







CPU Designer
文章目录
先决知识
数字电路与数字逻辑设计
risc-v汇编指令
引言
计算机的发明是信息时代最恢弘最根本的起点。操作系统与CPU是其中两个非常重要的部分,是计算机软件和硬件最核心也是最重要的模块。在这部分,我们将逐步动手实现一个CPU(center process unit 中央处理器),并在设计过程中逐步领会到计算机的组成原理,认识到如何从晶体管蜕变处理器的过程。
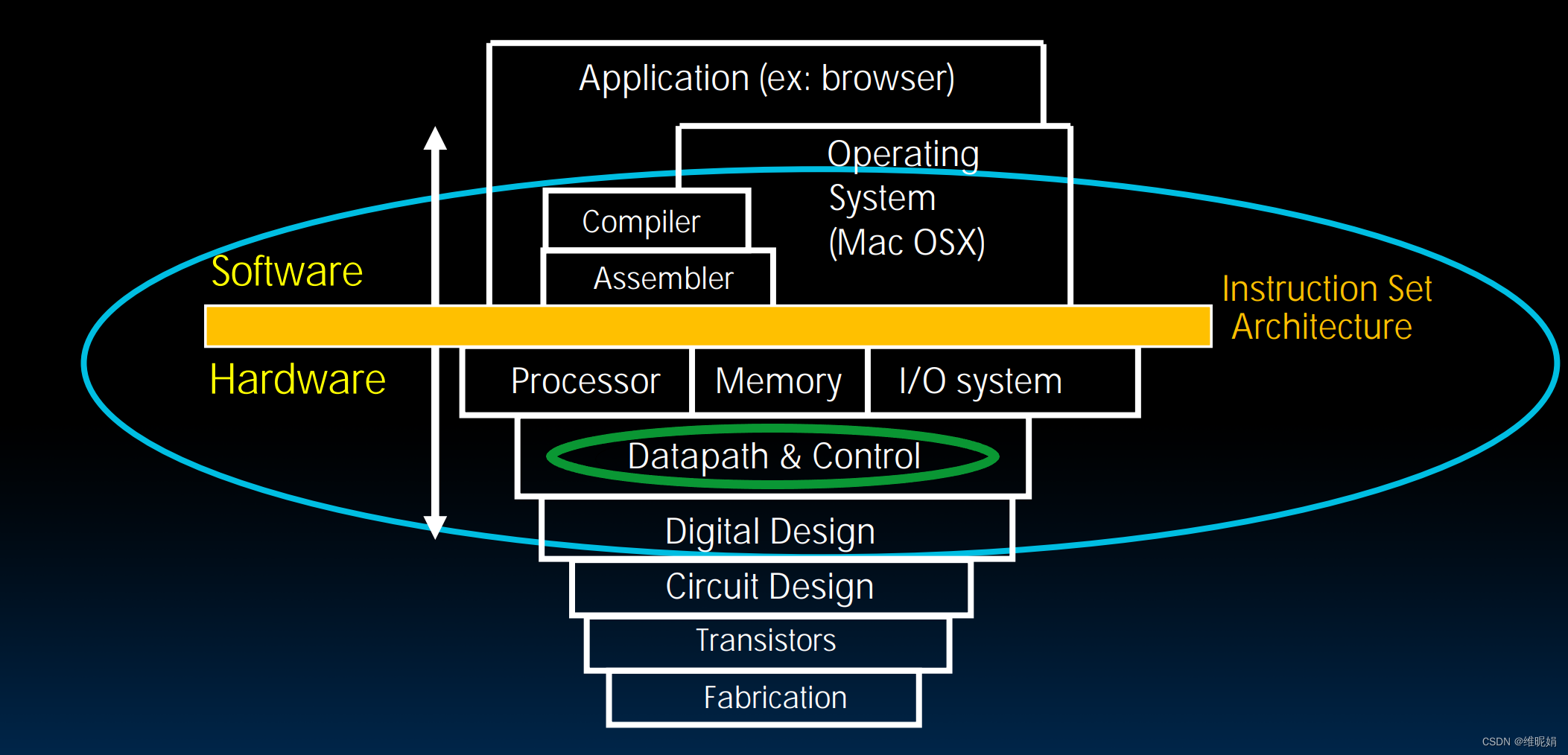
(上图引用自UCB,后面我们引用的绝大部分图片是来源于UCB, UCB 是risc-v的发源地)中间的是Instruction Set Architecture , 指令集架构,我们正在学的risc-v正是指令集架构的一种,它们处于硬件与软件的接口、中间层。它们的上层是软件,核心就是OS (操作系统), 下层是硬件,我们将学习的CPU就是Datapath and Control (数据通路和控制器,也叫运算器和控制器),用绿色线条圈出。
以前我喜欢运算器的名字,具体设计CPU时,数据通路这个名字其实更贴切
基础知识
这部分能解释CPU的前世今生,主要在告诉你为什么,可以把这部分内容当成素养阅读,只是简单的几分钟阅读,能改变你对计算机的很多看法。没时间可以跳过这部分。
数字信号与数字电路
计算机的语言:在计算机中,只需要0与1就能表示一切数字、字符、图片等等信号。
计算机的函数:组合逻辑和时序逻辑是计算机的函数,输入01序列通过函数便能返回需要的信号
计算机的心跳:时钟信号是计算机的心跳,寄存器等时序逻辑的值都会在时钟的有效跳沿处更新
risc-v 是同步的架构,采用同一个时钟信号,而非异步(多个时钟信号)
开关
最早期的计算机是通过开关来得到0与1的值,得到计算机的语言。


在有电的情况下,开关打开,灯泡变暗,表示0,开关关闭,灯泡变亮,表示1.这里的灯泡并不是真的指计算机中用灯泡的亮与暗,这只是一种比喻,灯泡的亮表明的是计算机获取到了一个1信号,反之则获取到0信号。
通过开关的串并联,能实现简单的逻辑门电路,通过简单的逻辑门电路能构成 复杂的逻辑门电路,再通过复杂逻辑门电路就能实现组合逻辑和时序逻辑,得到计算机的函数。


在上面的图中,当A的值为1表示开关闭合。相应的非门、异或门等等都可以这样构建。
通过门电路能构建出相应的电路产生时钟信号,从而得到计算机的心跳,具体是通过那些门电路实现的与我们相关性不高,学习的意义也不大,我们只需要知道能实现即可,具体找电信、微电子的人🐶来做。
思考题
如何用与或非等简单的门电路(直接用门电路,不要用开关)实现一个一位加法器?如何在此基础上设计一个4位加法器?
半导体与晶体管
你想用开关来构建CPU吗?显然不太现实 ,虽然技术上maybe可行,但是我们有更优秀的方案
当半导体被发现以后,人们制作了晶体管(二极管、三级管等等都属于晶体管),我们不必再通过开关的开闭来控制通断了,比如我们可以通过集电极、基极、发射极的电压来实现电路通断。(这里记不太清了,模电的知识,可能有一点问题,但重在表达意思)


对于第一个图片,当G电压很低的时候电路关闭,当G电压很高的时候电路开启,通过控制G电压就可以轻松实现通断,从而能够方便替代最初的开关。第二个图恰好相反工作。
有兴趣的通过可以通过上面这两个器件实现与门、或门等基础门电路。
所以,你现在能明白为什么集成电路(集成的晶体管数目)的规模能影响计算机的计算性能了吗?
寄存器与时钟信号
寄存器是通过组合逻辑和时序逻辑构建的,这里省略它的构建原理。但是有一个非常重要的知识需要记住
寄存器能够存储值,放在寄存器中的值会保持不变,直到下一次时钟信号的有效跳沿来临,才会改变其内的值。
与之相对应的是门电路:门电路的输出会时时刻刻随着输入而改变,尽管会有延迟,但我们近似的认为它是瞬间改变的,所以门电路的输出并不是一个稳定的值,而是一个时时刻刻变化着的值
小结
在这一部分内容中,我们学习了如何利用一些器件(开关、晶体管)来表达0与1,来构建门电路,在后面的部分,我们将通过门电路,构建出整个CPU,相信我 ,这是学习计算机最辉煌的时刻之一。
构建数据通路(运算器)
R 型指令格式
R型指令的指令编码
| 7位操作码 | 源寄存器2 | 源寄存器1 | 3位操作码 | 目标寄存器 | 操作码 |
|---|---|---|---|---|---|
| funct 7 | rs2 | rs1 | funct 3 | rd | opcode 7 |
| inst[31:25] | inst[24:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
指令编码是什么?我们常说risc-v是32位指令格式,指的就是risc-v的每条指令都是32位的长度,每条指令都对应着唯一的32位长的01序列,换句话说,指令编码就是机器语言,从汇编通过指令的编码(将指令的表示用01序列来表示)就成为了机器语言。所以我们其实学了汇编只需要通过查表就可以写出机器语言🐶.
