






一,ArrayList和LinkList
区别和联系:
1.底层数据结构:ArrayList是基于动态数组的数据结构实现,LinkList是基于双向链表的数据结构实现。
2.操作效率:ArrayList按照下标查询的时间复杂度为O(1),因为内存是连续的,根据寻址公式(首地址+索引*存储数据类型的大小),LinkList不支持下标查询,但是都支持遍历查询,时间复杂度都为O(n)。
新增删除:两个头尾的增加和删除元素都比较简单,时间复杂度为O(1),但是中间部分的时间复杂度为O(n)。
3.内存空间的占用:ArrayList内存是连续的,底层是数组,节省内存,而LinkList需要存储数据,和两个指针,比较占用内存
4.线程安全:总的来说两个都不是线程安全的,但是如果说在方法内使用则可以保证线程安全,或者使用synchronized包装
二,HashMap
二叉树:
1.什么是二叉树?
每个节点最多有两个叉,分别是左右子树,不要求每个节点都有两个子节点,
2.什么是二叉搜索树?
又名二叉查找树,有序二叉树,该节点的左子树的值小于该节点的值,右子树的值大于该节点的值,没有键值相等的节点,时间复杂度为O(logn)
3.什么是红黑树?
又叫自平衡的二叉搜索树,节点要么红色要么黑色,根节点是黑色,,叶子节点都是黑色的空节点,红色的子节点都是黑色。
4.什么是散列表?
它又叫哈希表,根据键key直接访问在内存存储位置中的值value的数据结构,它是由数组演化而来的。散列函数:hashValue=hash(key)
哈希冲突:当不同的key经过hash函数得到的value的地址值相同时,就会产生冲突,
解决方法1:数组的每个下标位置称之为桶或者是槽,在桶的后面会有一个链表(当列表的长度大于8,数组长度大于64才会转换成红黑树),所有散列值相同的元素放在链表中。
HashMap实现原理
1.底层使用hash表数据结构,数组+链表或者红黑树
添加数据时,先计算key的值确定元素在数组中的下标,key相同则替换,不同则存入链表
获取数据时通过key的hash计算数组下标获取元素。
2.HashMap的put方法的具体流程?
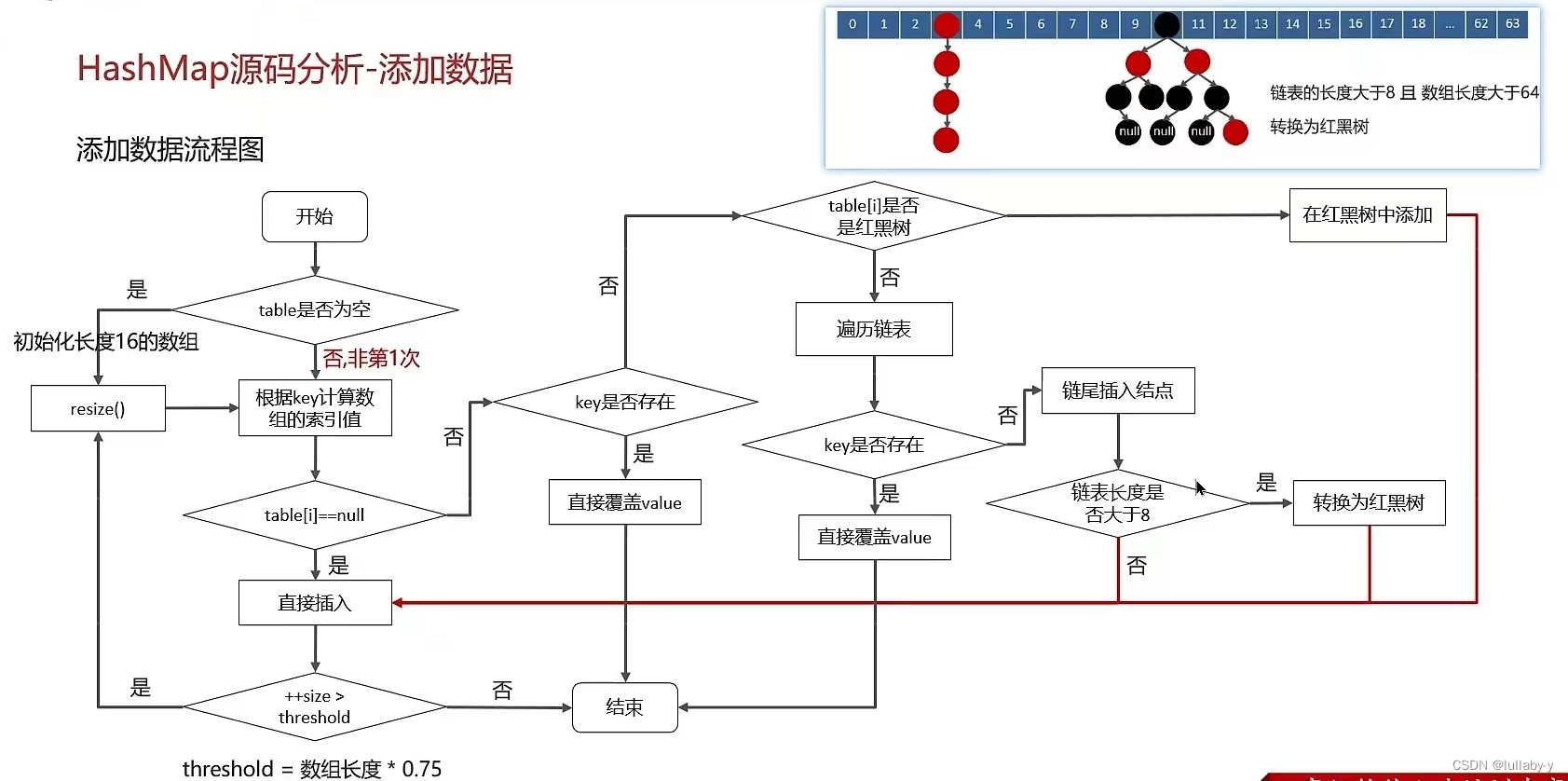
-
首先,根据键的哈希值(通过调用键对象的hashCode方法获得)和HashMap的容量计算出该键值对应的数组索引位置。这个过程称为哈希定位。
-
然后,检查该索引位置是否已经存在元素。如果该位置没有元素,则直接将键值对插入到该位置。
-
如果该位置已经存在元素(可能是一个键值对,也可能是链表或者红黑树),则需要进行进一步的处理:
- 如果该位置上的元素是一个链表或者红黑树,说明发生了哈希冲突,即不同的键具有相同的哈希值。这时候会根据键的equals方法比较键的值:
- 如果存在相同的键,则更新该键对应的值。
- 如果不存在相同的键,则将新的键值对添加到链表或红黑树的末尾。
- 如果该位置上的元素不是链表或红黑树,且与要插入的键值对的键不相等,说明该位置已经存在一个键值对,需要进行扩容。HashMap会将数组容量增加一倍,并将原有的键值对重新哈希到新的数组中。
- 如果该位置上的元素是一个链表或者红黑树,说明发生了哈希冲突,即不同的键具有相同的哈希值。这时候会根据键的equals方法比较键的值:
-
