







实验内容1(持续更新)
后续会顺带发布理论知识的梳理, 刚发出来前一段时间可能会有bug, 后续会打补丁, 目前推荐的软件感觉很好用,
实验的第二三部分应该问题不大,第一部分可能会有部分问题, 大概会在几天内修复.
这篇博客里的大部分都是跟着学校的任务做的,学校讲的偏向考研,进度还要跟着老师的来,很不习惯,对于喜欢自学和撸代码的同学来说看下边这个博客效率更佳,总共花费不到几天时间,能高效的建立数据库操作的基础,应用各种SQL语句肯定是不在话下.
(SQL快速入门(是入门,而不是开门)舒适版
下边这一套是按照学校要求来的,也算是中规中矩,正好借此机会和我之前自学的对比一下相互取长补短.
配套的实验2已经更新,以查询的操作为主,提供百来条看得过去的假数据,提供了造假数据的方法,提供了20个习题以及笔者的参考答案.觉得实验1太基础的老铁可以直接去实验2写各种查询哟~
边写SQL边学数据库入门实验2(持续更新)
1. 数据库ER图设计部分
《数据库系统原理》课程实验 第一部分
实验目的:通过本实验使学生掌握根据需求说明设计概念模型的方法;掌握将概念模型转化为关系模型的方法;掌握创建数据库关系图的方法,了解MySQL中的基本函数。
实验原理及知识点:
1.概念模型。
总结起来大概就是ER图
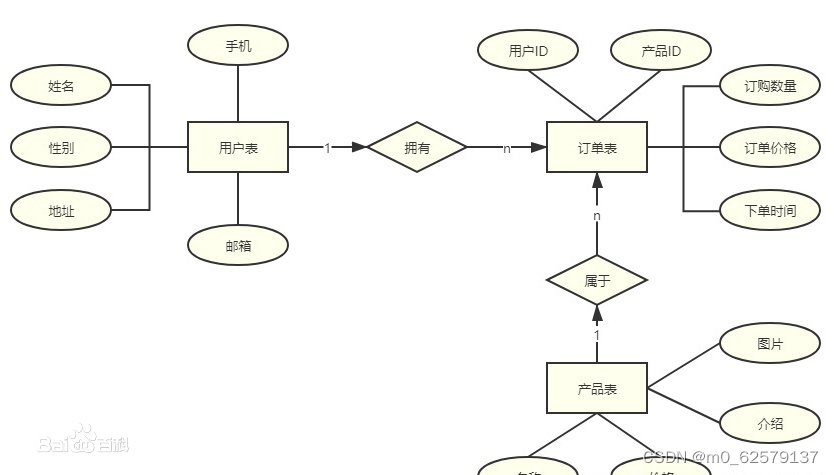
2.将概念模型转化为关系模型。
这个其实很简单,看下面这个例子就可以意会了.


3.创建数据库。
创建数据库的详细信息会在第二个实验中讲到,有这一章实验学院的表,为了舒服,我专门搞了个搞假数据的脚本,在数据库里提供百来条数据,提供一个用Navicate和python混合起来造假数据填充进数据库的方法.
4.创建数据表。
也简单,详见SQL必知必会的建表部分.
实验内容:(备注:完成后再直接粘贴到最终的实验报告)
第一部分:需求完成数据库的设计
假设要根据某大学计算机学院成绩管理的业务规则设计一个数据库的概念模型,这个学院的业务规则如下:
1、 该学院聘用多名教师,但每一位教师只属于该学院。教师包括教工号、姓名、学历、
职称、工资、电话号码信息。
一堆学院组成一个表,从目前来看学院应该包括学院名字,然后给个学院id作为主键.
一堆教师组成一个表, 教工号是主键,然后是姓名、学历、职称、工资、电话号码, 加上学院作为外键,参考学院表
2、一位教师可能讲多门课,每一门课可由多位教师讲授。课程包括课程号、课程名称、学时数和学分信息,每门课程可存在一门先行课程。
课程作为一个表,课程号是主键,然后是课程名称、学时数和 学分信息 先选课程的课程号(外键),参考这个课程的表
这里每个老师都可以教课,教课的时候一般会有上课时间,会有考勤啥的,这里简化一下给个总教学时长.
根据关系可以建一个教师开课表,教师编号作为外键,然后是开课时间,教师考勤
3、该学院有多名学生,且每一名学生只能属于该学院。学生包括学号、姓名、性别、出生年月、专业、籍贯、电话号码信息。
学院沿用`1.`中的学院表,学生学号是主键,然后是姓名、性别、出生年月、专业、籍贯、电话号码信息
4、每一名学生可选修多门课,且一门课有多名学生选;学生所修课程的成绩包括平时成绩与期末成绩。
建一个学生选课表,包括学生id(外键),课程号(外键),考勤总时间,平时成绩,期末考试成绩,总成绩,教师id(外键,这个其实不必要,但是多表查询比较麻烦,这样后续查起来舒服一些)
很舒服的是这个需求写的不错,基本上看到需求表就出来了,剩下的就是打字了
实验内容及步骤:
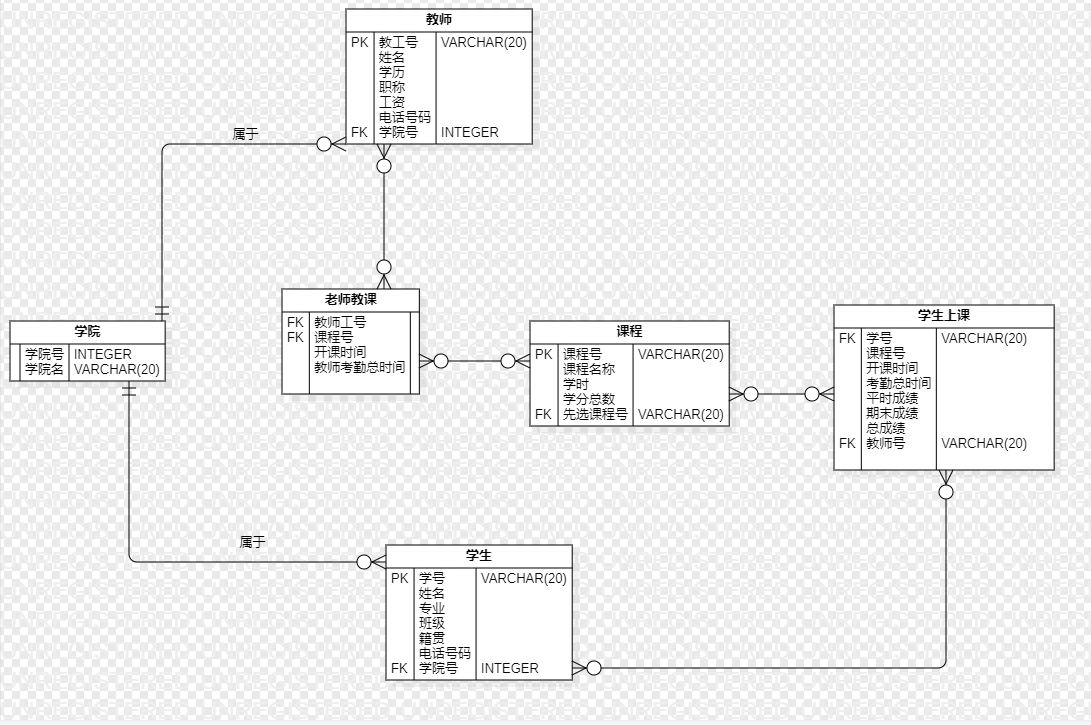
1. 根据需求说明设计某大学数据库的概念模型
模型:
学院(学院号#,学院名)
教师(教工号#,姓名,学历,职称,工资,电话号码,学院号-FK reference to 学院.学院号)
课程(课程号#,课程名称,学时,学分总数,先选课程号[]-FK reference to 课程.课程号)
学生(学号#,姓名,性别,出生年月,专业,籍贯,电话号码,学院号-FK reference to 学院.学院号)
老师教课(老师号-FK reference to 教师.教工号,课程号-FK reference to 课程.课程号,开课时间,老师考勤 )
学生上课(学生号-FK reference to 学生.学生号,课程号-FK reference to 课程.课程号,开课时间(同步老师教课的开课时间),考勤总时间,平时成绩,期末考试成绩,总成绩,教师号-FK reference to 教师.教工号)
一堆学院组成一个表,从目前来看学院应该包括学院名字,然后给个学院id作为主键.
