






第二章 Hadoop概述
1.hadoop简介
Hadoop是一个开源的,分布式存储和分布式计算平台,提供可靠的、可扩展的分布式计算。在这个平台上,用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力存储和计算数据。
2.hadoop发展史
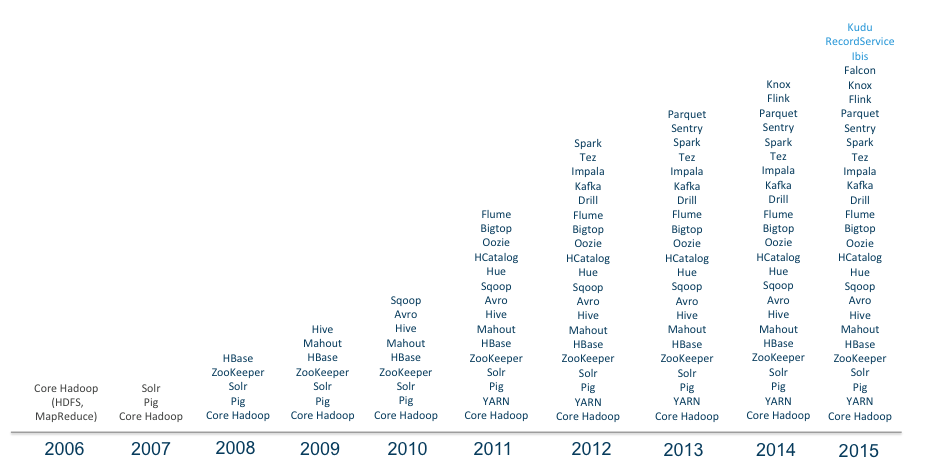
现在Hadoop 在一月发布了2.7.2 的稳定版, 已经从传统的Hadoop 三驾马车HDFS,MapReduce 和HBase 社区发展为60 多个相关组件组成的庞大生态,其中包含在各大发行版中的组件就有25 个以上,包括数据存储、执行引擎、编程和数据访问框架等。
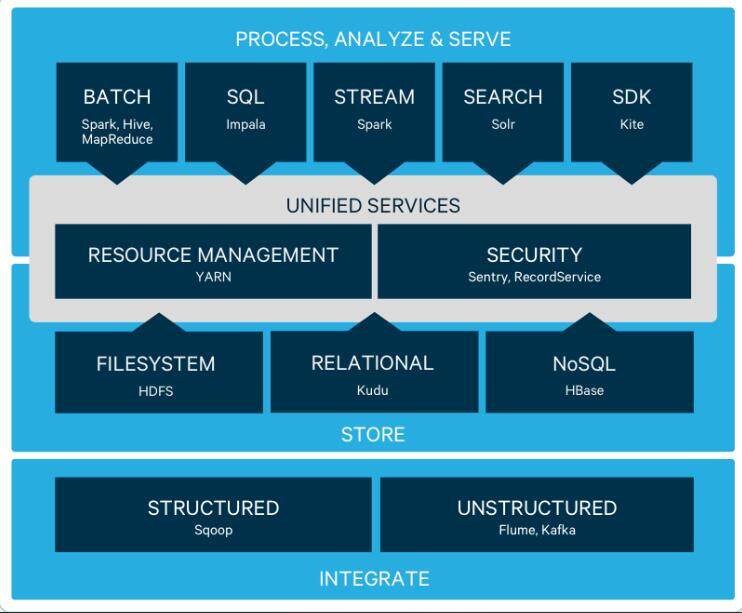
Hadoop 在 2.0 将资源管理从 MapReduce 中独立出来变成通用框架后,就从 1.0 的三层结构演变为了现在的四层架构:
- 底层——存储层,文件系统 HDFS
- 中间层——资源及数据管理层,YARN 以及 Sentry 等
- 上层——MapReduce、Impala、Spark 等计算引擎
- 顶层——基于 MapReduce、Spark 等计算引擎的高级封装及工具,如 Hive、Pig、Mahout 等等
3、Hadoop特性(优势)
(1)高可靠性:采用多副本冗余存储的方式,即使一个副本发生故障,其他副本还可以对外提供服务。
(2)高效性:采用分布式存储和分布式处理两大核心技术,高效地处理PB级别的数据。
(3)高可扩展性:高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的节点。
(4)高容错性:采用冗余存储方式,自动将失败的任务重新分配。
(5)成本低:采用廉价的计算机集群,成本低,普通用户也可以用pc搭建Hadoop运行环境。
(6)成熟的生态圈:拥有成熟的生态圈,囊括了大数据处理的方方面面。
4、Hadoop应用现状















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









