










上一篇我们学习了如何搭建伪分布式环境,今天我们来学习如何搭建完全分布式环境。
第一步
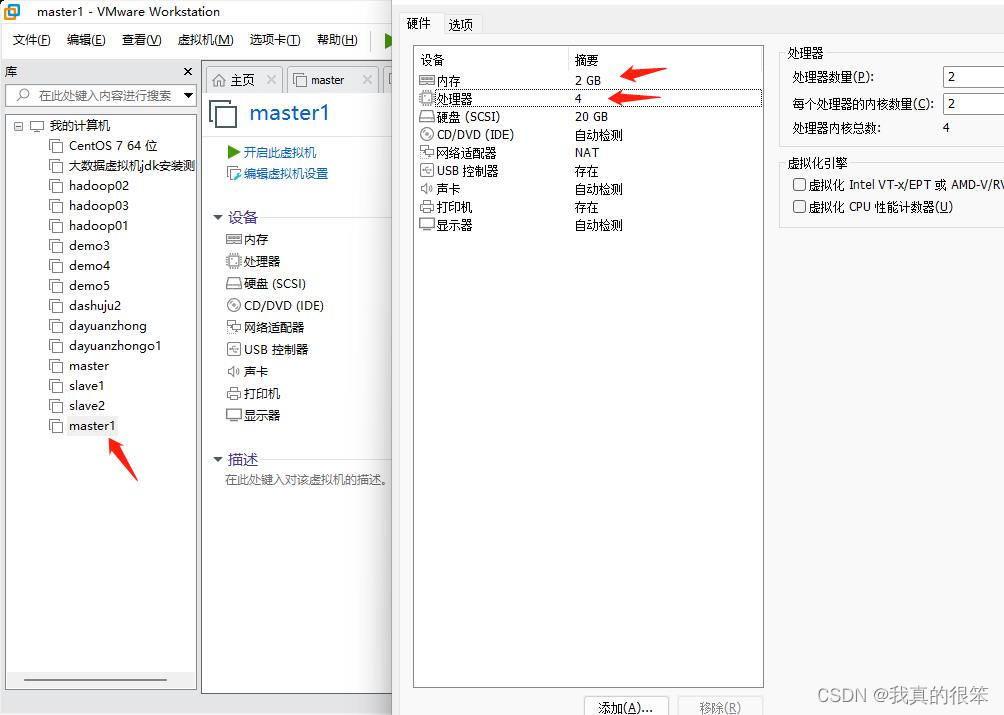
我们需要新建一个虚拟机master1,内存和cpu根据自己的电脑进行合理分配即可。
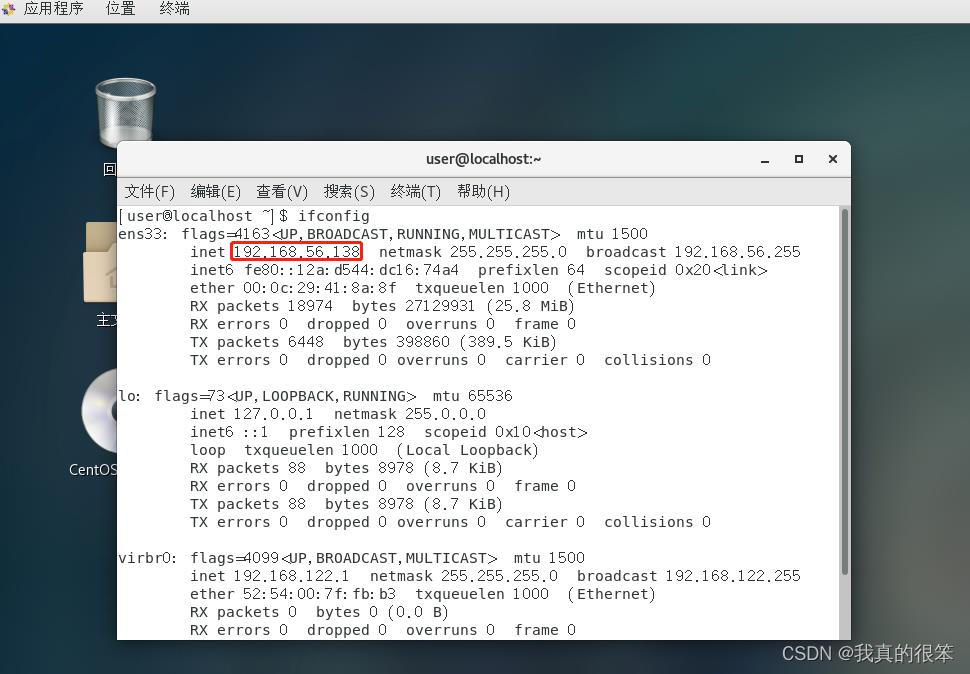
接下来我们首先查看自己master1虚拟机的ip
查看命令为
ifconfig
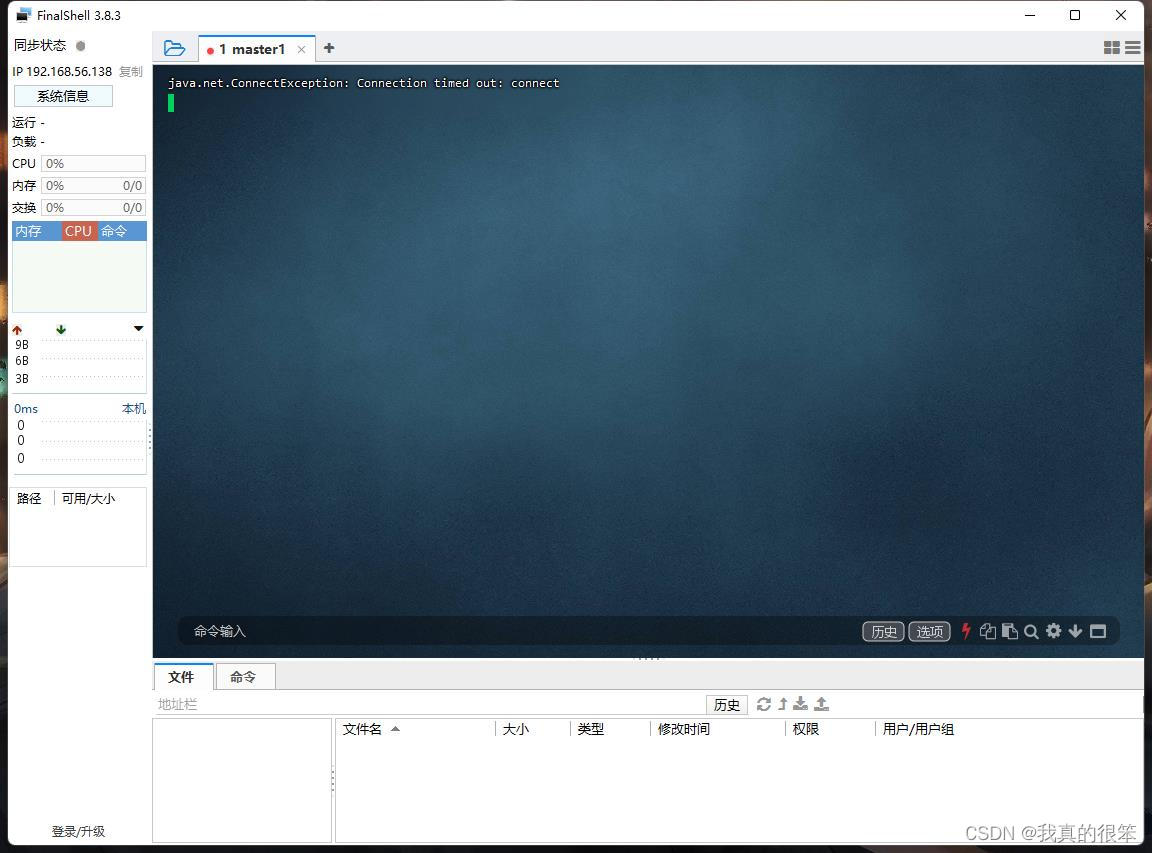
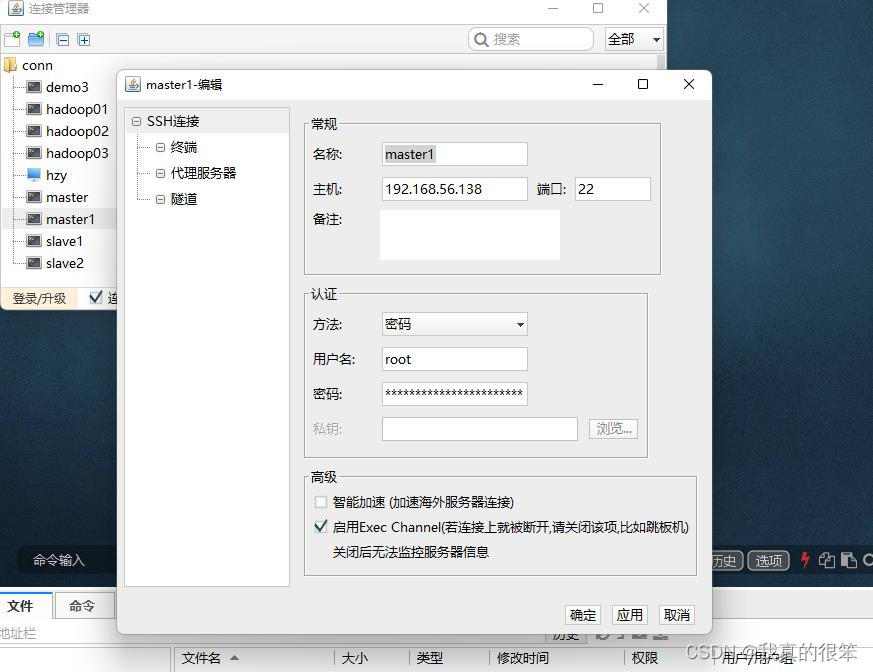
之后使用我们的FinalShell软件对master1进行连接