一堆教师组成一个表, 教工号是主键,然后是姓名、学历、职称、工资、电话号码, 加上学院作为外键,参考学院表
教师
课程作为一个表,课程号是主键,然后是课程名称、学时数和 学分信息 先选课程的课程号(外键),参考这个课程的表
这里每个老师都可以教课,教课的时候一般会有上课时间,会有考勤啥的,这里简化一下给个总教学时长.
根据关系可以建一个教师开课表,教师编号作为外键,然后是开课时间,教师考勤
学院沿用`1.`中的学院表,学生学号是主键,然后是姓名、性别、出生年月、专业、籍贯、电话号码信息
建一个学生选课表,包括学生id(外键),课程号(外键),考勤总时间,平时成绩,期末考试成绩,总成绩,教师id(外键,这个其实不必要,但是多表查询比较麻烦,这样后续查起来舒服一些)
2. 写出该模型的关系模型(关系模式)
按书上的写,或许应该大概是这样:
模型:
学院(学院号#,学院名)
教师(教工号#,姓名,学历,职称,工资,电话号码,学院号#)
课程(课程号#,课程名称,学时,学分总数,先选课程号#)
学生(学号#,姓名,性别,出生年月,专业,籍贯,电话号码,学院号#)
关系:
老师教课(老师号#,课程号#,开课时间,老师考勤 )
学生上课(学生号# ,课程号#,开课时间,考勤总时间,平时成绩,期末考试成绩,总成绩,教师号#)
自己写大概是这样:
学院(学院号#,学院名)
教师(教工号#,姓名,学历,职称,工资,电话号码,学院号-FK reference to 学院.学院号)
课程(课程号#,课程名称,学时,学分总数,先选课程号[]-FK reference to 课程.课程号)
学生(学号#,姓名,性别,出生年月,专业,籍贯,电话号码,学院号-FK reference to 学院.学院号)
老师教课(老师号-FK reference to 教师.教工号,课程号-FK reference to 课程.课程号,开课时间,老师考勤 )
学生上课(学生号-FK reference to 学生.学生号,课程号-FK reference to 课程.课程号,开课时间(同步老师教课的开课时间),考勤总时间,平时成绩,期末考试成绩,总成绩,教师号-FK reference to 教师.教工号)
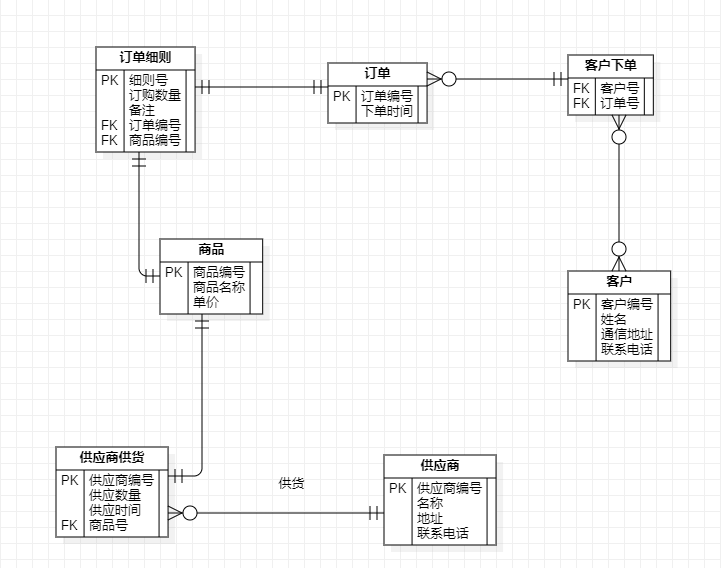
某销售商的订单系统需要如下信息:
1. 每个供应商包含供应商编号、名称、地址、联系电话信息。
2. 每种商品包含商品编号、商品名称、单价信息。
3. 每个供应商可供应多种商品,每种商品可由多个供应商供应。需要描述供应商供应商品的数量和供应的时间。
4. 客户包含客户编号、姓名、通信地址、联系电话信息。
5. 客户可以同时下很多订单,但是一个订单只能由一位顾客下单。订单中包含订单编号,下单时间。
6. 一个订单可以同时包含多个订单细则,而一个选定的订单细则只能由一个订单来列出。订单细则中包含订单细则号,订购数量。
7. 一个订单细则只能引用一种商品,而每种商品可以被多个订单细则引用。
实验内容及步骤:
1. 根据需求说明设计概念模型
2. 写出该模型的关系模型(关系模式)
供应商(供应商编号#,名称,地址,联系电话)
商品(商品编号#,商品名称,单价信息)
客户(客户编号#,姓名,通信地址,联系电话)
订单(订单编号#,下单时间)
订单细则(细则号#,订购数量,备注,订单编号#,商品编号#)
供应商供货(供应商编号#,商品号#,供应数量,供应时间)
客户下单(#客户号,#订单号)
第二部分:熟悉MySQL的实验环境
一、 MySQL的安装
https://dev.mysql.com/downloads/mysql/
https://support.microsoft.com/en-ph/help/2977003/the-latest-supported-visual-c-downloads
https://www.microsoft.com/zh-cn/download/confirmation.aspx?id=40784
2. MySQL的启动和登录MySQL服务
由于原先实验给出的示例太老了,而且现在这么不使用且用起来不舒服,这里结合我自己的尝试,给出以下几个环境的配置方法:
虽然在服务器上或者是在虚拟机上装mysql相对麻烦, 学生优惠的服务器一年几十块钱,好一点的也只要120, 能干很多事,还是很值的. 在云上部署服务器和业务最贴近实际使用的需求,首先推荐. 其次就是专门的远程数据库, 这个性价比很高, 我这个数据库是二十块钱3个T, 2M带宽的好像, 很耐用 ,也比较推荐这种.
