






https原理–RSA密钥协商算法
TLS握手过程
TLS 协议是如何解决 HTTP 的风险的呢?
- 信息加密:HTTP 交互信息是被加密的,第三方就无法被窃取;
- 校验机制:校验信息传输过程中是否有被第三方篡改过,如果被篡改过,则会有警告提示;
- 身份证书:证明淘宝是真的淘宝网;
在进行 HTTP 通信前,需要先进行 TLS 握手。TLS 的握手过程,如下图:
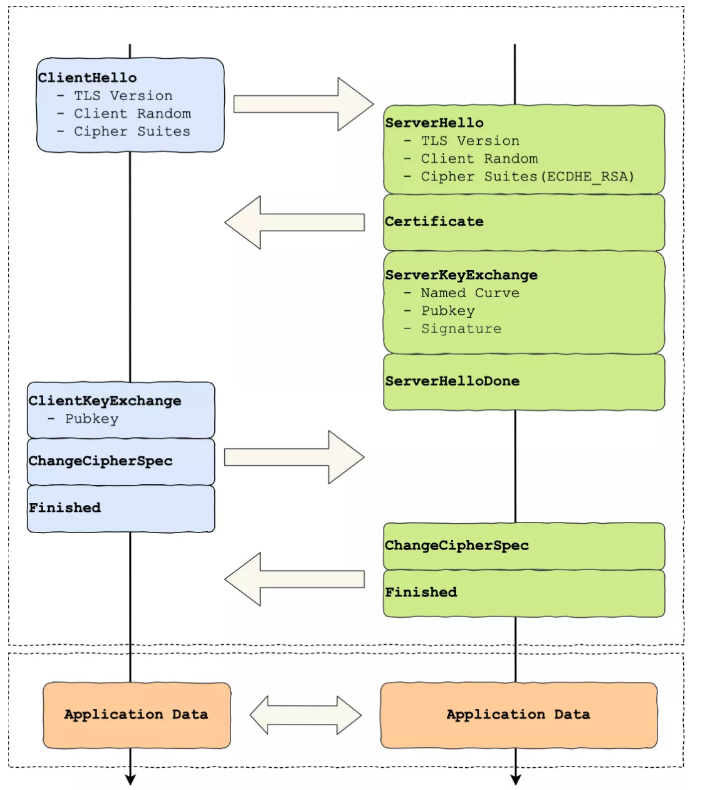
上图简要概述来 TLS 的握手过程,其中每一个「框」都是一个记录(record),记录是 TLS 收发数据的基本单位,类似于 TCP 里的 segment。多个记录可以组合成一个 TCP 包发送,所以通常经过「四个消息」就可以完成 TLS 握手,也就是需要 2个 RTT 的时延,然后就可以在安全的通信环境里发送 HTTP 报文,实现 HTTPS 协议。
所以可以发现,HTTPS 是应用层协议,需要先完成 TCP 连接建立,然后走 TLS 握手过程后,才能建立通信安全的连接。
接下来,我们就以最简单的 RSA 密钥交换算法,来看看它的 TLS 握手过程。更复杂更安全的密钥交换算法还有DHE算法,ECDHE算法。
RSA密钥协商握手过程
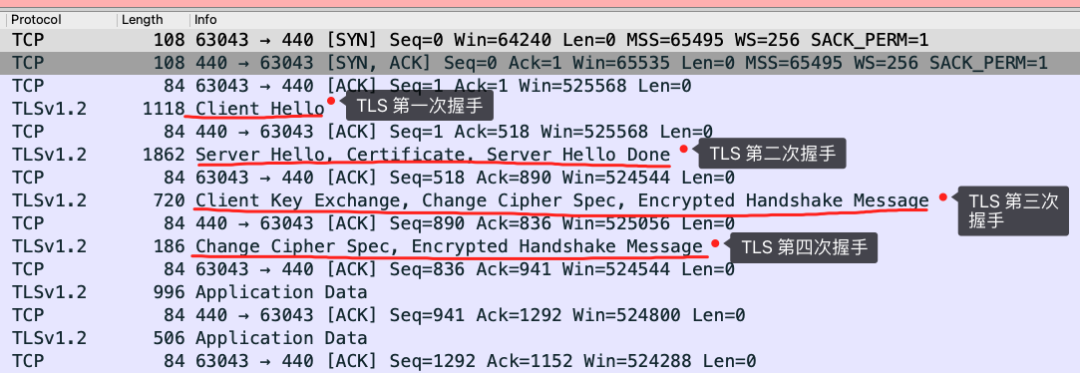
对应 Wireshark 的抓包,我也画了一幅图,你可以从下图很清晰地看到该过程:
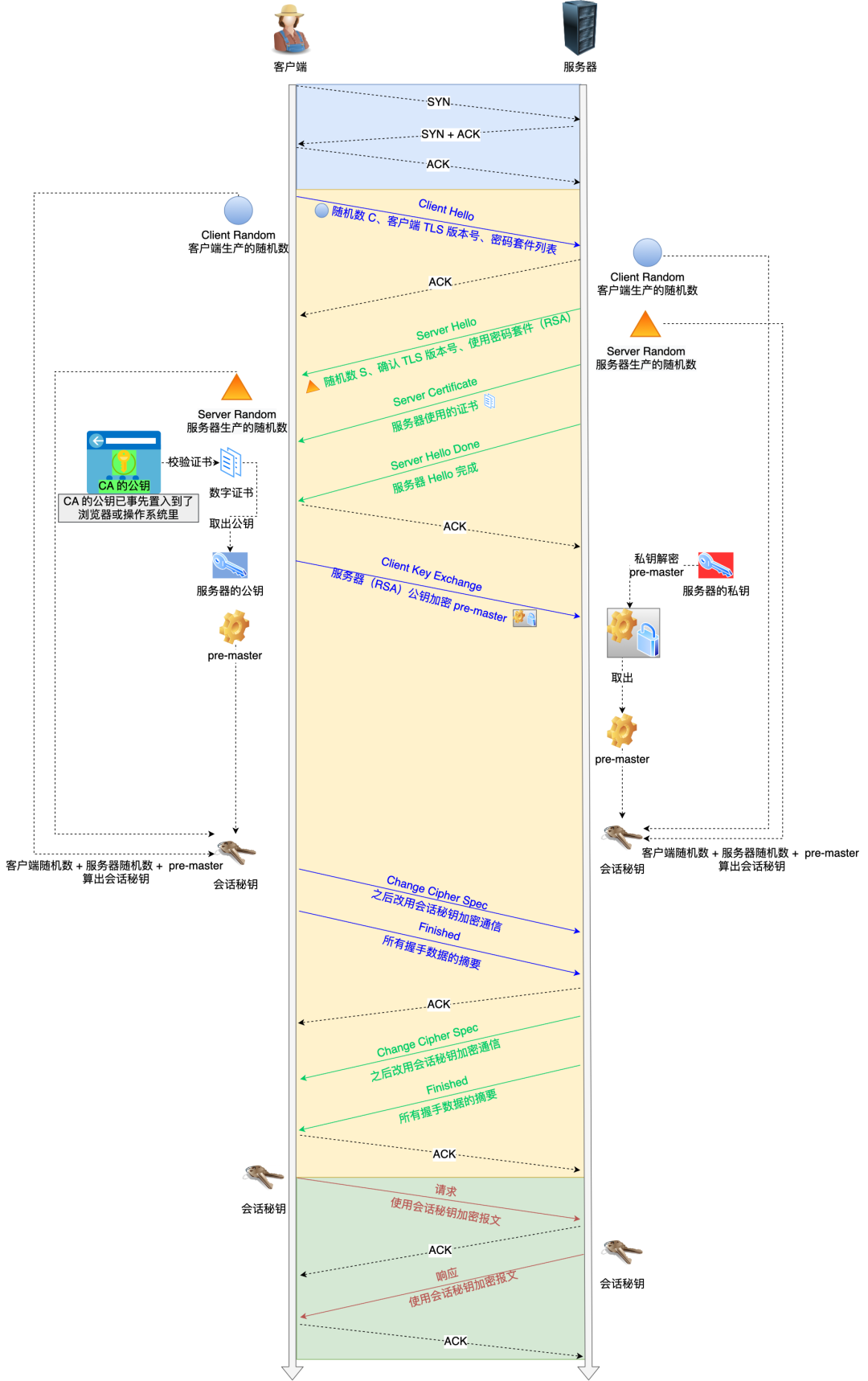
那么,接下来针对每一个 TLS 握手做进一步的介绍。
TLS 第一次握手
客户端首先会发一个「Client Hello」消息,字面意思我们也能理解到,这是跟服务器「打招呼」。
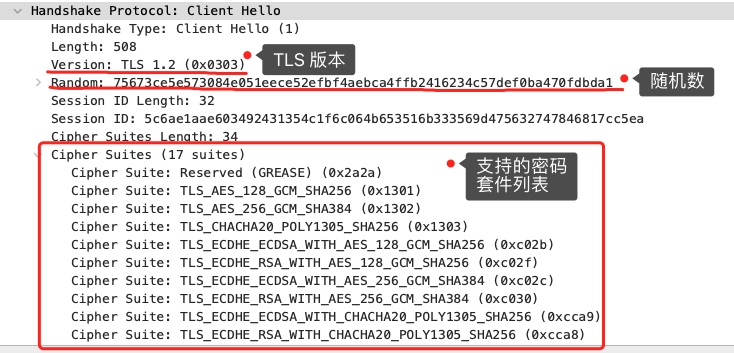
消息里面有客户端使用的 TLS 版本号、支持的密码套件列表,支持的压缩算法,以及生成的随机数(*Client Random*),这个随机数会被服务端保留,它是生成对称加密密钥的材料之一。
TLS 第二次握手
当服务端收到客户端的「Client Hello」消息后,会确认 TLS 版本号是否支持,和从密码套件列表中选择一个密码套件,还有选择压缩算法(安全性原因,一般不压缩),以及生成随机数(*Server Random*)。
接着,返回「Server Hello」消息,消息里面有服务器确认的 TLS 版本号,也给出了随机数(Server Random),然后从客户端的密码套件列表选择了一个合适的密码套件。
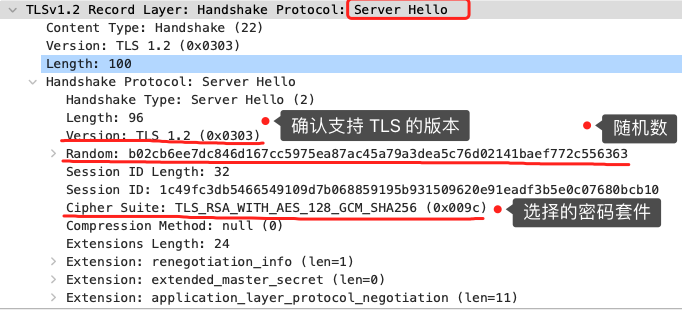
可以看到,服务端选择的密码套件是 “Cipher Suite: TLS_RSA_WITH_AES_128_GCM_SHA256”。
这个密码套件看起来真让人头晕,好一大串,但是其实它是有固定格式和规范的。基本的形式是「密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法」, 一般 WITH 单词前面有两个单词,第一个单词是约定密钥交换的算法,第二个单词是约定证书的验证算法。比如刚才的密码套件的意思就是:
- 由于 WITH 单词只有一个 RSA,则说明握手时密钥交换算法和签名算法都是使用 RSA;
- 握手后的通信使用 AES 对称算法,密钥长度 128 位,分组模式是 GCM;
- 摘要算法 SHA256 用于消息认证和产生随机数;
就前面这两个客户端和服务端相互「打招呼」的过程,客户端和服务端就已确认了 TLS 版本和使用的密码套件,而且你可能发现客户端和服务端都会各自生成一个随机数,并且还会把随机数传递给对方。
那这个随机数有啥用呢?其实这两个随机数是后续作为生成「会话密钥」的条件,所谓的会话密钥就是数据传输时,所使用的对称加密密钥。
然后,服务端为了证明自己的身份,会发送「Server Certificate」给客户端,这个消息里含有数字证书。
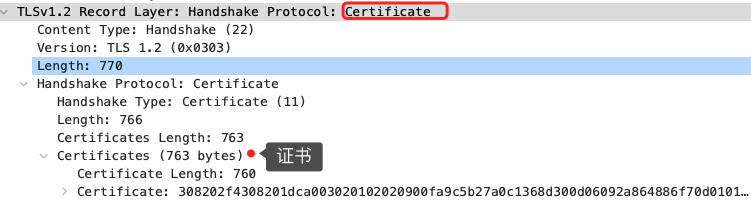
随后,服务端发了「Server Hello Done」消息,目的是告诉客户端,我已经把该给你的东西都给你了,本次打招呼完毕。

客户端验证证书
在这里刹个车,客户端拿到了服务端的数字证书后,要怎么校验该数字证书是真实有效的呢?
