







大模型学习笔记
引入:大模型技术全景
大模型=大规模(训练数据/模型规模大)语言模型(一种神经网络)
语言模型:理解输入-产生输出
统计语言模型-神经语言模型-预训练语言模型-大语言模型
卷积神经网络(CNN):图像处理 计算机视觉
循环神经网络(RNN):序列数据处理-文本音频
变压器模型(Transformer):自然语言处理和生成-逐渐和视觉领域融合(CNN)
生成式对抗网络(GANs):生成逼真图像视频
第一章 引言
语言模型:我们期望实现的是基于给定的文本信息输入,给出对应的新的文本/符号输出(可以是文本翻译、文本分类、文本扩写)。
解决问题:输入-文本转换数值 输出-数值转换文本(独热编码000 100 010 001)
语言模型本质上是对词元序列的概率分布,设词元集的词汇表V。语言模型p为每个词元序列 x1,...,xL ∈ V 分配一个概率(介于0和1之间的数字):p(x1,…,xL)
概率直观地告诉我们一个标记序列有多“好(good)”。
例如,如果词汇表为{ate, ball, cheese, mouse, the},语言模型可能会分配以下概率(演示):
p(the, mouse, ate, the, cheese)=0.02,好
p(the, cheese ate, the, mouse)=0.01,不好
p(mouse, the, the, cheese, ate)=0.0001,语法就不对 更不好
语言模型需要具备卓越的语言能力和世界知识,才能准确评估序列的概率。语言模型p接受一个序列并返回一个概率来评估其好坏。我们也可以根据语言模型生成一个序列。
1.1 自回归语言模型(Autoregressive language models)
x1:L∼p(x1:L代表一个长度为 L的序列,即x1,x2,...,xL。) 这部分表示从概率分布 p(x1:L)中采样,即按照语言模型的概率分布随机生成一个序列。
在生成序列时,我们 逐个 采样:
-
先根据 p(x1)选择第一个词 x1
-
再根据 p(x2|x1) 选择第二个词 x2
-
依此类推,直到生成完整的序列
要在概率上加一个1/T次幂,T≥0 是一个控制我们希望从语言模型中得到多少随机性的温度参数:
T=0:总是选择概率最高的词元(确定性生成)。
T=1:直接从模型的原始概率分布采样(正常采样)。
T→∞:所有词元的概率趋于相等(接近均匀随机采样)。
0<T<1:使高概率的词元更有可能被选中,降低低概率词元的概率(提高确定性)。
T>1:拉平分布,使得低概率词元更有可能被选中(增加随机性)。
这意味着当 T 值较高时,我们会获得更平均的概率分布,生成的结果更具随机性;反之,当 T 值较低时,模型会更倾向于生成概率较高的词元。

当 T ≠ 1 时,"逐步退火采样" 和 "整体退火采样" 可能会产生不同的结果,不能简单地等同。逐步退火是在 每个 token 的概率上调整温度后再生成,而整体退火是在 整个序列 的概率上调整温度后再采样。
非自回归的条件生成:你提供一个 前缀序列 x1:i(称为 提示 Prompt)。语言模型根据这个 提示 生成后续的文本 xi+1:L(称为 补全 Completion)。这种方法可以用于各种任务,如 文本补全、对话、翻译、代码补全等。
1.2 大模型历史
香农熵公式:
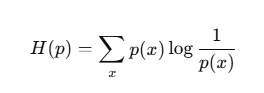
熵 H(p)H(p)H(p) 代表的是平均信息量,即编码整个概率分布所需的 最少平均比特数。
交叉熵:
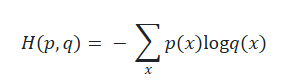
这测量了需要多少比特来编码样本x∼p,使用由模型q给出的压缩方案(用长度为1/q(x)的代码表示x)。
N-gram语言模型
N-gram 是一种基于前面 N-1 个词来预测当前词的模型。(不是所有)如:n=3
p(𝖼𝗁𝖾𝖾𝗌𝖾∣𝗍𝗁𝖾,𝗆𝗈𝗎𝗌𝖾,𝖺𝗍𝖾,𝗍𝗁𝖾)=p(𝖼𝗁𝖾𝖾𝗌𝖾∣𝖺𝗍𝖾,𝗍𝗁𝖾)。
基于统计次数计数:在一个大语料库(如维基百科)中,计算某个 N-gram 片段 出现的频率。但是有些组合从未出现,直接用频率计算会导致过拟合,N-gram采用平滑技术处理未见过的组合片段。
(1)加一平滑(Laplace Smoothing):给每个 n-gram 人工加一点概率,避免零概率问题。
(2)Kneser-Ney 平滑(更先进的方法):不是简单地基于频率计算概率,而是利用低阶 N-gram 频率来调整高阶概率,确保稀有词也能有合理的概率分布。
将n-gram模型拟合到数据上非常便宜且可扩展。因此,n-gram模型被训练在大量的文本上。然而,n-gram模型有其根本的限制。考虑:𝖲𝗍𝖺𝗇𝖿𝗈𝗋𝖽 𝗁𝖺𝗌 𝖺 𝗇𝖾𝗐 𝖼𝗈𝗎𝗋𝗌𝖾 𝗈𝗇 𝗅𝖺𝗋𝗀𝖾 𝗅𝖺𝗇𝗀𝗎𝖺𝗀𝖾 𝗆𝗈𝖽𝖾𝗅𝗌. 𝖨𝗍 𝗐𝗂𝗅𝗅 𝖻𝖾 𝗍𝖺𝗎𝗀𝗁𝗍 𝖻𝗒 ___
如果n太小,那么模型将无法捕获长距离的依赖关系,下一个词将无法依赖于𝖲𝗍𝖺𝗇𝖿𝗈𝗋𝖽。然而,如果n太大,统计上将无法得到概率的好估计(即使在“大”语料库中,几乎所有合理的长序列都出现0次):
count(𝖲𝗍𝖺𝗇𝖿𝗈𝗋𝖽,𝗁𝖺𝗌,𝖺,𝗇𝖾𝗐,𝖼𝗈𝗎𝗋𝗌𝖾,𝗈𝗇,𝗅𝖺𝗋𝗀𝖾,𝗅𝖺𝗇𝗀𝗎𝖺𝗀𝖾,𝗆𝗈𝖽𝖾𝗅𝗌)=0
神经语言模型
p(cheese∣ate,the)=some−neural−network(ate,the,cheese)
注意,上下文长度仍然受到n的限制,但现在对更大的n值估计神经语言模型在统计上是可行的。
然而,主要的挑战是训练神经网络在计算上要昂贵得多。他们仅在1400万个词上训练了一个模型,并显示出它在相同数据量上优于n-gram模型。但由于n-gram模型的扩展性更好,且数据并非瓶颈,所以n-gram模型在至少接下来的十年中仍然占主导地位。
神经语言建模的两个关键发展包括:
Recurrent Neural Networks(RNNs):一个词元条件分布可以依赖于整个上下文 但这些模型难以训练。
Transformers是一个较新的架构再次返回固定上下文长度n,但更易于训练(并利用了GPU的并行性)。此外,n可以对许多应用程序“足够大”(GPT-3使用的是n=2048)。
上下文学习:上下文学习(Context Learning)*是 GPT-3 通过观察输入示例的*格式、风格、规律,无需额外训练就能自动调整回答方式的能力。
第二章 大模型的能力
2.1 概述
GPT-3并未明确针对某种任务进行训练,它只是作为一个语言模型,被训练来预测下一个词。然而,即便没有“特别努力”,GPT-3平均来看,仍然可以在广泛的NLP任务中做得不错。由于GPT-3并未特别针对任何这些任务进行训练,因此它并未过度拟合,意味着它有很大的潜力在许多其他任务上表现良好。如果你希望在任何特定任务(例如问题回答)上表现良好,原则上你应能够利用大量的标签数据来适应GPT-3,并超越当前的技术水平。
2.2 语言模型的适应性:从语言模型到任务模型的转化
在自然语言处理的世界中,语言模型 p 是一种对token序列 x1:L 的分布。这样的模型能够用于评估序列,例如 p(𝗍𝗁𝖾,𝗆𝗈𝗎𝗌𝖾,𝖺𝗍𝖾,𝗍𝗁𝖾,𝖼𝗁𝖾𝖾𝗌𝖾) 。同样,它还能用于在给定提示的条件下生成完成的序列,如 𝗍𝗁𝖾 𝗆𝗈𝗎𝗌𝖾 𝖺𝗍𝖾⇝𝗍𝗁𝖾 𝖼𝗁𝖾𝖾𝗌𝖾 。
任务:输入-输出 如问答任务:
输入:What school did Burne Hogarth establish? 输出:School of Visual Arts
我们使用“适应(Adaptation)”一词来指代将语言模型转化为任务模型的过程。这个过程需要以下两个输入:
-
任务的自然语言描述
-
一组训练实例(输入-输出对)
我们主要有两种方式来进行这种适应:
训练(标准的有监督学习):训练一个新模型,使其能将输入映射到输出。这可以通过创建一个新模型并利用语言模型作为特征(探针法),或者从现有的语言模型出发,根据训练实例进行更新(微调),或者在这两者之间找到平衡(轻量级的微调)。
提示(上下文)学习:根据对任务的描述建一个或一组提示/上下文信息,将其输入到语言模型中以获取基于该任务的生成结果。根据提示/上下文信息的数量,我们还可以进一步细分:
-
零样本学习(Zero-shot):提示/上下文信息的数量为0,模型直接基于对任务的理解输出结果。
-
单样本学习(One-shot):提示/上下文信息的数量为1,一般来说模型基于1个例子可以更好的理解任务从而较好的生成结果。
-
少样本学习(Few-shot):提示/上下文信息的数量大于1,大模型可以看到更丰富的例子,一般来说获得比单样本学习更好的效果。
说白了语言模型改成任务模型有两种手段,一种从训练数据入手,把训练数据改成问答式重新训练或微调。一种是从上下文以问答模式进行学习。
提示的局限性在于我们只能利用少量的上下文实例(一般情况只能塞进一个提示的数量)。这种输入的局限性由于Transformer自身的局限性导致的,模型可输入的长度具有约束(一般来讲是2048个tokens)。
困惑度(Perplexity)是一个重要的指标,是自然语言处理和语言模型中的一个重要概念,用于衡量语言模型的性能。它可以解释为模型在预测下一个词时的平均不确定性。简单来说,如果一个模型的困惑度较低,那么它在预测下一个词的时候就会更加准确。对于给定的语言模型和一个测试数据集,困惑度被定义为:
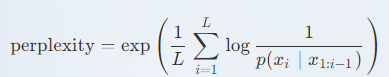
一个序列的联合概率取决于其长度,并且随着长度的增长,其值趋近于零,这使得困惑度变得难以追踪。我们希望对每个词标记(token)的概率 p(xi∣x1:i−1) 进行平均。这样做的目的是评估模型在处理各种词标记时的平均性能。事实上不希望采取算术平均,一个非常低的概率(如0)可能会被其他较高的概率抵消。
相反,我们希望采用几何平均,这就是困惑度(perplexity)所做的。在几何平均中,每个词标记的概率都被同等看待,并且一个极低的概率(如0)将会导致整个几何平均大幅度下降。(对数形式的“不确定性”。如果模型对某个词的预测概率很低(比如 p = 0.1 ),那么 log1/p就会很大,表示模型对这个词的预测“很不确定”。)因此,通过计算几何平均,我们可以更好地衡量模型在处理所有可能的词标记时的性能,特别是在处理那些模型可能会出错的情况。
困惑度就是表示下个词确定不确定从而衡量整个模型的预测性能。
两类错误:语言模型可能会犯两种类型的错误,而困惑度对这两种错误的处理方式并不对称:
(1)召回错误:语言模型未能正确地为某个词符分配概率值。这种情况下,困惑度是毫不留情的。例如,如果模型为词组 '𝖺𝗍𝖾' 在 '𝗍𝗁𝖾,𝗆𝗈𝗎𝗌𝖾' 后出现的概率预测为接近0,那么对应的困惑度值将趋近于无穷大。
(2)精确度错误:语言模型可能会对错误的词序列 赋予过高的概率,导致其生成的文本质量下降。假设我们给语言模型 p(xi∣x1:i−1)添加一个噪声分布 r(xi∣x1:i−1),按概率ϵ 混入垃圾信息:
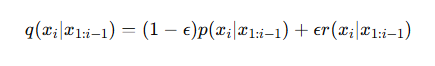
当我们计算 新的概率分布 q的困惑度 时,可以得出以下不等式: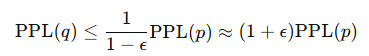
当 ϵ很小时,可以近似认为 困惑度增加 (1+ϵ) 倍。困惑度增加不多,但生成的文本质量会急剧下降。平均每 20 个词符 就会有 1 个词是随机的,导致生成的句子变得不通顺或无意义。
现实实例:
2.2.1 Penn Tree Bank
Penn Tree Bank 是自然语言处理中的一个经典数据集,最初是为了进行句法解析而标注的。若对PTB数据集使用语言模型对其基准进行测试,需要原始数据集做一些重要预处理,比如数据格式转换。
将整个文本作为提示输入到GPT-3中,并评估其困惑度。结果: GPT-3大幅度的超过了目前的最好结果(state-of-the-art)
那这个结果是否存在训练/测试泄露问题呢?数据泄露是当前大型数据集的另一个复杂问题:很难检查你的测试数据是否出现在你的训练数据中,并被记忆下来。
困惑度表示每个单词的确定概率,如果困惑度低说明模型对语言理解的好,每个单词都能准确预测出来。
2.2.2 LAMBADA
该数据的任务:预测句子的最后一个词。 动机:解决这个任务需要对较长的内容进行建模,并对较长的内容具有一定的依赖。LAMBADA本身是一个语言模型,因此就是使用自回归的方式生成下一个词,由于该任务的目的在于要求模型完成句子中的最后一个词。因此,一个关键的挑战是,模型默认情况下并不会识别出它需要生成的恰恰是句子的最后一个词。为了克服这一问题,我们需要将任务设计为更加明确的输入-输出映射关系。具体来说,通过提供额外的示例进行上下文学习,我们可以让模型学会在给定输入的情况下产生相应的输出,从而有效地解决了模型在完成句子时定位最后一个词的难题。
结果:GPT-3超过了之前的最好结果(GPT-2)
2.2.3 HellaSwag
动机:评估模型进行常识推理的能力 任务:从一系列选择中选出最适合完成句子的选项.该数据是一个多项选择任务,所以最自然的做法是用语言模型为每个候选答案打分,并预测“最佳”答案。
结果:GPT-3接近但没有超过最先进的水平,我们需要知道的是,SOTA结果是在该数据集的训练集中微调得到的结果,因此GPT-3在完全不在该数据集训练的情况下获得了接近的结果是很令人惊喜的。
***********问题回答********
我们现在考虑(闭卷)问答题,其中输入是一个问题,输出是一个答案。语言模型必须以某种方式“知道”答案,而无需在数据库或一组文档中查找信息。
2.2.4 TriviaQA
任务:给定一问题后生成答案 原始数据集是由业余爱好者收集的,并被用作开放式阅读理解的挑战,但我们用它来进行(闭卷)问题回答。我们根据训练实例和问题定义一个提示,并将完成的内容作为预测的答案。
结果:
| MODEL | ACCURACY |
|---|---|
| RAG | 68.0 |
| GPT-3 (zero-shot) | 64.3 |
| GPT-3 (few-shot) | 71.2 |
我们也看到,增加模型大小和增加in-context training实例都有助于提高性能。
2.2.5 WebQuestions
任务:和TriviaQA类似是问答任务 数据集从Google搜索查询中收集,最初用于对知识库的问题回答。我们定义一个提示,就如TriviaQA一样。
结果:
| MODEL | ACCURACY |
|---|---|
| RAG | 45.5 |
| GPT-3 (zero-shot) | 14.4 |
| GPT-3 (few-shot) | 41.5 |
2.2.6 Natural Questions
任务:回答问题 从Google搜索查询中收集的数据集(区别在于答案的长度较长)我们和上面一样定义一个提示。
2.2.7 Translation
翻译任务是将源语言(例如,德语)中的句子翻译成目标语言(例如,英语)中的句子。机器翻译一直是NLP的长期任务,2000年代开始,在NLP(拥有自己独特的子社区)中,统计机器翻译开始飞速发展,紧随其后的是2010年代中期的神经机器翻译。由于存在人类翻译者,因此它一直是一个数据丰富的领域。标准的评估数据集比如是WMT’14和WMT’16数据集。由于存在多种可能的翻译,所以(自动)评估指标是BLEU(它捕获了n-gram重叠的概念)。对于Few-shot的情况,我们构造了一个包含输入-输出训练实例以及输入的提示。
结果:这里是从德语到英语的结果:
| MODEL | ACCURACY |
|---|---|
| SOTA (supervised) | 40.2 |
| GPT-3 (zero-shot) | 27.2 |
| GPT-3 (few-shot) | 40.6 |
-
即使没有监督训练数据,GPT-3也能达到全监督系统的最新技术水平!
-
这为机器翻译的性能设定了一个下限;因为肯定会想利用大量的平行语料库(对齐的输入-输出对)。
-
法语和罗马尼亚语的结果类似。
-
从英语到外语的结果要差得多,这是可以预料的,因为GPT-3主要是一个英语模型。
2.2.8 Arithmetic
GPT-3是一个语言模型(主要是英语),但我们可以在一系列更“抽象推理”的任务上评估它,以评估GPT-3作为更通用模型的性能。这里的Arithmetic任务是做算术题(2-5位数的加法,减法,乘法)你没有实际的理由要解决这个问题;这只是一个诊断任务,满足我们的科学好奇心。
从实验结果看起来,虽说不能认为GPT-3获得很好的结果,但是还是让我们惊艳,并对未来充满想象。
2.2.9 News article generation
任务:给定标题和副标题,生成新闻文章。 数据集:标题/副标题取自newser.com。 我们设立了一个评估标准,人类根据文章可能由机器编写的可能性对文章进行评分。
结果:人类只有52%的概率能够正确地分类“人类”与“机器”(几乎只是随机机会)。
********新任务**********
2.2.10 使用新词
任务:给定一个新造的词和定义,生成使用该词的句子。
2.2.11 纠正英语语法
任务:给定一个不合语法的句子,生成其合语法的版本。 我们通过给出提示来描述任务(提示是有输入和输入对组成的)
2.2.12 其他任务
自原始论文以来,GPT-3已应用于许多更多的任务,包括基准数据集(Benchmark)和一次性的演示(one-off deoms)。
Benchmarks:
-
SWORDS:词汇替换,目标是在句子的上下文中预测同义词。
-
Massive Multitask Language Understanding:包括数学,美国历史,计算机科学,法律等57个多选问题。
-
TruthfulQA:人类由于误解而错误回答的问答数据集。
结果:虽说GPT-3在这些Benchmark数据集中的表现平庸,但是考虑到我们只使用了few-shot的情况,或许不算太差。
zero-shot 和 few-shot 的主要区别在于是否提供上下文提示(prompting)。
one-off Demos:
-
Examples from gpt3demo.com 这些演示既创新又有趣,但很难判断它们的可靠性如何。
第三章 模型架构
3.1 模型概括
我们一开始先将语言模型(model)的看作一个黑箱(black box)(在后续的内容中再逐步的拆解),其可以根据输入需求的语言描述(prompt)生成符合需求的结果(completion)。形式可以表达为:
大语言模型的训练数据(traning data)形式化描述:
training data⇒p(x1,...,xL) - 由训练数据得到模型参数
-
分词(Tokenization):即如何将一个字符串拆分成多个词元。
-
模型架构(Model architecture):我们将主要讨论Transformer架构,这是真正实现大型语言模型的建模创新。
3.2 分词
语言模型 p 是建立在词元(token)序列的上的一个概率分布输出,其中每个词元来自某个词汇表V,如下的形式。
[the, mouse, ate, the, cheese]
Tips: 词元(token)一般在NLP(自然语言处理)中来说,通常指的是一个文本序列中的最小单元,可以是单词、标点符号、数字、符号或其他类型的语言元素。通常,对于NLP任务,文本序列会被分解为一系列的tokens,以便进行分析、理解或处理。在英文中一个"token"可以是一个单词,也可以是一个标点符号。在中文中,通常以字或词作为token(这其中就包含一些字符串分词的差异性,将在后续内容中讲到)。
分词器将任意字符串转换为词元序列: 'the mouse ate the cheese.' ⇒[the,mouse,ate,the,cheese,.]
