






目录
2、分析与设计
2.1业务规则(描写题目的需求,包括实体之间的对应关系)
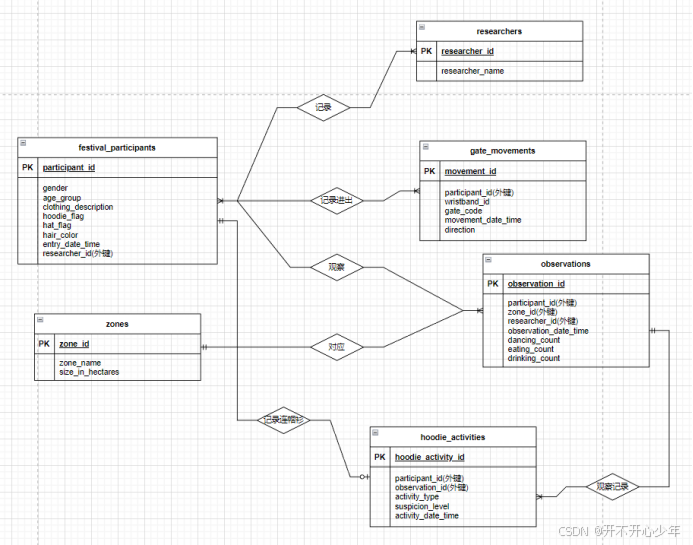
Rainbow Research (RR) 受音乐节的安保公司委托,进行参与音乐节的人员行为研究。RR 希望通过自动化的方式收集数据,并提供给研究人员一个数据收集应用程序(RR App)。研究人员将使用这个应用程序记录参与者的行为、穿着、以及进入音乐节区域的相关信息。音乐节的安保系统还会记录参与者的腕带扫描情况,以便后续分析。
主要需求包括:
记录参与者的个人特征(性别、年龄组、穿着等)。
记录参与者进出音乐节大门的情况。
记录研究人员对参与者的观察,特别是对穿连帽衫参与者的行为观察。
提供相关数据的查询和统计功能。
实体之间的对应关系:
festival_participant - researcher :每个音乐节参与者由一个研究人员记录,可能有多名参与者由同一名研究人员记录。
festival_participant – gate_movements:每个音乐节参与者可以有多个进出记录,通过不同的大门多次进出。
festival_participant – hoodie_activity:穿连帽衫的参与者可能有多个行为记录。
researcher – observation:每名研究人员可能会在不同的时间对多个区域进行观察。
zone – observation:每个区域可能会有多次观察记录。
2.2 命名约定(描写命名规则)
- 命名长度:大多数数据库系统对字段名的长度有限制,一般在1到64个字符之间。
- 字符限制:通常字段名只能包含字母(A-Z,a-z)、数字(0-9)和某些特殊字符,如下划线(_)或美元符号($)。不允许使用特殊字符。
- 首字符:字段名通常不能以数字开头。
- 关键字:字段名不能是数据库的保留关键字,如 SELECT、FROM、WHERE 等。
- 大小写敏感性:MySQL默认是大小写不敏感的,统一用小写加下划线的形式命名。
- 简洁性:字段名应简洁且具有描述性,易于理解。
- 一致性:在同一个数据库中,应保持命名规则的一致性。
2.3 数据类型选择(给出数据项相应的数据字典,如下表 )
表2.3.1 Festival Participant(音乐节参与者)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| participant_id | INT | 是 | 否 | 自增唯一标识符 | ||
| gender | VARCHAR | 10 | 否 | 否 | 性别(Male, Female, Other) | |
| age_group | VARCHAR | 5 | 否 | 否 | 年龄组(如:<20, 20-30) | |
| clothing_description | VARCHAR | 255 | 否 | 是 | 衣着描述 | |
| hoodie_flag | BOOLEAN | 否 | 否 | 是否穿连帽衫 | ||
| hat_flag | BOOLEAN | 否 | 是 | 是否戴帽子 | ||
| hair_color | VARCHAR | 20 | 否 | 是 | 头发颜色 | |
| entry_date_time | DATETIME | 否 | 否 | 进入时间 | ||
| researcher_id | INT | 否 | 否 | 外键,研究人员id |
表2.3.2 Researcher(研究人员)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| researcher_id | INT | - | - | 是 | 否 | 自增唯一标识符 |
| name | VARCHAR | 100 | - | 否 | 否 | 研究人员姓名 |
| | VARCHAR | 100 | - | 否 | 否 | 电子邮件 |
| phone | VARCHAR | 20 | - | 否 | 否 | 联系电话 |
表2.3.3 GateMovements(进出记录)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| movement_id | INT | 是 | 否 | 自增唯一标识符 | ||
| participant_id | INT | 否 | 否 | 外键,关联 festival_participant | ||
| wristband_id | VARCHAR | 50 | 否 | 否 | 腕带ID | |
| gate_code | VARCHAR | 10 | 否 | 否 | 大门代码(如:Main, South,East) | |
| direction | ENUM | 3 | 否 | 否 | 标志(IN/OUT) | |
| date_time | DATETIME | 否 | 否 | 记录日期时间 |
表2.3.3 Zone(音乐节区域)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| zone_id | INT | 是 | 否 | 自增唯一标识符 | ||
| zone_name | VARCHAR | 100 | 否 | 否 | 区域名称 | |
| size_hectares | DECIMAL | 5 | 2 | 否 | 否 | 区域大小(公顷) |
表2.3.4Hoodie Activity(连帽衫活动)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| hoodie_activity_id | INT | 是 | 否 | 自增唯一标识符 | ||
| participant_id | INT | 否 | 否 | 外键,关联 festival_participant | ||
| observation_id | INT | 否 | 否 | 外键,观察记录ID | ||
| activity_type | VARCHAR | 100 | 否 | 否 | 活动类型 | |