数字证书和 CA 机构
在说校验数字证书是否可信的过程前,我们先来看看数字证书是什么,一个数字证书通常包含了:
- 公钥;
- 持有者信息;
- 证书认证机构(CA)的信息;
- CA 对这份文件的数字签名及使用的算法;
- 证书有效期;
- 还有一些其他额外信息;
那数字证书的作用,是用来认证公钥持有者的身份,以防止第三方进行冒充。说简单些,证书就是用来告诉客户端,该服务端是否是合法的,因为只有证书合法,才代表服务端身份是可信的。
我们用证书来认证公钥持有者的身份(服务端的身份),那证书又是怎么来的?又该怎么认证证书呢?
为了让服务端的公钥被大家信任,服务端的证书都是由 CA (Certificate Authority,证书认证机构)签名的,CA 就是网络世界里的公安局、公证中心,具有极高的可信度,所以由它来给各个公钥签名,信任的一方签发的证书,那必然证书也是被信任的。
之所以要签名,是因为签名的作用可以避免中间人在获取证书时对证书内容的篡改。
数字证书签发和验证流程
如下图图所示,为数字证书签发和验证流程:
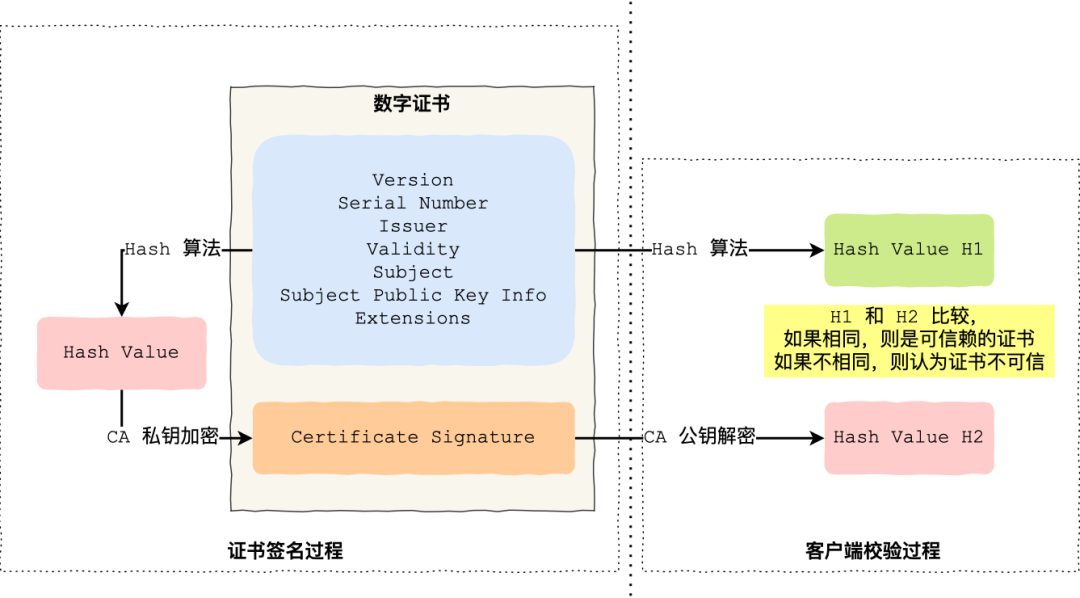
CA 签发证书的过程,如上图左边部分:
- 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
- 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
- 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
客户端校验服务端的数字证书的过程,如上图右边部分:
- 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
- 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
- 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
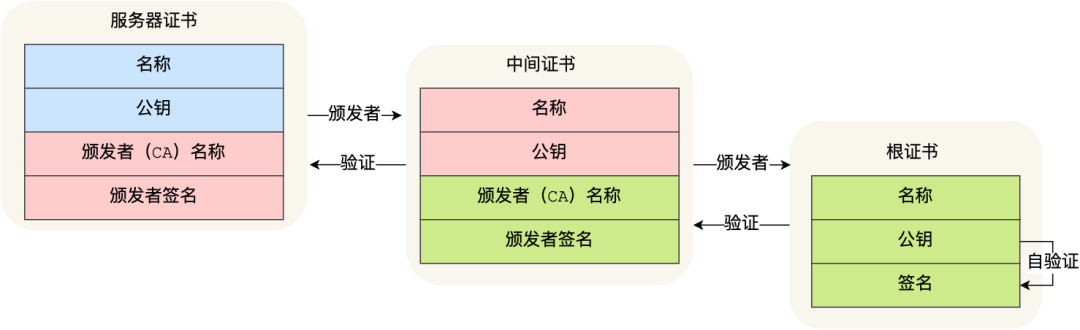
证书链
但事实上,证书的验证过程中还存在一个证书信任链的问题,因为我们向 CA 申请的证书一般不是根证书签发的,而是由中间证书签发的,比如百度的证书,从下图你可以看到,证书的层级有三级:
对于这种三级层级关系的证书的验证过程如下:
- 客户端收到 baidu.com 的证书后,发现这个证书的签发者不是根证书,就无法根据本地已有的根证书中的公钥去验证 baidu.com 证书是否可信。于是,客户端根据 baidu.com 证书中的签发者,找到该证书的颁发机构是 “GlobalSign Organization Validation CA - SHA256 - G2”,然后向 CA 请求该中间证书。
- 请求到证书后发现 “GlobalSign Organization Validation CA - SHA256 - G2” 证书是由 “GlobalSign Root CA” 签发的,由于 “GlobalSign Root CA” 没有再上级签发机构,说明它是根证书,也就是自签证书。应用软件会检查此证书有否已预载于根证书清单上,如果有,则可以利用根证书中的公钥去验证 “GlobalSign Organization Validation CA - SHA256 - G2” 证书,如果发现验证通过,就认为该中间证书是可信的。
- “GlobalSign Organization Validation CA - SHA256 - G2” 证书被信任后,可以使用 “GlobalSign Organization Validation CA - SHA256 - G2” 证书中的公钥去验证 baidu.com 证书的可信性,如果验证通过,就可以信任 baidu.com 证书。
在这四个步骤中,最开始客户端只信任根证书 GlobalSign Root CA 证书的,然后 “GlobalSign Root CA” 证书信任 “GlobalSign Organization Validation CA - SHA256 - G2” 证书,而 “GlobalSign Organization Validation CA - SHA256 - G2” 证书又信任 baidu.com 证书,于是客户端也信任 baidu.com 证书。
总括来说,由于用户信任 GlobalSign,所以由 GlobalSign 所担保的 baidu.com 可以被信任,另外由于用户信任操作系统或浏览器的软件商,所以由软件商预载了根证书的 GlobalSign 都可被信任。
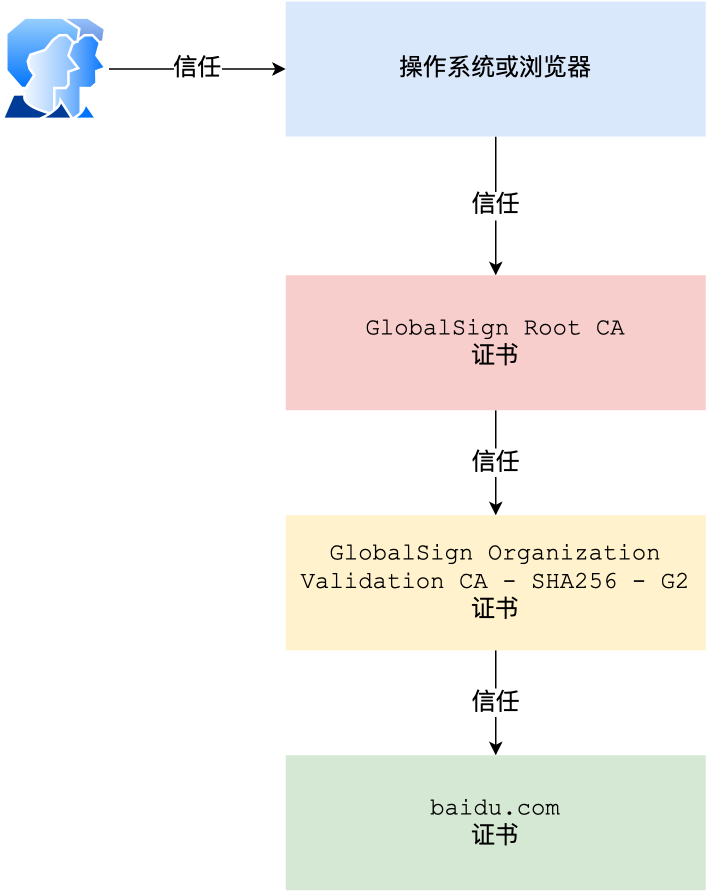
这样的一层层地验证就构成了一条信任链路,整个证书信任链验证流程如下图所示:
最后一个问题,为什么需要证书链这么麻烦的流程?Root CA 为什么不直接颁发证书,而是要搞那么多中间层级呢?