相当于把一个字符串分割为了多了子字符串,每个子字符串是一个词元。我们所日常了解的输入需要是数值的,从而才能在模型中被计算,所以,如果输入是非数值类型的字符串是怎么处理的呢?
自然语言和机器语言一种隐式的对齐,为什么说是“隐式的对齐”,这是由于每一个词在模型中,都有一个其确定的词向量。下面一个一个介绍如何分词以及词元如何转换成词向量。
3.2.1 基于空格的分词
可视化的词编码: GPT token encoder and decoder / Simon Willison | Observable
最简单的解决方案是使用text.split(' ')方式进行分词,这种分词方式对于英文这种按照空格,且每个分词后的单词有语义关系的文本是简单而直接的分词方式。然而,对于一些语言,如中文,句子中的单词之间没有空格,例如下文的形式。"我今天去了商店。"还有一些语言,比如德语,存在着长的复合词(例如Abwasserbehandlungsanlange)。即使在英语中,也有连字符词(例如father-in-law)和缩略词(例如don't),它们需要被正确拆分。因此,仅仅通过空格来划分单词会带来很多问题。
那么,什么样的分词才是好的呢?目前从直觉和工程实践的角度来说:
-
首先我们不希望有太多的词元(极端情况:字符或字节),否则序列会变得难以建模。
-
其次我们也不希望词元过少,否则单词之间就无法共享参数(例如,mother-in-law和father-in-law应该完全不同吗?),这对于形态丰富的语言尤其是个问题(例如,阿拉伯语、土耳其语等)。
-
每个词元应该是一个在语言或统计上有意义的单位。
3.2.2 Byte pair encoding
将字节对编码(BPE)算法应用于数据压缩领域,用于生成其中一个最常用的分词器。BPE分词器需要通过模型训练数据进行学习,获得需要分词文本的一些频率特征。
学习分词器的过程,直觉上,我们先将每个字符作为自己的词元,并组合那些经常共同出现的词元。整个过程可以表示为:Input(输入):训练语料库(字符序列)。
算法步骤:
(1)初始化词汇表 V 为字符的集合。
while(当我们仍然希望V继续增长时):
(2)找到V中共同出现次数最多的元素对 x,x′ 。
(3)用一个新的符号 xx′ 替换所有 x,x′ 的出现。
(4)将xx'添加到V中。
例子:输入语料: Input:I = [['the car','the cat','the rat']]
初始词汇表:V=['t','h','e',' ','c','a','r','t'],我们开始执行 Step2-4:
我们找到V中共同出现次数最多的元素对 x,x′,我们发现't'和'h'按照'th'形式一起出现了三次,'h'和'e'按照'he'形式一起出现了三次,我们可以随机选择其中一组,假设我们选择了'th'。用一个新的符号 xx′ 替换所有 x,x′ 的出现: 将之前的序列更新如下:(th 出现了 3次)
[[th, e, space, c, a, r], [th, e, space, c, a, t], [th, e, space, r, a, t]]
将xx'添加到V中: 从而得到了一次更新后的词汇表V=['t','h','e',' ','c','a','r','t','th']。接下来如此往复。
Unicode的问题:Unicode(统一码)是当前主流的一种编码方式。其中这种编码方式对BPE分词产生了一个问题(尤其是在多语言环境中),Unicode字符非常多(共144,697个字符)。在训练数据中我们不可能见到所有的字符。 为了进一步减少数据的稀疏性,我们可以对字节而不是Unicode字符运行BPE算法(Wang等人,2019年)。 以中文为例:
今天⇒[x62, x11, 4e, ca]
BPE算法在这里的作用是为了进一步减少数据的稀疏性。通过对字节级别进行分词,可以在多语言环境中更好地处理Unicode字符的多样性,并减少数据中出现的低频词汇,提高模型的泛化能力。通过使用字节编码,可以将不同语言中的词汇统一表示为字节序列,从而更好地处理多语言数据。
3.2.3 Unigram model (Sentence Piece)
与仅仅根据频率进行拆分不同,一个更“有原则”的方法是定义一个目标函数来捕捉一个好的分词的特征,这种基于目标函数的分词模型可以适应更好分词场景,Unigram model就是基于这种动机提出的。我们现在描述一下unigram模型(Kudo,2018年)。
这是SentencePiece工具(Kudo&Richardson,2018年)所支持的一种分词方法,与BPE一起使用。 它被用来训练T5和Gopher模型。给定一个序列 x1:L ,一个分词器 T 是 p(x1:L)=∏(i,j)∈Tp(xi:j) 的一个集合。这边给出一个实例:
-
训练数据(字符串): 𝖺𝖻𝖺𝖻𝖼
-
分词结果 T=(1,2),(3,4),(5,5) (其中 V=𝖺𝖻,𝖼 )
-
似然值: p(x1:L)=2/3⋅2/3⋅1/3=4/27
在这个例子中,训练数据是字符串" 𝖺𝖻𝖺𝖻𝖼 "。分词结果 T=(1,2),(3,4),(5,5) 表示将字符串拆分成三个子序列: (𝖺,𝖻),(𝖺,𝖻),(𝖼) 。词汇表 V=𝖺𝖻,𝖼 表示了训练数据中出现的所有词汇。
似然值 p(x1:L) 是根据 unigram 模型计算得出的概率,表示训练数据的似然度。在这个例子中,概率的计算为 2/3⋅2/3⋅1/3=4/27 。这个值代表了根据 unigram 模型,将训练数据分词为所给的分词结果 T的概率。
unigram 模型通过统计每个词汇在训练数据中的出现次数来估计其概率。在这个例子中, 𝖺𝖻 在训练数据中出现了两次, 𝖼 出现了一次。因此,根据 unigram 模型的估计, p(𝖺𝖻)=2/3 , p(𝖼)=1/3 。通过将各个词汇的概率相乘,我们可以得到整个训练数据的似然值为 4/27 。
似然值的计算是 unigram 模型中重要的一部分,它用于评估分词结果的质量。较高的似然值表示训练数据与分词结果之间的匹配程度较高,这意味着该分词结果较为准确或合理。
似然值越高,表示当前分词方式T在模型下越合理。训练过程的目标是 最大化数据的似然值,即找到最符合统计规律的分词方式。算法流程:
(1)初始化:设定一个相当大的初始词汇表V,包含所有可能的子词单元。例如:对于 "𝖺𝖻𝖺𝖻𝖼",初始V可能包括单个字符 {𝖺, 𝖻, 𝖼},也包括子串 {𝖺𝖻, 𝖻𝖺, 𝖺𝖻𝖼} 等。
(2)训练 - 使用 EM 算法优化 p(x) 和 T:p(x):每个子词 xxx 在词汇表中的概率。T:数据的最佳分词方式。
EM 算法的作用:E 步 (Expectation):
计算所有可能的分词方式 T 的概率,并找到最大似然分词方案。
M 步 (Maximization):
更新每个子词的概率 p(x)p(x)p(x),使得数据的似然值最大化。
(3)计算 Loss 并剪枝
一旦获得优化后的 p(x),我们计算每个词汇的 loss(衡量去掉某个子词后似然值降低的程度)。按照 loss(x)loss(x)loss(x) 进行排序,保留贡献最大的 80% 词汇,删除贡献较小的 20%。这样可以减少冗余词汇,提高模型效率,同时保留对分词最重要的子词。
(4)迭代优化
继续使用 更新后的词汇表 V 重新执行 Step 2-3。这个过程持续进行,直到词汇表收敛(不再大幅变化)。
这个过程旨在优化词汇表,剔除对似然值贡献较小的词汇,以减少数据的稀疏性,并提高模型的效果。通过迭代优化和剪枝,词汇表会逐渐演化,保留那些对于似然值有较大贡献的词汇,提升模型的性能。
3.3 模型架构
在实践中,对于专门的任务来说,避免生成整个序列的生成模型可能更高效。上下文向量表征 (Contextual Embedding): 作为模型处理的先决条件,其关键是将词元序列表示为响应的上下文的向量表征:(两个the上下文不同 表示也就不同)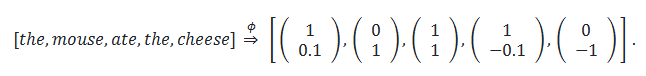
正如名称所示,词元的上下文向量表征取决于其上下文(周围的单词);例如,考虑mouse的向量表示需要关注到周围某个窗口大小的其他单词。
-
符号表示:我们将 ϕ:VL→ℝd×L 定义为嵌入函数(类似于序列的特征映射,映射为对应的向量表示)。
-
对于词元序列 x1:L=[x1,…,xL],ϕ生成上下文向量表征 ϕ(x1:L)。
3.3.1 语言模型分类
对于语言模型来说,最初的起源来自于Transformer模型,这个模型是编码-解码端 (Encoder-Decoder)的架构。但是当前对于语言模型的分类,将语言模型分为三个类型:编码端(Encoder-Only),解码端(Decoder-Only)和编码-解码端(Encoder-Decoder)。因此我们的架构展示以当前的分类展开。
编码端(Encoder-Only)架构
编码端架构的著名的模型如BERT、RoBERTa等。这些语言模型生成上下文向量表征,但不能直接用于生成文本。可以表示为, x1:L⇒ϕ(x1:L) 。这些上下文向量表征通常用于分类任务(也被称为自然语言理解任务)。任务形式比较简单,下面以情感分类/自然语言推理任务举例:
情感分析输入与输出形式:[[CLS],他们,移动,而,强大]⇒正面情绪
自然语言处理输入与输出形式:[[CLS],所有,动物,都,喜欢,吃,饼干,哦]⇒蕴涵
该架构的优势是对于文本的上下文信息有更好的理解,因此该模型架构才会多用于理解任务。该架构的有点是对于每个 xi ,上下文向量表征可以双向地依赖于左侧上下文 (x1:i−1) 和右侧上下文 (xi+1:L) 。但是缺点在于不能自然地生成完成文本,且需要更多的特定训练目标(如掩码语言建模)。
解码器(Decoder-Only)架构
解码器架构的著名模型就是大名鼎鼎的GPT系列模型。这些是我们常见的自回归语言模型,给定一个提示 x1:i ,它们可以生成上下文向量表征,并对下一个词元 xi+1 (以及递归地,整个完成 xi+1:L) 生成一个概率分布。 x1:i⇒ϕ(x1:i),p(xi+1∣x1:i) 。我们以自动补全任务来说,输入与输出的形式为, [[CLS],他们,移动,而]⇒强大 。与编码端架构比,其优点为能够自然地生成完成文本,有简单的训练目标(最大似然)。缺点也很明显,对于每个 xi ,上下文向量表征只能单向地依赖于左侧上下文 (x1:i−1) 。
总结:编码器适用于上下文理解从而分类,解码器只能读到左侧文本用于补全。
编码-解码端(Encoder-Decoder)架构
编码-解码端架构就是最初的Transformer模型,其他的还有如BART、T5等模型。这些模型在某种程度上结合了两者的优点:它们可以使用双向上下文向量表征来处理输入 x1:L ,并且可以生成输出 y1:L 。可以公式化为:
x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。
以表格到文本生成任务为例,其输入和输出的可以表示为:
[名称:,植物,|,类型:,花卉,商店]⇒[花卉,是,一,个,商店]。
该模型的具有编码端,解码端两个架构的共同的优点,对于每个 xi ,上下文向量表征可以双向地依赖于左侧上下文 x1:i−1 ) 和右侧上下文 ( xi+1:L ),可以自由的生成文本数据。缺点就说需要更多的特定训练目标。
3.3.2 语言模型理论
深度学习的美妙之处在于能够创建构建模块,就像我们用函数构建整个程序一样。因此,在下面的模型架构的讲述中,我们能够像下面的函数一样封装,以函数的的方法进行理解: TransformerBlock(x1:L)
基础架构
首先,我们需要将词元序列转换为序列的向量形式。EmbedToken 函数通过在嵌入矩阵 E∈ℝ|v|×d 中查找每个词元所对应的向量,该向量的具体值这是从数据中学习的参数:def EmbedToken(x1:L:VL)→ℝd×L :
-
将序列 x1:L 中的每个词元 xi 转换为向量。
-
返回[Ex1,…,ExL]。
以上的词嵌入是传统的词嵌入,向量内容与上下文无关。这里我们定义一个抽象的 Sequence Model 函数,它接受这些上下文无关的嵌入,并将它们映射为上下文相关的嵌入。
def Sequence Model(x1:L:ℝd×L)→ℝd×L :
-
针对序列 x1:L 中的每个元素xi进行处理,考虑其他元素。
-
[抽象实现(例如, Feed Forward Sequence Model , Sequence RNN , Transformer Block )]
递归神经网络
第一个真正的序列模型是递归神经网络(RNN),它是一类模型,包括简单的RNN、LSTM和GRU。基本形式的RNN通过递归地计算一系列隐藏状态来进行计算。
def Sequence RNN(x:ℝd×L)→ℝd×L :
-
从左到右处理序列 x1,…,xL ,并递归计算向量 h1,…,hL 。
-
对于i=1,…,L:
-
计算 hi=RNN(hi−1,xi) 。
