






文章目录
一. 递归算法设计:
1. 递归概念
递归算法是一种直接或者间接调用自身来解决问题方法的算法思想。
例:求n的阶乘

2. 递归思想的内涵
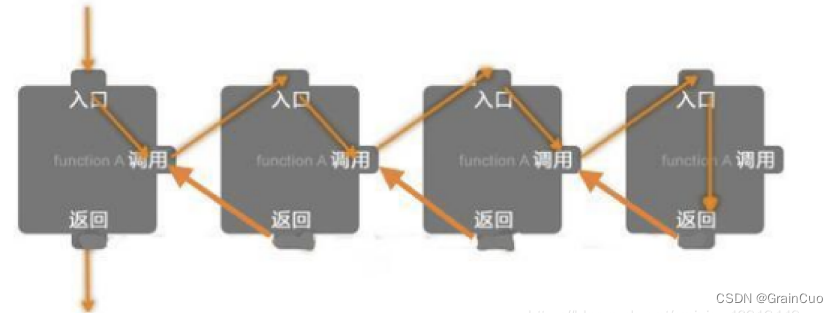
递归就是有去(递去)有回(归来),如下图所示。“有去”是指:递归问题必须可以分解为规模较小,通过包含调用自身的过程来解决见小数据规模后的相同问题,例如上文n的阶乘中:
public static int fact(int n){
if (n == 1){
return 1;
}else{
return n*fact(n-1)//分解为规模较小fact(n-1),与原问题形式相同--fact(),通过包含调用自身return fact(n-1)*n 的过程来解决较小数据规模后的相同问题
}
}
3. 递归解决问题的三定律
- 必须有一个基本结束条件(最小规模问题的直接解决)
- 递归算法能够改变状态向基本结束条件演进(减小问题规模)
- 递归算法必须通过包含调用自身函数来解决较小数据规模后的相同问题
4. 递归设计
- 由三定律1.有 (1) 明确问题最小规模的临界状态和返回值(解决方法)
- 由三定律2.和3.有 (2) 明确递归函数的功能:
- 缩小问题规模: 通过改变参数状态来实现
- 调用自身解决问题:明确函数的功能—将问题参数如何运算,返回当前问题规模(参数)的解
- 由三定律3. 有:(3)何时解决较小规模的问题?
- 递去的过程解决较小规模的问题
def func(n):
if base_condition:##基本情况/base condition
return val ##基本情况的解
##递去过程的操作
return func(n-1)*n##本行的非调用递归函数的其他操作(如*n)都是属于归去时的操作,不过变量本身是缓存的
##归来过程的操作
5.递归的问题的分类
(1).线性递归(阶乘, 数列前n项和/积, 链表的相关问题)—基础
(2). 数据结构是递归的(斐波那契数列, 树的操作)—中等(模版化)
(3). 问题的解法是递归思想来实现的:—难
- 分治
- 动态规划(优化重复的递归)
eg1. 数列前n项和
- 基本条件:当只有一个元素时,返回该元素值
- 确定函数: Sum(nums:List,n)
- (1) 函数是什么(输入什么,输出什么)? 输入数列和所求前n项(函数参数), 返回前n项和(返回值)
- (2) 最终结果可以通过函数到达的所指的更小规模是什么?如何到达?
- 更小规模: 求前n项和 = 求前n-1(更小规模)项和 + 第n项元素
- 如何到达: 求前n项和 = 求前n-1项和 + 第n项元素
def sum(nums,n):
if len(nums)==1:
return nums[0]
#else:
#递归情况:n大于1时,返回数列第1项加上其后n-1项子列的和
return nums[0] + sum(nums[1:n],n)

eg2. 斐波那契数列
a(1) = a(2) = 1 —基条件
a(i) = a(i-1) + a(i-2)
def a(i):
if i == 2 or i == 1:
return 1
#else:
return a(i-1)+a(i-2)
二. 树递归
树的深度递归遍历的框架:
def vistRe(root:Node):
#本行代码的含义:第一次访问时直接操作
if root == None: reutn
#本行代码含义:第一次访问且root不等于None时的操作
vistRe(root.left)
#本行代码含义:第一次返回到节点进行的操作
vistRe(root.right)
#本行代码含义:第二次返回到节点进行的操作
例:leetcode222.