这是为了确保根证书的绝对安全性,将根证书隔离地越严格越好,不然根证书如果失守了,那么整个信任链都会有问题。
TLS 第三次握手
客户端验证完证书后,认为可信则继续往下走。接着,客户端就会生成一个新的随机数 (pre-master),用服务器的 RSA 公钥加密该随机数,通过「Change Cipher Key Exchange」消息传给服务端。
服务端收到后,用 RSA 私钥解密,得到客户端发来的随机数 (pre-master)。
至此,客户端和服务端双方都共享了三个随机数,分别是 Client Random、Server Random、pre-master。
于是,双方根据已经得到的三个随机数,生成会话密钥(Master Secret),它是对称密钥,用于对后续的 HTTP 请求/响应的数据加解密。
生成完会话密钥后,然后客户端发一个「Change Cipher Spec」,告诉服务端开始使用加密方式发送消息。

然后,客户端再发一个「Encrypted Handshake Message(Finishd)」消息,把之前所有发送的数据做个摘要,再用会话密钥(master secret)加密一下,让服务器做个验证,验证加密通信是否可用和之前握手信息是否有被中途篡改过。

可以发现,「Change Cipher Spec」之前传输的 TLS 握手数据都是明文,之后都是对称密钥加密的密文。
TLS 第四次握手
服务器也是同样的操作,发「Change Cipher Spec」和「Encrypted Handshake Message」消息,如果双方都验证加密和解密没问题,那么握手正式完成。
最后,就用「会话密钥」加解密 HTTP 请求和响应了。
RSA 算法的缺陷
使用 RSA 密钥协商算法的最大问题是不支持前向保密。因为客户端传递随机数(用于生成对称加密密钥的条件之一)给服务端时使用的是公钥加密的,服务端收到后,会用私钥解密得到随机数。所以一旦服务端的私钥泄漏了,过去被第三方截获的所有 TLS 通讯密文都会被破解。
为了解决这一问题,于是就有了 DH 密钥协商算法,这里简单介绍它的工作流程。
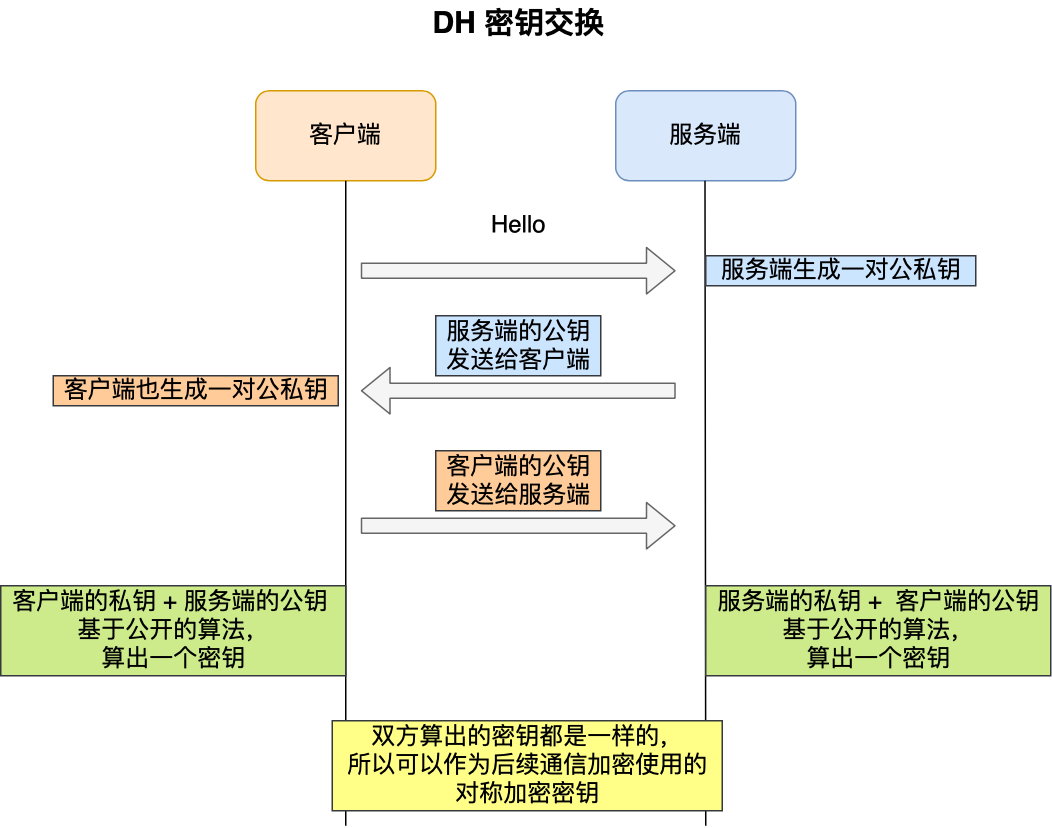
客户端和服务端各自会生成随机数,并以此作为私钥,然后根据公开的 DH 计算公示算出各自的公钥,通过 TLS 握手双方交换各自的公钥,这样双方都有自己的私钥和对方的公钥,然后双方根据各自持有的材料算出一个随机数,这个随机数的值双方都是一样的,这就可以作为后续对称加密时使用的密钥。
DH 密钥交换过程中,即使第三方截获了 TLS 握手阶段传递的公钥,在不知道的私钥的情况下,也是无法计算出密钥的,而且每一次对称加密密钥都是实时生成的,实现前向保密。
但因为 DH 算法的计算效率问题,后面出现了 ECDHE 密钥协商算法,我们现在大多数网站使用的正是 ECDHE 密钥协商算法。
RegExp对象
RegExp对象提供的正则表达式的功能
概述
正则表达式一种表达文本模式的方法,也就是按照给定的模式进行文本的匹配。
新建表达式的两种方法
字面量法
以斜杠表示开始和结束。
var regex=/xyz/;
RegExpg构造函数
var regex = new RegExp('xyz');
上面两种写法是等价的,主要区别在于字面量方法在引擎编译时就会新建正则表达式,第二种构造函数是在运行时新建正则表达式,所以字面量的方法效率较高。
RegExp构造函数还可以接受第二个参数,表示修饰符(详细解释见下文)。
var regex = new RegExp('xyz', 'i');
// 等价于
var regex = /xyz/i;
上面代码中,正则表达式/xyz/有一个修饰符i。
实例属性
正则对象的实例属性分成两类。
一类是修饰符相关,用于了解设置了什么修饰符。
RegExp.prototype.ignoreCase:返回一个布尔值,表示是否设置了i修饰符。RegExp.prototype.global:返回一个布尔值,表示是否设置了g修饰符。RegExp.prototype.multiline:返回一个布尔值,表示是否设置了m修饰符。RegExp.prototype.flags:返回一个字符串,包含了已经设置的所有修饰符,按字母排序。
上面四个属性都是只读的。
var r = /abc/igm;
r.ignoreCase // true
r.global // true
r.multiline // true
r.flags // 'gim'
另一类是与修饰符无关的属性,主要是下面两个。
RegExp.prototype.lastIndex:返回一个整数,表示下一次开始搜索的位置。该属性可读写,但是只在进行连续搜索时有意义,详细介绍请看后文。RegExp.prototype.source:返回正则表达式的字符串形式(不包括反斜杠),该属性只读。
var r = /abc/igm;
r.lastIndex // 0
r.source // "abc"
实例方法
RegExp.prototype.test()
正则实例对象的test方法返回一个布尔值,表示当前模式是否能匹配参数字符串。
/cat/.test('cats and dogs') // true
如果正则表达式带有g修饰符,则每一次test方法都从上一次结束的位置开始向后匹配。
var r = /x/g;
var s = '_x_x';
r.lastIndex // 0
r.test(s) // true
r.lastIndex // 2
r.test(s) // true
r.lastIndex // 4
r.test(s) // false
上面代码的正则表达式使用了g修饰符,表示是全局搜索,会有多个结果。接着,三次使用test方法,每一次开始搜索的位置都是上一次匹配的后一个位置。
带有g修饰符时,可以通过正则对象的lastIndex属性指定开始搜索的位置。
var r = /x/g;
var s = '_x_x';
r.lastIndex = 4;
r.test(s) // false
r.lastIndex // 0
r.test(s)
上面代码指定从字符串的第五个位置开始搜索,这个位置为空,所以返回false。同时,lastIndex属性重置为0,所以第二次执行r.test(s)会返回true。
注意,带有g修饰符时,正则表达式内部会记住上一次的lastIndex属性,这时不应该更换所要匹配的字符串,否则会有一些难以察觉的错误。
var r = /bb/g;
r.test('bb') // true
r.test('-bb-') // false
上面代码中,由于正则表达式r是从上一次的lastIndex位置开始匹配,导致第二次执行test方法时出现预期以外的结果。
lastIndex属性只对同一个正则表达式有效,所以下面这样写是错误的。
var count = 0;
while (/a/g.test('babaa')) count++;
上面代码会导致无限循环,因为while循环的每次匹配条件都是一个新的正则表达式,导致lastIndex属性总是等于0。
如果正则模式是一个空字符串,则匹配所有字符串。
new RegExp('').test('abc')
// true
RegExp.prototype.exec()
正则实例对象的exec()方法,用来返回匹配结果。如果发现匹配,就返回一个数组,成员是匹配成功的子字符串,否则返回null。
var s = '_x_x';
var r1 = /x/;
var r2 = /y/;
r1.exec(s) // ["x"]
r2.exec(s) // null
上面代码中,正则对象r1匹配成功,返回一个数组,成员是匹配结果;正则对象r2匹配失败,返回null。
如果正则表示式包含圆括号(即含有“组匹配”),则返回的数组会包括多个成员。第一个成员是整个匹配成功的结果,后面的成员就是圆括号对应的匹配成功的组。也就是说,第二个成员对应第一个括号,第三个成员对应第二个括号,以此类推。整个数组的length属性等于组匹配的数量再加1。
var s = '_x_x';
var r = /_(x)/;
r.exec(s) // ["_x", "x"]
上面代码的exec()方法,返回一个数组。第一个成员是整个匹配的结果,第二个成员是圆括号匹配的结果。
exec()方法的返回数组还包含以下两个属性:
input:整个原字符串。index:模式匹配成功的开始位置(从0开始计数)。
var r = /a(b+)a/;
var arr = r.exec('_abbba_aba_');
arr // ["abbba", "bbb"]
arr.index // 1
arr.input // "_abbba_aba_"
上面代码中的index属性等于1,是因为从原字符串的第二个位置开始匹配成功。
如果正则表达式加上g修饰符,则可以使用多次exec()方法,下一次搜索的位置从上一次匹配成功结束的位置开始。
var reg = /a/g;
var str = 'abc_abc_abc'
var r1 = reg.exec(str);
r1 // ["a"]
r1.index // 0
reg.lastIndex // 1
var r2 = reg.exec(str);
r2 // ["a"]
r2.index // 4
reg.lastIndex // 5
var r3 = reg.exec(str);
r3 // ["a"]
r3.index // 8
reg.lastIndex // 9
var r4 = reg.exec(str);
r4 // null
reg.lastIndex // 0
上面代码连续用了四次exec()方法,前三次都是从上一次匹配结束的位置向后匹配。当第三次匹配结束以后,整个字符串已经到达尾部,匹配结果返回null,正则实例对象的lastIndex属性也重置为0,意味着第四次匹配将从头开始。
字符串的实例方法
字符串的实例方法之中,有4种与正则表达式有关。
String.prototype.match():返回一个数组,成员是所有匹配的子字符串。String.prototype.search():按照给定的正则表达式进行搜索,返回一个整数,表示匹配开始的位置。String.prototype.replace():按照给定的正则表达式进行替换,返回替换后的字符串。String.prototype.split():按照给定规则进行字符串分割,返回一个数组,包含分割后的各个成员。
String.prototype.match()
字符串实例对象的match方法对字符串进行正则匹配,返回匹配结果。
var s = '_x_x';
var r1 = /x/;
var r2 = /y/;
s.match(r1) // ["x"]
s.match(r2) // null
从上面代码可以看到,字符串的match方法与正则对象的exec方法非常类似:匹配成功返回一个数组,匹配失败返回null。
如果正则表达式带有g修饰符,则该方法与正则对象的exec方法行为不同,会一次性返回所有匹配成功的结果。
var s = 'abba';
var r = /a/g;
s.match(r) // ["a", "a"]
r.exec(s) // ["a"]
设置正则表达式的lastIndex属性,对match方法无效,匹配总是从字符串的第一个字符开始。
String.prototype.search()
字符串对象的search方法,返回第一个满足条件的匹配结果在整个字符串中的位置。如果没有任何匹配,则返回-1。
'_x_x'.search(/x/)
// 1
String.prototype.replace()
字符串对象的replace方法可以替换匹配的值。它接受两个参数,第一个是正则表达式,表示搜索模式,第二个是替换的内容。
str.replace(search, replacement)
正则表达式如果不加g修饰符,就替换第一个匹配成功的值,否则替换所有匹配成功的值。
'aaa'.replace('a', 'b') // "baa"
'aaa'.replace(/a/, 'b') // "baa"
'aaa'.replace(/a/g, 'b') // "bbb"
上面代码中,最后一个正则表达式使用了g修饰符,导致所有的a都被替换掉了。
replace方法的一个应用,就是消除字符串首尾两端的空格。
var str = ' #id div.class ';
str.replace(/^\s+|\s+$/g, '')
// "#id div.class"
replace方法的第二个参数可以使用美元符号$,用来指代所替换的内容。
$&:匹配的子字符串。$`:匹配结果前面的文本。$':匹配结果后面的文本。$n:匹配成功的第n组内容,n是从1开始的自然数。$$:指代美元符号$。
'hello world'.replace(/(\w+)\s(\w+)/, '$2 $1')
// "world hello"
'abc'.replace('b', '[$`-$&-$\']')
// "a[a-b-c]c"
上面代码中,第一个例子是将匹配的组互换位置,第二个例子是改写匹配的值。
String.prototype.split()
字符串对象的split方法按照正则规则分割字符串,返回一个由分割后的各个部分组成的数组。
str.split(separator, [limit])
该方法接受两个参数,第一个参数是正则表达式,表示分隔规则,第二个参数是返回数组的最大成员数。
// 非正则分隔
'a, b,c, d'.split(',')
// [ 'a', ' b', 'c', ' d' ]
// 正则分隔,去除多余的空格
'a, b,c, d'.split(/, */)
// [ 'a', 'b', 'c', 'd' ]
// 指定返回数组的最大成员
'a, b,c, d'.split(/, */, 2)
[ 'a', 'b' ]
上面代码使用正则表达式,去除了子字符串的逗号后面的空格。
// 例一
'aaa*a*'.split(/a*/)
// [ '', '*', '*' ]
// 例二
'aaa**a*'.split(/a*/)
// ["", "*", "*", "*"]
上面代码的分割规则是0次或多次的a,由于正则默认是贪婪匹配,所以例一的第一个分隔符是aaa,第二个分割符是a,将字符串分成三个部分,包含开始处的空字符串。例二的第一个分隔符是aaa,第二个分隔符是0个a(即空字符),第三个分隔符是a,所以将字符串分成四个部分。
如果正则表达式带有括号,则括号匹配的部分也会作为数组成员返回。
'aaa*a*'.split(/(a*)/)
// [ '', 'aaa', '*', 'a', '*' ]
上面代码的正则表达式使用了括号,第一个组匹配是aaa,第二个组匹配是a,它们都作为数组成员返回。
匹配规则
正则表达式的规则很复杂,下面一一介绍这些规则。
字面量字符和元字符
大部分字符在正则表达式中,就是字面的含义,比如/a/匹配a,/b/匹配b。如果在正则表达式之中,某个字符只表示它字面的含义(就像前面的a和b),那么它们就叫做“字面量字符”(literal characters)。
/dog/.test('old dog') // true
上面代码中正则表达式的dog,就是字面量字符,所以/dog/匹配old dog,因为它就表示d、o、g三个字母连在一起。
除了字面量字符以外,还有一部分字符有特殊含义,不代表字面的意思。它们叫做“元字符”(metacharacters),主要有以下几个。
(1)点字符(.)