-
返回 [h1,…,hL] 。
-
实际完成工作的模块是RNN,类似于有限状态机,它接收当前状态h、新观测值x,并返回更新后的状态:
def RNN(h:ℝd,x:ℝd)→ℝd :
-
根据新的观测值x更新隐藏状态h。
-
[抽象实现(例如,Simple RNN,LSTM,GRU)]
有三种方法可以实现RNN。最早的RNN是简单RNN(Elman,1990),它将h和x的线性组合通过逐元素非线性函数 σ (例如,逻辑函数 σ(z)=(1+e−z)−1 或更现代的 ReLU 函数 σ(z)=max(0,z) )进行处理。
def Simple RNN(h:ℝd,x:ℝd)→ℝd :
-
通过简单的线性变换和非线性函数根据新的观测值 x 更新隐藏状态 h 。
-
返回 σ(Uh+Vx+b) 。
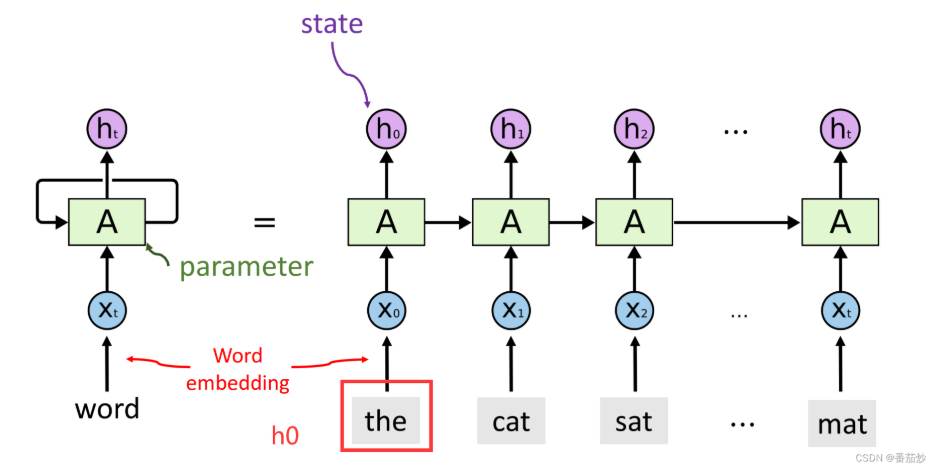
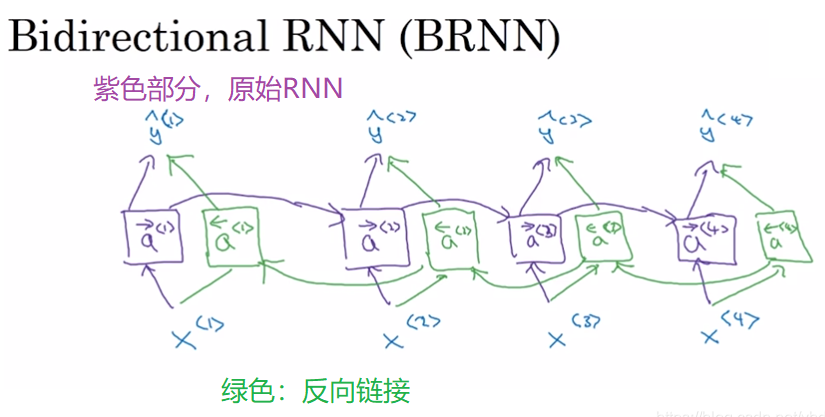
注意:整个RNN只有一个参数A, 不论这条链有多长,参数A只有一个,最开始A随机初始化,然后利用训练数据来学习A,正如定义的RNN只依赖于过去,但我们可以通过向后运行另一个RNN来使其依赖于未来两个。这些模型被ELMo和ULMFiT使用。提出双向RNN:
def Bidirectional Sequence RNN(x1:L:ℝd×L)→ℝ2d×L :
-
同时从左到右和从右到左处理序列。
-
计算从左到右: [h→1,…,h→L]←Sequence RNN(x1,…,xL) 。
-
计算从右到左: [h←L,…,h←1]←Sequence RNN(xL,…,x1) 。
-
返回 [h→1h←1,…,h→Lh←L] 。
-
简单RNN由于梯度消失的问题很难训练。
-
为了解决这个问题,发展了长短期记忆(LSTM)和门控循环单元(GRU)(都属于RNN)。
-
然而,即使嵌入h200可以依赖于任意远的过去(例如,x1),它不太可能以“精确”的方式依赖于它(更多讨论,请参见Khandelwal等人,2018)。
-
从某种意义上说,LSTM真正地将深度学习引入了NLP领域。
3.3.3 Transformer
现在,我们将讨论Transformer(Vaswani等人,2017),这是真正推动大型语言模型发展的序列模型。正如之前所提到的,Transformer模型将其分解为Decoder-Only(GPT-2,GPT-3)、Encoder-Only(BERT,RoBERTa)和Encoder-Decoder(BART,T5)模型的构建模块。
论文:attention is all you need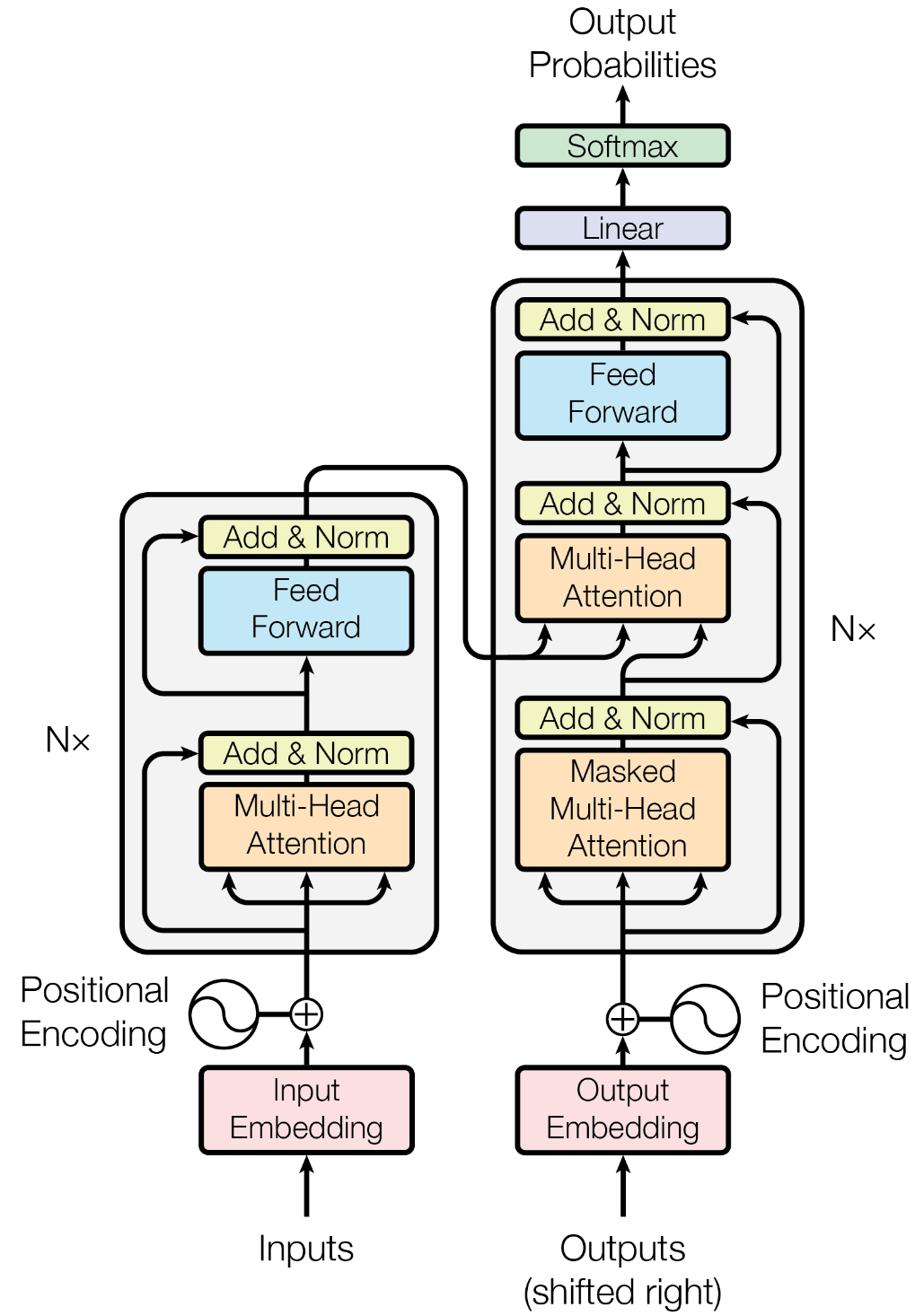
Add&Norm残差连接:是一种常用于深度学习模型中的技术,旨在帮助解决随着网络深度增加而出现的梯度消失或梯度爆炸问题。在传统的深度神经网络中,每一层的输出是基于前一层的输出进行计算。当网络层次增加时,网络的训练变得困难,因为梯度在反向传播过程中容易消失或爆炸。残差连接通过添加额外的“快捷连接”(shortcut connections)来解决这个问题。这些快捷连接允许一部分输入直接跳过一个或多个层传到更深的层,从而在不增加额外参数或计算复杂度的情况下,促进梯度的直接反向传播。 具体来说:设想一个简单的网络层,其输入为 𝑥,要通过一个非线性变换 𝐹(𝑥) 来得到输出。在没有残差连接的情况下,这个层的输出就是 𝐹(𝑥)。当引入残差连接后,这个层的输出变为𝐹(𝑥) + 𝑥。这里的𝑥是直接从输入到输出的跳过连接(Skip Connection),𝐹(𝑥) + 𝑥即是考虑了输入本身的残差输出。这样设计允许网络在需要时倾向于学习更简单的函数(例如,当 𝐹(𝑥) 接近0时,输出接近输入),这有助于提高网络的训练速度和准确性。
编码器:N=6完全一样的层,每个层会有两个子层。(多头注意和MLP-多层感知机)
残差连接:+x避免导数趋于0 梯度消散,要求输入和输出维度相同。所以定为512。
所以参数只有两个,一个就是N多少层,一个就是dmodel嵌入向量维度。
batchnorm和layernorm区别:(用于加速训练等)
batchnorm:一批的同一特征归一化
layernorm:一批的其中一个样本的归一化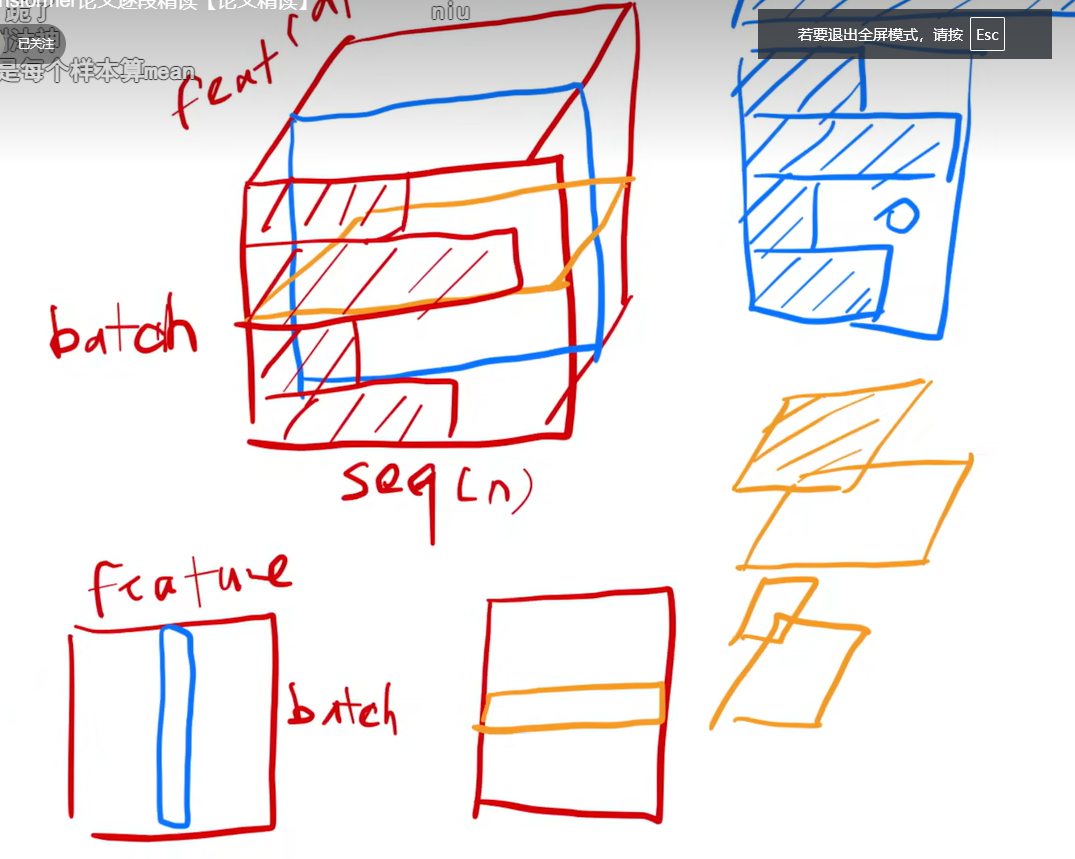
解码器:跟编码器对应N=6,每个里面两个子层。自回归输入是之前的输出,所以他预测的时候应该看不到t时刻之后的输入。但是注意力机制之前说是能看到整个输入的,所以这里需要有一个mask机制(掩码注意力机制),保证训练时看到的和真正预测时看到的一致。
注意力机制:注意力函数可以解释为一个查询和一对key-value映射到输出。输出是根据key和query的相似度计算来的。相似函数可以不同。
文章假设query和key长度相同,两个向量做内积,内积越大相似度越高,公式如下: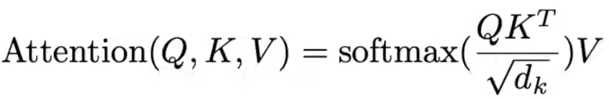

softmax之后得到相似度权重乘以value后得到注意力的输出。n个query m个key 每个key对应一个value 每个key有一个权重 计算出n个加权后的输出。
为什么除以根号下dk:当dk不是很大的时候其实无所谓,但是当dk很大的时候,q,k两个向量很长。点积的差距比较大(大的很大 小的很小),做softmax就会往两端靠拢,这样梯度很小,跑不动。
正常在推理时,我看不到kt以后的token,但是注意力机制q*k时,是跟所有的k进行内积。这样并不是很一致,那怎么办呢?计算原理如图:(mask屏蔽到kt以后的信息)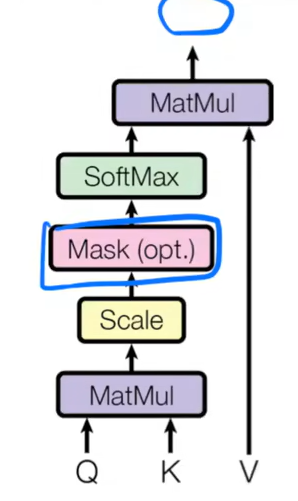
kt以后计算的数换成很大的复数,softmax之后这些东西就会变成0。
多头注意力:如图: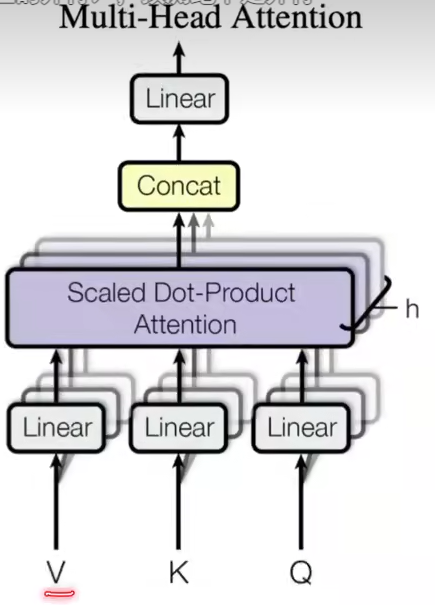
原始的QKV,经过线性层(投影到低维度)。经过注意力计算h次,再把输出向量合并在一起经过线性投影把维度升回来。h次不同投影方法~(Wi)公式如下:
transformer如何使用多头注意力(三处):
(1)编码器注意力:输入分成三叉,也就是说它既作为Q也作为K,V。(自注意力机制)输出是value的加权和,权重由q,k决定。
(2)解码器输入注意力:同上,不同点在于mask。
(3)编码器最上面的注意力:不再是自注意力,根据编码器(v,k)和解码器(q)的输出,相当于解码器把编码器里想要的一些东西拎出来。比如hello world翻译为中文,在输出到“好”的时候,跟hello应该更相近一些。
那feedforward是干啥的?
输入很多词,每个词都是一个position。公式如下: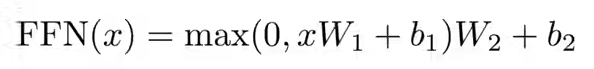
一个MLP对每个词作用一次,W1会把x(512)扩为2048,W2又变为512。
attention把序列全局数据抓取出来做一次汇聚,MLP提取非线性特征。自注意力使得所有的词元都可以“相互通信”,而前馈层提供进一步的连接。
attention没有时序信息,加入时序信息(positional encoding):词位置加入输入里。公式如下: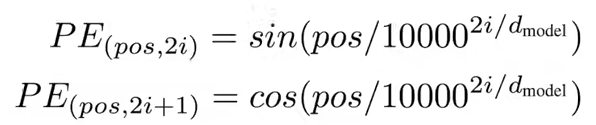
一个词用512的向量表示,位置也是。相加就完成嵌入了。
第四章 新的模型架构
随着模型越来越大,它们必须被拆分到更多的机器上,网络带宽成为训练的瓶颈。下面是一个模型并行示例:
GPU1[layer1,layer2]GPU2[layer3,layer4]GPU3[layer5,layer6]
因此,如果我们要继续扩大规模,我们需要重新思考如何构建大语言模型。对于稠密的Transformer模型,每个输入使用语言模型的相同(所有)参数(如GPT-3的175B参数)。相反,我们是否可以让每个输入使用不同的(更小的)参数子集?在本章中,我们将探讨两种不同类型的“新”模型架构,这提高了模型的规模上限。特别地,我们将讨论:
-
混合专家模型:我们创建一组专家。每个输入只激活一小部分专家。
-
直觉:类似一个由专家组成的咨询委员会,每个人都有不同的背景(如历史、数学、科学等)。
-
input⇒expert1 expert2 expert3 expert4⇒output.
-
基于检索的模型:我们有一个原始数据存储库。给定一个新的输入,我们检索存储库中和它相关的部分,并使用它们来预测输出。
-
直觉:如果有人问你一个问题,你会进行网络搜索,并阅读搜索得到的文档以得出答案。
-
store|input⇒relevant data from store⇒output.
4.1 混合专家模型
混合专家的想法可以追溯到Jacobs et al. (1991)。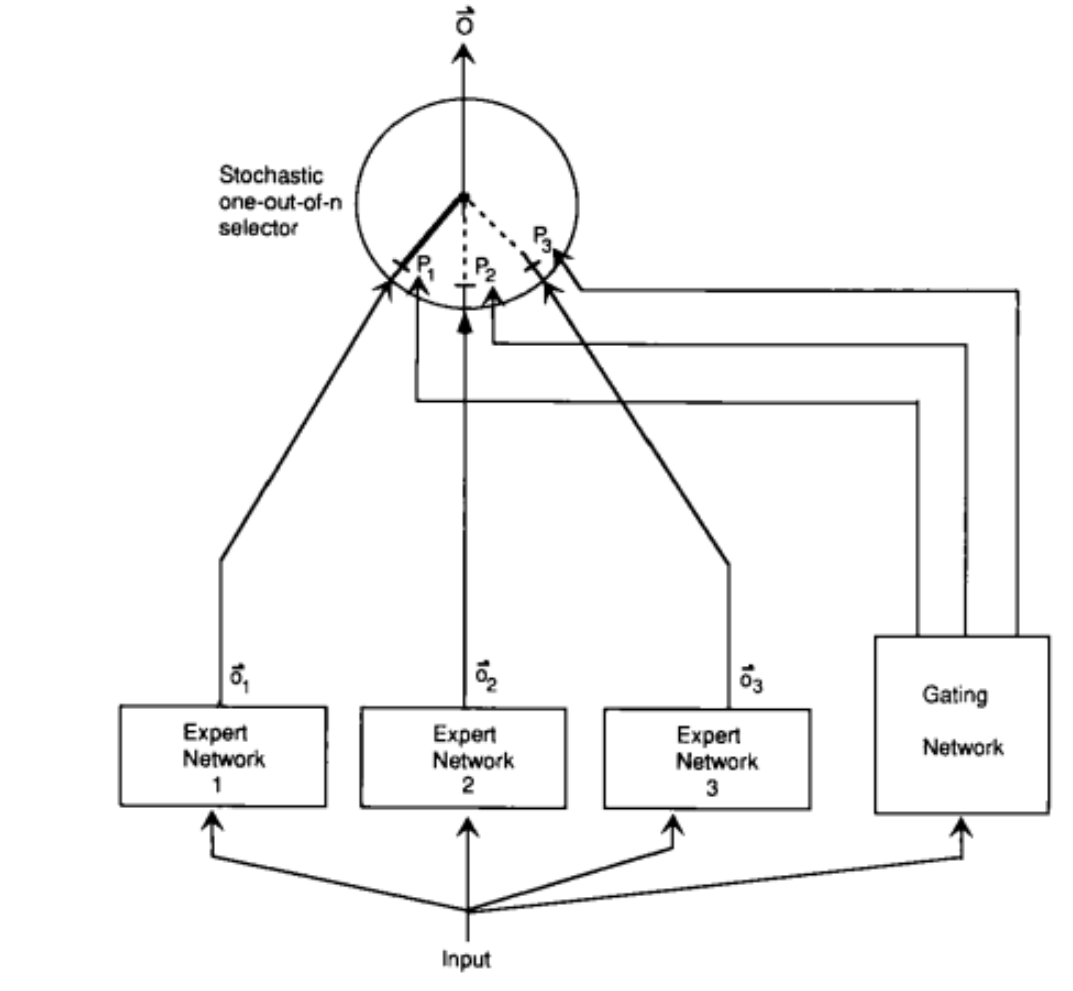
为了介绍基本思想,假设我们正在解决一个预测问题:
x∈Rd⇒y∈Rd.
让我们从学习前馈(ReLU)神经网络开始:
hθ(x)=W2max(W1x,0),
其中参数为 θ=(W1,W2) 。
-
然而,这个函数可能表达能力不足。
-
我们可以使神经网络更宽或更深。
但专家的混合方法是:
-
定义 E 个专家。
-
每个专家 e=1,…,E 都具有自己的嵌入 we∈Rd 。
-
将门控函数定义为 E 个专家上的概率分布:
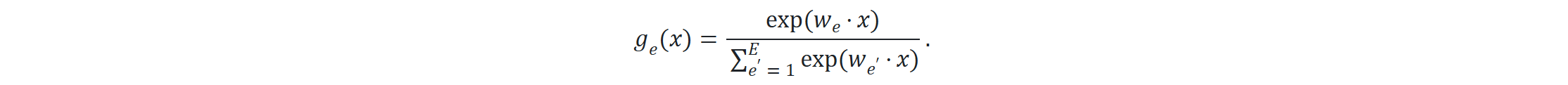
-
每个专家 e=1,…,E 都具有自己的参数 θ(e)=(W1(e),W2(e)) 。
-
根据专家特定参数定义每个专家函数:
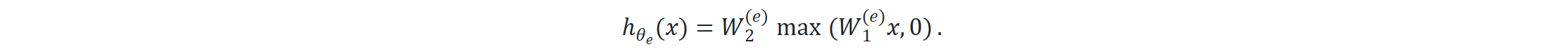
由 所有专家的输出加权求和: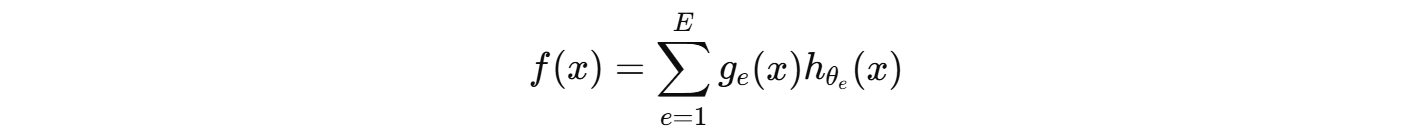
ge(x)作为权重,用来加权专家hθe(x)的输出。
4.1.1 示例
考虑d=2,并且每个专家都是一个线性分类器(来源):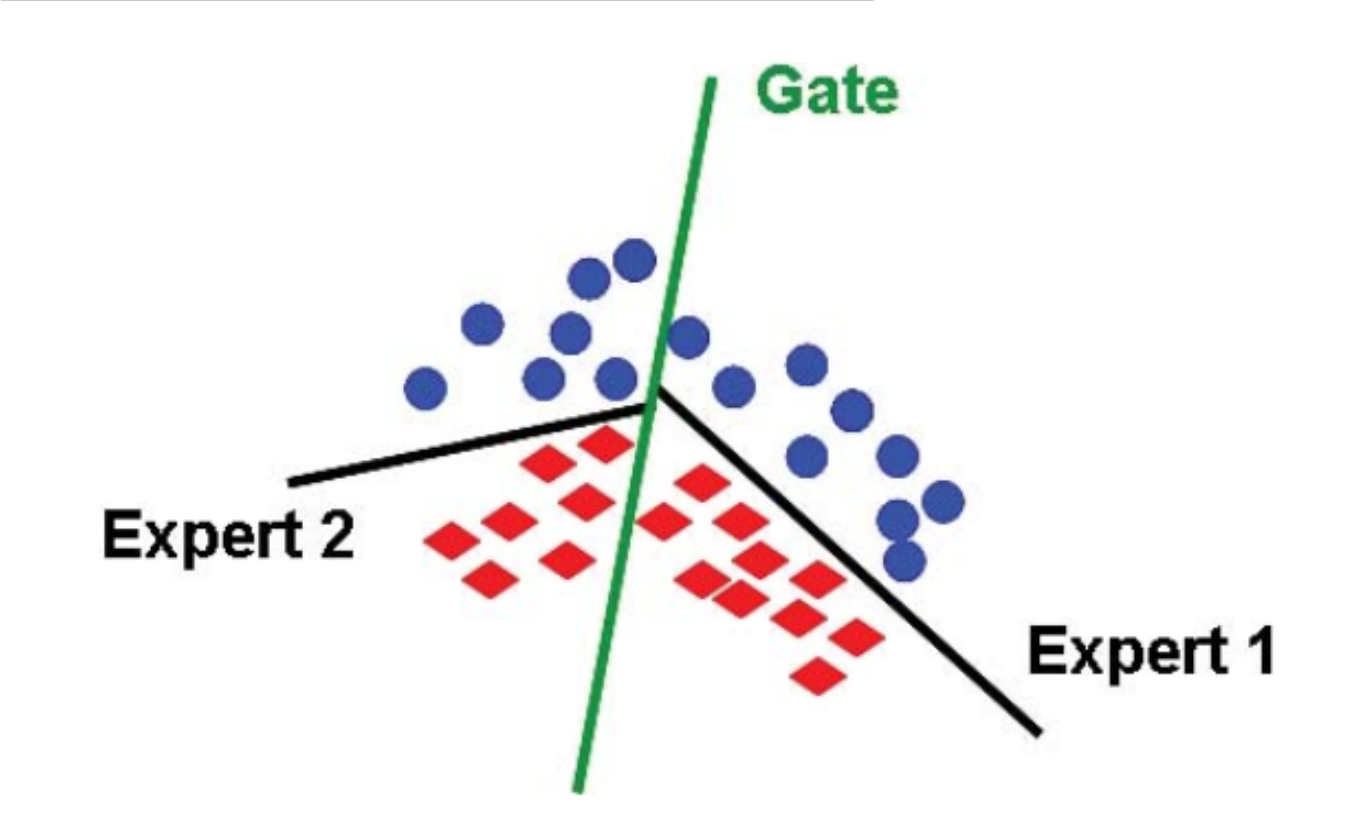
我们可以通过反向传播来学习混合专家模型。根据链式法则,可以得到:
注意到,梯度与 ge(x) 成比例,并且同时更新门控函数和专家。
为所有专家分配了非零权重,例如:
g(x)=[0.04,0.8,0.01,0.15]
这意味着每次前向传播(forward pass)和反向传播(backward pass)都必须计算 所有专家 的输出,这会导致计算资源的浪费,尤其是当专家数量很大时。
在原始的 MoE 结构中,门控网络 g(x)为了节省计算,我们可以让大部分专家的权重变为零,只选择一部分专家进行计算。例如:
-
选取权重最大的前 k 个专家(通常是 top-1 或 top-2)。
-
其他专家的权重设为 0。
-
对选中的专家的权重重新归一化,使其总和仍为 1。
示例
-
原始的门控输出:
g(x)=[0.04,0.8,0.01,0.15]
-
取前 2 个专家(Top-2 gating):
-
选取第 2 个(0.8)和第 4 个(0.15)。
-
归一化它们,使总和仍为 1:
g~(x)=[0,0.84,0,0.16]
-
这样,在前向和反向传播时,我们只计算非零权重的专家,节省了大量计算量。
这种方法被称为稀疏门控(Sparse MoE),被 Google 在 Switch Transformer 和 GLaM(Generalist Language Model) 中广泛使用,大幅降低了计算成本。
-
只有所有专家都参与进来,混合专家才有效。
-
如果只有一个专家处于活跃状态(例如, g(x)=[0,1,0,0] ),那么这就是浪费。
-
此外,如果我们一直处于这种状态,那么未使用的专家的梯度将为零,因此他们将不会收到任何梯度并得到改善。
-
因此,使用混合专家的主要考虑因素之一是确保所有专家都能被输入使用。
-
混合专家非常有利于并行。
-
每个专家都可以放置在不同的机器上。
-
我们可以在中心节点计算近似门控函数 g~(x) 。
-
然后,我们只要求包含激活专家的机器(稀疏)来处理 x 。
4.1.2 Sparsely-gated mixture of experts (Lepikhin et al. 2021)
-
现在我们考虑如何将混合专家思想应用于语言模型。
-
最简单的解决方案是仍然使用96层Transformer,但是
-
门控函数以某种方式应用于序列;
-
只在顶层进行专家的结合。
-
-
因此,我们将混合专家的想法应用于:
-
每个token
-
每层Transformer block(或者隔层使用)
-
-
由于前馈层对于每个token是独立的,因此,我们将每个前馈网络转变为混合专家(MoE)前馈网络:
MoETransformerBlock(x1:L)=AddNorm(MoEFeedForward,AddNorm(SelfAttention,x1:L)).
