







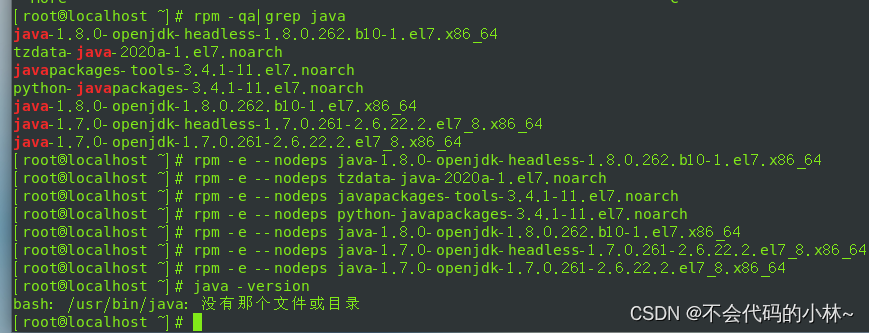
1.卸载Linux自带的jdk
2.安装并解压jdk和hadoop安装包
[root@localhost software]# tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
[root@localhost software]# tar -zxvf hadoop-2.8.0.tar.gz -C /opt/module/
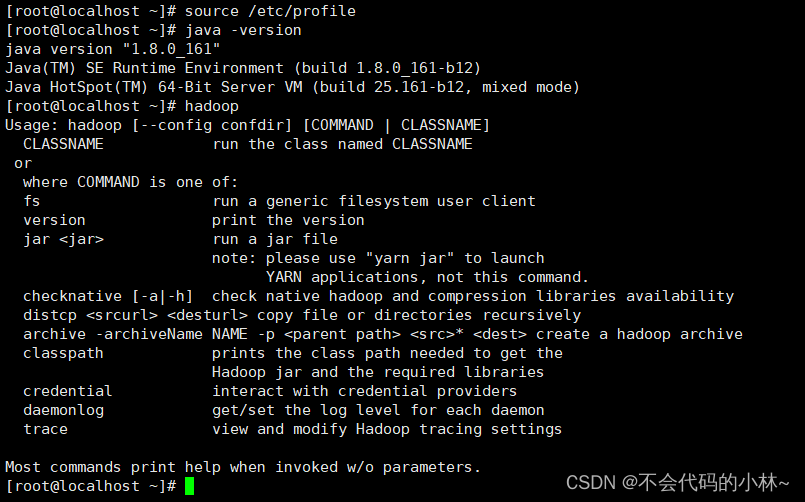
3.配置jdk和hadoop的系统环境变量
- vim /etc/profile
#JAVA
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP
export HADOOP_HOME=/opt/module/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4.关闭防火墙
- 永久关闭防火墙:systemctl disable firewalld.service

5.将虚拟机进行关机,再克隆2台服务器(root136,root137)

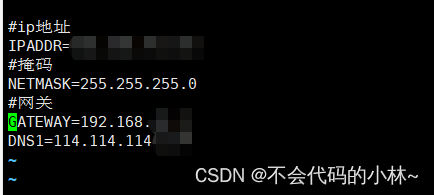
6.设置3台服务器的静态ip
- vim /etc/sysconfig/network-scripts/ifcfg-ens33
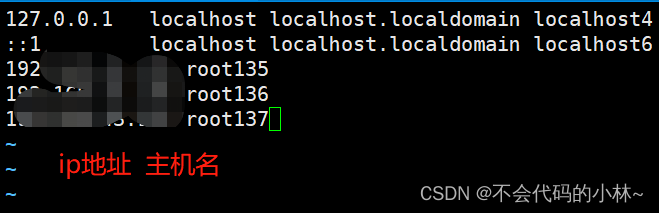
7.修改3台服务器的主机名、/etc/hosts文件
[root@localhost ~]# hostnamectl set-hostname root135
[root@localhost ~]# bash
[root@root135 ~]# vim /etc/hosts
8.编写xsync脚本以便进行服务器之间文件的传输更新
#!/bin/bash
#1. 判断参数个数
# 判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 对135,136,137都进行分发
for host in root135 root136 root137
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done
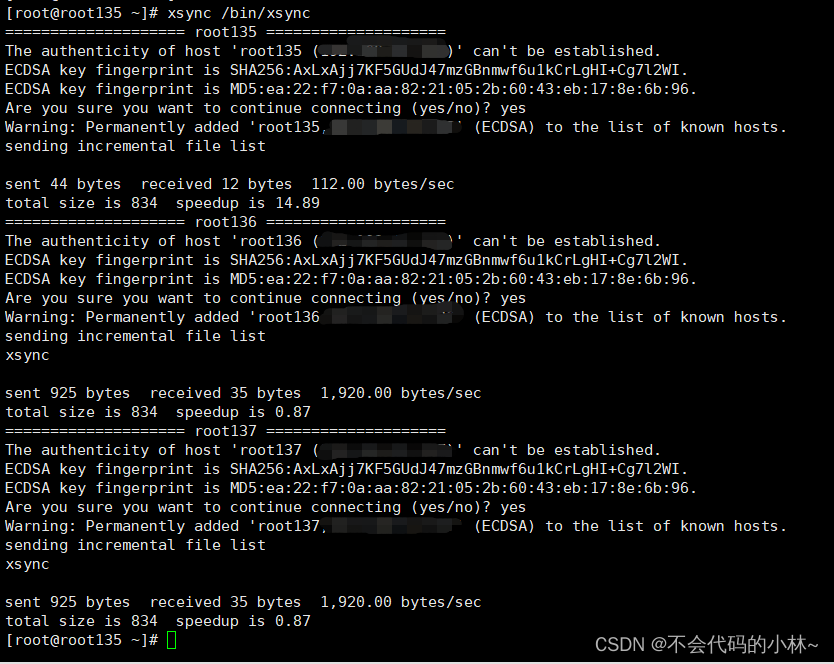
9.ssh免密登录

