






一:简介
一、背景
1. 对于公有云计算平台来说,只有计算、网络与存储这三大服务往往是不太够的,在目前互联网应用百花齐放的背景下,几乎所有应用都使用到数据库,而数据库承载的往往是应用最核心的数据。此外,在大数据分析越来越盛行的背景下,对数据库的可靠便捷管理也变得更为重要。因此,DBase as a Service(DBaaS,数据库服务)也就顺理成章地成为了云计算平台为用户创造价值的一个重要服务。
2. 对比Amazon AWS中各种关于数据的服务,其中最著名的是RDS(SQL-base)和DynamoDB(NoSQL),除了实现了基本的数据管理能力,还具备良好的伸缩能力、容灾能力和不同规格的性能表现。因此,对于最炙手可热的开源云计算平台Openstack来说,也从Icehouse版加入了DBaaS服务,代号Trove。直到去年底发布的Openstack Liberty版本,Trove已经经过了4个版本的迭代发布,目前已经成为Openstack官方可选的核心服务之一。本文将深入介绍Trove的原理、架构与功能,并通过实践来展示Trove的应用。
二、设计目标
1. Trove is Database as a Service for OpenStack. It’s designed to run entirely on OpenStack, with the goal of allowing users to quickly and easily utilize the features of a relational or non-relational database without the burden of handling complex administrative tasks. ”这是Trove在官方首页上对这个项目的说明,有两个关键点。一个是从产品设计上说,它定位不仅仅是关系型数据库,而且还涵盖非关系数据库的服务。另一个是从产品实现上说,它是完全基于Openstack的。
2. 从第一点可以看出Trove解决问题的高度已经超越了同类产品。因为我们从其他云计算平台对比去看,关系型和非关系型数据库都是由不同的服务去提供(比如AWS的RDS和DynamoDB),而且实现上也往往互相独立的系统,不仅UI不同,API也不一样。而Trove的目标是抽象尽可能多的东西,对外提供统一的UI和API,尽量减少冗余实现,提升平台内聚。只要具备了实例、数据库、用户、配置、备份、集群、主从复制这些概念,不管是关系型还是非关系型数据库,都能统一管理起来。从最新的Liberty版本发布的情况下,目前开源的主流关系型和非关系型数据库也得到了支持,比如Mysql(包括Percona和MariaDB分支)、Postgresql、Redis、MongoDB、CouchDB、Cassandra等等。不过根据官方的介绍,目前只有Mysql是得到了充分的生产性测试,其他的还处于实验性阶段。
3. 而第二点完全基于Openstack的,可以说是一个较大的创新。试想,假设你是一个云计算服务商,如果现在要提供数据库服务,只需要在原有平台软件上升级与配置一下就行,其他什么都不需要,不需要采购数据库服务器硬件,不需要规划网络,不需要规划IDC,这是一种什么样的感觉?Trove完全构建于Openstack原有的几大基础服务之上。打个比喻类似于Google著名的Bigtable服务是构建于GFS、Borg、Chubby等几个基础服务之上。所以,Trove实际上拥有了云平台的一些基础特性,比如容灾隔离、动态调度、快速响应等能力,而且从研发的角度看,也大大减少了重复造轮子的现象。
三、基本概念
1. 数据库实例(Instance):包含数据库程序的openstack虚拟机,如果用户创建了一个数据库实例,那么他其实就创建了一台openstack虚拟机,并在该虚拟机上启动了数据库服务。
2. Datastore:用来表示和存储数据库的类型、版本、虚拟机镜像等信息。当用户创建一个数据库实例时需要指定Datastore.
3. 配置组(Configuration Group):数据库参数组成的集合。用户可以将配置组应用到一个或多个数据库实例上,因而避免了大量的重复操作。
四、特点
1. "按需"获得数据库服务器,配置所获得的数据库服务器或者数据库服务器集群
2. 自动化操作,自动的增、删、改、备。
3. 更好的资源利用,你可以根据业务量,自由的对数据库实例进行伸缩。
二:架构
一、核心架构