-
隔层使用MoE Transformer block。
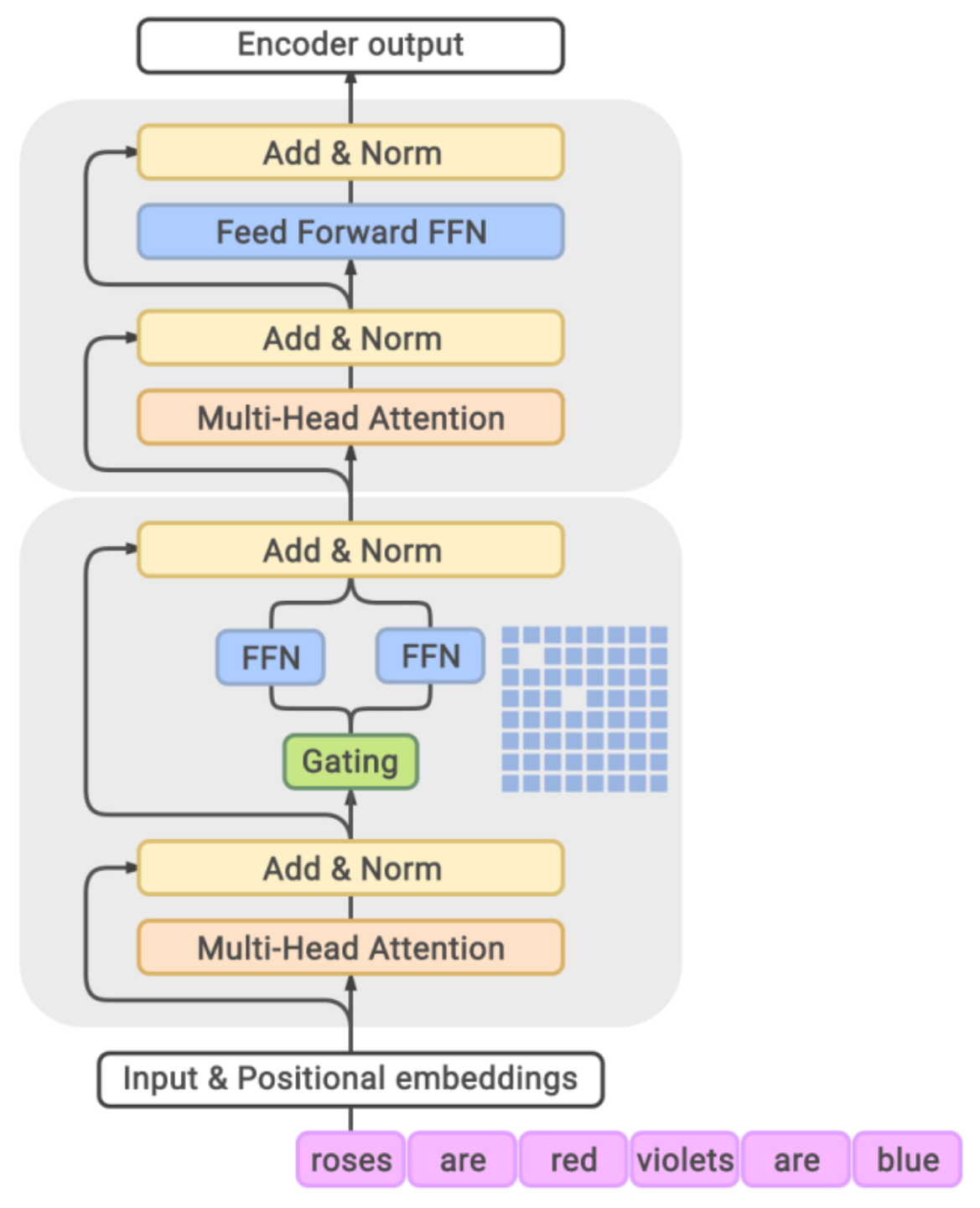
我们将top-2专家的近似门控函数定义如下:
-
计算第一个专家: e1=arg maxe ge(x) 。
-
计算第二个专家: e2=arg maxe≠e1 ge(x) 。
-
始终保留第一个专家,并随机保留第二个专家。
符号定义:
-
设 B 是一个batch中的token数量(在所有序列中);通常在百万数量级。
-
设 E 是专家数目;通常在千数量级。
-
设 x1,…,xB 为一个batch中的token。
下面是一个 B=2 个token, E=4 个专家的例子:
g(x1)=[0.2,0.6,0.1,0.1]⇒g~(x1)=[0.25,0.75,0,0]g(x2)=[0.1,0.6,0.2,0.1]⇒g~(x2)=[0,0.75,0.25,0]
4.1.3 Switch Transformer (Fedus et al. 2021)
-
定义近似门控函数 g~(x) 只有一个专家(获得更多稀疏性)。
-
技巧:
-
将FP32训练替换成FP16
-
使用的较小参数进行初始化
-
专家dropout
-
专家并行
-
-
训练了一个1.6万亿参数模型
-
与T5-XXL(110亿参数)相比,训练速度提高了4倍
4.1.4 Balanced Assignment of Sparse Experts (BASE) layers (Lewis et al., 2021)
-
BASE将近似门控函数 g~(x) 定义为对batch中的所有token进行联合优化的结果。
-
我们将为每个token分配1名专家,但负载平衡是一种约束,而不是软惩罚。
-
我们定义 a=[a1,…,aB]∈1,…,EB 作为联合分配向量。

-
这是一个可以有效求解的线性方程。
-
在实践中,我们将线性方程并行化。
-
在测试时,只需选择top 1的专家即可。
总结:
-
Switch Transformer(谷歌)使用了top-1专家。
-
BASE(Facebook)为每个token分配1名专家,但进行了联合优化。
-
这两个模型的性能都无法与GPT-3可比。虽然谷歌和Facebook都发布了两个最新的高性能MoE语言模型,它们的性能确实与GPT-可比,但有趣的是,它们仍然基于最初简单的top-2专家:
-
谷歌的GLaM
-
来自Facebook的“FacebookMoE”
-
4.1.5 Generalist Language Model (GLaM) (Du et al. 2021)
规格
-
1.2万亿个参数(GPT-3有1750亿个参数)
-
64个专家,64层,32K个隐藏单元
-
每个token激活95B(1.2T的8%)的参数
其他
-
创建了共有1.6万亿个token的新数据集(GLaM dataset),来源包括网页、论坛、书籍、新闻等。
-
相对位置编码、门控线性单元、GeLU激活函数、RMSNorm(非LayerNorm)
-
如果遇到NaN/Inf,跳过权重更新/回滚到早期检查点。
-
“通过仔细实施上述技巧,我们观察到,稀疏激活的模型在各个尺度上的训练都变得相当稳定。”
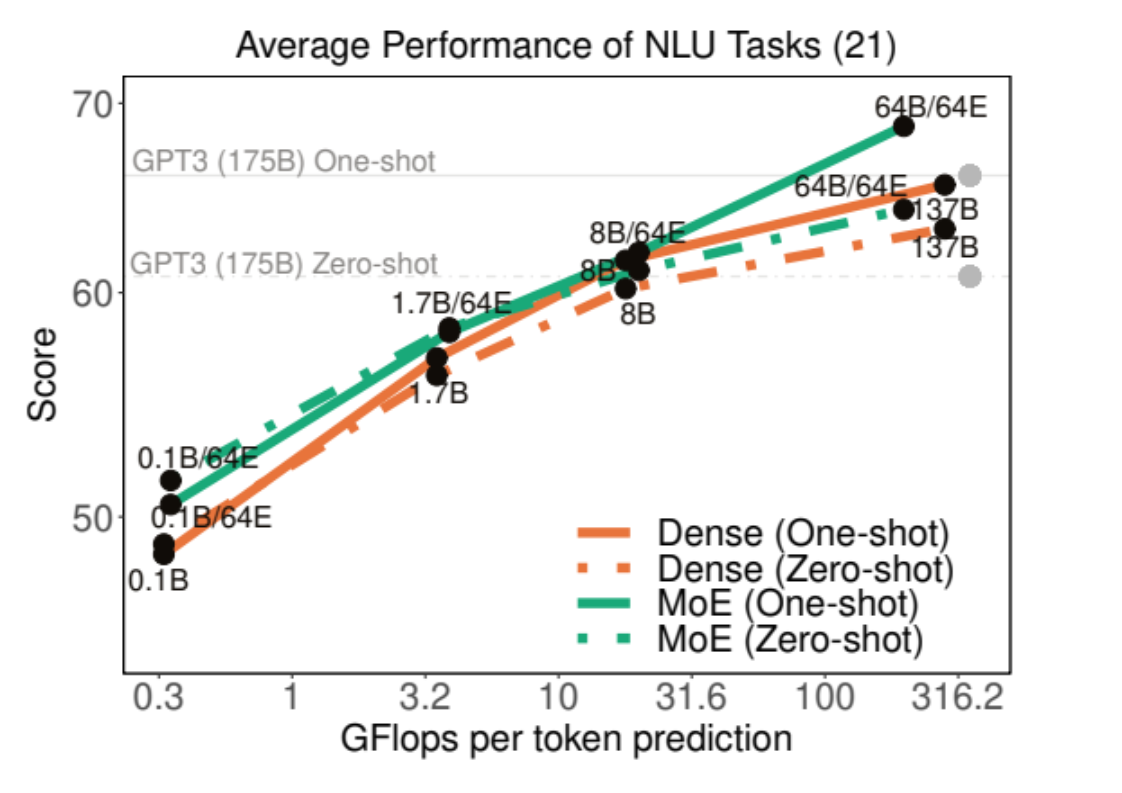
结果
-
与GPT-3相比,训练成本仅为1/3
-
在与GPT-3相同的基准上进行评估(开放域问答、阅读理解、SuperGLUE等)
-
与GPT-3相比,实现了更好的0-shot和1-shot性能(尤其是在知识密集型任务中的性能)
-
注:他们没有在GPT-3更强的few-shot中进行评估
4.1.6 FacebookMoE (Artetxe et al., 2021)
-
训练了一个1.1T参数的模型
-
512名专家(超过GLaM),32层,4096个隐藏单元
-
使用112 billion token进行训练,来源包括网页、论坛、书籍、新闻等。
-
小模型收益更大,模型越大,收益递减
4.1.7 Decentralized mixture-of-experts (Ryabinin & Gusev, 2020)
动机:
-
到目前为止,混合专家纯粹是中心机构(如谷歌或Facebook)从扩大大语言模型的角度出发的。
-
然而,混合专家自然地指示了一种更激进的权力下放。
-
为例训练GPT-3,Azure超级计算机集群耗资2.5亿美元。
-
我们如何利用数以亿计的消费PC?
-
Folding@Home是一个志愿者计算项目,利用世界各地的志愿者捐赠计算机进行分子动力学模拟。
-
2020年4月,Folding@Home有70万人捐赠了产生2.43 exaFLOP(GPT-3需要350千兆FLOP)(文章)。
-
主要区别在于分子动力学模拟计算量大,不需要网络带宽。
考虑因素:
-
节点众多( 103∼106 异构PC)
-
频繁的节点故障(5-20%的节点每天至少有一次故障)
-
家庭互联网通信带宽(100Mbps;相比之下,Azure超级计算机为400Gbps)
分布式哈希表:
-
N 个节点
-
单个节点需要与其他 O(logN) 节点通信
-
使用Kademlia DHT协议(被BitTorrent和以太网使用)
实验:
-
选取top-4的专家(共256名专家)
-
每个专家都是一个Transformer层
-
在4个GPU上训练了一个小型Transformer LM
4.1.8 Diskin et al., 2021
-
40名志愿者
-
为孟加拉语训练了一个ALBERT的掩码语言模型
-
一起训练Transformer:任何人都可以加入并贡献计算
4.1.9 总结
-
混合专家:起源于将不同专家应用于不同输入的经典理念
-
允许训练更大的语言模型(1.1万亿个参数)
-
与稠密Transformer模型相比,每个输入的效率高得多(FLOP更少)
-
效果难以比较:在相同规模上,直接比较仍然具有挑战性(GPT-3与GLaM与FacebookMoE)
-
对权力下放的重大影响
4.2 基于检索的模型
现在,我们转向另一类语言模型,基于检索的(或检索增强的、记忆增强的模型),它可以帮助我们突破稠密Transformer的缩放上限。
4.2.1 编码器-解码器
让我们首先关注使用编码器-解码器框架的序列到序列任务:
input x⇒output y
示例(开放问答):
-
输入x:What is the capital of Canada?
-
输出y:Ottawa
p(y∣x)
其使用去噪目标函数进行训练。 例如: 输入 x :Thank you me to your party week. 输出 y : for inviting last
4.2.2 检索方法
假设我们有一个存储库 S ,它是一组序列(通常是文档或段落)的集合。
S=Why is the...,Thanks for,...,The quick...,Stanford....
基于检索的模型直观的生成过程:
-
基于输入 x ,检索相关序列 z 。
-
给定检索序列 z 和输入 x ,生成输出 y 。
示例(开放问答):
-
输入 x :What is the capital of Canada?
-
检索 z :Ottawa is the capital city of Canada.
-
输出 y :Ottawa
最近邻是最常用的一种检索方法:
-
S 是训练集。
-
检索 (x′,y′)∈S ,使得 x′ 和 x最相似。
-
生成 y=y′ 。
4.2.3 Retrieval-augmented generation (RAG) (Lewis et al., 2020)
给定输入 x,生成输出 y 的概率可以通过对所有可能的检索文档 z 进行加权求和来计算。
p(z∣x)(Retriever,检索器): 给定输入 x,找到与 x 相关的检索文档 z,并计算其概率。
p(y∣z,x)(Generator,生成器): 给定输入 x 和检索到的文档 z,计算生成目标输出 y 的概率。
∑z∈S: 遍历所有可能的检索文档 S,加权计算最终的输出概率。
检索器:
Dense Passage Retrieval (DPR) (Karpukhin et al., 2020)
DPR(Dense Passage Retrieval)是一种基于双塔 BERT 模型的密集检索方法,主要用于高效检索与输入相关的文档段落。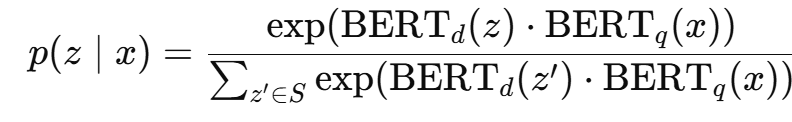
表示计算某个文档段落 z 相对于查询 xxx 的概率,核心思想是计算 query 和 document 之间的点积相似度(余弦相似度)。
训练数据通常由查询(query)和正/负例文档(passages) 组成:
-
查询 q:通常来自 QA 数据集,如 NaturalQuestions、TriviaQA 等。
-
正例 p+:包含正确答案的段落。
-
负例 p−:不包含答案的段落(可以是随机选择的,也可以用 BM25 选取)。
模型的目标是让 BERT 学习将查询 q 和正例 p+ 的向量靠近,而与负例 p− 拉远。
在推理(inference)时,我们需要在超大规模文档集合(如整个维基百科)中高效地检索出最相关的段落,这时就用到了 FAISS(Facebook AI Similarity Search)。FAISS 是一个高效的相似度搜索库,它允许在超大规模向量数据库(例如数百万甚至数十亿条向量)中进行快速近似最近邻(ANN, Approximate Nearest Neighbor)搜索
生成器:
p(y∣z,x)=p(y∣concat(z,x)).
-
使用BART-large(400M参数),其中输入为检索出的段落 z 和输入 x
-
回想一下,BART是基于网络、新闻、书籍和故事数据,使用去噪目标函数(例如,掩码)训练得到的。
4.2.4 RETRO (Borgeaud et al., 2021)
-
基于32个token的块进行检索
-
存储库:2 trillion tokens
-
70亿参数(比GPT-3少25倍)
-
使用冻结的BERT进行检索(不更新)
-
在MassiveText上训练(与训练Gopher的数据集相同)
4.3 讨论
-
基于检索的模型高度适合知识密集型的问答任务。
-
除了可扩展性之外,基于检索的模型还提供了可解释性和更新存储库的能力。
-
目前尚不清楚这些模型是否具有与稠密Transformer相同的通用能力。
-
为了扩大模型规模,需要改进稠密Transformer。
-
混合专家和基于检索的方法相结合更有效。
-
如何设计更好的、可扩展的体系结构仍然是一个悬而未决的问题。
第五章 大模型的数据
到目前为止,我们已经讨论了大型语言模型的行为(能力和损害)。现在,我们要剥开洋葱的第一层,开始讨论这些模型是如何构建的。任何机器学习方法的起点都是训练数据,因此这就是我们开始的地方。
5.1 大语言模型背后的数据
我们要清楚,大型语言模型是在"原始文本"上进行训练的。为了实现高度的能力(如语言和世界知识),这些文本应涵盖广泛的领域、类型、语言等。
网络是寻找这种文本的自然场所(但不是唯一场所),因此这将是我们主要关注的焦点。网络的体量绝对巨大。作为下限,谷歌的搜索索引就有100PB(参考资料)。实际的网络可能更大,而深网(指的是所有无法被搜索引擎识别的网页)的规模比这还要大。
值得注意的是,大公司中存储的私有数据集甚至比公开可用的数据更大。例如,沃尔玛每小时就会产生2.5PB的数据!
