







文章目录
求字符串长度
strlen
函数功能
求一个字符串的长度,计算的是’\0’之前出现的字符个数
函数参数
size_t strlen( const char *string );
# size_t 是函数的返回类型
# char* string 是函数参数
模拟实现
size_t my_strlen(char *str)
{
int count = 0;
while (*str != '\0')
{
count++;
str++;
}
return count;
}
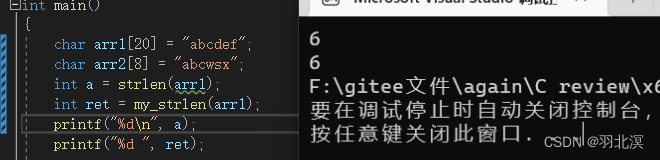
注意事项
1.strlen的结束标志是’\0’,因此要求传给strlen的参数必须带’\0’,否则strlen的结果就是随机值。(因为strlen会一直向后访问,直到找到’\0’。可以说是一个大情种了(手动滑稽))。
2.strlen的返回值是无符号整形,如果用两个strlen相减的话得到的结果始终是非负数。
长度不受限制的字符串函数
strcpy
函数功能
字符串拷贝,将一个字符串的内容拷贝到另一个字符串中(包括’\0’)
函数参数
char* strcpy(char * destination, const char * source );
# char* 是函数的返回值,返回的是目标空间的起始地址
# source 是要拷贝的字符串
# destination 是目标空间
模拟实现
char* my_strcpy(char* dest, char* src)
{
assert(dest&&src);//assert断言,保证dest和src不为空指针,头文件为#include<assert.h>
char* ret = dest;//函数要求返回目标空间的起始地址
while (*dest++ = *src++)
{
;
}
return ret;
}
while循环里的语句是将src指向的内容拷贝到dest当前指向的位置,再用拷贝的结果来作为判断,最后对两个指针进行自增操作。

