






所用的技术:
Frida(hook app可以抓包 app版本号6.9.31,可以去豌豆荚下载历史版本,我上传的js仅对此版本有效)。
Mitmdump(抓包软件,可以和python进行交互)
Bat(自动化操作app,当然也可以使用按键精灵之类的软件)
开发环境:
Windows10
安卓手机(安卓7.0以下不用管系统证书安装的问题,视频中演示的手机小米4真机。也可以使用雷电模拟器,别的模拟器不推荐,雷电模拟器4.0以上为安卓7版本,需要解决系统证书的问题)
下面截图是运行环境
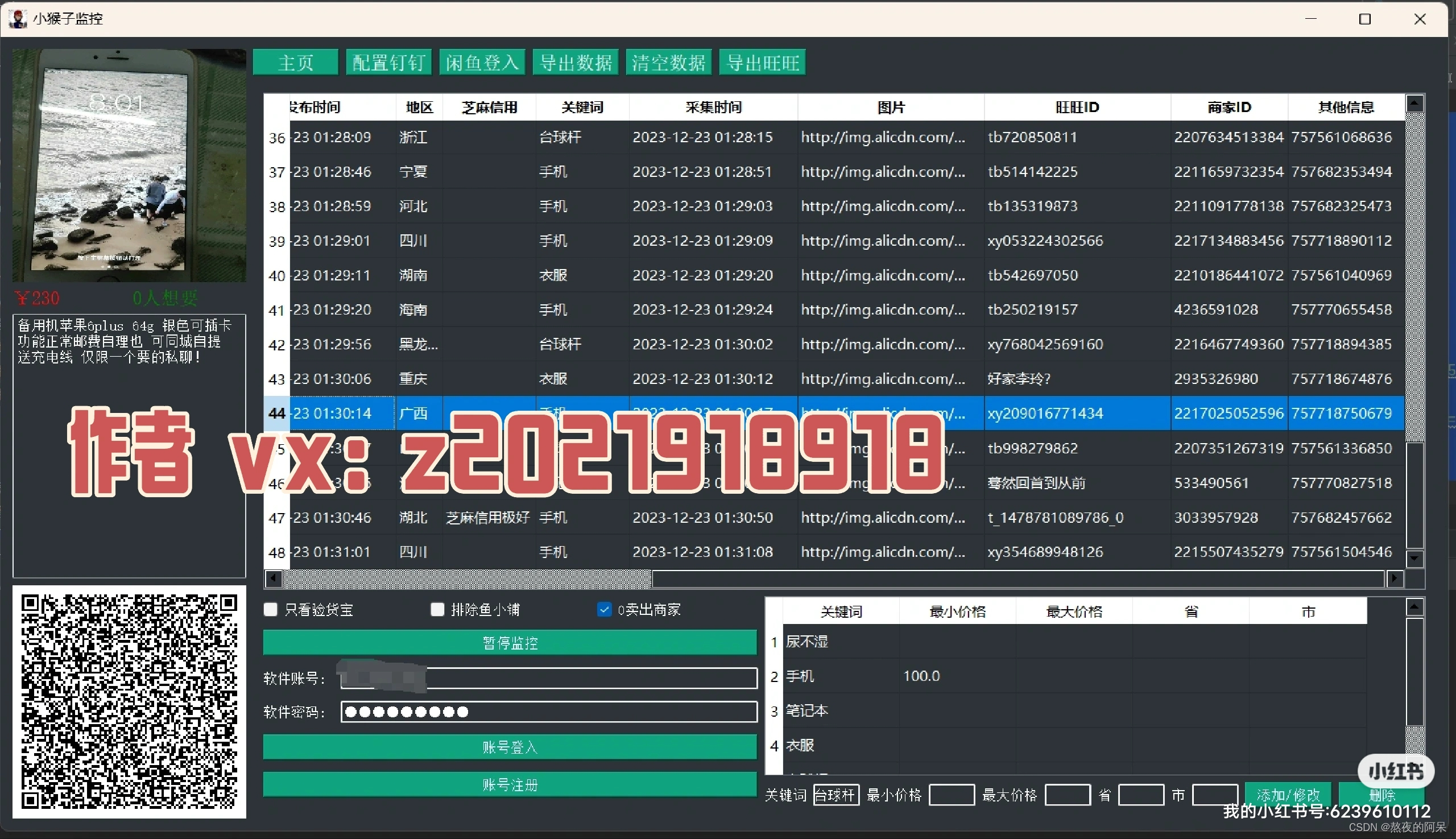
所用的技术:
Frida(hook app可以抓包 app版本号6.9.31,可以去豌豆荚下载历史版本,我上传的js仅对此版本有效)。
Mitmdump(抓包软件,可以和python进行交互)
Bat(自动化操作app,当然也可以使用按键精灵之类的软件)
开发环境:
Windows10
安卓手机(安卓7.0以下不用管系统证书安装的问题,视频中演示的手机小米4真机。也可以使用雷电模拟器,别的模拟器不推荐,雷电模拟器4.0以上为安卓7版本,需要解决系统证书的问题)
下面截图是运行环境
 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