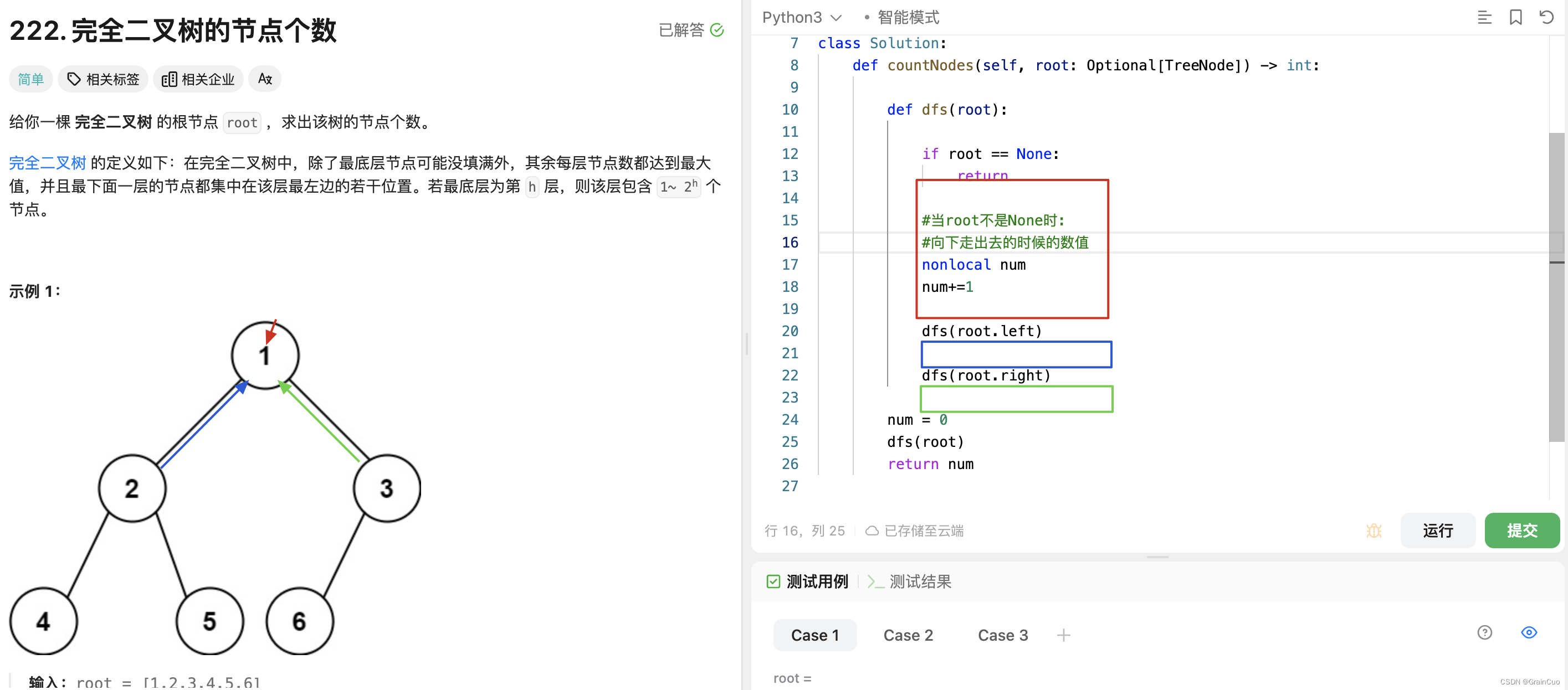
非递归遍历
- 先序:
- (0)将根压栈 (1)弹, 置为cur ,处理(输出)cur (2)cur 先右后左 (3)重复(1)~(2)直到栈空
- 后序: 将先序的入栈左右顺序颠倒, 出栈不直接打印而是放入辅助栈最后输出
- 准备两个栈:s collect
- (0)将根压栈s (1)弹,置为cur, cur放入collect (2)cur 先左后右(3)重复(1)~(2)直到栈空 (4)collect出栈为中序序列
- 中序
- 每棵子树的左节点进栈,依次弹出
- 非递归的先序 中序 后序 关键操作不同
先序非递归
# 先序遍历非递归:
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
'''
非递归---自己创建栈来模拟:
背诵:
(0)首先将根节点压入栈完成初始化
(1)从栈顶弹出一个节点cur
(2)处理cur
(3)⭐️关键操作: 先序遍历需要左孩子节点在栈顶,因此 先 压入右孩子节点再压入左孩子节点,让左孩子节点在栈顶
(4)重复(1)~(3)直到栈为空结束
'''
res = []
stack = []
if root == None:
return []
#else:
stack.append(root)
while stack != []:
cur = stack.pop()
res.append(cur.val)
#栈--先进后出,先序遍历--根左右:根->左子...->右子
if cur.right: stack.append(cur.right)
if cur.left: stack.append(cur.left)
return res
非递归—自己创建栈模拟递归过程(不是完全相同,递归是访问时处理,子树全访问完出栈,循环是,出栈处理再入栈):
背诵:
(0)首先将根节点压入栈完成初始化
(1)从栈顶弹出一个节点cur
(2)处理cur
(3)⭐️关键操作: 先 压入cur右孩子节点再压入左孩子节点,因为先序遍历需要左孩子节点在栈顶,让左孩子节点在栈顶
(4)重复(1)~(3)直到栈为空结束
‘’’
树的广度优先遍历
- 非递归版本(更好想到)
def bfs(root):
ass_queue =[]
ass_queue.append(root)
while ass_queue != []:
cur = ass_queue.pop(0)##出队队首节点
print(cur.val)##对队首节点进行操作: fun(cur)
#继续入队先左子节点后右子节点
if cur.left != None: ass_queue.append(cur.left)
if cur.right!= None: ass_queue.append(cur.right)
- 非递归, 每次对本层节点进行操作
def bfs(root):
ass_queue = [] #广度优先遍历的辅助队列
ass_queue.append(root) #将根节点压入队列进行初始化辅助队列
