







哨兵模式
自动选取主机的模式。
概述
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
单机哨兵
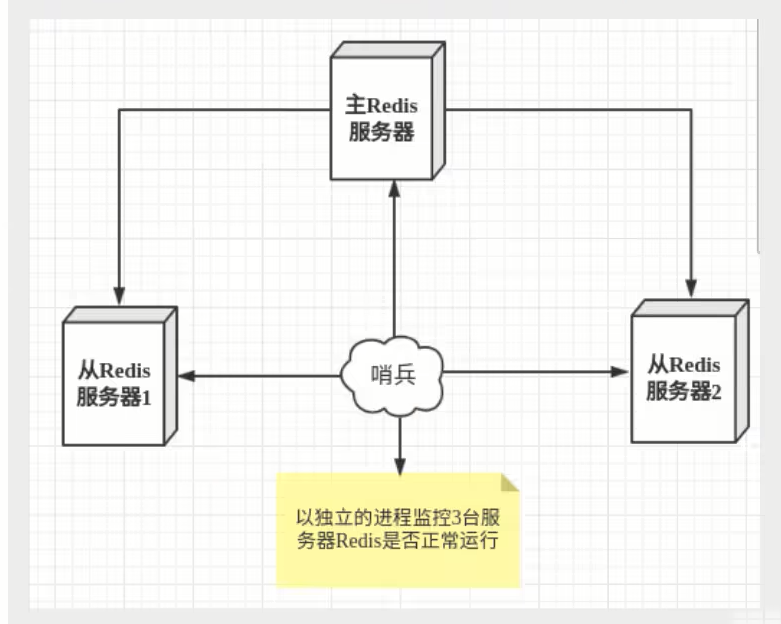
作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
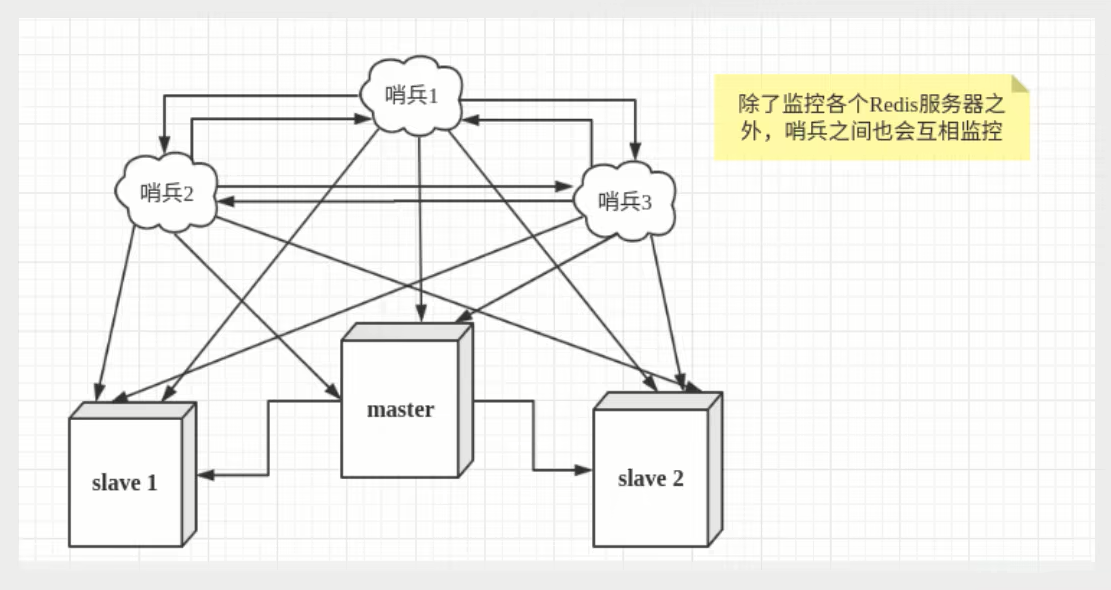
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线.
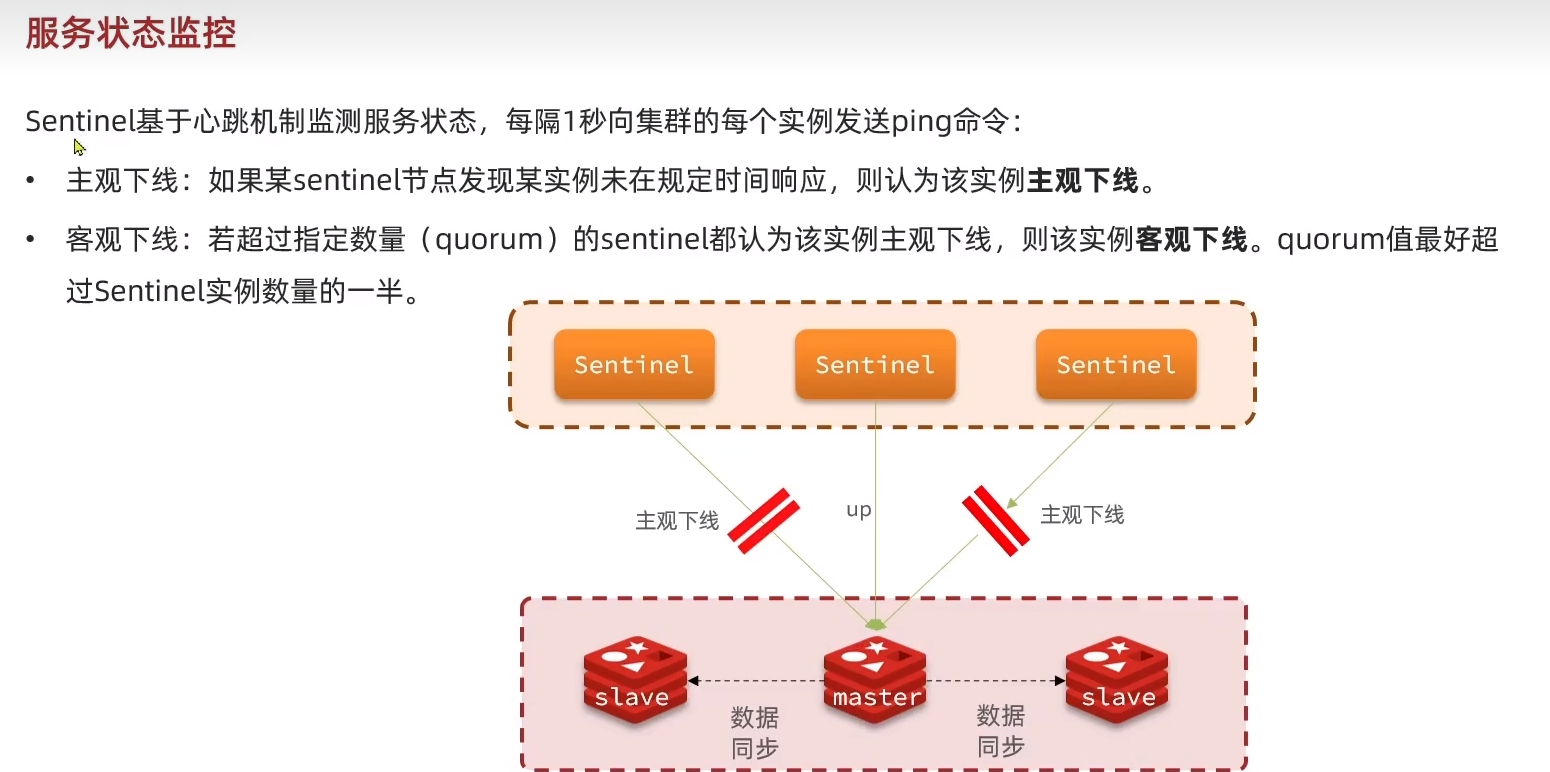
选举

故障转移

测试
在一主二从的状态下配置哨兵。
要新建一个redis容器来做这个东西。
新建一个sentinel.conf配置文件如下。
这个配置文件在容器里面的位置是/etc/redis/sentinel.conf,和/etc/redis/redis.conf配置文件在同一个目录下。
所以这里要先新建好对应映射文件目录。
在之前的基础上新加一条
touch /docker/redis/conf/sentinel.conf
然后准备好对应的哨兵配置文件。
哨兵配置文件
bind 0.0.0.0
# 端口号
port 26379
# 关闭保护模式
protected-mode no
# 开启后台运行,这里哨兵的后台运行也会和docker的后台运行冲突
daemonize no
#日志
logfile "/data/sentinel.log"
# 配置监听的主服务器 sentinel monitor代表监控,myredis代表服务器名称 1表示有一个哨兵,并且只要有一个哨兵认为主机不可用就会进行failover操作
sentinel monitor myredis 127.0.0.1 6380 1
# sentinel auth-pass定义服务的密码,myredis是服务名称,123456是密码
sentinel auth-pass myredis 123456
# 设置主机多少秒无应答,就认为下线
sentinel down-after-milliseconds myredis 30000
# 主备切换时,最多有几个slave同时对新的redis进行同步,默认是1
sentinel parallel-syncs myredis 1
# 故障转移
sentinel failover-timeout myredis 180000启动哨兵
重新创建一个新的redis容器并启动哨兵服务服务。
--privileged=true根据情况选择是否添加。
