






前期准备:
(1)租借autodl服务器
autodl 服务器:
https://www.autodl.com/console/homepage/persona
建议选 4090(24G),不然微调的显存不够。
我们用 LoRA 微调,至少得 20G(8B模型)。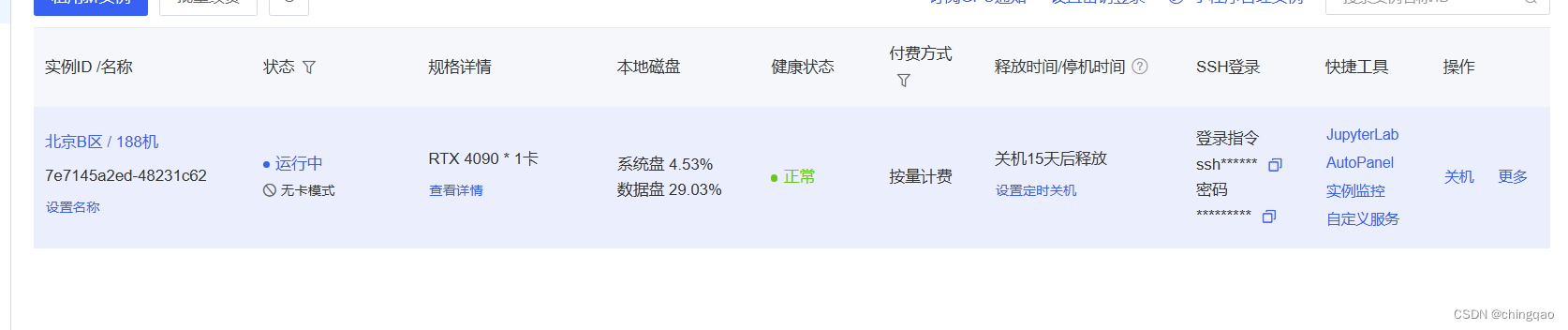
(2)开源微调工具
下载微调工具 LLaMA-Factory
LLaMA-Factory 是一个基于 LLaMA 模型的高效微调工具,它可以帮助用户快速、轻松地微调 LLaMA 模型以适应各种下游任务。LLaMA-Factory 提供了一个简单易用的命令行界面,用户可以通过几个简单的命令来实现对 LLaMA 模型的微调。同时,LLaMA-Factory 也支持一些高级功能,如模型并行、混合精度训练等,可以帮助用户更高效地微调 LLaMA 模型。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[metrics] # 下载全部依赖(3)部署模型:通义千问
什么是通义千问?
通义千问(Tongyi Qianwen)是由阿里巴巴集团旗下的云端运算服务的科技公司阿里云开发的聊天机器人。它能够与人互动、回答问题及协作创作。这个名字来源于两个方面:“通义”意味着该模型具有广泛的知识和普适性,可以理解和回答各种领域的问题。作为一个大型预训练语言模型,“通义千问”在训练过程中学习了大量的文本数据,从而具备了跨领域的知识和语言理解能力。“千问”代表了模型可以回答各种问题,包括常见的、复杂的甚至是少见的问题。
什么是LLM?
LLM(Large Language Model)是一种语言模型,以其实现通用语言理解和生成的能力而闻名。LLM通过在计算密集型的自监督和半监督训练过程中从文本文档中学习统计关系来获得这些能力。例如,OpenAI的GPT模型(例如,用于ChatGPT的GPT-3.5和GPT-4),Google的PaLM(用于Bard),Meta的LLaMA,以及BLOOM,Ernie 3.0 Titan和Anthropic的Claude 2等都是LLM的例子。
LLM模型的架构由多个因素决定,如特定模型设计的目标、可用的计算资源以及LLM要执行的语言处理任务的类型。LLM的一般架构包括许多层,如前馈层、嵌入层、注意力层。一个嵌入在内部的文本被协同起来生成预测。
环境配置
要求(Requirements)
python 3.8及以上版本
pytorch 2.0及以上版本
建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
我选择的环境是python=3.9,创建环境名字light
conda create --name light python=3.9
conda activate light
可以到这个网站https://pytorch.org/get-started/previous-versions/,CTRL+F搜索CUDA 11/12找自己版本对应的pytorch安装pytorch
以我的CUDA 11.7为例子,pip进行安装:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
进入到工作目录,安装Qwen项目,
注:如果网络不好,可以选择ZIP压缩包下载方式下载
git clone https://github.com/QwenLM/Qwen.git
进入到项目根目录,安装所需要的环境
cd Qwen/
pip install -r requirements.txt
requirements.txt:
transformers==4.32.0
accelerate
tiktoken
einops
transformers_stream_generator==0.0.4
scipy
我后面还报了几个错误,需要装这几个库,总之报错了根据提示装上就好
pip install optimum
pip install auto-gptq
Optimum是huggingface开源的模型加速项目。
auto-gptq是一个基于 GPTQ 算法,简单易用且拥有用户友好型接口的大语言模型量化工具包。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