output_list = []
while ass_queue != []: #对整个树进行广度优先遍历的临界条件
level_node = [] #本层节点列表进行初始化,在每次遍历时,实现连续将本层节点输出
level_node_num = len(level_node)
for _ in range(level_node_num):#连续的对本层个数元素进行迭代
cur_node = ass_queue.pop(0)
level_node.append(cur_node)#将当前迭代节点加入本层输出队列
if cur_node.left != None:#将当前迭代到的节点的左子节点入队(如果有)
ass_queue.append(cur.left)
if cur_node.right != None:#将当前迭代到的节点的右子节点入队(如果有)
ass_queue.append(cur.right)
output_list.append(level_node)
三. 刷题心得:
102二叉树的层序遍历
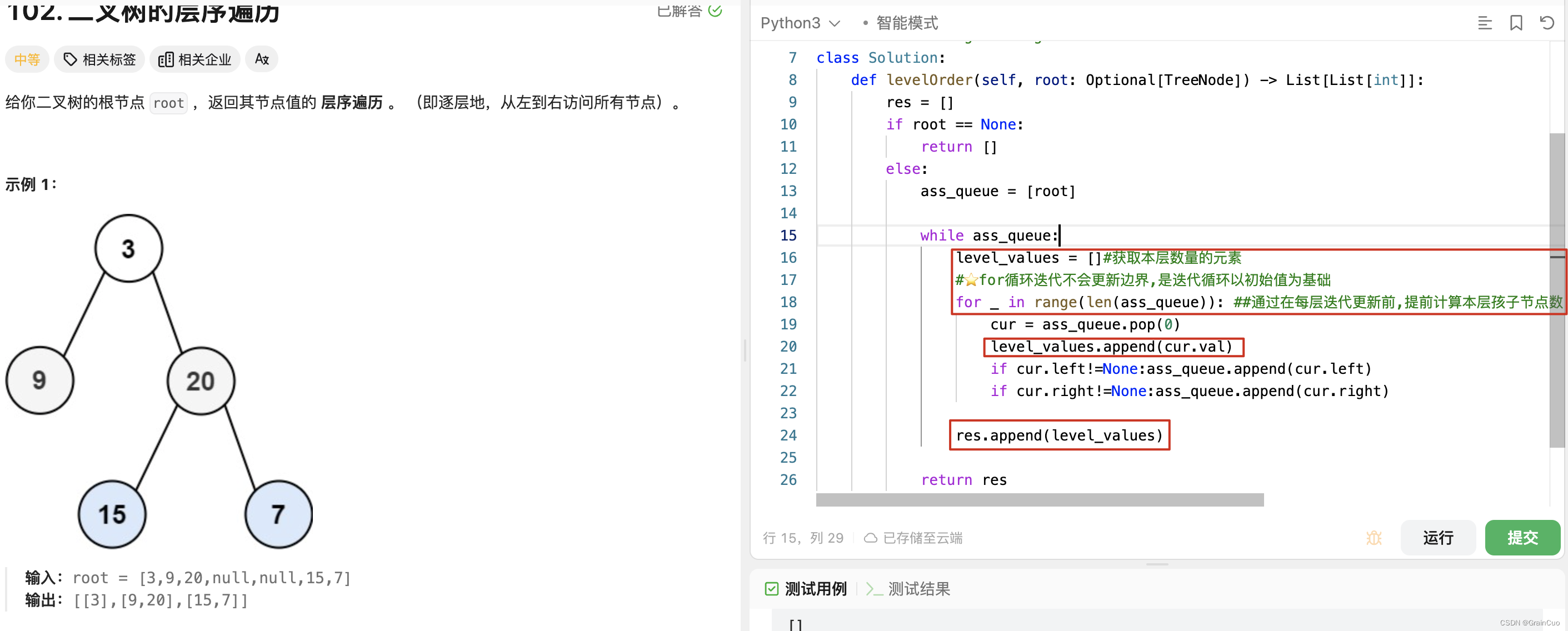
- 注意: 本题的坑在于让你输出形式为一个层为一个列表因此为了控制按层输出需要补充对当前层进行统一遍历的逻辑( 通过计数(当前层节点数)循环,达到准确控制连续输出当层的节点 ),如下红框所示. 注2:#⭐️python中的for循环迭代不会更新边界,是迭代循环,以初始值为固定值
429 N叉树的层序遍历
- 问题
-
- M叉树的数据结构,children节点怎么操作?
- 答:
-
//C语言中的节点结构体定义:
struct Node{
int val;
int num_childern;
struct Node** childern;
};
看了C语言下节点结构体的代码得知: 一个节点的是由(1)节点数值val (2)子节点数目numChildern (3)指向子节点指针(数组)的一个二级指针struct Node** children 构成的
C++的结构体更好的应正了(3)为一个指向孩子节点的指针数组(C++用动态数组存储基本元素为Node* 指针)
//C++节点结构体定义:
class Node {
public:
int val;
vector<Node*> children;
// ⭐️vector是C++标准库中的动态数组容器
///- 语法: (1)头文件:#include <vector>
///- 声明与初始化: (1)vector<type> vec_name (2)默认0初始化: vector<type> vec_name(elem_number) (3)自定义初始化vector<type> vec_name = {elem1,elem2,...}
///- 访问:(1)idx访问:vec_name[idx] (2)访问第第一个元素:vec_name.front() (3)访问最后一个元素:vec_name.back()
///- 添加与删除:1)在末尾:(1)在末尾添加:vec_name.push_back(elem) (2)在末尾移除:vec_name.pop_back()
