直)跨越了灰度值的连续范围。为了形成数字函数,灰度值也必须转换(量化)为离散量。该图的右侧显示了已分为8个离散区间的灰度标尺,范围从黑到白。垂直刻度标记指出了赋予8个灰度的每一个特定值。通过对每一样本赋予8个离散灰度级中的一个来量化连续灰度级。赋值取决于该样本与一个垂直刻度标记的垂直接近程度。
取样和量化操作生成的数字样本如图4所示。
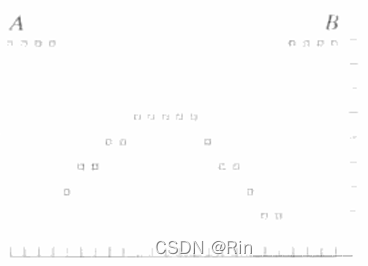
从该图像的顶部开始逐行执行这一过程,则会产生一幅二维数字图像。 意味着除了所用的离散级数外,量化所达到的精度强烈地依赖于取样信号的噪声。
下图显示了取样和量化后的图像。很明显,数字图像的质量在很大程度上取决于取样和量化中所用的样本数和灰度级。然而,在选择这些参数时,图像内容是一个重要的考虑因素。
2.4.2 数字图像表示
令f(s,t)表示一幅具有两个连续变量s和t的连续图像函数。如前一节解释的那样,通过取样和量化,我们可把该函数转换为数字图像。假如我们把该连续图像取样为一个二维阵列f(x,y),该阵列包含有M行和N列,其中(x,y)是离散坐标。为表达清楚和方便起见,我们对这些离散坐标使用整数值:x=0,1,2,…,M-1和y=0,1,2,…,N-1。这样,数字图像在原点的值就是f(0,0),第1行中下一个坐标处的值是 f(0,1)。这里,符号(0,1)表示第一行的第二个样本,它并不意味着是对图像取样时的物理坐标值。通常,图像在任何坐标(x,y)处的值记为f(x,y),其中x和y都是整数。由一幅图像的坐标张成的实平面部分称为空间域,x和y称为空间变量或空间坐标。
有3种基本方法表示f(x,y)。
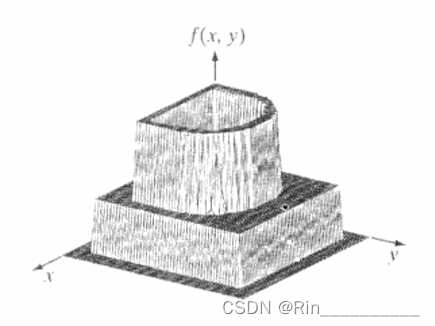
第一种方法是用两个坐标轴决定空间位置,第三个坐标是以两个空间变量x和y为函数的f(灰度)值。虽然我们可以在这个例子中用该图来推断图像的结构,但是,通常复杂的图像细节太多,以至于很难由这样的图去解译。
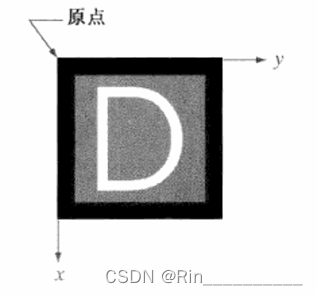
如下是更一般的表示。它显示了f(x,y)出现在监视器或照片上的情况。这里,每个点的灰度与该点处的f值成正比。该图中仅有三个等间隔的灰度值。如果灰度被归一化到区间[0,1]内,那么图像中每个点的灰度都有0,0.5或1这样的值。监视器或打印机简单地把这三个值分别变换为黑色、灰色或白色,如图所示。
第三种表示是将f(x,y)的数值简单地显示为一个阵列(矩阵)。在这个例子中,f的大小为600x600个元素,或360000个数字。很清楚,打印整个矩阵是很麻烦的,且传达的信息也不多。然而,在开发算法时,当图像的一部分被打印并作为数值进行分析时,这种表示相当有用。

在某些讨论中,使用传统的矩阵表示法来表示数字图像及其像素更为方便:
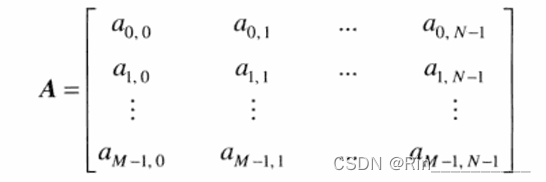
显然,
a
=
f
(
x
=
i
,
y
=
j
)
=
f
(
i
,
j
)
a =f(x=i,y= j)= f(i,j)
a=f(x=i,y=j)=f(i,j)
我们甚至可以将一幅图像表示一个向量。例如,尺寸为MNx1的列向量由v的第一M个元素作为A的第一列来构成,下一M个元素作为第二列,等等。我们也可以使用A的行代替列来形成这样的一个向量。只要一致,哪种表示都是有效的。
数字化过程要求针对 M值、N值和离散灰度级数做出判定对于M和N,除了必须取正整数外没有其他限制。然而,出于存储和量化硬件的考虑,灰度级数典型地取为2的整数次幂,即
L
=
2
k
L=2^k
L=2k
通常,将L个灰度值缩放至区间[0,1]对于计算或算法开发目的是有用的,这时,它们不再是整数。但多数情形下,这些值都会被缩放到用于图像存储和显示的整数区间[0,L-1]。
