



音频高光检测就是利用音频信号去找到那些特别激动人心的片段 就比如你看一场球赛 只听声音就知道什么时候进球了 比如讲解员突然很激动 观众席掌声 或者播放了音乐等 这些都可以被算法识别出来 → 这些就是可能的“音频高光”。
大家都知道音频都有哪些特征呢? 大家看一下
| 音量(Loudness) | 音量突然升高,可能表示有激动事件(进球、欢呼) |
| 音调(Pitch) | 高音调变化可能和情绪或重要瞬间相关 |
| 梅尔频谱(Mel Spectrogram) | 把音频变成类似图像的频率-时间图,供CNN等模型分析 |
| MFCC | 提取音频中人的语音或情感成分,常用于情绪识别 |
| 节奏变化(Rhythm) | 比如鼓点加快、情绪紧张,常用于电影剪辑中的高光判断 |
虽然大家可能都知道这是啥意思?但是我们还是具体来看模型到底是如何检测出这些特征的变化的
音量
音量的变化,在计算机中体现为:
-
波形振幅变大或变小
-
在短时分析中,帧能量或功率发生变化
那模型如何察觉音量变化呢?音频信号通常会被切分成小段(如每帧 25ms),从每段中提取特征,这些特征被称为音量指标 其中叫做RMS能量是最直接的音量指标 然后在模型训练的时候 输入音频的帧特征(包含能量等)标签是“高光”或“非高光” 若模型发现“音量上升”经常对应“高光”,就会自动学习到这种模式 模型通过分析“帧能量”等特征,学习音量变化和高光之间的关联,从而在新的视频中察觉音量变化来辅助判断“是不是高光”
监督方式的话是人为打上去的 就是标注这段时间是高光或者不是高光 然后训练模型的输入是音频的特征 模型通过学习这些特征 来预测哪一段是高光 这段话是啥意思呢? 你可以这样理解
人告诉模型「这段音频是高光,那段不是」,
模型去找:高光音频里到底有什么“特点”?
然后当再给模型一段新音频时,它就能“看特征”来判断:
——「哎,这里也很像以前的高光,我觉得这段也是!
就是模型开始瞎猜 猜错了就反向传播修改参数 一次次试错就知道啥才是真正的高光了 “只要有很大声 + 节奏明显变化,那多半是高光!” 这样的话当我把一段视频的音频提取出来给模型 模型通过声音就能分辨出哪段是高光
可以分开训练 也可以一起 如果之前看过我写的论文精读 应该知道视觉和音频分开训练,然后再对齐 与视觉和音频同时输入模型,进行联合建模 的一个区别 我将开一个帖子再详细说一下这两个的区别
还有一个是跨模型训练 就是先训练好一个视觉高光检测模型 然后得到这些时间段是视觉高光的标签 然后用这些时间段去监督训练音频模型 让它学会从音频中感知高光 这叫做试听对齐和伪标签学习
音调也是跟音量一样的
梅尔频谱
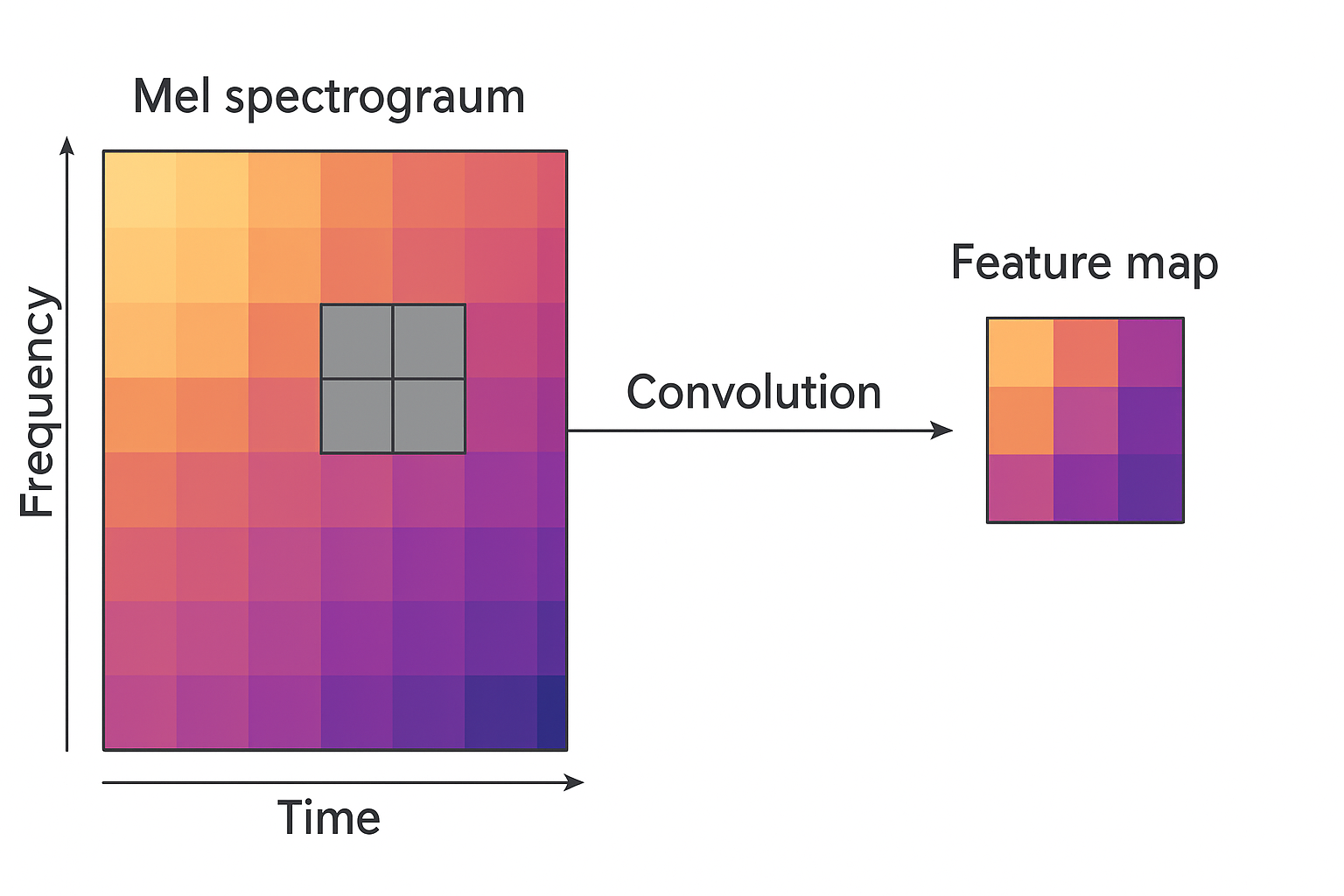
这个也挺常见的。梅尔频谱图是用来表示“音频中什么时候包含哪些音高(频率)”的一张图 就是使用一些操作使得这个频率变成人耳更能感知的 将音频变为图像的形式 什么时刻(横轴) 哪个频率(纵轴)有多强(像素亮度) CNN本来就是处理图像数据的 梅尔谱是二维的、结构像图像、局部相关性强——这正是CNN最擅长处理的