| suspicion_level | INT | 否 | 否 | 怀疑等级(1-9) | ||
| activity_date_time | DATETIME | 否 | 否 | 记录日期时间 |
表2.3.5 Observation(观察记录)表
| 属性 | 数据类型 | 长度 | 小数点 | 主键 | 空值 | 备注 |
| observation_id | INT | 是 | 否 | 自增唯一标识符 | ||
| participant_id | INT | 否 | 否 | 外键,参与者ID | ||
| researcher_id | INT | 否 | 否 | 外键,关联 researcher | ||
| zone_id | INT | 否 | 否 | 外键,关联 zone | ||
| observation_date_time | DATETIME | 否 | 否 | 观察日期时间 | ||
| dancing_count | INT | 否 | 是 | 观察到跳舞的人数 | ||
| eating_count | INT | 否 | 是 | 观察到吃饭的人数 | ||
| drinking_count | INT | 否 | 是 | 观察到喝酒的人数 |
3、数据对象及查询
3.1 视图
需求:
能够展示参加音乐节的人员的基本信息以及他们的观察记录。这可以帮助研究人员快速查看某个参与者的整体情况,例如他们的入场时间、性别、年龄组、以及他们在哪些区域被观察到的活动记录。
| CREATE VIEW vw_participant_summary AS SELECT fp.participant_id, fp.gender, fp.age_group, fp.clothing_description, fp.hoodie_flag, fp.hat_flag, fp.hair_color, fp.entry_date_time, fp.researcher_id, r.researcher_name, o.observation_date_time, z.zone_name, o.dancing_count, o.eating_count, o.drinking_count, ha.activity_type, ha.suspicion_level FROM festival_participants fp JOIN observations o ON fp.participant_id = o.participant_id JOIN zones z ON o.zone_id = z.zone_id JOIN researchers r ON fp.researcher_id = r.researcher_id LEFT JOIN hoodie_activities ha ON fp.participant_id = ha.participant_id AND o.observation_id = ha.observation_id; |
3.2 存储过程
需求:
假设需要一个存储过程来添加新的音乐节参与者记录,并且在添加记录时,自动记录他们的入场信息和分配的研究人员。该存储过程将接收参与者的基本信息作为输入参数,并完成以下任务:
添加参与者记录。
自动分配研究人员(可以是随机分配或基于某种策略)。
自动记录入场时间。
| DELIMITER $$ CREATE PROCEDURE sp_add_participant( IN p_gender ENUM('Male', 'Female', 'Other'), IN p_age_group ENUM('<20', '20-30', '31-40', '41-50', '51-60', '>60'), IN p_clothing_description TEXT, IN p_hoodie_flag BOOLEAN, IN p_hat_flag BOOLEAN, IN p_hair_color VARCHAR(50) ) BEGIN DECLARE v_researcher_id INT; DECLARE v_entry_date_time DATETIME; -- 随机分配研究人员 SELECT researcher_id INTO v_researcher_id FROM researchers ORDER BY RAND() LIMIT 1; -- 记录入场时间 SET v_entry_date_time = NOW(); -- 插入新的参与者记录 INSERT INTO festival_participants ( gender, age_group, clothing_description, hoodie_flag, hat_flag, hair_color, entry_date_time, researcher_id ) VALUES ( p_gender, p_age_group, p_clothing_description, p_hoodie_flag, p_hat_flag, p_hair_color, v_entry_date_time, v_researcher_id ); -- 返回新参与者的ID SELECT LAST_INSERT_ID() AS new_participant_id;
END $$ DELIMITER ; |
3.3 触发器
需求分析:
假设需要一个触发器,在音乐节参与者的表 festival_participants 中插入新记录时,自动检查该参与者的年龄组,并确保记录的年龄组符合参与者的年龄。如果参与者的年龄组不符合他们的实际年龄,触发器将抛出错误。
| DELIMITER $$ CREATE TRIGGER trg_check_age_group BEFORE INSERT ON festival_participants FOR EACH ROW BEGIN DECLARE age INT;