而存储一幅图所需的比特数为
b
=
M
×
N
×
k
b=M×N×k
b=M×N×k
2.4.3 空间和灰度分辨率
直观上看,空间分辨率是图像中可辨别的最小细节的度量。在数量上,空间分辨率可以有很多方法来说明,其中每单位距离线对数和每单位距离点数(像素数)是最通用的度量。
2.4.4 图像内插
内插是在诸如放大、收缩、旋转和几何校正等任务中广泛应用的基本工具。这一节我们的主要目标是介绍内插并用它调整图像的大小(收缩和放大),这是基本的图像重取样方法。
以下我们举例说明最近邻内插法:假设一幅大小为500x500像素的图像要放大15 倍到750x750像素。一种简单的放大方法是创建一个假想的 750x750网格,它与原始图像有相同的间隔,然后将其收缩,使它准确地与原图像匹配。显然,收缩后的750x750网格的像素间隔要小于原图像的像素间隔。为了对覆盖的每一个点赋以灰度值,我们在原图像中寻找最接近的像素,并把该像素的灰度赋给750x750网格中的新像素。当我们完成对网格中覆盖的所有点的灰度赋值后,就把图像扩展到原来规定的大小,得到放大后的图像。
但这种方法容易照成图像的失真,所以并不常用。
常用的是双线性内插:
对于双线性内插来说,赋值是由下面的公式得到的:
v
(
x
,
y
)
=
a
x
+
b
y
+
c
x
y
+
d
v(x,y)=ax+by+cxy+d
v(x,y)=ax+by+cxy+d
其中,4个系数可由4个用(x,y)点最近邻点写出的未知方程确定。
还有一种是双三次内插,它包括16个最近邻点。赋予点(x,y)的灰度值是使用下式得到的:
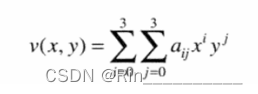
通常,双三次内插在保持细节方面比双线性内插相对要好。双三次内插是商业图像编辑程序的标准内插方法,比如Adobe PS。
2.5 像素间的一些基本关系
在这一节,我们考虑数字图像中像素间的几个重要关系。正如前面提及的那样,图像由f(x,y)表示。当在本节中引用某个特殊的像素时,我们通常会使用小写字母,如p和q。
2.5.1 相邻像素
位于坐标(x,y)处的像素p有4个水平和垂直的相邻像素,其坐标由下式给出:
(
x
+
1
,
y
)
,
(
x
−
1
,
y
)
,
(
x
,
y
+
1
)
,
(
x
,
y
−
1
)
(x+1, y),(x-1, y),(x,y+1),(x,y-1)
(x+1,y),(x−1,y),(x,y+1),(x,y−1)
这组像素为p的4邻域,记作
N
4
(
p
)
N_4(p)
N4(p)
方便笔记攥写,后续写作N4(p)
每个像素距(x,y)一个单位距离,如果(x,y)位于图像的边界上,则p的某些相邻像素位于数字图像的外部。
p的4个对角相邻像素的坐标如下:
(
x
+
1
,
y
+
1
)
,
(
x
+
l
,
y
−
1
)
,
(
x
−
l
,
y
+
1
)
,
(
x
−
1
,
y
−
1
)
(x+1, y+1),(x+l,y-1),(x-l,y+1),(x-1,y-1)
(x+1,y+1),(x+l,y−1),(x−l,y+1),(x−1,y−1)
记作
N
D
(
p
)
N_D(p)
ND(p)
方便笔记攥写,后续写作ND(p)
这些点与4 个邻点一起称为p的8邻域。
记作
N
8
(
p
)
N_8(p)
N8(p)
方便笔记攥写,后续写作N8(p)
与前面一样,如果(x,y)位于图像的边界上,某些邻点会落入图像的外边。
2.5.2 邻接性、连通性、区域、边界
邻接性
