







作者:困了电视剧
专栏:《JavaSE语法与底层详解》
文章分布:这是一篇关于Java数组的博客,在这篇博客中我会讲解Java中数组的详细知识,包括数组在内存中的构造方式,数组名的本质等,如果对你有帮助,可以订阅我的专栏,我会在未来更新出更多有价值的文章。

目录
大家好!这里是困了电视剧,欢迎来到我的博客,今天我将带大家学习Java中数组的知识,在这篇博客中https://blog.csdn.net/m0_62815572/article/details/127841022,我详细地介绍了C语言对数组的处理方式,毕竟C生万物,Java对数组的处理和C语言具有一定的相似性,可以通过这篇博客进行对比学习以加深对知识的理解。
数组的基本概念
什么是数组
数组:可以看成是相同类型元素的一个集合。在内存中是一段连续的空间。在java中,包含6个整形类型元素的数组,就相当于连在一起的6个位置
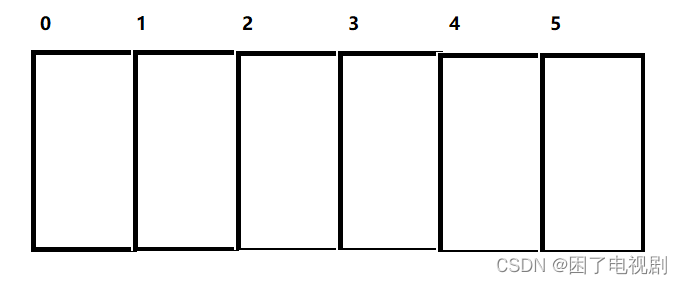
我们可以看到:1. 数组中存放的元素其类型相同
2. 数组的空间是连在一起的
3. 每个空间有自己的编号,起始位置的编号为0,即数组的下标。
数组的创建和初始化
数组的创建
![]()
其中T:表示数组中存放元素的类型 ,T[]:表示数组的类型 ,N:表示数组的长度。
动态初始化
动态初始化:在创建数组时,直接指定数组中元素的个数。
![]()
静态初始化
静态初始化:在创建数组时不直接指定数据元素个数,而直接将具体的数据内容进行指定。
语法格式: T[] 数组名称 = {data1, data2, data3, ..., datan};

注意
静态初始化虽然没有指定数组的长度,编译器在编译时会根据{}中元素个数来确定数组的长度。
静态初始化时, {}中数据类型必须与[]前数据类型一致。
静态初始化可以简写,省去后面的new T[]。

静态和动态初始化也可以分为两步,但是省略格式不可以。
int[] array1;
array1 = new int[10];
int[] array2;
array2 = new int[]{10, 20, 30};
// 注意省略格式不可以拆分, 否则编译失败
// int[] array3;
// array3 = {1, 2, 3};如果没有对数组进行初始化,数组中元素有其默认值
如果数组中存储元素类型为基类类型,默认值为基类类型对应的默认值,比如:
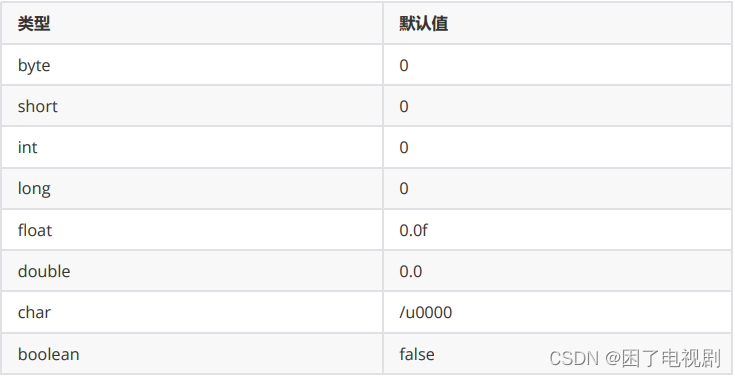
如果数组中存储元素类型为引用类型,默认值为null。
数组是引用类型
初始JVM的内存分布
内存是一段连续的存储空间,主要用来存储程序运行时数据的。比如:
1. 程序运行时代码需要加载到内存
2. 程序运行产生的中间数据要存放在内存
3. 程序中的常量也要保存
4. 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
因此JVM也对所使用的内存按照功能的不同进行了划分:
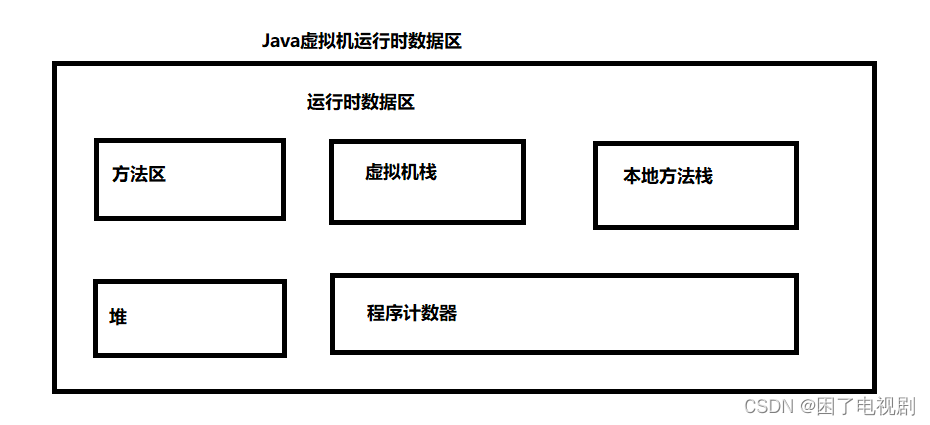
其中, 方法区和堆是由所有线程共享的数据区,而其他三个区是线程隔离的数据区
程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址
虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含 有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一 些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似. 只不过保存的内容是Native方法的局 部变量. 在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的
堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2, 3} ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销 毁。
方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数 据. 方法编译出的的字节码就是保存在这个区域
C语言也同样对内存进行了划分,详情可以参考一下我的这篇博客,里面有提及:
https://blog.csdn.net/m0_62815572/article/details/127484662
基本类型变量与引用类型变量的区别
基本数据类型创建的变量,称为基本变量,该变量空间中直接存放的是其所对应的值;
而引用数据类型创建的变量,一般称为对象的引用,其空间中存储的是对象所在空间的地址。
public static void main(String[] args) {
int a=10;
int b=20;
int[] arr=new int[5];
} 其在内存中的分布如下图所示,arr在堆中存储的可以简单理解为是arr的首元素的地址,指向的是其在堆中开辟的一片空间。
从上图可以看到,引用变量并不直接存储对象本身,可以简单理解成存储的是对象在堆中空间的起始地址。通过该 地址,引用变量便可以去操作对象。有点类似C语言中的指针,但是Java中引用要比指针的操作更简单。
二维数组
C语言说二维数组是特殊的一维数组,这句话在Java中诠释的非常好。当我们在Java中定义一个二维数组的时候,虚拟机会在栈上创建一个引用类型,这个引用类型指向了堆中开辟的一段空间的首元素的位置,这段空间的大小取决于行数,每一个空间里面放的仍然是一个地址,这些地址指向堆中开辟的其他连续的空间,这个空间大小取决于列数,举个栗子:
public static void main(String[] args) {
int[][] arr=new int[3][3];
}这段代码在空间中的分布为:
既然知道了内存分布,那我们就不得不讨论一个老生常谈的问题了——这个二维数组在初始化时是否可以省略行或列?
