







前言
之所以开设“前人种树”专栏,是因为笔者十分推崇某位牛马前辈,当初刚入学对实验一筹莫展时偶然接触到这位前辈分享的材料,且不说对我有没有帮助,反正从那以后我经常看他分享的实验材料。慢慢地看多了之后才发现,原来这位前辈发材料的初衷可能没有我想的那么高尚,不是为了作为前人种树让后来人乘凉的,纯纯为了炫耀。为什么这么说呢?因为基本上他所有的公开分享的材料,都是要么缺斤少两,要么就在某个细节上把原来正确的改成错的。而他收费恰米的材料,都是完全正确可以直接拿来用的。
所以我呢,就把自己的实验材料也做个分享,不缺斤少两,更不故意把对的改成错的让后面的学弟们找半天,故意捉弄人嘛这不是?【楽】希望我这个种树的前人能对后人们有些许帮助,也希望各位是在弄懂我的东西后才去套用甚至自创。
说远了,这个课程设计实验分三大部分,对应课上教的词法扫描器/语法分析器/语义分析器。课程验收形式一个是上交作业平台测试通过(20’+20’+10’),一个是实验报告(10’),一个是择日到机房现场根据要求稍微修改代码(20’+10’+10’)。
一、设计(实验)正文
1、词法扫描器
设计并实现词法扫描器,其输入是源程序字符串,输出是二元式(种别编码,单词的属性值)形式的单词。
同时需要创建并填写符号表和常数表。
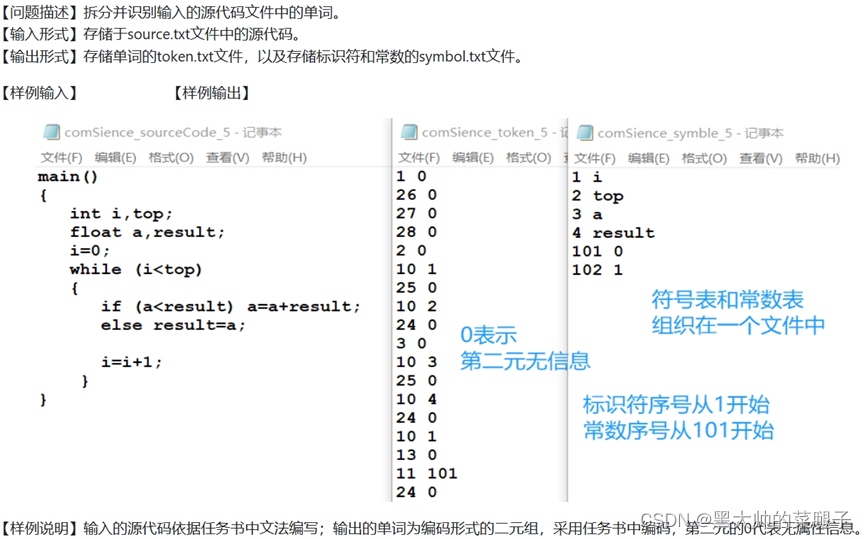
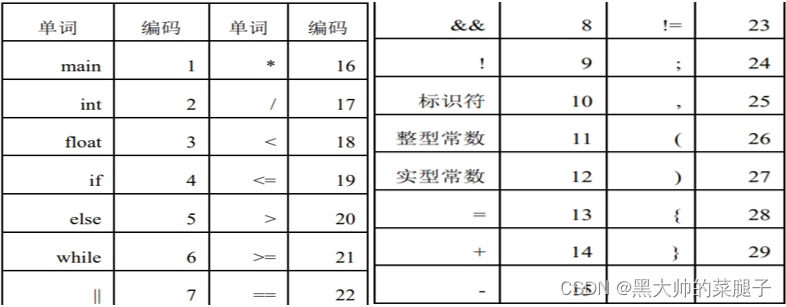
单词种别码约定如图所示:
token.txt文件数据结构说明:
(单词种别码 无种别码内值则默认置0/种别码内值)
symbol.txt文件数据结构说明:
(种别码内值 标识符/整型常数)
基本思路:
- 逐个字符串读入字符型数组str(即从首字符开始读入直到空格/换行为一个字符串),循环操作至文件结尾
- 在扫描器内做单词种别码判断,给syn token x xtemp sum y ytemp z赋值
- 开始写文件操作:
- 若该单词不需要种别码内值,则只写入token.txt;
- 若该单词需要种别码内值,且已记录在symbol中,则只需写入token.txt;
- 若该单词需要种别码内值,且尚未记录在symbol中(即为新的码内值),则写入token.txt并写入symbol.txt;
核心部分——扫描器scanner:
输入:
一次读入的一个字符串(可能包含多个“单词”)
输出:
不输出,扫描器的功能仅在于对相关全局变量进行赋值,以便被主函数调用后在主函数中进行写文件操作
基本框架:
1.判断字符是否为数字

2.判断字符为字符串的开头,表现为字母开头衔接任意个数字或字母
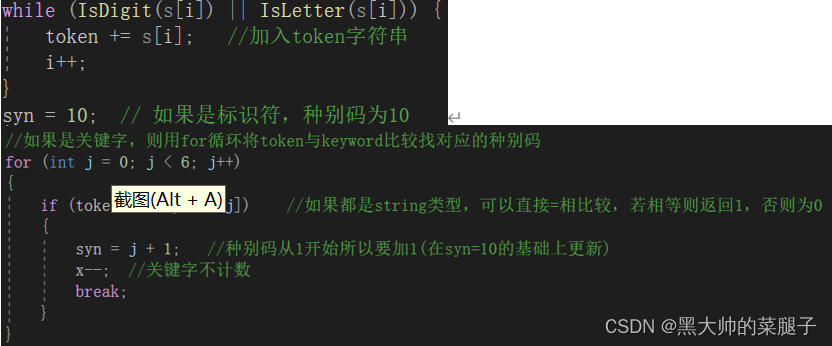
3.判断为符号

补充:
该程序仍有不足,并未考虑到real实型常数,而是将其与int实型常数混为一谈,之所以能满分通过平台测试大概是因为平台采用的测试数据中并没有实型常数。所以我后来对程序进行了完善和补充。主要是针对扫描器scanner里面对于第一部分1.判断字符是否为数字,和用于遍历查找整型常数码内值是否已经记录过的queryArray11or12(原queryArray11)进行了完善和补充,以及一些变量定义类型、数组名的修改(便于理解)。 需要避坑的地方是sum值小数部分的计算,由于计算方法不同于其整数部分的乘十累加, 所以需要额外定义一个局部变量temp用于暂存小数部分的累加值,最后再加回sum。
核心修改部分:

修改之后已经能同时正确识别出整型和实型常数,并且在symbol文档中也不会重复记录。(示例如截图所示:)
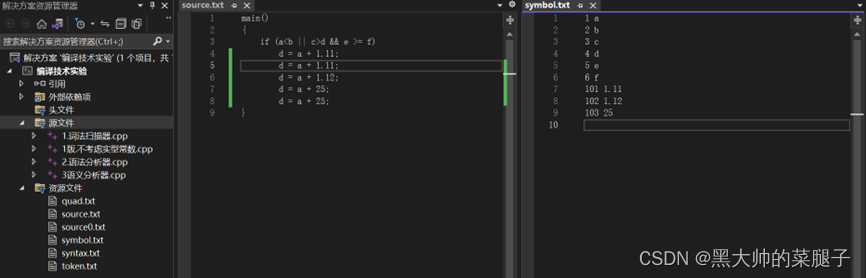
原本还考虑到负数的判断:

但是转念一想,即便是负数,也可视为减去一个正数,所以就不画蛇添足了(真要改的话也确实不好实现,可能要多准备一个二元结构体数组存放各个读入的单词种别码和码内值索引,而不能一次读入便不做记录舍弃掉,这样整段代码都要伤筋动骨)。
源码附上:
/*——————词法扫描器——————*/
#include<fstream>
#include <iostream>
#include <cstring>
#include <cmath>
using namespace std;
//保留字
const string KeyWord[9] = { "main","int","float","if","else","while","char","bool","void" };
int syn; //单词种别码
string token; //单词自身字符串.用于在程序整体中找到每个单位字符串
double sum; //INT整型/REAL实型常数(种别码 11/12)里的码内值,即常数的值(本来是字符串)
int i = 0; //循环索引(注意索引是1/2/3共用的)
int x = 0; //对标识符(种别码10)计数(标识符从0开始计数)
int y = 100; //对整型常数(种别码 11/12)计数(整型常数从100开始计数)
int z = 200; //对实型常数(种别码 12)计数(实型常数从200开始计数)
int xtemp = 0; //若标识符码内值已记录,则用xtemp来定位该标识符码内值的index
int ytemp = 0; //若整型常数码内值已记录,则用ytemp来定位该整型常数码内值的index
int ztemp = 0; //若实型常数码内值已记录,则用ztemp来定位该实型常数码内值的index
string array10[999]; //记录标识符码内值
double array11[999]; //记录整型/实型常数码内值
double array12[999]; //记录整型/实型常数码内值
// 函数声明:
bool IsLetter(char ch); //判断是否为字母(空格后首字符是字母可能是关键字或者标识符)
bool IsDigit(char ch); //判断是否为数字
bool IsDot(char ch); //判断是否为小数点