令V是用于定义邻接性的灰度值集合。在二值图像中,如果把具有1值的像素归诸于邻接像素,则V={1}。在灰度图像中,概念是一样的,但是集合V一般包含有更多的元素。例如,具有可能的灰变值范围为0到 255 的邻接像素中,集合V可能是这 256 个值的任何一个子集。
若有以下3种邻接:
(a)4邻接。如果q在集合N4(p)中,则具有V中数值的两个像素p和q是4邻接的。
(b)8邻接。如果q在集合N8(p)中,则具有V中数值的两个像素p和q是8邻接的。
©m邻接(混合邻接)。如果q在N4(p)中,或q在N8(p)中,且集合
N
4
(
p
)
∩
N
4
(
q
)
N_4(p) ∩ N_4(q)
N4(p)∩N4(q)
中没有来自V中数值的像素,则具有V中数值的两个像素p和q是m邻接的。
连通性
令S是图像中的一个像素子集。如果S的全部像素之间存在一个通路,则可以说两个像素p和q在S中是连通的。对于S中的任何像素p,S中连通到该像素的像素集称为S的连通分量。如果S仅有一个连通分量,则集合S称为连通集。(需要区别于数据结构中图的概念)
区域
令R是图像中的一个像素子集。如果R是连通集,则称 R为一个区域。两个区域,如果它们联合形成一个连通集,则区域Ri和Rj称为邻接区域。不邻接的区域称为不连接区域。
假设一幅图像包含有K个不连接的区域,即Rk,k=1,2.…,K,且它们都不接触图像的边界。
2.5.3 距离度量
计算距离的方式与初中数学中,坐标系上两点距离公式相似。
2.6 数字图像处理中所用数学工具的介绍
2.6.1 阵列和矩阵操作
对图像的操作是以像素为基础来执行的,所以一幅图像可以被等价的看成一个矩阵,矩阵相关的数学知识可以参考线性代数。
2.6.2 线性操作与非线性操作
个人理解为:
若
H
[
f
(
x
,
y
)
]
=
g
(
x
,
y
)
H[f(x,y)]=g(x,y)
H[f(x,y)]=g(x,y)
且
H
[
a
i
f
i
(
x
,
y
)
+
a
j
f
j
(
x
,
y
)
]
=
a
i
H
[
f
i
(
x
,
y
)
]
+
a
j
H
[
f
j
(
x
,
y
)
]
=
a
i
g
i
(
x
,
y
)
+
a
j
g
j
(
x
,
y
)
H[a_if_i(x,y)+a_jf_j(x,y)]=a_iH[f_i(x,y)]+a_jH[f_j(x,y)] =a_ig_i(x,y)+a_jg_j(x,y)
H[aifi(x,y)+ajfj(x,y)]=aiH[fi(x,y)]+ajH[fj(x,y)]=aigi(x,y)+ajgj(x,y)
则称输出是线性的。
反之很好理解,若不符合输入展开等于输出,则称输出是非线性的。参考高等数学。
2.6.3 算术操作
图像间的算术操作是阵列操作,其意思是算术操作在相应的像素对之间执行。4种算术操作表示为
s
(
x
,
y
)
=
f
(
x
,
y
)
+
g
(
x
,
y
)
s(x,y)=f(x,y)+g(x,y)
s(x,y)=f(x,y)+g(x,y)
d
(
x
,
y
)
=
f
(
x
,
)
−
g
(
x
,
y
)
d(x,y)=f(x,)-g(x,y)
d(x,y)=f(x,)−g(x,y)
p
(
x
,
y
)
=
f
(
x
,
y
)
×
g
(
x
,
y
)
p(x, y)= f(x, y)×g(x,y)
p(x,y)=f(x,y)×g(x,y)
v
(
x
,
y
)
=
f
(
x
,
y
)
÷
g
(
x
,
y
)
v(x,y)=f(x, y)÷g(x,y)
v(x,y)=f(x,y)÷g(x,y)
它可理解为是在f和8中相应的像素对之间执行操作,其中x=0,1,2,…,M-1,y=0,1,2.…,N-1。通常,M和N是图像的行和列。很清楚,s,d,p和v是大小为MxN的图像。注意,按照刚才定义的方式,图像算术操作涉及相同大小的图像(这又涉及到线性代数相关的知识,因为前面提到图像可以等价的视作一个矩阵,不同大小的矩阵是不能进行加减乘除的)。