#将公钥拷贝到其他服务器上
[root@root135 ~]# ssh-copy-id root135
[root@root135 ~]# ssh-copy-id root136
[root@root135 ~]# ssh-copy-id root13710.集群部署规划
| root135 | root136 | root137 | |
| HDFS | DataNode NameNode | DataNode | DataNode SecondaryNameNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager |
11.配置核心文件
- 修改hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_161
- 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://root135:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.8.0/data/tmp</value>
</property>
</configuration>
- 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-addresss</name>
<value>root137:50090</value>
</property>
</configuration>
- 修改yarn-env.sh

- 修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>root136</value>
</property>
</configuration>
- 修改mapred-site.xml
<configuration>
<property>
<name>mapred.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改slaves
root135
root136
root13712.xsync进行配置文件的分发

13.对hadoop集群行进格式化

14.编写myhadoop脚本启动集群,编写jpsall脚本查看集群启动情况
- vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh root135 "/opt/module/hadoop-2.8.0/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh root136 "/opt/module/hadoop-2.8.0/sbin/start-yarn.sh"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 yarn ---------------"
ssh root136 "/opt/module/hadoop-2.8.0/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh root135 "/opt/module/hadoop-2.8.0/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
- vim jpsall
#!/bin/bash
for host in root135 root136 root137
do
echo =============== $host ===============
ssh $host $JAVA_HOME/bin/jps
done
- xsync myhadoop.sh jpsall
- 修改权限:chmod 777 myhadoop.sh / chmod 777 jpsall
- 启动服务:myhadoop.sh start
- 查看进程:jpsall