-- 假设age_group用实际年龄范围的下限来表示 CASE WHEN NEW.age_group = '<20' THEN SET age = 19; WHEN NEW.age_group = '20-30' THEN SET age = 29; WHEN NEW.age_group = '31-40' THEN SET age = 39; WHEN NEW.age_group = '41-50' THEN SET age = 49; WHEN NEW.age_group = '51-60' THEN SET age = 59; WHEN NEW.age_group = '>60' THEN SET age = 61; ELSE SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Invalid age group!'; END CASE;
-- 检查是否年龄符合指定的年龄组 IF NEW.age > age THEN SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Age does not match the specified age group!'; END IF; END $$ DELIMITER ; |
3.4 查询
3.4.1 查询一
| SELECT gate_code, COUNT(*) AS hoodie_count FROM festival_participants fp JOIN entry_exit_logs eel ON fp.participant_id = eel.participant_id WHERE fp.hoodie_flag = TRUE AND eel.entry_exit_flag = 'IN' -- 只统计进入的 GROUP BY eel.gate_code; |
3.4.1 查询二
| SELECT age_group, COUNT(*) AS participant_count FROM festival_participants GROUP BY age_group; |
3.4.1 查询三
| SELECT activity_type, COUNT(*) AS activity_count FROM hoodie_activities WHERE participant_id IN ( SELECT participant_id FROM festival_participants WHERE hoodie_flag = TRUE ) GROUP BY activity_type; |
一、数据库表设计
1. FestivalParticipants (节日参与者表)
用于记录节日参与者的基本信息。
-
ParticipantID (主键): 唯一标识符(UUID)
-
Gender (性别): CHAR(1), 默认值为 'U'(Unknown, 未知),CHECK约束('M', 'F', 'U' 三者之一)
-
AgeGroup (年龄组): INT, CHECK约束(范围: 0-5,分别对应<20, 20-30, 31-40, 41-50, 51-60, >60)
-
ClothingDescription (穿着描述): VARCHAR(255)
-
HoodieFlag (是否穿连帽衫): BOOLEAN, NOT NULL, 默认值为 FALSE
-
HatFlag (是否戴帽子): BOOLEAN, 默认值为 FALSE
-
HairColor (头发颜色): VARCHAR(50), 可为空
-
EntryDateTime (首次入场时间): DATETIME, NOT NULL
-
ResearcherID (研究人员ID): FOREIGN KEY 关联 Researcher 表中的 ResearcherID
2. Researcher (研究人员表)
记录参与研究的研究人员信息。
-
ResearcherID (主键): 唯一标识符(UUID)
-
ResearcherName (研究人员姓名): VARCHAR(100), NOT NULL
3. GateMovements (大门进出记录表)
记录节日参与者进出大门的信息。
-
MovementID (主键): 唯一标识符(UUID)
-
ParticipantID (参与者ID): FOREIGN KEY 关联 FestivalParticipants 表中的 ParticipantID
-
WristbandID (腕带ID): VARCHAR(50), NOT NULL
-
GateCode (大门代码): CHAR(1), CHECK 约束('M' 为主门, 'S' 为南门, 'E' 为东门)
-
MovementDateTime (日期时间): DATETIME, NOT NULL
-
Direction (进出方向): BOOLEAN, NOT NULL (TRUE表示进入,FALSE表示离开)
4. Zones (区域表)
记录节日区域的信息。
-
ZoneID (主键): 唯一标识符(UUID)
-
ZoneName (区域名称): VARCHAR(100), NOT NULL
-
SizeInHectares (区域大小): DECIMAL(4, 2), NOT NULL
5. Observations (观察记录表)
记录研究人员对节日区域内的观察结果。
-
ObservationID (主键): 唯一标识符(UUID)
-
ParticipantID (参与者ID): FOREIGN KEY 关联 FestivalParticipants 表中的 ParticipantID
-
ZoneID (区域ID): FOREIGN KEY 关联 Zones 表中的 ZoneID
-
ResearcherID (研究人员ID): FOREIGN KEY 关联 Researcher 表中的 ResearcherID
-
ObservationDateTime (观察日期时间): DATETIME, NOT NULL
-
DancingCount (跳舞人数): INT, 默认值为 0
-
EatingCount (吃饭人数): INT, 默认值为 0
-
DrinkingCount (喝酒人数): INT, 默认值为 0
6. HoodieActivities (连帽衫活动记录表)
记录穿着连帽衫的人的活动情况。
-