Common Crawl是一个非营利组织,它对网络进行爬取,并提供免费给公众的快照。由于其便利性,它已经成为许多模型如T5、GPT-3和Gopher的标准数据源。例如,Common Crawl在2021年4月的快照就有320TB的数据,这比谷歌的索引小了好几个数量级。
尽管网络数据丰富,但Bender等人在2021年的研究中指出:
-
大规模数据在全球人口中的代表性仍然不均衡。
-
网络数据过多地代表了来自发达国家的年轻用户。
-
GPT-2的训练数据基于Reddit,根据皮尤互联网研究的2016年调查,美国Reddit用户中有67%是男性,64%的年龄在18到29岁之间。
-
维基百科的编者中只有8.8-15%是女性。
-
网络上的骚扰可能会让某些人群(如跨性别者、神经发育不同的人)产生排斥感。
-
过滤"不良词汇"可能进一步边缘化某些人群(如LGBT+)。 因此,我们的结论是:理解和记录用于训练大型语言模型的数据集的组成是至关重要的。
5.1.1 WebText和OpenWebText数据集
WebText数据集被用于训练GPT-2模型。其目标是获取既多样化又高质量的数据集。以前的研究主要是在新闻、维基百科或小说等数据集上进行训练,而Common Crawl包含了大量的垃圾信息(如无意义文本和模板文本)。Trinh和Le在2018年根据n-gram与目标任务的重叠性,选择了Common Crawl的一小部分。创建WebText的过程包括:抓取至少获得3个赞的所有外链,过滤掉维基百科以便在基于维基百科的基准测试中进行评估,最终得到了40GB的文本。
尽管OpenAI并没有公开发布WebText数据集,但OpenWebText数据集在理念上复制了WebText的构建方法。也就是说,虽然OpenWebText并非OpenAI直接发布的WebText的副本,但它遵循了WebText的制作思路和方法,目的是尽可能地模拟和复现WebText的数据特性和结构。这样,研究者们就可以利用OpenWebText来进行一些原本需要WebText数据集的实验和研究。OpenWebText从Reddit提交的数据集中提取所有URL,使用Facebook的fastText过滤掉非英语内容,删除近乎重复的内容,最终得到了38GB的文本。
在2020年的RealToxicityPrompts研究中,Gehman等人对这两个数据集进行了毒性分析:OpenWebText有2.1%的内容毒性得分>=50%,WebText有4.3%的内容毒性得分>=50%。新闻的可靠性与毒性负相关(Spearman ρ=−0.35),并且OpenWebText中有3%的内容来自被禁止或被隔离的subreddits,如/r/The_Donald和/r/WhiteRights。
5.1.2 Colossal Clean Crawled Corpus(C4)
C4语料库被用来训练T5模型。这个语料库从2019年4月的Common Crawl快照(1.4万亿个标记)开始,移除了“bad words”,移除了代码(“{”),通过langdetect过滤掉了非英语文本,最终得到了806GB的文本(1560亿个标记)。
Dodge等人在2021年对C4数据集进行了深入分析。分析主要涉及以下几个方面:
-
元数据:来源,话语数据。
-
包含的数据:由机器或人类创作的,社会偏见,数据污染。
-
排除的数据:医疗或健康数据,人口身份。 值得注意的是,Raffel等人在2020年的研究中只提供了重建脚本;仅运行这些脚本就需要数千美元。而且,令人惊讶的是,大量数据来自patents.google.com。互联网档案中的65%页面都被纳入其中,而在这些页面中,92%的页面是在过去十年内编写的。然而,虽然美国托管的页面占到了51.3%,来自印度的页面数量却相对较少,尽管那里有大量的英语使用者。另外,来自patents.google.com的一些文本是自动生成的,因此可能存在系统性的错误:例如,用外国的官方语言(如日语)提交的专利将自动翻译成英语;另一些则是由光学字符识别(OCR)自动生成的。
5.1.3 Benchmark的数据污染问题
当我们评估大型语言模型的能力时,我们常常会使用一些基准数据,例如问题-答案对。然而,若基准数据在模型的训练数据中出现过,基准性能就可能会产生偏差。一般而言,在机器学习中,保证训练数据和测试数据的分离(我们称之为数据卫生)相对容易。但对于大型语言模型,训练数据和基准数据都源自互联网,要事先保证它们的完全分离就显得有些困难。
以XSum摘要数据集为例,输入的是一段关于一个前阿森纳门将的介绍,而输出则是这位门将被任命为技术主管的新闻,细节如下面的例子。这就存在两种类型的污染。一种是输入和输出污染,即输入和输出都出现在训练数据中,其比例在1.87%至24.88%之间。另一种是只有输入在训练数据中出现,比如来自维基百科的QNLI数据集,这种污染的比例在1.8%至53.6%之间。
此外,我们还要注意,这种数据污染并不是由于数据集的托管方式导致的,因为数据集通常会以JSON文件的形式存储,而不是网页。因此也可以说当前的数据污染是一种自身很难避免的特性。
但是,数据集也可能引发多种问题。首先,存在代表性损害的可能,例如,我们发现与特定族群相关的词汇(如"犹太"和"阿拉伯")与积极情绪词汇的共现频率存在差异,这可能反映了模型的某种偏见。其次,数据集的选择和过滤也可能导致分配损害。以过滤版的Common Crawl(即C4)为例,只有大约10%的内容被保留。然而,涉及性取向的内容更容易被过滤掉,而其中一部分是并无冒犯之意的。某些特定的方言也更容易被过滤,例如非洲裔美国人的英语和西班牙裔的英语,相比之下,白人美国英语的过滤率就要低得多。
5.1.4 GPT-3的数据集
GPT-3的数据集主要源自Common Crawl,而Common Crawl又类似于一个参考数据集——WebText。GPT-3下载了41个分片的Common Crawl数据(2016-2019年)。通过训练一个二元分类器来预测WebText与Common Crawl的区别,如果分类器认为文档更接近WebText,那么这个文档就有更大的概率被保留。在处理数据时,GPT-3采用了模糊去重的方法(检测13-gram重叠,如果在少于10个训练文档中出现,则移除窗口或文档),并从基准数据集中移除了数据。此外,GPT-3也扩大了数据来源的多样性(包括WebText2、Books1、Books2以及维基百科)。在训练过程中,Common Crawl被降采样,它在数据集中占82%,但只贡献了60%的数据。
然而,GPT-3也暗示了我们除了网络爬虫之外,也许还可以寻找其他更高质量的数据来源。EleutherAI(一个致力于构建开放语言模型的非营利组织)进一步推动了这个想法。他们发布了一种语言模型的数据集,名为The Pile,其核心理念是从较小的高质量数据源(如学术和专业资源)中获取数据。
5.1.5 The Pile数据集
The Pile数据集包含了825GB的英文文本,由22个高质量数据集组成。当用这个数据集训练GPT-2Pile(1.5B参数)并与用GPT-3数据集训练的GPT-3(175B参数)进行比较时,研究者们发现,The Pile包含了大量GPT-3数据集未能很好覆盖的信息。他们还分析了贬损内容、性别/宗教偏见等问题,结果与以前的研究大致相同。
总的来说,网络和私有数据的总量是巨大的,但是简单地将所有数据(甚至是Common Crawl)都用于训练并不能有效地利用计算资源。数据的过滤和策划(如OpenWebText,C4,GPT-3数据集)是必要的,但可能会导致偏见。策划非网络的高质量数据集(如The Pile)是有前途的,但也需要仔细记录和审查这些数据集。
5.1.6 数据集文档
在本文中,我们将深入探讨数据的一般原则,暂时不讨论语言模型数据集的具体内容。长期以来,人们都明白文档记录的重要性,然而在机器学习领域,这个过程往往被处理得较为随意。为了更好地理解这一点,让我们来看一些其他领域的例子:在电子行业中,每个组件都有一份详细的数据表,包含其运行特性、测试结果、推荐使用情况等信息;又如美国食品药品监督管理局要求所有的食品都必须标注营养成分。Gebru等人在2018年发表的论文深刻影响了这一领域,他们提出了围绕文档的社区规范。Bender和Friedman在2018年的论文《数据声明》也提出了一个更适用于语言数据集的框架,这两个工作都在强调透明度。
数据文档的主要目的有两个:一方面,它让数据集的创建者有机会反思他们的决策,以及在创建数据集过程中可能产生的潜在危害,比如社会偏见;另一方面,它让数据集的使用者了解何时可以使用数据集,何时不应使用数据集。
在整个数据集的生命周期中,我们需要考虑很多问题,比如数据集的创建动机,谁是数据集的创建者,数据集的创建是由谁资助的。在数据集的组成部分,我们需要了解数据集中的实例代表什么,是否有缺失信息,是否包含机密数据等。在收集过程中,我们需要了解每个实例的数据是如何获取的,谁参与了数据收集,他们是如何获得报酬的,以及是否进行了道德审查等。在预处理、清理和标记阶段,我们需要了解这些工作是否已经完成,是否有相应的软件可供使用。在数据集的使用方面,我们需要了解数据集是否已经被用于某些任务,是否有不适合使用该数据集的任务。在分发阶段,我们需要了解数据集将如何分发,是否有第三方对数据施加了知识产权或其他的限制。在维护阶段,我们需要了解谁会负责维护数据集,数据集是否会更新。
专门针对自然语言处理(NLP)数据集的工作,比如数据声明,还涵盖了其他方面,例如策划理念,语言多样性,说话人和注释者的人口统计学信息等。以"The Pile"数据集为例,我们可以更好地理解这些问题。
5.1.7 数据生态
目前为止,我们主要关注了现有大型语言模型数据集的分析以及文档记录,但实际上数据是一个广泛的概念,可以从许多其他角度进行研究。
在数据管理方面,我们在机器学习研究中通常认为数据集是固定的对象,收集起来之后,直接投入到训练算法中。然而在数据库领域,有一整个子领域正在思考数据是如何产生和使用的生态系统,这在工业领域特别相关。
在基础模型报告的数据部分中讨论了一些问题。数据治理主要关注一个组织如何创建数据、维护其质量和安全性。Hugging Face发起的BigScience项目旨在收集一个大型多语种数据集并训练一个大型语言模型。BigScience的数据治理工作组正在开发一个框架,以负责任地策划高质量的数据源,而不是无差别地爬取网页。
数据尊严是一个源自微软和RadicalxChange的概念,试图思考数据的本质。人们创造数据,由于人们生活在社会环境中,数据也并不仅仅是个体的财产,而是群体的财产。比如电子邮件、遗传数据。在个体层面上,数据没有价值,但在集体层面上,它具有巨大的价值。相关的有一个为在机器学习的背景下给定数据点赋予价值的框架Data Shapley。现状是,人们免费放弃他们的数据,大公司从中获取大量的价值和权力。例如,Alice和Bob都是作家。Alice免费提供写作示例,这可以被用来训练可以替代Bob的语言模型。我们应该将数据视为劳动而不是财产权。数据隐私是在个人层面上工作,而这是不够的。有一种提议是数据联盟,这些联盟是介于数据生产者和数据购买者之间的中间组织,它们能够代表数据生产者进行集体谈判。更多详情请阅读这篇文章。
第六章 模型训练
上一章中,我们讨论了大语言模型(例如,Transformer)的模型结构。 在本章中,我们将讨论如何训练大语言模型。 本章分成目标函数和优化算法两部分。
6.1 目标函数
我们研究三类语言模型的目标函数:
-
只包含解码器(Decoder-only)的模型(例如,GPT-3):计算单向上下文嵌入(contextual embeddings),一次生成一个token
-
只包含编码器(Encoder-only)的模型(例如,BERT):计算双向上下文嵌入
-
编码器解码器(Encoder-decoder)模型(例如,T5):编码输入,解码输出
我们可以使用任何模型将token序列映射到上下文嵌入中(例如,LSTM、Transformers):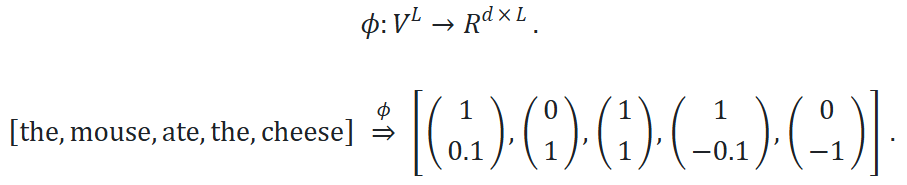
6.1.1 Decoder-only 模型
回想一下,自回归语言模型定义了一个条件分布:
p(xi∣x1:i−1).
这个过程可以拆解成三个步骤:(假设我们正在训练一个语言模型,它已经看到了一段文本:
The cat sat on the
现在模型需要预测下一个单词(比如 "mat")。)
(1) 计算上下文嵌入(经过 Transformer 计算,模型会输出一个向量 ϕ(x1:i) 代表 "The cat sat on the" 的语义信息。)
ϕ(x1:i)=Transformer(x1:i)
这里的 ϕ(x1:i) 是 Transformer 计算出的上下文向量,即对输入的 token x1,x2,...,xi 进行编码,得到每个 token 的表示(embedding)。
(2) 计算得分(logits)(用词嵌入矩阵 EEE 计算每个可能的单词的得分,例如:
arduinoCopyEditp("mat") = 8.2
p("dog") = 4.1
p("table") = 2.7
p("car") = 1.3
)
Eϕ(x1:i)i
EEE 是词嵌入矩阵,其形状为 RV×d,其中:
-
V 是词汇表大小(vocabulary size)。
-
d 是嵌入维度(embedding dimension)。
计算 Eϕ(x1:i)i 后,我们得到了一个形状为 V 的向量,它表示每个可能的下一个 token 的得分(logits)。
(3) 计算概率分布()
-
-
softmax 之后,我们得到:
arduinoCopyEditp("mat") = 0.75 p("dog") = 0.15 p("table") = 0.07 p("car") = 0.03 -
最高概率的是 "mat",所以预测的下一个 token 是 "mat"。
-
p(xi+1∣x1:i)=softmax(Eϕ(x1:i)i)
对得分向量进行 softmax 归一化,得到每个单词作为 xi+1 的概率。
最高概率的单词可以作为预测的下一个 token。
最大似然
设 θ 是大语言模型的所有参数。设 D 是由一组序列组成的训练数据。 然后,我们可以遵循最大似然原理,定义以下负对数似然目标函数: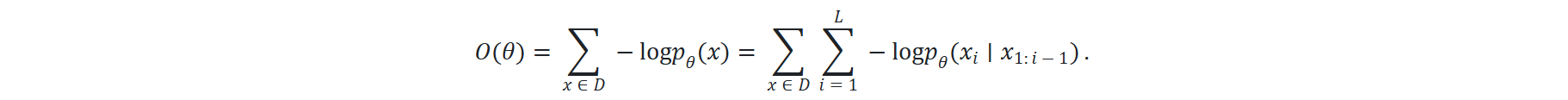
并且,有很多的方法可以有效地优化这一目标函数。
在 NLP 任务中,给定训练数据集 D={x(1),x(2),...,x(N)},其中每个 x(i) 是一个文本序列,我们希望找到模型参数 θ,使得模型分布 pθ(x) 能够尽可能接近真实数据分布。
6.1.2 Encoder-only 模型
单向到双向
使用上述最大似然可以训练得到Decoder-only模型,它会产生(单向)上下文嵌入。但如果我们不需要生成,我们可以提供更强的双向上下文嵌入。
BERT
我们首先介绍BERT的目标函数,它包含以下两个部分:
-
掩码语言模型(Masked language modeling)
-
下一句预测(Next sentence prediction)
以自然语言推理(预测隐含、矛盾或中性)任务中的序列为例:
x1:L=[[CLS],all,animals,breathe,[SEP],cats,breathe].
其中有两个特殊的token:
-
[CLS] :包含用于驱动分类任务的嵌入
-
[SEP] :用于告诉模型第一个序列(例如,前提)与第二个序列(例如,假设)的位置。
根据上一章的公式,BERT模型定义为:
BERT(x1:L)=TransformerBlock24(EmbedTokenWithPosition(x1:L)+SentenceEmbedding(x1:L))∈Rd×L,
其中, SentenceEmbedding(x1:L) 根据序列返回以下两个矢量之一
-
对于 [SEP] 左边的,返回 eA∈Rd
-
对于 [SEP] 右边的,返回 eB∈Rd
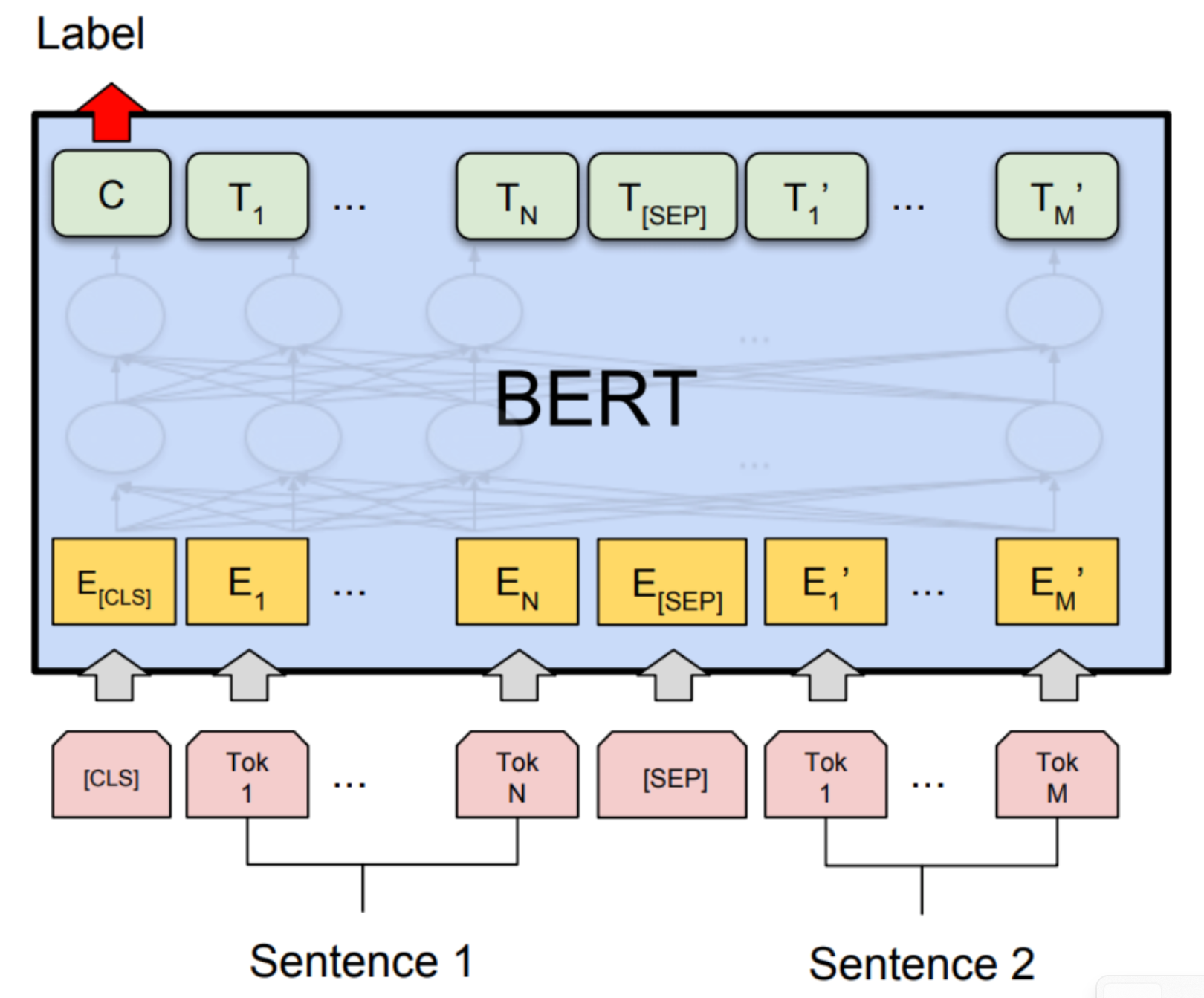
BERT-large有 nheads=16 个注意头,并且 dmodel=1024 ,总共355M个参数。
掩码语言模型
MLM 的核心思想是:
-
随机隐藏(mask)部分输入文本的 token,让模型去预测被隐藏的部分。
-
训练目标是最大化正确恢复被 mask 掉的 token 的概率。
例如:
原句子: the mouse ate the cheese 输入序列: the [MASK] ate [MASK] cheese 目标输出: the mouse ate the cheese
模型的目标是:根据上下文预测被 mask 掉的单词。
MLM 的过程可以类比于 去噪自动编码器(Denoising Autoencoder, DAE):
-
输入:有噪声的文本(部分 token 被掩码)
-
输出:原始文本(恢复被掩码的 token)
这个过程可以表示为:
x1,x2,...,xL⇒x~1,x~2,...,x~L
其中 x~i 是经过随机掩码的文本。
BERT 通过学习如何从有噪声的数据恢复完整句子,来训练自己理解语言的深层语义关系。
给定输入序列 x1,x2,...,xL我们定义一个噪声函数 A 来随机掩码部分 token:
-
随机选择 15% 的 token 进行替换,令 I 代表这些被选中的 token 的索引。
-
对每个选中的 token 进行如下操作:
-
80% 概率:用
[MASK]替换,例如:the cat sat → the [MASK] sat
-
10% 概率:用一个随机单词替换,例如:
the cat sat → the dog sat
-
10% 概率:保持原样不变,例如:
the cat sat → the cat sat
-
这个设计的目的是:
-
大部分时间模型都学会填充
[MASK],以便在推理时能正确预测。 -
少量时间遇到真实单词或随机单词,让模型不会只依赖
[MASK]这个特殊 token,提高泛化能力。
(1)训练时
在 BERT 训练时:
-
输入数据大部分都带有
[MASK],模型学会填充[MASK]。 -
但在实际使用(推理)时,我们不会输入
[MASK],而是输入完整的句子。
(2)测试时的分布偏移
如果训练时始终使用 [MASK] 进行掩码,而推理时输入的是完整句子,可能会导致模型在实际使用时表现不佳。 原因:训练数据的分布和测试时不匹配(distribution shift)。
(3)解决方案:减少 [MASK] 依赖
为了减轻这种偏移,BERT 训练时做了一个小优化:
-
20% 的情况下,使用原始单词而不是
[MASK]。 -
这样,模型不仅能学会填充
[MASK],还能够适应正常文本的分布,提高泛化能力。
既然掩码会影响泛化性 为什么还要掩码呢?