上面的inst[6:0]表示指令的第0位到指令的第6位属于操作码,以此类推。
例:
add x10, x11, x12
目标寄存器 rd ,在这里是x10, 所以rd的编码就是01010 (表示10). risc-v 只有32个寄存器,因此每个寄存器只需要5位就可以唯一确定这个寄存器。
源寄存器1: x11, 所以rs1 即 01011
源寄存器2:x12 ,所以rs2 即01100
接下来,通过查表,我们可以知道add指令的操作码
funct7: 0000000
funct3: 000
opcode : 0110011
于是这条指令的编码就是 0000000 01100 01011 000 01010 0110011
一个有用的tip是:将指令从左往右看到的寄存器 与 指令格式(编码)从右往左看的寄存器是对应的。比如rd 在指令中是x10,是左边第一个寄存器,相应的在指令编码中它是右边往左的第一个寄存器,后面的其他指令类型大多也支持这个tip.(除了S 型,它刚好相反)

R型指令包含哪些
只要是有三个寄存器的,长的像add指令的,都是R型指令,具体有算术运算,逻辑运算, 移位运算。因为R型指令只有寄存器(reg),所以叫R型指令
| + | - | & | | | ^ | << | >>> | >> |
|---|---|---|---|---|---|---|---|
| add | sub | and | or | xor | sll | sra | srl |
其他的如乘法运算,除法运算的等等也属于这一类,下面这张表非常完整的展示了指令格式。opcode都是一样的,因为它们都是R类型的指令,funct3与funct7(特别注意fun7的第二位)共同决定了它的功能是什么。
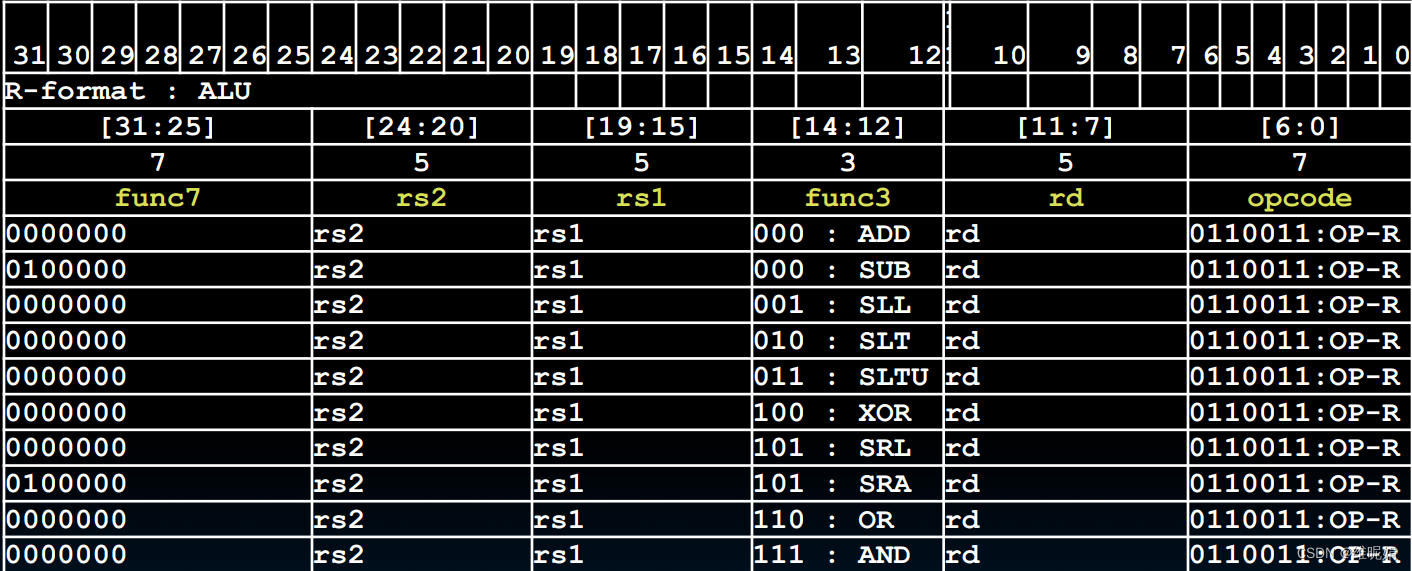
再往后看之前,先做一道题,做不出来可以看数电书或者其他
重复这个问题:如何用与或非等简单的门电路实现一个一位加法器?如何在此基础上设计一个4位加法器?
R 型数据通路
add
对于一条add 指令,我们需要做哪些事情呢?
- 从指令内存(专门存放指令的一块内存,剧透一下,后面我们会学习到,其实它是一块cache)中,把pc的值当成是内存地址,读取对应内存空间存储的指令, 也就是我们上面所讲的指令编码,也就是读出来32个01序列。当pc读完数据以后,pc就立即加4,(一条指令32位,就是4个字节,所以下一条指令的地址与当前指令地址相差4),从而指向下一条指令的地址。
- 解析这条指令,把这条指令中所蕴含的寄存器的信息,以及它所要完成的功能读出来(功能是通过控制信号体现出来的,后面会详细讲)
- 执行它的功能,对于一条add指令来说,这个功能是完成rs1寄存器和rs2寄存器的加法
- 将加法的结果写入到rd寄存器中
上面对应的四个步骤就分别是 取指(IF instruction fetch)、 译码 (ID instruction decode)、执行(EX execute) 、WB(write back)
将之分成4个阶段是与设计相关联的。下面将给出电路图,在这一环节,只有一个要求:了解、认识、熟悉、模仿它,等学完所有的数据通路,请尝试自己手绘出来所有的电路。
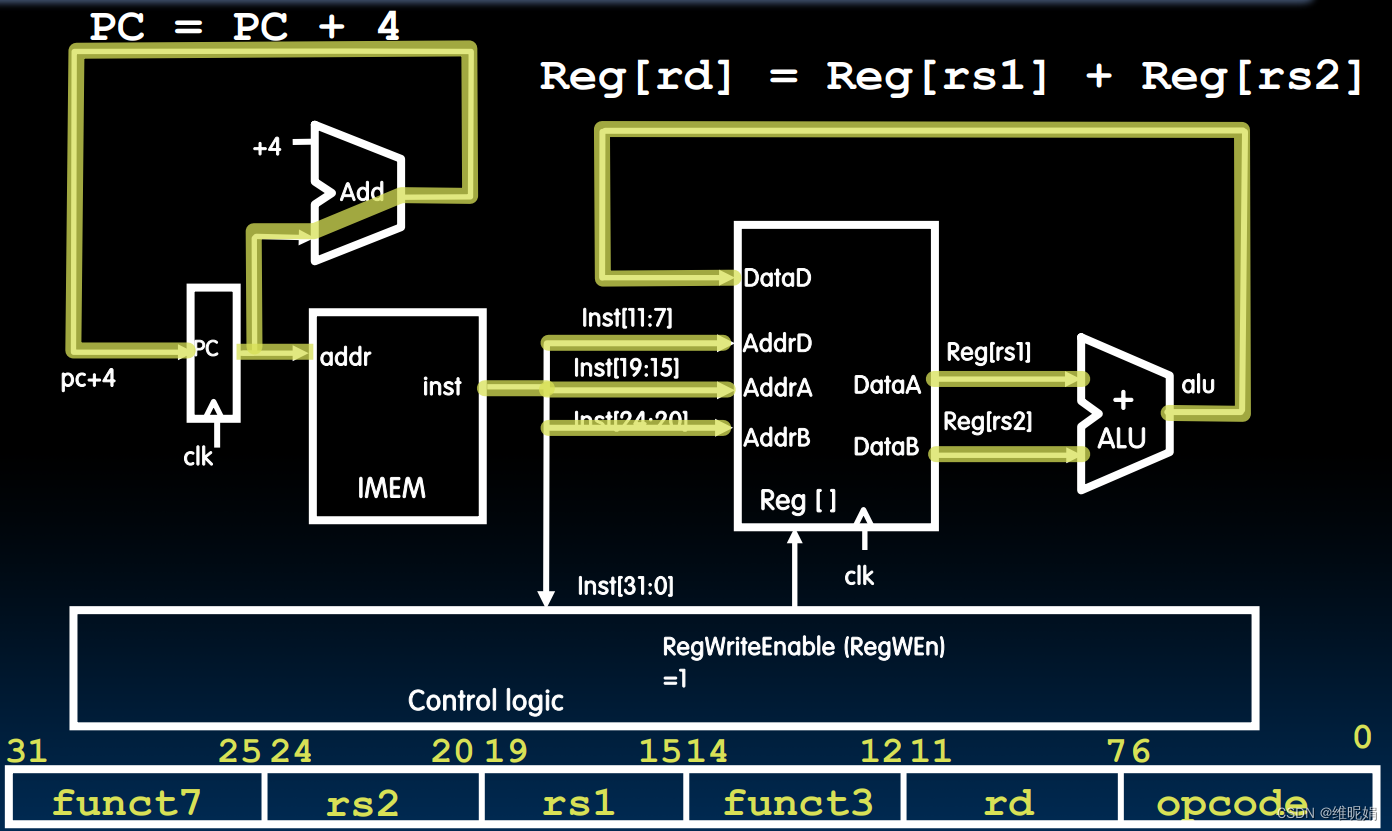
最下面是指令编码,右为低位,从0到31共32位, 上面就是电路图。其中control logic 是控制器,我们将用到它,但是后面才会讲如何设计它。最上面是数据通路,执行顺序为从左到右。
首先,时钟来到了上升沿(假设上升沿是有效跳沿)。
IF : 最左边,pc的值作为地址输入到IMEM的addr(内存地址端口),IMEM将对应的指令读出来,从inst端口出来。于此同时,pc的值会经过一个加法器与4相加,再将pc+4的值送回到pc中,注意,pc的值并不会在这个时候被更新,它是一个寄存器,将在下一个时钟上升沿到来的时候进行更新。IF完成。
ID : 往右,取出来的指令的第7-11位(就是rd),15-19位(就是rs1), 20-24 (rs2), 将被送入到寄存器堆(reg[])的AddrD、AddrA、AddrB端口,对应的就是rd,rs1,rs2.注意,risc-v设计的非常规整,后面的其他类型的指令的第一个源寄存器==如果存在==,就一定是15-19位,rs2和rd同理。寄存器堆就是一堆寄存器放的位置,它通过指令给的编号(AddA/AddB)找出对应的寄存器,并读出这两个寄存器的值,从DataA和DataB端口输出。而AddD现在还用不到。ID完成