bool queryArray10(string token, string array10[]); //遍历查找标识符码内值是否已经记录过
bool queryArray11(double sum, double array11[]); //遍历查找整型常数码内值是否已经记录过
bool queryArray12(double sum, double array12[]); //遍历查找实型常数码内值是否已经记录过
void scanner(char s[]); //扫描器
int main()
{
memset(array11, 111111, sizeof(double) * 999); //给数组赋同一初值
memset(array12, 111111, sizeof(double) * 999); //给数组赋同一初值
char str[20];
ifstream infile;
ofstream outfile1, outfile2;
//输入文件scource
infile.open("source.txt", ios::in);
//输出文件token与symbol
outfile1.open("token.txt", ios::out);
outfile2.open("symbol.txt", ios::out);
if (!infile)
{
cout << "读取特征文件失败!";
}
//逐个字符串(视作字符数组)遇到空格或换行才结束读取,循环读入字符数组str
while (infile >> str) {
do {
scanner(str); //在扫描器内做单词种别码判断,给syn token x xtemp sum y ytemp z赋值
if (syn <= 9 || (syn <= 33 && syn >= 13))
{
outfile1 << syn << " " << 0 << endl; //对关键字跟符号不计数(恒等于0)
}
else if (syn == 10)
{
if (!queryArray10(token, array10)) //找不到,即token是新的码内值
{
array10[x] = token;
outfile1 << syn << " " << x << " " << endl; //标识符从0计数
outfile2 << x << " " << token << endl;
}
else
{
outfile1 << syn << " " << xtemp << " " << endl;
}
}
else if (syn == 11)
{
if (!queryArray11(sum, array11)) //找不到,即sum是新的码内值
{
array11[y] = sum;
outfile1 << syn << " " << y << " " << endl; //整型常数从100计数
outfile2 << y << " " << sum << endl;
}
else //找得到
{
outfile1 << syn << " " << ytemp << " " << endl;
}
}
else if (syn == 12)
{
if (!queryArray12(sum, array12)) //找不到,即sum是新的码内值
{
array12[z] = sum;
outfile1 << syn << " " << z << " " << endl; //实型常数从200计数
outfile2 << z << " " << sum << endl;
}
else //找得到
{
outfile1 << syn << " " << ztemp << " " << endl;
}
}
} while (i < strlen(str));
i = 0;
}
infile.close();
outfile1.close();
outfile2.close();
return 0;
}
bool IsLetter(char ch) //判断是否为字母
{
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || (ch == '_')) // || (ch == '$')标识符不能有$,有则跳过
return true;
else if (ch == '$')
{
i++;
return false;
}
else
return false;
}
bool IsDigit(char ch) //判断是否为数字
{
if (ch >= '0' && ch <= '9')
return true;
else
return false;
}
bool IsDot(char ch) //判断是否为小数点
{
if (ch == '.')
return true;
else
return false;
}
bool queryArray10(string token, string array10[]) //遍历查找标识符码内值是否已经记录过
{
for (int j = 0; j < 999; j++)
{
if (token == array10[j])
{
xtemp = j;
return true;
}
}
return false;
}
bool queryArray11(double sum, double array11[]) //遍历查找整型常数码内值是否已经记录过
{
for (int j = 0; j < 999; j++)
{
if (sum == array11[j])
{
ytemp = j;
return true;
}
}
return false;
}
bool queryArray12(double sum, double array12[]) //遍历查找实型常数码内值是否已经记录过
{
for (int j = 0; j < 999; j++)
{
if (sum == array12[j])
{
ztemp = j;
return true;
}
}
return false;
}