虚拟机是最省钱也比较方便的方法了, 因为贴近服务器, 又便于入门,也比较推荐这种.
最后是本地mysql了,这个相较于前几个优势在于门槛低, 使用非常方便, 如果用这套方案的话, 就要重复体现出方便的优势, 不然还不如找个服务器去折腾. 篇幅有限, 这里前三个就只放一个当初我认为有用的链接了, 只演示一下最后一个.
(1)远程linux类服务器+MySQL+本地终端
有空再填坑,略~
(2)远程云数据库产品+本地终端
有空再填坑,略~
(3)虚拟机linux类服务器+MySQL+本地终端
有空再填坑,略~
(4)本地MySQL+本地终端
- 准备以下软件环境:.
下载好了像安软件一样无脑next就好了,都2022年了,安装个软件真没必要一步一步截图.
-
Navicate
Navicat | 下载 Navicat Premium 14 天免费 Windows、macOS 和 Linux 的试用版
是不是Premium版都行,推荐Premium版,主要是用这个直观的看数据库里的数据,下载好了有个十几天的试用.
-
Jetbrains DataGrip
Download DataGrip: Cross-Platform IDE for Databases & SQL (jetbrains.com)
比Popsql等感觉好用,可以之间运行触发器的sql语句,功能非常强大,也有三十天的免费试用期.
-
Git+Github(可选)
gitee,本地gitlab都行,这里只给出git+github的示例了