点字符(.)匹配除回车(\r)、换行(\n) 、行分隔符(\u2028)和段分隔符(\u2029)以外的所有字符。注意,对于码点大于0xFFFF字符,点字符不能正确匹配,会认为这是两个字符。
/c.t/
上面代码中,c.t匹配c和t之间包含任意一个字符的情况,只要这三个字符在同一行,比如cat、c2t、c-t等等,但是不匹配coot。
(2)位置字符
位置字符用来提示字符所处的位置,主要有两个字符。
^表示字符串的开始位置$表示字符串的结束位置
// test必须出现在开始位置
/^test/.test('test123') // true
// test必须出现在结束位置
/test$/.test('new test') // true
// 从开始位置到结束位置只有test
/^test$/.test('test') // true
/^test$/.test('test test') // false
(3)选择符(|)
竖线符号(|)在正则表达式中表示“或关系”(OR),即cat|dog表示匹配cat或dog。
/11|22/.test('911') // true
上面代码中,正则表达式指定必须匹配11或22。
多个选择符可以联合使用。
// 匹配fred、barney、betty之中的一个
/fred|barney|betty/
选择符会包括它前后的多个字符,比如/ab|cd/指的是匹配ab或者cd,而不是指匹配b或者c。如果想修改这个行为,可以使用圆括号。
/a( |\t)b/.test('a\tb') // true
上面代码指的是,a和b之间有一个空格或者一个制表符。
其他的元字符还包括\、*、+、?、()、[]、{}等,将在下文解释。
转义符
正则表达式中那些有特殊含义的元字符,如果要匹配它们本身,就需要在它们前面要加上反斜杠。比如要匹配+,就要写成\+。
/1+1/.test('1+1')
// false
/1\+1/.test('1+1')
// true
上面代码中,第一个正则表达式之所以不匹配,因为加号是元字符,不代表自身。第二个正则表达式使用反斜杠对加号转义,就能匹配成功。
正则表达式中,需要反斜杠转义的,一共有12个字符:^、.、[、$、(、)、|、*、+、?、{和\。需要特别注意的是,如果使用RegExp方法生成正则对象,转义需要使用两个斜杠,因为字符串内部会先转义一次。
(new RegExp('1\+1')).test('1+1')
// false
(new RegExp('1\\+1')).test('1+1')
// true
上面代码中,RegExp作为构造函数,参数是一个字符串。但是,在字符串内部,反斜杠也是转义字符,所以它会先被反斜杠转义一次,然后再被正则表达式转义一次,因此需要两个反斜杠转义。
特殊字符
正则表达式对一些不能打印的特殊字符,提供了表达方法。
\cX表示Ctrl-[X],其中的X是A-Z之中任一个英文字母,用来匹配控制字符。[\b]匹配退格键(U+0008),不要与\b混淆。\n匹配换行键。\r匹配回车键。\t匹配制表符 tab(U+0009)。\v匹配垂直制表符(U+000B)。\f匹配换页符(U+000C)。\0匹配null字符(U+0000)。\xhh匹配一个以两位十六进制数(\x00-\xFF)表示的字符。\uhhhh匹配一个以四位十六进制数(\u0000-\uFFFF)表示的 Unicode 字符。
字符类
字符类(class)表示有一系列字符可供选择,只要匹配其中一个就可以了。所有可供选择的字符都放在方括号内,比如[xyz] 表示x、y、z之中任选一个匹配。
/[abc]/.test('hello world') // false
/[abc]/.test('apple') // true
上面代码中,字符串hello world不包含a、b、c这三个字母中的任一个,所以返回false;字符串apple包含字母a,所以返回true。
有两个字符在字符类中有特殊含义。
(1)脱字符(^)
如果方括号内的第一个字符是[^],则表示除了字符类之中的字符,其他字符都可以匹配。比如,[^xyz]表示除了x、y、z之外都可以匹配。
/[^abc]/.test('bbc news') // true
/[^abc]/.test('bbc') // false
上面代码中,字符串bbc news包含a、b、c以外的其他字符,所以返回true;字符串bbc不包含a、b、c以外的其他字符,所以返回false。
如果方括号内没有其他字符,即只有[^],就表示匹配一切字符,其中包括换行符。相比之下,点号作为元字符(.)是不包括换行符的。
var s = 'Please yes\nmake my day!';
s.match(/yes.*day/) // null
s.match(/yes[^]*day/) // [ 'yes\nmake my day']
上面代码中,字符串s含有一个换行符,点号不包括换行符,所以第一个正则表达式匹配失败;第二个正则表达式[^]包含一切字符,所以匹配成功。
注意,脱字符只有在字符类的第一个位置才有特殊含义,否则就是字面含义。
(2)连字符(-)
某些情况下,对于连续序列的字符,连字符(-)用来提供简写形式,表示字符的连续范围。比如,[abc]可以写成[a-c],[0123456789]可以写成[0-9],同理[A-Z]表示26个大写字母。
/a-z/.test('b') // false
/[a-z]/.test('b') // true
上面代码中,当连字号(dash)不出现在方括号之中,就不具备简写的作用,只代表字面的含义,所以不匹配字符b。只有当连字号用在方括号之中,才表示连续的字符序列。
以下都是合法的字符类简写形式。
[0-9.,]
[0-9a-fA-F]
[a-zA-Z0-9-]
[1-31]
上面代码中最后一个字符类[1-31],不代表1到31,只代表1到3。
连字符还可以用来指定 Unicode 字符的范围。
var str = "\u0130\u0131\u0132";
/[\u0128-\uFFFF]/.test(str)
// true
上面代码中,\u0128-\uFFFF表示匹配码点在0128到FFFF之间的所有字符。
另外,不要过分使用连字符,设定一个很大的范围,否则很可能选中意料之外的字符。最典型的例子就是[A-z],表面上它是选中从大写的A到小写的z之间52个字母,但是由于在 ASCII 编码之中,大写字母与小写字母之间还有其他字符,结果就会出现意料之外的结果。
/[A-z]/.test('\\') // true
上面代码中,由于反斜杠(‘\’)的ASCII码在大写字母与小写字母之间,结果会被选中。
预定义模式
预定义模式指的是某些常见模式的简写方式。
\d匹配0-9之间的任一数字,相当于[0-9]。\D匹配所有0-9以外的字符,相当于[^0-9]。\w匹配任意的字母、数字和下划线,相当于[A-Za-z0-9_]。\W除所有字母、数字和下划线以外的字符,相当于[^A-Za-z0-9_]。\s匹配空格(包括换行符、制表符、空格符等),相等于[ \t\r\n\v\f]。\S匹配非空格的字符,相当于[^ \t\r\n\v\f]。\b匹配词的边界。\B匹配非词边界,即在词的内部。
下面是一些例子。
// \s 的例子
/\s\w*/.exec('hello world') // [" world"]
// \b 的例子
/\bworld/.test('hello world') // true
/\bworld/.test('hello-world') // true
/\bworld/.test('helloworld') // false
// \B 的例子
/\Bworld/.test('hello-world') // false
/\Bworld/.test('helloworld') // true
上面代码中,\s表示空格,所以匹配结果会包括空格。\b表示词的边界,所以world的词首必须独立(词尾是否独立未指定),才会匹配。同理,\B表示非词的边界,只有world的词首不独立,才会匹配。
通常,正则表达式遇到换行符(\n)就会停止匹配。
var html = "<b>Hello</b>\n<i>world!</i>";
/.*/.exec(html)[0]
// "<b>Hello</b>"
上面代码中,字符串html包含一个换行符,结果点字符(.)不匹配换行符,导致匹配结果可能不符合原意。这时使用\s字符类,就能包括换行符。
var html = "<b>Hello</b>\n<i>world!</i>";
/[\S\s]*/.exec(html)[0]
// "<b>Hello</b>\n<i>world!</i>"
上面代码中,[\S\s]指代一切字符。
重复类
模式的精确匹配次数,使用大括号({})表示。{n}表示恰好重复n次,{n,}表示至少重复n次,{n,m}表示重复不少于n次,不多于m次。
/lo{2}k/.test('look') // true
/lo{2,5}k/.test('looook') // true
上面代码中,第一个模式指定o连续出现2次,第二个模式指定o连续出现2次到5次之间。
量词符
量词符用来设定某个模式出现的次数。
?问号表示某个模式出现0次或1次,等同于{0, 1}。*星号表示某个模式出现0次或多次,等同于{0,}。+加号表示某个模式出现1次或多次,等同于{1,}。
// t 出现0次或1次
/t?est/.test('test') // true
/t?est/.test('est') // true
// t 出现1次或多次
/t+est/.test('test') // true
/t+est/.test('ttest') // true
/t+est/.test('est') // false
// t 出现0次或多次
/t*est/.test('test') // true
/t*est/.test('ttest') // true
/t*est/.test('tttest') // true
/t*est/.test('est') // true
贪婪模式
上一小节的三个量词符,默认情况下都是最大可能匹配,即匹配到下一个字符不满足匹配规则为止。这被称为贪婪模式。
var s = 'aaa';
s.match(/a+/) // ["aaa"]
上面代码中,模式是/a+/,表示匹配1个a或多个a,那么到底会匹配几个a呢?因为默认是贪婪模式,会一直匹配到字符a不出现为止,所以匹配结果是3个a。
除了贪婪模式,还有非贪婪模式,即最小可能匹配。只要一发现匹配,就返回结果,不要往下检查。如果想将贪婪模式改为非贪婪模式,可以在量词符后面加一个问号。
var s = 'aaa';
s.match(/a+?/) // ["a"]
上面例子中,模式结尾添加了一个问号/a+?/,这时就改为非贪婪模式,一旦条件满足,就不再往下匹配,+?表示只要发现一个a,就不再往下匹配了。
除了非贪婪模式的加号(+?),还有非贪婪模式的星号(*?)和非贪婪模式的问号(??)。
+?:表示某个模式出现1次或多次,匹配时采用非贪婪模式。*?:表示某个模式出现0次或多次,匹配时采用非贪婪模式。??:表格某个模式出现0次或1次,匹配时采用非贪婪模式。
'abb'.match(/ab*/) // ["abb"]
'abb'.match(/ab*?/) // ["a"] *表示匹配0次或多次 *后面跟?相当于匹配0次b,也就是不匹配b
'abb'.match(/ab?/) // ["ab"]
'abb'.match(/ab??/) // ["a"] ?表示匹配0次或1次 两个?也就是尽可能少b,也就是不匹配b
上面例子中,/ab*/表示如果a后面有多个b,那么匹配尽可能多的b;/ab*?/表示匹配尽可能少的b,也就是0个b。
修饰符
修饰符(modifier)表示模式的附加规则,放在正则模式的最尾部。
修饰符可以单个使用,也可以多个一起使用。
// 单个修饰符
var regex = /test/i;
// 多个修饰符
var regex = /test/ig;
(1)g 修饰符
默认情况下,第一次匹配成功后,正则对象就停止向下匹配了。g修饰符表示全局匹配(global),加上它以后,正则对象将匹配全部符合条件的结果,主要用于搜索和替换。
var regex = /b/;
var str = 'abba';
regex.test(str); // true
regex.test(str); // true
regex.test(str); // true
上面代码中,正则模式不含g修饰符,每次都是从字符串头部开始匹配。所以,连续做了三次匹配,都返回true。
var regex = /b/g;
var str = 'abba';
regex.test(str); // true
regex.test(str); // true
regex.test(str); // false
上面代码中,正则模式含有g修饰符,每次都是从上一次匹配成功处,开始向后匹配。因为字符串abba只有两个b,所以前两次匹配结果为true,第三次匹配结果为false。
(2)i 修饰符
默认情况下,正则对象区分字母的大小写,加上i修饰符以后表示忽略大小写(ignoreCase)。
/abc/.test('ABC') // false
/abc/i.test('ABC') // true
上面代码表示,加了i修饰符以后,不考虑大小写,所以模式abc匹配字符串ABC。
(3)m 修饰符
m修饰符表示多行模式(multiline),会修改^和$的行为。默认情况下(即不加m修饰符时),^和$匹配字符串的开始处和结尾处,加上m修饰符以后,^和$还会匹配行首和行尾,即^和$会识别换行符(\n)。
/world$/.test('hello world\n') // false
/world$/m.test('hello world\n') // true
上面的代码中,字符串结尾处有一个换行符。如果不加m修饰符,匹配不成功,因为字符串的结尾不是world;加上以后,$可以匹配行尾。
/^b/m.test('a\nb') // true
上面代码要求匹配行首的b,如果不加m修饰符,就相当于b只能处在字符串的开始处。加上m修饰符以后,换行符\n也会被认为是一行的开始。
组匹配
(1)概述
正则表达式的括号表示分组匹配,括号中的模式可以用来匹配分组的内容。
/fred+/.test('fredd') // true
/(fred)+/.test('fredfred') // true
上面代码中,第一个模式没有括号,结果+只表示重复字母d,第二个模式有括号,结果+就表示匹配fred这个词。