二、组件详解
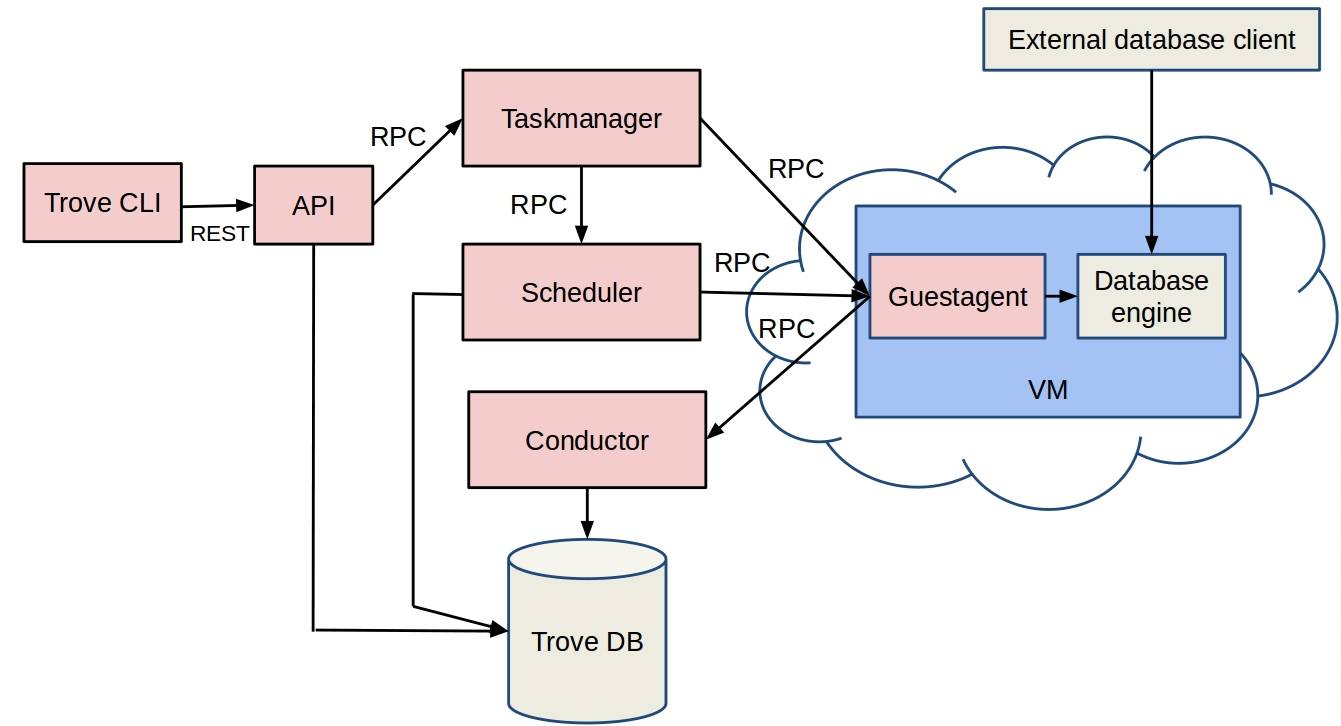
1. trove-api:用于操作请求的接收和分发操作提供 REST 风格的 API,同时与 trove-conductor 和 trove-taskmanager 通信,一些轻量级的请求,比如获取实例状态,实例数量等操作都是自身直接处理或访问 trove。trove-conductor 和 trove-taskmanager处理比较重量级的操作。比如创建数据库,创建备份等操作都是通过rpc传递给 trove-taskmanager,然后通过调用 nova、swift、neutron、cinder等组件来完成操作。
2. trove-conductor:将 vm 内 trove-guestagent 发送的状态信息保存到数据库,与 trove-guestagent 的通信是通过rpc来实现的,trove-conductor 这个组件的目的是为了避免创建的数据库的实例直接访问数据库,它是做为一个 trove-guestagent 将昨天写入数据库的中间件。
3. trove-taskmanager:执行 trove 中大部分复杂的操作,请求者发送消息到 trove-taskmanager,trove-taskmanager 在请求者的上下文中调用相应的程序执行这些请求。taskmanager 处理一些操作,包括实例的创建、删除,与其他服务如Nova、Cinder、Swift等的交互,一些更复杂的Trove操作如复制和集群,以及对实例的整个生命周期的管理。trov-taskmanager就像是其他openstak服务的客户端,如nova,swift,cinder等,当要创建数据库实例时就将请求发送给nova,让nova去创建个实例,要备份的话就调用swift接口上传备份。
4. trove-guestagent:集成在vm镜像里面,通过监听rpc里面task manager发过来的指令,并在本地执行代码完成数据库任务,taskmanager将消息发送到guest agent,guest agent通过调用相应的程序执行这些请求。
三、功能

1. 动态resize能力:分为instance-resize和volume-resize,前者主要是实例运行的内存大小和cpu核数,后者主要是指数据库分区对应的硬盘卷的大小。由于实例是跑在vm上的,而vm的cpu和memory的规格可以通过Nova来进行动态调整,所以调整是非常方便快捷的。另外硬盘卷也是由Cinder提供的动态扩展功能来实现resize。resize过程中服务会有短暂的中断,是由于mysqld重启导致的。
2. 全量与增量备份:目前mysql的实现中,备份是由实例vm上的guestagent运行xtrabackup工具进行备份,且备份后的文件会存储在Swift对象存储中。从备份创建实例的过程则相反。由于xtrabackup强大的备份功能,所以Trove要做的只是做一些粘胶水的工作。
3. 动态配置更新:目前支持实例的自定义配置,可以创建配置组应该到一组实例上,且动态attach到运行中的实例中生效。
4. 一主多从的一键创建:在创建数据库实例的API中,支持批量创建多个从实例,并以指定的实例做主进行同步复制。这样就方便了从一个已有实例创建多个从实例的操作。而且mysql5.6版本之后的同步复制支持GTID二进制日志,使得主从实例之间关系的建立更加可靠和灵活,在failover处理上也更加快速。
5. 集群创建与管理(percona/mariadb支持):Cluster 功能目前在 mysql原生版本暂时不支持,但是其两个分支版本 percona和 mariadb基于 Galera库实现的集群复制技术是支持的。另外Liberty版本的Trove也提供了对mongodb的集群支持。
三:常用操作
一、实例、数据库、数据库用户管理

二、备份和集群管理
















 2232
2232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