EX : 往右,ALU(algorithm logisim unit 算术逻辑单元,就是用来执行算术逻辑运算的),在这个时候是一个加法器,将两个寄存器的值相加。EX完成
WB : 再往右,相加得到的结果输入到寄存器堆的DataD端口,表明这是将写入到rd寄存器中的数据。此时,寄存器堆通过之前获取到的AddD找到对应的寄存器,将DataD给这个寄存器,注意,此时并不会立刻更新,会在下一个时钟上升沿进行更新。另外值得注意的是,此时控制器(control logic)设置RegWEn为1,表示是否允许写入寄存器,设置为1表示写入,设置为0表示不允许写入,DataD的值将无法写入到寄存器中。WB完成
最后时钟再一次来到了上升沿,完成寄存器的更新,并重复执行上面的步骤。
sub
在add的基础上如何完成sub的功能
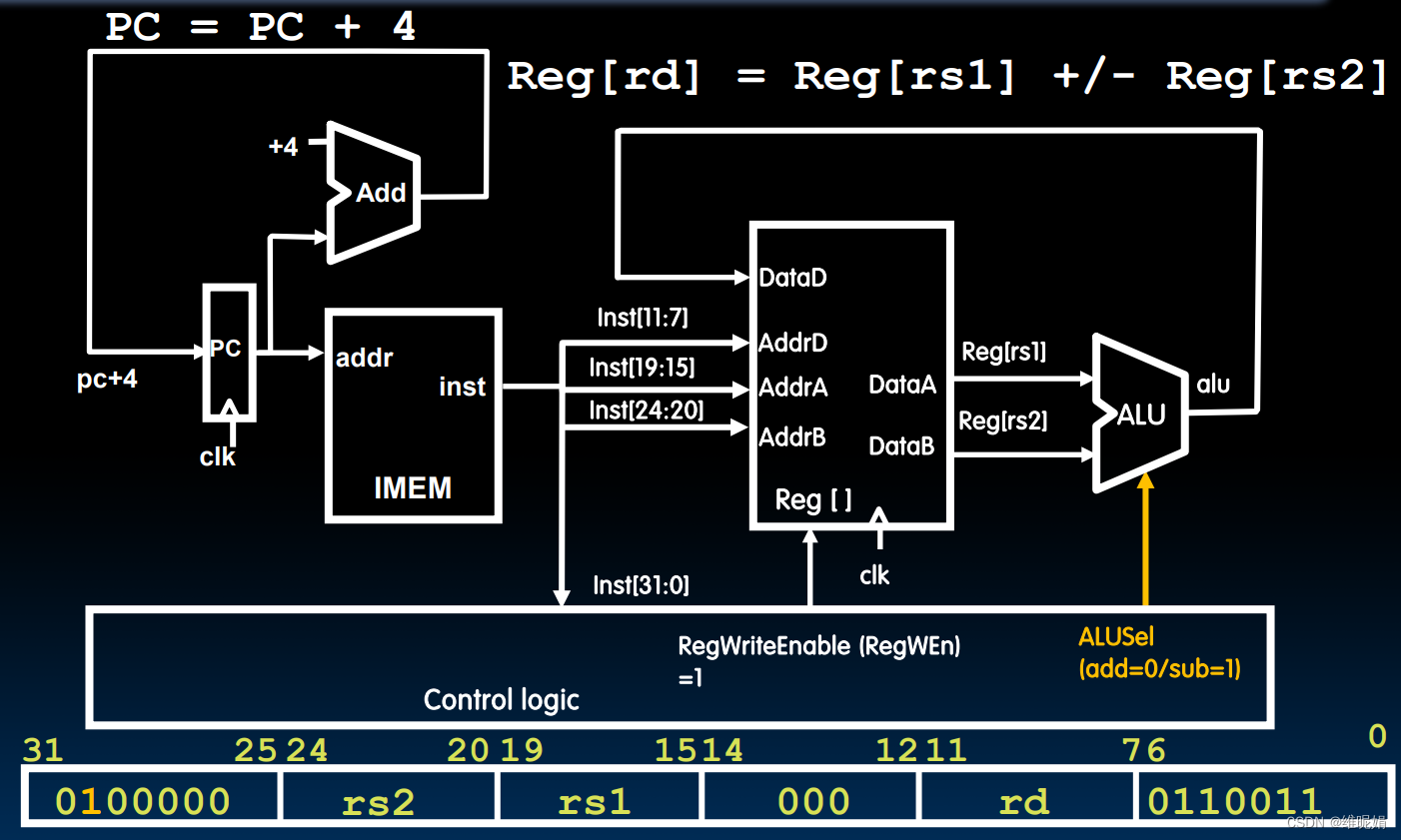
黄色的部分表示与上一张图片的区别,实际上只有三个区别。
第一个区别是: sub指令的编码与add指令的编码自然是不同的,它的第30位是1,而add是0
第二个区别是: 我们的ALU不再是一个简单的加法器了,它同时也能做减法运算
第三个区别是: 因为指令是不同的,当control logic 解析到sub指令时会告诉ALU去做减法运算,如何告诉呢?通过设置ALUSel (ALU select : select 是选择的意思)为1就表示做减法,为0就做加法。ALU通过读取ALUSel就能执行相应的功能。
其他算术逻辑功能
效仿sub指令的做法
- 扩展ALU的功能,让它能做相应的运算,本质上是增加了一些门电路组成的组合逻辑函数
- 每个功能都与一个独特的ALUSel 对应,当控制器解析完指令的时候就传递相应的控制信号给ALU。
I 型指令格式
I型指令的指令编码
| 立即数 | 源寄存器1 | 3位操作码 | 目标寄存器 | 操作码 |
|---|---|---|---|---|
| imm | rs1 | funct 3 | rd | opcode 7 |
| inst[31:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
addi x10, x11, 20
这条指令是一条I型指令,形如这样的指令都是I型指令。它与R型指令相比,少了一个源寄存器和func7,变成了相应的立即数(Imm),所以叫I型指令。为什么要去掉func7?如果不去掉func7,那么Imm只有5位的大小,最多能表示的数字是-16到15,这个范围太小了不够用,所以干脆去掉了func7,现在立即数有12位的大小,最多能表示 -2048 到2047个数字。基本上够用。对于更大的立即数,后面会继续讲的。
立即数的本质是什么?立即数本质上是编码在指令里面的01序列所对应的值。
例:
下面是对应的opcode 和func3, 求解上面那条指令的编码(2进制表示)

答案:
对于上面那条指令而言,
x10是目标寄存器: rd = 01010
x11是源寄存器1:rs1 = 01011
立即数是20: imm = 0000 0001 0100
查表得到 相应的
opcode : 0010011 fun3: 000
所以这条指令的编码是 000000010100 01011 000 01010 0010011
I 型指令包含哪些
形如 addi 指令的都是I型指令,或者说,将之前的R型指令只要稍微变形一下,就能得到对应的I型指令。具体的可以看刚刚的那张表。
我们接下来实现的是RV-32,也就是32位的操作系统或者说32位的地址空间的指令,相应的我们的寄存器的位数也是32位,对应到C语言就是对应的是int ,我们不实现long类型等64位,它们的原理是差不多的,学会一种很容易就迁移到另外一个,RV-32相对而言简单一点
RV-32 与 RV-64的区别在于:
- 前者的寄存器是32位的,后者是64位的
- 前者的地址空间是32位的,后者是64位的
为啥讲这些?看到上面的slli 和 srli 和 srai 指令
slli x10, x11, 20
看这条指令,它表示讲x11寄存器逻辑左移20位然后赋值给x10,如果寄存器只有32的话,我们至多左移0-31位,再高就没有意义了(再高的数字一般是通过模32得到真正的移位量),因此,我们的立即数实际上只需要5位就可以表示0-31的所有数字了,所以对于立即数移位操作而言,我们只需要5位立即数(shamt),多出来的7位我们用来做操作码了.