-
MySql8.0
https://www.mysql.com/downloads/
下载点这个开源版的就好了,不然好像还要一堆注册啥的,安装完了会自己后台运行,很省心. 会在引导界面里让用户自己设置用户名和密码, 用户名和密码要记住. 后续终端设备就是通过这个连接的.
-
StarUml(画ER图用,可选)
下载后有三十天使用,一般试用期到之前就够用了(用老版本的也行)
-
SQL必知必会纸质书或者是电子书
里边的例子简洁,代码可运行,有练习与参考答案,这本书看起来就像是一个大佬和你侃侃而谈,SQL学习的入门神书.
- 下载数据集
MySQL Crash Course – Ben Forta
下载后加压到一个知道的地方,
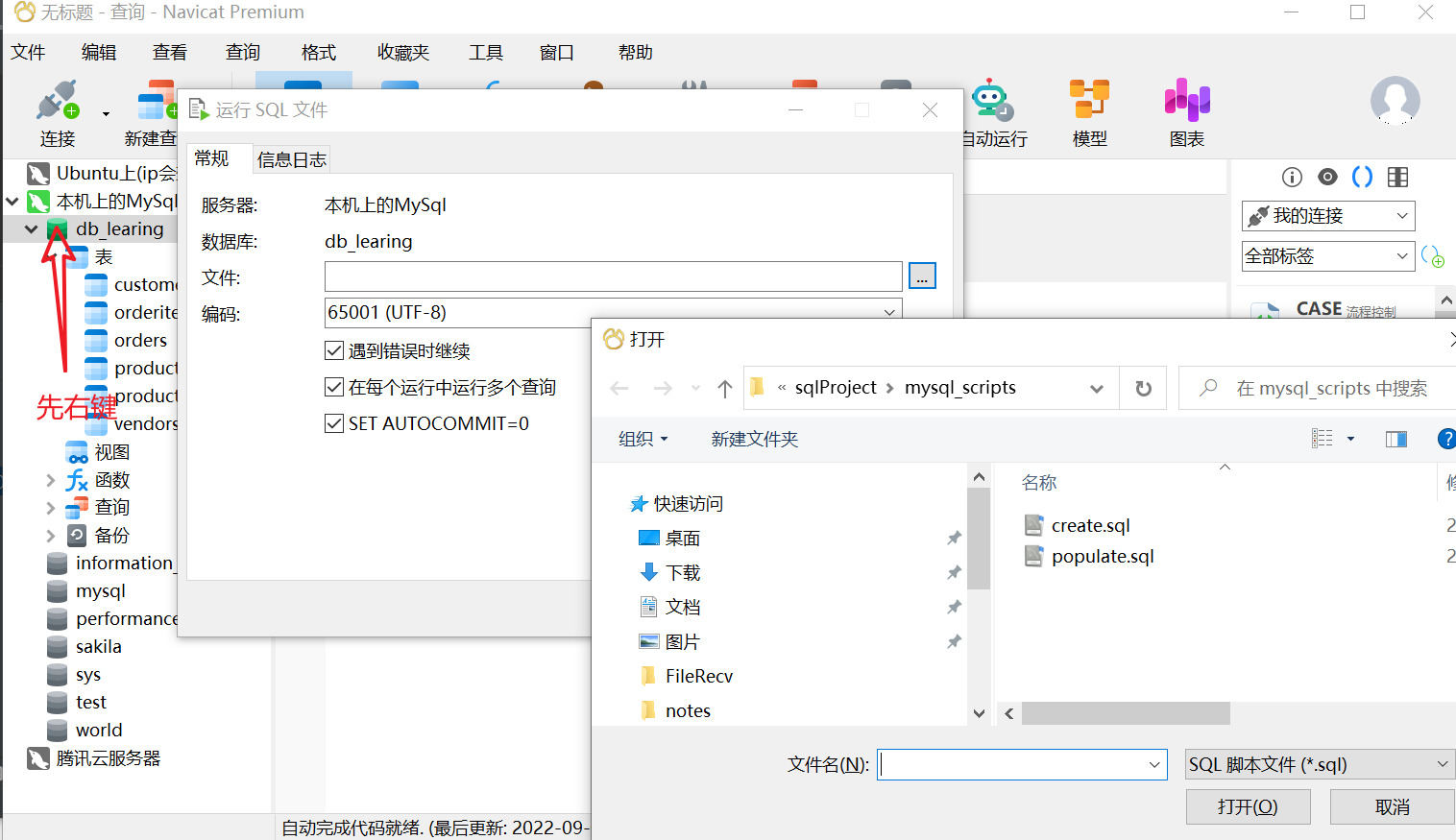
随便建立一个数据库,我这里名字叫db_learning
然后运行sql文件:
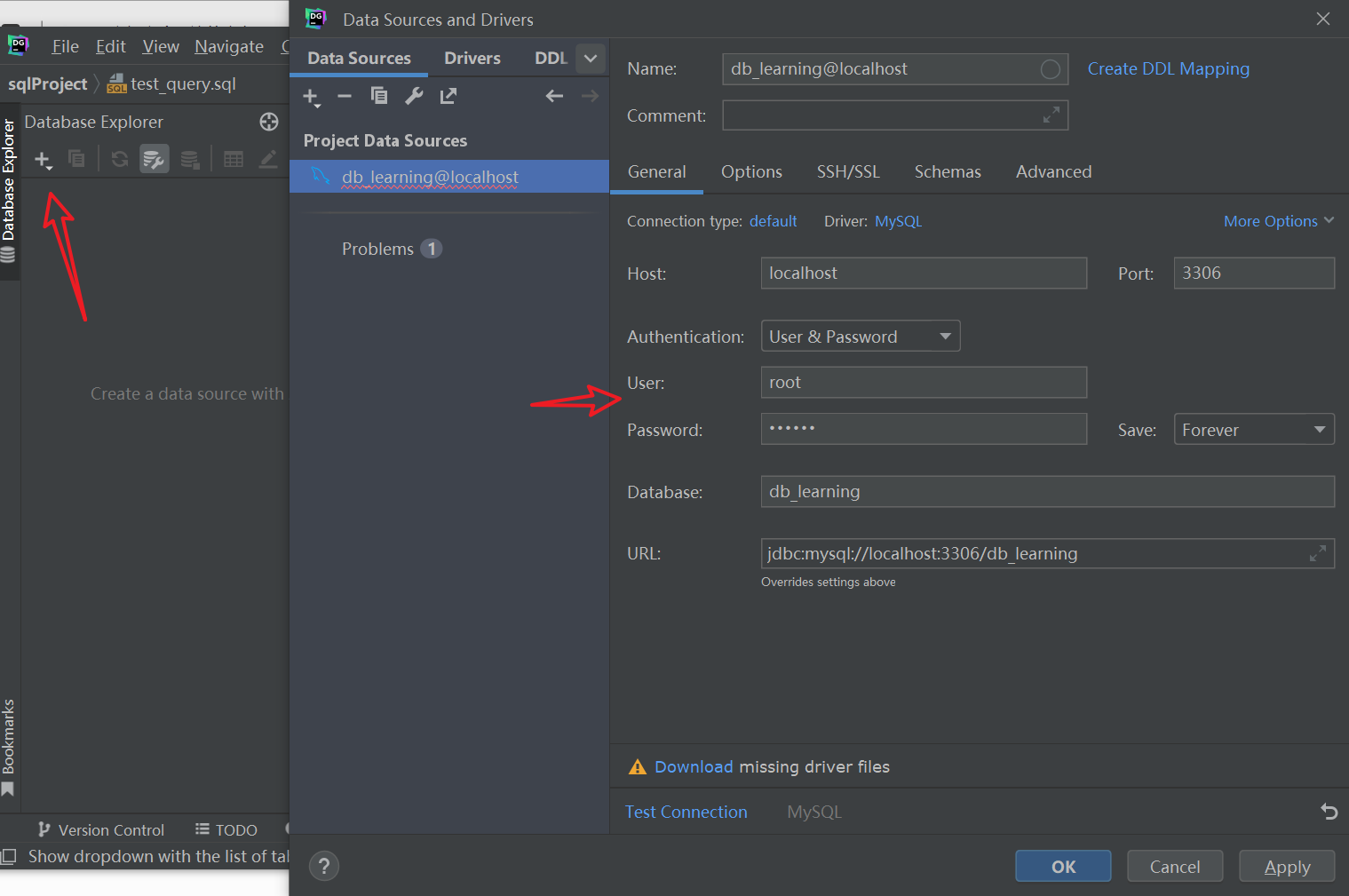
然后配置一下DataGrip连接:
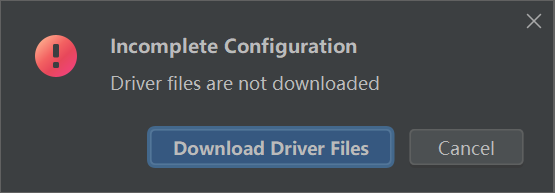
安装驱动: 点一下那个就好了
3.配置完成后随便运行一句话测试一下
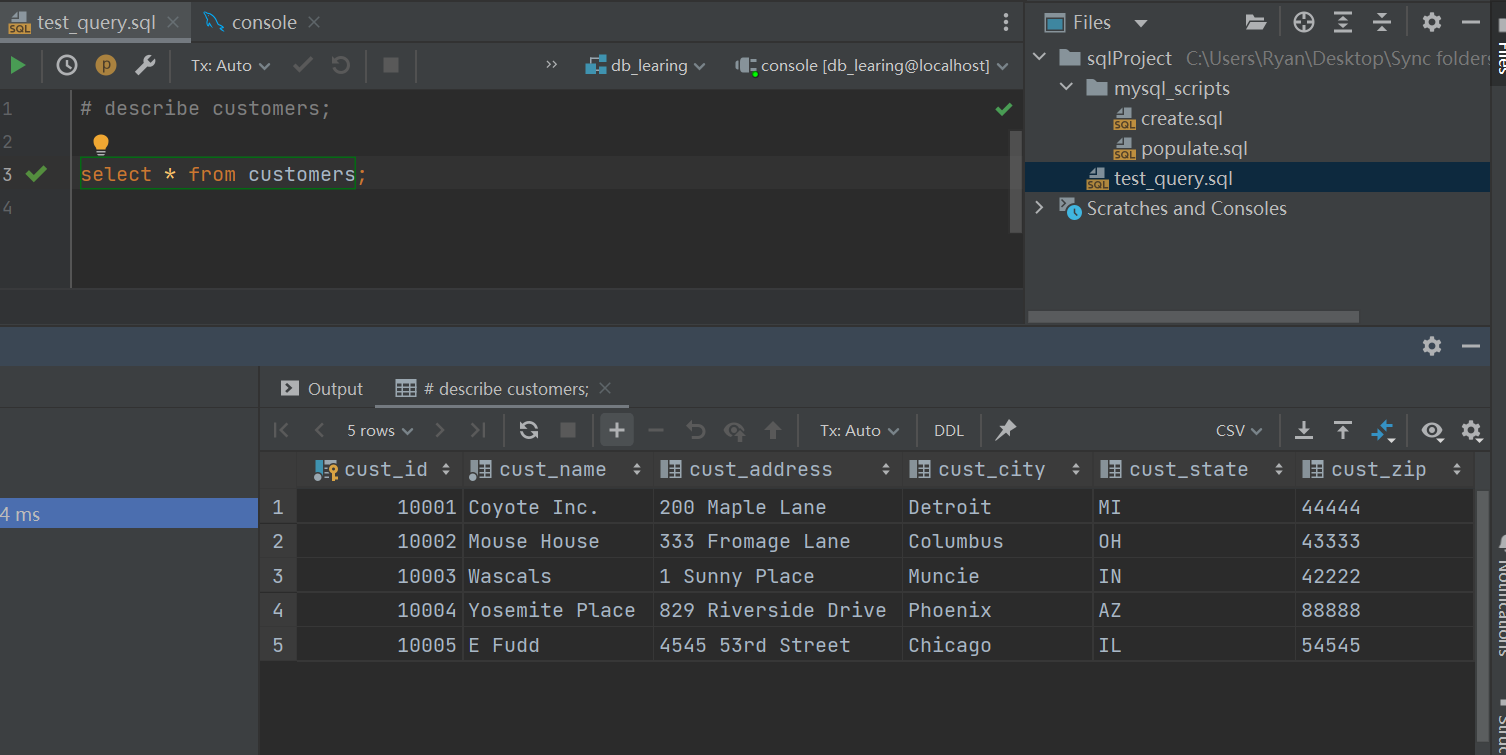
*4.git简单提交一下
SQL偏向一种工具,顺便和Git一起用也不错,一般这种的都是用着用着就会了,大概用个一年,就很熟悉很熟练了.