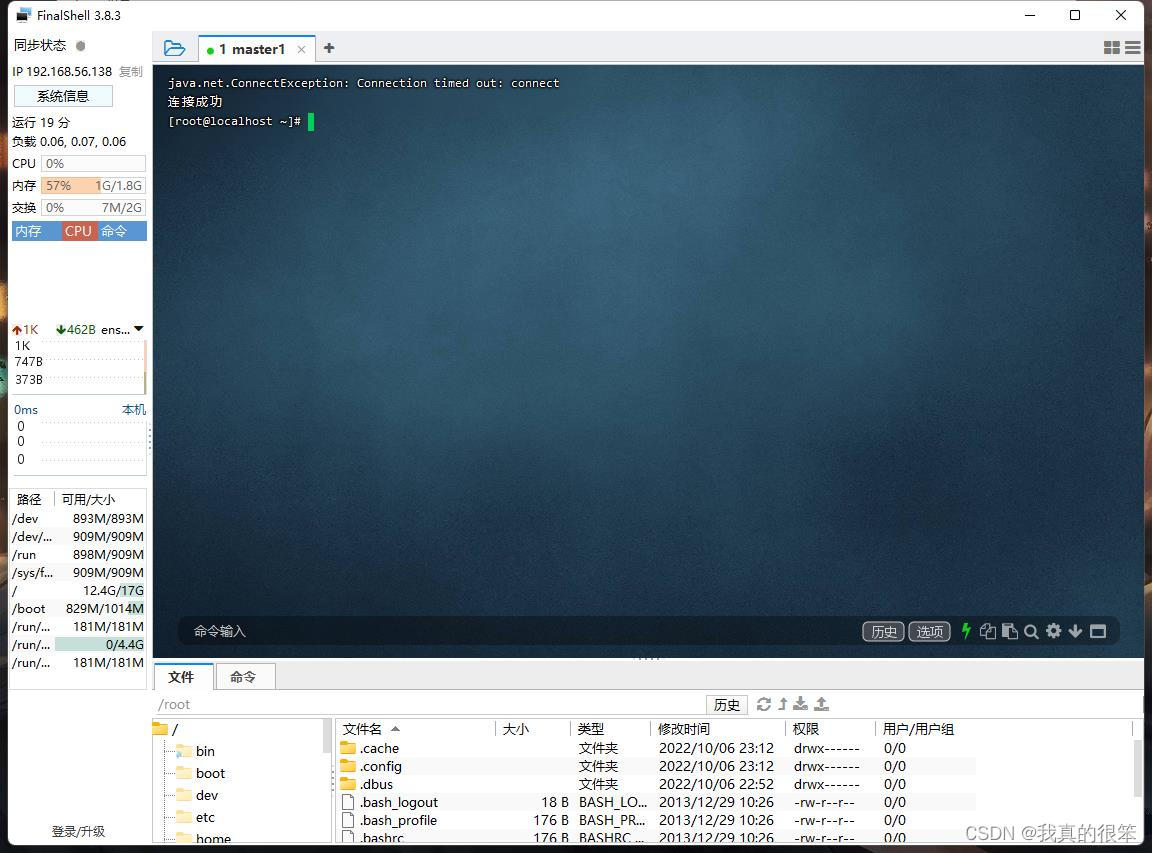
可以看到我们连接失败了失败的原因一般是ip地址,用户名或密码写错的问题
检查一下并没有写错
还有种原因是我们的主机的vm8网络没有打开,确实是没有打开,我们将它开启后重新进行连接成功了
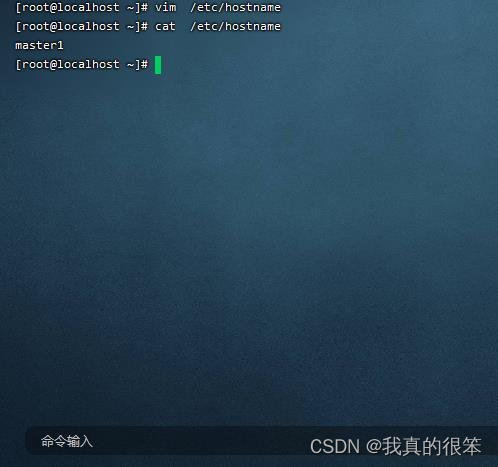
更改虚拟机主机名称为master1
更改命令为vim /etc/hostname
查看命令为cat /etc/hostname
JDK安装
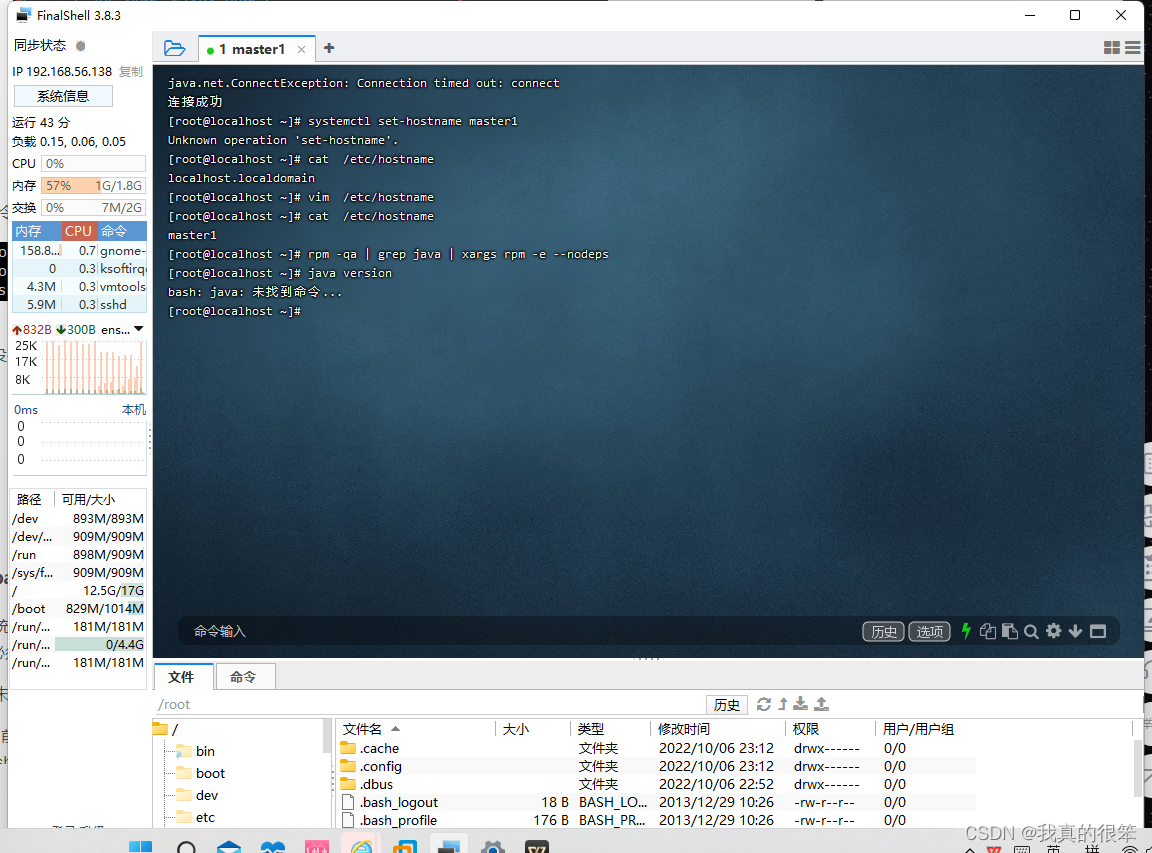
第一步首先我们要将虚拟机自带的jdk进行卸载
命令为
rpm -qa | grep java | xargs rpm -e --nodeps