docker run -itd --restart=always -p 26379:26379 -v /docker/redis/conf/sentinel.conf:/etc/redis/sentinel.conf --name redis_st redis redis-sentinel /etc/redis/sentinel.conf启动完成之后是可以看见有提示的。
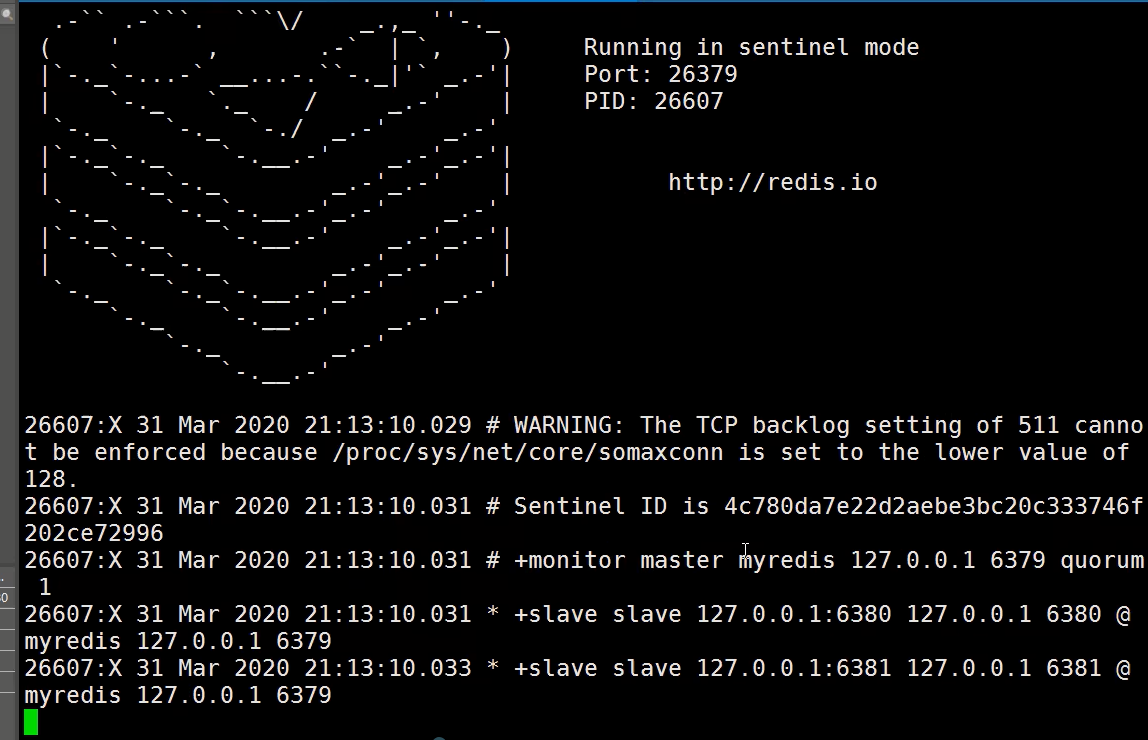
无法真正重选主机

但是在我尝试挂掉主机去重新选举时问题出现了。这里选来选去都是旧的主机。
无法切换,有几种情况:
1-redis保护模式开启了
2-端口没有放开;
3-master密码和从密码不一致。
4-master节点的redis.conf没有添加masterauth
处理方法:
首先配置文件都要修改如下。
所有的redis配置文件都要改,以及哨兵的那个配置文件也要改。
bind 0.0.0.0
protected-mode no
master密码和从密码不一样
在哨兵配置的时候只配置了master的密码, 加入master挂了,哨兵会拿着master的密码去访问从机。所以密码应该设置一样。
另外也要在matser节点中设置masterauth,否则会无法成为xinmaster节点的从节点。
真正的解决方案(docker部署集群的要点)
没错,上面的问题都不是我的问题,我真正的问题在这里。
因为我用的是docker进行redis集群的部署,我主机和从机开了三个docker。
映射关系分别是
6380->6379
6381->6379
6382->6379
这里的三个6379都是docker内的端口号。但是在哨兵那里看过去都是6379,但是实际上不应该是这样,像下图这里就是一个错误示范,也是用docker部署的错误点。
哨兵在从机里面选举时会按照6379这个端口访问,但是实际上我的两个从机在外部的端口应该是6381和6382才对,所以我前面才一直访问不到。
现在只要将docker内redis服务的端口号和外部映射的端口号一一对应开即可。
6380->6380
6381->6381
6382->6382
并且这里是要将redis服务的端口改成6380,6381和6382的的才可以。
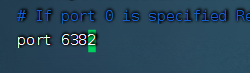
测试成功
然后等到我原本的master重新上线时就只能跟随新产生的master了。(哨兵模式的规则)
优点和缺点
优点
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮!
缺点
1、Redis 不好啊在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦!