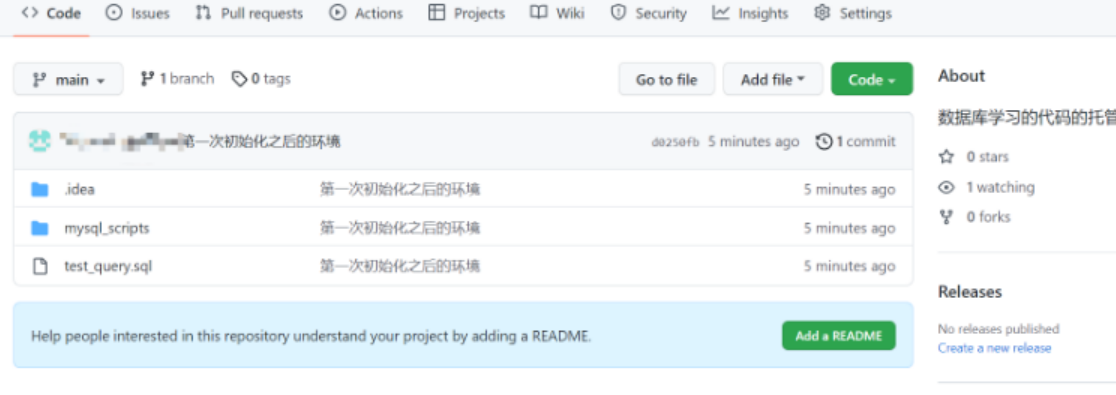
按ctrl+回车运行
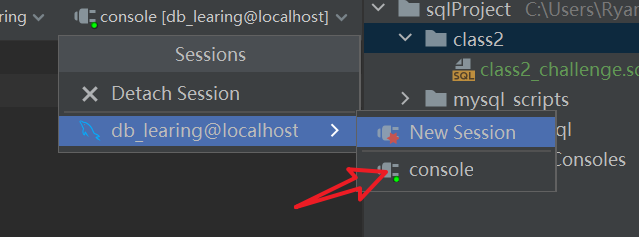
运行需要选择会话,选择这个
3. 了解MySQL的基本语法
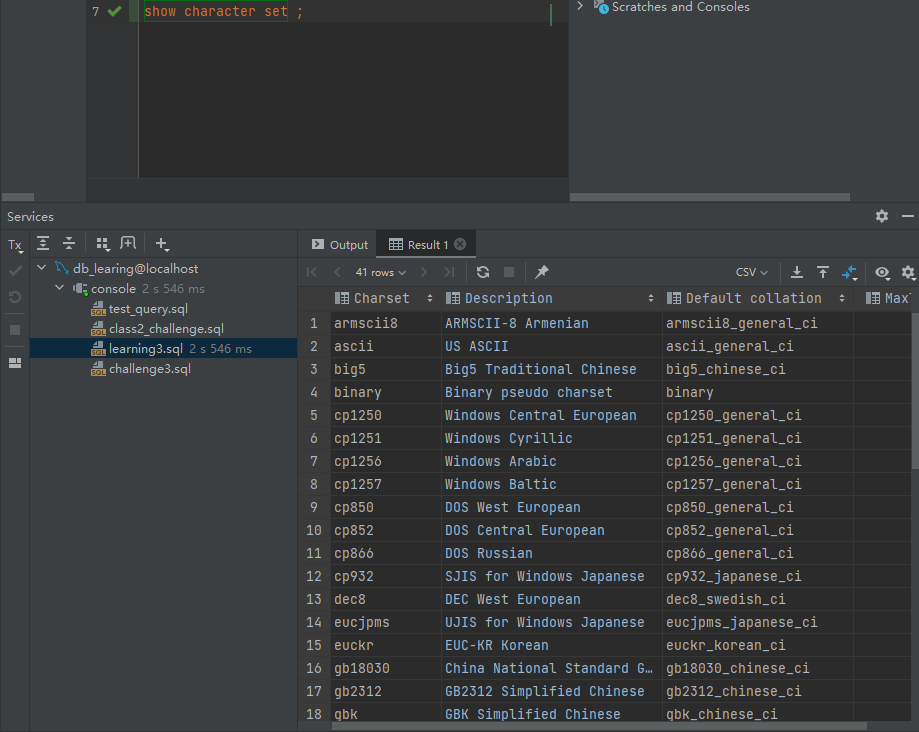
(1)在命令窗口查看MySQL的字符集。 show charset; show char set;
show character set ;
(2)查看mySQL字符序
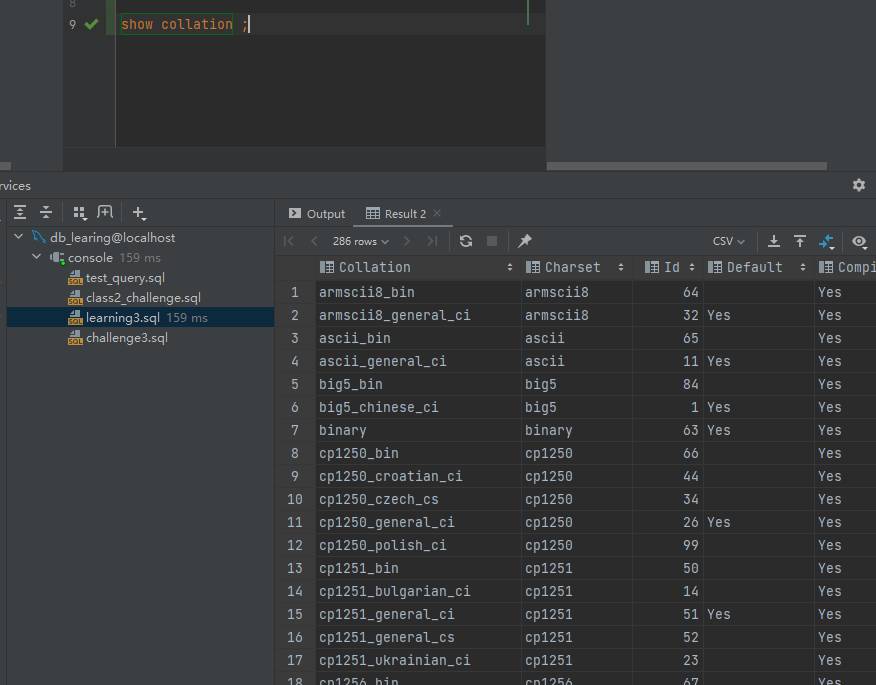
show collation ;
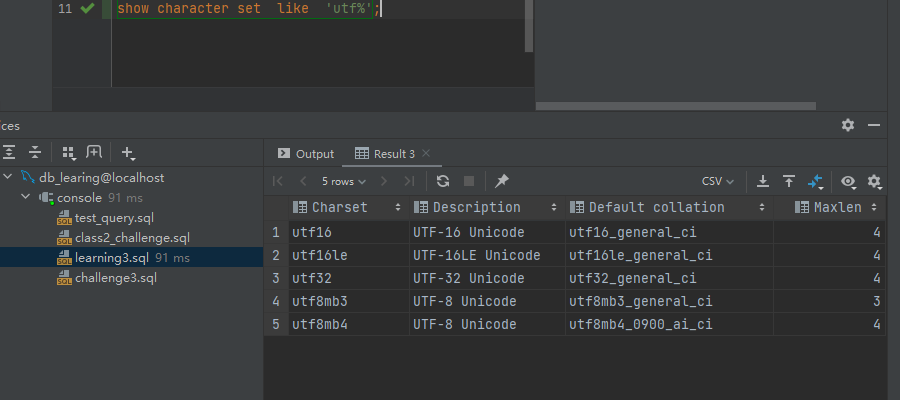
(3)查看特定字符集信息(例如:以utf开头的字符集以及其对应的字符序)
show character set like 'utf%';
//模糊查询
2、mySQL的系统变量
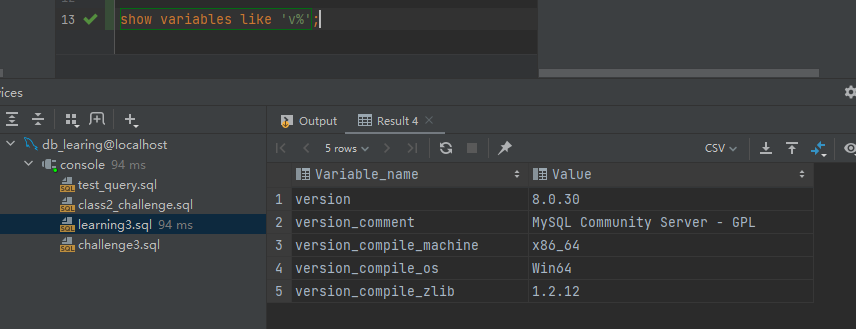
(1)查看字符v开头的系统变量,如下图所示:
show variables like 'v%';
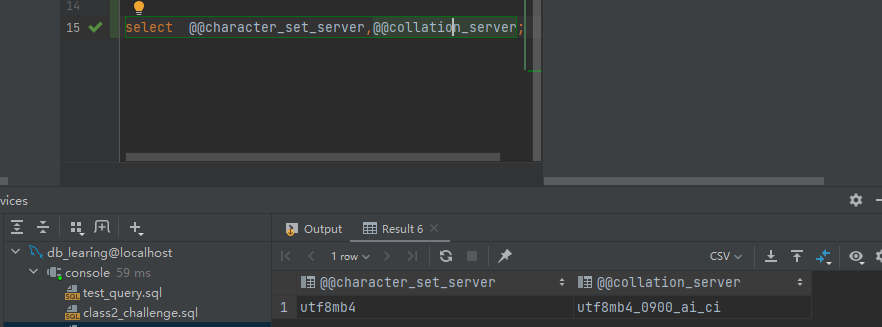
**(2)**查看MySQL Server当前的Charset和Collation
(注意:系统全局变量必须在变量名称前加两个@@符号)
select @@character_set_server,@@collation_server;
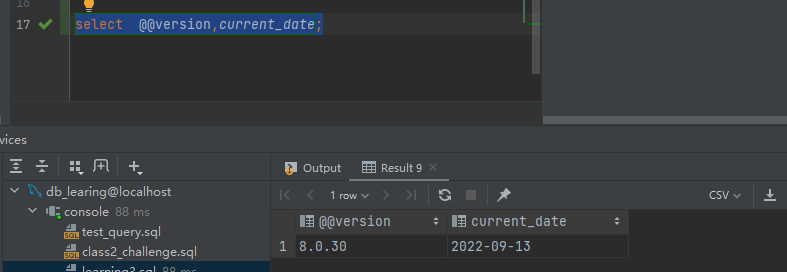