卸载后使用
java version 进行查看出现以下提示时,证明卸载成功了
下一步将自己下载的jdk进行安装
安装目录为
/usr/java
首先在usr目录下新建一个java目录
首先
cd到usr目录下
然后使用mkdir java 新建Java目录
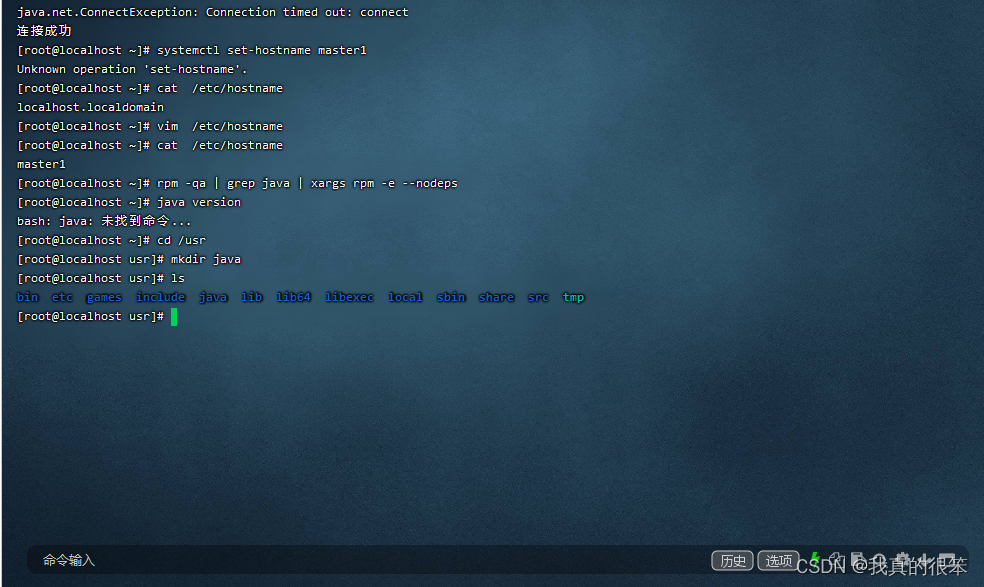
之后将我们下载的JKD安装包导入到java目录下
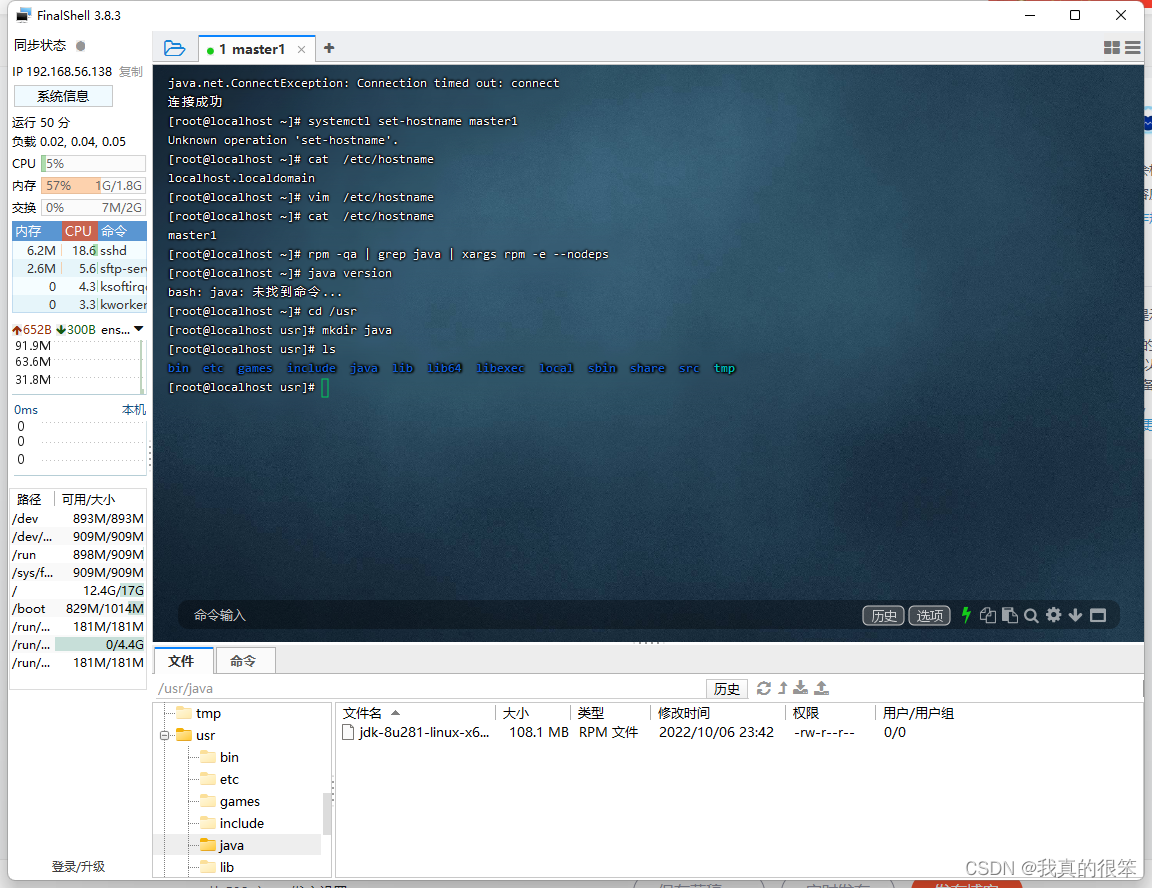
上传完成开始进行安装
安装命令为
rpm -ivh jdk-8u281-linux-x64.rpm
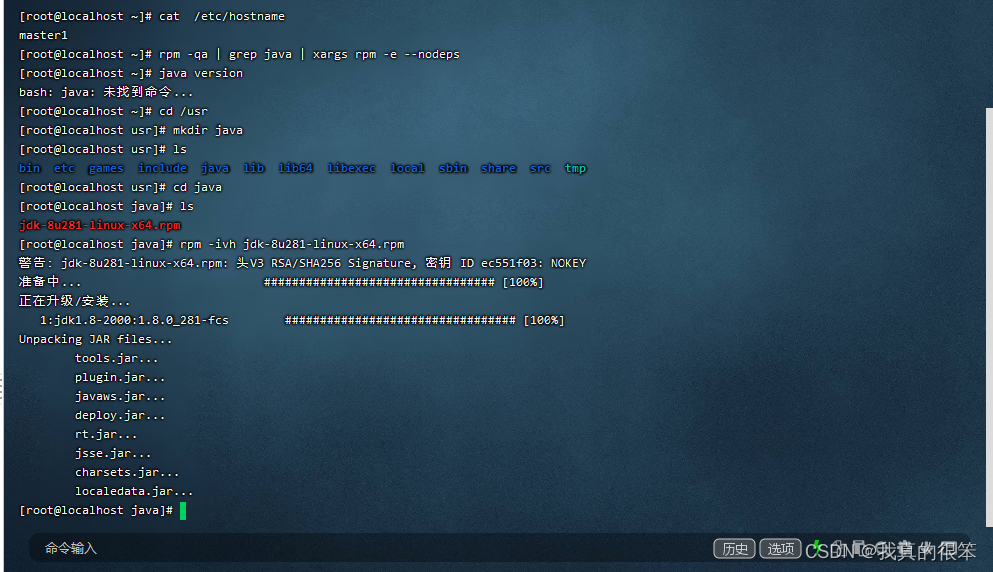