HoodieActivityID (主键): 唯一标识符(UUID)
-
ParticipantID (参与者ID): FOREIGN KEY 关联 FestivalParticipants 表中的 ParticipantID
-
ObservationID (观察记录ID): FOREIGN KEY 关联 Observations 表中的 ObservationID
-
ActivityType (活动类型): VARCHAR(100), NOT NULL
-
SuspicionLevel (怀疑等级): INT, CHECK 约束(范围: 1-9)
-
ActivityDateTime (活动日期时间): DATETIME, NOT NULL
二、实现约束条件
-
主键及外键约束:每个表的主键都是唯一标识符,外键约束确保表之间的关系完整性。
-
缺省约束:如在节日参与者表中,性别默认值为 'U',在观察记录表中,跳舞、吃饭和喝酒人数的默认值均为 0。
-
非空约束:如客户姓名、腕带ID、观察日期时间等关键字段设置为 NOT NULL。
-
CHECK约束:例如年龄组的取值限制,活动的怀疑等级限制,以及大门代码的限定。
-
规则:设计过程中通过业务逻辑实现,确保每位参与者可以从不同的大门进入。
三、表之间关系说明
-
FestivalParticipants 表记录了节日参与者的基本信息,与 GateMovements、Observations 和 HoodieActivities 表通过 ParticipantID 相关联。
-
Observations 表通过 ZoneID 关联到 Zones 表,记录研究人员在不同区域内的观察结果。
-
HoodieActivities 表记录了穿连帽衫参与者的活动,与 Observations 表通过 ObservationID 关联。
1. festival_participants 表
CREATE TABLE festival_participants (
participant_id INT AUTO_INCREMENT PRIMARY KEY,
gender ENUM('Male', 'Female', 'Other') DEFAULT 'Other',
age_group ENUM('<20', '20-30', '31-40', '41-50', '51-60', '>60'),
clothing_description TEXT,
hoodie_flag BOOLEAN NOT NULL DEFAULT FALSE,
hat_flag BOOLEAN NOT NULL DEFAULT FALSE,
hair_color VARCHAR(50),
entry_date_time DATETIME NOT NULL,
researcher_id INT,
FOREIGN KEY (researcher_id) REFERENCES researchers(researcher_id)
);
CREATE INDEX idx_gender ON festival_participants (gender);
CREATE INDEX idx_age_group ON festival_participants (age_group);
CREATE INDEX idx_hoodie_flag ON festival_participants (hoodie_flag);
CREATE INDEX idx_entry_date_time ON festival_participants (entry_date_time);
示例数据:
INSERT INTO festival_participants (gender, age_group, clothing_description, hoodie_flag, hat_flag, hair_color, entry_date_time, researcher_id)
VALUES
('Male', '20-30', 'Jeans and T-shirt', TRUE, FALSE, 'Brown', '2024-08-31 18:30:00', 1),
('Female', '31-40', 'Dress and sandals', FALSE, TRUE, 'Blonde', '2024-08-31 18:45:00', 2);
2. researchers 表
CREATE TABLE researchers ( researcher_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, email VARCHAR(100) NOT NULL, phone VARCHAR(20) NOT NULL, ); CREATE UNIQUE INDEX idx_researcher_name ON researchers (researcher_name);
示例数据:
INSERT INTO researchers (researcher_name)
VALUES
('John Doe','1545454545@qq.com','17848484848'),
('Jane Smith','4545454545@qq.com','13698598989');
3. gate_movements 表
CREATE TABLE gate_movements (
movement_id INT AUTO_INCREMENT PRIMARY KEY,
participant_id INT,
wristband_id VARCHAR(50) NOT NULL,
gate_code ENUM('Main', 'South', 'East') NOT NULL,
movement_date_time DATETIME NOT NULL,
direction ENUM('In', 'Out') NOT NULL,
FOREIGN KEY (participant_id) REFERENCES festival_participants(participant_id)
);