2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择。
哨兵模式的配置文件
下面这里还不是完整的配置,如果要做哨兵集群还要涉及到更多的东西。
还有什么保护模式,后台运行,日志文件等等配置,下面都没有列出来。
# Example sentinel.conf
# 1、哨兵sentinel 实例运行的端口 默认26379
port 26379
# 2、 哨兵 sentinel 的工作目录
dir "/usr/local/bin"
# 3、哨兵sentinel监控的redis主节点 host port
# - master-name 可以自己对 主节点 明明
# - quorum 配置多少个sentinel 哨兵认为master 主节点失联,那么这个时候就客观的认为失恋了
# sentinel monitor master-name host port quorum
sentinel monitor myredis 127.0.0.1 7371 1
# 4、在Redis实例中开启了密码,这时,所有连接Redis的客户端都需要密码
# - 设置了哨兵sentinel 连接上主从的密码,注意必须设置一样的验证码
# sentinel auth-pass master-name password
sentinel auth-pass myredis 123456
# 5、指定多少毫秒后 主节点没有回答哨兵sentinel 此时 哨兵主观上认为主节点离线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds myredis 30000
# 6、这个配置指定了在发生failover 主备切换时最多可以由多少个slave同时对新的master进行同步
- 这个数字越小,完成failover 所需的时间越长
- 这个数字越大,就意味着越多的slave 因为repkication 而不可用
- 可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态
# sentinel parallel-syncs <master-name> <numreplicas>
sentinel parallel-syncs mymaster 1
# 7、故障转移的时间 failover-timeout 可以用一下这些方面
同一个sentinel 对同一个master 两次failover 之间的间隔时间
当想要取消一个正在进行的fai1over所需要的时间,直到slave 被纠正为向正确的master那里同步数据时
当进行fai1over时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,s1aves依然会被正确配置为指向 master,但是就不按para11e1-syncs所配置的规则来了
# sentinel failover-timeout <master-name> <milliseconds> 默认三分钟
sentinel failover-timeout mymaster 180000
# 8、配置当某一个事件发生时需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时,发送
邮件通知相关人员
- 对于脚本的运行结果有以下规则:
1.若脚本执行后返回1,那么该脚本稍后会重新执行,重复次数默认为10
2.若脚本执行后返回2,或者是比2更高的返回值,脚本将不会执行