///2)在指定位置(1)在指定位置添加:vec_name.insert(ve_name.begin()+site,elem)其中ve_name.begin()+site为在第一个位置的基础上加site个位置
///(2)移除指定位置元素:vec_name.erase(ve_name.begin()+site)
///- 大小和容量: (1)返回元素个数:ve_name.size() (2)返回容量,不是元素数量:ve_name.capacity() (3)检查是否为空:ve_name.empty()
///- 调整大小: ve_name.resize(new_size)
Node() {} //⭐️构造函数1 (类名为函数名,无返回值)
Node(int _val) { //⭐️构造函数2
val = _val;
}
Node(int _val, vector<Node*> _children) //⭐️构造函数3
{
val = _val;
children = _children;
}
};
# Definition for a Node.
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
因此,虽然python这种非强制定义类型语言描述下的N叉树的节点类中的childern无法定义,但是可以从其他语言的描述中推断出children是一个列表,由此我们可以在二叉树的广度优先遍历的基础上将入队操作中对左右孩子节点的入队改成对子节点列表的入队,即可从二叉树的广度优先遍历修改为n叉树的广度优先遍历
"""
# Definition for a Node.
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
"""
class Solution:
def levelOrder(self, root: 'Node') -> List[List[int]]:
if root == None:
return []
ass_q = [root]
res = []
while ass_q:
level_nodes = []
level_node_num = len(ass_q)
for _ in range(level_node_num):#控制输出当前层数个节点,从而达到层序整体遍历
cur = ass_q.pop(0)
level_nodes.append(cur.val)
for child in cur.children:#将当前节点的孩子节点全部入队
ass_q.append(child)
res.append(level_nodes)
return res
对于输入的测试用例[1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 为什么在
for child in cur.children:#将当前节点的孩子节点全部入队
ass_q.append(child)
迭代到child = null时对其进行操作没有报错?
