






最近在学习xpath,当爬取站长素材图片时遇到了以下问题,记录一下。
当利用class属性在浏览器中测试是能出结果的,但在python中却得到了空值
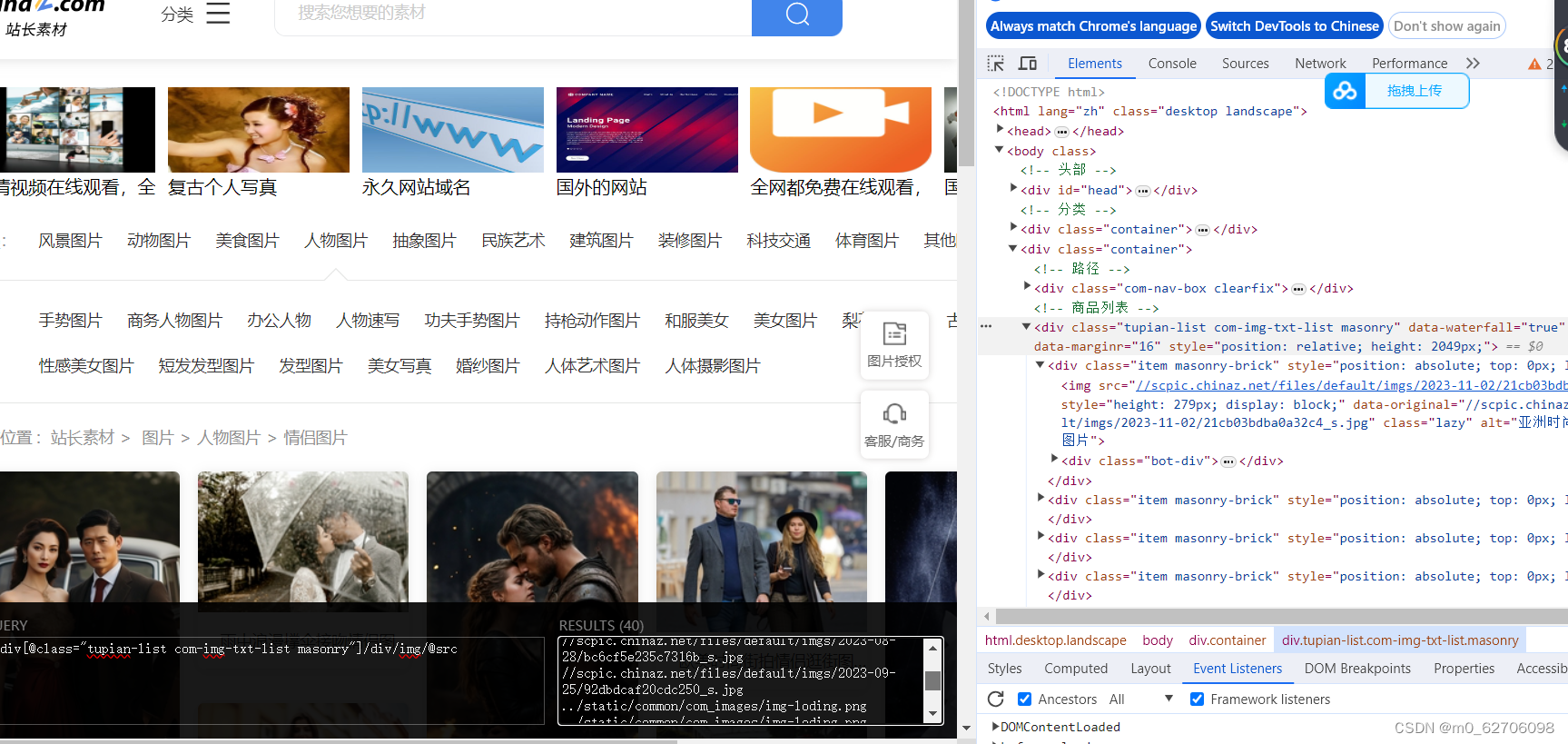