CREATE INDEX idx_participant_id ON gate_movements (participant_id);
CREATE INDEX idx_wristband_id ON gate_movements (wristband_id);
CREATE INDEX idx_gate_code ON gate_movements (gate_code);
CREATE INDEX idx_movement_date_time ON gate_movements (movement_date_time);
示例数据:
INSERT INTO gate_movements (participant_id, wristband_id, gate_code, movement_date_time, direction) VALUES (1, 'W001', 'Main', '2024-08-31 19:00:00', 'In'), (2, 'W002', 'South', '2024-08-31 19:15:00', 'In');
4. zones 表
CREATE TABLE zones ( zone_id INT AUTO_INCREMENT PRIMARY KEY, zone_name VARCHAR(100) NOT NULL, size_in_hectares DECIMAL(5, 2) NOT NULL ); CREATE INDEX idx_zone_name ON zones (zone_name);
示例数据:
INSERT INTO zones (zone_name, size_in_hectares)
VALUES
('Mojo Tent', 0.75),
('Crossroads', 1.20);
5. observations 表
CREATE TABLE observations (
observation_id INT AUTO_INCREMENT PRIMARY KEY,
participant_id INT,
zone_id INT,
researcher_id INT,
observation_date_time DATETIME NOT NULL,
dancing_count INT DEFAULT 0,
eating_count INT DEFAULT 0,
drinking_count INT DEFAULT 0,
FOREIGN KEY (participant_id) REFERENCES festival_participants(participant_id),
FOREIGN KEY (zone_id) REFERENCES zones(zone_id),
FOREIGN KEY (researcher_id) REFERENCES researchers(researcher_id)
);
CREATE INDEX idx_participant_id ON observations (participant_id);
CREATE INDEX idx_zone_id ON observations (zone_id);
CREATE INDEX idx_researcher_id ON observations (researcher_id);
CREATE INDEX idx_observation_date_time ON observations (observation_date_time);
示例数据:
INSERT INTO observations (participant_id, zone_id, researcher_id, observation_date_time, dancing_count, eating_count, drinking_count) VALUES (1, 1, 1, '2024-08-31 19:30:00', 5, 3, 2), (2, 2, 2, '2024-08-31 19:45:00', 7, 1, 4);
6. hoodie_activities 表
CREATE TABLE hoodie_activities (
hoodie_activity_id INT AUTO_INCREMENT PRIMARY KEY,
participant_id INT,
observation_id INT,
activity_type VARCHAR(100) NOT NULL,
suspicion_level TINYINT CHECK (suspicion_level BETWEEN 1 AND 9),
activity_date_time DATETIME NOT NULL,
FOREIGN KEY (participant_id) REFERENCES festival_participants(participant_id),
FOREIGN KEY (observation_id) REFERENCES observations(observation_id)
);
CREATE INDEX idx_participant_id ON hoodie_activities (participant_id);
CREATE INDEX idx_observation_id ON hoodie_activities (observation_id);
CREATE INDEX idx_activity_type ON hoodie_activities (activity_type);
CREATE INDEX idx_suspicion_level ON hoodie_activities (suspicion_level);
示例数据:
INSERT INTO hoodie_activities (participant_id, observation_id, activity_type, suspicion_level, activity_date_time) VALUES (1, 1, 'Standing near toilet', 5, '2024-08-31 19:35:00'), (2, 2, 'Approaching stranger', 7, '2024-08-31 19:50:00');