下面是另外一个分组捕获的例子。
var m = 'abcabc'.match(/(.)b(.)/);
m
// ['abc', 'a', 'c']
上面代码中,正则表达式/(.)b(.)/一共使用两个括号,第一个括号捕获a,第二个括号捕获c。
注意,使用组匹配时,不宜同时使用g修饰符,否则match方法不会捕获分组的内容。
var m = 'abcabc'.match(/(.)b(.)/g);
m // ['abc', 'abc']
上面代码使用带g修饰符的正则表达式,结果match方法只捕获了匹配整个表达式的部分。这时必须使用正则表达式的exec方法,配合循环,才能读到每一轮匹配的组捕获。
var str = 'abcabc';
var reg = /(.)b(.)/g;
while (true) {
var result = reg.exec(str);
if (!result) break;
console.log(result);
}
// ["abc", "a", "c"]
// ["abc", "a", "c"]
正则表达式内部,还可以用\n引用括号匹配的内容,n是从1开始的自然数,表示对应顺序的括号。
/(.)b(.)\1b\2/.test("abcabc")
// true
上面的代码中,\1表示第一个括号匹配的内容(即a),\2表示第二个括号匹配的内容(即c)。
下面是另外一个例子。
/y(..)(.)\2\1/.test('yabccab') // true
括号还可以嵌套。
/y((..)\2)\1/.test('yabababab') // true
上面代码中,\1指向外层括号,\2指向内层括号。
组匹配非常有用,下面是一个匹配网页标签的例子。
var tagName = /<([^>]+)>[^<]*<\/\1>/;
tagName.exec("<b>bold</b>")[1]
// 'b'
上面代码中,圆括号匹配尖括号之中的标签,而\1就表示对应的闭合标签。
上面代码略加修改,就能捕获带有属性的标签。
var html = '<b class="hello">Hello</b><i>world</i>';
var tag = /<(\w+)([^>]*)>(.*?)<\/\1>/g;
var match = tag.exec(html);
match[1] // "b"
match[2] // " class="hello""
match[3] // "Hello"
match = tag.exec(html);
match[1] // "i"
match[2] // ""
match[3] // "world"
(2)非捕获组
(?:x)称为非捕获组(Non-capturing group),表示不返回该组匹配的内容,即匹配的结果中不计入这个括号。
非捕获组的作用请考虑这样一个场景,假定需要匹配foo或者foofoo,正则表达式就应该写成/(foo){1, 2}/,但是这样会占用一个组匹配。这时,就可以使用非捕获组,将正则表达式改为/(?:foo){1, 2}/,它的作用与前一个正则是一样的,但是不会单独输出括号内部的内容。
请看下面的例子。
var m = 'abc'.match(/(?:.)b(.)/);
m // ["abc", "c"]
上面代码中的模式,一共使用了两个括号。其中第一个括号是非捕获组,所以最后返回的结果中没有第一个括号,只有第二个括号匹配的内容。
下面是用来分解网址的正则表达式。
// 正常匹配
var url = /(http|ftp):\/\/([^/\r\n]+)(\/[^\r\n]*)?/;
url.exec('http://google.com/');
// ["http://google.com/", "http", "google.com", "/"]
// 非捕获组匹配
var url = /(?:http|ftp):\/\/([^/\r\n]+)(\/[^\r\n]*)?/;
url.exec('http://google.com/');
// ["http://google.com/", "google.com", "/"]
上面的代码中,前一个正则表达式是正常匹配,第一个括号返回网络协议;后一个正则表达式是非捕获匹配,返回结果中不包括网络协议。
(3)先行断言
x(?=y)称为先行断言(Positive look-ahead),x只有在y前面才匹配,y不会被计入返回结果。比如,要匹配后面跟着百分号的数字,可以写成/\d+(?=%)/。
“先行断言”中,括号里的部分是不会返回的。
var m = 'abc'.match(/b(?=c)/);
m // ["b"]
上面的代码使用了先行断言,b在c前面所以被匹配,但是括号对应的c不会被返回。
(4)先行否定断言
x(?!y)称为先行否定断言(Negative look-ahead),x只有不在y前面才匹配,y不会被计入返回结果。比如,要匹配后面跟的不是百分号的数字,就要写成/\d+(?!%)/。
/\d+(?!\.)/.exec('3.14')
// ["14"]
上面代码中,正则表达式指定,只有不在小数点前面的数字才会被匹配,因此返回的结果就是14。
“先行否定断言”中,括号里的部分是不会返回的。
var m = 'abd'.match(/b(?!c)/);
m // ['b']
上面的代码使用了先行否定断言,b不在c前面所以被匹配,而且括号对应的d不会被返回。
实例对象与 new 命令
对象是什么
(1)对象是单个实物的抽象。
一本书、一辆汽车、一个人都可以是对象,一个数据库、一张网页、一个远程服务器连接也可以是对象。当实物被抽象成对象,实物之间的关系就变成了对象之间的关系,从而就可以模拟现实情况,针对对象进行编程。
(2)对象是一个容器,封装了属性(property)和方法(method)。
属性是对象的状态,方法是对象的行为(完成某种任务)。比如,我们可以把动物抽象为animal对象,使用“属性”记录具体是哪一种动物,使用“方法”表示动物的某种行为(奔跑、捕猎、休息等等)。
构造函数
面向对象编程的第一步,就是要生成对象。前面说过,对象是单个实物的抽象。通常需要一个模板,表示某一类实物的共同特征,然后对象根据这个模板生成。
典型的面向对象编程语言(比如 C++ 和 Java),都有“类”(class)这个概念。所谓“类”就是对象的模板,对象就是“类”的实例。但是,JavaScript 语言的对象体系,不是基于“类”的,而是基于构造函数(constructor)和原型链(prototype)。
JavaScript 语言使用构造函数(constructor)作为对象的模板。所谓”构造函数”,就是专门用来生成实例对象的函数。它就是对象的模板,描述实例对象的基本结构。一个构造函数,可以生成多个实例对象,这些实例对象都有相同的结构。
构造函数就是一个普通的函数,但具有自己的特征和用法。
var Vehicle = function () {
this.price = 1000;
};
上面代码中,Vehicle就是构造函数。为了与普通函数区别,构造函数名字的第一个字母通常大写。
构造函数的特点有两个。
- 函数体内部使用了
this关键字,代表了所要生成的对象实例。 - 生成对象的时候,必须使用
new命令。
new 命令
基本用法
new命令的作用,就是执行构造函数,返回一个实例对象。
var Vehicle = function () {
this.price = 1000;
};
var v = new Vehicle();
v.price // 1000
上面代码通过new命令,让构造函数Vehicle生成一个实例对象,保存在变量v中。这个新生成的实例对象,从构造函数Vehicle得到了price属性。new命令执行时,构造函数内部的this,就代表了新生成的实例对象,this.price表示实例对象有一个price属性,值是1000。
使用new命令时,根据需要,构造函数也可以接受参数。
var Vehicle = function (p) {
this.price = p;
};
var v = new Vehicle(500);
new命令本身就可以执行构造函数,所以后面的构造函数可以带括号,也可以不带括号。下面两行代码是等价的,但是为了表示这里是函数调用,推荐使用括号。
// 推荐的写法
var v = new Vehicle();
// 不推荐的写法
var v = new Vehicle;
一个很自然的问题是,如果忘了使用new命令,直接调用构造函数会发生什么事?
这种情况下,构造函数就变成了普通函数,并不会生成实例对象。而且由于后面会说到的原因,this这时代表全局对象,将造成一些意想不到的结果。
var Vehicle = function (){
this.price = 1000;
};
var v = Vehicle();
v // undefined
price // 1000
上面代码中,调用Vehicle构造函数时,忘了加上new命令。结果,变量v变成了undefined,而price属性变成了全局变量。因此,应该非常小心,避免不使用new命令、直接调用构造函数。
为了保证构造函数必须与new命令一起使用,一个解决办法是,构造函数内部使用严格模式,即第一行加上use strict。这样的话,一旦忘了使用new命令,直接调用构造函数就会报错。
function Fubar(foo, bar){
'use strict';
this._foo = foo;
this._bar = bar;
}
Fubar()
// TypeError: Cannot set property '_foo' of undefined
上面代码的Fubar为构造函数,use strict命令保证了该函数在严格模式下运行。由于严格模式中,函数内部的this不能指向全局对象,默认等于undefined,导致不加new调用会报错(JavaScript 不允许对undefined添加属性)。
另一个解决办法,构造函数内部判断是否使用new命令,如果发现没有使用,则直接返回一个实例对象。
function Fubar(foo, bar) {
if (!(this instanceof Fubar)) {
return new Fubar(foo, bar);
}
this._foo = foo;
this._bar = bar;
}
Fubar(1, 2)._foo // 1
(new Fubar(1, 2))._foo // 1
上面代码中的构造函数,不管加不加new命令,都会得到同样的结果。
new 命令的原理
使用new命令时,它后面的函数依次执行下面的步骤。
- 创建一个空对象,作为将要返回的对象实例。
- 将这个空对象的原型,指向构造函数的
prototype属性。 - 将这个空对象赋值给函数内部的
this关键字。 - 开始执行构造函数内部的代码。
也就是说,构造函数内部,this指的是一个新生成的空对象,所有针对this的操作,都会发生在这个空对象上。构造函数之所以叫“构造函数”,就是说这个函数的目的,就是操作一个空对象(即this对象),将其“构造”为需要的样子。
如果构造函数内部有return语句,而且return后面跟着一个对象,new命令会返回return语句指定的对象;否则,就会不管return语句,返回this对象。
var Vehicle = function () {
this.price = 1000;
return 1000;
};
(new Vehicle()) === 1000
// false
上面代码中,构造函数Vehicle的return语句返回一个数值。这时,new命令就会忽略这个return语句,返回“构造”后的this对象。
但是,如果return语句返回的是一个跟this无关的新对象,new命令会返回这个新对象,而不是this对象。这一点需要特别引起注意。
var Vehicle = function (){
this.price = 1000;
return { price: 2000 };
};
(new Vehicle()).price
// 2000
上面代码中,构造函数Vehicle的return语句,返回的是一个新对象。new命令会返回这个对象,而不是this对象。
另一方面,如果对普通函数(内部没有this关键字的函数)使用new命令,则会返回一个空对象。
function getMessage() {
return 'this is a message';
}
var msg = new getMessage();
msg // {}
typeof msg // "object"
上面代码中,getMessage是一个普通函数,返回一个字符串。对它使用new命令,会得到一个空对象。这是因为new命令总是返回一个对象,要么是实例对象,要么是return语句指定的对象。本例中,return语句返回的是字符串,所以new命令就忽略了该语句。
new命令简化的内部流程,可以用下面的代码表示。
function _new(/* 构造函数 */ constructor, /* 构造函数参数 */ params) {
// 将 arguments 对象转为数组
var args = [].slice.call(arguments);
// 取出构造函数
var constructor = args.shift();
// 创建一个空对象,继承构造函数的 prototype 属性
var context = Object.create(constructor.prototype);
// 执行构造函数
var result = constructor.apply(context, args);
// 如果返回结果是对象,就直接返回,否则返回 context 对象
return (typeof result === 'object' && result != null) ? result : context;
}
// 实例
var actor = _new(Person, '张三', 28);
new.target
函数内部可以使用new.target属性。如果当前函数是new命令调用,new.target指向当前函数,否则为undefined。
function f() {
console.log(new.target === f);
}
f() // false
new f() // true
使用这个属性,可以判断函数调用的时候,是否使用new命令。
function f() {
if (!new.target) {
throw new Error('请使用 new 命令调用!');
}
// ...