于是我选择了使用js-do值试试,没想到python中也出结果了
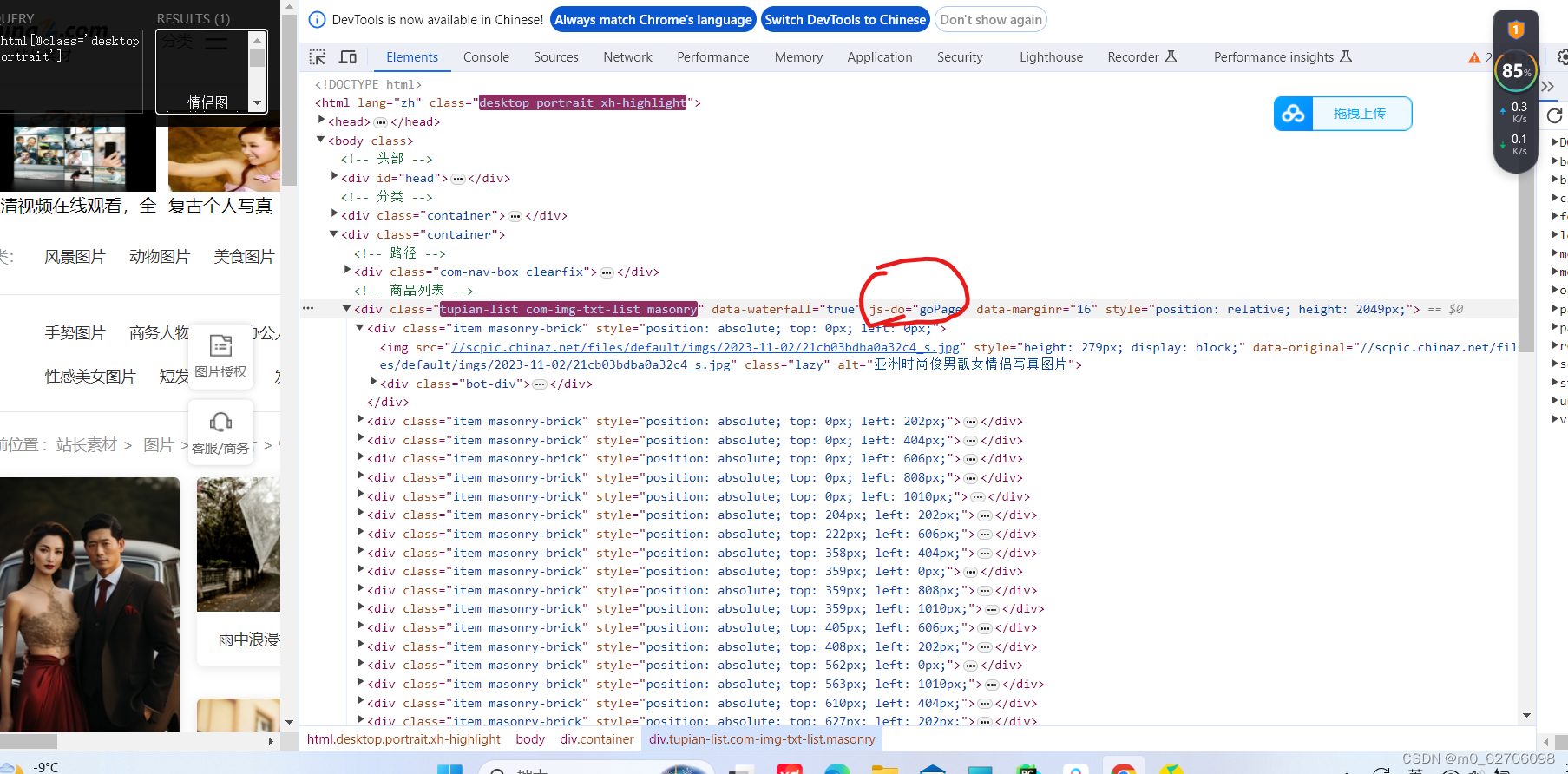
但是却是相同的src。
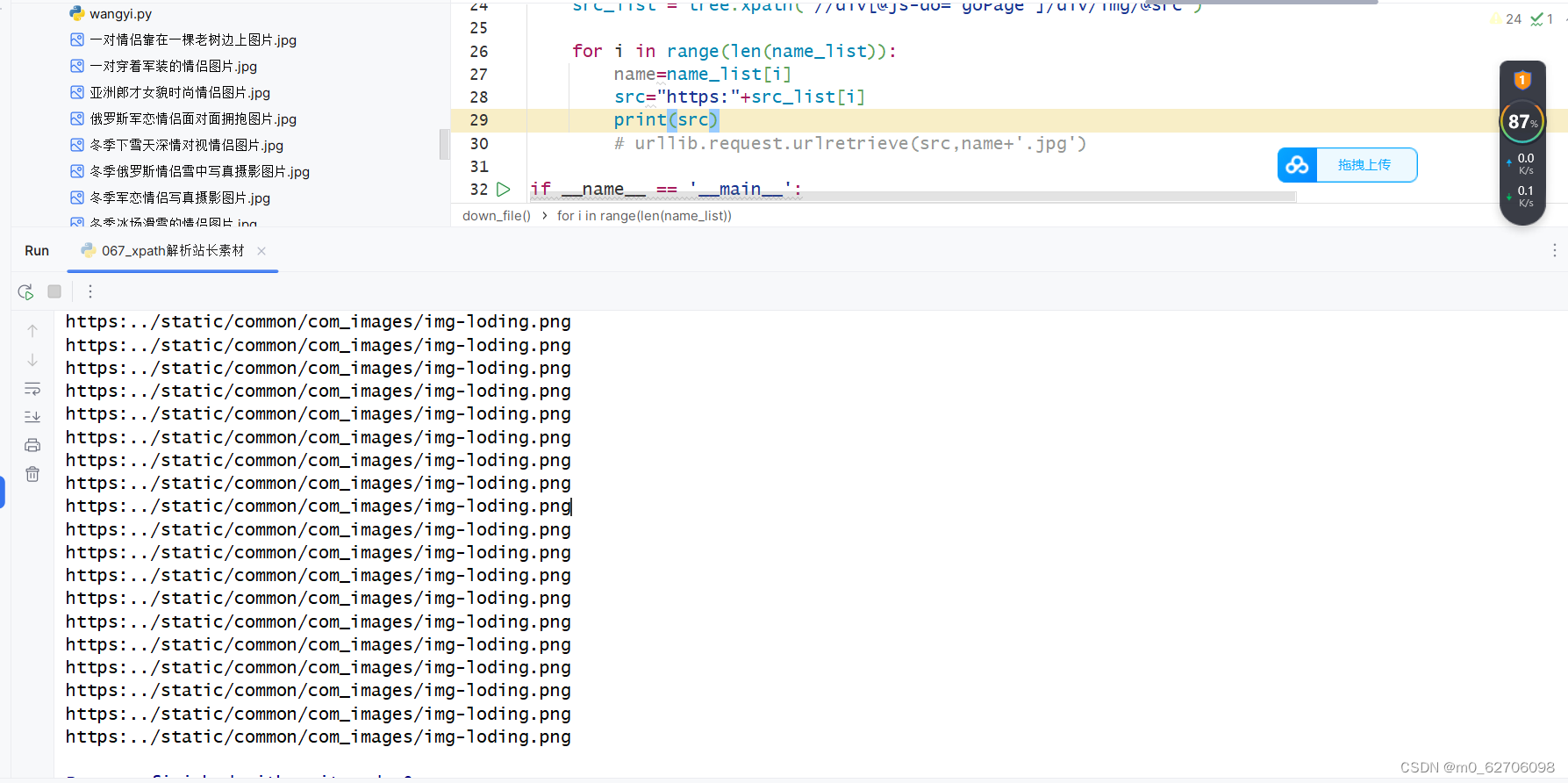
经过上网查发现这是懒加载,当我们刚开始进入到一个具