







引言
XPath 是一门在 XML 文档中查找信息的语言。
目录
XPath 术语
节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 HTML 文档:

<table> (文档节点)
<strong>双排街纺织一街新建电梯房全新装</strong> (元素节点)
target="_blank" (属性节点)
基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。
基本值的例子:
基本值:<strong>双排街纺织一街新建电梯房全新装</strong>;
<td>128㎡</td>
项目(Item)
项目是基本值或者节点。
节点关系
父(Parent)
每个元素以及属性都有一个父。
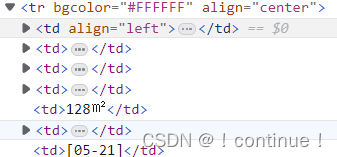
tr元素是td元素的父。
子(Children)
元素节点可有零个、一个或多个子。
td元素是tr元素的子。
同胞(Sibling)
拥有相同的父的节点
这幅图里面的全部td都拥有同一个父,所以它们都是同胞。
先辈(Ancestor)
某节点的父、父的父,等等。
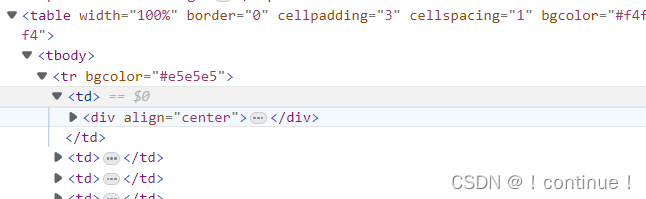
div 元素的先辈是 td 元素和 tr 元素和 tbody元素。
后代(Descendant)
某个节点的子,子的子,等等。
tbody元素的后代是 td 元素和 tr 元素和 div元素。
XPath 语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
|---|---|
| tbody | 选取 tbody 元素的所有子节点。 |
| /tbody | 选取根元素 tbody。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| tbody/tr | 选取属于 tbody 的子元素中所有的tr元素。 |
| //td | 选取所有 td 子元素,而不管它们在文档中的位置。 |
| tbody//tr | 选择属于 tbody 元素的后代的所有 tr 元素,而不管它们位于 tbody 之下的什么位置。 |
| //@td | 选取名为 td 的所有属性。 |
| 路径表达式 | 结果 |
|---|---|
| /tobody/tr[1] | 选取属于 tbody 子元素的第一个 tr 元素。 |
| /tbody/tr[last()] | 选取属于 tbody 子元素的最后一个 tr 元素。 |
| //tr[@lcenter] | 选取所有拥有名为 center 的属性的 tr 元素。 |
| //tr[@target="_blank''] | 选取所有 title 元素,且这些元素拥有值为 _blank 的 target 属性。 |
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
XPath 运算符
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。 如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
xpath解析原理
- 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
- 2.调用etree对象中的xpath方法结合xpath表达式实现标签的定位和内容的捕获。
实例化etree对象
将从互联网上获取的源代码数据加载到etree对象中
tree = etree.HTML(html)xpath(‘xpath的匹配表达式’)
xxdz = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[@target="_blank"]/strong/text()')
qy = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?dq")]/text()')
fx = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?fwtype")]/text()')
hx = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?hx")]/text()')
mhj = tree.xpath('//tr[@bgcolor="#FFFFFF"]/td/text()')xpath爬取龙港二手房实例
爬取网址
实例代码
import urllib.request
from lxml import etree
import re
import xlwt
datalist = []
title = ['详细地址','区域','房型','户型','面积','价格','日期']
# for l in range(0,9):
url = "https://www.lgfdcw.com/cs/index.php?userid=&infotype=&dq=&fwtype=&hx=&price01=&price02=&pricetype=&fabuday=&addr=&PageNo="
headers = {'User-Agent':'Mozilla/5.0 3578.98 Safari/537.36'}
resp = urllib.request.Request(url,headers=headers)
pa = urllib.request.urlopen(resp)
html = pa.read().decode('gbk')
tree = etree.HTML(html)
xxdz = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[@target="_blank"]/strong/text()')
qy = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?dq")]/text()')
fx = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?fwtype")]/text()')
hx = tree.xpath('//tr[@bgcolor="#FFFFFF"]//a[contains(@href,"?hx")]/text()')
mhj = tree.xpath('//tr[@bgcolor="#FFFFFF"]/td/text()')
mj = []
sj = []
for i in range(0,50):
if i%2==0:
mj.append(mhj[i])
else:
sj.append(mhj[i])
jg = []
jg1 = tree.xpath('//tr[@bgcolor="#FFFFFF"]/td/font/text()')
for o in range(0,30):
m = jg1[o]
m = re.sub(" ","",m)
m = re.sub("\r\n","",m)
jg.append(m)
Workbook = xlwt.Workbook(encoding="utf-8")
worksheet = Workbook.add_sheet('龙港地产')
for i in range(0,len(title)):
worksheet.write(0,i,title[i])
for z in range(0,25):
worksheet.write(z+1,0,xxdz[z])
worksheet.write(z+1,1,qy[z])
worksheet.write(z+1,2,fx[z])
worksheet.write(z+1,3,hx[z])
worksheet.write(z+1,4,mj[z])
worksheet.write(z+1,5,jg[z])
worksheet.write(z+1,6,sj[z])
Workbook.save("龙港1.xls")
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