//关键就在于scanner()扫描器函数(结合各种条件与提前定义好的函数判断程序中每个单位字符串的种类,并且指定相应的syn种别码)
void scanner(char s[]) //扫描
{
// 0.预处理
token = ""; //清空当前字符串(每次判断前都要清空上一次的记录)
// 1.判断字符是否为数字
if (IsDigit(s[i])) //空格后第一个字符是数字,则整个单元字符串一定是数
{
token = ""; //清空当前字符串
sum = 0.0;
while (IsDigit(s[i]))
{
sum = sum * 10.0 + (s[i] - '0') * 1.0; //逐位读取得该常数值(整数部分)
i++; //字符位置++
if (IsDot(s[i])) // 读到了小数点
{
i++;
syn = 12; //real常数种别码为12
double temp = 0.0;
double count = 1.0;
while (IsDigit(s[i]))
{
temp += (s[i] - '0') / pow(10.0, count); //逐位读取得该常数值(小数部分)
count++;
i++; //字符位置++
}
sum += temp;
break;
}
else
syn = 11; //INT常数种别码为11
}
if (syn == 11 && !queryArray11(sum, array11))
{
y++; //从100开始计数
}
if (syn == 12 && !queryArray12(sum, array12))
{
z++; //从200开始计数
}
}
// 2.判断字符为字符串的开头,表现为字母开头衔接任意个数字或字母
else if (IsLetter(s[i]))//空格后第一个字符是字母,是标识符或者关键字(先判断标识符再在其基础上判断关键字)
{
token = ""; //清空当前字符串
while (IsDigit(s[i]) || IsLetter(s[i])) {
token += s[i]; //加入token字符串
i++;
}
syn = 10; // 如果是标识符,种别码为10
if (!queryArray10(token, array10))
{
x++; //从0开始计数
}
//如果是关键字,则用for循环将token与keyword比较找对应的种别码
for (int j = 0; j < 9; j++)
{
if (token == KeyWord[j]) //如果都是string类型,可以直接=相比较,若相等则返回1,否则为0
{
if (token == "main")
{
syn = 1;
}
else if (token == "int")
{
syn = 2;
}
else if (token == "float")
{
syn = 3;
}
else if (token == "if")
{
syn = 4;
}
else if (token == "else")
{
syn = 5;
}
else if (token == "while")
{
syn = 6;
}
else if (token == "char")
{
syn = 30;
}
else if (token == "bool")
{
syn = 31;
}
/*else if (token == "")
{
syn = 32;
}*/
else if (token == "void")
{
syn = 33;
}
x--; //关键字不计数
break;
}
}
}
//3. 判断为符号
else {
token = ""; //清空当前字符串
switch (s[i])
{
case '|':
i++;
if (s[i] == '|')
{
syn = 7;
i++;
token = "||";
}
break;
case '&':
i++;
if (s[i] == '&')
{
syn = 8;
i++;
token = "&&";
}
break;
case '!':
syn = 9;
i++;
if (s[i] == '=')
{
syn = 23;
i++;
token = "!=";
}
break;
case '=':
syn = 13;
i++;
token = "=";
if (s[i] == '=') {
syn = 22;
i++;
token = "==";
}
break;
case '+':
syn = 14;
i++;
token = "+";
break;
case '-':
syn = 15;
i++;
token = "-";
break;
case '*':
syn = 16;
i++;
token = "*";
break;
case '/':
syn = 17;
i++;
token = "/";
break;
case '<':
syn = 18;
i++;
token = "<";
if (s[i] == '=')
{
syn = 19;
i++;
token = "<=";
}
break;
case '>':
syn = 20;
i++;
token = ">";
if (s[i] == '=')
{
syn = 21;
i++;
token = ">=";
}
break;
case ';':
syn = 24;
i++;
token = ";";
break;
case ',':
syn = 25;
i++;
token = ",";
break;
case '(':
syn = 26;
i++;
token = "(";
break;
case ')':
syn = 27;
i++;
token = ")";
break;
case '{':
syn = 28;
i++;
token = "[";
break;
case '}':
syn = 29;
i++;
token = "]";
break;
default:
//i++; //辅助调试:取消代码前注释以跳出死循环
syn = -1;
break;
}
}
}