}
f() // Uncaught Error: 请使用 new 命令调用!
上面代码中,构造函数f调用时,没有使用new命令,就抛出一个错误。
Object.create() 创建实例对象
构造函数作为模板,可以生成实例对象。但是,有时拿不到构造函数,只能拿到一个现有的对象。我们希望以这个现有的对象作为模板,生成新的实例对象,这时就可以使用Object.create()方法。
var person1 = {
name: '张三',
age: 38,
greeting: function() {
console.log('Hi! I\'m ' + this.name + '.');
}
};
var person2 = Object.create(person1);
person2.name // 张三
person2.greeting() // Hi! I'm 张三.
上面代码中,对象person1是person2的模板,后者继承了前者的属性和方法。
JavaScript闭包和this
闭包
一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。
在JS中,通俗来讲,闭包就是能够读取外层函数内部变量的函数。
1.1 变量作用域
变量的作用域为两种:全局作用域和局部作用域
1)函数内部可以读取全局变量
let code = 200;
function f1() {
console.log(code);
}
f1(); // 200
2)函数外部无法读取函数内部的局部变量
function f1() {
let code = 200;
}
console.log(code); // Uncaught ReferenceError: code is not defined
1.2 读取函数内部的局部变量
1)在函数内部再定义一个函数
function f1() {
let code = 200;
function f2() {
console.log(code);
}
}
函数f1内部的函数f2可以读取f1中所有的局部变量。因此,若想在外部访问函数f1中的局部变量code,可通过函数f2间接访问。
2)为外部程序提供访问函数局部变量的入口
function f1() {
let code = 200;
function f2() {
console.log(code);
}
return f2;
}
f1()(); // 200
1.3 闭包概念
1.2中的函数f2,就是闭包,其作用就是将函数内部与函数外部进行连接。
- 闭包访问的变量,是每次运行上层函数时重新创建的,是相互独立的。
function f1() {
let obj = {};
function f2() {
return obj;
}
return f2;
}
let result1 = f1();
let result2 = f1();
console.log(result1() === result2()); // false
- 不同的闭包,可以共享上层函数中的局部变量
function f() {
let num = 0;
function f1() {
console.log(++num);
}
function f2() {
console.log(++num);
}
return {f1,
f2};
}
let result = f();
result.f1(); // 1
result.f2(); // 2
旅行者走路的问题
function factory() {
var start = 0
function walk(step) {
var new_total = start + step
start = new_total
return start
}
return walk
}
var res = factory()
res(1)
res(2)
res(3)
从结果可以看出,闭包f1和闭包f2共享上层函数中的局部变量num。
使用闭包的注意点:
1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
this 关键字
涵义
前面已经提到,this可以用在构造函数之中,表示实例对象。除此之外,this还可以用在别的场合。但不管是什么场合,this都有一个共同点:它总是返回一个对象。
简单说,this就是属性或方法“当前”所在的对象。
this.property
上面代码中,this就代表property属性当前所在的对象。
下面是一个实际的例子。
var person = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
person.describe()
// "姓名:张三"
上面代码中,this.name表示name属性所在的那个对象。由于this.name是在describe方法中调用,而describe方法所在的当前对象是person,因此this指向person,this.name就是person.name。
由于对象的属性可以赋给另一个对象,所以属性所在的当前对象是可变的,即this的指向是可变的。
var A = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
var B = {
name: '李四'
};
B.describe = A.describe;
B.describe()
// "姓名:李四"
上面代码中,A.describe属性被赋给B,于是B.describe就表示describe方法所在的当前对象是B,所以this.name就指向B.name。
稍稍重构这个例子,this的动态指向就能看得更清楚。
function f() {
return '姓名:'+ this.name;
}
var A = {
name: '张三',
describe: f
};
var B = {
name: '李四',
describe: f
};
A.describe() // "姓名:张三"
B.describe() // "姓名:李四"
上面代码中,函数f内部使用了this关键字,随着f所在的对象不同,this的指向也不同。
只要函数被赋给另一个变量,this的指向就会变。
var A = {
name: '张三',
describe: function () {
return '姓名:'+ this.name;
}
};
var name = '李四';
var f = A.describe;
f() // "姓名:李四"
上面代码中,A.describe被赋值给变量f,内部的this就会指向f运行时所在的对象(本例是顶层对象)。
总结一下,JavaScript 语言之中,一切皆对象,运行环境也是对象,所以函数都是在某个对象之中运行,this就是函数运行时所在的对象(环境)。这本来并不会让用户糊涂,但是 JavaScript 支持运行环境动态切换,也就是说,this的指向是动态的,没有办法事先确定到底指向哪个对象,这才是最让初学者感到困惑的地方。
实质
JavaScript 语言之所以有 this 的设计,跟内存里面的数据结构有关系。
var obj = { foo: 5 };
上面的代码将一个对象赋值给变量obj。JavaScript 引擎会先在内存里面,生成一个对象{ foo: 5 },然后把这个对象的内存地址赋值给变量obj。也就是说,变量obj是一个地址(reference)。后面如果要读取obj.foo,引擎先从obj拿到内存地址,然后再从该地址读出原始的对象,返回它的foo属性。
原始的对象以字典结构保存,每一个属性名都对应一个属性描述对象。举例来说,上面例子的foo属性,实际上是以下面的形式保存的。
{
foo: {
[[value]]: 5
[[writable]]: true
[[enumerable]]: true
[[configurable]]: true
}
}
注意,foo属性的值保存在属性描述对象的value属性里面。
这样的结构是很清晰的,问题在于属性的值可能是一个函数。
var obj = { foo: function () {} };
这时,引擎会将函数单独保存在内存中,然后再将函数的地址赋值给foo属性的value属性。
{
foo: {
[[value]]: 函数的地址
...
}
}
由于函数是一个单独的值,所以它可以在不同的环境(上下文)执行。
var f = function () {};
var obj = { f: f };
// 单独执行
f()
// obj 环境执行
obj.f()
JavaScript 允许在函数体内部,引用当前环境的其他变量。
var f = function () {
console.log(x);
};
上面代码中,函数体里面使用了变量x。该变量由运行环境提供。
现在问题就来了,由于函数可以在不同的运行环境执行,所以需要有一种机制,能够在函数体内部获得当前的运行环境(context)。所以,this就出现了,它的设计目的就是在函数体内部,指代函数当前的运行环境。
var f = function () {
console.log(this.x);
}
上面代码中,函数体里面的this.x就是指当前运行环境的x。
var f = function () {
console.log(this.x);
}
var x = 1;
var obj = {
f: f,
x: 2,
};
// 单独执行
f() // 1
// obj 环境执行
obj.f() // 2
上面代码中,函数f在全局环境执行,this.x指向全局环境的x;在obj环境执行,this.x指向obj.x。
使用场合
this主要有以下几个使用场合。
(1)全局环境
全局环境使用this,它指的就是顶层对象window。
this === window // true
function f() {
console.log(this === window);
}
f() // true
上面代码说明,不管是不是在函数内部,只要是在全局环境下运行,this就是指顶层对象window。
(2)构造函数
构造函数中的this,指的是实例对象。
var Obj = function (p) {
this.p = p;
};
上面代码定义了一个构造函数Obj。由于this指向实例对象,所以在构造函数内部定义this.p,就相当于定义实例对象有一个p属性。
var o = new Obj('Hello World!');
o.p // "Hello World!"
(3)对象的方法
如果对象的方法里面包含this,this的指向就是方法运行时所在的对象。该方法赋值给另一个对象,就会改变this的指向。
但是,这条规则很不容易把握。请看下面的代码。
var obj ={
foo: function () {
console.log(this);
}
};
obj.foo() // obj
上面代码中,obj.foo方法执行时,它内部的this指向obj。
但是,下面这几种用法,都会改变this的指向。
// 情况一
(obj.foo = obj.foo)() // window
// 情况二
(false || obj.foo)() // window
// 情况三
(1, obj.foo)() // window
上面代码中,obj.foo就是一个值。这个值真正调用的时候,运行环境已经不是obj了,而是全局环境,所以this不再指向obj。
可以这样理解,JavaScript 引擎内部,obj和obj.foo储存在两个内存地址,称为地址一和地址二。obj.foo()这样调用时,是从地址一调用地址二,因此地址二的运行环境是地址一,this指向obj。但是,上面三种情况,都是直接取出地址二进行调用,这样的话,运行环境就是全局环境,因此this指向全局环境。上面三种情况等同于下面的代码。
// 情况一
(obj.foo = function () {
console.log(this);
})()
// 等同于
(function () {
console.log(this);
})()
// 情况二
(false || function () {
console.log(this);
})()
// 情况三
(1, function () {
console.log(this);
})()
如果this所在的方法不在对象的第一层,这时this只是指向当前一层的对象,而不会继承更上面的层。
var a = {
p: 'Hello',
b: {
m: function() {
console.log(this.p);
}
}
};
a.b.m() // undefined
上面代码中,a.b.m方法在a对象的第二层,该方法内部的this不是指向a,而是指向a.b,因为实际执行的是下面的代码。
var b = {
m: function() {
console.log(this.p);
}
};
var a = {
p: 'Hello',
b: b
};
(a.b).m() // 等同于 b.m()
如果要达到预期效果,只有写成下面这样。
var a = {
b: {
m: function() {
console.log(this.p);
},
p: 'Hello'
}
};
如果这时将嵌套对象内部的方法赋值给一个变量,this依然会指向全局对象。
var a = {
b: {
m: function() {
console.log(this.p);
},
p: 'Hello'
}
};
var hello = a.b.m;
hello() // undefined
上面代码中,m是多层对象内部的一个方法。为求简便,将其赋值给hello变量,结果调用时,this指向了顶层对象。为了避免这个问题,可以只将m所在的对象赋值给hello,这样调用时,this的指向就不会变。
var hello = a.b;
hello.m() // Hello
箭头函数中的this
箭头函数中的this是定义函数时绑定的,而不是在执行函数时绑定。若箭头函数在简单对象中,由于简单对象没有执行上下文,所以this指向上层的执行上下文;若箭头函数在函数、类等有执行上下文的环境中,则this指向当前函数、类。
1)箭头函数在普通对象中
var code = 404;
let obj = {
code: 200,
getCode: () => {
console.log(this.code);
}
}
obj.getCode(); // 404
在箭头函数中,this 的值是在定义函数时确定的,而不是在运行时确定的。在这个例子中,箭头函数 getCode 是在对象 obj 定义时创建的,而不是在调用 obj.getCode() 的时候。
箭头函数中的 this 指向的是外层的词法作用域的 this 值,而不是指向调用它的对象。在全局作用域中,this 指向的是全局对象(在浏览器环境中通常是 window 对象)。所以,当箭头函数中使用 this.code 时,它实际上是引用全局作用域中的 code 变量,其值为 404。
2)箭头函数在函数中
var code = 404;
function F() {
this.code = 200;
let getCode = () => {
console.log(this.code);
};
getCode();
}
var f = new F() //200
var f = F() //构造函数没有new调用,就成为了一个普通函数
console.log(f)
console.log(code)
3)箭头函数在类中
var code = 404;
class Status {
constructor(code) {
this.code = code;
}
getCode = () => {
console.log(this.code);
};
}
let status = new Status(200);
status.getCode(); // 200
不管是箭头函数还是普通函数,只要是类中,this就指向实例对象。
样例详解
var code = 404;
let status = {
code : 200,
getCode : function() {
return function(){
return this.code;
};
}
};
console.log(status.getCode()()); // 404
行status.getCode()时,返回函数,status.getCode()()表示执行当前返回的函数,其调用者为全局变量window,所以this.code为绑定在window中的code,值为404。
var code = 404;
let status = {
code : 200,
getCode : function() {
let that = this;
return function(){