自回归模型(如 GPT):只根据前面的词预测下一个词,无法利用双向信息。掩码语言模型(MLM,如 BERT):可以利用上下文两侧的信息,即 双向编码。
下一句预测
在 BERT 训练过程中,除了 掩码语言模型(MLM),BERT 还会学习一个额外的任务——预测两个句子是否是连续的。
[[CLS],the,mouse,ate,the,cheese,[SEP],it,was,full]⇒1.
[[CLS],the,mouse,ate,the,cheese,[SEP],hello,world]⇒0.
然后使用 [CLS] 的嵌入来做二分类。
D 是按如下方式构造的一组样本 (x1:L,c) :
-
令 A 是语料库中的一个句子。
-
以0.5的概率, B 是下一句话。
-
以0.5的概率, B 是语料库中的一个随机句子。
-
令 x1:L=[[CLS],A,[SEP],B]
-
令 c 表示 B 是否是下一句。
-
BERT(以及ELMo和ULMFiT)表明,一个统一的体系结构(Transformer)可以用于多个分类任务。
-
BERT真正将NLP社区转变为预训练+微调的范式。
-
BERT显示了深度双向上下文嵌入的重要性,尽管通过模型大小和微调策略可能会弥补这一点(p-tuning)。
RoBERTa对BERT进行了以下改进:
-
删除了下一句预测这一目标函数(发现它没有帮助)。
-
使用更多数据训练(16GB文本 ⇒ 160GB文本 )。
-
训练时间更长。
-
RoBERTa在各种基准上显著提高了BERT的准确性(例如,在SQuAD上由81.8到89.4)。
6.1.3 Encoder-decoder 模型
任务示例(表格生成文本):
[name,:,Clowns,|,eatType,:,coffee,shop]Rightarrow[Clowns,is,a,coffee,shop].
回想一下编码器-解码器模型(例如,BART、T5):
-
首先像BERT一样对输入进行双向编码。
-
然后像GPT-2一样对输出进行自回归解码。
BART (Lewis et al. 2019)是基于Transformer的编码器-解码器模型。
-
使用与RoBERTa相同的编码器架构(12层,隐藏维度1024)。
-
使用与RoBERTa相同的数据进行训练(160GB文本)。
基于BERT的实验,最终模型进行以下了变换:
-
掩码文档中30%的token
-
将所有子句打乱
最后,通过微调,BART在分类和生成任务上都展示了强大的效果。
T5 (Raffel et al., 2020)是另一种基于Transformer的编码器-解码器模型。
预训练任务: 给定一段文本,在随机位置将其分割为输入和输出:
[the,mouse]⇒[ate,the,cheese].
论文尝试了许多不同的无监督目标:
论文还将所有经典的NLP任务放在一个统一的框架中,称为“Text-to-Text”任务:
以分类任务任务为例,不同模型的差异如下:
-
BERT使用 [CLS] 的嵌入来预测。
-
T5、GPT-2、GPT-3等(生成模型)将分类任务转换成自然语言生成。
注意:
-
论文对整个pipline的许多方面(数据集、模型大小、训练目标等)进行了深入研究。
-
基于这些见解,他们训练了一个11B的模型。
6.2 优化算法
现在,我们将注意力转向如何优化目标函数。
为了简单起见,让我们以自回归语言模型为例。
6.2.1 随机梯度下降(SGD)
最简单的优化算法是用小批量进行随机梯度下降,该算法的步骤如下:
-
初始化参数 θ0
-
重复以下步骤:
-
采样小批量 Bt⊂D
-
根据梯度更新参数:
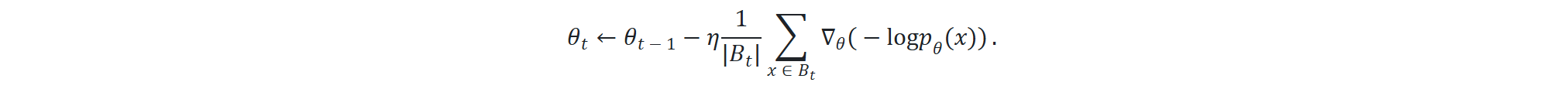
优化的关键点包括:
-
我们希望参数 θ 可以快速收敛
-
我们希望优化在数值上是稳定的
-
我们希望内存高效(尤其是对于大模型)
这些点往往相互矛盾(例如,通过低精度训练,可以实现快速收敛、减少内存占用,但是会导致训练不稳定)
因此,我们可以从几个层次来进行优化:
-
针对经典优化:二阶方法、约束优化等。
-
针对机器学习:随机方法、隐式正则化+早停法
-
针对深度学习:初始化、归一化(更改模型架构)
-
针对大语言模型:由于稳定性问题,学习率和一些直觉(例如,二阶方法)仍然有用,但要使大语言模型有效训练,还需要克服许多其他独特的挑战。不幸的是,其中大部分内容都是特别的,人们对此了解甚少。
-
6.2.2 Adam (adaptive moment estimation)
Adam算法拥有以下两个创新:
-
引入动量(继续朝同一方向移动)。
-
参数 θ0 的每个维度都有一个自适应(不同)的步长(受二阶方法启发)。
它的步骤如下:
-
初始化参数 θ0
-
初始化动量 m0,v0←0
-
重复以下步骤:
-
采样小批量 Bt⊂D
-
按照如下步骤更新参数:
-
计算梯度
-
-
gt←1|Bt|∑x∈Bt∇θ(−logpθ(x)).
- 更新一阶、二阶动量
mt←β1mt−1+(1−β1)gt
vt←β2vt−1+(1−β2)gt2
- 对偏差进行修正
m^t←mt/(1−β1t)
v^t←vt/(1−β2t)
- 更新参数
θt←θt−1−η,m^t/(v^t+ϵ).
存储占用分析:
Adam将存储从2倍的模型参数( θt,gt )增加到了4倍( θt,gt,mt,vt )。
6.2.3 AdaFactor
AdaFactor是一种为减少存储占用的优化算法。它有如下特点:
-
它不储存 mt,vt 这样的 O(m×n) 矩阵,而是存储行和列的和 O(m+n) 并重构矩阵
-
去除动量
-
它被用来训练T5
-
AdaFactor可能使训练变得困难(见Twitter thread和blog post)
6.2.4 混合精度训练
混合精度训练是另一种减少存储的方法
-
通常来说,默认的精度是:FP32(32位浮点)
-
其他可选精度:FP16(16位浮点),但问题是任何小于 2−24 的值都会变为0。
-
解决方案:将主权重存储在FP32中,并在FP16中执行其他所有操作。
-
损失缩放:按比例放大损失,以避免梯度数值太小。
-
结果:存储减少了一半。
6.2.5 学习率
-
通常情况下,学习率会随着时间的推移而衰减。
-
对于Transformer模型,我们实际上需要通过预热(warmup)提高学习率。
-
Huang et al., 2020表明,一个潜在的原因是防止层归一化的梯度消失,导致使用Adam优化器训练时不稳定。
6.2.6 初始化
-
给定矩阵 W∈Rm×n ,标准初始化(即,xavier初始化)为 Wij∼N(0,1/n) 。
-
GPT-2和GPT-3通过额外的 1/N 缩放权重,其中 N 是残差层的数量。
-
T5将注意力矩阵增加一个 1/d (代码)。
以GPT-3为例,使用的参数如下:
-
Adam参数: β1=0.9,β2=0.95,ϵ=10−8
-
批量小:320万个token(约1500个序列)
-
使用梯度剪裁( gt←gt/min(1,|g|2) )
-
线性学习率预热(前3.75亿个token)
-
余弦学习率衰减到10%
-
逐渐增加批大小
-
权重衰减设为0.1
第七章 大模型之Adaptation
使用语言模型(例如在上下文学习中)通过仅给出提示,我们已经能够执行一些任务。然而,提示方法并不适用于全部的下游任务,如自然语言推理(NLI)、问题回答(QA)、将网络表格转换为文本、解析电子健康记录(EHR)等。
下游任务与语言模型的训练数据(例如,Pile数据集)可能在格式和主题上有所不同,或者需要随时间更新新知识。因此,语言模型需要使用特定于任务的数据或领域知识来针对下游任务进行适配。
7.1 引言
在自动化和人工智能的时代,语言模型已成为一个迅速发展的领域。这些模型被训练为对各种各样的任务作出响应,但它们真的适合所有的任务吗?在探讨这一问题之前,我们需要理解语言模型如何被训练,并明确下游任务与原始训练任务之间可能存在的不同之处。
从语言模型的训练方式来说,语言模型,例如GPT-3,通常是任务不可知(task-agnostic)- task-agnostic这个词组用于描述一种不针对任何特定任务进行优化的方法或模型。在机器学习和人工智能的背景下,task-agnostic通常指的是一种可以在多个不同任务上运行,而不需要对每个单独任务进行特别调整或训练的方法。例如,一个task-agnostic的语言模型在训练时不会专门针对特定任务进行优化,例如情感分析、文本摘要或问题回答。相反,它被设计为能够捕捉到语言的通用特性和结构,以便可以用于许多不同的下游任务。这种方法的优点是灵活性和广泛适用性,因为相同的模型可以用于各种各样的应用。然而,它也可能带来挑战,因为通用模型可能在特定任务上不如专门为该任务训练的模型表现出色。这就引出了如何将task-agnostic的模型适应特定任务的需求,以便在不同的应用场景中实现最佳性能。这意味着它们在一个广泛的领域内进行训练,而不是针对特定任务。这种方法的优点在于模型具有广泛的适用性,但也带来了一些挑战。比如下游任务的多样性,不同的下游任务与语言模型的预训练方式可以非常不同,这可能导致问题。例如,自然语言推理(NLI)任务与Pile数据集上的语言建模任务可能完全不同。考虑以下例子:
- **Premise**: I have never seen an apple that is not red. - **Hypothesis**: I have never seen an apple. - **Correct output**: Not entailment (the reverse direction would be entailment)
这种格式对模型来说可能并不自然,因为它远离了模型的训练范围。
另外在处理下游任务时,与原始训练任务之间的差异可能造成一些挑战。这些不同之处可以从以下几个方面进行详细探讨:
1.格式的不同(要的内容格式不一致):
-
自然语言推理(NLI): 下游任务如NLI涉及两个句子的比较以产生单一的二进制输出。这与语言模型通常用于生成下一个标记或填充MASK标记的任务截然不同。例如,NLI的逻辑推理过程涉及多层次的比较和理解,而不仅仅是根据给定的上下文生成下一个可能的词。
-
BERT训练与MASK标记: BERT训练过程中使用了MASK标记,而许多下游任务可能并不使用这些标记。这种不同可能导致在针对具体任务时需要对模型进行显著的调整。
2.主题转变(要的内容领域不一致):
-
特定领域的需求: 下游任务可能集中在特定的主题或领域上,例如医疗记录分析或法律文档解析。这些任务可能涉及专门的术语和知识,与模型的通用训练任务相去甚远。
-
广泛主题的灵活性: 语言模型可能需要处理各种不同的主题。如果下游任务突然聚焦在一个新的或非常独特的领域上,这可能会超出模型的训练范围。
3.时间转变(要的内容需要更新知识):
-
新知识的需求: 随着时间的推移,新的信息和知识不断涌现。例如,GPT-3在拜登成为总统之前就已训练完毕,因此可能缺乏有关他总统任期的最新信息。
-
非公开信息的需求: 有时下游任务可能涉及在训练期间不公开的信息。这可能需要更多特定领域的专业知识和调整。
因此可以总结一下”为什么需要语言模型的Adaptation?“,下游任务与语言模型的训练任务之间的不同之处非常复杂。这些差异可以从格式、主题和时间三个方面来探讨,每个方面都可能涉及许多具体的挑战和需求。通过深入了解这些不同之处,我们可以更好地理解如何有效地适配语言模型以满足各种下游任务的需求。
下面提供使用预训练语言模型(LM)的参数来适配(adapt)下游任务的一般设置。下面我将这个过程分为相关且逐渐递进的各个部分:
-
预训练语言模型(Pre-trained LM): 在适配阶段的开始,我们已经有了一个预训练的语言模型,用参数θLM表示。这个模型被训练来理解和生成语言,但不是特别针对任何特定任务。(训练好的模型)
-
下游任务数据集(Downstream Task Dataset): 我们获得了一组来自下游任务分布P_task的样本数据。这些数据可以是文本分类、情感分析等任务的特定实例,每个样本由输入x和目标输出y组成。(目标任务数据集)
-
适配参数(Adaptation Parameters): 为了使预训练的LM适合特定的下游任务,我们需要找到一组参数gamma,这组参数可以来自现有参数的子集或引入的新的参数,gamma。这些参数将用于调整模型,以便它在特定任务上的表现更好。(调整的参数可以已有的也可以新加入)
-
任务损失函数(Task Loss Function): 我们需要定义一个损失函数ell_task来衡量模型在下游任务上的表现。例如,交叉熵损失是一种常见的选择,用于衡量模型预测的概率分布与真实分布之间的差异。(下游任务的适配性损失函数)
-
优化问题(Optimization Problem): 我们的目标是找到一组适配参数gamma_adapt,使得任务损失在整个下游数据集上最小化。数学上,这可以通过以下优化问题表示。(优化获得适配参数最小化损失函数)
通过这个过程,我们可以取得一组适配参数gamma_adapt,用于参数化适配后的模型p_adapt。这样,我们就可以将通用的、任务无关的预训练语言模型适配到特定的下游任务上,以实现更好的性能。这种适配方法将模型的通用性与特定任务的效能结合在一起,既保留了模型的灵活性,又确保了在特定任务上的高效表现。
7.2 当前主流的几种Adaptation方法
7.2.1 Probing
Probing(探针)策略是大规模预训练阶段就已经广泛使用的一种微调策略,这一小节将讨论探测(Probing)策略的引入及其应用,同时探讨固定长度表示的策略。