为啥操作码这么重要,而且正常情况下越多越好?
一条指令编码对应着一条具体的指令,而一个独特的操作码(opcode + func3 + func7)则对应着一类指令,比如都是addi 指令或者都是subi指令,只是立即数和寄存器可能有点区别而已。因此,当操作码越多,其实也就是表示着我们能进行的操作越多。
剧透🐶 后面的控制器实际上需要的就是操作码,而不是整个指令。因为它只要知道了需要执行什么操作进而就能分配出相应的控制信号来完成这些操作。
I 型数据通路
选择器

选择器,也叫多路复选器,有多个输入,在上图中有两个输入,分别是32位的A和32位的B,然后通过选择信号(select) ,当选择信号为0的时候选择第一个输入,当选择信号为1的时候选择第二个输入。
这里的位宽可以更改为64位或者其他任意你需要的位宽,唯一的限制是输入与输出的位宽必须是一致的。
当select 位宽为1时,最多从两个输入中选择一个到输出。位宽为2时,最多可以从4个输入中选一个输出。依此类推。
数据通路
下面是完整的数据通路(以addi 为例,其他情况同理可得)
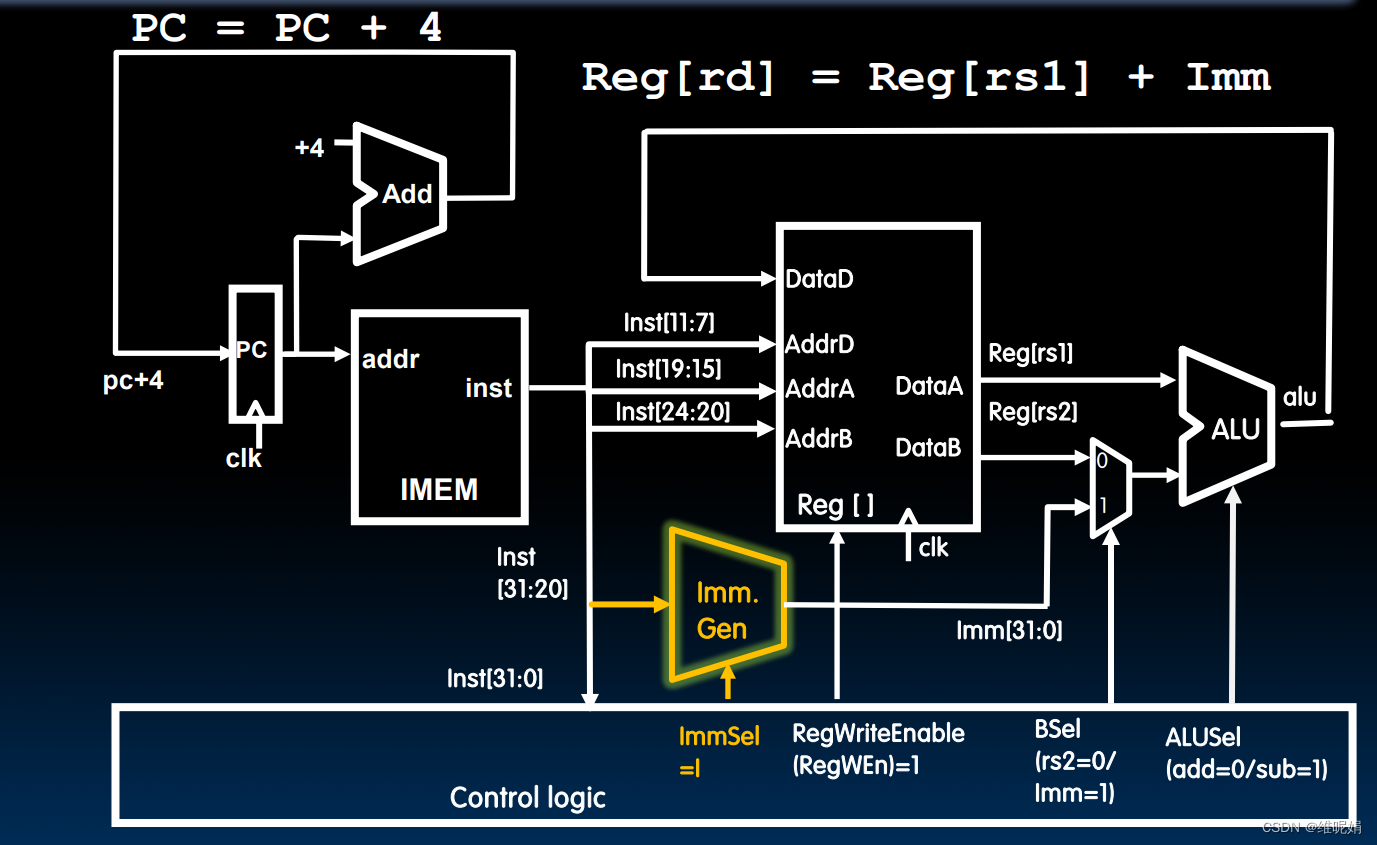
它与R型数据通路的区别主要在于多了一个 立即数生成器(Imm Gen) 和 一个由 BSel控制的选择器。
add x10, x11, x12
addi x10, x11, 12
这两条指令的唯一区别就是,原本的x11加x12变成了 x11加 12. 所以只需要更改加法器的输入就可以了。
立即数的输入是指令的20到31位,经过立即数生成单元进行符号扩展到32位,输入到选择器中。当这是一条I型指令的时候,控制器就会发送Bsel = 1信息给选择器,选择器从而选择立即数作为ALU的输入。同时因为这是一条addi指令,所以ALUSel 被设置为0.
立即数生成单元:在当前情况下只是简单的进行符号扩展,但实际上,它后面会逐步完善功能。我们对它的最好理解方式就是:给它指令,它就能给你正确的立即数。它的具体实现是通过符号扩展器和拼接器等门电路完成的,就是一些简单的门电路而已。动手设计时便知道。
ImmSel 控制信号:后续不同的指令的立即数的编码位置是不一样的,所以ImmGen 能根据不同的Immsel实现不同的立即数拼接扩展等操作。目前我们只学了一种立即数格式,这里的的Immsel设置为1,无需记忆。
实现load指令
lw x10, 20(x11)
// 事实上,上面的这种写法等价于下面的这种写法
lw x10, x11, 20
load指令格式
上面的指令格式是否非常眼熟?仔细想想, 没错,它就是I型指令格式,所以load指令没有自己独特的指令格式,它的指令格式就是I型。
| 立即数 | 源寄存器1 | 3位操作码 | 目标寄存器 | 操作码 |
|---|---|---|---|---|
| imm | rs1 | funct 3 | rd | opcode 7 |
| inst[31:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
对应的指令是: lb, lh, lw, ld (RV-32中并没有这条指令,double word 双子是64位,RV-32不支持,但是RV-64支持), 下图是完整的load指令集
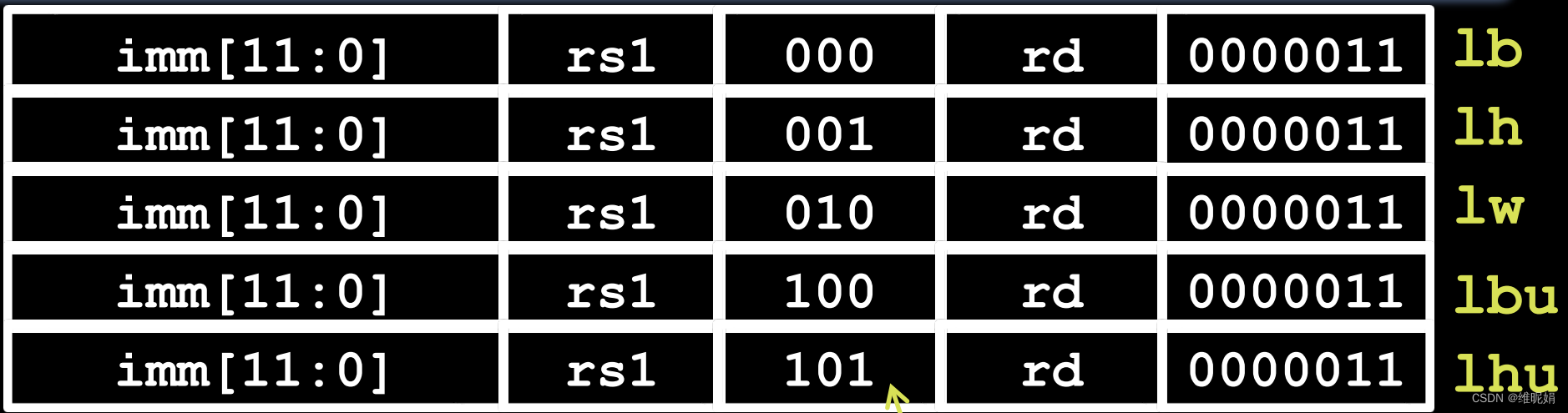
load 的数据通路
我们将在I 型指令的基础上扩展数据通路。

lw x10, 20(x11)
上面这条指令的含义是将x11和20的值相加,把相加后的结果作为地址访问内存,内存对应位置存放的数据写入x10寄存器中。
控制信号的设置
所以在上面的这个数据通路中,我们需要设置 ImmSel 为 I 型指令的立即数生成方式(假设为1,这个其实是由我们自己决定的,后面控制器设计时继续谈),因为我们要将返回结果写入rd寄存器中去, 所以我们要设置RegWriteEnable 为1 ,表示我们能够写入rd寄存器。BSel 设置为1, 因为我们相加的时rs1和立即数,而非rs1和rs2,事实上,此时我们也没有rs2。ALUSel 设置为 add对应的选择信号。MemRW设置为1, 表示我们要访问内存。访问内存所得到的数据从DataR端口出来,注意到此时有一个选择器,如果当前指令是I 型指令或者R 型指令,我们会设置WBSel 为1, 也就是alu的输出直接写入到rd寄存器中。而对于load指令,我们会设置WBSel为0, 从而将内存中的数据写入到rd寄存器中。
写入到内存的过程我们称之为MEM (memory ),目前我们就学习了完整的CPU执行的五个过程, 分别是 IF, ID, EX, MEM, WB. 取指, 译码, 执行, 访存, 回写。
DMEM是啥?