(3) 用系统变量查看MySQL服务器的版本和当前系统日期(常量current_date)。
select @@version,current_date;
MySQL的常用函数可参考以下网站:
https://dev.mysql.com/doc/refman/5.7/en/functions.html
https://dev.mysql.com/doc/refman/8.0/en/functions.html
https://www.runoob.com/mysql/mysql-functions.html
实验内容: (附上实验MySQL命令和结果截图)
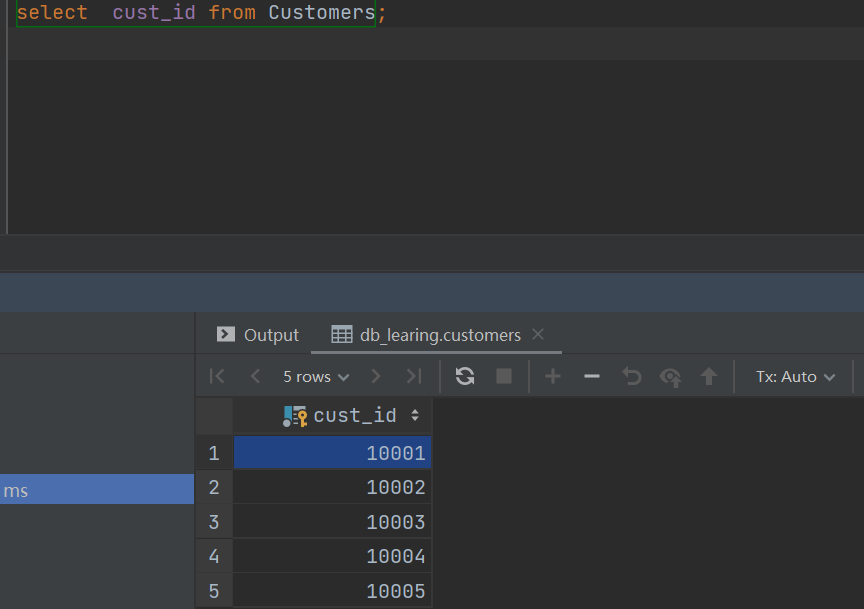
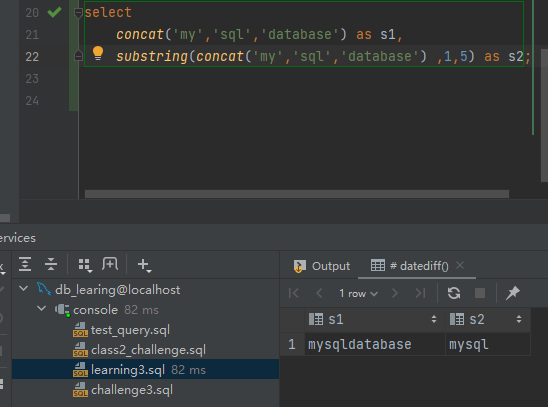
(1)利用concat()函数将字符串‘my’,‘sql’,’database’连接,并以别名s1显示连接后的字符串,再利用substring()函数获得子串’mysql’,并以别名s2显示该子串。
select
concat('my','sql','database') as s1,
substring(concat('my','sql','database') ,1,5) as s2;
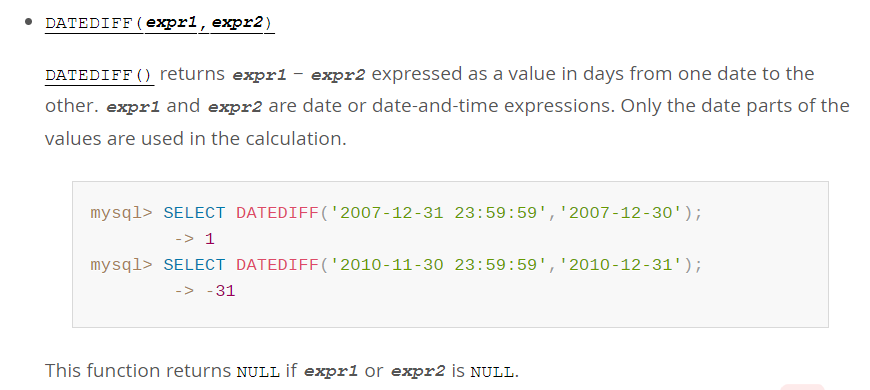
(2)如果2023年2月1日放假,使用datediff()函数计算现在离放假还有多少天。
去官网查询一下,是这么用:
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_datediff
去bing搜索也差不多.