先说结论,可以省略列但不能省略行:
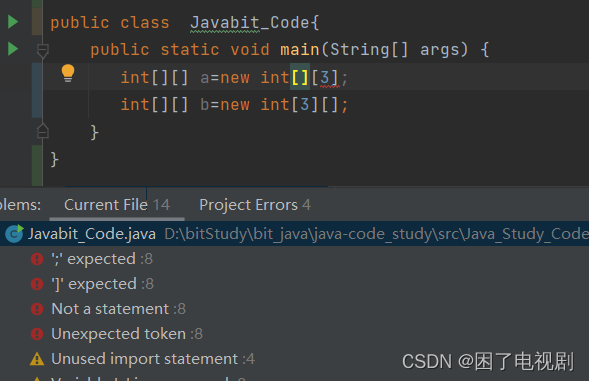
这与C语言截然相反,我们仔细思考一下,当我们定义行数而没有定义列数的时候,他进行动态初始化,然后由于我们没有定义列数,它会将这个数组的元素全部初始化为null,符合语法。
当我们定义列数而没有定义行数的时候,此时栈中的a指向null,这时我们又要求他指向一块地址,null要指向一块地址会报空指针异常的,所以语法错误。
数组的应用场景
数组传参
数组用的场景最多的地方莫过于给一个函数传参了,当我们将一个数组作为一个参数进行传递时,这个形参是实参的零时拷贝但不是实参,这时候我们就会引发一系列有趣的现象:
public static void func(int[] arr){
arr=new int[]{4,5,6};
}
public static void main(String[] args) {
int[] arr={1,2,3};
func(arr);
System.out.println(Arrays.toString(arr));
}这个程序的运行结果为:
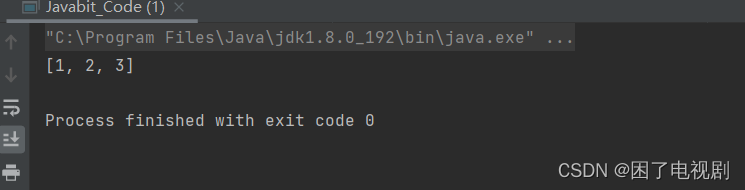
看到这个运行结果,有的同学可能会感到不解,我用一个图来解释原因:

开始时,他们的地址一样都指向同一块空间,现在执行方法中的语句
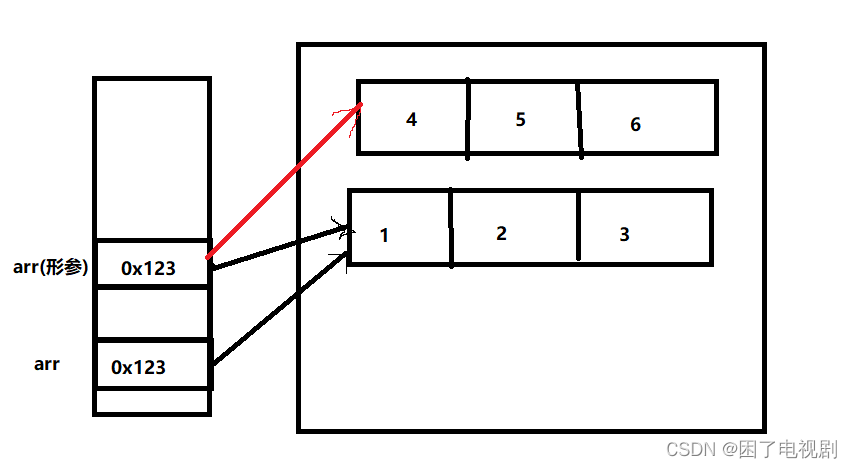
会发现形参指向了一个全新的地方,但实参所指向的空间里面的值仍没有改变,所以导致如上现象。
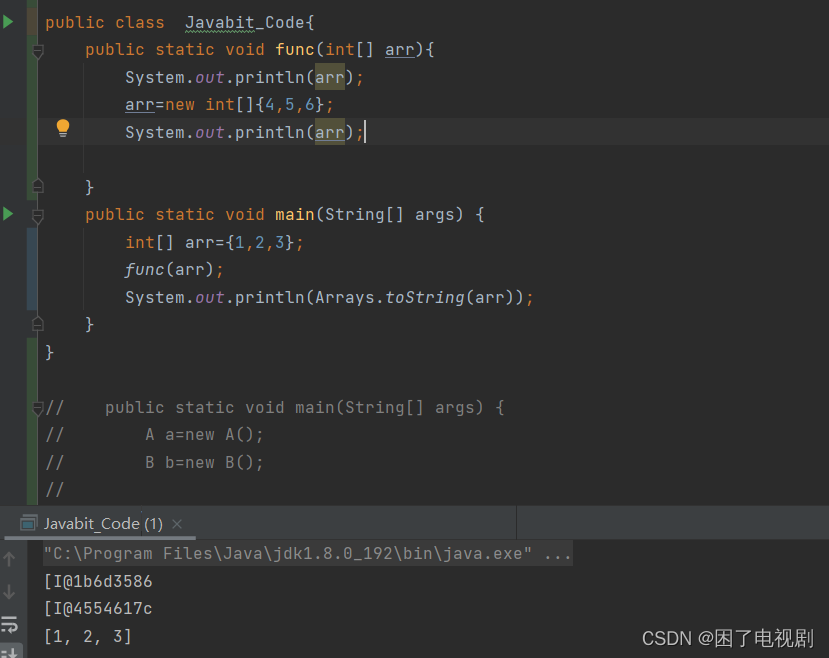
验证,arr前后的地址雀食不一样。
总结:

数组的高频使用
数组拷贝
我们在使用数组的时候,经常会有备份某一数组的需求,Java作为一门成熟的语言,自然也看到了这一点,对于数组拷贝Java提供了几种方式。
先纠正一个误区,可能很多萌新小白都会犯这个错误,反正当我第一次接触Java的时候确实吃了不小的亏,那就是认为数组拷贝可以通过直接赋值的方法来完成,比如这样:
public class Javabit_Code{
public static void main(String[] args) {
int[] arr1={1,2,3};
int[] arr2=arr1;
System.out.println(arr1);
System.out.println(arr2);
}
}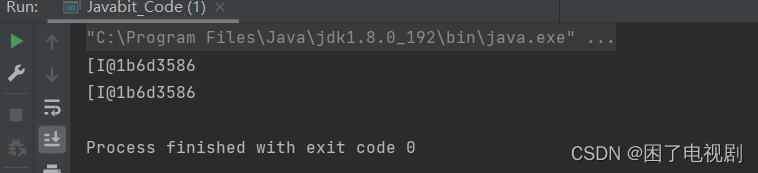
但很明显,堆区中的数组对象还是只有一份,这份工作只不过是让两个引用变量都指向同一个对象 而已,而我们要做的是在堆区中重新创建一个内容和arr1数组完全一样的数组,我们可以这样解决。
循环嵌套
这是最朴素的方法,重新定义一个数组,通过进行for循环的嵌套将arr1中的元素一个一个地进行赋值,通俗易懂容易理解,但是缺点也很明显,那就是时间复杂度较大,比较耗时,并且代码冗长。
copyOf方法
Arrays类中有一个copyOf方法,他可以直接将数组进行拷贝。
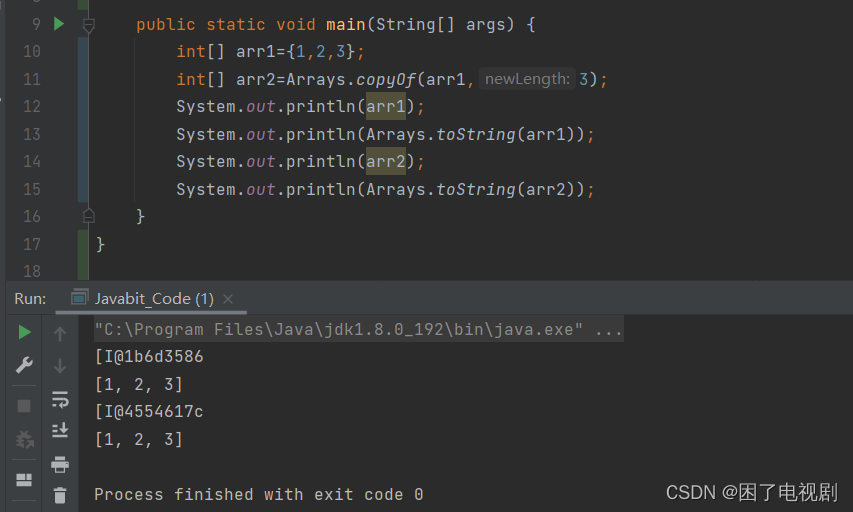
如图,并且他是一个深拷贝,现在让我们看一下这个方法的底层源码;

一个newLength参数也说明了这个方法不仅可以实现深拷贝的功能,而且能额外实现扩容的功能,功能较为强大,并且可以避免代码的冗长。
arraycopy方法
Java中有一个本地方法——arraycopy方法。
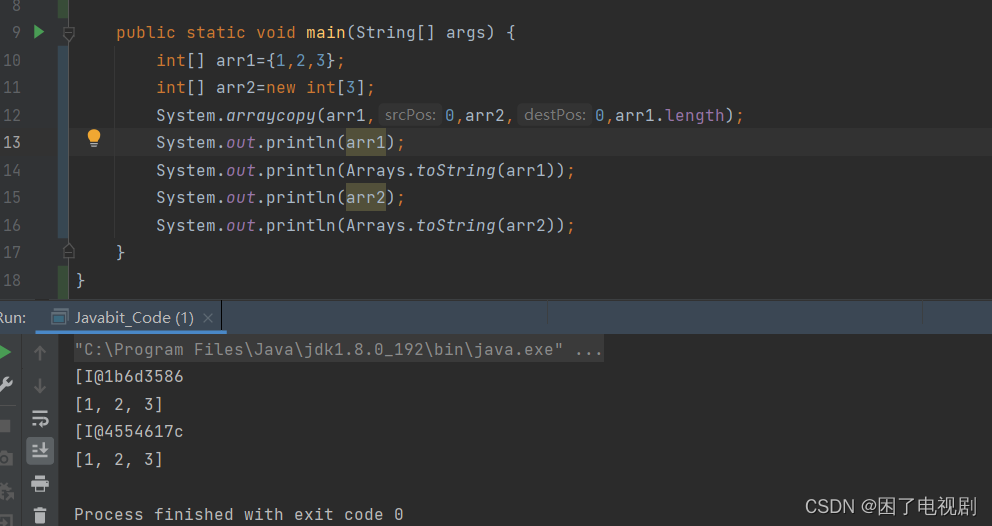
这个方法的底层:

我们可以看到他的前面有一个native的修饰符,说明这是一个本地方法!本地方法有一个共同的特点,那就是它的底层是由c/c++实现的,这说明了什么,这说明他的运行更快!这是一个及有效率的方法,他不仅避免了代码的冗长,并且加快了程序的运行速度,是一个很不错的方法。
