







 SQL是一种声明式语言,主要用于处理关系型数据库。文中详细介绍了SQL的声明式特性、DDL(数据定义语言)用于修改和定义模式,DML(数据操纵语言)用于查询和操作数据。重点讨论了GROUPBY和HAVING子句在数据分组和过滤中的应用,以及聚合函数如AVG、COUNT等如何对数据进行汇总。此外,还提到了NULL值在SQL中的特殊处理方式和在查询中的影响。
SQL是一种声明式语言,主要用于处理关系型数据库。文中详细介绍了SQL的声明式特性、DDL(数据定义语言)用于修改和定义模式,DML(数据操纵语言)用于查询和操作数据。重点讨论了GROUPBY和HAVING子句在数据分组和过滤中的应用,以及聚合函数如AVG、COUNT等如何对数据进行汇总。此外,还提到了NULL值在SQL中的特殊处理方式和在查询中的影响。
1.sql
sql的pros and cons
-
declarative声明式
-
not targeted at Turing-complete tasks
sql不是图灵完备的。
图灵完备性指的是系统模拟图灵机的能力,而SQL本身并不具备这种能力。
-
General-purpose(通用) and feature-rich
SQL can indeed call out to other languages and extend its functionality.
relational terminology
-
relation(table)
-
【形式】schema就是table(Relation)的格式?有几列,分别是什么意思
-
【数据】instance:满足schema的数据集
-
-
attribute(a column/field of a relational table)[感觉是只有一列的table]
a column of data(it’s got a schema and an instance)
-
tuple (a record or a row) is an individual row in the table
relational tables
-
schema is fixed
-
unique属性名,属性具有原子性(不可再分)
-
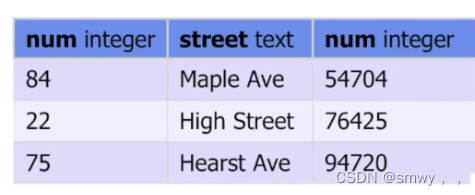
每列应该有不同的名称
each column should have distinct name

不符合atomic
-
-
instance can change often插入的数据可以经常被改变
A row must have an entry for each column(如果可以是null呢??)
sql language
-
Data Definition language DDL
修改、定义schema
-
DML Data Manipulation Language
write queries(manipulate the instance the actual data)(增删改查)
-
RDBMS(ralational …) is responsible for efficient evaluation of the sql language.
-
choose and run algorithms and the choice of algorithm must not affect query answer.
database实现查询的方式很多,但是结果一定一样
-
DDL
PRIMARY KEY
-
provide a unique “lookup key” for the relation
-
doesn’t have to be single column
-
duplicate constraint
Foreign keys
-
pointers in schemas–a pointer it references to the b table-the column points to the b tables
-
by definition, a foreign key references the primary key columns of the table that it references
basic single-table queries
select[distinct] <column expression list>FROM<SINGLE TABLE>[WHERE<PREDICATE>] 从single table中选择出满足where谓词的所有元组,输出这些元组的expression list(可以是列索引,也可以是表达式)这些列 distinct指明了输出去除重复的元组 FROM student S 指把student表称作S,是别名 student AKA S SELECT S.name,S.gpa*2 AS a2将gpa*2这一列以名为a2的列输出 ORDER BY S.gpa,S.name,a2;以字典序输出(??这怎么排??三个吗)--(This means that the result will be ordered first by Sgpa, then by S.name, and finally by a2 in lexicographic order.) 先按gpa升序,gpa相同就按name字典序,前两者相同就按a2升序[Ascending order by default] ORDER BY S.gpa DESC,S.name ASC,a2;[默认升序,指定DESC降序,ASC升序] LIMIT 3;[只输出前三行] SELECT AVG(S.gpa)输出符合条件的元组的gpa的均值(一行)Other aggregates:SUM,COUNT,MAX,MIN
distinct:
SELECT [DISTINCT] AVG(S.gpa), S.dept FROM Students S GROUP BY S.dept 输出:Query A has a row of output for every department and its average GPA假设有五个部门就输出五行数据 这个distinct:DISTINCT 关键字的作用是确保查询结果中的行是唯一的,消除重复的行。【确保输出的行是唯一的】 DISTINCT 关键字应用于整个结果集中的每一行,确保返回的结果集中每一行都是唯一的。它的作用域涵盖了所有被选择的列,包括 AVG(S.gpa) 和 S.dept。在给定的查询中,如果使用 SELECT DISTINCT AVG(S.gpa), S.dept,当两个不同的部门 A 和 B 的平均GPA值都是 3.5 时,将会输出两行数据,分别显示部门 A 和 3.5,以及部门 B 和 3.5。每个不同的组合 (平均GPA, 部门) 将作为单独的行出现在查询结果中。 The given SQL query is calculating the average GPA (grade point average) for each department in the Students table and returning the results. 输出两列:AVG(S.gpa), S.dept;AVG(S.gpa)是按S.dept不同来计算的各dept对应的gpa的均值 It means that the average GPA will be calculated for each unique department in the table. Partition table into groups with same GROUP BY column values以该列不同的值分类 每组产生一个aggregate值 the number of distinct values in that column will determine the cardinality or the number of rows in the output result set. dept中不同的值会决定输出的set中的行数 Note: can put grouping columns in SELECT list就是也可以输出dept,这样就能对应