2、语法分析器
程序设计语言所涉及的大部分语法单位,都可以采用递归下降分析法或预测分析分析法。注意,为了构造不带有回溯的自上而下的语法分析,首先需要通过形式变换将文法转化为 LL(1)文法。但是,算数表达式和布尔表达式也可以采用算符优先分析法,从而避免消除左递归带来的语法单位结构变化问题。

BNF规定如图:

为便于编程实现,我通过提取公共左因子、消除左递归等操作将上图转换如下所示:

(注:
其中,每条规则对应一个子函数;
转换的基本思想是,从每个左部出发往右部进行,(若有候选式,则)判断时,总是能唯一确定入口子函数;
有候选式的时候具体又分三种情况:
- 候选式开头全是< ? >,即没有一个候选式开头可确定syn种别码,那么在以该规则左部为入口的函数中,只需按序依次写出候选式对应的入口子函数;
- 候选式开头既有< ? >,又有可确定开头单词syn种别码的候选式,那么在以该规则左部为入口的函数中,则需判断读取到的syn是否等于该种别码,若是则进入该候选式对应的入口子函数,否则进入以< ? >开头的候选式对应的入口子函数;
- 候选式开头全是有可确定开头单词syn种别码的候选式,那么根据各个种别码判断读取到的syn是否相等,哪个相等就进入哪个候选式对应的入口子函数;
- 需要注意的是,如果候选式中含空字,则在以上三种情况的后面多加一条else return;即可(为了格式好认,不写也会自动回溯)
)
syntax.txt文件数据结构说明:
(语法名)
基本思路:递归回溯
- 在主函数中进入program子函数,之后各个子函数依据转换后的BNF一一定义
- 需要特别注意的是,需要打印输出相应语法名的七个子函数,各自之间有上级父函数对下级子函数的调用关系,基本上都是循规蹈矩的父函数调用子函数,所以基本都是从下一级子函数回溯到父函数之后才打印输出该父函数对应的语法名,这样能保证打印顺序正确,
- 唯独一条特例:
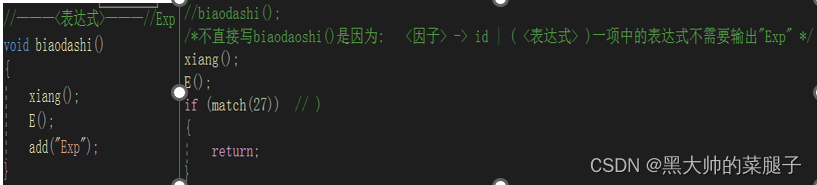
 ,由BNF可知,<表达式>对应的函数是<因子>对应的函数的上级,如果在<因子>对应的函数中直接定义<表达式>对应的函数,就会导致多余的打印输出。解决方案:把<表达式>对应的函数换成其除了打印输出的其余部分。
,由BNF可知,<表达式>对应的函数是<因子>对应的函数的上级,如果在<因子>对应的函数中直接定义<表达式>对应的函数,就会导致多余的打印输出。解决方案:把<表达式>对应的函数换成其除了打印输出的其余部分。
源码附上:
/*——————语法分析器——————*/
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
//函数声明:
void add(string s);
void getsyn();
bool match(int expectedsyn);
void chengxu();
void yujuliebiao();
void danyuju();
void shuomingyuju();
void fuzhiyuju();
void ifyuju();
void C();
void whileyuju();
void yujukuai();
void biaodashi();
void E();
void xiang();
void G();
void yinzi();
void buerbiaodashi();
void H();
void buerxiang();
void I();
void bueryinzi();
void guanxishi();
void guanxifu();
//全局变量声明:
int syn = 0; //读到的当前编码
string sign[5000]; //语法表
int signnum = 0; //语法个数
int synarray[5000]; //单词种别码表
int synnum = 0; //单词种别码数
int num = 0; //读到的当前编码下标
ifstream infile;
ofstream outfile;
int main()
{
int flag = 0;
infile.open("token.txt", ios::in);
outfile.open("syntax.txt", ios::out);
//将token.txt文件里的单词种别码逐个读入synarray数组中
while (!infile.eof())
{
infile >> flag;
synarray[synnum++] = flag;
infile >> flag;
}
getsyn();
chengxu();
//将语法表(sign数组)写到syntax.txt中
for (int i = 0; i < signnum; i++)
{
outfile << sign[i] << endl;
}
//记得关闭文件
infile.close();
outfile.close();
return 0;
}
//将判断成功的文法写入语法表
void add(string s)
{
sign[signnum++] = s;
}
//自动跳到下一个编码
void getsyn()
{
syn = synarray[num++];
}
//判断当前的编码与预期是否相同,相同则返回true并自动跳到下一个编码
bool match(int expectedsyn)
{
if (syn == expectedsyn)
{
getsyn();
return true;
}
return false;
}
//(——BNF见实验任务书——)
//———<程序>———//Program
void chengxu()
{
if (match(1)) // main
{
if (match(26)) // (
{
if (match(27)) //)
{
if (match(28)) // {
{
yujuliebiao();
if (match(29)) // }
{
add("Program");
return;
}
else
{