注意事项
源字符串必须要是以"\0"结束
目标空间要足够大
目标空间必须可修改。
strcat
函数功能
字符串追加,在一个字符串的末尾追加另一个字符串(包含’\0’)
函数参数
char * strcat ( char * destination, const char * source );
# char* 是函数的返回值,返回的是目标空间的起始地址
# source 是要追加的字符串
# destination 是目标空间
模拟实现
char* my_strcat(char* dest, char* src)
{
assert(dest&&src);
char* ret = dest;
//先找到dest的末尾,再字符串拷贝
while (*dest != '\0')
{
dest++;
}
while (*dest++ = *src++)
{
;
}
return ret;
}
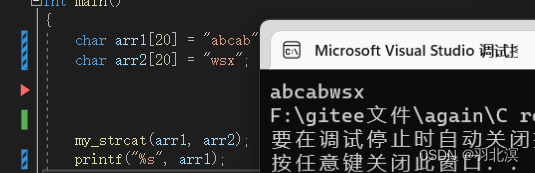
注意事项
1.源字符串必须以’\0’结束
2.目标空间必须足够大,能够放下追加后的字符
3.目标空间必须是可修改的
4.strcat不能自己给自己追加。(因为自己给自己追加会覆盖掉末尾的’\0’,导致死循环)
strcmp
函数功能
字符串比较,比较两个字符串大小,如果相等则往后移,直到’\0’结束
函数参数
int strcmp ( const char * str1, const char * str2 );
# int 函数返回值
# char* str1 char* str2 用于比较的两个字符串
#返回值
>0 : str1 大于 str2;
=0 : str1 等于 str2;
<0 : str1 小于 str2
模拟实现
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);
//如果相等就往后比较
while (*str1 != '\0' && *str2 != '\0' && *str1 == *str2)
{
//相等的情况在这里,如果进来循环并且有一个为\0,那就说明两个字符串都到结尾了
if (*str1 == '\0')
return 0;
str1++;
str2++;
}
/*if (*str1 > *str2)
return 1;
else
return -1;*/
return(*str1 - *str2);//第一个字符串大于第二个字符串,则返回大于0的数字,第一个字符串小于第二个字符串,则返回小于0的数字。既然它们不相等,那么直接作差就能得到大小
}
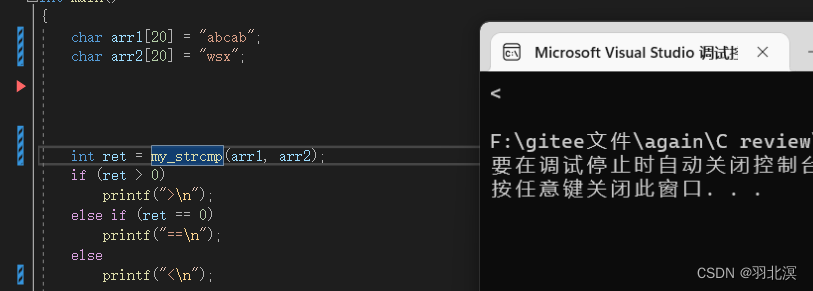
注意事项
字符在内存中是以ASCII码值存储的,因此比较的也是每一对字符的ASCII码值
长度受限制的字符串函数
由于strcpy,strcat,strcmp等字符串函数不受长度的限制,容易造成越界的问题存在安全隐患。因此C语言还给我们提供了另外几种相对安全的字符串函数,即strncpy,strncat,strncmp。它们比原字符串函数多了一个参数,这个参数是用于指定操作的字节数。因为受到长度的限制,不会无脑梭哈,因此也相对更安全。(不是绝对安全,毕竟我要写bug谁也拦不住(斜眼笑))。
strncpy
函数功能
字符串拷贝,把一个字符串中指定的字节数的内容拷贝到另一个字符串中
函数参数
char * strncpy ( char * destination, const char * source, size_t num );
# char* 是函数的返回值,返回的是目标空间的起始地址
# source 是要拷贝的字符串
# destination 是目标空间
# num 是要拷贝的字节数
模拟实现
char* my_strncpy(char* dest, const char* src, size_t num)
{
assert(dest && src);
char* ret = dest; //记录目标空间的起始地址
while (num--)
{
*dest = *src;
if (*dest == '\0') //如果*dest为0,说明将src的结束字符赋给了dest,这种情况下源字符串的长度小于num
{
while (num--)
{
//如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。(与库函数的实现方式保持一致)
*dest++ = 0;
}
break;
}
dest++;
src++;
}
*dest = '\0'; //在dest的末尾补上结束字符
return ret;
}
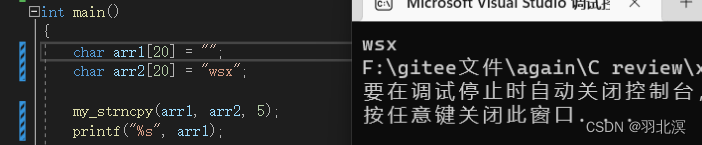
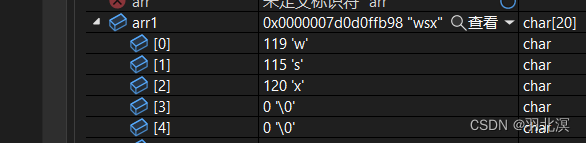
注意事项
可以看到,如果源字符串中的内容不够num个,会把用’\0’来补足。
strncat
函数功能
字符串追加,将一个字符串中num个字节的内容拷贝到另一个字符串的末尾,并在末尾补充’\0’。
函数参数
char * strncat ( char * destination, const char * source, size_t num );
# char* 是函数的返回值,返回的是目标空间的起始地址
# source 是要追加的字符串
# destination 是目标空间
# num 是要追加的字节数
模拟实现
char* my_strncat(char* dest, const char* src, size_t num)
{
assert(dest && src);
char* ret = dest; //记录目标空间的起始地址
//找到dest末尾
while (*dest != '\0')
{
dest++;
}
//strncpy
while (num--)
{
*dest = *src;
if (*dest == '\0') //如果*dest为0,说明将src的结束字符赋给了dest,这种情况下源字符串的长度小于num
{
//如果源字字符串的长度小于num,则只复制到终止空字符的内容。(与库函数的实现方式保持一致)
return ret; //直接返回
}
dest++;
src++;
}
*dest = '\0'; //则在dest的末尾补上结束字符
return ret;
}
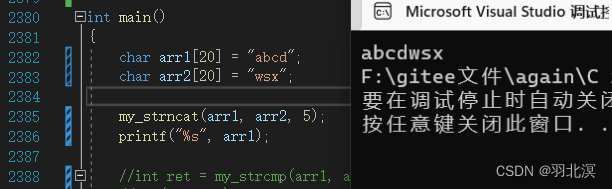
注意事项
如果源字符串的内容少于num个字节,也只复制到终止空字符的内容,也就是说并不会再去补’\0’。
strncmp
函数功能
字符串比较,比较两个字符串中前num个字节内容的大小
函数参数
int strncmp ( const char * str1, const char * str2, size_t num );
# int 函数返回值
# char* str1 char* str2 用于比较的两个字符串
# num 要比较的字节数
#函数返回值
>0 : str1 大于 str2;
=0 : str1 等于 str2;
<0 : str1 小于 str2
模拟实现
int my_strncmp(const char* str1, const char* str2, int num)
{
assert(str1 && str2);
for(int i=0;i<num;i++)//库中使用的是for循环,因此我们也用for循环
{
if (*str1 == *str2)
{
str1++;
str2++;
}
else
{
return(*str1 - *str2);
}
}
return 0;
}