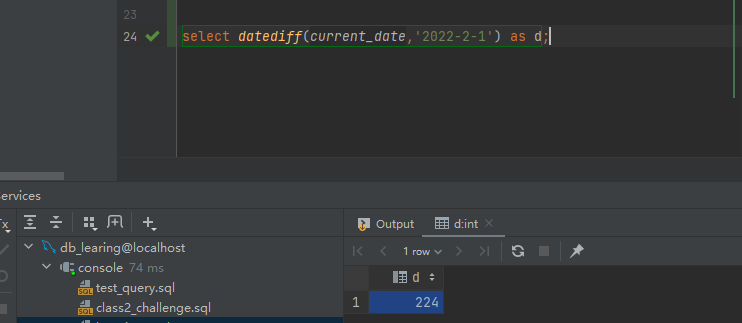
select datediff(current_date,'2022-2-1') as d;
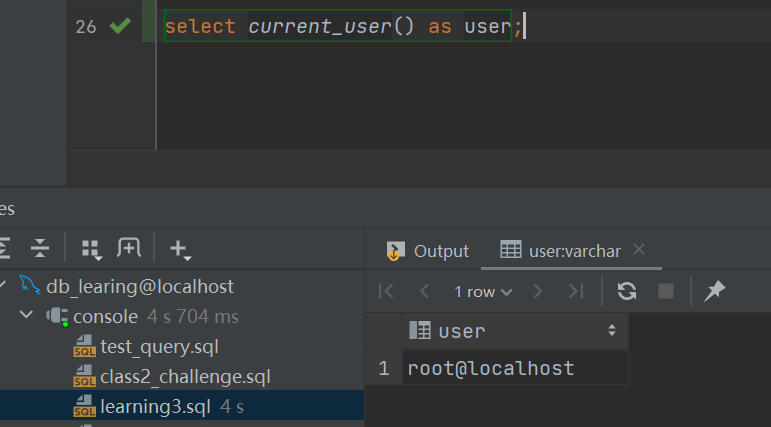
(3)返回MySQL服务器的版本当前数据库名和当前用户名信息,并查看当前用户连接MySQL服务器的次数。
https://dev.mysql.com/doc/refman/8.0/en/information-functions.html#function_current-user

select current_user() as user;
(4)利用随机函数输出10—80的任意两个数(含2位小数)。
https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_rand
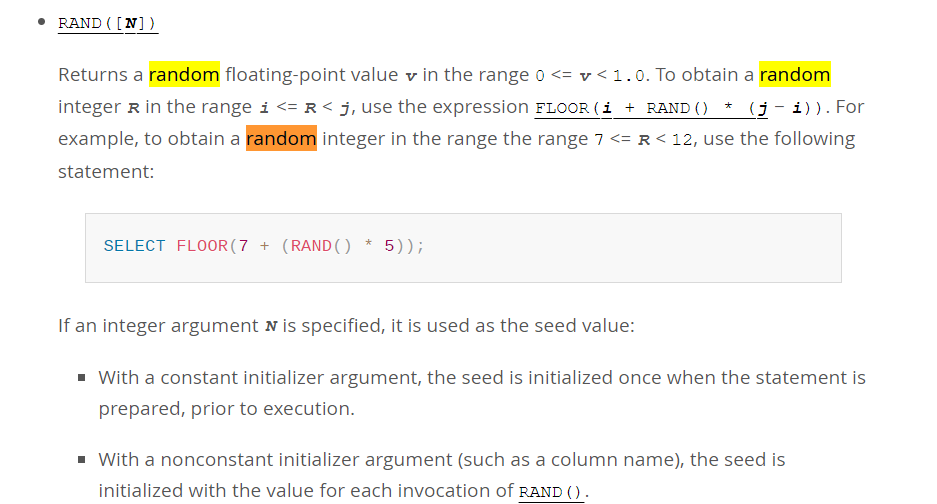
rand()返回一个[0,1)区间的数,那应该是10+70*rand()了,这样不会小于10,也不会大于八十.
floor(float x)返回一个不大于x的整数,这样就能取整了.
https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_floor

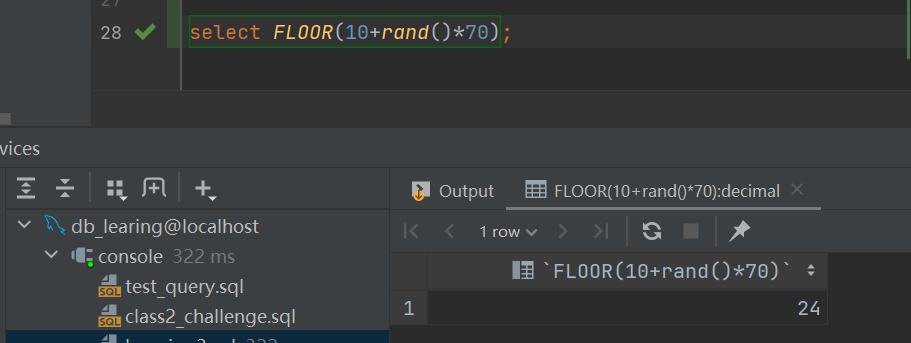
最后验证一下,取0.99的时候是69.3,加上10为79.3,向下取整为79,符合上限要求,下限显然也符合,不再验证.