cout << "Syntax error: Missing '}'" << endl;
}
}
else
{
cout << "Syntax error: Missing '{'" << endl;
}
}
else
{
cout << "Syntax error: Missing ')' after identifier" << endl;
}
}
else
{
cout << "Syntax error: Missing '(' after 'main'" << endl;
}
}
else
{
cout << "Syntax error: Missing 'main' in program declaration" << endl;
}
}
//———<语句列表>———
void yujuliebiao()
{
if (syn != 29) // }
{
danyuju();
yujuliebiao();
}
else
{
return;
}
}
//———<单语句>———
void danyuju()
{
if (match(2) || match(3)) //为类型关键字int float进入说明语句
{
shuomingyuju();
}
else if (match(10)) //为标识符进入赋值语句
{
fuzhiyuju();
}
else if (match(4)) //为if进入if语句
{
ifyuju();
}
else if (match(6)) //为while进入while语句
{
whileyuju();
}
else //以上均不是则语法错误
{
cout << "Syntax error: Invalid statement" << endl;
}
}
//———<说明语句>———//DecSta
void shuomingyuju()
{
if (match(10)) // 标识符
{
if (match(25)) // ,
{
shuomingyuju();
}
else if (match(24)) // ;
{
add("DecSta");
}
else
{
cout << "Syntax error: Missing ';' or '=' in declaration statement" << endl;
}
}
}
//———<赋值语句>———//AssSta
void fuzhiyuju()
{
if (match(13)) // =
{
biaodashi();
if (match(24)) // ;
{
add("AssSta");
return;
}
else
{
cout << "Syntax error: Missing ';'" << endl;
}
}
}
//———<if语句>———//IfSta
void ifyuju()
{
if (match(26)) // (
{
buerbiaodashi();
if (match(27)) // )
{
yujukuai();
C();
add("IfSta");
return;
}
}
}
//———C———
void C()
{
if (match(5)) // else
{
yujukuai();
return;
}
else
{
return;
}
}
//———<while语句>———//WhileSta
void whileyuju()
{
if (match(26)) // (
{
buerbiaodashi();
if (match(27)) // )
{
yujukuai();
add("WhileSta");
return;
}
}
}
//———<语句块>———
void yujukuai()
{
if (match(28)) // {
{
yujuliebiao();
if (match(29)) // }
{
return;
}
else
{
cout << "Syntax error: Missing '}'" << endl;
}
}
else
{
danyuju();
}
}
//———<表达式>———//Exp
void biaodashi()
{
xiang();
E();
add("Exp");
}
//———E———
void E()
{
if (match(14) || match(15)) // + -
{
xiang();
E();
}
else
{
return;
}
}
//———<项>———
void xiang()
{
yinzi();
G();
}
//———G———
void G()
{
if (match(16)|| match(17)) // * /
{
yinzi();
G();
}
else
{
return;
}
}
//———<因子>———
void yinzi()
{
if (match(10) || match(11) || match(12)) // 标识符 整型常数 实型常数
{
return;
}
if (match(26)) // (
{
//biaodashi();
/*不直接写biaodaoshi()是因为: <因子> -> id | ( <表达式> )一项中的表达式不需要输出"Exp" */
xiang();
E();
if (match(27)) // )
{
return;
}
}
}
//———<布尔表达式>———//BoolExp
void buerbiaodashi()
{
buerxiang();
H();
add("BoolExp");
}
//———H———
void H()
{
if (match(7)) // ||
{
buerxiang();
H();
}
else {
return;
}
}
//———<布尔项>———
void buerxiang()
{
bueryinzi();
I();
}
//———I———
void I()
{
if (match(8)) // &&
{
bueryinzi();
I();
}
else
{
return;
}
}
//———<布尔因子>———
void bueryinzi()
{
if (match(9)) // !