安装完成后就要对虚拟机的变量进行配置
使用vi ~/.bash_profile 进行配置,完成后使用source ~/.bash_profile进行释放
配置方法为
| export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64 export PATH=$JAVA_HOME/bin:$PATH |
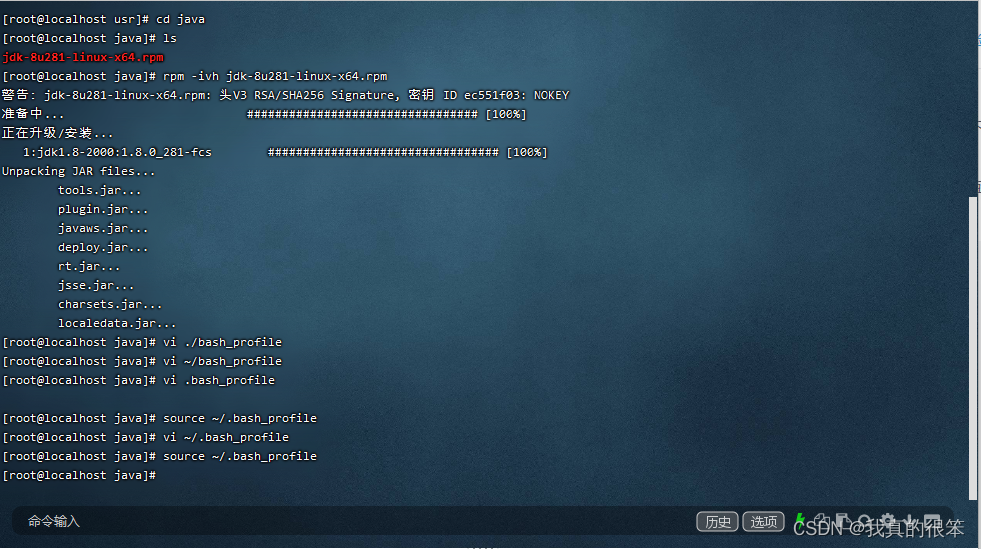
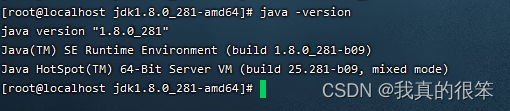
完成后使用java -version命令进行查看出现下面提示后证明安装成功。
克隆虚拟机master1
首先关闭虚拟机(这个就不演示了)