在现代的处理器中,指令(instruction)和数据(data)虽然都存放到内存中,但是为了方便处理器读取数据和指令,分别设计了指令内存IMEM 和数据内存 DMEM , (它们实际上是cache)。在电路板中,它们可能一个在CPU的左上方,一个在CPU的左下方,我只是举个例子,希望你明白。
S 型指令格式
S 型指令的指令编码
sw x10, 10(x11)
# 或者等价的
sw x10, x11, 10
// x11 是 rs1 , x10 是 rs2
这条指令虽然长得特别像I 型指令和load 指令,但是,它的意思和那两种指令的意思截然不同。这也决定了它们的编码方式也截然不同
| 立即数 | 源寄存器2 | 源寄存器1 | 3位操作码 | 立即数 | 操作码 |
|---|---|---|---|---|---|
| imm[11:5] | rs2 | rs1 | funct 3 | imm[4:0] | opcode 7 |
| inst[31:25] | inst[24:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
S型的编码比较特殊,首先,对于上面的指令而言, rs1 是指x11,也就是基址寄存器。rs2是x10,也就是写入的数据。rd的位置上是立即数的低位部分。区分rs1和rs2是为了后面设计数据通路时要用到。这里的imm 也常成为offset(偏移量)。
这条指令的意思是将 x11 加 10 的值作为地址,将x10的值写入到这个地址对应的内存中去。所以我们的目的并不是寄存器,而是内存,我们并没有rd, 所以原本属于rd的位置便空下来了, 我们因此存放立即数的低5位。
其次,对于所有指令而言,只要有源寄存器,就一定放在rs1和rs2的位置,只要有目的寄存器,就一定放在inst[11:7]的位置,如果没有,就用来存放其他的数据。
因为这样的设计我们每次就只需要去相同的位置就能读到我们所需要的寄存器了, 而当我们不需要使用它们的时候,只需要简单的改变控制信号,不去选择它们对应的输出就可以了。
指令的编码对于我们来说可能并不友好,因为它是从处理器的角度考虑的,这样能尽量减少不必要的门电路的数量, 从而加快速度,简单源于规整。
S型指令的数据通路
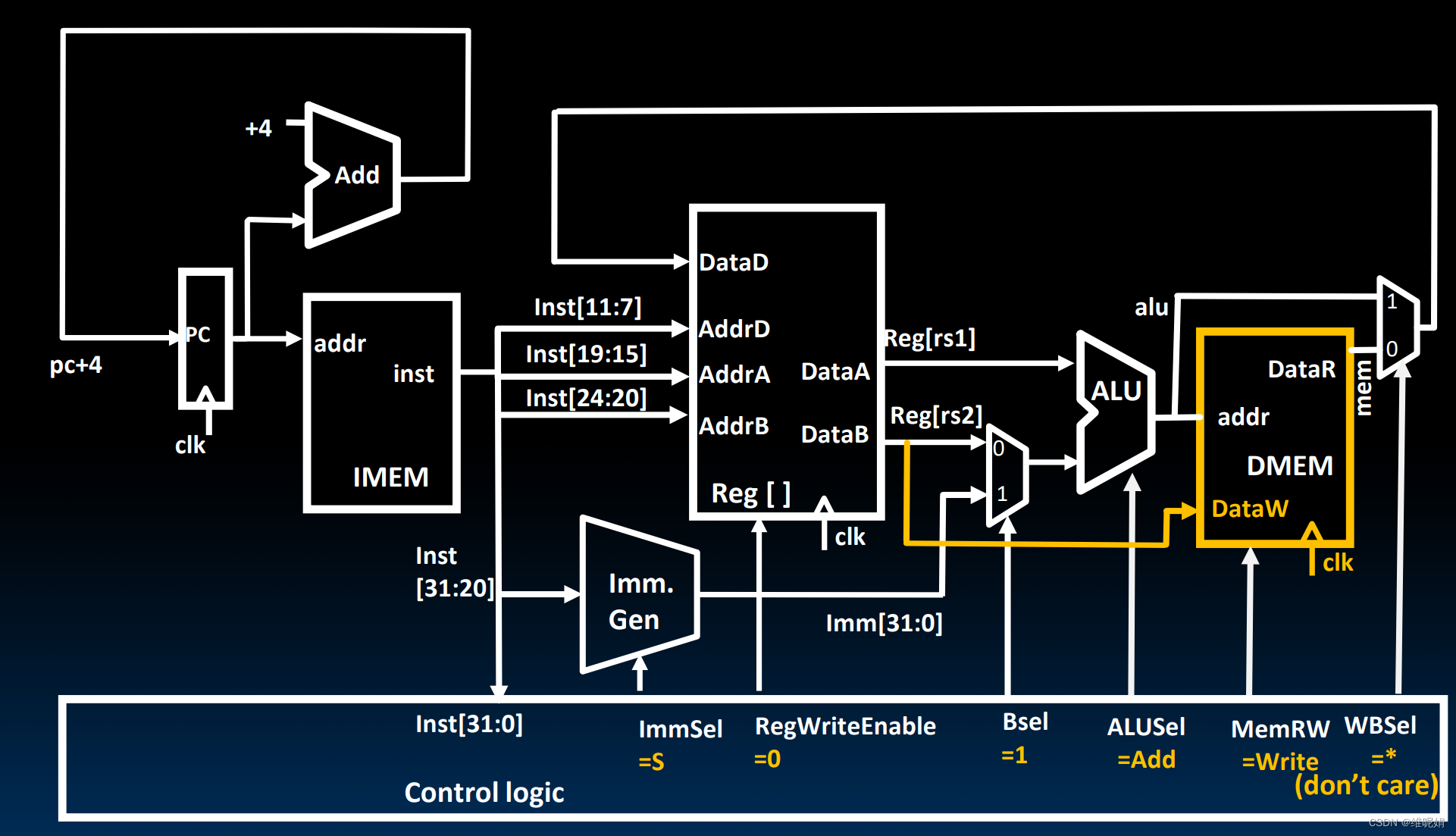
(上面这张图有问题, 你发现了没有?后面会讲)
这里为了加深对CPU执行五过程的理解,先做一道题
请写出CPU 的完整执行过程, 从clk 上升沿(假设 上升沿是有效跳沿)到来开始
答案:
首先,时钟来到了上升沿。
IF : 最左边,pc的值作为地址输入到IMEM的addr(内存地址端口),IMEM将对应的指令读出来,从inst端口出来。于此同时,pc的值会经过一个加法器与4相加,再将pc+4的值送回到pc中,注意,pc的值并不会在这个时候被更新,它是一个寄存器,将在下一个时钟上升沿到来的时候进行更新。IF完成。
ID : 往右,取出来的指令的第7-11位(对应rd),15-19位(就是rs1), 20-24 (rs2), 将被送入到寄存器堆(reg[])的AddrD、AddrA、AddrB端口,对应的就是rd,rs1,rs2. 于此同时,ImmSel 被设置为S(这个最后也是一个01序列的编码), 表示生成S型的立即数, 于是inst[11:7]和inst[31: 25] 经过ImmGen 被拼接到一起并进行符号扩展到32位。 ID完成
注意:虽然S型指令并没有rd, 但是它还是会读取这一部分数据, 显然这一部分数据是garbege, 我们只需要将RegWriteEnable设置为0表示不允许写入, 所以无论读取或者不读取,其实都没有作用,后面在内存也有类似的操作,理念就是,我可以读取你的值, 但只要我不用你的值,我通过选择器选别人,或者我通过 控制信号关闭了你,那么你的值对我就没有任何副作用。😸
EX : 往右,我们的两个加法的输入是rs1 和 imm , 因此我们的BSel 选择为1, 因为我们要将基址寄存器的值加上立即数作为地址, 所以此时的ALUSel = add, 起一个加法器的功能,将两个输入的值相加。EX完成
MEM: ALU的输出作为地址输入到 addr 中, dataW端口表示写入内存中的数据, 也就是rs2所对应的值, 于是我们在它们之间连电路线。MemRW控制信号表示写入内存还是读取内存,此时设置为Write, 因为我们完成的是写入内存的操作。 值得注意的是, 此时内存中的数据并不会立刻更新, 而是会在下一个时钟周期的上升沿来临时才完成更新的操作。MEM完成
