









leader和follower
kafka的leader和follower是相对于分区有意义的,不是相对于broker。
因为每个分区都有leader和follower,
leader负责读写数据。
follower负责复制leader的数据保存到自己的日志数据中,并在leader挂掉后重新选举出leader。
kafka会再创建topic的时候尽量让分配分区的leader在不同的broker中,就是负载均衡。

与Zookeeper区分
zookeeper的leader负责读写,follower可以读取。
kafka的leader负责读写,follower不能读写数据(确保每个消费者消费的数据是一致的),kafka一个topic有多个分区leader,一样可以实现负载均衡。
AR/ISR/OSR
kafka的follower可以分为三类:AR ISR OSR
- AR(Assigned Replicas)表示一个topic下的所有副本。
- ISR(In-Sync Replicas)表示一个topic下正在同步的副本。
- OSR表示(OUT-SYNC-Replicas)不再同步的副本。
AR=ISR+OSR

查看分区的ISR
使用Kafka Eagle查看某个Topic的partition的ISR有哪几个节点。

partition是创建的topic为test的 0 1 2 三个分区。
Log Size是日志文件的大小
Leader是leader副本在那个broker节点上
Replicas是它的副本在哪些broker节点上。
In sync Replicas是正在同步的副本(包括leader)
尝试关闭id为0的broker(杀掉该broker的进程),参看topic的ISR情况。

leader的选举
leader的选举对于消息的写入以及读取非常关键,此时有两个疑问:
- kafka是如何确定partition的哪个副本是leader,那个副本是follower呢?
- 某个leader崩溃后,怎么快速确定另一个leader呢?因为Kafka的吞吐量很高、延迟很低,所以选举leader必须非常快
leader崩溃,kafka如果处理
使用Kafka Eagle找到某个partition的leader,再找到leader所在的broker。在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。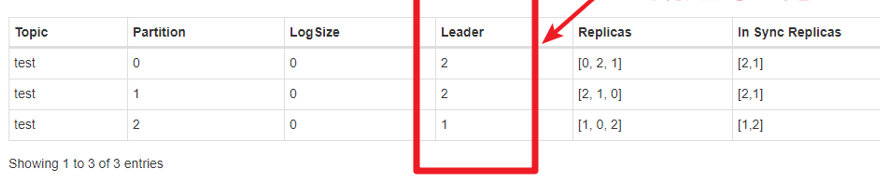
通过观察,我们发现,leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader。
Controller
- kafka启动的时候,会在所有的broker中选举出controller
- 前面的leader和follower是针对partition的副本,而controller是针对broker的。
- 创建topic或者添加分区,修改副本数量之类的管理任务都是交给controller完成的。
- kafka分区leader的选举,也是由controller决定的。
Controller的选举
- 在kafka集群启动的时候,每个broker都会尝试去Zookeeper上注册为controller(ZK临时节点)
- 但是只有一个竞争成功,其他的broker会注册该节点的监视器。
- 一但节点的状态发生变化,就可以进行处理。
- Controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为Controller。
Controller选举partition的leader
- 所有Partition的leader选举都由controller决定.
- controller会将leader的改变通过RPC的方式通知需要为此做出响应的Broker
- controller读取当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader。
- 如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不通过ZK的方式进行选举?
如果kafka是居于ZK进行选举,ZK的压力比较大,例如某个节点崩溃,这个节点上不仅仅只有一个leader,是有不少的leader需要选举,通过ISR可以快速选举。
leader的负载均衡
kafka中引入Preferred Replica的概念,意思是优先的Replica。
在ISR中第一个replica就是preferred-replica.
副本存放的第一个broker,肯定就是preferred-replica
执行以下脚本可以将preferred-replica设置为leader,均匀分配每个分区的leader。
./kafka-leader-election.sh --bootstrap-server node1.itcast.cn:9092 --topic 主题 --partition=1 --election-type preferred















 5359
5359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