HAVING predicate:
SELECT [DISTINCT] AVG(S.gpa), S.dept FROM Students S GROUP BY S.dept HAVING COUNT(*) > 2 The HAVING COUNT(*) > 2 part filters the groups based on the condition that the count of rows in each group (represented by COUNT(*)) must be greater than 2.每组必须超过两个人才会输出 In other words, the query will calculate the average GPA (AVG(S.gpa)) for each department (S.dept) in the Students table, but it will only include the departments in the result set if they have more than 2 students. The HAVING clause is applied after the GROUP BY clause to filter the grouped results based on the specified condition.这个语句作为分组后的filter滤出 The HAVING predicate filters groups滤出功能 HAVING is applied after grouping and aggregation 在grouping和聚合的基础上使用 Hence can contain anything that could go in the SELECT list因此能contain any expressions or conditions that could also appear in the SELECT list of the query. This includes aggregate functions (such as COUNT, SUM, AVG, etc.) and the columns used for grouping.[针对不同组,把一组看出一个整体进行一些聚合操作] eg: SELECT Department, COUNT(*) AS NumEmployees FROM Employees GROUP BY Department HAVING COUNT(*) > 10; In this query, the HAVING clause is evaluating the condition COUNT(*) > 10, which compares the count of employees in each department to the value 10. It is applied after the grouping and aggregation have taken place. The COUNT(*) expression appears both in the SELECT list to calculate the count of employees and in the HAVING clause to filter out the groups where the count is not greater than 10.因此having能让你基于aggregate这些值或者列上指定条件从而 further filter and refine the grouped results
illegal:
SELECT S.name, AVG(S.gpa) FROM Students S GROUP BY S.dept; 这个是会输出什么?会输出所有学生的名字吗? It will only display the name of one student per department along with the corresponding average GPA for each department.每个dept只有一行,这个是非法的查询、,因为使用了不在GROUP BY这个column里面的column【就是说name不在group by里也不再聚合函数aggregate中】,因为学生可能有很多个,我们无法将其归为一个值,因为每个dept没有独特的学生名字,是没有意义的。
query a table
-
Filtering out uninteresting rows删去不感兴趣的行
-
输出指定的列
filtering null values—NULL短路是为什么??
• If you do anything with NULL, you’ll just get NULL. For instance if x is NULL, then x > 3, 1 = x, and x + 4 all evaluate to NULL. Even x = NULL would evaluate to NULL; 如果您想要检查x是否为NULL,您应该使用IS NULL或IS NOT NULL来进行判断。 例如,WHERE x IS NULL可以用来筛选出x为NULL的行。 是什么意思?表达式也能有值吗?是true or false or null吗 是当x是null的时候,如果要判断的条件是x>3,1=x,x+4(对于表达式 x + 4,如果 x 是 NULL,根据标准的SQL行为,其结果应该是 NULL),x=NULL,这些表达式的值都是NULL。比如WHERE x>3,这一行是不会被选中的。 NULL is falsey, meaning that WHERE NULL is just like WHERE FALSE. The row in question does not get included 什么意思--这个数据是NULL就不会被WHERE操作后选中 NULL短路?? NULL short-circuits with boolean operators. That means a boolean expression involving NULL will evaluate to: – TRUE, if it’d evaluate to TRUE regardless of whether the NULL value is really TRUE or FALSE. – FALSE, if it’d evaluate to FALSE regardless of whether the NULL value is really TRUE or FALSE. – Or NULL, if it depends on the NULL value. 什么意思 Because NULL is falsey, this row will be excluded
grouping and aggregation
summarizing columns of data【summarize an entire column of your database into a single number.】