Probing是一种分析和理解模型内部表示的技术。它引入了一个新的参数集Gamma,用于定义Probing,这些Probing通常是线性的或浅前馈网络。通过Probing方法,我们可以检查和理解模型的表示。例如,如果一个简单的探针可以预测词性标注(POS),那么这些表示就“存储”了POS信息。
探测主要适用于仅编码器模型(例如,BERT),但解码器模型也可以使用(Liu et al. 2021)。对于Adaptation来说,我们从语言模型(LM)的最后一层表示中训练一个Probing(或预测头)到输出(例如,类标签),整体的形式如下图所示: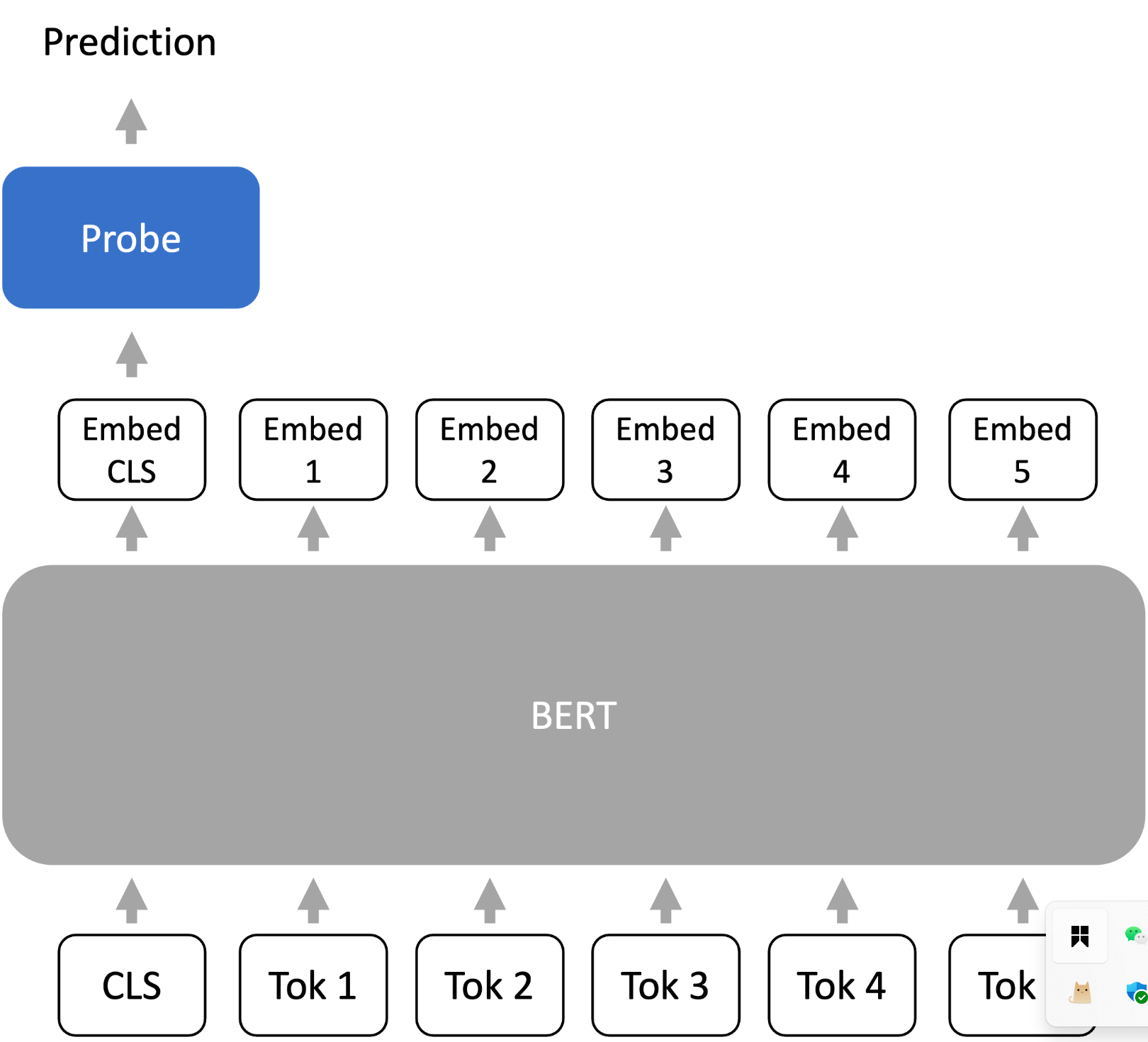
我们可以发现Probing方法是通过线性的或浅前馈网络来学习预训练模型的输出,并获得分析和理解模型内容表示的能力,从而在下游任务中取得不错的表现。值得一提的是,Probing方法对于预训练模型本身的权重是固定的,只对参数量很少的线性的或浅前馈网络进行训练,因此符合Adaptation,大大的减缓训练成本。
探测作为一种强大的分析工具,通过冻结语言模型表示编码器(上图中灰色部分)和优化特定任务的探针(上图中预测头,蓝色部分)来工作。这些模型可以是线性的或浅前馈预测头,提供了一种灵活的方法来理解和解释深度学习模型的内部工作机制。固定长度表示的策略也进一步促进了这一目的,提供了灵活而有效的解决方案。
7.2.2 Fine-tuning
Fine-tuning(微调)使用语言模型参数θLM作为优化的初始化。其中,优化后的参数家族Gamma包括了所有的语言模型参数和任务特定的预测头参数。与此同时,预训练的优化器状态被丢弃。
在微调过程中,通常至少使用比预训练时小一个数量级的学习速率,而且微调的时长远远少于预训练。这意味着需要存储针对每个下游任务专门化的大型语言模型,这可能相当昂贵。然而,微调是在更大的模型家族(即,非常具有表现力)上进行优化的,并且通常比探针有更好的性能。
zero-shot learning(零样本学习)是一种机器学习范式,在训练阶段没有见过的任务或类别上进行泛化的能力。它允许模型在没有任何具体示例的情况下解释和处理全新的信息。这个能力对于许多实际应用至关重要,特别是当新任务或类别的样本难以获得时。
零样本学习的能力使得模型具有更高的灵活性和泛化能力,能够在未见过的任务上迅速适应。这在现实世界中极为重要,因为我们常常会遇到一些新的、未在训练数据中出现过的任务或情境。零样本学习模型可以迅速解决这些问题,而无需每次都进行繁琐的重新训练。
针对零样本性能的微调是对现有模型的进一步优化,可以提高模型在未见过的任务上的表现。以下是经过微调后对零样本性能的影响:
-
模型调整:技术如FLAN和T0微调模型以获得更好的零样本性能。它们通过统一许多下游任务的prompt format(提示格式),并根据此格式微调模型来执行各种各样的任务。
-
性能提升:与原始语言模型相比,未见任务的零样本性能得到了显著提高。这表明微调可以有效地改善模型的泛化能力。
-
学习新技能:模型正在学习使用提示格式来执行零样本任务。这样的提示格式有助于引导模型理解和完成全新的任务,从而实现了真正的零样本学习。
在当前的LLMs中,指令(instructions)常常作为输入提示(prompt),来引导模型产生特定类型的输出。有效的指令可以让模型更好地理解人类用户的需求,并产生有用、诚实、无害的反馈,LLMs带来的有害性参考之前学习内容。人类反馈是指从人类用户或评估者收集的反馈,以评价模型的输出是否符合人们的期望和需求。人类反馈在模型的训练和微调中起着关键作用。
微调的目的是使得模型更好地遵循人类的期望和价值观,减少有害输出,并提高任务的有效性。
三个步骤:
(1)收集人类书写的示范行为:
-
目标:收集符合人类期望的示例,确保模型学到人类写作风格和行为。
-
过程:通过人工标注,收集并整理出符合期望的语言输出示例。这些示例会作为监督学习的基础,指导模型学习如何产生人类所期望的输出。
(2)基于指令的采样与人类偏好:
-
目标:根据模型生成的输出,收集人类的反馈来进一步指导模型的优化。
-
过程:
-
对每个给定的指令,模型从第一步的训练中采样多个输出(例如,采样k个不同的回答)。
-
然后,收集人类的反馈,判断哪一个输出更符合人类的偏好和期望。
-
相比步骤1,这个过程的数据收集成本较低,因为人类的反馈不需要像步骤1那样手工标注。
-
(3)使用强化学习目标微调LM:
-
目标:通过强化学习优化模型输出,使得模型能在生成过程中最大化符合人类偏好的输出。
-
过程:在这个阶段,模型利用强化学习算法根据人类反馈(偏好奖励)来调整权重,从而生成更符合人类目标的输出。(优化模型参数)
经过这样的微调,1.3B的InstructGPT模型在85%的时间里被优先于175B的GPT-3,使用少样本提示时为71%。在封闭领域的问答/摘要方面,InstructGPT 21%的时间会产生虚构信息,相比GPT-3的41%有所改善。在被提示要尊重时,InstructGPT比GPT-3减少了25%的有毒输出。
微调是一种强大的工具,可以使预先训练的语言模型更好地符合人类的期望和需求。通过监督学习、人类反馈和强化学习等手段,可以显著提高模型在特定任务和场景下的性能。然而,仍需关注并解决某些方面的挑战,如偏见和虚构信息的产生,以确保语言模型的安全和可靠使用。虽然有一些挑战和限制,但微调仍然是现代机器学习中一种非常有力的工具。
7.2.3 Lightweight Fine-tuning
轻量级微调(Lightweight Fine-Tuning)是一种特殊的微调技术,旨在结合全面微调的表现力和更节省资源的优点。轻量级微调试图在不需要为每个任务存储完整语言模型的同时,保持与全面微调相同的表现力。换句话说,它希望在减小模型存储需求和计算负担的同时,仍然实现出色的性能。
轻量级微调的变体
轻量级微调有许多变体,其中一些主要的方法包括:
-
提示调整(Prompt Tuning):通过微调模型的输入prompt提示来优化模型的表现。提示调整可以被视为一种更灵活的微调方法,允许用户通过调整输入提示来导向模型的输出,而不是直接修改模型参数。
-
前缀调整(Prefix Tuning):与提示调整类似,前缀调整也集中在输入部分。它通过添加特定前缀来调整模型的行为,从而对特定任务进行定制。
-
适配器调整(Adapter Tuning):适配器调整是通过在模型的隐藏层之间插入可训练的“适配器”模块来微调模型的一种方法。这些适配器模块允许模型在不改变原始预训练参数的情况下进行微调,从而降低了存储和计算的需求。
Prompt Tuning
提示调整(Prompt Tuning)是一种特殊的微调技术,主要用于文本分类任务。Prompt Tuning的灵感来源于推理为基础的自适应提示设计/工程。与传统的微调方法不同,提示调整专注于优化输入提示,而不是改变模型的内部参数。
Prompt Tuning通过在输入前添加k个可学习的、连续的标记嵌入(定义为Γ)来工作。因此,新的输入长度现在为L' = L + k,其中L是原始输入的长度。这些额外的标记嵌入通过在带标签的任务数据上进行训练来学习。
与此同时,整个预训练的语言模型被冻结,这意味着模型的主体部分不会在微调过程中发生改变。随着冻结语言模型的规模增加,提示调整的性能变得越来越有竞争力,甚至可以与全面微调(也称为“模型调整”)相媲美。这表明,即使在不改变预训练参数的情况下,也可以通过调整输入提示来获得出色的性能。
提示调整涉及不同的初始化策略,如:
-
随机词汇词嵌入(Embedding of random vocab words):选择随机的词汇作为嵌入。
-
类标签词嵌入(Embedding of class label words):使用与分类标签相关的词汇进行嵌入。
-
随机初始化(Random init):这种方法通常效果不佳,不推荐使用。
需要提一下,P-Tuning v2这篇工作是提示调整的全层版本。所有层级的参数对文本分类和生成任务都有助益。
总的来说,Prompt Tuning是一种创新的轻量级微调方法,通过在输入上添加可学习的嵌入,而不是改变整个模型的结构来实现任务特定的优化。这不仅减少了计算和存储的需求,而且还允许使用较大的冻结模型来实现与全面微调相当的性能。在文本分类等任务中,提示调整提供了一种灵活和高效的解决方案。
Prefix Tuning
前缀调整(Prefix Tuning)是一种特别设计用于语言生成任务的微调方法,已在BART和GPT-2模型上进行了开发。以下是对Prefix Tuning的详细解释:
Prefix Tuning通过在输入的开始处添加k个位置,并在每个注意力层连接额外的可学习权重,作为键(keys)和值(values)来实现。这些附加的权重允许模型在微调过程中学习特定任务的上下文和结构。虽然Prefix Tuning与Prompt Tuning在某些方面有相似之处(例如,都涉及微调输入),但两者之间存在重要区别。比如与Pompt Tuning不同,Prefix Tuning不仅添加可学习的输入,还在每个注意力层中添加可学习的权重。这些权重可以更好地捕获任务特定的依赖关系和上下文信息。
所有层级的可训练参数可以增强模型的性能,允许模型在更细粒度上进行优化。
总的来说,前缀调整通过在注意力机制的键和值部分添加可学习的权重,为模型提供了一种强大的微调手段。这种方法允许模型更好地捕捉任务特定的模式,并与提示调整等其他技术相辅相成,提供了一种灵活和强大的任务特定优化手段。
Adapter Tuning
Adapter Tuning(适配器调整)是一种微调技术,通过在每个(冻结的)Transformer层之间添加新的学习“bottleneck”层(称为适配器)来实现,而不改变原始Transformer层的参数。
总之,适配器调整提供了一种灵活的微调方法,允许在不改变原始Transformer层的情况下,通过引入新的可学习层来调整模型。这种方法与提示调整和前缀调整等技术相结合,为自然语言处理任务提供了一种高效、可扩展的解决方案。适配器的设计使其可以在不牺牲整体模型结构的情况下,增强特定任务的性能。
-
Lightweight Fine-tuning的表达能力相当复杂,因为它与特定的预训练语言模型(LM)紧密相连。如果预训练LM的权重为0,则Pormpt/Prefix Tuning将不起作用。
-
以上提到的Promt/Prefix/Adapter Tuning提供了一种实现个性化模型的方法。假设我们想为N个用户部署个性化模型,通过Prefix Tuning,我们可以存储N个前缀,每个用户一个。然后,在一个小批量内,通过在每个输入之前附加相应的用户特定前缀,可以并行运行每个用户的个性化模型。这种方法实现了用户特定的调整,同时有效地利用了并行处理能力。
-
Lightweight Fine-tuning方法的鲁棒性得到了提升,这些方法倾向于在与全面微调相比,改善分布外(out-of-distribution,OOD)的性能,例如在不同主题或领域的文本上的表现。例如,Prompt Tuning方法提高了OOD的准确性:与在SQuAD上训练并在领域外的MRQA 2019任务上测试的全面微调(模型调整)相比,Prompt Tuning方法在F1结果上表现得更好。
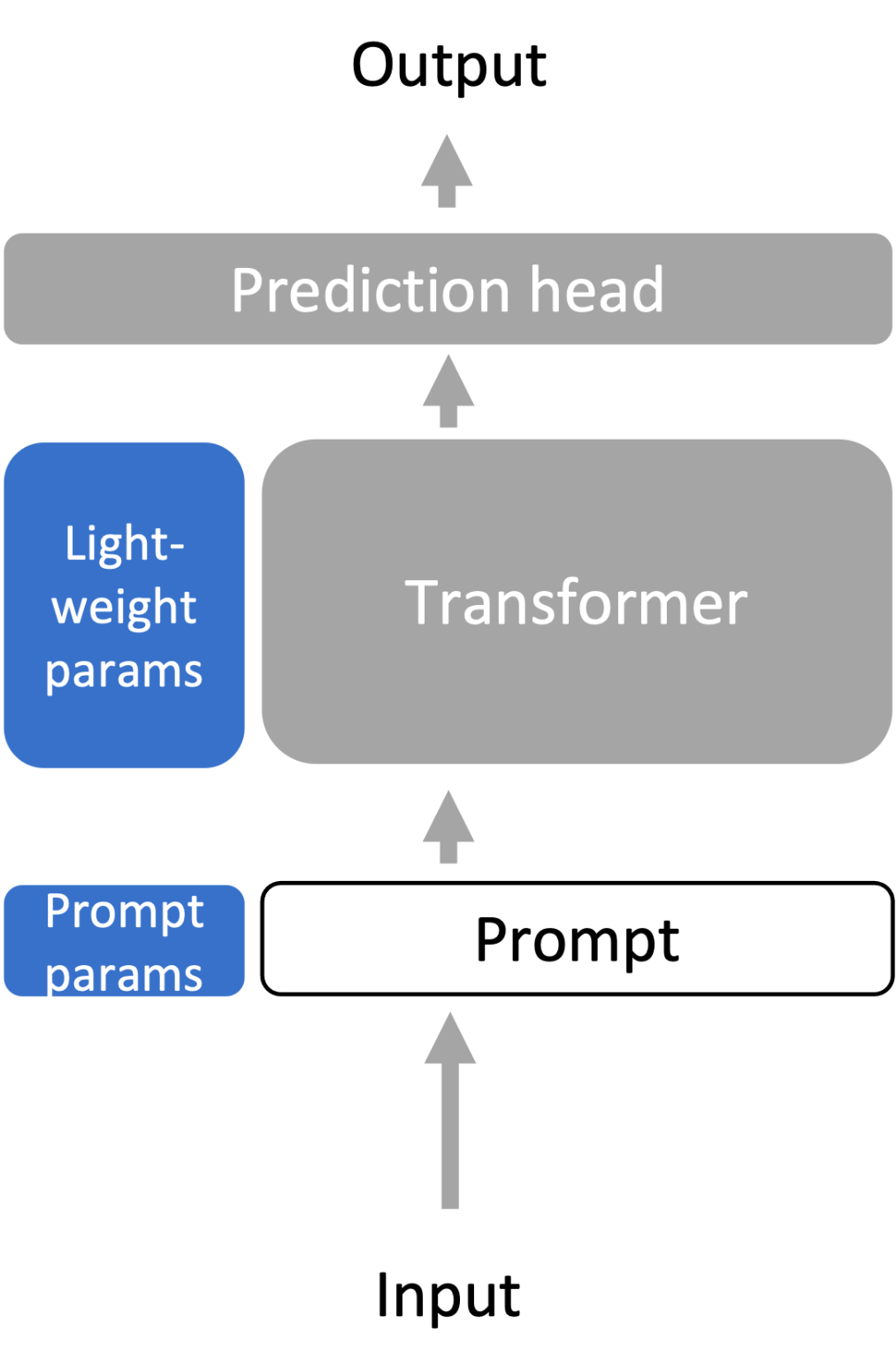
轻量微调不动原来transformer参数,而是就一些额外参数(输入/自注意)
普通微调可能会优化一些参数
我们需要将大型语言模型适配到各种不同的下游任务中,这些任务可能与语言建模有很大不同。
-
探测法(Probing):探测法在冻结的语言模型之上训练一个特定任务的预测头,将语言模型视为良好的表示提取器。冻结语言模型倾向于限制该方法的表现能力。
-
微调(Fine-tuning):微调将大型语言模型参数视为下游任务的进一步训练的初始化,这比探测更具表现力,但也更昂贵,因为我们必须为每个下游任务保存整个模型。
-
轻量级微调(Lightweight fine-tuning):轻量级微调在微调和探测之间取得了平衡,只优化少量参数(模型的<1%),但它优化了模型的高杠杆部分,因此仍然非常具有表现力。 通过上述方法,可以更灵活地应对各种不同的下游任务,既实现了对特定任务的精确适配,又在一定程度上控制了计算和存储的成本,从而在实际应用中取得更好的性能和效率。
第八章 基于大模型的智能体(Agent)
8.1 简介
在科技发展的历史中,人类一直期望追求智能化的实现,由此的幻想早已先行,有《机器人总动员》中的瓦力,有《终结者》中的T-800,也有《最后的问题》中的「模」,人们试图打造一种可以自主完成预设目标的代理或实体,即智能体 (AI Agents 或 Agents),以协助人类完成各种各样繁琐的任务。多年来,智能体作为人工智能一个活跃的应用领域吸引人们不断地研究探索。如今,大语言模型正蓬勃发展,日新月异。在智能体技术的实现上,尤其是在基于大型语言模型(LLM)的智能体构建中,LLM在智能体的智能化中扮演着至关重要的角色。这些智能体能够通过整合LLM与规划、记忆以及其他关键技术模块,执行复杂的任务。在此框架中,LLM充当核心处理单元或“大脑”,负责管理和执行为特定任务或响应用户查询所需的一系列操作。 以一个新的例子来展示LLM智能体的潜力,设想我们需要设计一个系统来应对以下询问: 当前欧洲最受欢迎的电动汽车品牌是什么? 这个问题可直接由一个更新至最新数据的LLM给出答案。若LLM缺乏即时数据,可以借助一个RAG(检索增强生成)系统,其中LLM可以访问最新的汽车销售数据或市场报告。 现在,让我们考虑一个更为复杂的查询:
过去十年里,欧洲电动汽车市场的增长趋势如何,这对环境政策有何影响?能否提供这一时期内市场增长的图表?