有懒加载的页面时,没被加载出来的图片都是一个src,当我们下滑拖动加载完成后,图片的src也会随之变化,这个src才是我们所需要的。
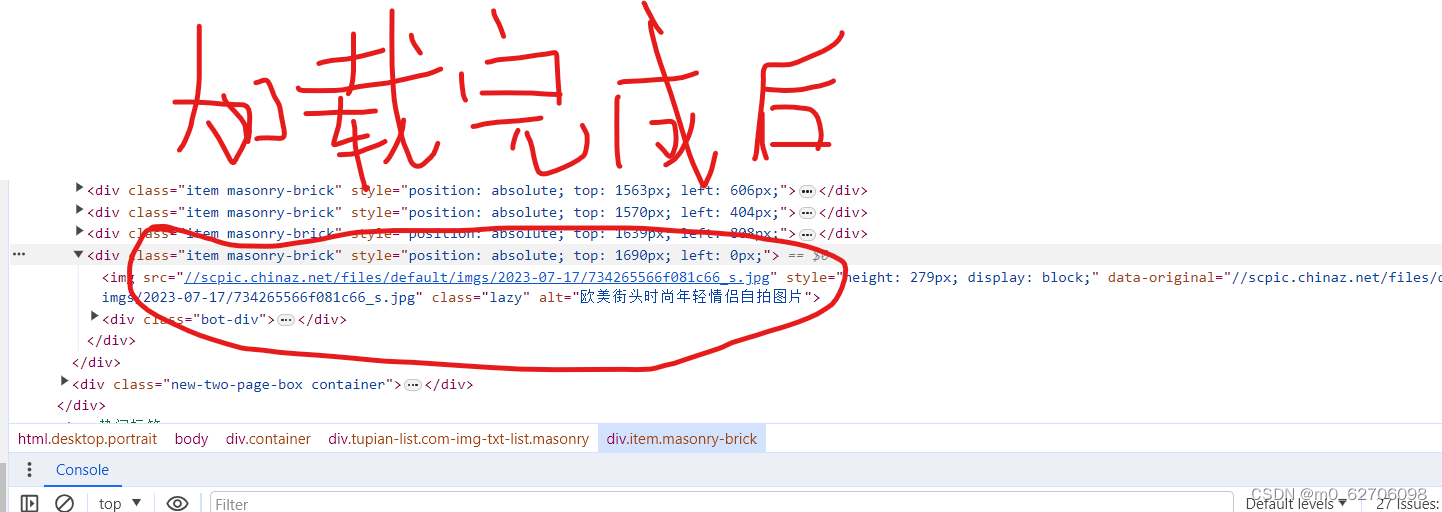
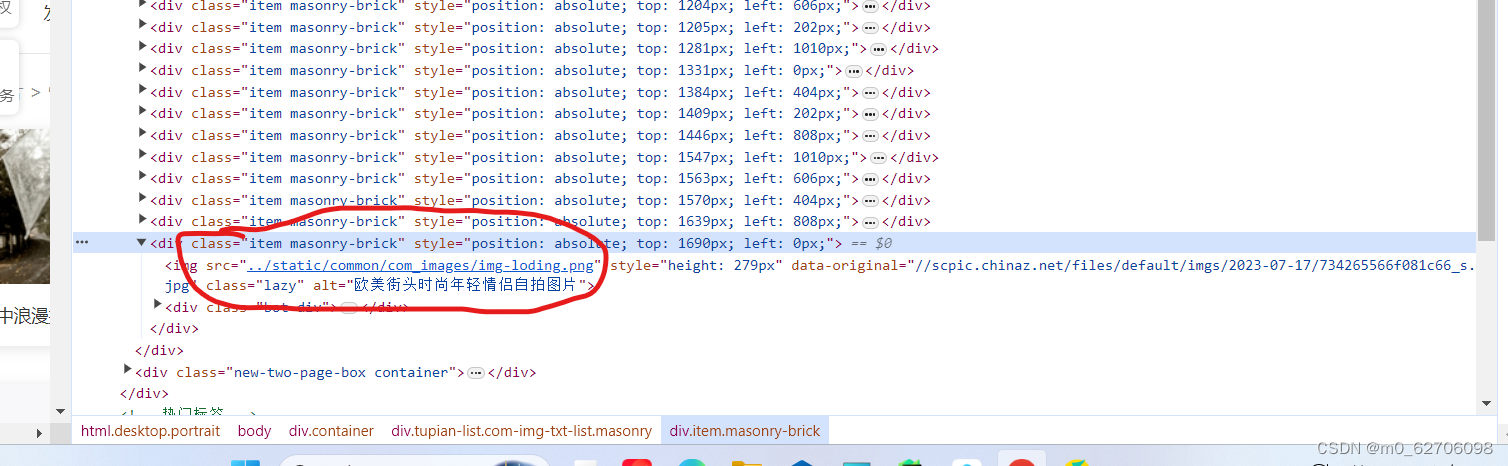