关闭之后右键虚拟机master1 点击管理 选择克隆
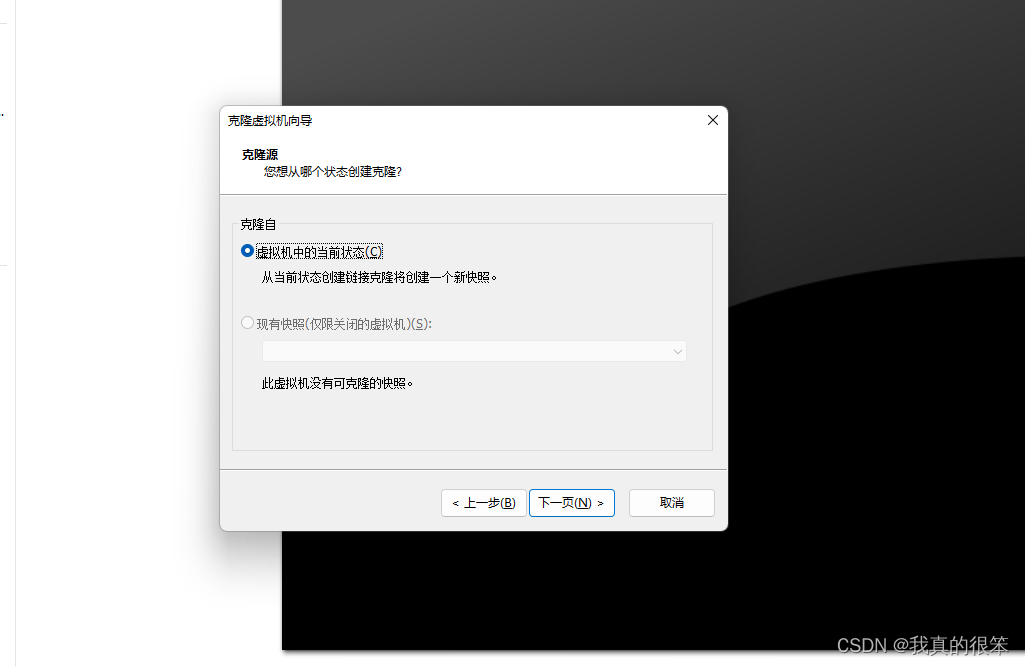
选择当前状态
选择创建完整克隆
更改名称为slave3 之后点击完成
之后重复以上步骤创建slave4
之后将三个虚拟机同时开启,使用ifconfig指令查看ip后用FinalShell软件进行连接
完成之后将slave3和slave4的虚拟机主机名称由master1更改为slave3和slave4并查看
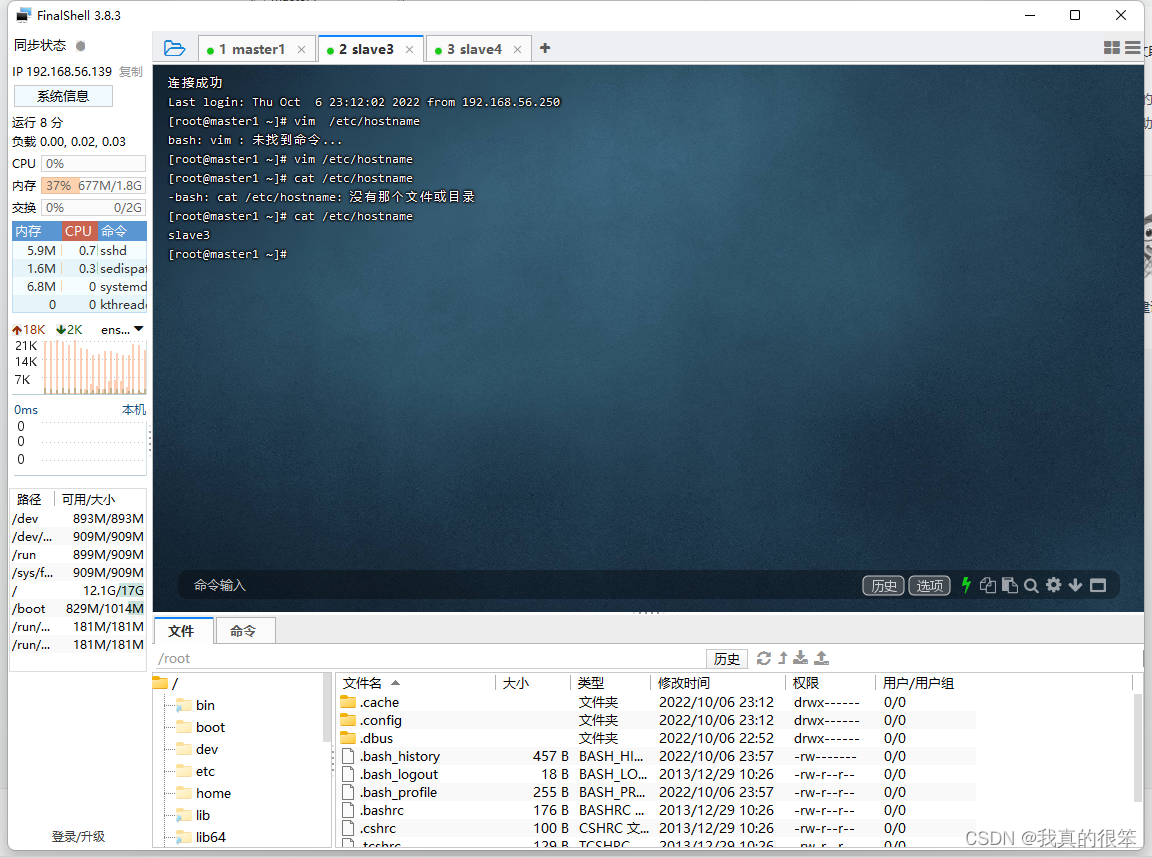
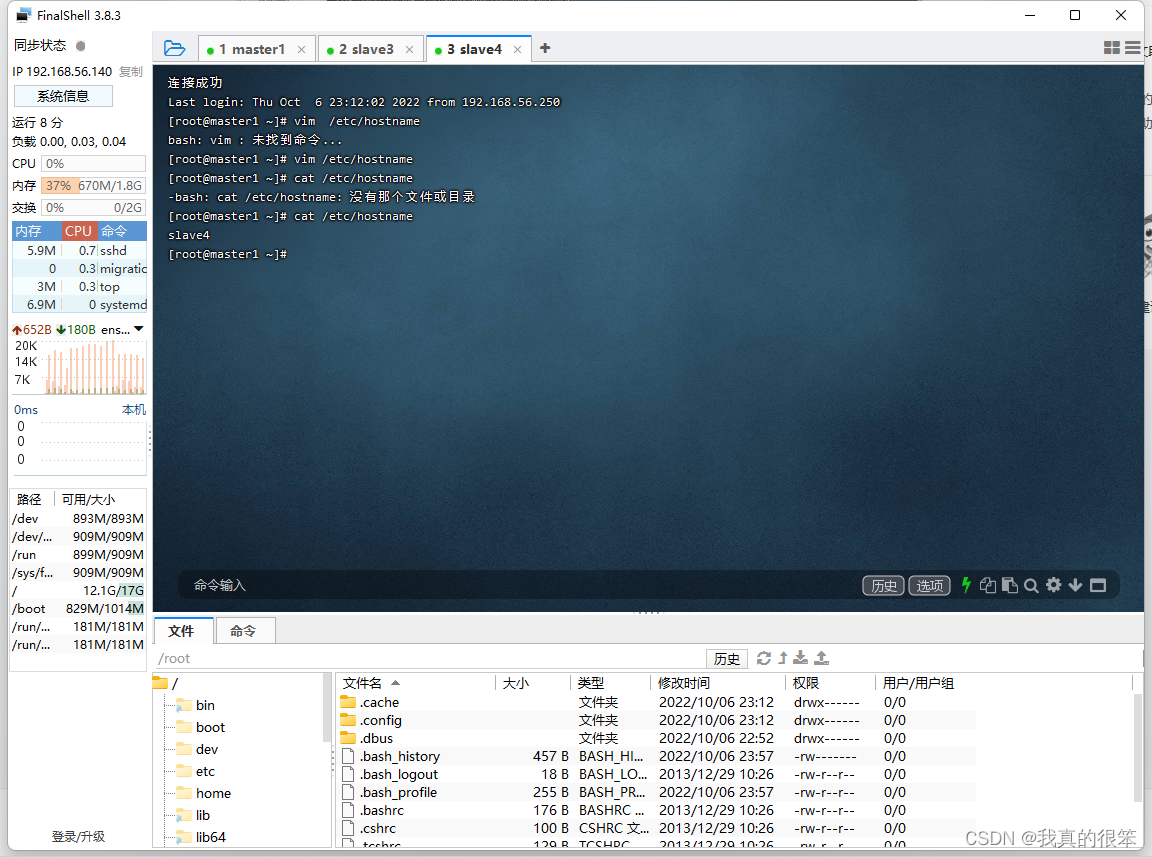
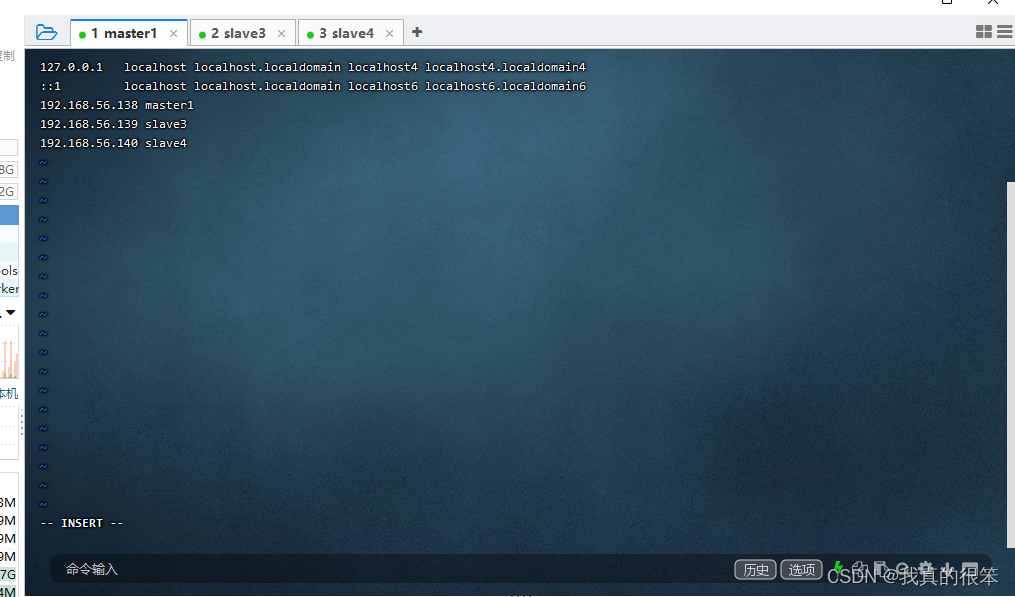