15.登录HDFS、YARN网页查验集群是否搭建成功
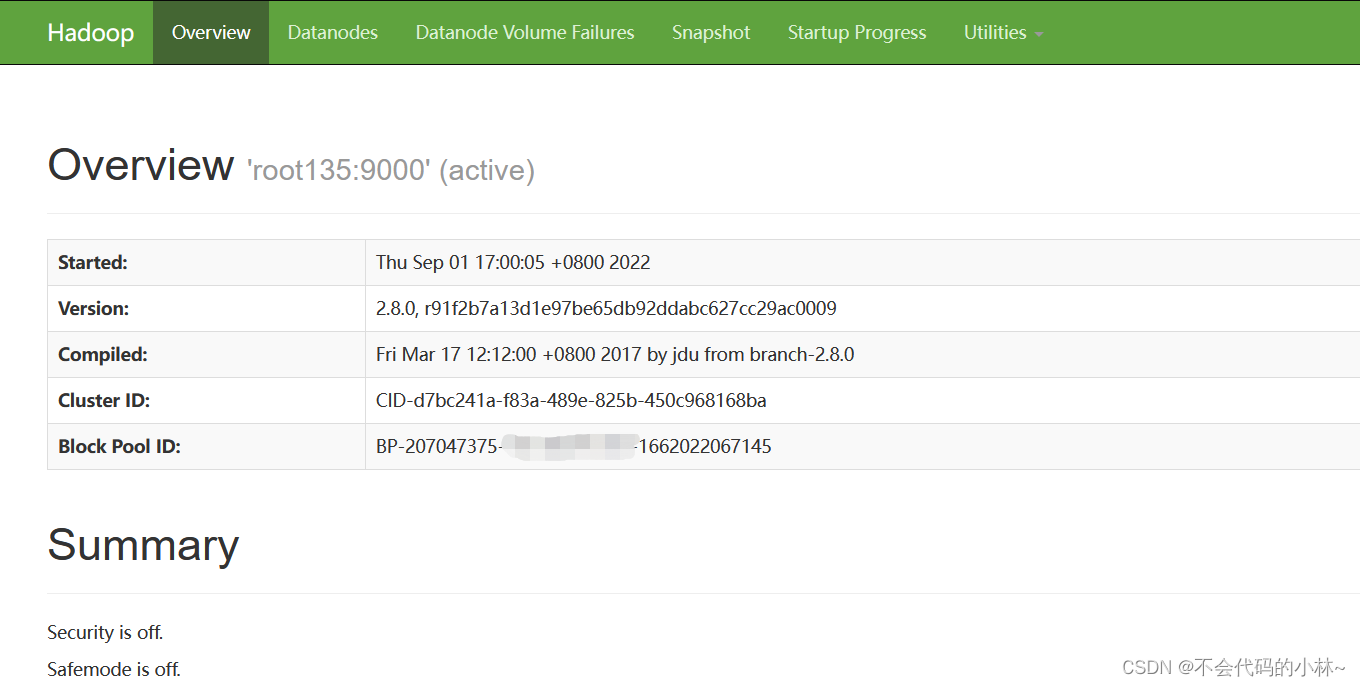
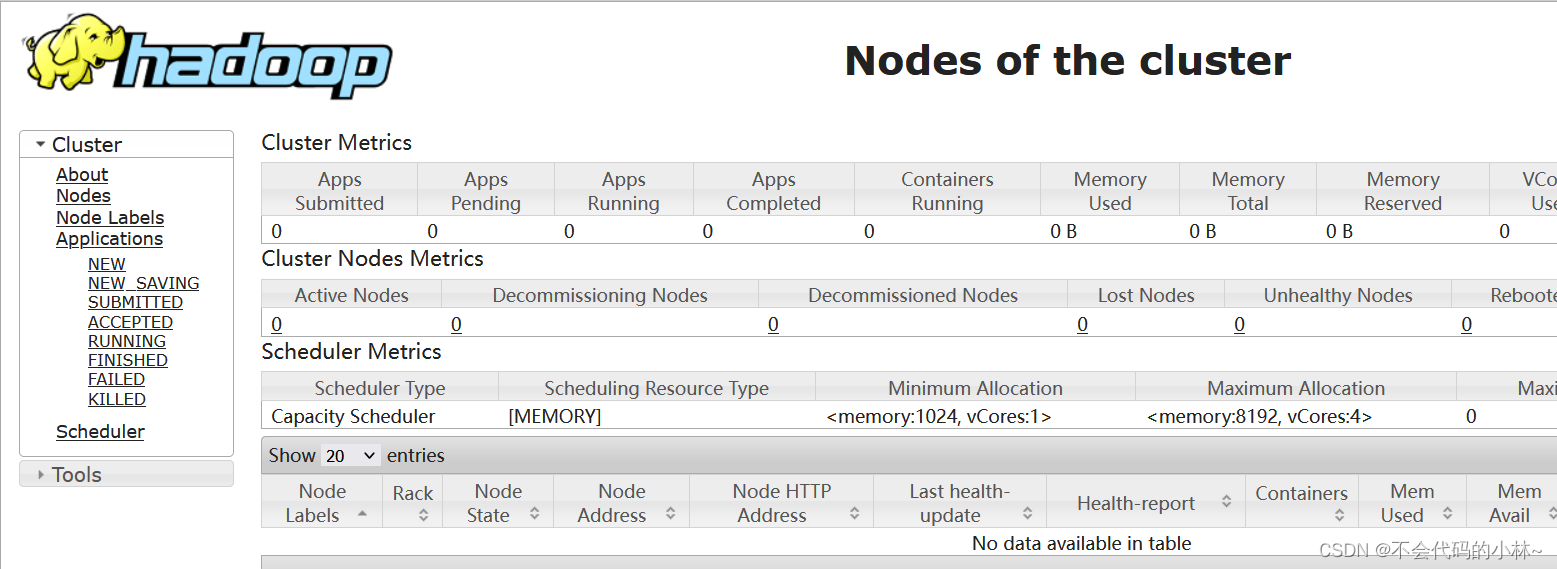
16.案例测试WordCount
- vim test
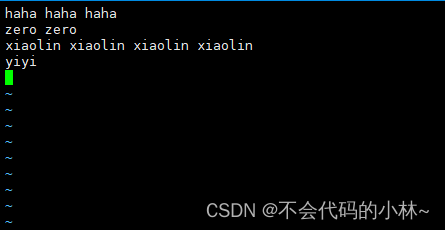
- hadoop fs -put test /