3.若脚本在执行过程中由于收到系统中断信号被终止了,则同返回值1的时候的相同
4.一个脚本执行的最大时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,重新执行
- 通知型脚本:当sentine1有任何警告级别的事件发生时(比如说re dis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentine1.conf配置文件中配置了这个脚本路路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则 sentine1无法正常启动成功。
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 9、客户端重新配置主节点参数脚本
- 当一个master 发生改变时,这个脚本就会被调用,通知相关的客户端关于 master 地址已经发生改变
- 一下参数将会在调用脚本的时候传给脚本
1. <master-name> <role> <state> <from-ip><from-port><to-ip><to-port>
2. 目前<state>总是"failover”
3. <ro1e>是"leader"或者"observer”中的一个。
4. 参数from-ip,from-port,to-ip,to-port是用来和旧的master和新的master(即旧的s1ave)通信的
5. 这个脚本应该是通用的,能被多次调用,不是针对性的
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.shRedis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
RedisTemplate的哨兵模式

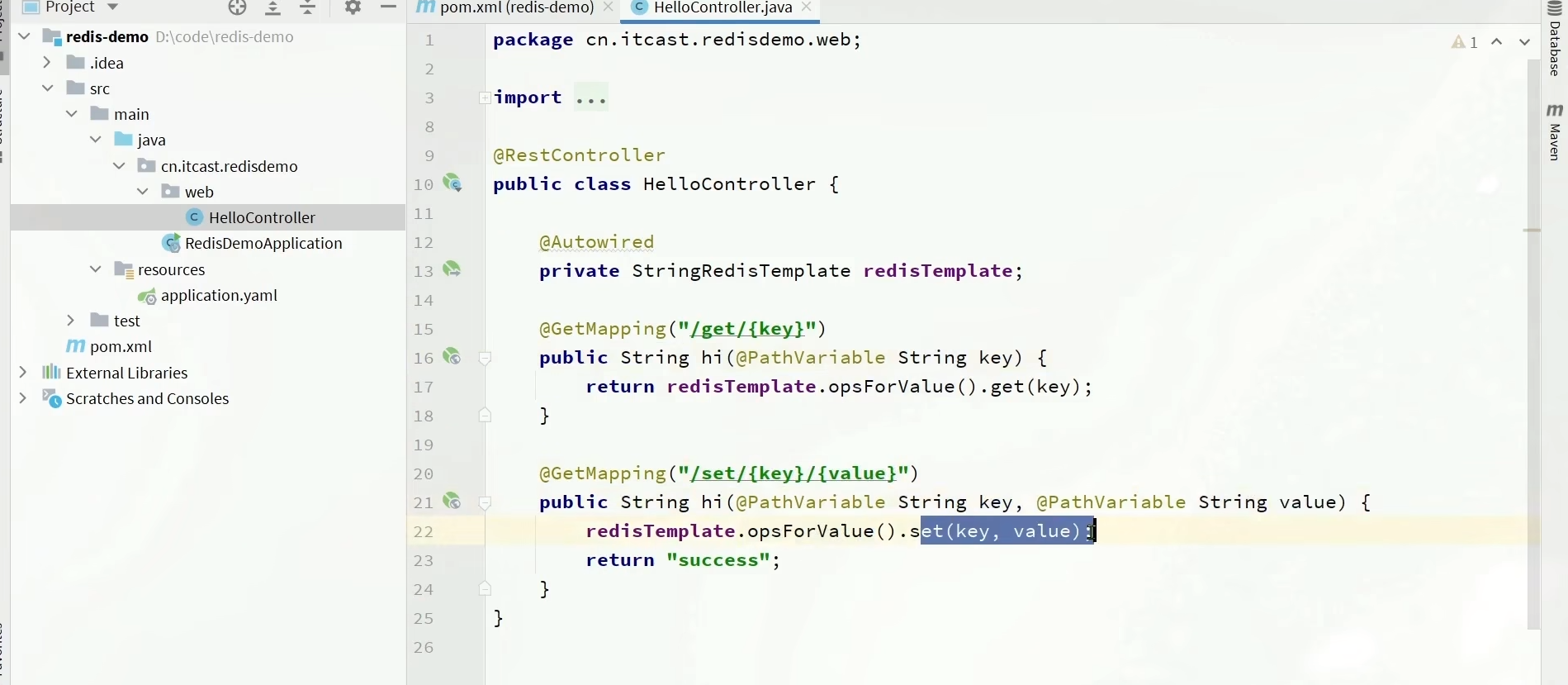
这里配置文件里的master一定要和哨兵配置文件里监控的master同名。
 配置主从读写分离
配置主从读写分离
缓存穿透(查不到)
概念
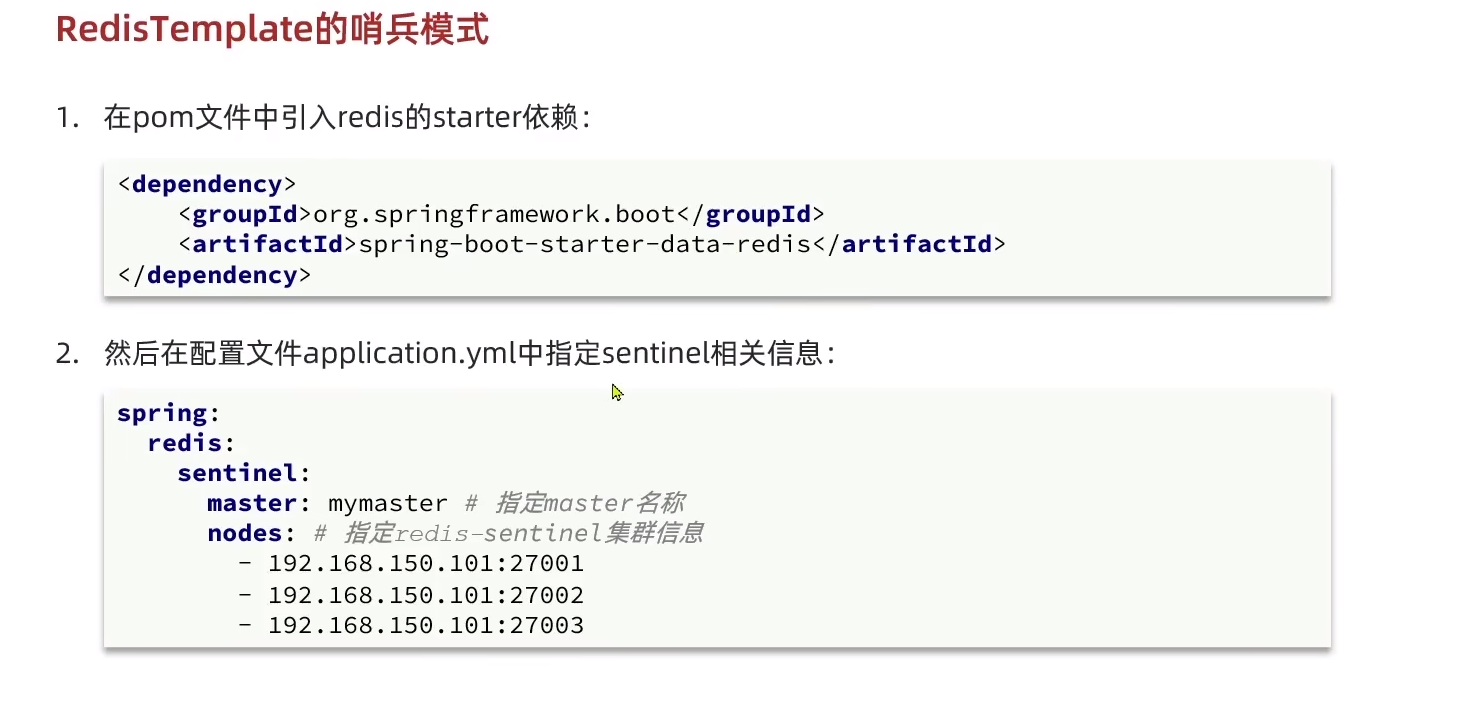
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀服务),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。
缓存空对象
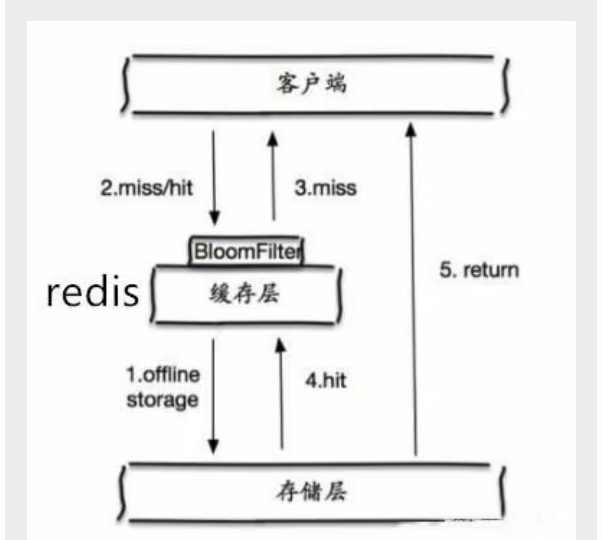
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量过大,缓存过期)
概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大
解决方案
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis宕机。
立生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
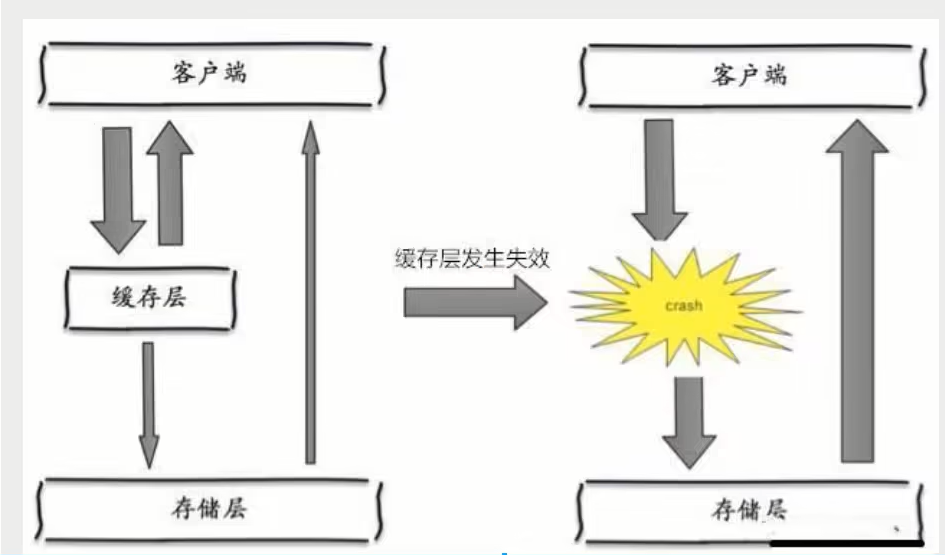
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。(异地多服)
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀.