- 注: 不能采取,省略root==None的判断,
if root == None: reuturn[]
而通过while ass_q != None:或者while ass_q != []因为,当root == None时,会通过ass_q =[root]进行初始化为[None]从而在while迭代判断循环条件时有[None] != None ⇒ True并且[None] != [] ⇒ True, 所以应该进行判断是否为
559 N叉树最大深度
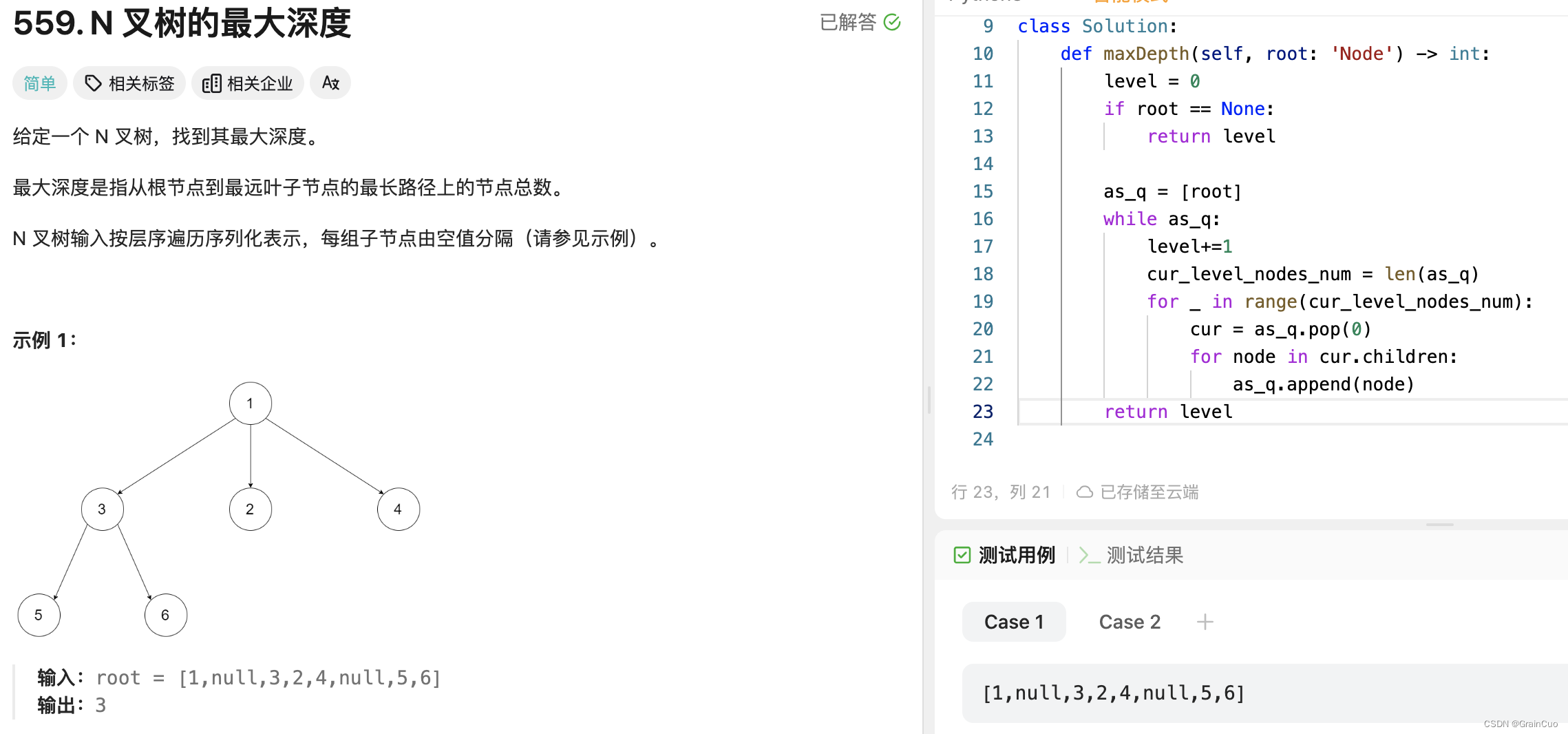
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
class Solution:
def maxDepth(self, root: 'Node') -> int:## maxDepth 输入当前节点, 输出当前节点的最大深度
if root == None:
return 0
dep = 1 #节点不为空,初始深度为1
for node in root.children:#对根节点的所有子节点进行迭代,获取子节点中最大深度
dep = max(dep, self.maxDepth(node)+1)#树的最大深度= 子树中最大深度 +1