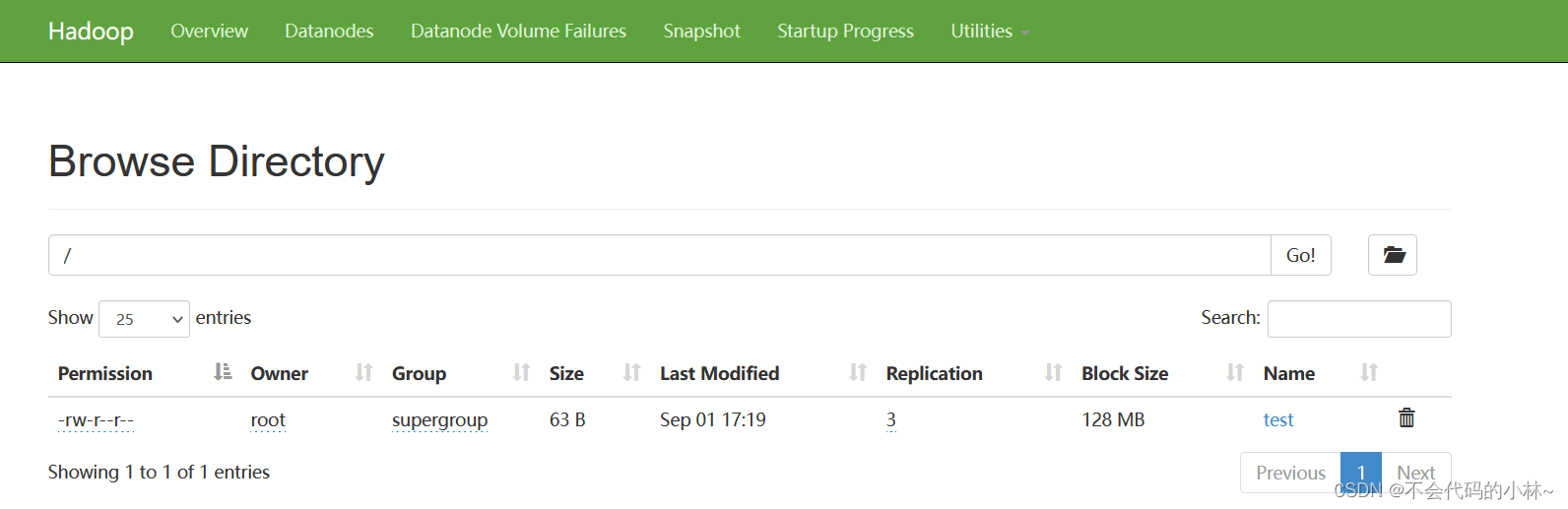
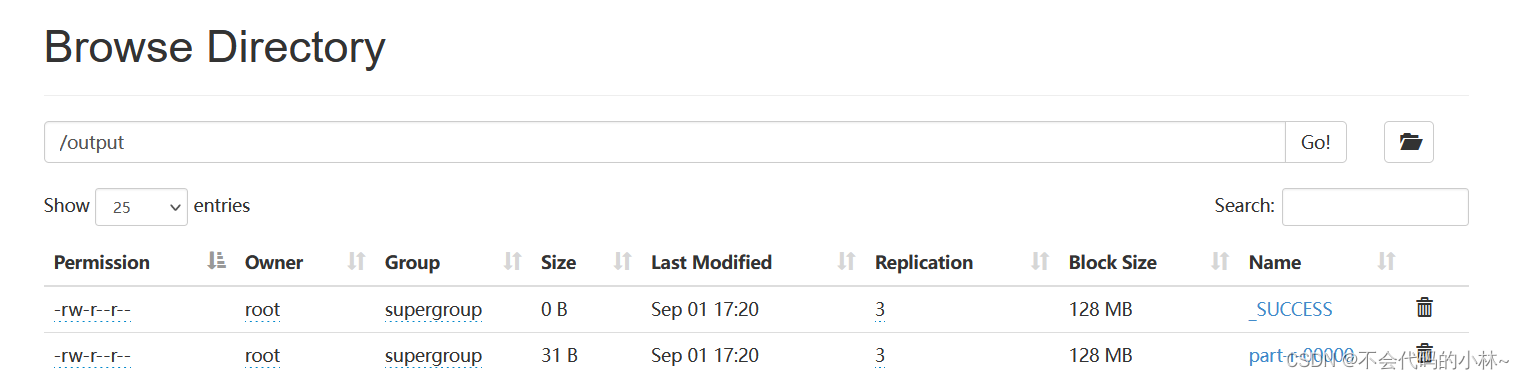
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /test /output
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