仅依赖LLM来解答此类复杂问题是不够的。虽然结合LLM与外部知识库的RAG系统能提供某种帮助,但要全面回答这个问题,还需要更进一步的操作。这是由于要解答这个问题,首先需要将其拆解成多个子问题,其次需要并通过特定的工具和流程进行解决,最终获得所需答案。一个可能的方案是开发一个能够访问最新的环境政策文献、市场报告以及公开数据库的LLM智能体,以获取关于电动汽车市场增长及其环境影响的信息。 此外,LLM智能体还需配备“数据分析”工具,这可以帮助智能体利用收集到的数据制作出直观的图表,从而清晰地展示过去十年欧洲电动汽车市场的增长趋势。虽然这种智能体的高级功能目前还属于理想化设想,但它涉及多项重要的技术考量,如制定解决方案的规划和可能的记忆模块,这有助于智能体追踪操作流程、监控和评估整体进展状态。
8.2 LLM Agent 架构
一般而言,基于LLM的智能体框架包括以下核心组件:
-
用户请求 - 用户的问题或请求
-
智能体/大脑 - 充当协调者的智能体核心
-
规划 - 协助智能体规划未来的行动
-
记忆 - 管理智能体的过往行为
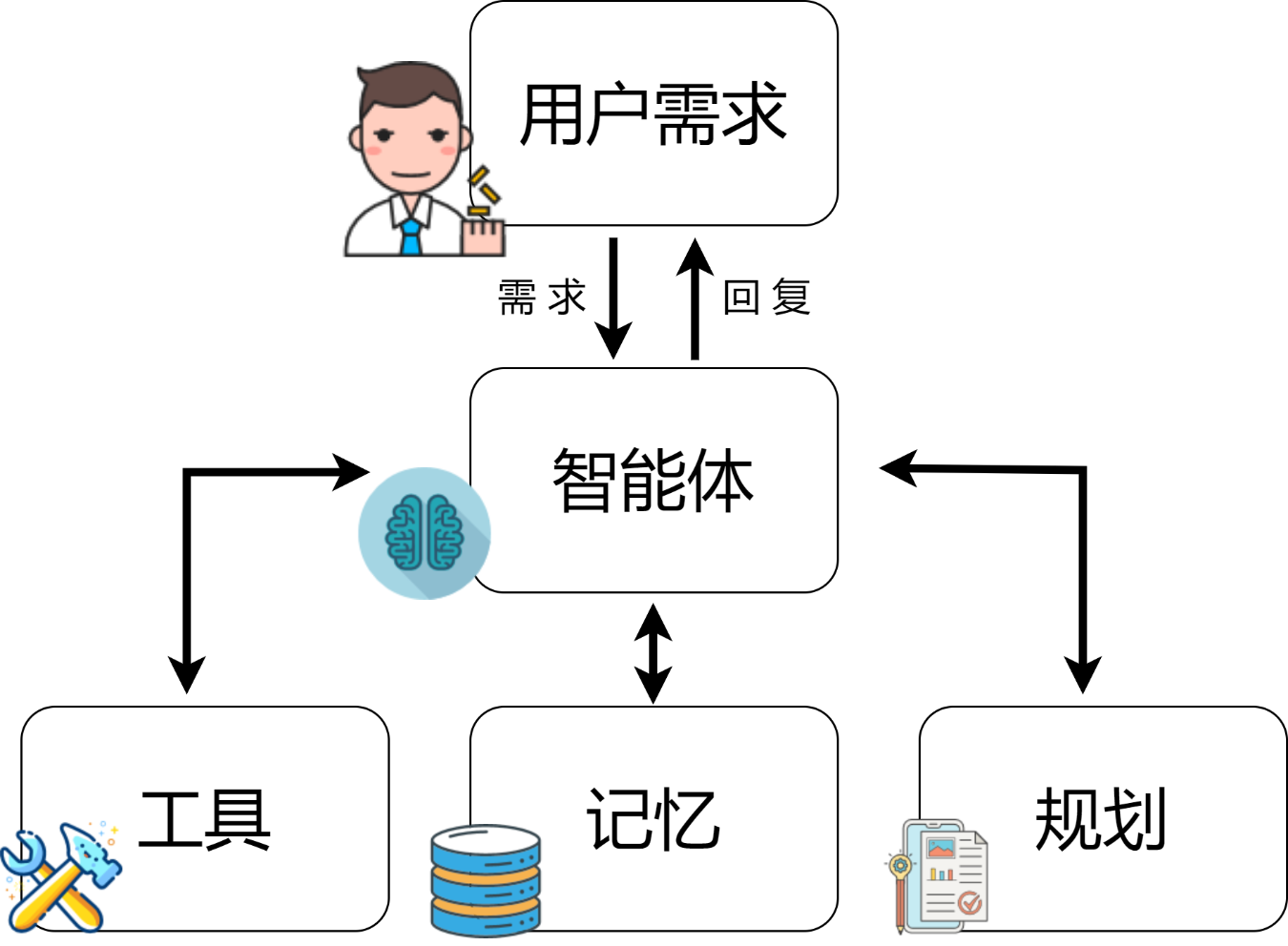
在构建以大型语言模型(LLM)为核心的智能体系统中,LLM是至关重要的,充当系统的主脑和多任务协调的核心。这种智能体通过解析和执行基于提示模板的指令,这些模板不仅指导LLM具体操作,也详细定义了智能体的角色和人格,包括背景、性格、社会环境及人口统计信息等。这种人格化的描述使得智能体能更精准地理解和执行任务。 为了优化这一过程,系统设计需要综合考虑几个关键方面:
-
首先,系统需具备丰富的上下文理解和持续学习能力,不仅处理和记忆大量交互信息,还需不断优化执行策略和预测模型。
-
其次,引入多模态交互,融合文本、图像、声音等多种输入输出形式,让系统更自然有效地处理复杂任务和环境。此外,智能体的动态角色适应和个性化反馈也是提升用户体验和执行效率的关键。
-
最后,加强安全性和可靠性,确保系统稳定运行,赢得用户信任。 整合这些元素,基于LLM的智能体系统能够在处理特定任务时展现出更高的效率和准确性,同时,在用户交互和系统长期发展方面展现出更强的适应性和可持续性。这种系统不仅仅是执行命令的工具,更是能够理解复杂指令、适应不同场景并持续优化自身行为的智能合作伙伴。
8.3 规划
规划模块是智能体理解问题并可靠寻找解决方案的关键,它通过分解为必要的步骤或子任务来回应用户请求。任务分解的流行技术包括思维链(COT)和思维树(TOT),分别可以归类为单路径推理和多路径推理。
首先,我们介绍“思维链(COT)”的方法,它通过分步骤细分复杂问题为一系列更小、更简单的任务,旨在通过增加计算的测试时间来处理问题。这不仅使得大型任务易于管理,而且帮助我们理解模型如何逐步解决问题。
接下来,有研究者在此基础上提出了思维树(TOT)”方法,通过在每个决策步骤探索多个可能的路径,形成树状结构图。这种方法允许采用不同的搜索策略,如宽度优先或深度优先搜索,并利用分类器来评估每个可能性的有效性。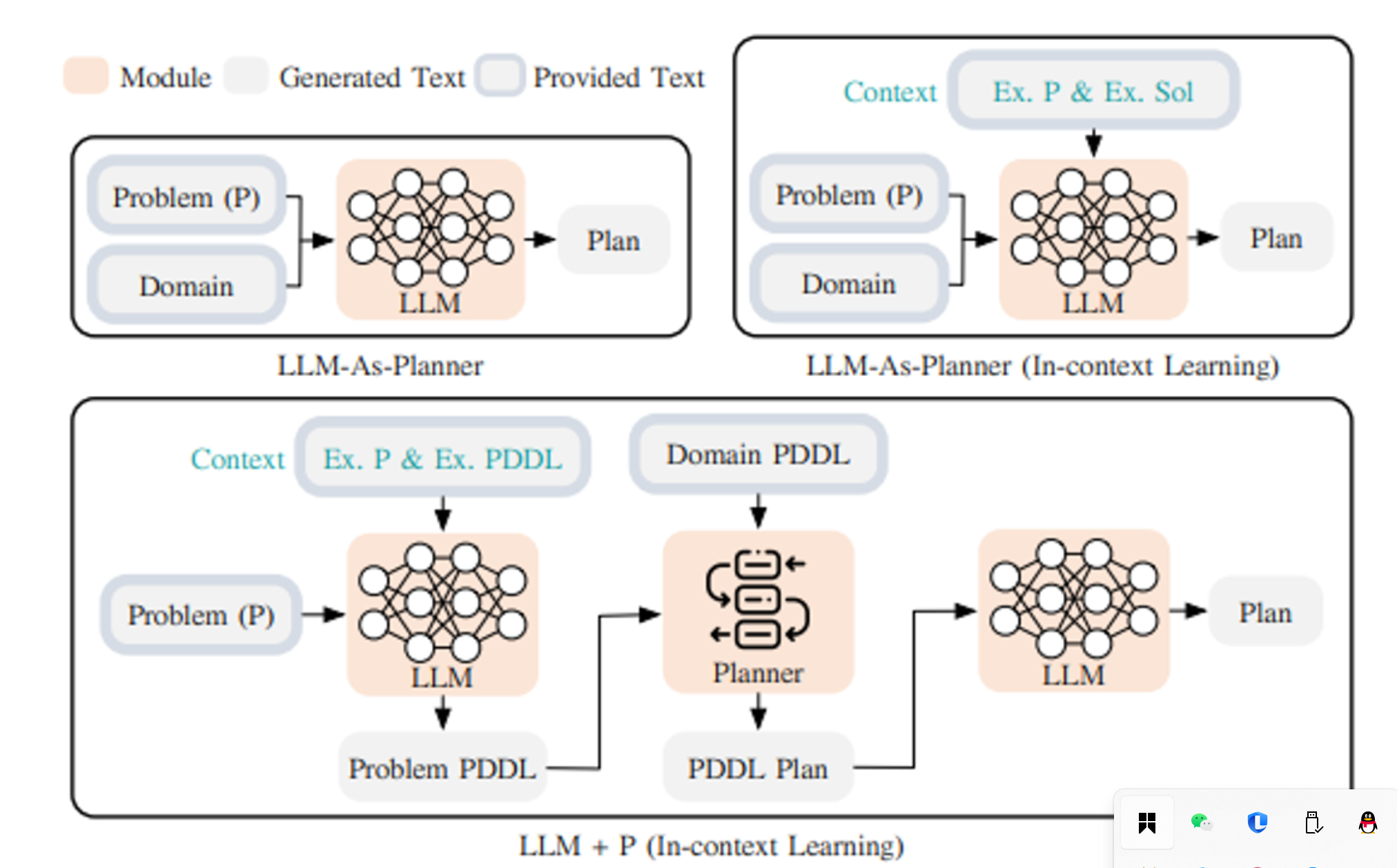
LLM与经典规划器结合(LLM+P):
-
这种方法结合了LLM和经典规划器,后者通常用于执行长期规划任务。具体步骤包括:
-
将问题转化为PDDL格式:PDDL(Planning Domain Definition Language)是一种描述规划问题的标准语言,广泛应用于人工智能领域的自动规划中。通过将任务描述转化为PDDL格式,规划器可以更容易地理解和处理问题。
-
规划器生成解决方案:外部规划器使用PDDL格式的任务描述进行推理,生成一个详细的解决方案或行动计划。
-
将解决方案转化回自然语言:最后,生成的解决方案会被转化为自然语言的形式,供人类理解或应用。
-
-
适用场景:这种方法非常适合那些需要详细、长期规划的任务,例如涉及多个步骤和复杂决策的场景。但它依赖于特定领域的PDDL和规划器,因此它的适用范围可能较为局限,特别是当任务不适合经典规划模型时。
有反馈规划
上述规划模块不涉及任何反馈,这使得实现解决复杂任务的长期规划变得具有挑战性。为了解决这一挑战,可以利用一种机制,使模型能够根据过去的行动和观察反复思考和细化执行计划。目标是纠正并改进过去的错误,这有助于提高最终结果的质量。这在复杂的现实世界环境和任务中尤其重要,其中试错是完成任务的关键。这种反思或批评机制的两种流行方法包括ReAct和Reflexion。
ReAct方法提出通过结合特定任务的离散动作与语言描述,实现了在大规模语言模型(LLM)中融合推理与执行的能力。离散动作允许LLM与其环境进行交互,如利用Wikipedia搜索API,而语言描述部分则促进了LLM产生基于自然语言的推理路径。这种策略不仅提高了LLM处理复杂问题的能力,还通过与外部环境的直接交互,增强了模型在真实世界应用中的适应性和灵活性。此外,基于自然语言的推理路径增加了模型决策过程的可解释性,使用户能够更好地理解和校验模型行为。ReAct设计亦注重模型行动的透明度与控制性,旨在确保模型执行任务时的安全性与可靠性。因此,ReAct的开发为大规模语言模型的应用提供了新视角,其融合推理与执行的方法为解决复杂问题开辟了新途径。
Reflexion是一个框架,旨在通过赋予智能体动态记忆和自我反思能力来提升其推理技巧。该方法采用标准的强化学习(RL)设置,其中奖励模型提供简单的二元奖励,行动空间遵循ReAct中的设置,即通过语言增强特定任务的行动空间,以实现复杂的推理步骤。每执行一次行动后,智能体会计算一个启发式评估,并根据自我反思的结果,可选择性地重置环境,以开始新的尝试。启发式函数用于确定轨迹何时效率低下或包含幻觉应当停止。效率低下的规划指的是长时间未成功完成的轨迹。幻觉定义为遭遇一系列连续相同的行动,这些行动导致在环境中观察到相同的结果。
记忆模块是智能体存储内部日志的关键组成部分,负责存储过去的思考、行动、观察以及与用户的互动。它对于智能体的学习和决策过程至关重要。根据LLM智能体文献,记忆可分为两种主要类型:短期记忆和长期记忆,以及将这两种记忆结合的混合记忆,旨在提高智能体的长期推理能力和经验积累。
-
短期记忆 - 关注于当前情境的上下文信息,是短暂且有限的,通常通过上下文窗口限制的学习实现。
-
长期记忆 - 储存智能体的历史行为和思考,通过外部向量存储实现,以便快速检索重要信息。
-
混合记忆 -通过整合短期和长期记忆,不仅优化了智能体对当前情境的理解,还加强了对过去经验的利用,从而提高了其长期推理和经验积累的能力。
工具使大型语言模型(LLM)能够通过外部环境(例如Wikipedia搜索API、代码解释器和数学引擎)来获取信息或完成子任务。这包括数据库、知识库和其他外部模型的使用,极大地扩展了LLM的能力。在我们最初的与汽车销量相关的查询中,通过代码实现直观的图表是一个使用工具的例子,它执行代码并生成用户请求的必要图表信息。
LLM以不同方式利用工具:
-
MRKL:是一种用于自主代理的架构。MRKL系统旨在包含一系列“专家”模块,而通用的大型语言模型(LLM)作为路由器,将查询引导至最合适的专家模块。这些模块既可以是大模型,也可以是符号的(例如数学计算器、货币转换器、天气API)。他们以算术为测试案例,对LLM进行了调用计算器的微调实验。实验表明,解决口头数学问题比解决明确陈述的数学问题更困难,因为大型语言模型(7B Jurassic1-large模型)未能可靠地提取出基本算术运算所需的正确参数。结果强调,当外部符号工具可以可靠地工作时,知道何时以及如何使用这些工具至关重要,这由LLM的能力决定。
-
Toolformer:这个学术工作是训练了一个用于决定何时调用哪些API、传递什么参数以及如何最佳地将结果进行分析的大模型。这一过程通过微调的方法来训练大模型,仅需要每个API几个示例即可。该工作集成了一系列工具,包括计算器、问答系统、搜索引擎、翻译系统和日历。Toolformer在多种下游任务中实现了显著提升的零次学习(zero-shot)性能,经常与更大的模型竞争,而不牺牲其核心的语言建模能力。
-
函数调用(Function Calling): 这也是一种增强大型语言模型(LLM)工具使用能力的策略,它通过定义一系列工具API,并将这些API作为请求的一部分提供给模型,从而使模型能够在处理文本任务时调用外部功能或服务。这种方法不仅扩展了LLM的功能,使其能够处理超出其训练数据范围的任务,而且还提高了任务执行的准确性和效率。
-
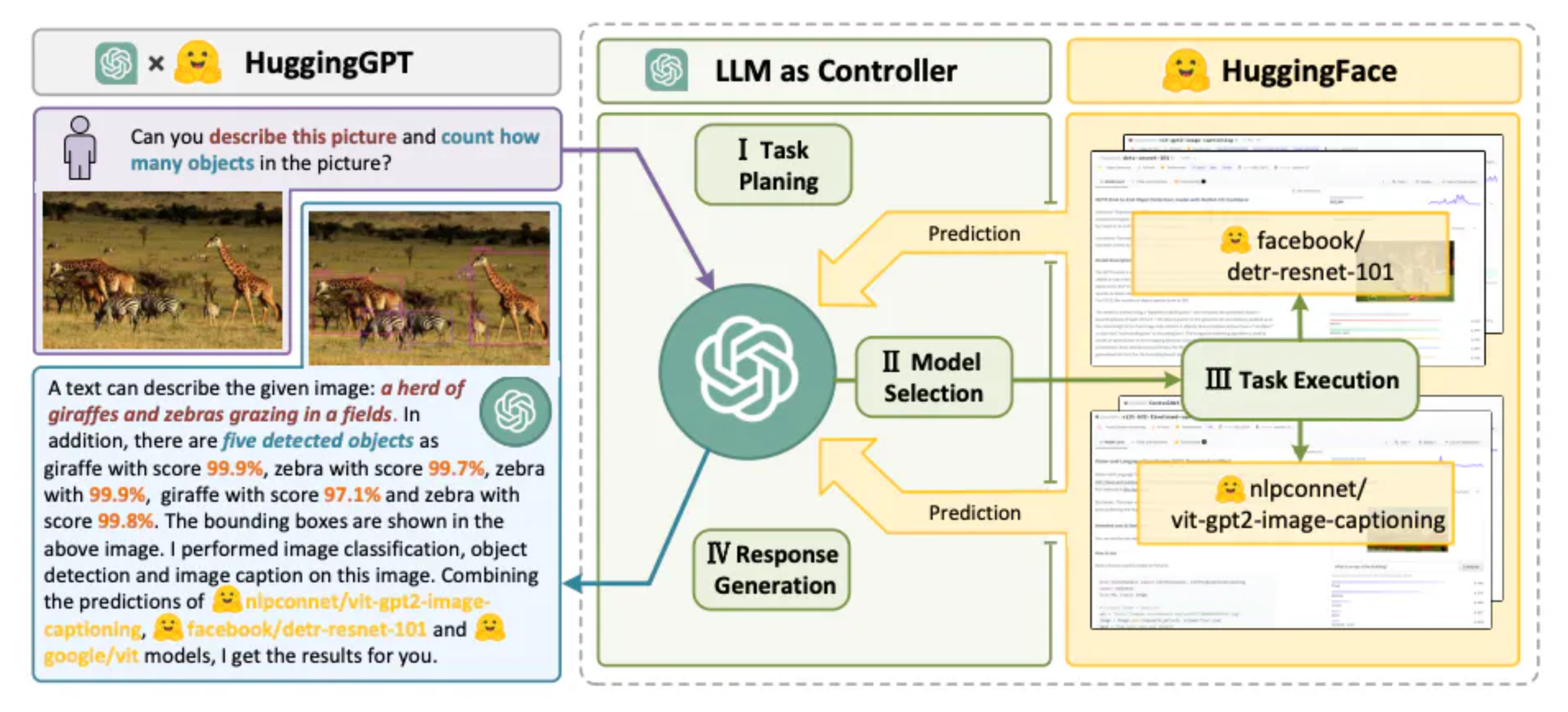
HuggingGPT : 它是由大型语言模型(LLM)驱动的,设计用来自主处理一系列复杂的人工智能任务。HuggingGPT融合了LLM的能力和机器学习社区的资源,例如ChatGPT与Hugging Face的结合,使其能够处理来自不同模态的输入。具体来说,LLM在这里扮演着大脑的角色,一方面根据用户请求拆解任务,另一方面依据模型描述选择适合的模型执行任务。通过执行这些模型并将结果整合到计划的任务中,HuggingGPT能自主完成复杂的用户请求。这个过程展示了从任务规划到模型选择,再到任务执行,最后是响应生成的完整流程。首先,HuggingGPT利用ChatGPT分析用户的请求以理解他们的意图,并将其分解为可能的解决方案。接下来,它会选择Hugging Face上托管的、最适合执行这些任务的专家模型。每个选定的模型被调用并执行,其结果将反馈给ChatGPT。最终,ChatGPT将所有模型的预测结果集成起来,为用户生成响应。HuggingGPT的这种工作方式不仅扩展了传统单一模式处理的能力,而且通过其智能的模型选择和任务执行机制,在跨领域任务中提供了高效、准确的解决方案。
这些策略和工具的结合不仅增强了LLM与外部环境的交互能力,也为处理更复杂、跨领域的任务提供了强大的支持,开启了智能体能力的新篇章。
8.4 挑战
构建基于大型语言模型(LLM)的智能体是一个新兴领域,面临着众多挑战和限制。以下是几个主要的挑战及可能的解决方案:
-
角色适应性问题: 智能体需要在特定领域内有效工作,对难以表征或迁移的角色,可以通过针对性地微调LLM来提高性能。这包括代表非常见角色或心理特征的能力提升。
-
上下文长度限制: 有限的上下文长度限制了LLM的能力,尽管向量存储和检索提供了访问更大知识库的可能性。系统设计需要创新,以在有限的通信带宽内有效运作。
-
提示的鲁棒性: 智能体的提示设计需要足够鲁棒,以防微小的变化导致可靠性问题。可能的解决方案包括自动优化调整提示或使用LLM自动生成提示。
-
知识边界的控制: 控制LLM的内部知识,避免引入偏见或使用用户不知道的知识,是一个挑战。这要求智能体在处理信息时更加透明和可控。
-
效率和成本问题: LLM处理大量请求时的效率和成本是重要考量因素。优化推理速度和成本效率是提升多智能体系统性能的关键。
总的来说,基于LLM的智能体构建是一个复杂且多面的挑战,需要在多个方面进行创新和优化。持续的研究和技术发展对于克服这些挑战至关重要。
参考项目:大模型基础
个人理解,仅供参考~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