如果是要取[0,80]区间的话改成10+71*rand()即可.
select FLOOR(10+rand()*70);
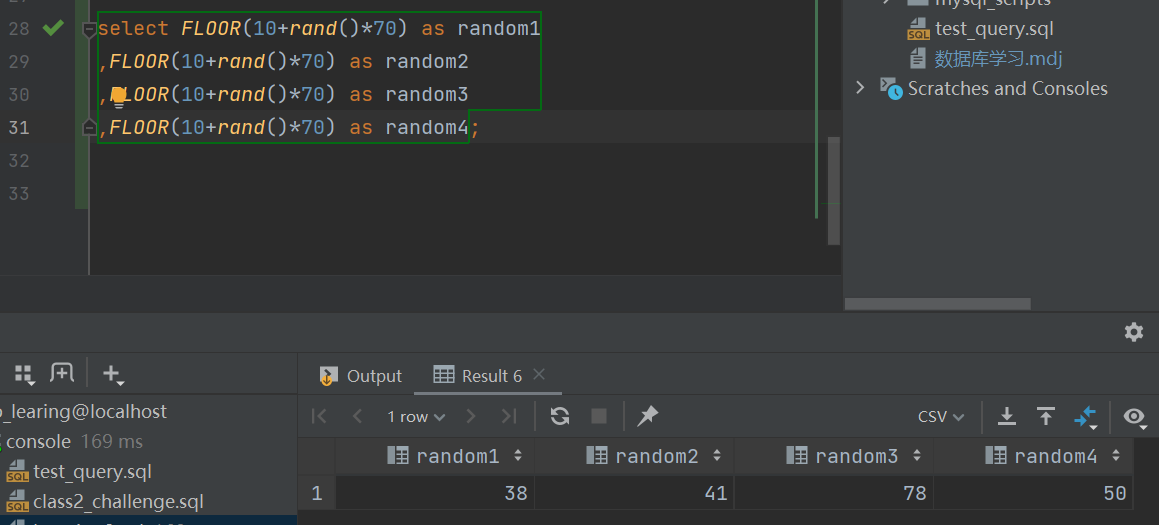
只有一个效果太不明显了,感觉还是多选几个容易看得出来:
select FLOOR(10+rand()*70) as random1
,FLOOR(10+rand()*70) as random2
,FLOOR(10+rand()*70) as random3
,FLOOR(10+rand()*70) as random4;
(5)计算900天后的日期和1000分钟后的日期时间。
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_adddate
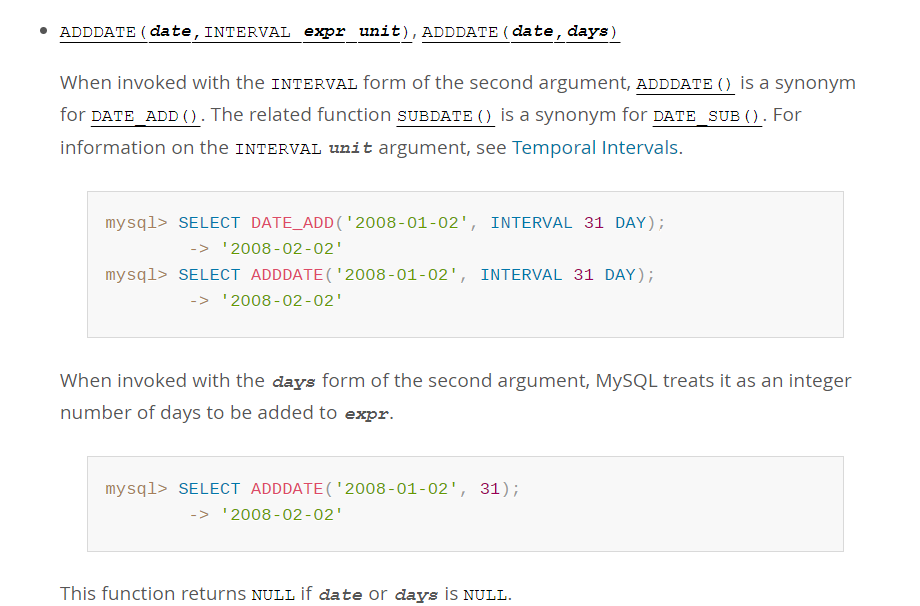
计算900天后很简单,参考示例就好了.
select adddate(current_date,900);
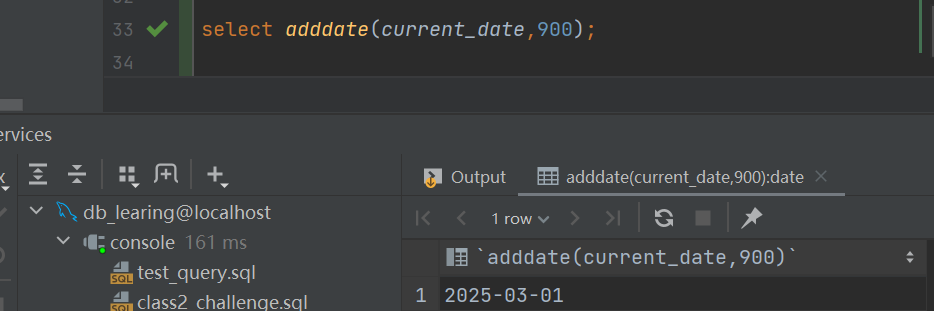
加1000分钟需要知道现在的时间,具体到分钟,这时候想到了时间戳,时间戳就是年月日时分秒,还有些精准的时间戳能精准到毫秒以下.
mysql里是有这个关键字的,仿照例子搞一个1000分钟的变量加进去,得到结果.
select adddate(current_timestamp ,interval 1000 minute );
日期与时间的相关函数都在这里,不得不说,这个帮助文档的搜索还是蛮好用,凭借四级左右的英语水平就能比较流畅的搜索了,而且基本上很多都在第一个,点进去后有下一步的索引页.
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html

4. 第一次实验总结
试了试从官网查函数资料,发现很方便,而且因为是从官网上查下来的,很权威,看起来很专业,很舒服,很有成就感.
经过前边的测试,先打出关系模型在画ER图是很快的.之前都是自己分析一波,然后把分析的敲下来,然后对着自己分析的建表,关系比较乱. 现在对着需求分析关系模型,分析完了就有记录,趁着没忘了外键是啥,赶紧画ER图,效率提高了.
装环境的话我也就装过亿次. 在虚拟机,树莓派,腾讯云服务器上,本机上,都有我的mysql, 最后发现还是云上数据库产品最好用. 用了popsql,mysql work branch,navicate premium,命令行等等工具, 最后发现还是jetbrains的DataGrip好用,相较于popsql而言,它可以建立工程,执行sql文件,执行触发器,并且代码洞察也很到位,很舒服. 这次用现代化的工具装个舒适点的环境, 敲代码的时候头也不疼了,腰也不酸了,整个人都舒服极了. 私以为像python,sql,这些工具类型的语言可以和工具类型的软件一起学着用, 比如说git,staruml,gitlab,linux常用命令这些, 基本上用个几个月就会用了. 上课这种慢慢来的方式还是很舒服的, 有种岁月静好的感觉.
最后是熟悉几个sql的常用函数, 所幸有点底子,用起来也很舒服, 实验里给的链接用起来很好用,很舒服.
这个实验内容写了一段时间发现也适合当作博客来写,浩浩荡荡忙活一晚上,终于写完了, 欢迎各位评论留言, 一键三连啊~















 6965
6965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









