






windows11彻底关闭Microsoft Defender的3种方法
Microsoft Defender Antivirus 是 Microsoft Windows 11 操作系统的默认防病毒解决方案。默认情况下它处于打开的状态。大多数第三方的杀毒软件都可以识别,并代替它。
但是大多数情况下,我们总是有各种理由需要关闭它,例如 Windows Defender Antivirus 导致资源使用率高或系统出现其他问题。
方法一:启用或禁用 Windows Defender 的实时保护
可以通过设置打开或者关闭某些模块(例如实时保护)的选项
第一步,右键点击开始菜单--设置 或者 按住 WIN + I (大写的i)快捷键打开
点击隐私和安全性,然后选择windows安全中心
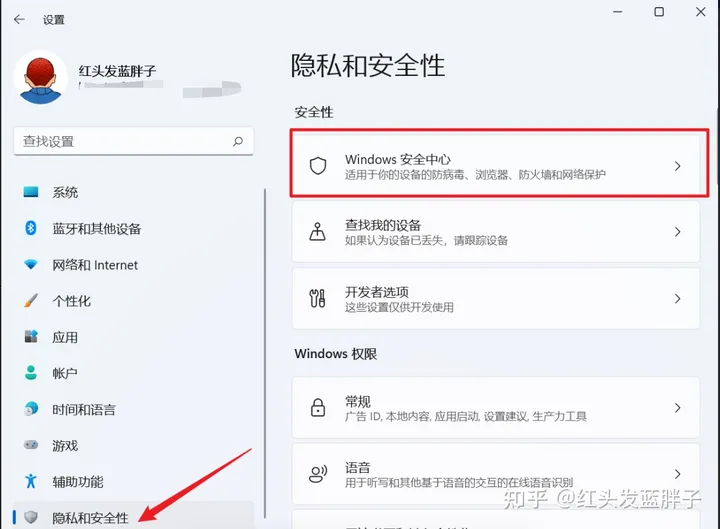
第二步,打开--保护区域下的病毒和威胁防护
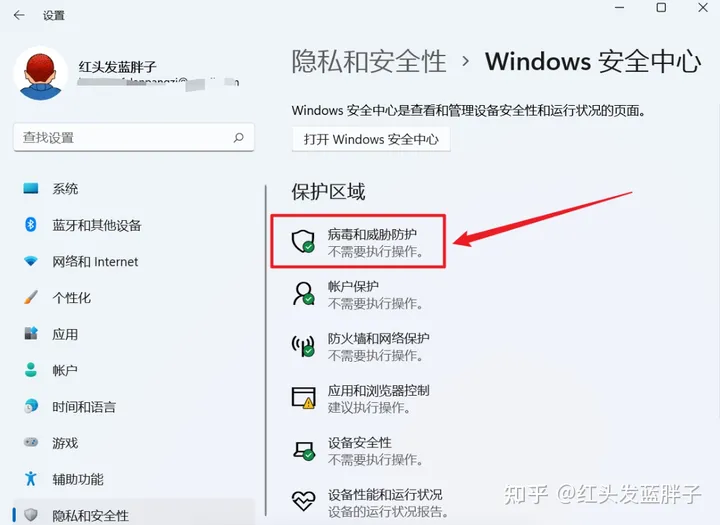
第三步,选择病毒和威胁保护设置--管理设置。
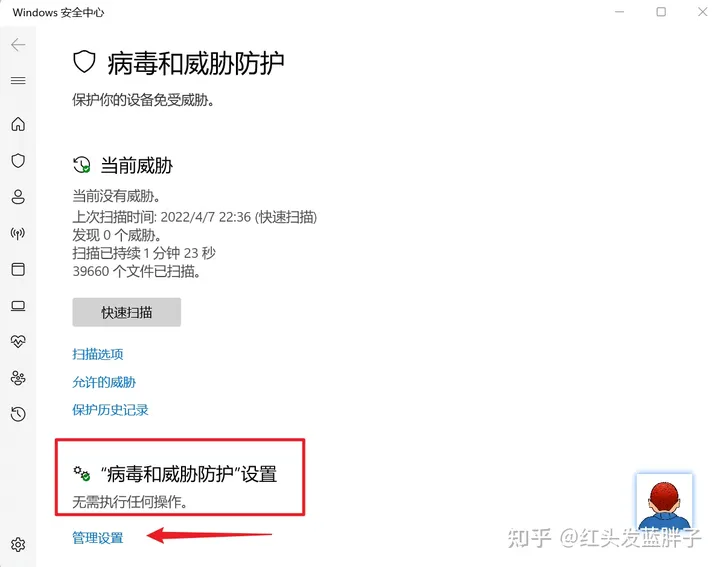
关闭实时保护,云提供的保护,自动提交样本,篡改防护,全部关闭


关闭后状态
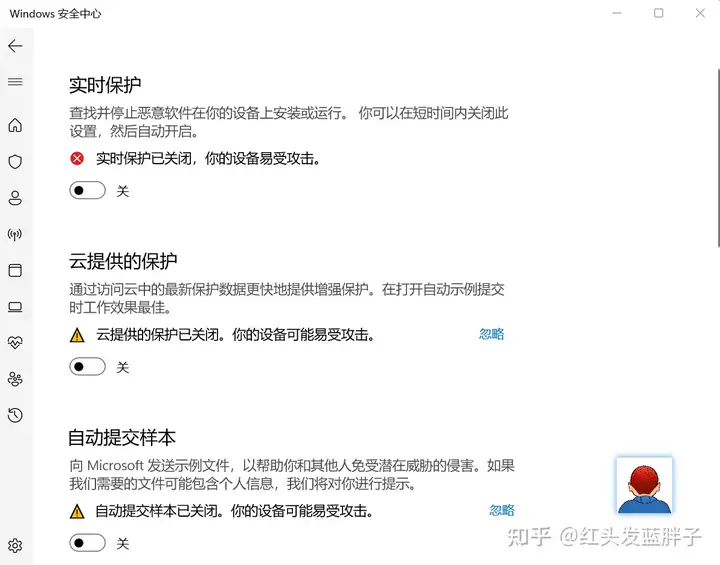

注意:页面会提示您暂时关闭。
方法二:使用组策略编辑器禁用 Windows Defender
使用组策略编辑器永久禁用 Windows Defender 防病毒。
注意:在进行更改之前,必须禁用 Windows 安全中心的篡改保护。
否则,Windows 安全中心可能会再次打开 Windows Defender 防病毒。