return that.coe;
};
}
};
console.log(status.getCode()()); // 200
执行status.getCode()时,this指向status,并通过局部变量that保存this的值,最后返回值为函数。status.getCode()()表示执行返回的函数,其that指向的status,所以返回值为200。
更复杂的例子
function f() {
//宏任务
setTimeout(() => {
console.log(">>>" + this); // >>>[object object],语句5
this.code = 401;
}, 0)
//同步
console.log( this.code );
}
let obj = {
">>>" + this
code: 200,
foo: f
};
var code = 500;
同步和异步 关键词说的很好
宏任务 微任务
1.宏任务 微任务 同步异步
2.箭头函数this指向问题
3.字符串+ this [object object]
obj.foo(); // 200,语句1
console.log("--" + obj.code); // --200,语句3
//宏任务
setTimeout(()=>{console.log("---" + obj.code);}, 0); // ---401,语句4
obj.foo(); (语句1):调用 obj 对象的 foo 方法。
输出:200
解释:在 foo 方法内部的 console.log(this.code) 打印出 obj 对象的 code 属性,其值为 200。
console.log("--" + obj.code); (语句3):打印 obj 对象的 code 属性。
输出:--200
解释:在全局作用域中,code 被赋值为 500,但这里的 obj.code 指向的是 obj 对象的 code 属性,其值仍然是 200。
setTimeout(() => { console.log("---" + obj.code); }, 0); (语句4):设置一个零延迟的定时器,其中的箭头函数在调用。
输出:---401
解释:在调用 obj.foo() 的过程中,foo 方法中的 setTimeout 在当前宏任务结束后执行。由于是箭头函数,this 的值保持与父作用域一致(也就是 obj 对象)。所以在箭头函数内部,this.code 被设置为 401。
setTimeout(() => { console.log(">>>" + this); this.code = 401; }, 0) (语句5):设置一个零延迟的定时器,其中的箭头函数在调用。
输出:>>>[object Object]
解释:在调用 obj.foo() 的过程中,foo 方法中的 setTimeout 在当前宏任务结束后执行。箭头函数的 this 始终指向它被创建时的外部作用域,所以 this 指向了 obj 对象,而在控制台中打印 this 时会将其转换为字符串。所以输出为 >>>[object Object]。
知识补充:函数setTimeout用于创建一个定时器,在同一个的对象上,各个定时器使用用一个编号池(这点很关键),不同的对象使用独立的编号池,同一个对象上的多个定时器有不同的定时器编号。所以,setTimeout到了执行时间点时,其内部的this指向定时器所绑定的对象。
结果分析:函数setTimeout中传入的函数句柄,由于js是单线程执行,即使延时为0,仍需等到本次执行的所有同步代码执行完毕,才能执行。所以在两次执行obj.foo()的过程中,其内部的setTimeout的入参函数(也就是语句5)都未执行。同理,执行语句3时,语句5同样未执行。直到执行语句4,当前同步代码块执行完毕,语句5执行(并且执行了2次,因为语句1和语句2分别执行1次),obj上绑定的code被更新为401。最终,语句4的入参函数执行,输出obj.code的值为401。
由上面的例子继续扩展
function doFoo(fn) {
this.code = 404;
fn();
}
function f() {
setTimeout(() => {
console.log(">>>" + this); // >>>[object window],语句3
this.code = 401; // 语句4
}, 0)
console.log( this.code ); // 404,语句2
}
let obj = {
code: 200,
foo: f
};
var code = 500;
doFoo( obj.foo ); // 语句1
setTimeout(()=>{console.log(obj.code)}, 0); // 200,语句5
setTimeout(()=>{console.log(window.code)}, 0); // 401,语句6
结果分析:obj.foo为函数句柄,作为入参传入函数doFoo,doFoo的调用房为全局变量window,所以,语句2中doFoo对象的code是404、3、4中的this均指向window。
使用注意点
避免多层 this
由于this的指向是不确定的,所以切勿在函数中包含多层的this。
var o = {
f1: function () {
console.log(this);
var f2 = function () {
console.log(this);
}();
}
}
o.f1()
// Object
// Window
上面代码包含两层this,结果运行后,第一层指向对象o,第二层指向全局对象,因为实际执行的是下面的代码。
var temp = function () {
console.log(this);
};
var o = {
f1: function () {
console.log(this);
var f2 = temp();
}
}
一个解决方法是在第二层改用一个指向外层this的变量。
var o = {
f1: function() {
console.log(this);
var that = this;
var f2 = function() {
console.log(that);
}();
}
}
o.f1()
// Object
// Object
上面代码定义了变量that,固定指向外层的this,然后在内层使用that,就不会发生this指向的改变。
事实上,使用一个变量固定this的值,然后内层函数调用这个变量,是非常常见的做法,请务必掌握。
避免数组处理方法中的 this
数组的map和foreach方法,允许提供一个函数作为参数。这个函数内部不应该使用this。
var o = {
v: 'hello',
p: [ 'a1', 'a2' ],
f: function f() {
this.p.forEach(function (item) {
console.log(this.v + ' ' + item);
});
}
}
o.f()
// undefined a1
// undefined a2
上面代码中,foreach方法的回调函数中的this,其实是指向window对象,因此取不到o.v的值。原因跟上一段的多层this是一样的,就是内层的this不指向外部,而指向顶层对象。
解决这个问题的一种方法,就是前面提到的,使用中间变量固定this。
var o = {
v: 'hello',
p: [ 'a1', 'a2' ],
f: function f() {
var that = this;
this.p.forEach(function (item) {
console.log(that.v+' '+item);
});
}
}
o.f()
// hello a1
// hello a2
另一种方法是将this当作foreach方法的第二个参数,固定它的运行环境。
var o = {
v: 'hello',
p: [ 'a1', 'a2' ],
f: function f() {
this.p.forEach(function (item) {
console.log(this.v + ' ' + item);
}, this);
}
}
o.f()
// hello a1
// hello a2
避免回调函数中的 this
回调函数中的this往往会改变指向,最好避免使用。
var o = new Object();
o.f = function () {
console.log(this === o);
}
// jQuery 的写法
$('#button').on('click', o.f);
上面代码中,点击按钮以后,控制台会显示false。原因是此时this不再指向o对象,而是指向按钮的 DOM 对象,因为f方法是在按钮对象的环境中被调用的。这种细微的差别,很容易在编程中忽视,导致难以察觉的错误。
为了解决这个问题,可以采用下面的一些方法对this进行绑定,也就是使得this固定指向某个对象,减少不确定性。
绑定 this 的方法
this的动态切换,固然为 JavaScript 创造了巨大的灵活性,但也使得编程变得困难和模糊。有时,需要把this固定下来,避免出现意想不到的情况。JavaScript 提供了call、apply、bind这三个方法,来切换/固定this的指向。
Function.prototype.call()
函数实例的call方法,可以指定函数内部this的指向(即函数执行时所在的作用域),然后在所指定的作用域中,调用该函数。
var obj = {};
var f = function () {
return this;
};
f() === window // true
f.call(obj) === obj // true
上面代码中,全局环境运行函数f时,this指向全局环境(浏览器为window对象);call方法可以改变this的指向,指定this指向对象obj,然后在对象obj的作用域中运行函数f。
call方法的参数,应该是一个对象。如果参数为空、null和undefined,则默认传入全局对象。
var n = 123;
var obj = { n: 456 };
function a() {
console.log(this.n);
}
a.call() // 123
a.call(null) // 123
a.call(undefined) // 123
a.call(window) // 123
a.call(obj) // 456
上面代码中,a函数中的this关键字,如果指向全局对象,返回结果为123。如果使用call方法将this关键字指向obj对象,返回结果为456。可以看到,如果call方法没有参数,或者参数为null或undefined,则等同于指向全局对象。
如果call方法的参数是一个原始值,那么这个原始值会自动转成对应的包装对象,然后传入call方法。
var f = function () {
return this;
};
f.call(5)
// Number {[[PrimitiveValue]]: 5}
上面代码中,call的参数为5,不是对象,会被自动转成包装对象(Number的实例),绑定f内部的this。
call方法还可以接受多个参数。
func.call(thisValue, arg1, arg2, ...)
call的第一个参数就是this所要指向的那个对象,后面的参数则是函数调用时所需的参数。
function add(a, b) {
return a + b;
}
add.call(this, 1, 2) // 3
上面代码中,call方法指定函数add内部的this绑定当前环境(对象),并且参数为1和2,因此函数add运行后得到3。
call方法的一个应用是调用对象的原生方法。
var obj = {};
obj.hasOwnProperty('toString') // false
// 覆盖掉继承的 hasOwnProperty 方法
obj.hasOwnProperty = function () {
return true;
};
obj.hasOwnProperty('toString') // true
Object.prototype.hasOwnProperty.call(obj, 'toString') // false
上面代码中,hasOwnProperty是obj对象继承的方法,如果这个方法一旦被覆盖,就不会得到正确结果。call方法可以解决这个问题,它将hasOwnProperty方法的原始定义放到obj对象上执行,这样无论obj上有没有同名方法,都不会影响结果。
Function.prototype.apply()
apply方法的作用与call方法类似,也是改变this指向,然后再调用该函数。唯一的区别就是,它接收一个数组作为函数执行时的参数,使用格式如下。
func.apply(thisValue, [arg1, arg2, ...])
apply方法的第一个参数也是this所要指向的那个对象,如果设为null或undefined,则等同于指定全局对象。第二个参数则是一个数组,该数组的所有成员依次作为参数,传入原函数。原函数的参数,在call方法中必须一个个添加,但是在apply方法中,必须以数组形式添加。
function f(x, y){
console.log(x + y);
}
f.call(null, 1, 1) // 2
f.apply(null, [1, 1]) // 2
上面代码中,f函数本来接受两个参数,使用apply方法以后,就变成可以接受一个数组作为参数。
利用这一点,可以做一些有趣的应用。
(1)找出数组最大元素
JavaScript 不提供找出数组最大元素的函数。结合使用apply方法和Math.max方法,就可以返回数组的最大元素。
var a = [10, 2, 4, 15, 9];
Math.max.apply(null, a) // 15
(2)将数组的空元素变为undefined
通过apply方法,利用Array构造函数将数组的空元素变成undefined。
Array.apply(null, ['a', ,'b'])
// [ 'a', undefined, 'b' ]
空元素与undefined的差别在于,数组的forEach方法会跳过空元素,但是不会跳过undefined。因此,遍历内部元素的时候,会得到不同的结果。
var a = ['a', , 'b'];
function print(i) {
console.log(i);
}
a.forEach(print)
// a
// b
Array.apply(null, a).forEach(print)
// a
// undefined
// b
(3)转换类似数组的对象
另外,利用数组对象的slice方法,可以将一个类似数组的对象(比如arguments对象)转为真正的数组。
Array.prototype.slice.apply({0: 1, length: 1}) // [1]
Array.prototype.slice.apply({0: 1}) // []
Array.prototype.slice.apply({0: 1, length: 2}) // [1, undefined]
Array.prototype.slice.apply({length: 1}) // [undefined]
上面代码的apply方法的参数都是对象,但是返回结果都是数组,这就起到了将对象转成数组的目的。从上面代码可以看到,这个方法起作用的前提是,被处理的对象必须有length属性,以及相对应的数字键。
(4)绑定回调函数的对象
前面的按钮点击事件的例子,可以改写如下。
var o = new Object();
o.f = function () {
console.log(this === o);
}
var f = function (){
o.f.apply(o);
// 或者 o.f.call(o);
};
// jQuery 的写法
$('#button').on('click', f);
上面代码中,点击按钮以后,控制台将会显示true。由于apply()方法(或者call()方法)不仅绑定函数执行时所在的对象,还会立即执行函数,因此不得不把绑定语句写在一个函数体内。更简洁的写法是采用下面介绍的bind()方法。
Function.prototype.bind()
bind()方法用于将函数体内的this绑定到某个对象,然后返回一个新函数。
var d = new Date();
d.getTime() // 1481869925657
var print = d.getTime;
print() // Uncaught TypeError: this is not a Date object.