{
guanxishi();
}
else
{
guanxishi();
}
}
//———<关系式>———
void guanxishi()
{
if (match(10) || match(11) || match(12)) // 标识符 整型常数 实型常数
{
guanxifu();
if (match(10) || match(11) || match(12)) // 标识符 整型常数 实型常数
{
return;
}
else
{
cout << "Syntax error: Missing right operand in relational expression" << endl;
}
}
else
{
cout << "Syntax error: Missing left operand in relational expression" << endl;
}
}
//———<关系符>———
void guanxifu()
{
if (match(18) || match(19) || match(20) || match(21) || match(22) || match(23)) // < <= > >= == !=
{
return;
}
}3、语义分析器
对语法分析正确的程序在其语法分析的基础上,进行语义翻译工作。每当分析出某语法单位时,就调用对应产生式的语义子程序,完成相应的翻译工作。例如,说明语句的语义动作为填写符号表,执行语句将生成相应的四元式。

BNF来源于实验二,不再赘述。
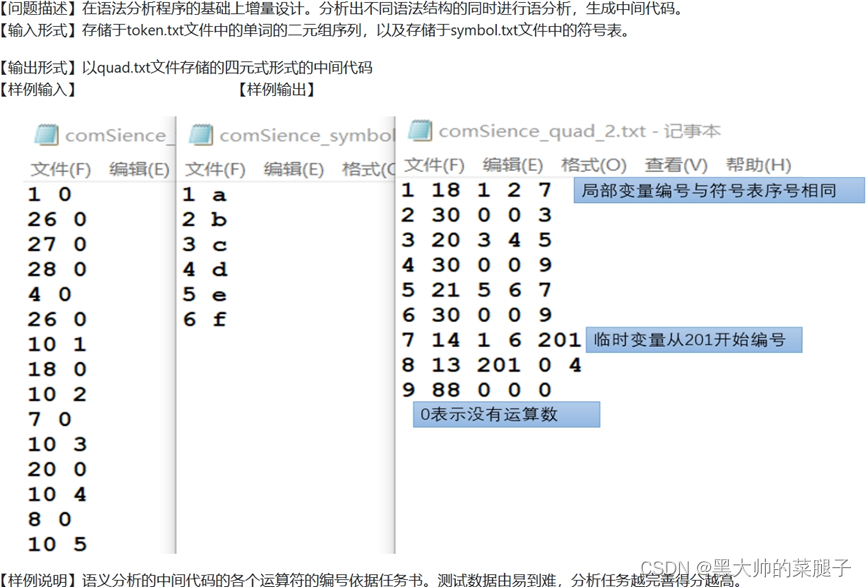
quad.txt文件数据结构说明:
(序号 操作码 参数一 参数二 结果)
基本思路:
将token.txt读取到自定义结构体数组struct Token token中(种别码,码内值索引);
由于该自上而下翻译模式需要做回填动作,所以不能一次性把四元式确定下来写入quad.txt,因此也要先用自定义结构体数组struct Equ equ来记录四元式的四个参数(特别是result);
关于各个语法成分对应的子函数的定义和实验二大体一致,此外还需对照教科书上控制语句、赋值语句、说明语句、布尔表达式等的翻译模式表,在各函数中添加上对应的语义动作。
源码附上:
/*——————语义分析器——————*/
#include<iostream>
#include<string>
#include<fstream>
#include<sstream>
using namespace std;
//——————函数声明——————
void tokenSolution(); // 读取token.txt,记录种别码和码内值索引
void emit(int op, int arg1, int arg2, int result); // 赋值四元式
int merge(int p1, int p2); // 合二为一,返回合并后的链首
void program(); //———<程序体>———
void sen_group(); //———<语句组>———
void single_sen(); //———<单语句>———
void shuomingyuju(); //———<说明语句>———
void if_sen(); //———<if语句>———
void while_sen(); //———<while语句>———
void simple_sen(); //———<赋值语句,简单句>———
void var_definition(); //———<变量定义>———
void type_definition(); //———<类型定义>———
void char_table(); //———<符号表>———
void bool_sen(); //———<bool语句>———
void bool_term(); //———<bool项>———
void bool_factor(); //———<bool因子>———
void backpatch(int p, int t); //回填
void sen_block(); //———<语句块>———
int expression();//———<表达式>———
int term(); //———<项>———
void gramma_analysis(); //———<语法分析>———
int factor(); //———<因子>———
int CreateTemp(); // 创建临时变量
//——————变量声明——————
typedef struct Token {
int syn = 0; // 种别码
int index; // 码内值索引
}Token;
typedef struct Equ {
int op = 0; // 操作码
int arg1 = 0; // 参数一
int arg2 = 0; // 参数二
int result = 0; // 结果
int type = 0;
}Equ;
struct Token token[999]; // 记录(种别码,码内值索引)
int token_index = 0; // token的索引
struct Equ equ[999]; // 暂存四元式序列
int equ_index = 1; // equ的索引
int mtrue[200], mfalse[200];
int mt = 0, mf = 0;
int temp = 200; // 临时变量,从200开始计数
//——————函数体——————
//——————主函数——————
int main() {
tokenSolution(); // 记录种别码和码内值索引
gramma_analysis(); // 语法分析
emit(88, 0, 0, 0); // 程序停止编码88
ofstream outfile;
outfile.open("quad.txt");
for (int i = 1; i < equ_index; i++) {
outfile << i << " " << equ[i].op << " " << equ[i].arg1 << " " << equ[i].arg2 << " " << equ[i].result << endl;
}
outfile.close();
return 0;
}
//——————子函数——————
// 读取token.txt,记录种别码和码内值索引:
void tokenSolution() { // 将token.txt中的(种别码,码内值索引)写入struct Token token[500]的(syn,index)
int flag = 0, i = 0;
int t;
fstream infile;
infile.open("token.txt");
while (!infile.eof()) {
if (flag == 0) {
infile >> t;
token[i].syn = t; // 写入种别码
flag = 1;
}
else {
infile >> t;
token[i].index = t; // 写入码内值索引
i++;
flag = 0;
}
}
infile.close();
}
// 语法分析:
void gramma_analysis()
{
if (token[token_index].syn == 1) // main
{
token_index = token_index + 4; // 省去main(){
program();
if (token[token_index].syn == 29) // 省去}