打开组策略---点击开始菜单--输入 gpedit.msc
或者按WIN + R ,输入 gpedit.msc
找到计算机配置>管理模板>Windows 组件>关闭Microsoft Defender 防病毒
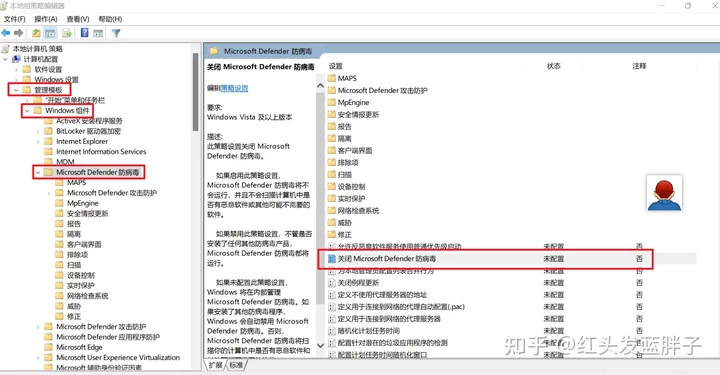
- 双击关闭 Microsoft Defender 防病毒策略。
- 选择已启用,点确定
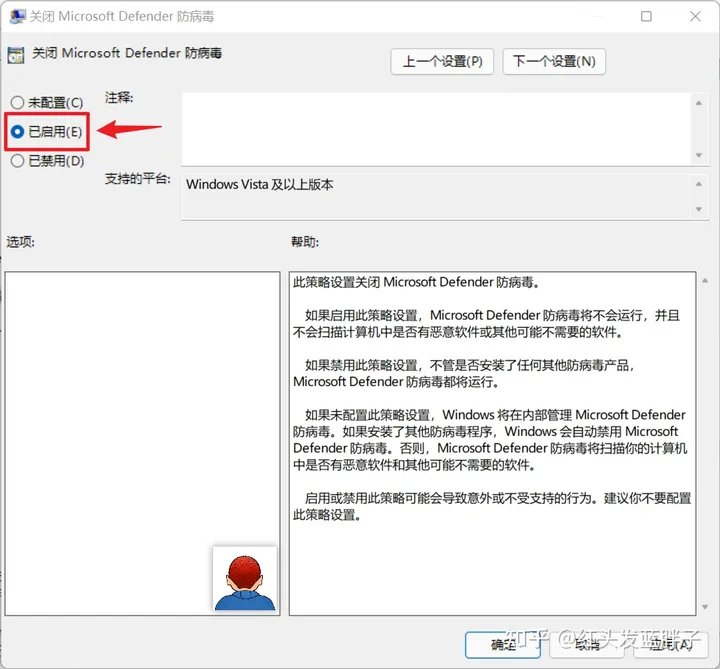
然后,重新启动Windows 11。
重新启动Windows11后,病毒和威胁防护将关闭。
方法三:使用小工具彻底关闭Windows Defender
Defender Control 是一个绿色的小工具,无需安装直接运行。可以一键关闭Windows Defender,支持多语言,支持中文。
注意:该工具运行时,可能会被Windows Defender,所以运行前,先需要执行方法一,关闭实时保护后再运行该工具,彻底关闭Windows Defender
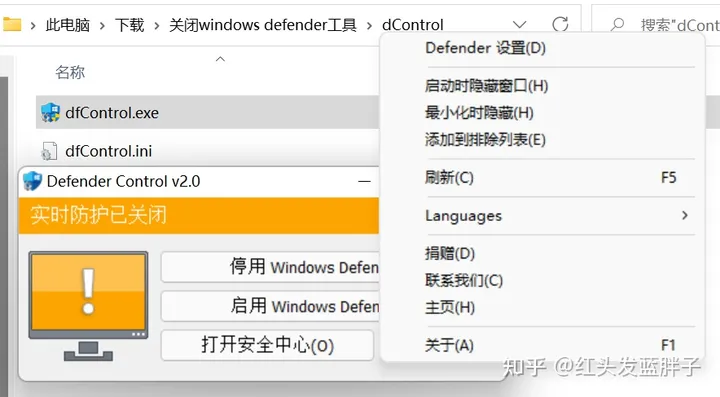
点击停用 Windows Defender(D)。彻底停用Defender。
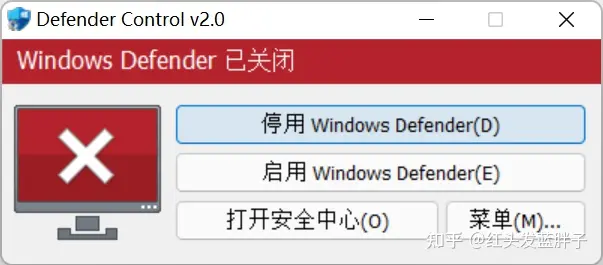
Defender_Control_v2.0.exe

















 9614
9614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