下一步更改三台虚拟机的hosts配置使三台虚拟机之间能够互相ping通
更改命令为
vi /etc/hosts
根据自己三台虚拟机的ip进行更改(虚拟机的ip查看命令上面有提到不知道的可以往上划一划)
注:三台虚拟机都要进行更改
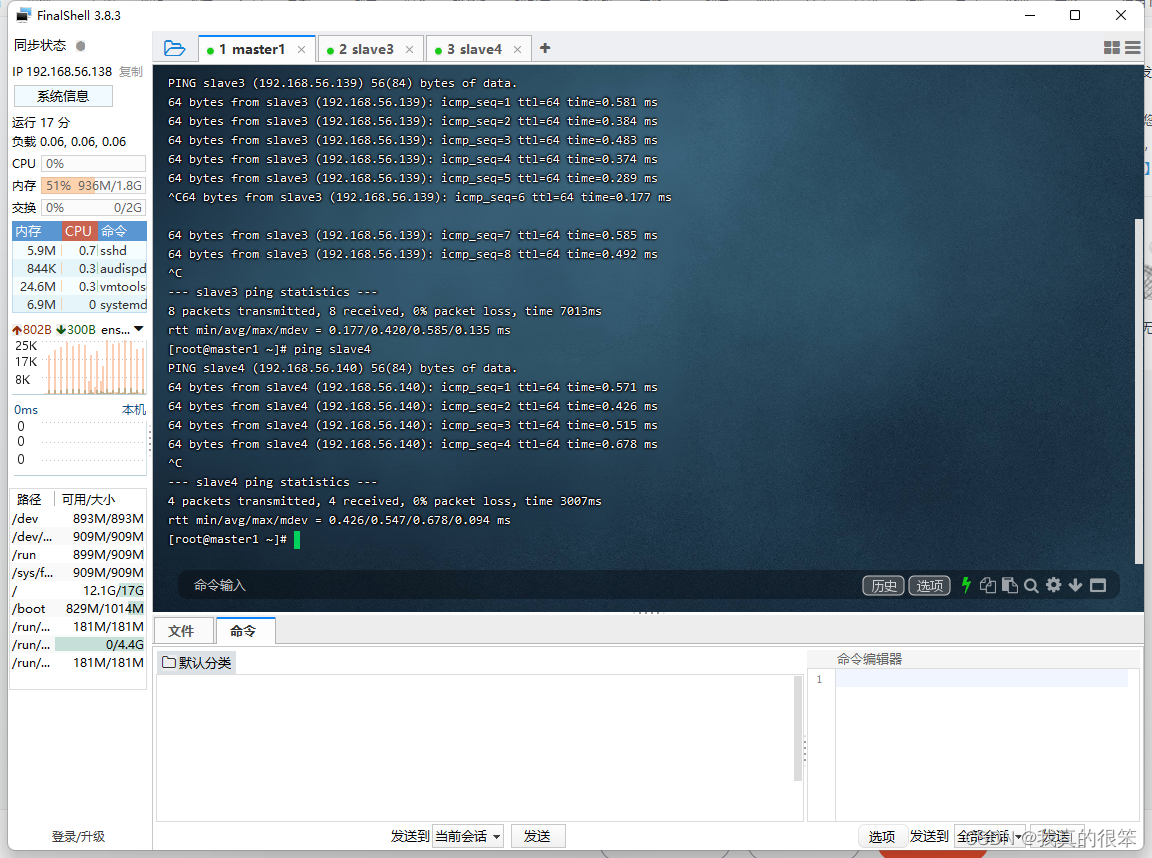
测试一下(因为文章的原因这里我只展示了虚拟机master1pingslave3和slave4,你们进行搭建的时候必须全部测试以下)成功ping通
下一步为三台虚拟机设置静态ip
设置命令为 vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO处改为static