那他应该怎样使用呢?我们通过他的参数进行分析。src是拷贝的数组(为了方便,之后用arr1来代替),srcPos是指定拷贝数组的开始拷贝的位置(取决于元素下标),dest是 被拷贝的数组(之后用copy代替),destPos是被拷贝数组开始被拷贝的位置,最后一个length则是拷贝的长度。由此可以看,他还有更加灵活的特点。
clone方法
clone方法也是一种对数组进行拷贝的方法,但和以上方法有所不同的是,他是一个浅拷贝的方法,在很多情况下容易出错,我之后会写一篇关于深浅拷贝的文章来进行解释。
冒泡排序
冒泡排序是一个很基础很实用的知识点,他的核心思想为每次循环都将剩余元素的最大(最小)值移到正确的位置。
public static void main(String[] args) {
int[] arr={1,2,3,7,5,4,9,0};
for(int i = 0; i < arr.length - 1; i++) {
for(int j = 0; j < arr.length - 1; j++) {
int temp=0;
if(arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}我们可以对其进行优化——既然他每次都可以将一个元素移到正确的位置,那么被嵌套的for循环是不是就可以少移一个元素:
public static void main(String[] args) {
int[] arr={1,2,3,7,5,4,9,0};
for(int i = 0; i < arr.length - 1; i++) {
for(int j = 0; j < arr.length - 1 - i; j++) {
int temp=0;
if(arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}如上,这样就可进一步提高效率了。
以上,就是关于Java中数组的几乎所有知识点了,我之后会将深浅拷贝的文章给肝出来,订阅我的专栏下次不迷路哦,如有什么缺漏的地方还请大佬指正。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