1. 创建视图
需求:
我们希望创建一个视图,能够展示参加音乐节的人员的基本信息以及他们的观察记录。这可以帮助研究人员快速查看某个参与者的整体情况,例如他们的入场时间、性别、年龄组、以及他们在哪些区域被观察到的活动记录。
视图定义:
CREATE VIEW vw_participant_summary AS
SELECT
fp.participant_id,
fp.gender,
fp.age_group,
fp.clothing_description,
fp.hoodie_flag,
fp.hat_flag,
fp.hair_color,
fp.entry_date_time,
fp.researcher_id,
r.researcher_name,
o.observation_date_time,
z.zone_name,
o.dancing_count,
o.eating_count,
o.drinking_count,
ha.activity_type,
ha.suspicion_level
FROM
festival_participants fp
JOIN
observations o ON fp.participant_id = o.participant_id
JOIN
zones z ON o.zone_id = z.zone_id
JOIN
researchers r ON fp.researcher_id = r.researcher_id
LEFT JOIN
hoodie_activities ha ON fp.participant_id = ha.participant_id AND o.observation_id = ha.observation_id;
说明:
-
vw_participant_summary 视图汇总了参加音乐节的人员基本信息和他们的观察记录。
-
视图中的每一行代表某个参与者在某个区域的某次观察记录,包含了观察到的活动类型及其怀疑等级(如果适用)。
视图查询示例:
SELECT * FROM vw_participant_summary WHERE suspicion_level > 5;
这条查询将返回所有怀疑等级大于 5 的参与者信息及其观察记录。
1. 需求分析
假设你需要一个存储过程来添加新的音乐节参与者记录,并且在添加记录时,自动记录他们的入场信息和分配的研究人员。该存储过程将接收参与者的基本信息作为输入参数,并完成以下任务:
-
添加参与者记录。
-
自动分配研究人员(可以是随机分配或基于某种策略)。
-
自动记录入场时间。
2. 创建存储过程
DELIMITER $$
CREATE PROCEDURE sp_add_participant(
IN p_gender ENUM('Male', 'Female', 'Other'),
IN p_age_group ENUM('<20', '20-30', '31-40', '41-50', '51-60', '>60'),
IN p_clothing_description TEXT,
IN p_hoodie_flag BOOLEAN,
IN p_hat_flag BOOLEAN,
IN p_hair_color VARCHAR(50)
)
BEGIN
DECLARE v_researcher_id INT;
DECLARE v_entry_date_time DATETIME;
-- 随机分配研究人员
SELECT researcher_id
INTO v_researcher_id
FROM researchers
ORDER BY RAND()
LIMIT 1;
-- 记录入场时间
SET v_entry_date_time = NOW();
-- 插入新的参与者记录
INSERT INTO festival_participants (
gender, age_group, clothing_description, hoodie_flag, hat_flag, hair_color, entry_date_time, researcher_id
) VALUES (
p_gender, p_age_group, p_clothing_description, p_hoodie_flag, p_hat_flag, p_hair_color, v_entry_date_time, v_researcher_id
);
-- 返回新参与者的ID
SELECT LAST_INSERT_ID() AS new_participant_id;
END $$
DELIMITER ;
3. 使用说明
调用存储过程:
你可以使用以下语句来调用存储过程 sp_add_participant,并插入新的参与者信息:
CALL sp_add_participant('Male', '20-30', 'Jeans and Hoodie', TRUE, FALSE, 'Black');
说明:
-
sp_add_participant存储过程接受六个参数,分别对应参与者的性别、年龄组、衣着描述、是否穿连帽衫、是否戴帽子及头发颜色。 -
存储过程会自动分配一个研究人员,并记录当前时间作为参与者的入场时间。
-
最后,它返回新参与者的
participant_id。
1. 需求分析
假设你需要一个触发器,在音乐节参与者的表 festival_participants 中插入新记录时,自动检查该参与者的年龄组,并确保记录的年龄组符合参与者的年龄。如果参与者的年龄组不符合他们的实际年龄,触发器将抛出错误。
2. 创建触发器
以下是一个示例触发器,它会在插入或更新 festival_participants 表时执行:
DELIMITER $$
CREATE TRIGGER trg_check_age_group
BEFORE INSERT ON festival_participants
FOR EACH ROW
BEGIN
DECLARE age INT;
-- 假设age_group用实际年龄范围的下限来表示
CASE
WHEN NEW.age_group = '<20' THEN SET age = 19;