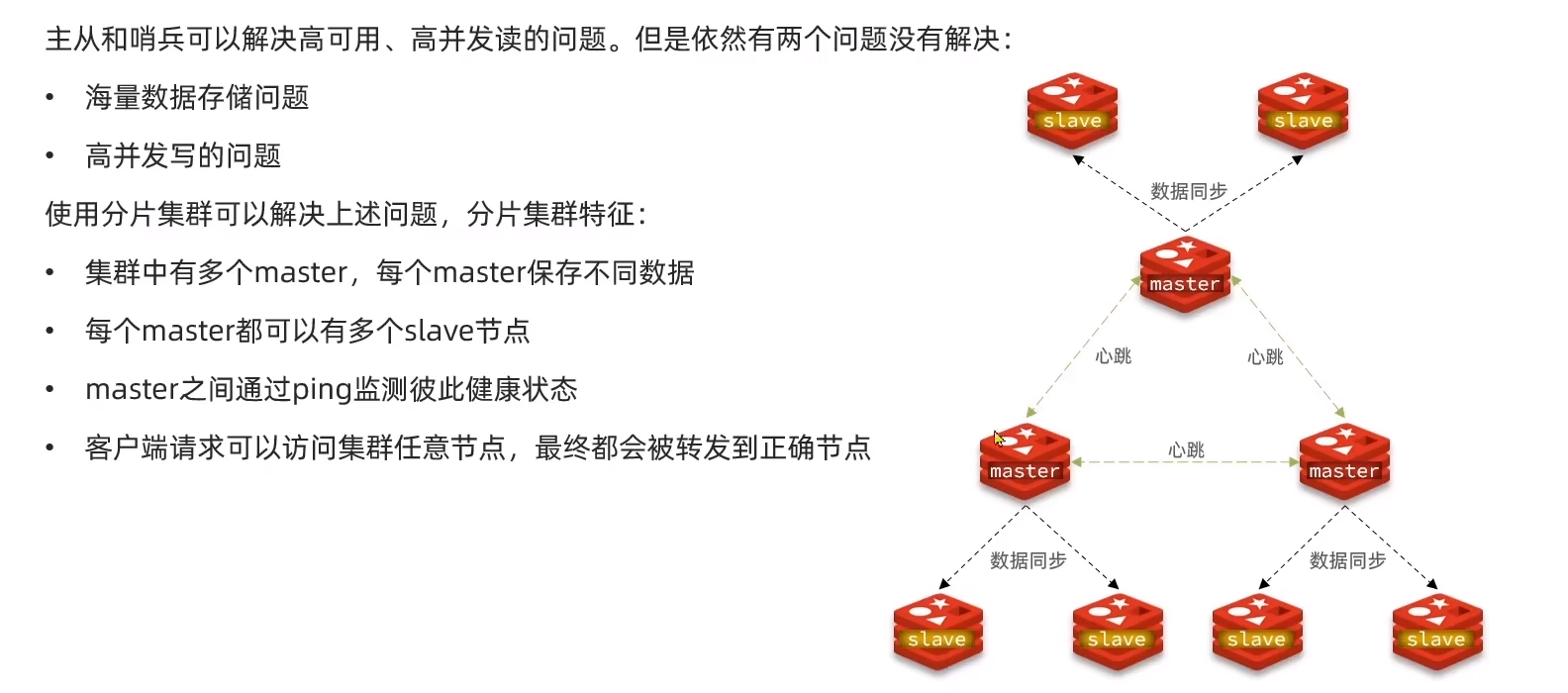
分片集群
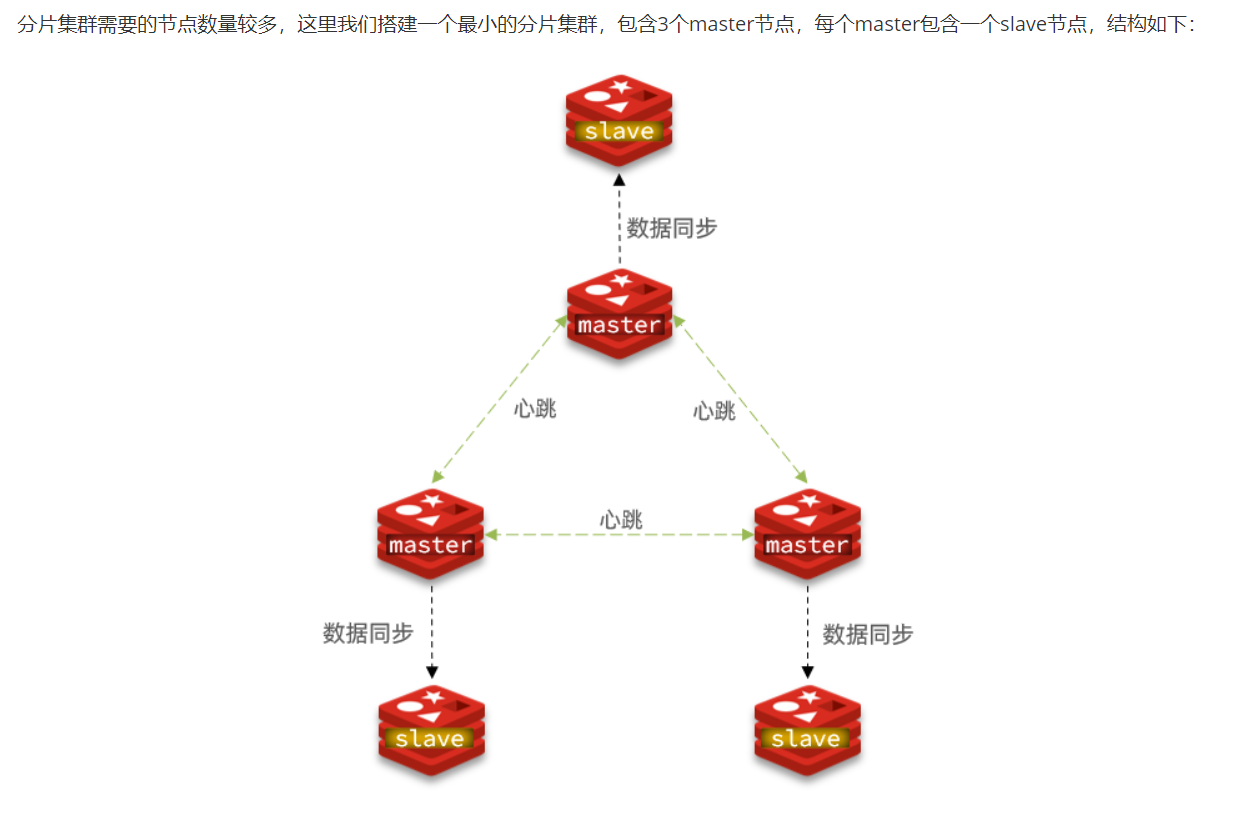
搭建分片集群
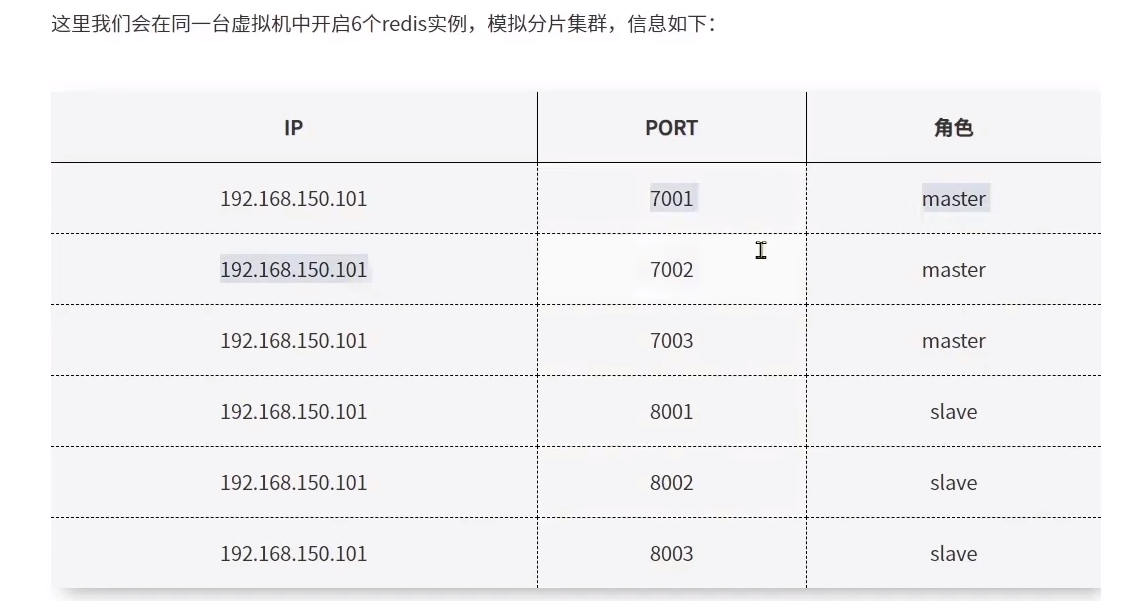 准备实例的配置
准备实例的配置
# 创建目录mkdir 7001 7002 7003 8001 8002 8003在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf启动
如果是在一台虚拟机上进行启动的话,可以直接启动。
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf如果是在docker启动的话需要创建6个容器,并且每个容器都要进行数据卷挂载和端口映射.