WB : 再往右,我们需要将返回值写回到返回值寄存器吗?我们不需要, 因此, 我们的RegWriteEnable 设置为0, 表示无法写入寄存器, 所以我们的WBSel可以随意选择, 毕竟无论如何它们也不会起作用。WB完成
最后时钟再一次来到了上升沿,完成寄存器的更新,并开始执行下一条指令。
B型指令格式
旧版本中叫SB型
beq x8, x9, Label
bge x8, x9, Label
这是两条典型的B型指令, 可以看出有两个源寄存器, 没有目的寄存器, 有一个Label , 实质上Label 会被编译器解释为Imm, 也叫Offset 偏移量, 而且显然这是PC相对寻址的, 假如实际的偏移是8个字节, 那么我们的Offset的值是4即可, 因为PC相对寻址会默认给Offset乘以2.(我们将在硬件层面看到事实上这一点是如何实现的)
指令的编码
| 立即数 | 源寄存器2 | 源寄存器1 | 3位操作码 | 立即数 | 操作码 |
|---|---|---|---|---|---|
| imm[12, 10:5] | rs2 | rs1 | funct 3 | imm[4:1, 11] | opcode 7 |
| inst[31:25] | inst[24:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
12位的立即数被分成了4段, 貌似不可思议以及难以想象会有这么难看的指令格式。听我解释解释这种指令格式对处理器的友好之处。
首先, 我们发现以往的立即数都是[11:0]的12位, 但是这个是[12:1], 那个Imm[0]不见了。为什么?因为PC相对寻址Offset都会默认乘以2, 也就是说每个立即数的最后一位都是0, 既然大家都是一样的, 就没必要拿出一位空间 来存储这个0了, 于是Imm[0]会被默认设置为0, 因此, 多的一位存储空间就用来放Imm[12]了。
imm[4:1]的放法是为了和之前在同一个位置, Imm[10:5]同理, 原先Imm[0]的位置由Imm[11]替代, 因为Imm[12]是最高位, 是符号位, 为了方便处理器每次都在同一个地方找到符号位, 所以Imm[12]必须放最前面, 所以只能将Imm[11]放在Imm[0]的位置上了
指令经过立即数生成单元ImmGen,根据相应的控制信号, 最终会生成正确的立即数 。imm[0]就是在立即数生成单元中设置为0的, 所以ImmGen之后的立即数就是最后我们真正需要的立即数。
B型指令的数据通路
beq x8, x9, Label
# 经过编译器处理以后,会变成类似这样的格式.
beq x8, x9, 10
这条语句的作用是如果 x8 等于 x9 , 那么pc 就跳转到pc + 10*2 的位置上去。
简单的分析我们就可以知道, 我们将不会对内存操作, 也不会回写到rd寄存器中去, 它的操作对象是pc。
数据通路
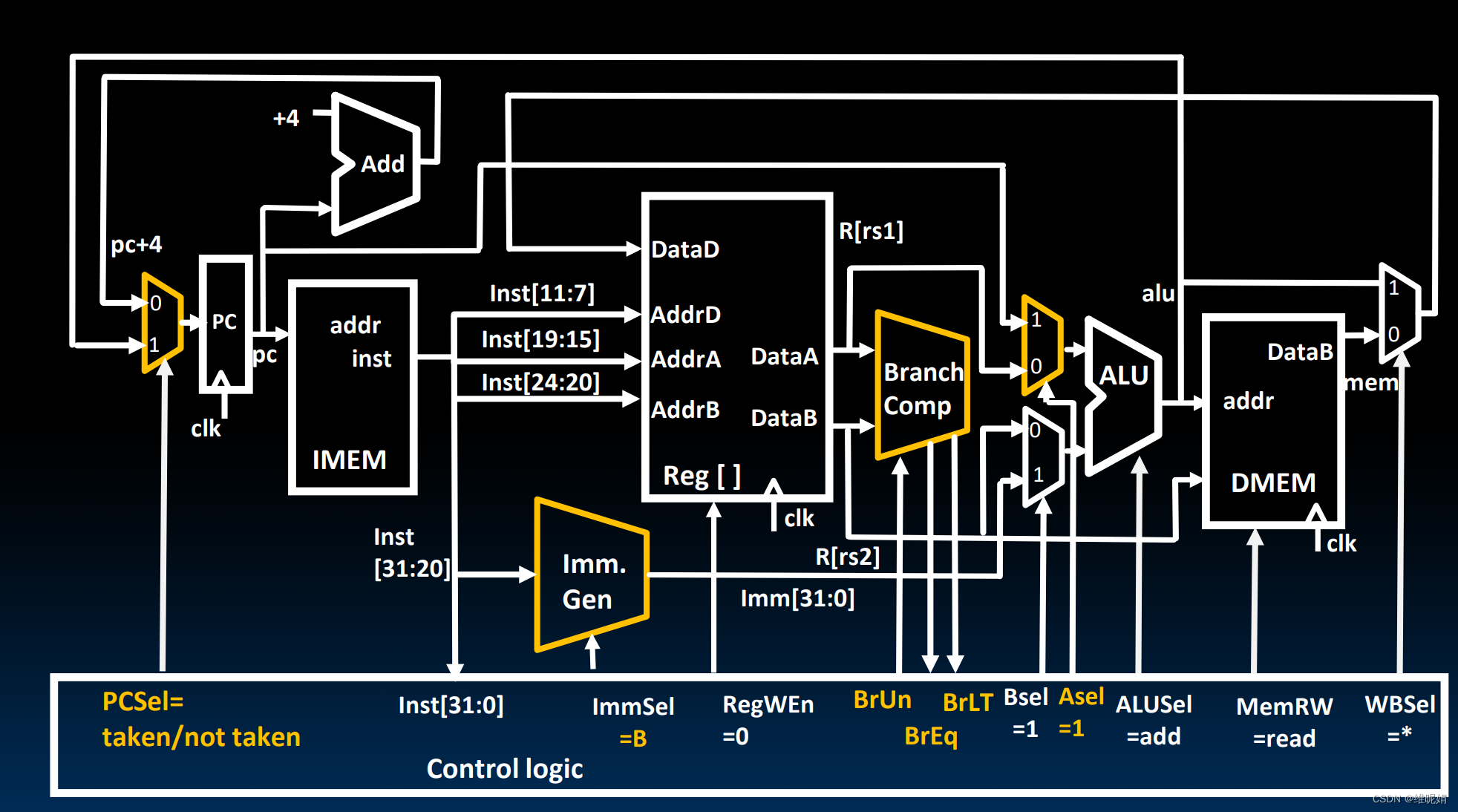
这里的几个主要的变化如下:
-
ImmGen的控制信号ImmSel设置为B型
-
多了一个比较器,用来比较 dataA和dataB的大小,
控制信号为 BrUn:是否是无符号数比较大小
输出信号为 BrLT: dataA是否小于dataB
BrEq: dataA等于小于dataB -
ALU前方多了一个选择器, 为了计算 pc + Imm 的值, 当Bsel为1, ASel 为1的时候, 选择PC和Imm 进行加法, 并将结果送到PC前方的选择器中。
-
PC前方多了一个选择器, PCSel控制信号选择采取哪个输入, 事实上, PCSel由指令的格式以及BrLT和BrEq的值决定。
以Beq为例
P
C
=
{
P
C
+
4
,
r
s
1
!
=
r
s
2
P
C
+
I
m
m
,
r
s
1
=
r
s
2
PC = \begin{cases} PC+4,& rs1 != rs2 \\ PC + Imm , & rs1 = rs2 \end{cases}
PC={PC+4,PC+Imm,rs1!=rs2rs1=rs2
任务1: 分析5个过程分别干了啥, 并且分析应该采用什么样的控制信号。自行和上图比对与思考
任务2: MemRW只有read和write两种状态, 你能明白为什么这里选用read的原因吗?