注意事项
比较的是每一对字符中的ASCII码值。
对前num个字节逐一比较,除非遇到’\0’或者不相等字符。
字符串查找函数
strstr
函数功能
查找子串,在一个字符串中查找是否包含该子串
函数参数
char * strstr ( const char *str1, const char * str2);
# char* 函数返回值,返回字符串中子串的起始地址,若找不到,则返回NULL;
# char* str1 要搜索的字符串;
# char* str2 子串
模拟实现
分析:

代码实现:
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
//根据分析,至少要三个指针
const char* s1 = str1;
const char* s2 = str2;
const char* p = str1;
while (*p)
{
s1 = p;//
s2 = str2;
while (*s1 != '\0' && *s2 != '\0' && *s1 == *s2)
{
s1++;
s2++;
}
if (*s2 == '\0')
return (char*)p;
p++;//p记录的是上次匹配的起始位置,匹配失败要从上次的位置的下一个位置开始匹配
}
return NULL;
}
总结
每次匹配失败后,子串回到起始位置,主串回到上次匹配的起始位置的下一个位置。
注意事项:被查找的主串和子串都不能为空串,且都要以"\0"结尾。如果查找成功则返回主串中子串所在位置的地址,查找失败则返回空指针。
KMP算法
strstr每次匹配失败子串都要回到起始位置,主串则是这个不行那就换下一个位置。这样的效率就很低,因为主串中的每一个位置都被尝试过,而子串也被遍历了很多遍。而KMP的一个优化就在于,匹配失败后主串的位置保持不动,而子串的位置回到一个特定位置(可能是起始位置也可能不是)。
引入

那么假设能在已经成功匹配的字符串中找到一个最大程度相同的串,那么如何确定子串回退的位置?
下面是两个例子:

这两个例子看起来好像很凑巧,哎,就是凑巧,就是玩~。其实关于子串回退的位置,KMP给定了一个next数组用于保存子串在某个位置匹配失败后应该回退的位置。
next数组
用next[ j ]=k 来表示子串在某个位置匹配失败应该回退的位置。其中 j 是子串匹配失败的位置,而 k 是子串在j位置匹配失败后应该回退的位置。
k值的求法
1.找到匹配成功部分两个相等的真子串(不包含本身),一个以下标0开始,一个以下标 “j-1 ”结束。
2.不管什么样的数据,规定:next[ 0 ]=-1,next[ 1 ]=0.
举例求next数组:

解析:
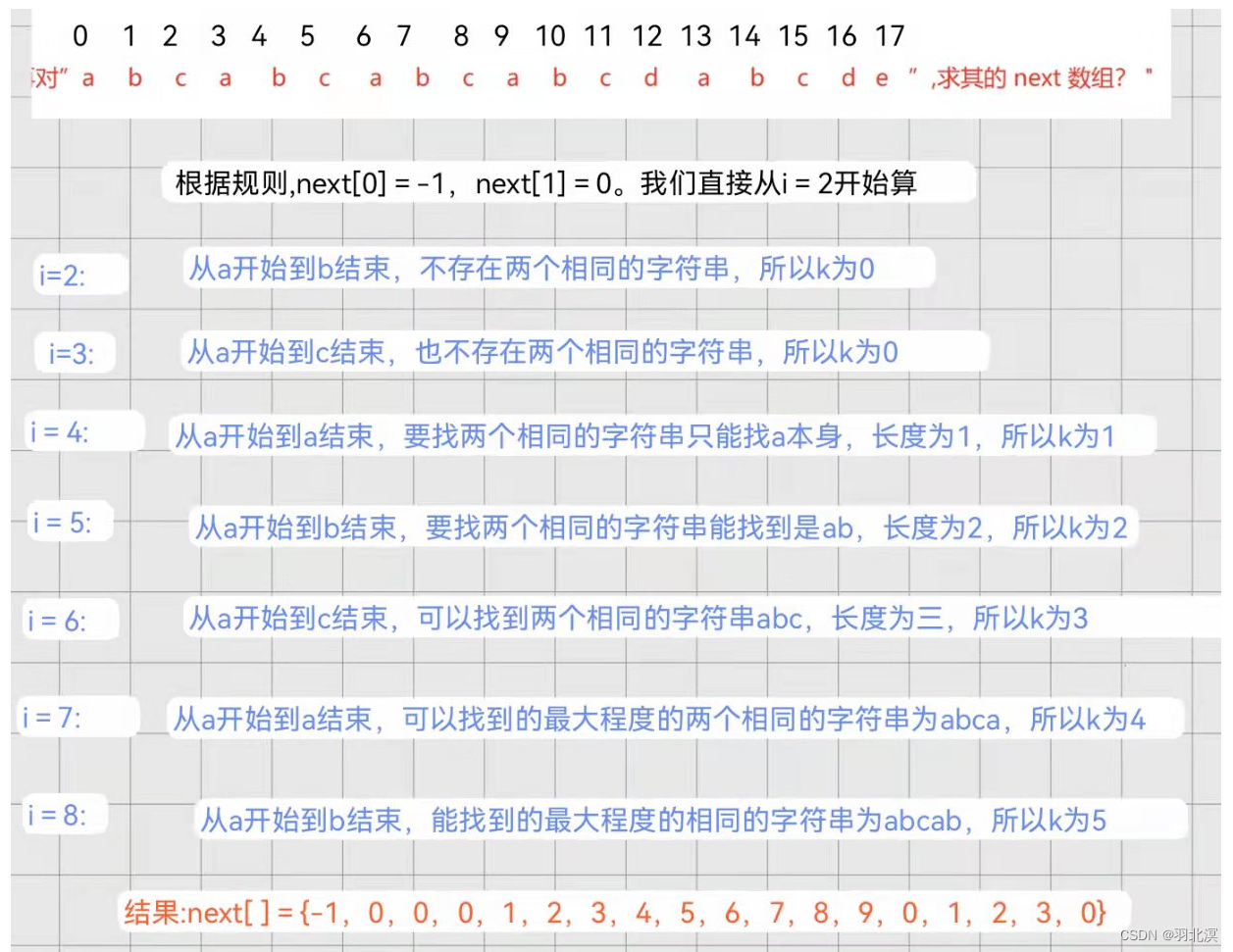
注意事项
这里说的相同的字符串,可以有部分内容是重叠的。但必须要是从 0 下标开始到 “j-1 ”下标结束。
k的值是以能找到的最大程度相同字符串的长度为准。
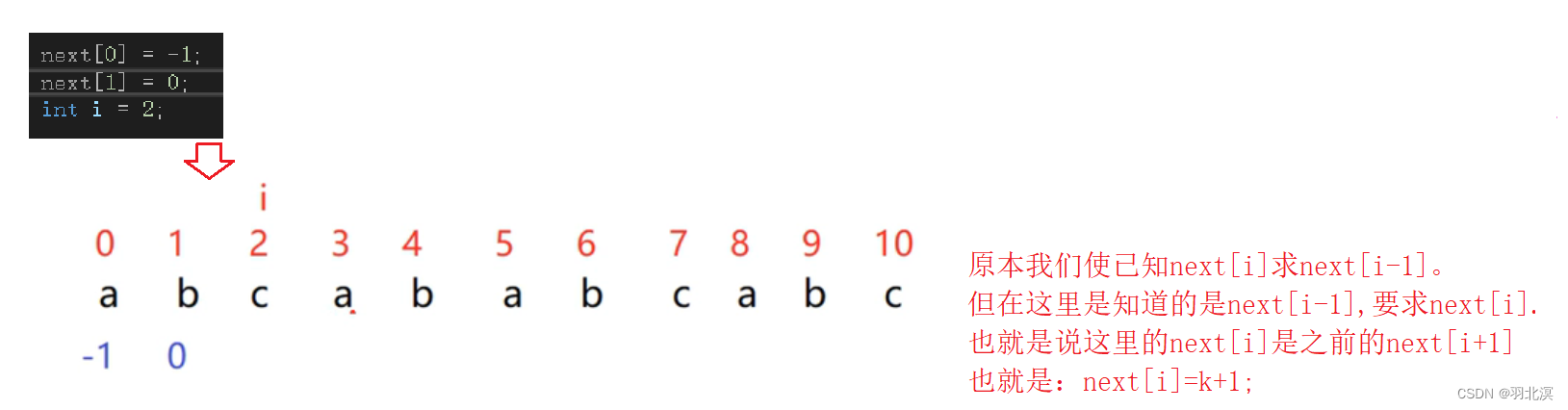
此时我们已经学会如何求next数组了,那么假设我们知道next[ i ]=k,我们如何求next[ i+1]?
这里就要用一点数学来推导了:

这里很凑巧的是子串的P[ i ]==P[ k ],那么如果子串的P[ i ]!=P[ k ]我们又如何知道next[ i+1 ]的值呢?

如果P[ i ] ! = P[ k ],那么可以说,当前的k位置的元素一定不是我们要找的,因此还要继续回退,即 k = next[ k ] ,也就是将next[ k ]的值赋给next,直到p[ i ] == p[ k ]。
值得注意的是,这些推导都是在next[ i ] = k的前提下才存在的。
next数组就是KMP算法的精髓,因为next数组的存在,子串不必每次都从头再来,主串也不必走回头路。学会了next数组的求法,就已经是掌握了KMP思想,接下来就是代码实现了。
代码实现
KMP代码:
//str代表主串
//sub代表子串
//pos代表从主串的pos位置开始查找
int KMP(char* str, char* sub, int pos)
{
assert(str && sub);
int lenStr = strlen(str);
int lenSub = strlen(sub);
if (lenStr == 0 || lenSub == 0)
return -1;
if (pos<0 || pos>lenStr)
return -1;
int* next = (int*)malloc(sizeof(int) * lenSub);
assert(next);
GetNext(sub,next, lenSub);
int i = pos;//遍历主串
int j = 0;//遍历子串
while (i < lenStr && j < lenSub)
{
if (j==-1||str[i] == sub[j])//如果第一次匹配就失败,但next[0]=-1,此时j为-1,但其实只需要回退到0位置,sub[-1]越界为了避免这种情况,当j为-1时,直接放进去++。
{
i++;
j++;
}
else
{
//匹配失败,i不回退,j回退到next[j]的位置
j = next[j];
}
}
if (j >= lenSub)
return i - j;
return -1;
}
这里需要留意的一点就是:规定next数组下标为0处的值为负一,但是子串从负一位置开始访问就是越界了。因此当 j 为负一时应该直接进入循环。