通过ps查看状态。
ps -ef | grep redis如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown创建集群
上面的实例现在都是独立的。
redis5.0版本后可以在redis-cli创建集群。
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003命令说明:
-
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令 -
create:代表是创建集群 -
--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
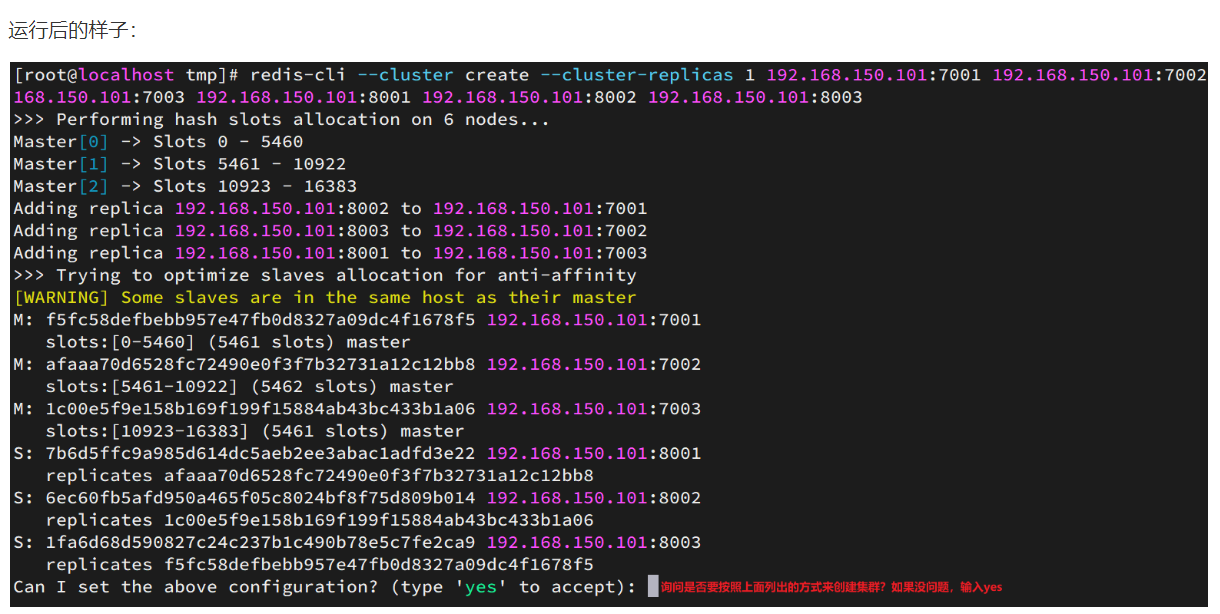 这里输入yes,则集群开始创建:
这里输入yes,则集群开始创建:
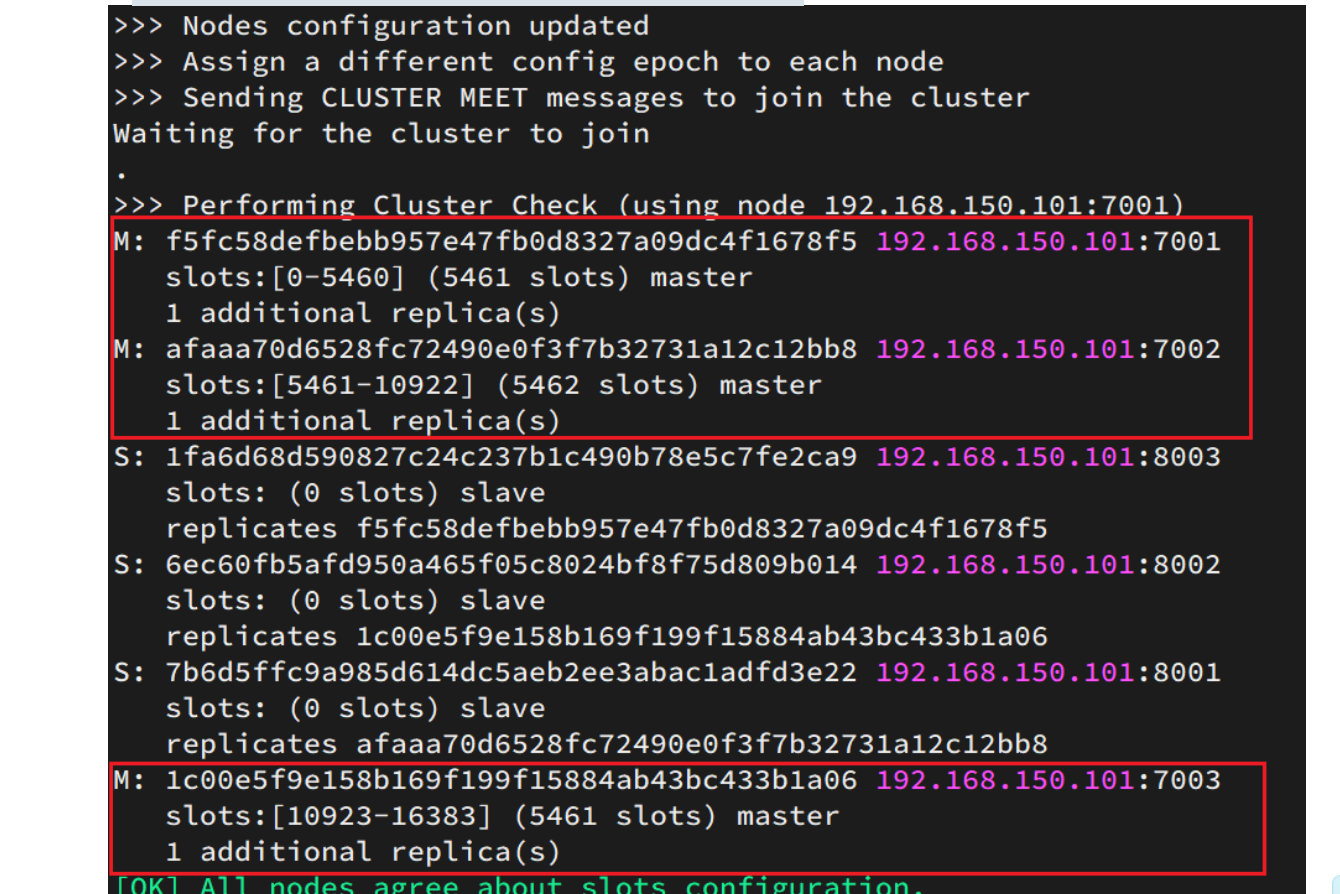
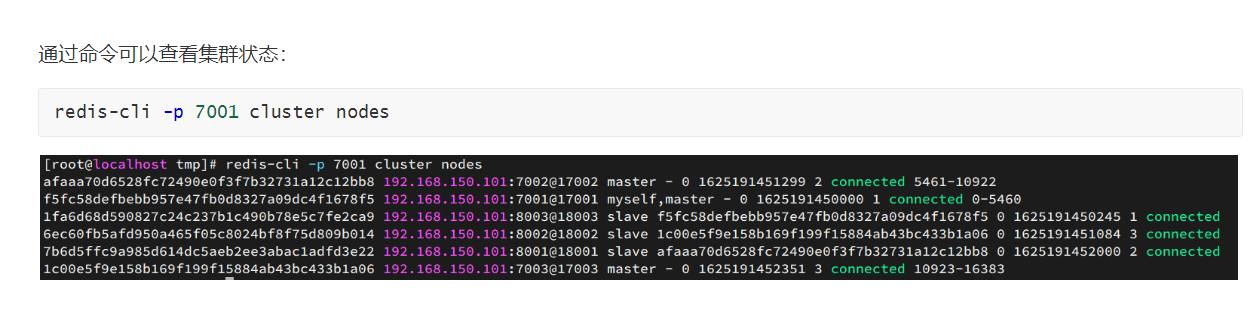 测试
测试
连接其中一个节点,存储一个数据.