但是我们如何获得这个正确的src呢,前后src的变量名并未发生改变,经过观察我们发现有一个叫
data-original 属性里面的值和src中的值是相同的
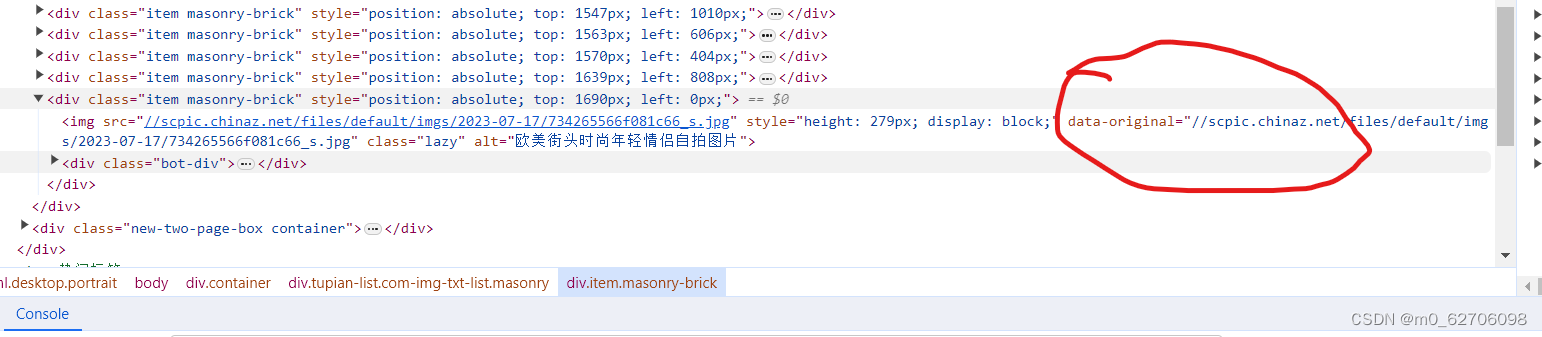