GetNext实现:
void GetNext(char* sub, int* next,int lenSub)
{
next[0] = -1;
next[1] = 0;
int i = 2;
int k = 0;//是钱一项的k
while (i < lenSub)
{
if(k==-1||sub[i - 1] == sub[k])//本来是sub[i]==sub[k],但是这个i是已经自增一次后得到的i
{
next[i] = k + 1;
i++;
k++;
}
else
{
k = next[k];//sub[i-1]!=sub[k],要继续回退,此时的k应该等于当前k位置对应的next数组的值
}
}
}
这里同样有需要注意的地方:之前是已知next[ i ]的值求next[ i+1 ]。但这里是已知next[ i-1 ]求next[ i ]的值。
完整代码:
void GetNext(char* sub, int* next,int lenSub)
{
next[0] = -1;
next[1] = 0;
int i = 2;
int k = 0;//是钱一项的k
while (i < lenSub)
{
if(k==-1||sub[i - 1] == sub[k])//本来是sub[i]==sub[k],但是这个i是已经自增一次后得到的i
{
next[i] = k + 1;
i++;
k++;
}
else
{
k = next[k];//sub[i-1]!=sub[k],要继续回退,此时的k应该等于当前k位置对应的next数组的值
}
}
}
int KMP(char* str, char* sub, int pos)
{
assert(str && sub);
int lenStr = strlen(str);
int lenSub = strlen(sub);
if (lenStr == 0 || lenSub == 0)
return -1;
if (pos<0 || pos>lenStr)
return -1;
int* next = (int*)malloc(sizeof(int) * lenSub);
assert(next);
GetNext(sub,next, lenSub);
int i = pos;//遍历主串
int j = 0;//遍历子串
while (i < lenStr && j < lenSub)
{
if (j==-1||str[i] == sub[j])//如果第一次匹配就失败,但next[0]=-1,此时j为-1,但其实只需要回退到0位置,sub[-1]越界为了避免这种情况,当j为-1时,直接放进去++。
{
i++;
j++;
}
else
{
//匹配失败,i不回退,j回退到next[j]的位置
j = next[j];
}
}
if (j >= lenSub)
return i - j;
return -1;
}
int main()
{
printf("%d\n", KMP("ababcabcdabcde", "abcd", 0));//5
printf("%d\n", KMP("ababcabcdabcde", "abcdef", 0));//-1
printf("%d\n", KMP("ababcabcdabcde", "ab", 0));//0
return 0;
}