WHEN NEW.age_group = '20-30' THEN SET age = 29;
WHEN NEW.age_group = '31-40' THEN SET age = 39;
WHEN NEW.age_group = '41-50' THEN SET age = 49;
WHEN NEW.age_group = '51-60' THEN SET age = 59;
WHEN NEW.age_group = '>60' THEN SET age = 61;
ELSE SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Invalid age group!';
END CASE;
-- 检查是否年龄符合指定的年龄组
IF NEW.age > age THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Age does not match the specified age group!';
END IF;
END $$
DELIMITER ;
3. 触发器说明
-
触发时间:
BEFORE INSERT指示触发器在插入新记录之前执行。 -
目标表:
festival_participants是触发器所作用的表。 -
触发逻辑:
-
使用
CASE语句检查age_group字段,并确定每个年龄组的上限。 -
如果插入的数据年龄超过了指定的年龄组上限,触发器将抛出一个自定义错误信息,阻止插入操作。
-
4. 使用场景
假设你试图插入一个参与者,他们的实际年龄为 35 岁,但你将他们的年龄组指定为 20-30,触发器将会抛出错误,阻止插入操作。
示例:
INSERT INTO festival_participants (
gender, age, age_group, clothing_description, hoodie_flag, hat_flag, hair_color, entry_date_time, researcher_id
) VALUES (
'Female', 35, '20-30', 'Dress', FALSE, TRUE, 'Blonde', NOW(), 1
);
此操作将失败,并返回错误信息:“Age does not match the specified age group!”
要查询每个门进入的穿连帽衫的参与者数量,你可以使用以下 SQL 语句。这条语句将统计每个门进入的穿连帽衫的参与者的数量,并按门进行分组。
SQL 查询
SELECT
gate_code,
COUNT(*) AS hoodie_count
FROM
festival_participants fp
JOIN
entry_exit_logs eel ON fp.participant_id = eel.participant_id
WHERE
fp.hoodie_flag = TRUE
AND eel.entry_exit_flag = 'IN' -- 只统计进入的
GROUP BY
eel.gate_code;
解释
-
gate_code: 每个大门的代码(例如主门、南门、东门)。
-
COUNT(*) AS hoodie_count: 计算符合条件的记录数量,并将结果命名为
hoodie_count。 -
JOIN: 连接
festival_participants表和entry_exit_logs表,以匹配参与者的入场记录。 -
WHERE: 筛选条件,选择穿连帽衫的参与者 (
hoodie_flag = TRUE) 和入场记录 (entry_exit_flag = 'IN')。 -
GROUP BY: 按大门代码分组,以便计算每个门进入的穿连帽衫者数量。
这个查询将为每个大门返回穿连帽衫的参与者数量。
要查询每个年龄组的参与者人数,可以使用以下 SQL 语句。这条语句将统计 festival_participants 表中每个年龄组的参与者数量,并按年龄组进行分组。
SQL 查询
SELECT age_group, COUNT(*) AS participant_count FROM festival_participants GROUP BY age_group;
解释
-
age_group: 参与者的年龄组(例如
<20、20-30、31-40等)。 -
COUNT(*) AS participant_count: 计算符合条件的记录数量,并将结果命名为
participant_count。 -
GROUP BY age_group: 按年龄组分组,以便计算每个年龄组的参与者人数。
这个查询将为每个年龄组返回参与者的总数。
要查询穿连帽衫的参与者所表现的每种活动类型的次数,可以使用以下 SQL 语句。此查询将统计 hoodie_activities 表中,每种活动类型的发生次数,并按活动类型进行分组。
SQL 查询
SELECT activity_type, COUNT(*) AS activity_count FROM hoodie_activities WHERE participant_id IN ( SELECT participant_id FROM festival_participants WHERE hoodie_flag = TRUE ) GROUP BY activity_type;
解释
-
activity_type: 记录的活动类型(例如站在马桶附近、接近陌生人、疯狂行为等)。
-
COUNT(*) AS activity_count: 计算每种活动类型的发生次数,并将结果命名为
activity_count。 -
WHERE participant_id IN (...): 子查询筛选出所有穿连帽衫的参与者的
participant_id。 -
GROUP BY activity_type: 按活动类型分组,以便统计每种活动的次数。
这个查询将返回穿连帽衫的参与者中每种活动类型的发生次数。


















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