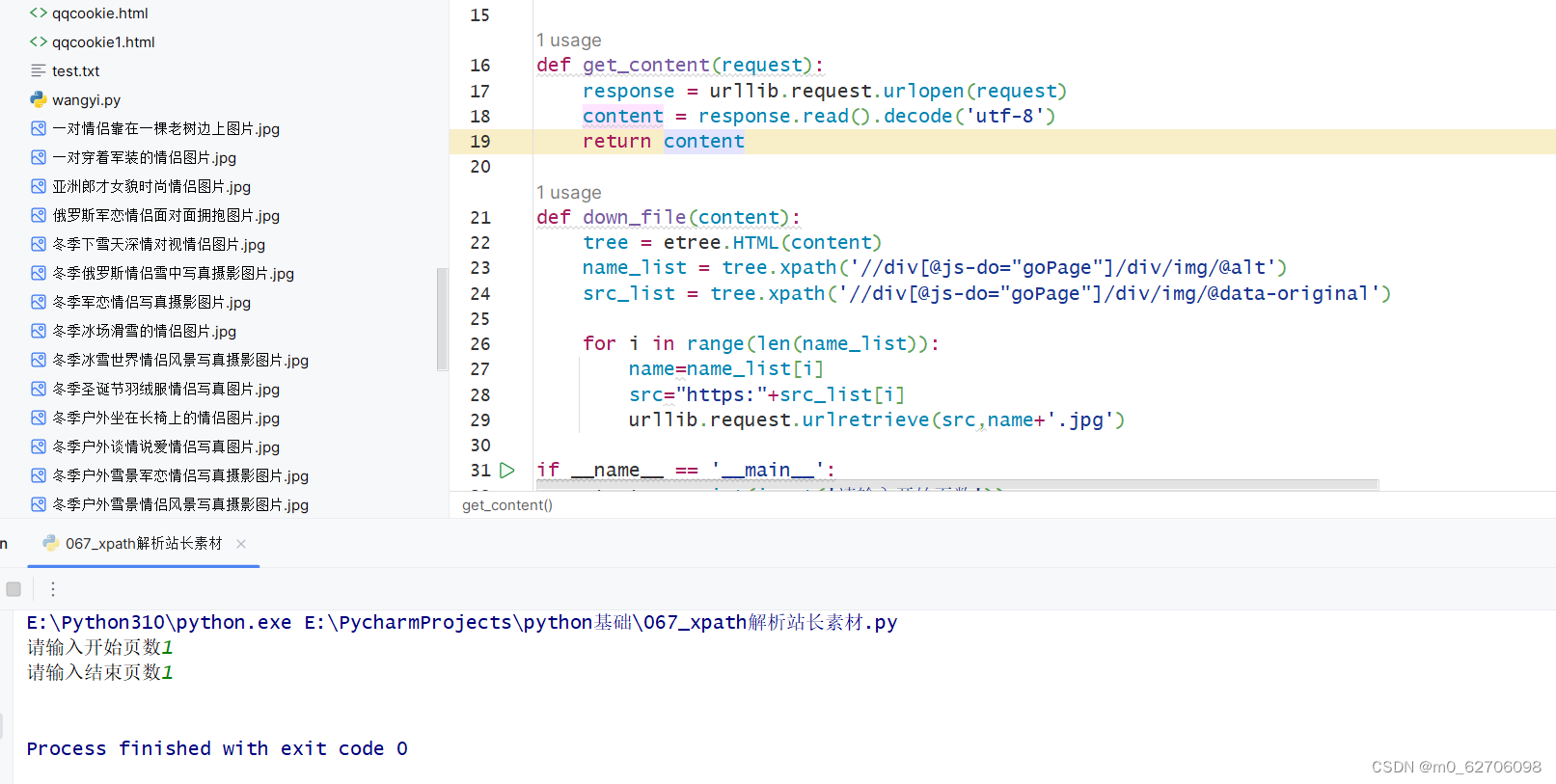
直接利用这个属性值,下载成功















 3762
3762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









