







摘 要: 本文主要对神奇的哈夫曼(Huffman)算法进行介绍。哈夫曼算法是一种基于统计的贪心算法,通过对信息频率进行统计,记作权值,进而建立一个带权路径长度最短的二叉树,即哈夫曼树。哈夫曼算法主要用于哈夫曼编码,可以根据哈夫曼编码对照表和哈夫曼树编码和译码,从而实现压缩和解压缩。最后,对哈夫曼算法的其他应用进行简略介绍。
关键词: 哈夫曼树 带权路径长度(WPL) 数据压缩 贪心算法
1 引言
在大数据横行的信息时代,人们对使用计算机获取信息、处理信息的依赖性越来越高,如此庞大的信息量无论是在存储还是传输过程中都会对硬件系统造成压力,因此,数据压缩极为重要。哈夫曼算法是哈夫曼在1952年首次提出的,是一种奇妙且高效的算法,且作为一种重要的数据压缩算法,在当今信息处理领域获得了广泛的应用。
哈夫曼算法实现了这样一个功能,即通过给定的一组字符和他们的权值,来找出一个最小期望二进制码字长度的无前缀二进制码,也等价于寻找具有最小从根开始的加权路径长度的树(一种一对多的数据结构)。
当逐个字符的限制被取消时,或者当概率密度函数未知时,它不是最优的。
但是,哈夫曼算法对于已知输入概率分布的逐个字符编码是最优的,因此哈夫曼编码有时又被称为最佳编码。
2 哈夫曼树的建立
哈夫曼算法的核心在于哈夫曼树的构建,哈夫曼压缩和解压过程都需要哈夫曼树来支持相关操作。
哈夫曼树的建立算法主要利用了贪心策略(取局部最优解的策略),算法的具体描述如下:
- 将每个字符是一个叶子结点,加入一个根据权值(通常是概率分布)排序的优先队列,权值越小排在前面。我们将每个结点看成一个树,这些树组成了森林。
- 当森林中有多于一个结点时,进行下列循环:
- 2.1 从森林队列前面依次取出两个树,从队列中移除
- 2.2 将取出的两个结点分别作为左右子树用根节点结合起来,形成一个新的树,此时根节 点的权值为两个子节点的权值之和
- 2.3再将这个新的树加入队列
- 3.将最后剩下的结点作为根节点,就形成了哈夫曼树
用以字符串abcdacdaad为例,将字符与对应频率形成字典dict={a:4,b:1,c:2,d:3},执行第一步,得到:

图2.1
此时选取b,c字符对应的两个结点,组成一个二叉树 ,如图2.2,2.3
新形成的树: 森林队列:


图2.2 图2.3
此时将bc和d取出并组合,形成的森林队列(图2.4)
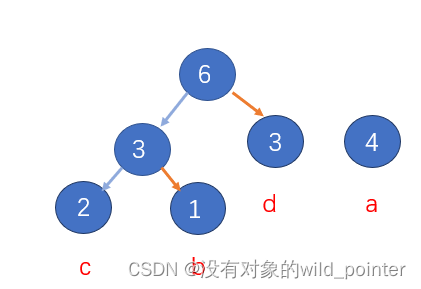
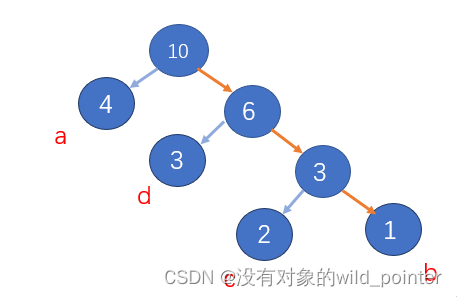
图2.4 图2.5
最终得到哈夫曼树,如图2.5
哈夫曼树的每个叶子结点到根节点的距离就是路径长度,记为li,对于每个叶子结点,根据出现的频率作为权值wi,于是可以得到n个字符的带权路径长度(WPL),可以证明,在所有的二叉树中,哈夫曼树的所有字符的带权路径和最小,即
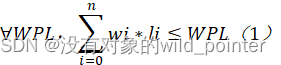
其中的WPL为其他任意一种二叉树的带权路径长度。
前面我们已经提到,构造哈夫曼树采用的是贪心算法,即每次取局部最优解,证明贪心算法的合理性,首先要证明哈夫曼建树问题具有贪心选择性质并且存在最优子结构。
贪心选择性质:即一个问题的整体最优解可通过一系列局部的最优解的选择达到,并且每次的选择可以依赖以前但不依赖于后面要作出的选择。在构建哈夫曼树的过程中,我们只需要证明,对于n个叶子结点的哈夫曼树,开始选权值最小的x,y结点合并是可以构成哈夫曼树的,也就是证明n个叶子节点的哈夫曼树,x,y处于层数最深的那层并且有同一个父节点。
对于层数最深,假设有一个哈夫曼树,得到的加权路径总长度为WPL,如果把层数较浅的叶子节点z与x互换,由哈夫曼树的性质易知wz>=wx,那么新的加权路径总长度WPL’为
其中,depthz和depthx分别为z,x结点的深度。所以,交换位置一定不会让总长度变小,所以,x,y必在层数最深的一层。对于x,y是否有同一父节点,由前面推导可知x,y必在同一层,又因为哈夫曼树同一层的结点互换位置不影响整体的带权路径长度,因此,必然存在一种哈夫曼树,使得x,y有同一父节点。
最优子结构:对于n个结点,哈夫曼树已经完成了x,y两个结点组合。设整个字符集C,则剩余字符集C-{x,y},设其加权路径长度为WPL’,则总的哈夫曼树的加权路径长度为:
若要保证整体n个节点为最优树(加权路径和为最小的树),则C-{x,y}也应为最优树。
最终,可以知道哈夫曼算法形成的哈夫曼树为最优树。
3 哈夫曼编码
哈夫曼编码是利用哈夫曼树找到编码表,高频字符的编码短,低频字符的编码长,将字符转化为对应的二进制码的形式,从而最大程度减少内存占用,达到压缩目的。
其中,仍以之前的字符串为例,哈夫曼编码的大致过程如下:
首先对哈夫曼树做处理,将指向左孩子的线段编为0,指向右孩子的线段标为1(也可以反过来)。
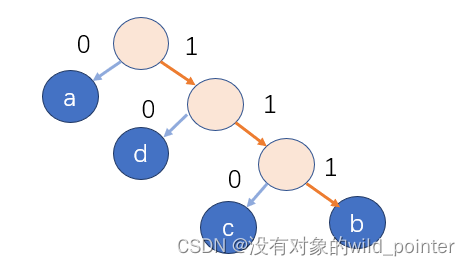
图3.1
从根节点出发,到达各个字符对应的叶子节点,则经过的01路径就为该字符的哈夫曼编码。
由图3.1可以得到,各字符编码如下表:
| a | 0 |
| b | 111 |
| c | 110 |
| d | 10 |
表3.1
最后将要压缩的文件转化为相应的二进制编码即可得到压缩文件。
如本例压缩后的文本为0 111 110 10 0 110 10 0 0 10,共19位,但是原来的文本按照一个字符一个字节(1字节=8位)来算原来是80位,但是也要考虑计算机存储的关系,有时可能要凑齐整数个字节,压缩后的文本可能略大于19位。
从前面的讨论容易知道哈夫曼压缩后的文本长度就是文本所有字符对应的带权路径和,根据文本的不同,哈夫曼树和哈夫曼编码方式也不同,设L为原始的文件的bit位数,WPL为压缩后的文本的bit位数,则该算法的压缩率![]() 约为
约为
本例的压缩率约为23.75%,一般文件的压缩率大概在20%-90%之间。当然,由于哈夫曼树同一层结点可以交换位置的性质,同一文本对应的哈夫曼编码也可能不同,算法的细节不同可能导致最终的压缩后的文件也不同,但是最终的压缩效果是相同的。
4 哈夫曼译码
哈夫曼译码是哈夫曼编码的逆过程,是通过哈夫曼树将压缩码转化为原来的字符码的过程。具体算法如下:
仍以之前的字符串为例,得到的哈夫曼编码为0111110100110100010,此时依照哈夫曼树,依次读取二进制码,然后从哈夫曼树的根节点开始,按照二进制码01选择当初编码时的方向,0向左,1向右,直到走到叶子节点,如图4.1所示。这里只进行了翻译了前三个字符。
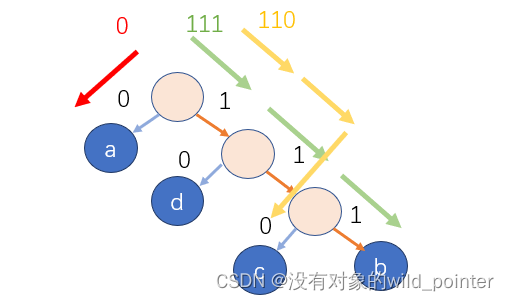

图4.1 图4.2
容易知道,哈夫曼解码的过程是完全将原来的文件还原,是一种无损压缩算法。
5 哈夫曼算法的其他应用
5.1 判定树
要设计时间性能更高的判定树,提高判定效率,可以采用哈夫曼算法。就要在最多的情况设置在判定树根部,最少的情况设置在最深处。例如,某班级中的成绩比例大小关系为:不及格>中>良>优,则可以根据哈夫曼算法设计如图5.1所示的判定树。
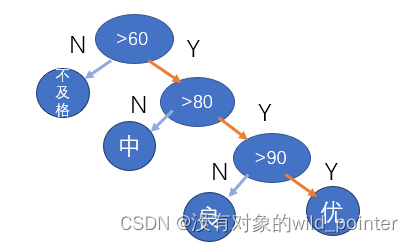
图5.1
5.2 文件归并
给定一组不同长度的排好序的文件构成的集合S={f1,…fn},其中fi代表第i个文件含有的项数。使用二分归并将这些文件归并成有序文件。用二叉树实现,文件作为叶子节点,归并后的文件作为父节点。这里文件的大小作为权值,合并次数为路径,可以发现利用哈夫曼算法进行文件合并的次数是最少的,证明同上。所以有序文件归并的次序和哈夫曼编码的次序可以等同起来。
参考文献:
[1]严蔚敏,吴伟民.数据结构(C语言版)[M].北京:清华大学出版社,2007:144-148
[2]王晓东.计算机算法分析与设计[M].第四版.北京:电子工业出版社,2021.2:99-100
[3]熊旋,付颖芳. 优化哈夫曼算法的数据压缩研究[J]. 电脑知识与技术(学术交流),2006(8):7-7,9. DOI:10.3969/j.issn.1009-3044.2006.08.005..
[4]维基百科Huffman coding[EB/OL].[2023-03-12].
https://en.wikipedia.org/wiki/Huffman_coding![]() https://en.wikipedia.org/wiki/Huffman_coding
https://en.wikipedia.org/wiki/Huffman_coding















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