return dep
算法学习—DFS相关模版题型
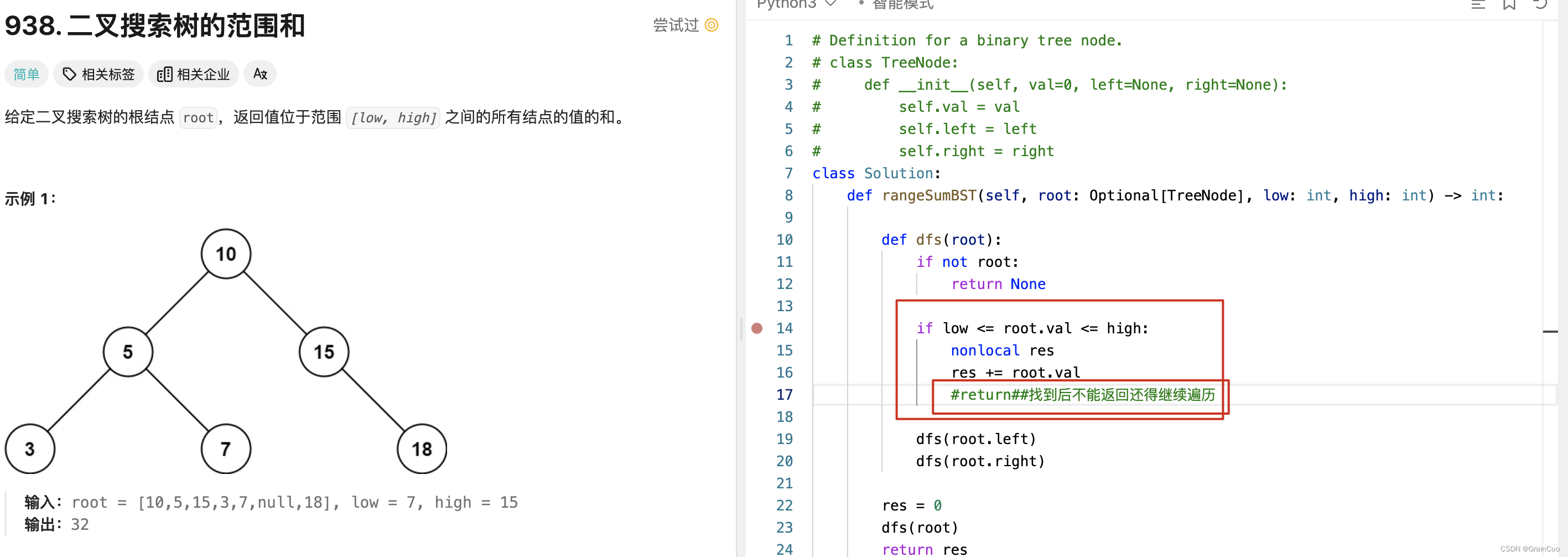
1.1 找到之后就返回,可以不在继续向下遍历
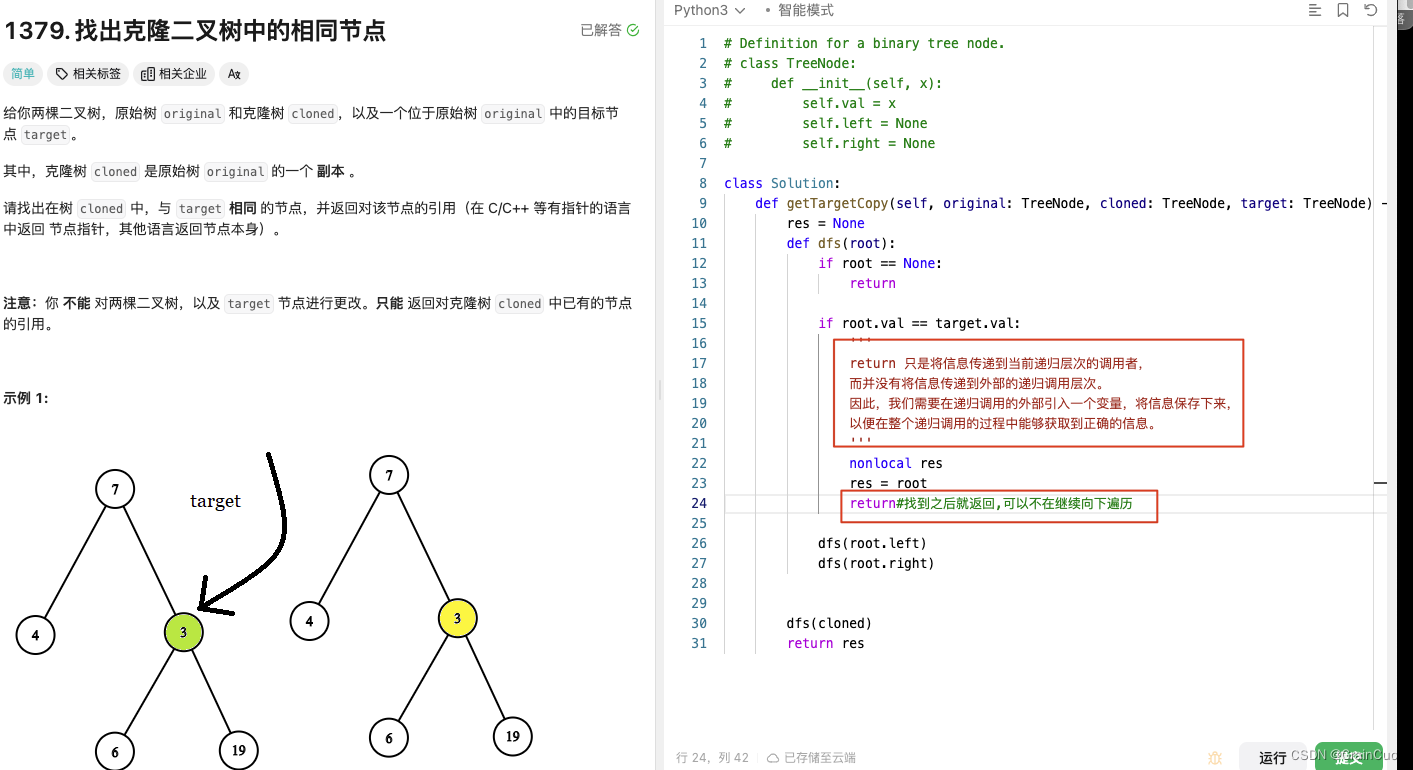
1.2 找到后不能返回还得继续遍历
算法设计:
1. leetcode226. 翻转二叉树
-
递归函数本身也是函数,调用递归函数就把它当做普通函数来看待,一定要只思考当前层的处理逻辑,明白该递归函数的输入输出是什么即可,调用的时候不要管函数内部实现。 不要用肉脑 debug 递归函数的调用过程,会被绕进去
-
首先来分析invertTree(TreeNode root)函数的定义:
- 函数的定义是什么?
该函数可以翻转一棵二叉树,即将二叉树中的每个节点的左右孩子都进行互换。 - 函数的输入是什么?
函数的输入是要被翻转的二叉树。 - 函数的输出是什么?
返回的结果就是已经翻转后的二叉树。
即: root 节点的新的左子树:是翻转了的 root.right => 即 root.left = invert(root.right);
root 节点的新的右子树:是翻转了的 root.left => 即 root.right = invert(root.left);
- 函数的定义是什么?
-
然后我们来分析函数的写法:
- 递归终止的条件
当要翻转的节点是空,停止翻转,返回空节点。 - 返回值
虽然对 root 的左右子树都进行了翻转,但是翻转后的二叉树的根节点不变,故返回 root 节点。 - 函数内容
root 节点的新的左子树:是翻转了的 root.right => 即 root.left = invert(root.right);
root 节点的新的右子树:是翻转了的 root.left => 即 root.right = invert(root.left);
- 递归终止的条件
-
注意
提醒大家避免踩一个小坑,不能直接写成下面这样的代码:
root.left = invert(root.right)
root.right = invert(root.left)
这是因为第一行修改了root.left,会影响了第二行。在 Python 中,正确的写法是把两行写在同一行,就能保证 root.left 和 root.right 的修改是同时进行的。
引用:
作者:负雪明烛 链接














 930
930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