这样CNN 就会自动学会 哪些时间频率组合容易出现在高光音频中 哪些区域没什么信息可以忽略 就是跟CNN处理平常的图像一样 进行特征的提取 CNN处理后的特征图在时间维度上是有序的,可以按时间步展开成序列 这个序列特征输入RNN(如LSTM、GRU)或Transformer编码器,建模时间依赖 为啥建模时间依赖呢?其实想想也是 高光是一个片段 单独看某一帧的音频 很难判断是不是高光 需要结合前后多帧的信息,来判断这段时间的声音是否属于高光段。
MFCC
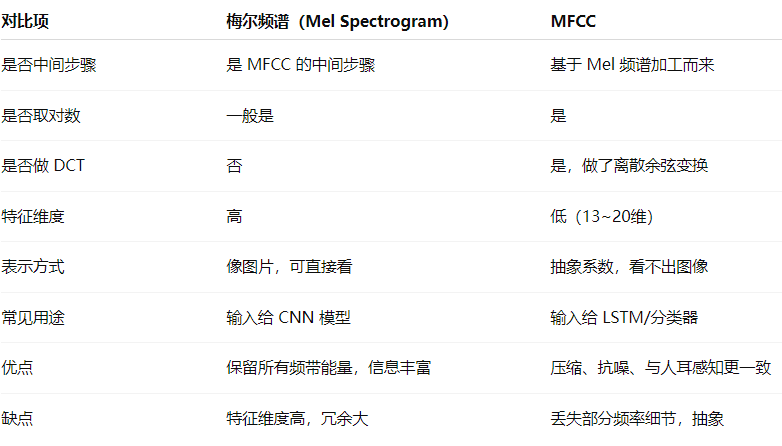
全称Mel-Frequency Cepstral Coefficients(梅尔频率倒谱系数),中文常叫做“梅尔频率倒谱系数”。MFCC = 对梅尔频谱取对数后再做 DCT 得到的一组更紧凑的系数 直接看对比吧
节奏变化(Rhythm)
道理是相同的 也就是对应的一些检测节奏变量的算法 然后给定规则 啥样是高光的 模型自己就学会了
我接下来要写的帖子包括 两阶段和同时建模、视觉和音频对齐
然后后续会更新对于一些代码的学习 大家如果感兴趣欢迎关注我


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