连接集群时要加上一个-c的参数.
# 连接
redis-cli -c -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
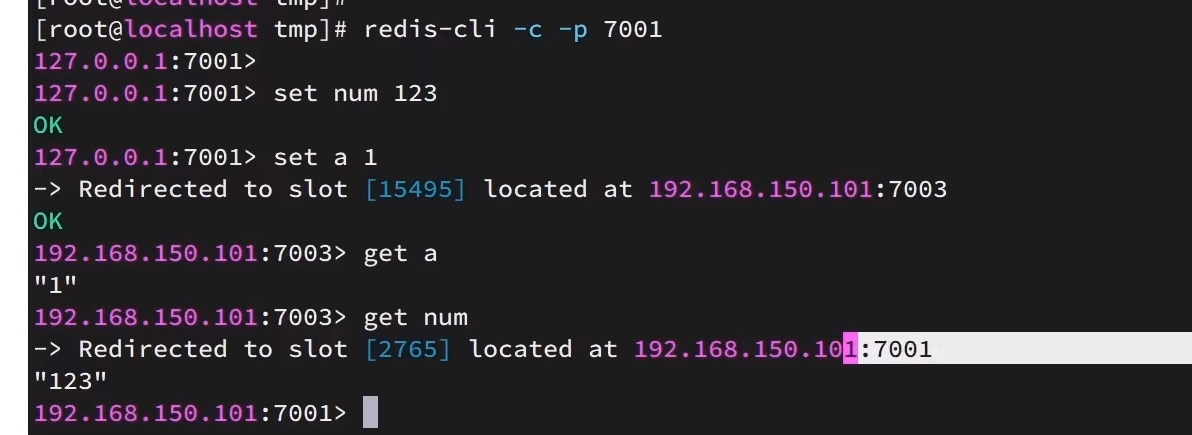
set a 1散列插槽
算出来的具体槽位只是说明我要汪那个节点放,卡槽不存储数据。

key a 算出来的插槽值是15495,存储在节点7003上面。然后这里直接重定向到7003.
get num时算出来2765直接重定向到7001.
可以知道,set 和get的时候都是先根据key计算插槽在哪一个节点,然后再跳转节点获取和插入数据。