注意:返回值是子串在主串中的位置。
内存操作函数
前面的strcpy,strcat,strcmp,strncpy,strncat,strncmp,strstr等都是字符串函数,也就是说它们只能对字符串进行操作。如果要对其他类型操作就需要学习内存操作函数。常见的内存操作函数有memcpy,memmove,memcmp,memset。因为内存操作函数可以操作的类型很多,我们不会知道使用者会给我们传什么类型的参数,因此我们在实现时通常将函数参数设定为泛型指针,在实现功能时以字节为单位。
memcpy
函数功能
内存拷贝,将一块内存中的num个字节拷贝到另外一块内存中。常用来处理空间不重叠的数据拷贝。
函数参数
void * memcpy ( void * destination, const void * source, size_t num );
# void* 函数返回值,返回dest内存空间的地址;
# void* destination 目标内存空间地址;
# void* source 源空间地址;
# size_t num 要拷贝的字节数;
模拟实现
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
char* ret = dest;
//要将src中num个字节拷贝到dest中,因为不确定num的大小,所以我们一个字节一个字节的拷贝是最正确的选择
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
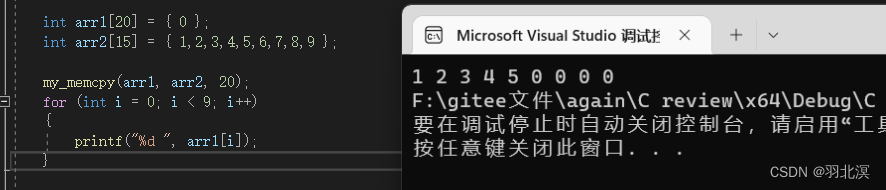
注意事项
在C语言标准中,memcpy只用来拷贝非重叠空间的数据。如果拷贝重叠空间的内容,由于mempy是由前向后拷贝的,这就会导致数据覆盖覆盖的情况发生,最后得到的结果不是我们想要的。C语言为了处理重叠的数据空间,给定了memmove函数。
memove
函数功能
内存移动,将一块内存数据的num个字节的内容向指定的位置移动。常用来处理重叠空间的数据拷贝。
函数参数
# memmove 函数的参数和 memcpy 函数完全相同
void * memmove ( void* destination, const void * source, size_t num );
模拟实现
memove的参数与memcpy的参数相同,那么memmove是如何实现重叠空间的拷贝的呢?
前面提到memcpy是从前向后拷贝的,而memmove之所以能处理重叠空间的拷贝,是因为memmove会根据情况的不同选择由前向后拷贝还是从后向前拷贝。

总结:src < dest就从前向后拷贝,其他都从后向前拷贝
代码实现:
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
char* ret = dest;
//总结就是分两种情况,src<dest就从前向后拷贝,其他都从后向前拷贝
if (dest < src)
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest+1;
src = (char*)src + 1;
}
}
else
{
//从后向前拷贝,是指从最后一个字节开始,起始位置+(--num)就是最后一个字节
while (num--)
{
*((char*)dest + num) = *((char*)src + num);//num在递减,每次加num就能直接实现从最后一个字节往前移动
}
}
}

memset
函数功能
内存设置,把一块内存中num个字节的内容设定为指定的数据。
函数参数
void *memset( void *dest, int c, size_t count );
# void* 函数返回值,返回目标空间的地址;
# int c 函数参数,指定你想要初始化的数据;
# size_t count 函数参数,指定初始化的字节数
模拟实现
void* my_memset(void* dest, int k, size_t num)
{
assert(dest);
char* ret = dest;
//将dest的num个字节全部初始化为k
while (num--)
{
*(char*)dest = (char)k;
dest = (char*)dest + 1;
}
return ret;

memcmp
函数功能
内存比较,比较两块内存中前num个字节内容的大小。
函数参数
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
# int 函数返回值;
# void* ptr1 void* ptr2 要比较的两块内存;
# size_t num 要比较的字节数;
#函数返回值
>0 : ptr1 大于 ptr2;
=0 : ptr1 等于 ptr2;
<0 : ptr1 小于 ptr2;··
模拟实现
int my_memcmp(const void* str1, const void* str2, size_t num)
{
assert(str1 && str2);
int count = 0;
while (count < num&& *(char*)str1 == *(char*)str2)
{
count++;
str1 = (char*)str1 + 1;
str2 = (char*)str2 + 1;
}
if (count == num)
return 0;
else
return (*(char*)str1 - *(char*)str2);
}

















 8763
8763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