上面代码中,我们将d.getTime()方法赋给变量print,然后调用print()就报错了。这是因为getTime()方法内部的this,绑定Date对象的实例,赋给变量print以后,内部的this已经不指向Date对象的实例了。
bind()方法可以解决这个问题。
var print = d.getTime.bind(d);
print() // 1481869925657
上面代码中,bind()方法将getTime()方法内部的this绑定到d对象,这时就可以安全地将这个方法赋值给其他变量了。
bind方法的参数就是所要绑定this的对象,下面是一个更清晰的例子。
var counter = {
count: 0,
inc: function () {
this.count++;
}
};
var func = counter.inc.bind(counter);
func();
counter.count // 1
上面代码中,counter.inc()方法被赋值给变量func。这时必须用bind()方法将inc()内部的this,绑定到counter,否则就会出错。
this绑定到其他对象也是可以的。
var counter = {
count: 0,
inc: function () {
this.count++;
}
};
var obj = {
count: 100
};
var func = counter.inc.bind(obj);
func();
obj.count // 101
上面代码中,bind()方法将inc()方法内部的this,绑定到obj对象。结果调用func函数以后,递增的就是obj内部的count属性。
bind()还可以接受更多的参数,将这些参数绑定原函数的参数。
var add = function (x, y) {
return x * this.m + y * this.n;
}
var obj = {
m: 2,
n: 2
};
var newAdd = add.bind(obj, 5);
newAdd(5) // 20
上面代码中,bind()方法除了绑定this对象,还将add()函数的第一个参数x绑定成5,然后返回一个新函数newAdd(),这个函数只要再接受一个参数y就能运行了。
如果bind()方法的第一个参数是null或undefined,等于将this绑定到全局对象,函数运行时this指向顶层对象(浏览器为window)。
function add(x, y) {
return x + y;
}
var plus5 = add.bind(null, 5);
plus5(10) // 15
上面代码中,函数add()内部并没有this,使用bind()方法的主要目的是绑定参数x,以后每次运行新函数plus5(),就只需要提供另一个参数y就够了。而且因为add()内部没有this,所以bind()的第一个参数是null,不过这里如果是其他对象,也没有影响。
bind()方法有一些使用注意点。
(1)每一次返回一个新函数
bind()方法每运行一次,就返回一个新函数,这会产生一些问题。比如,监听事件的时候,不能写成下面这样。
element.addEventListener('click', o.m.bind(o));
上面代码中,click事件绑定bind()方法生成的一个匿名函数。这样会导致无法取消绑定,所以下面的代码是无效的。
element.removeEventListener('click', o.m.bind(o));
正确的方法是写成下面这样:
var listener = o.m.bind(o);
element.addEventListener('click', listener);
// ...
element.removeEventListener('click', listener);
(2)结合回调函数使用
回调函数是 JavaScript 最常用的模式之一,但是一个常见的错误是,将包含this的方法直接当作回调函数。解决方法就是使用bind()方法,将counter.inc()绑定counter。
var counter = {
count: 0,
inc: function () {
'use strict';
this.count++;
}
};
function callIt(callback) {
callback();
}
callIt(counter.inc.bind(counter));
counter.count // 1
上面代码中,callIt()方法会调用回调函数。这时如果直接把counter.inc传入,调用时counter.inc()内部的this就会指向全局对象。使用bind()方法将counter.inc绑定counter以后,就不会有这个问题,this总是指向counter。
还有一种情况比较隐蔽,就是某些数组方法可以接受一个函数当作参数。这些函数内部的this指向,很可能也会出错。
var obj = {
name: '张三',
times: [1, 2, 3],
print: function () {
this.times.forEach(function (n) {
console.log(this.name);
});
}
};
obj.print()
// 没有任何输出
上面代码中,obj.print内部this.times的this是指向obj的,这个没有问题。但是,forEach()方法的回调函数内部的this.name却是指向全局对象,导致没有办法取到值。稍微改动一下,就可以看得更清楚。
obj.print = function () {
this.times.forEach(function (n) {
console.log(this === window);
});
};
obj.print()
// true
// true
// true
解决这个问题,也是通过bind()方法绑定this。
obj.print = function () {
this.times.forEach(function (n) {
console.log(this.name);
}.bind(this));
};
obj.print()
// 张三
// 张三
// 张三
(3)结合call()方法使用
利用bind()方法,可以改写一些 JavaScript 原生方法的使用形式,以数组的slice()方法为例。
[1, 2, 3].slice(0, 1) // [1]
// 等同于
Array.prototype.slice.call([1, 2, 3], 0, 1) // [1]
上面的代码中,数组的slice方法从[1, 2, 3]里面,按照指定的开始位置和结束位置,切分出另一个数组。这样做的本质是在[1, 2, 3]上面调用Array.prototype.slice()方法,因此可以用call方法表达这个过程,得到同样的结果。
call()方法实质上是调用Function.prototype.call()方法,因此上面的表达式可以用bind()方法改写。
var slice = Function.prototype.call.bind(Array.prototype.slice);
slice([1, 2, 3], 0, 1) // [1]
上面代码的含义就是,将Array.prototype.slice变成Function.prototype.call方法所在的对象,调用时就变成了Array.prototype.slice.call。类似的写法还可以用于其他数组方法。
var push = Function.prototype.call.bind(Array.prototype.push);
var pop = Function.prototype.call.bind(Array.prototype.pop);
var a = [1 ,2 ,3];
push(a, 4)
a // [1, 2, 3, 4]
pop(a)
a // [1, 2, 3]
如果再进一步,将Function.prototype.call方法绑定到Function.prototype.bind对象,就意味着bind的调用形式也可以被改写。
function f() {
console.log(this.v);
}
var o = { v: 123 };
var bind = Function.prototype.call.bind(Function.prototype.bind);
bind(f, o)() // 123
上面代码的含义就是,将Function.prototype.bind方法绑定在Function.prototype.call上面,所以bind方法就可以直接使用,不需要在函数实例上使用。
JS宏任务和微任务
什么是微任务和宏任务
首先,我们要先了解下 Js 。js 是一种单线程语言,简单的说就是:只有一条通道,那么在任务多的情况下,就会出现拥挤的情况,这种情况下就产生了 ‘多线程’ ,但是这种“多线程”是通过单线程模仿的,也就是假的。那么就产生了同步任务和异步任务。
JS为什么要区分微任务和宏任务
(1)js是单线程的,但是分同步异步
(2)微任务和宏任务皆为异步任务,它们都属于一个队列
(3)宏任务一般是:script、setTimeout、setInterval、postMessage
(4)微任务:Promise.then ES6
先执行同步 再执行异步
(5)先执行同步再执行异步,异步遇到微任务,先执行微任务,执行完后如果没有微任务,就执行下一个宏任务,如果有微任务,就按顺序一个一个执行微任务
微任务和宏任务有哪些
(1)宏任务一般是:script、setTimeout、setInterval、postMessage
(2)微任务:Promise.then
微任务和宏任务是怎么执行的?
执行顺序:先执行同步代码,遇到异步宏任务则将异步宏任务放入宏任务队列中,遇到异步微任务则将异步微任务放入微任务队列中,当所有同步代码执行完毕后,再将异步微任务从队列中调入主线程执行,微任务执行完毕后再将异步宏任务从队列中调入主线程执行,一直循环直至所有任务执行完毕。
这里容易产生一个错误的认识:就是微任务先于宏任务执行。实际上是先执行同步任务然后在执行异步任务,异步任务是分宏任务和微任务两种的。
案例
eg1:
//宏任务 放进队列
setTimeout(function(){
console.log(1);
});
//微任务
new Promise(function(resolve){
console.log(2);
resolve();
}).then(function(){
console.log(3);
}).then(function(){
console.log(4)
});
//同步代码
console.log(5);
// 2 5 3 4 1
分析:
遇到setTimout,异步宏任务,放入宏任务队列中
遇到new Promise,new Promise在实例化的过程中所执行的代码都是同步进行的,所以输出2
Promise.then,异步微任务,将其放入微任务队列中
遇到同步任务console.log(5);输出5;主线程中同步任务执行完
从微任务队列中取出任务到主线程中,输出3、 4,微任务队列为空
从宏任务队列中取出任务到主线程中,输出1,宏任务队列为空
eg2:
setTimeout(()=>{
new Promise(resolve =>{
resolve();
}).then(()=>{
console.log('test');
});
console.log(4);
});
new Promise(resolve => {
resolve();
console.log(1)
}).then( () => {
console.log(3);
Promise.resolve().then(() => {
console.log('before timeout');
}).then(() => {
Promise.resolve().then(() => {
console.log('also before timeout')
})
})
})
console.log(2);
//1,2,3,before timeout,also before timeout,4,test;
分析:
遇到setTimeout,异步宏任务,将() => {console.log(4)}放入宏任务队列中;
遇到new Promise,new Promise在实例化的过程中所执行的代码都是同步进行的,所以输出1;
而Promise.then,异步微任务,将其放入微任务队列中
遇到同步任务console.log(2),输出2;主线程中同步任务执行完
从微任务队列中取出任务到主线程中,输出3,此微任务中又有微任务,Promise.resolve().then(微任务a).then(微任务b),将其依次放入微任务队列中;
从微任务队列中取出任务a到主线程中,输出 before timeout;
从微任务队列中取出任务b到主线程中,任务b又注册了一个微任务c,放入微任务队列中;
从微任务队列中取出任务c到主线程中,输出 also before timeout;微任务队列为空
从宏任务队列中取出任务到主线程,此任务中注册了一个微任务d,将其放入微任务队列中,接下来遇到输出4,宏任务队列为空
从微任务队列中取出任务d到主线程 ,输出test,微任务队列为空
eg3
console.log(1)
setTimeout(function() {
console.log(2)
}, 0)
const p = new Promise((resolve, reject) => {
resolve(4)
})
p.then(data => {
console.log(data)
})
console.log(3)
//1,3,4,2
分析
遇到同步任务console.log(1);输出1;
遇到setTimeout 异步宏任务,放入宏任务队列中;
遇到 Promise,new Promise在实例化的过程中所执行的代码都是同步进行的,但由于new Promise没有输出事件,所以接着执行遇到.then;
执行.then,异步微任务,被分发到微任务Event Queue中;
遇到同步任务console.log(3);输出3;
主线程中同步任务执行完,从微任务队列中取出任务到主线程中,p.then 输出4,微任务执行完毕,任务队列为空;
开始执行宏任务setTimeout 输出2,宏任务队列为空;
eg4
console.log(1)
setTimeout(function() {
console.log(2)
new Promise(function(resolve) {
console.log(3)
resolve()
}).then(function() {
console.log(4)
})
})
new Promise(function(resolve) {
console.log(5)
resolve()
}).then(function() {
console.log(6)
})
setTimeout(function() {
console.log(7)
new Promise(function(resolve) {
console.log(8)
resolve()
}).then(function() {
console.log(9)
})
})
console.log(10)
//1,5,10,6,2,3,4,7,8,9
分析
遇到同步任务console.log(1);输出1;
遇到setTimeout 异步宏任务,放入宏任务队列中;
遇到 Promise,new Promise在实例化的过程中所执行的代码都是同步进行的,所以输出5,所以接着执行遇到.then;
执行.then,异步微任务,被分发到微任务Event Queue中;
遇到setTimeout,异步宏任务;放入宏任务队列中;
遇到同步任务console.log(10);输出10,主线程中同步任务全部执行完;
从微任务队列中取出任务到主线程中,输出6;
在从宏任务队列中取出任务到主线程中,执行第一个setTimeout,输出2,3,4(在宏任务中执行同步,同步,异步微任务);
在执行第二个setTimeout,输出7,8,9(和8同理);
eg5
new Promise((resolve, reject) => {
resolve(1)
new Promise((resolve, reject) => {
resolve(2)
}).then(data => {
console.log(data)
})
}).then(data => {
console.log(data)
})
console.log(3)
//3,2,1
分析
遇到Promise,new Promise在实例化的过程中所执行的代码都是同步进行的,但由于new Promise没有输出事件,所以接着往下执行遇到new Promise没有输出事件再接着往下执行遇到.then,异步微任务,被分发到微任务Event Queue中,再接着 .then 放入微任务
遇到同步任务console.log(3) 输出3,主线程中同步任务执行完;
从微任务队列中取出任务到主线程中,输出2,1,微任务执行完毕,任务队列为空。
小结
微任务和宏任务的执行顺序是先执行同步任务,先执行同步后异步,异步分为宏任务和微任务两种,异步遇到微任务先执行微任务,执行完后如果没有微任务,就执行下一个宏任务。














 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