实现jalr 指令
jalr ra, imm(x10)
# 等价于下面这条语句
jalr ra, x10, imm
问题: 已知这个指令可以用之前的指令格式实现, 你觉得用哪种指令格式最合适
答案
I 型指令, 它们都有rs1和 rd ,第一个寄存器是rd, 第二个寄存器是rs1, imm的生成方式也是一样的。
| 立即数 | 源寄存器1 | 3位操作码 | 目标寄存器 | 操作码 |
|---|---|---|---|---|
| imm | rs1 | funct 3 | rd | opcode 7 |
| inst[31:20] | inst[19:15] | inst[14:12] | inst[11:7] | inst[6:0] |
数据通路
以上面的指令为例, 作用是, pc 跳转到 imm + x10的地方(本质是将imm+ x10 的值赋给pc), 因为这是绝对寻址方式, 所以不用乘2。同时将返回地址, 也就是pc + 4, 写入到rd寄存器中去。
PC相对是Imm + pc, 需要对原来的立即数乘2, 绝对寻址方式是imm + reg, 不能乘2
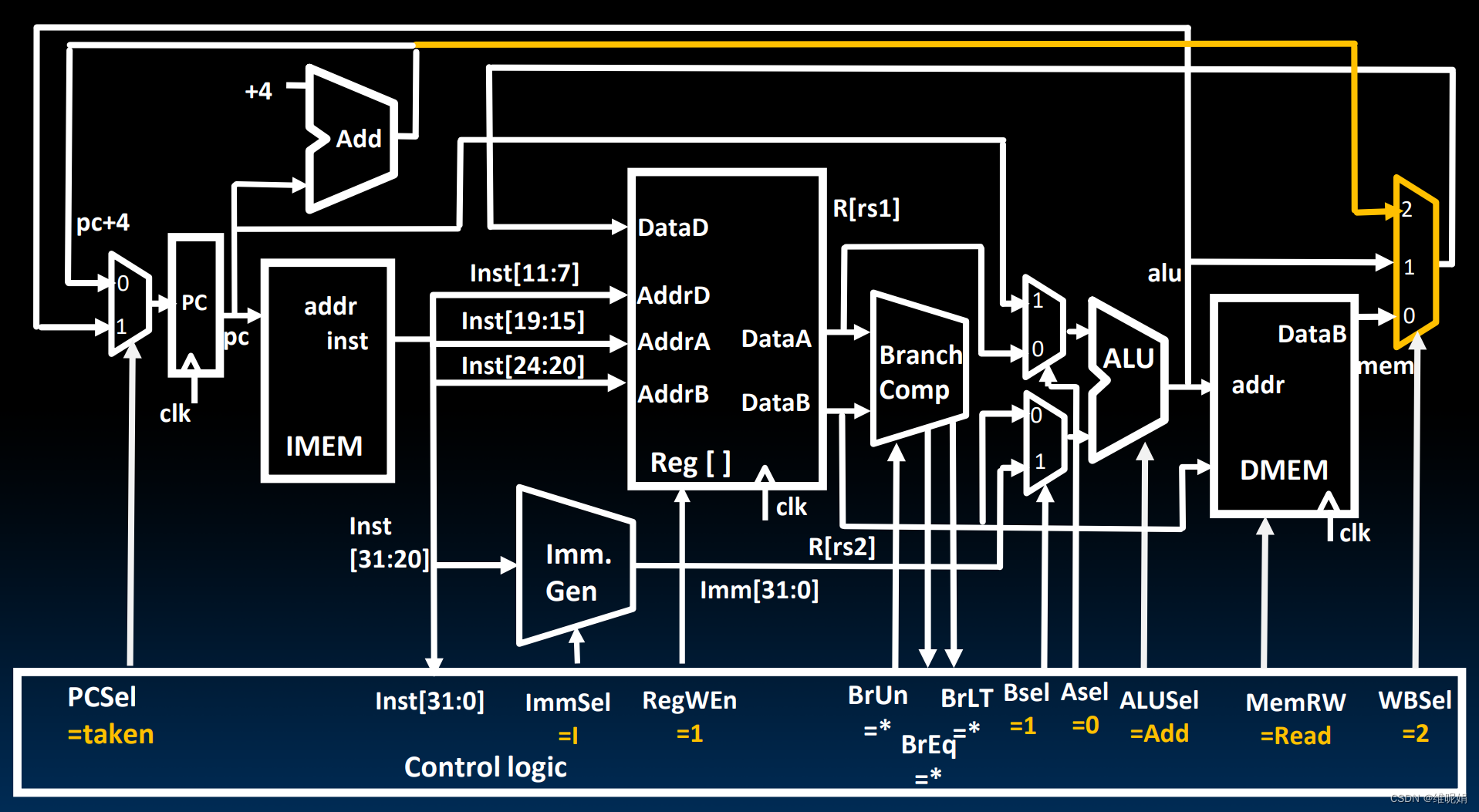
IF: 根据pc的当前值读取到指令, 并同时将pc+4, 发送到选择器, 因为是jalr指令,所以一定PCSel一定是1 (taken).
ID: 根据指令读取相应的寄存器, 生成相应的立即数, 其中ImmSel 选I 型。 我们并不关心分支比较的结果, 也不关心它的输入信号。 它们并不会有任何副作用。
EX: Asel : 0 选择dataA, Bsel : 1, 选择Imm, ALU选择Add, 从而得到 reg+imm的值, 并将这个值发送给PC
MEM: 不写内存, 因而MemRW选择Read,(Read没有任何副作用, 但是Write 会写入内存, 所以不用Write) , 事实上这一阶段啥也不干
WBSel: 我们需要将pc+4, 也就是返回地址写回到rd寄存器中去, 因此选择器又加入了一个输入, 显然, 我们的WBSel选择 2。
J 型指令格式
旧版本叫UJ型
jal x0, Label
# 等价于下面的指令
jal x0, Offset
在这个指令中, 我们只有一个目的寄存器和一个立即数, 没有源寄存器, 因此, 多出来的位置可以给Imm. 事实上,我们给Imm的位置不仅仅是这些。
| 立即数 | 目标寄存器 | 操作码 |
|---|---|---|
| imm[20, 10:1, 11, 19:12] | rd | opcode 7 |
| inst[31:12] | inst[11:7] | inst[6:0] |
这个立即数的格式我并不想做任何解释, 我们无需记忆。 我们只需要知道这是一个20位的大常数即可, 同样的, 因为这条指令也是PC相关的, 所以Imm[0]也是默认被设置为了0, 指令中无需保存。
为了方便表达, 从现在开始,用offset表示修正之前的立即数, 用Imm表示修正之后的立即数
J型指令的数据通路
我们需要做的事情是
- pc 跳转到 pc + 2 * offset的位置,即pc + Imm
- 原先的pc + 4写入到 x0 寄存器中(也可以是其他寄存器)
在看结果之前, 我们先自己想想需要做哪些改变
- 立即数生成方式要改为J 型
- pc+4要在WB阶段写入到rd寄存器中去
- pc的值要改变为 pc + Imm
数据通路
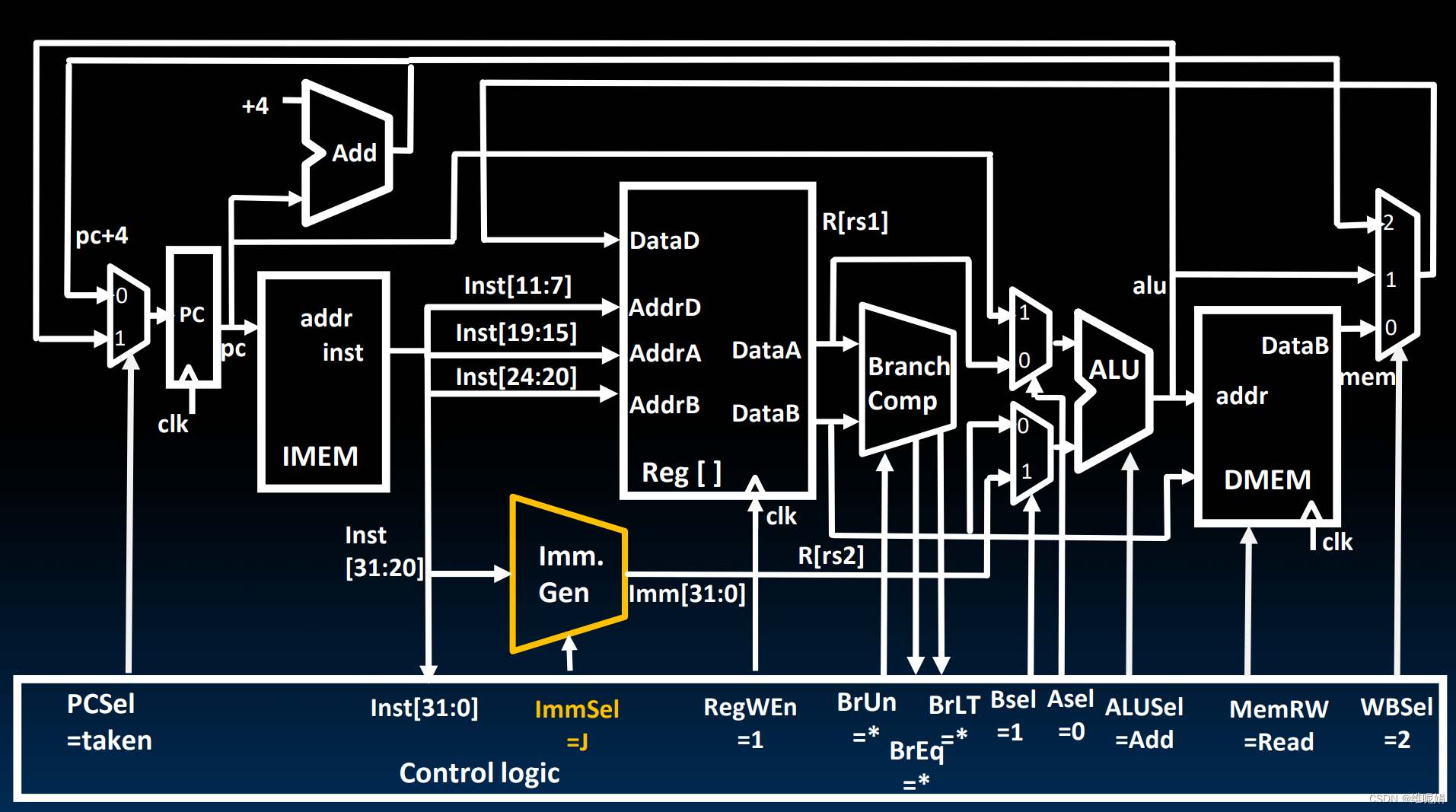
(这张图片的ASel 应该改为1, ImmGen前面的inst[31:20]都是老错误了, 我就不说了),具体分析交给你自己了。
U型指令格式
指令
lui x10, 100000 # x10 的高20位被赋值为了 100000
auipc x10, 100000 # 将pc的高20位加上100000,然后把结果赋值给x10
| 立即数 | 目标寄存器 | 操作码 |
|---|---|---|
| imm[31:12] | rd | opcode 7 |
| inst[31:12] | inst[11:7] | inst[6:0] |