2.6.4 集合和逻辑操作
集合
相关概念就是基本的数学知识。这里不再赘述。
逻辑操作
逻辑操作的原理很简单,就是我们计算机的基础。
在处理二值图像时,我们可以把图像想象为像素集合的前景(1值)与背景(0值)。然后,如果我们将区域(目标)定义为由前景像素组成,集合操作就变成了二值图像中目标坐标间的操作。处理二值图像时,OR、AND和NOT逻辑操作就是指普通的并、交和求补操作,其中“逻辑”’一词来自逻辑理论,在逻辑理论中,1代表真,0代表假。
模糊集合
前述的集合和逻辑结果是“干脆”的概念,在这种意义下,元素要么是要么不是集合中的成员这在某些应用中受到严重限制。考虑一个简单的例子。假如我们希望把世界上的所有人分为年轻人和非年轻人。使用“干脆”的集合,令U代表所有的人,令A是U的子集,我们把它称为年轻人集合。为了形成集合 A,我们需要一个隶属度函数,该函数可以对 U中的每个元素(人)赋1值或0值。如果 U中的元素赋值为1,则该元素就是A的–个成员,否则就不是A的一个成员。因为我们是在处理二值逻辑,隶属度函数简单地定义为一个阈值,低于该阈值的人考虑为年轻人,高于该阈值的人考虑为非年轻人。假如我们定义任何 20岁或更年轻的人是年轻人。我们面临一个直接的困难:年龄为20岁零1秒的人将不是年轻人集合的成员。这一限制出现在我们用于分类年轻人年龄的阈值上。什么是我们意味的“年轻”需要更多的灵活性,即需要从年轻到非年轻逐步过渡。模糊集合理论使用隶属度函数来实现这种概念,该函数在数值1(定义为年轻)和0(定义为非年轻)之间逐步过渡。使用模糊集合我们可以声明一个人的年轻度为50%(年轻和非年轻过渡的中间)。换句话说,年龄是一个不精确的概念,而模糊逻辑提供处理这种概念的工具。
2.6.5 空间操作
空间操作直接在给定图像的像素上执行。我们把空间操作分为三大类:
(1)单像素操作
我们在数字图像中执行的最简单的操作就是以灰度为基础改变单个像素的值。这类处理可以用一个形如下式的变换函数T来描述:
s
=
T
(
z
)
s=T(z)
s=T(z)
其中,z是原图像中像素的灰度,s是处理后的图像中相应像素的(映射)灰度。
(2)邻域操作
令S代表图像f中以任意一点(x,y)为中心的一个邻域的坐标集。邻域处理在输出图像g中的相同坐标处生成一个相应的像素,该像素的值由输入图像中坐标在S内的像素经指定操作决定。
(3)几何空间变换
几何变换改进图像中像素间的空间关系。这些变换通常称为橡皮膜变换,因为它们可看成是在一块橡皮膜上印刷一幅图像,然后根据预定的一组规则拉伸该薄膜。
在数字图像处理中,常见的有坐标的空间变换:
通过数学操作来实现我们所可以直观感受到的旋转、平移、放大缩小或偏移操作。

2.6.6 向量和矩阵操作
我们知道,彩色图片由彩色的像素组成,而彩色的像素是由一个3维向量来表示的
z = [ z 1 z 2 z 3 ] z = \begin{bmatrix} \begin{matrix} z_1 \\z_2 \\z_3\\\end{matrix} \end{bmatrix} z= z1z2z3
其中,z1是红色图像中像素的亮度,其他两个元素是相应的绿色图像和蓝色图像中像素的亮度。
这样,大小为M×N的RGB彩色图像就可用这一大小的三个分量图像来表示,或者总共用M*N个三维向量来表示。
一旦像素被表示为向量,我们就可以使用向量矩阵理论这一工具。
参考书籍:数字图像处理(第三版)冈萨雷斯


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