集群伸缩


将来有需要现查吧。
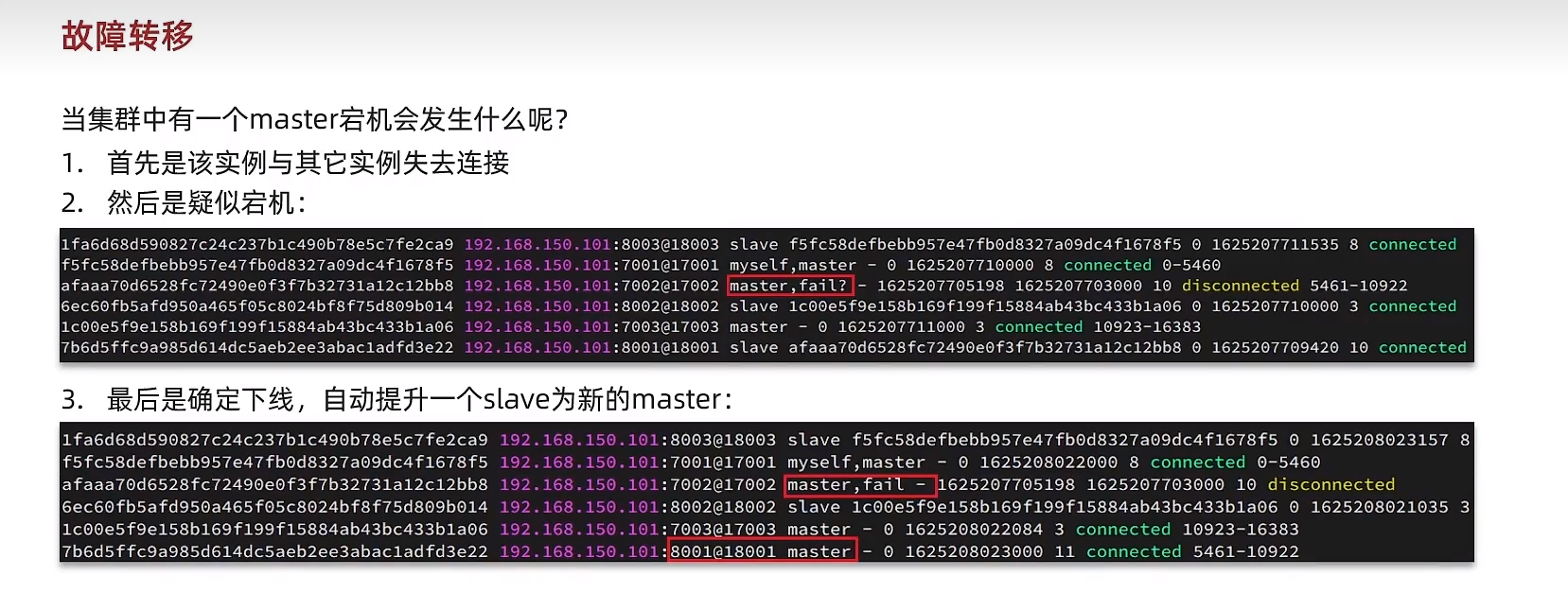
故障转移
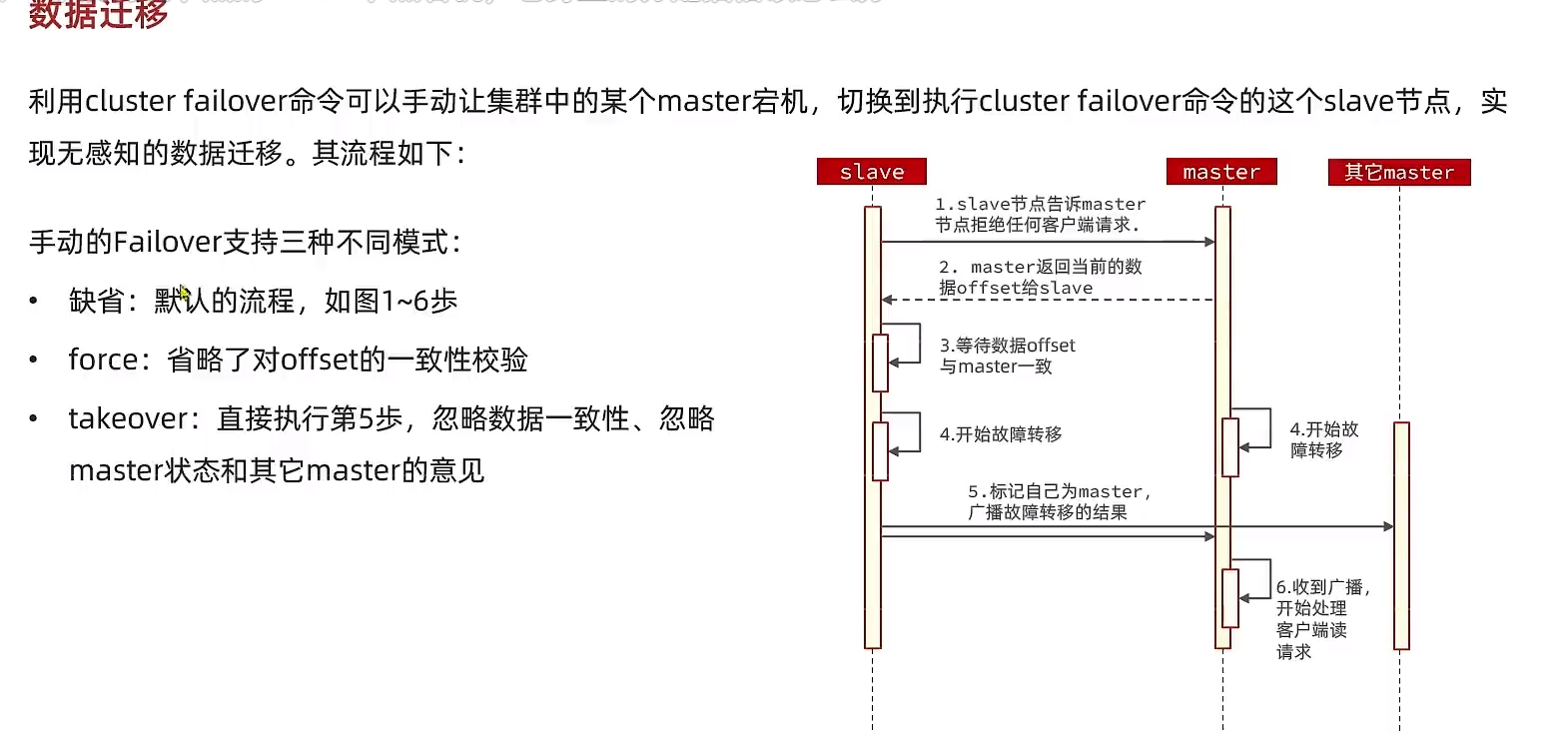

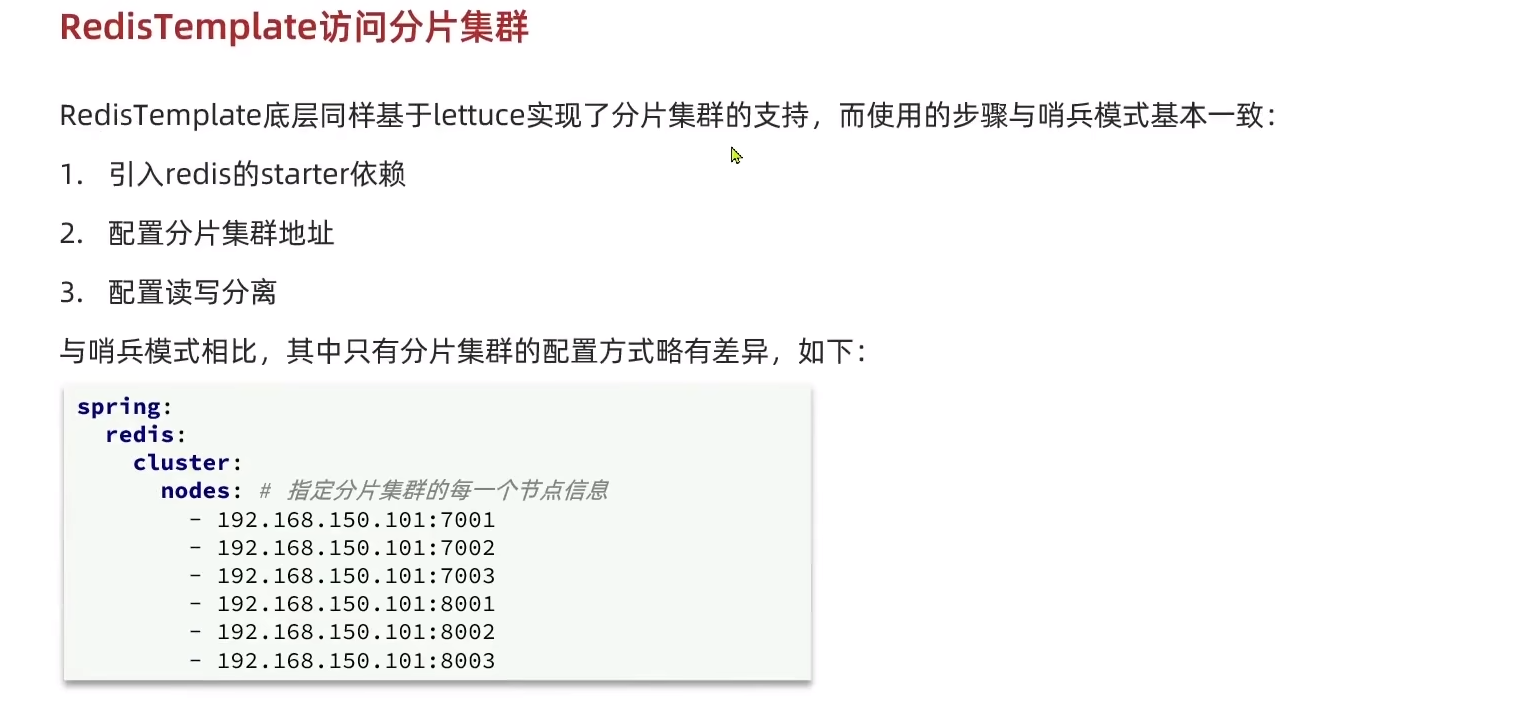
RedisTemplate访问分片集群















 1720
1720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