这个指令格式挺好看的。注意它的立即数不是一般的立即数,而是高20位是inst[31:12], 低20位是0的立即数。
U型指令的数据通路
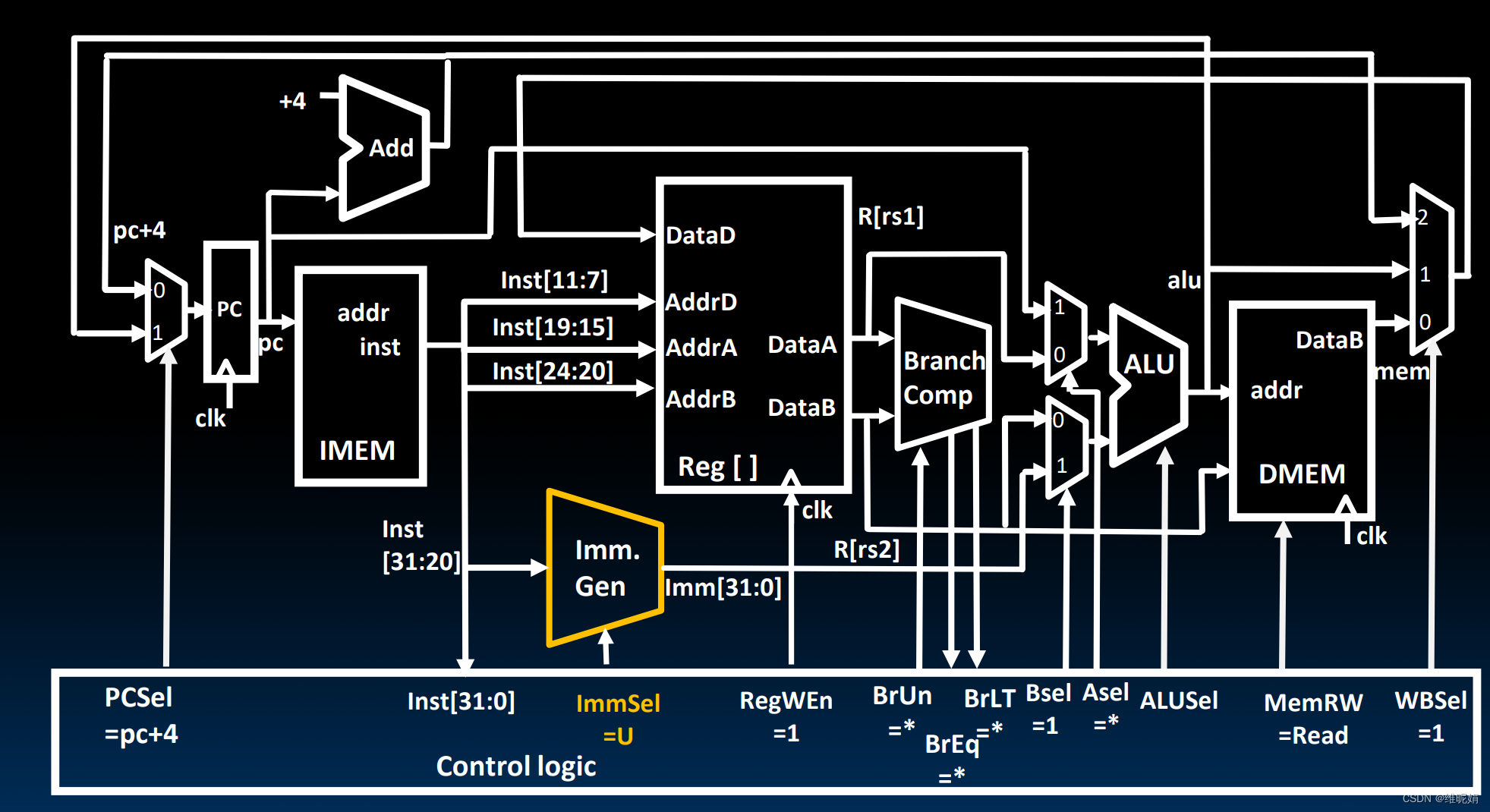
给你一张图, 我觉得够了 🐶。
构建控制器
我们的控制器的输入是32位指令, 事实上, 我们并不需要完整的32位指令, 我们只需要opcode 和 func3 以及 func7 对应的字段即可, 我们的输出是我们在数据通路中的那些控制信号。
输入是17位长度, 这个长度还是大了,我们可以继续简化, 这样能帮助我们后面的化简, 因为opcode 最后几位是用来标识RV-32和RV-64和RV-16的, 因为我们设计的都是RV-32, 所以最后两位一定是11, 可以去掉。 我们还需要处理15位的输入。
通过观察, 可以发现R型指令的opcode 都是0110011, S型指令的opcode都是0100011, SB型指令都是1100111, U型都是 0110111, J 型都是1101111。 I 型指令可以分成三个部分, 分别是load类型, 普通I类型, jalr类型, 归纳起来, 可以得到如下的结论
| 指令类型 | opcode |
|---|---|
| R 型 | 0110011 |
| S型 | 0100011 |
| B型 | 1100111 |
| U型 | 0110111 |
| I型 | 0010011 |
| load型 | 0000011 |
| jalr型 | 1100111 |
去掉最后的两个1, 也就是5位的输入, 便决定了对应的大类型。
当我们根据opcode 锁定了指令的大类型之后, 我们还需要进一步确定它所对应的小类型。
对于绝大多数指令, 我们只需要再根据funct3就能够确定它的小类型了, 而 add 与sub, srli 和srai这两对指令我们还需要根据func7的一位来确定它们的类型。
自此, 我们便掌握了理论上的控制器的构建。
题目
题目, 假设你是一个控制器, 对于指令0000000 01100 01011 000 01010 0010011, 你将把下列控制信号如何设置?
| PCSel | ImmSel | RegWEn | BrUn | BSel | ASel | AlUSel | MemRW | WBSel |
|---|---|---|---|---|---|---|---|---|
答案:
根据最后7位, opcode = 0010011, 这是一个I型指令,再根据func3 = 000, 这是一个addi指令, 此时已经能够确定无需再看func7了。 所以它对应的功能是
| PCSel | ImmSel | RegWEn | BrUn | BSel | ASel | AlUSel | MemRW | WBSel |
|---|---|---|---|---|---|---|---|---|
| untaken | I | 1 | * | 0 | 0 | add | read | 1 |
值得注意的是这里的untaken 和 add 和 read等都需要进一步编码, 我相信你会的。
最后, 其实控制器也可以使用ROM(只读存储器)来实现, 也非常方便, 容易扩展, 这里不做更多的介绍了
总结
我们已经完成了非常重要的环节, CPU在我们眼中不再是一个神秘莫测的事物了, 尽管它可能在电路板上像是一个杰出的艺术品,像具有魔力的潘多拉魔盒, 能够完成整个计算机的运算功能, 但事实上, 它们的工作原理和我们讲的相差无几。
接下来:
实践设计CPU
我们在理论上实现了一个CPU, 是的, 我们并没有具体的用数字逻辑和门电路来构建它们, 寄存器堆究竟是怎样的, 内存又是如何读取的,ImmGen、ALU、 Branch Comp、控制器它们具体实现是什么样子的?未完待续。
流水线CPU
当今世界上的处理器都是流水线处理器, 它们是更现代化的产物, 现在躺在每个人电脑中的CPU都是用流水线的架构设计出来的。 它将是我们下一步的主题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