token_index++;
}
}
// 赋值四元式:
void emit(int op, int arg1, int arg2, int result)
{
equ[equ_index].op = op;
equ[equ_index].arg1 = arg1;
equ[equ_index].arg2 = arg2;
equ[equ_index].result = result;
equ_index++;
}
// 合二为一,返回合并后的链首:
int merge(int p1, int p2)
{
if (equ[p2].result == 0)
return p1;
else {
int p = p2;
while (equ[p].result != 0)
p = equ[p].result;
equ[p].result = p1 + 1;
return p2;
}
}
//———<程序体>———
void program() {
sen_group();
}
//———<语句组>———
void sen_group() {
single_sen();
if (token[token_index].syn != 29) // 不是}
sen_group();
}
//———<单语句>———
void single_sen() {
if (token[token_index].syn == 2 || token[token_index].syn == 3) // int,float
{
shuomingyuju(); // 说明语句
return;
}
if (token[token_index].syn == 4) // if
{
if_sen(); // if语句
return;
}
if (token[token_index].syn == 6) // while
{
while_sen(); // while语句
return;
}
if (token[token_index].syn == 10) // 标识符
{
simple_sen(); // 赋值语句,简单句
return;
}
}
//———<说明语句>———
void shuomingyuju()
{
var_definition();
if (token[token_index].syn == 2 || token[token_index].syn == 3) // int,float
shuomingyuju();
}
//———<if语句>———
void if_sen() {
if (token[token_index].syn == 4) // if
{
token_index = token_index + 2; // 省去if(
int t = mt;
int f = mf;
bool_sen();
token_index++; // 省去)
while (mt > t)
{
backpatch(mtrue[mt - 1], equ_index);
mt--;
}
sen_block();
if (token[token_index].syn == 5) // else
{
token_index++;
int t = equ_index;
emit(30, 0, 0, 0);
while (mf > f)
{
backpatch(mfalse[mf - 1], equ_index);
mf--;
}
sen_block();
equ[t].result = equ_index;
}
while (mf > f)
{
backpatch(mfalse[mf - 1], equ_index);
mf--;
}
}
}
//———<while语句>———
void while_sen() {
if (token[token_index].syn == 6)//while
{
int t = equ_index;
token_index = token_index + 2;//省去while (
bool_sen();
token_index++;//省去 )
while (mt > 0)
{
backpatch(mtrue[mt - 1], equ_index);
mt--;
}
sen_block();
emit(30, 0, 0, t);
while (mf > 0)
{
backpatch(mfalse[mf - 1], equ_index);
mf--;
}
}
}
//———<赋值语句,简单句>———
void simple_sen() {
int op, arg1, arg2, result;
if (token[token_index].syn == 10) // 标识符
{
token_index++;
if (token[token_index].syn == 13) // =
{
result = token[token_index - 1].index;
op = 13;
arg2 = 0;
token_index++;
arg1 = expression();
emit(op, arg1, arg2, result);
}
if (token[token_index].syn == 24)//;
token_index++;
}
}
// 变量定义:
void var_definition() {
type_definition();
char_table();
}
// 类型定义:
void type_definition() {
if (token[token_index].syn == 2 || token[token_index].syn == 3) // int,float
{
token_index++;
}
}
//———<符号表>———
void char_table() {
if (token[token_index].syn == 10) // 标识符
{
token_index++;
while (token[token_index].syn == 10 || token[token_index].syn == 25) { // 标识符 / ,
token_index++;
}
}
if (token[token_index].syn == 24) // ;
token_index++;
}
//———<bool语句>———
void bool_sen() {
bool_term();
while (token[token_index].syn == 7) // ||
{
token_index++;
backpatch(mfalse[mf - 1], equ_index);
mf--;
bool_term();
equ[equ_index].result = merge(mtrue[mt], mtrue[mt - 1]);
}
}
//———<bool项>———
void bool_term() {
bool_factor();
while (token[token_index].syn == 8) // &&
{
if (mf > 0) {
backpatch(mtrue[mt - 1], equ_index);
mt--;
}
token_index++;
bool_factor();
equ[equ_index].result = merge(mfalse[mf], mfalse[mf - 1]);
}
}
//———<bool因子>———
void bool_factor() {
int op = 0, arg1 = 0, arg2 = 0, result = 0;
if (token[token_index].syn == 9) //非 !