characteristics The input to an aggregate function is the name of a column, and the output is a single value that summarizes all the data within that column (输入是column输出是单值--一列到单值) Every aggregate ignores NULL values except for COUNT(*). (So COUNT(<column>) returns the number of non-NULL values in the specified column, whereas COUNT(*) returns the number of rows in the table overall. (COUNT(<column>)聚合忽略NULL,COUNT(*) 返回表中的总行数)
单个值的表格与单个值本身没有本质上的区别:
So, if we desired the range of ages represented in our database, then we could use the query below and it would produce the result 20. (Technically it would produce a one-by-one table(包含单个值的表) containing the number 20, but SQL treats it the same as the number 20 itself. 在SQL中,查询结果被组织为表格形式,即使结果只有一个单元格也是如此。所以,即使查询结果只有一个值20,它仍然被表示为一个表格,其中包含一个单元格,并且这个单元格中的值是20。虽然查询结果以表格形式返回,但对于SQL来说,这个包含单个值的表格与单个值本身没有本质上的区别。
Summarizing Groups of Data
having:
This is possible with the GROUP BY clause, which allows us to split our data into groups and then summarize each group separately.( every group gets collapsed into a single row) SELECT <columns> FROM <tbl> WHERE <predicate> −− Filter out rows ( before grouping ) .(It filters out uninteresting rows)滤除不感兴趣的行 GROUP BY <columns> HAVING <predicate>; −− Filter out groups ( after grouping ) .( It filters out uninteresting groups)滤出不感兴趣(不符合要求)的groupA、B这些 在分组后执行having count(*)>1判定,对每一个group都执行having,和where类似,但是having是在grouping之后
顺序:
So, to recap, here’s how you should go about a query that follows the template above: • Start with the table specified in the FROM clause. • Filter out uninteresting rows, keeping only the ones that satisfy the WHERE clause. • Put data into groups, according to the GROUP BY clause. • Filter out uninteresting groups, keeping only the ones that satisfy the HAVING clause. • Collapse each group into a single row, containing the fields specified in the SELECT clause. 先看FROM选中表,再看WHERE从表中滤除不符合条件的行,再看GROUP BY将剩余行分组,再看HAVING滤除不符合条件的组,再将每组压缩成一行(?为什么?如果SELECT中没有aggregate这类的要怎么办?也还是一组一行吗?---如果SELECT中有非分组依据的column实际上是非法的。)
distinct在group后的影响:
还是不明白distinct在group这一类之后的影响?? SELECT age FROM Person WHERE age >= 18 GROUP BY age HAVING COUNT( ∗ ) > 1 ; 但是这个没有用distinct会输出几行呢?假设有三行age为18的,那么输出也是输出三行18吗 不对,只要用了GROUP BY就是会把每组变成一行,所以应该是一行18 用上distinct是会只输出一行吗? 没影响 SELECT age ,AVG( num dogs ) FROM Person WHERE age >= 18 GROUP BY age HAVING COUNT( ∗ ) > 1 ;假设有三行age为18的,那么输出也是输出三行18吗然后他们的AVG( num dogs )相同? 一行 DISTINCT是在输出之前删除重复的行 DISTINCT的作用是在结果集中选择不同的行,它不会影响从表中选择的过程。
eg:
SELECT DISTINCT AVG(gpa),age FROM students S WHERE S.dept='CS' GROUP BY S.age;
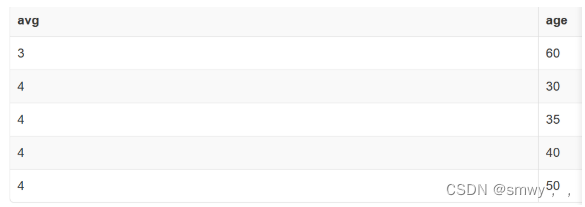
distinct具体区别:
SELECT COUNT(DISTINCT S.name) From Students S WHERE S.dept = 'cs'; SELECT DISTINCT COUNT( S.name) From Students S WHERE S.dept = 'cs'; 两者并不相同: 第一个是在计数之前先把重复名字删除,如果有10个Bob,4个Mary将会只有两个不同的名字就是2 第二个我们得到14后删除重复行但是只有14这一行所以输出14
A Word of Caution
SELECT age , AVG( num dogs ) FROM Person ; age is an entire column of numbers, whereas AVG(num dogs) is just a single number 非法 SELECT age , num dogs FROM Person GROUP BY age ; Then the SELECT clause’s job is to collapse each group into a single row. 只要用了GROUP BY 就是会在SELECT时把每组变成一行 总之避免非法就要在SELECT grouped/aggregated columns If you’re going to do any grouping / aggregation at all, then you must only SELECT grouped / aggregated columns.
大小写问题
keyword、alias、table name的大小写都没事,都不太敏感


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