如果插入操作成功,HashMap会更新键值对的数量,并根据需要进行扩容操作。
HashMap的扩容机制
-
创建一个新的数组,其长度是当前数组长度的两倍。
-
遍历原数组中的每个位置,将其中的键值对重新计算哈希值,并放入新数组的对应位置中。
-
扩容后的数组中可能存在哈希冲突,即不同的键计算得到的哈希值相同,这时候需要进行链表转换或者树化操作。
- 如果某个位置上的链表长度小于8,仍然使用链表存储键值对。
- 如果链表长度达到8,则将链表转换为红黑树,以提高查询、插入、删除的性能。
-
扩容完成后,HashMap会更新容量和阈值(负载因子与容量的乘积),以便在下次插入操作时继续判断是否需要扩容。
扩容过程是一个相对耗时的操作,因为需要重新计算哈希值并重新分配元素的位置。但是它能够有效地减少哈希冲突,提高HashMap的性能。
HashMap的寻址算法
-
首先,计算键的哈希值。哈希值是一个32位的整数,用于表示键的特征码。
-
对哈希值进行再哈希(hash & (length-1))。这个操作的目的是为了将哈希值映射到数组的索引位置。这里的(length-1)是因为HashMap的容量总是2的幂次方,这样可以保证再哈希的结果在数组索引范围内。
-
得到的索引就是键值对在数组中的位置。如果该位置上已经存在元素,则可能会发生哈希冲突。
在发生哈希冲突时,HashMap采用的解决方法是链地址法(Separate Chaining):
- 如果哈希冲突发生在数组的某个位置上,HashMap会将具有相同哈希值的键值对存储在同一个位置上,形成一个链表。
- 当需要查找或插入键值对时,HashMap会根据键的哈希值定位到数组的位置,然后遍历该位置上的链表,通过比较键的equals方法找到对应的键值对。
HashMap的死循环问题
HashMap的死循环问题通常指的是在多线程环境下,对HashMap进行并发的插入、删除等操作时可能会导致的死循环情况。这种情况主要是由于HashMap在进行扩容(rehash)操作时,可能会出现环形链表,从而导致死循环。
具体来说,当多个线程同时对HashMap进行插入操作时,可能会触发HashMap的扩容操作。在扩容过程中,原数组中的元素需要重新分配到新的数组中,如果多个线程同时进行这个操作,并且它们互相干扰了对方正在进行的操作,就可能导致环形链表的产生。这种环形链表可能会导致某些线程在遍历HashMap时陷入死循环。
为了解决这个问题,可以采用以下几种方法:
-
使用并发安全的HashMap实现,例如ConcurrentHashMap。ConcurrentHashMap采用了分段锁(Segment)的机制,每个Segment上有一个锁,不同的Segment可以同时进行操作,从而减少了线程之间的竞争,避免了死循环问题。
-
在多线程环境下,尽量避免对HashMap进行并发的插入、删除操作。如果确实需要进行并发操作,可以采用显式的同步措施(如使用同步代码块或锁)来确保线程安全。
-
在Java 8及更新版本中,可以考虑使用并发工具类中提供的线程安全的集合实现,如ConcurrentHashMap、CopyOnWriteArrayList等,以减少在多线程环境下出现死循环的可能性。















 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