{
token_index++;
bool_factor();
}
else if (token[token_index].syn == 10 || token[token_index].syn == 11 || token[token_index].syn == 12) // 标识符,整数,实数
{
arg1 = token[token_index].index;
token_index++;
if (token[token_index].syn >= 18 && token[token_index].syn <= 23) {
if (token[token_index].syn == 18) // <
op = 18;
if (token[token_index].syn == 19) // <=
op = 19;
if (token[token_index].syn == 20) // >
op = 20;
if (token[token_index].syn == 21) // >=
op = 21;
if (token[token_index].syn == 22) // ==
op = 22;
if (token[token_index].syn == 23) // !=
op = 23;
token_index++;
if (token[token_index].syn == 10 || token[token_index].syn == 11 || token[token_index].syn == 12) { // 标识符,整数,实数
arg2 = token[token_index].index;
token_index++;
}
else if (token[token_index].syn == 26) // (
{
token_index++;
arg2 = expression();
if (token[token_index].syn == 27) // )
token_index++;
}
}
}
else if (token[token_index].syn == 26) // (
{
arg1 = expression();
token_index++;
if (token[token_index].syn >= 18 && token[token_index].syn <= 23) {
if (token[token_index].syn == 18) // <
op = 18;
if (token[token_index].syn == 19) // <=
op = 19;
if (token[token_index].syn == 20) // >
op = 20;
if (token[token_index].syn == 21) // >=
op = 21;
if (token[token_index].syn == 22) // ==
op = 22;
if (token[token_index].syn == 23) // !=
op = 23;
token_index++;
if (token[token_index].syn == 10 || token[token_index].syn == 11 || token[token_index].syn == 12) { // 标识符,整数,实数
arg2 = token[token_index].index;
token_index++;
}
else if (token[token_index].syn == 26)
{
token_index++;
arg2 = expression();
if (token[token_index].syn == 27)
token_index++;
}
}
}
mtrue[mt] = equ_index;
mt++;
equ[equ_index].type = 1;
emit(op, arg1, arg2, 0);
mfalse[mf] = equ_index;
mf++;
equ[equ_index].type = 2;
emit(30, 0, 0, 0);
}
//回填:
void backpatch(int p, int t) {
int q = p;
while (q != 0)
{
int m = equ[q].result;
equ[q].result = t;
q = m;
}
}
//———<语句块>———
void sen_block()
{
if (token[token_index].syn == 28)//{
{
token_index++;//省去{
sen_group();
token_index++;//省去}
}else
{
single_sen();
}
}
//———<表达式>———
int expression() {
int op, arg1, arg2, result;
arg1 = term();
if (token[token_index].syn == 14 || token[token_index].syn == 15)//加减,+-
{
if (token[token_index].syn == 14) {
op = 14;
}
if (token[token_index].syn == 15) {
op = 15;
}
token_index++;
arg2 = term(); //expression();
result = CreateTemp();
emit(op, arg1, arg2, result);
return result;
}
else
{
return arg1;
}
}
//———<项>———
int term() {
int op, arg1, arg2, result;
arg1 = factor();
while (token[token_index].syn == 16 || token[token_index].syn == 17) // * /
{
if (token[token_index].syn == 16) {
op = 16;
}
if (token[token_index].syn == 17) {
op = 17;
}
token_index++;
arg2 = factor();
result = CreateTemp();
emit(op, arg1, arg2, result);
arg1 = result;
}
return arg1;
}
//———<因子>———
int factor() {
int arg;
if (token[token_index].syn == 10 || token[token_index].syn == 11 || token[token_index].syn == 12) // 标识符,整数,实数
{
arg = token[token_index].index;
token_index++;
}
else if (token[token_index].syn == 26) // (
{
token_index++;
arg = expression();
if (token[token_index].syn == 27) { // )
token_index++;
}
}
return arg;
}
// 创建临时变量:
int CreateTemp() {
temp++;
return temp;
}三、课程设计(综合实验)总结或结论
1 词法分析器
词法分析器是最基础的步骤,核心部分是扫描器scanner(),需要注意的细节挺多的,比如整型常数和实型常数获取整数部分和小数部分数值的算法不相同,需要分开写;类似&&、||这种两个字符当作一个字符看的,也要一个字符一个字符地拆开嵌套判断;还有写symbol文档之前需要先判断该码内值是否已经记录过了,避免重复记录等等。
2 语法分析器
在经过词法分析scanner()扫描后可以得到token和symbol文档,不同于词法分析器一次读入不做记录的读取方式,语法分析器需要将字符(串)读入存到一个数组里,方便后续操作。
为了方便编程,基于每次判断只有唯一的下一步操作的思想,可以将任务书的BNF通过消除左递归、消除回溯的手段转换,得到新的BNF。
3 语义分析器
由于该自上而下翻译模式需要做回填动作,所以不能一次性把四元式确定下来写入quad.txt,因此也要先用自定义结构体数组struct Equ equ来记录四元式的四个参数(特别是result);关于各个语法成分对应的子函数的定义和实验二大体一致,此外还需对照教科书上控制语句、赋值语句、说明语句、布尔表达式等的翻译模式表,在各函数中添加上对应的语义动作。
四、参考文献
[1] 鲁斌, 李继荣等. 编译技术基础教程. 2011年10月第1版. 北京:清华大学出版社, 2011
[2] 刘磊. 编译原理及实现技术[M]. 北京:机械工业出版社,2010















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