下面的是要自己手动添加的
IPADDR=虚拟机ip地址
NETMASK=255.255.255.0
GATEWAY=网关
DNS1=与GATEWAY一致
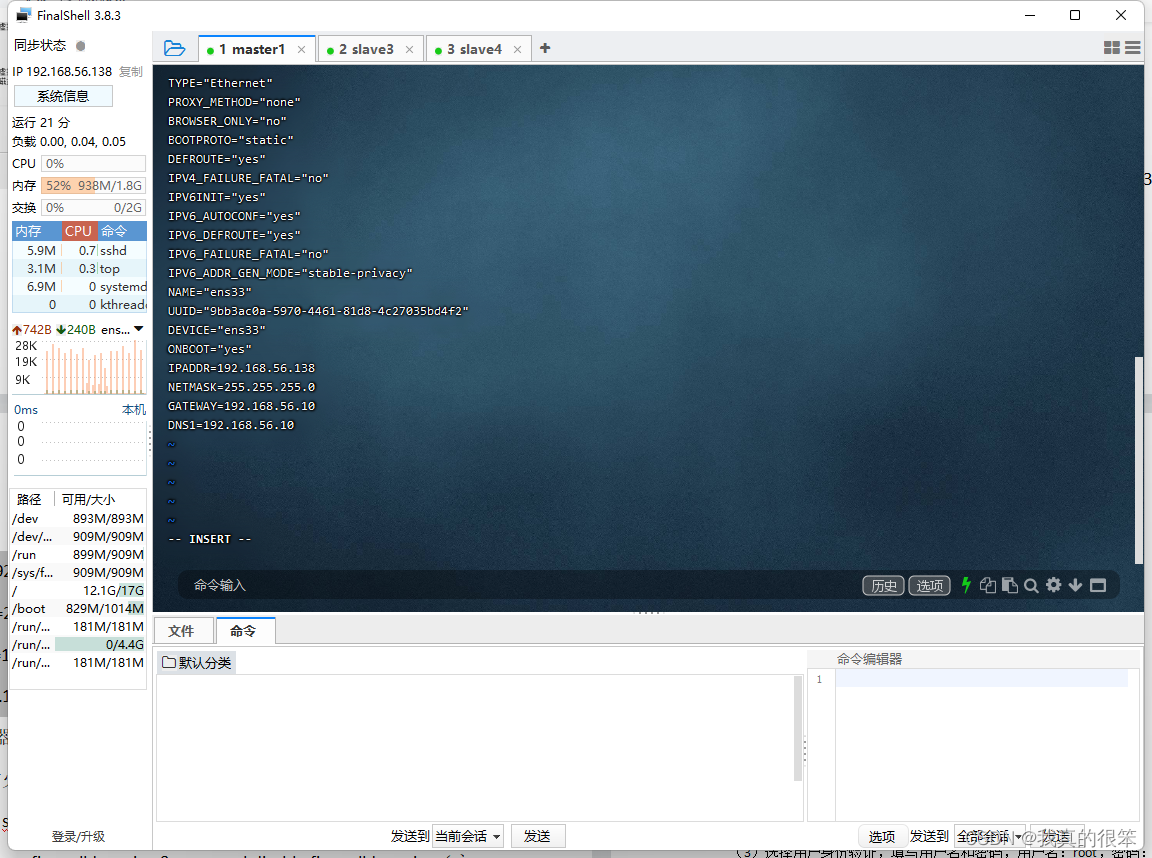
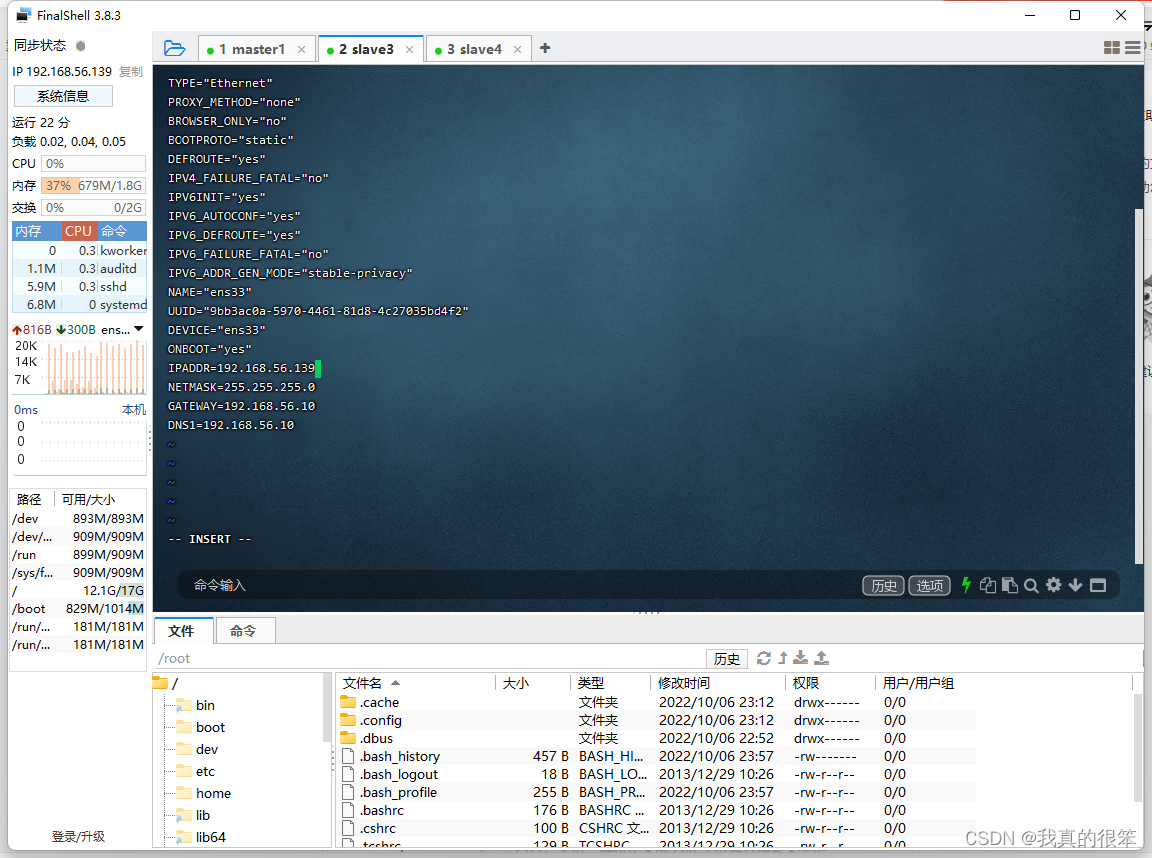
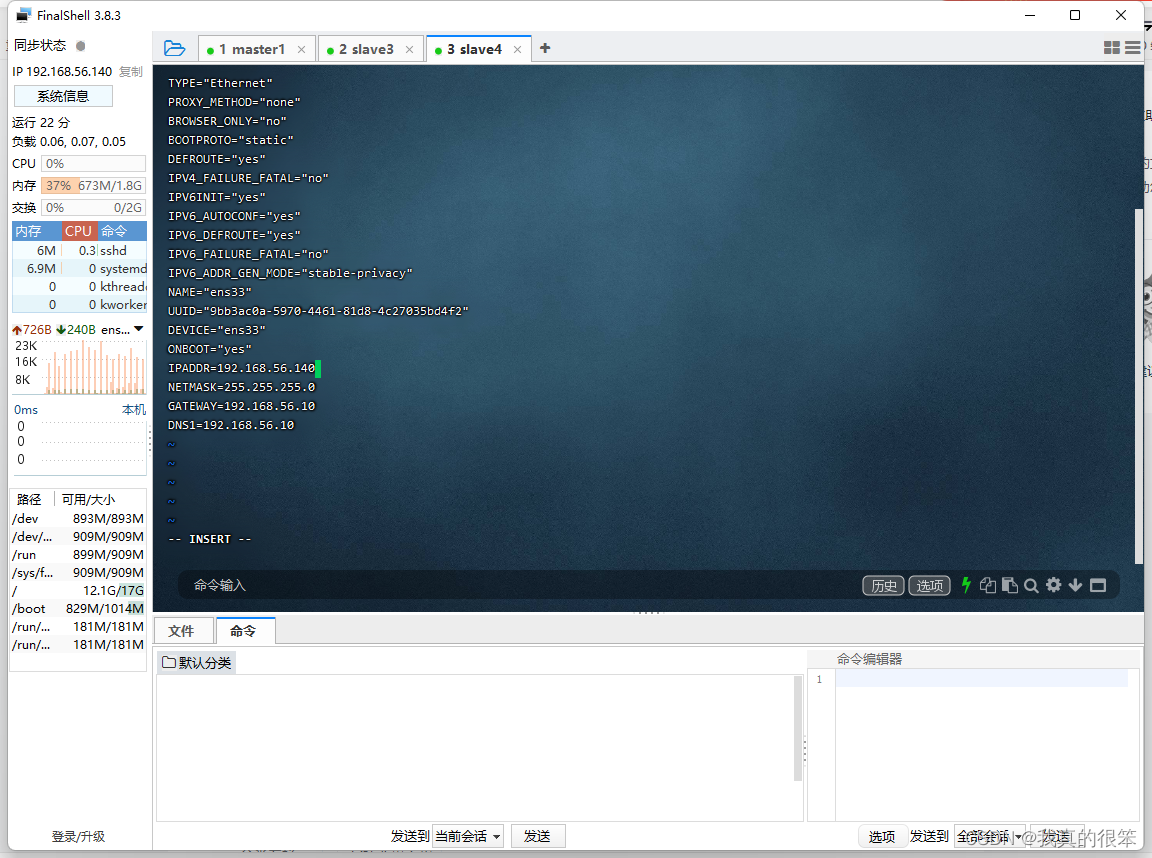
下面是三台虚拟机配置好的截图
master1
slave3
slave4
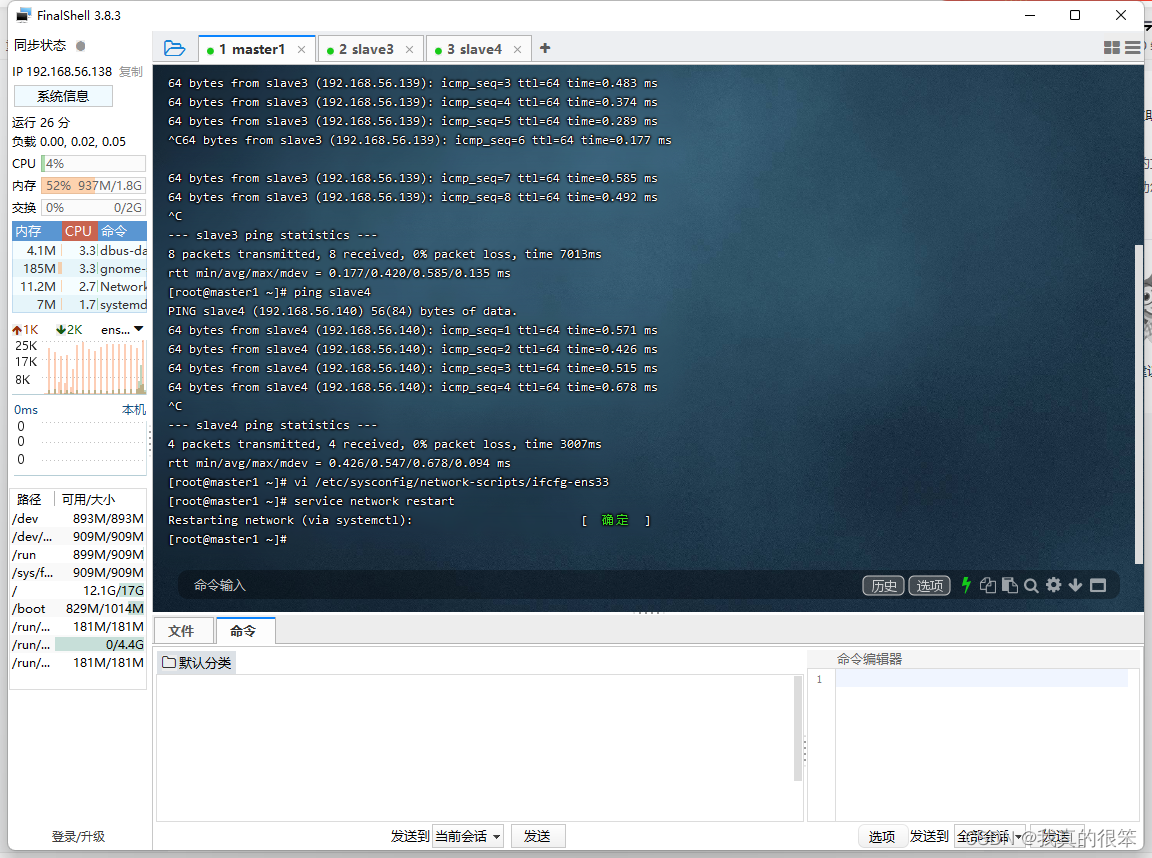
完成后使用service network restart指令重启网络,出现下面提示(就是那个原谅色的确定)说明重启成功(三台虚拟机都要重启)
下一步永久关闭防火墙(三台虚拟机都要关闭防火墙)
防火墙永久关闭命令为
systemctl stop firewalld.service & systemctl disable firewalld.service
可以看到防火墙已经成功关闭

接下来的操作只在master1上进行
Hadoop安装
首先上传hadoop安装包到opt目录下(与jkd安装包上传方式相同不做演示)
上传完成后进入到opt目录下使用命令
tar -zxf hadoop-3.1.4.tar.gz
进行解压安装
之后使用vi ~/.bash_profile进行变量配置之后使用source ~/.bash_profile进行释放
用hadoop version进行查看
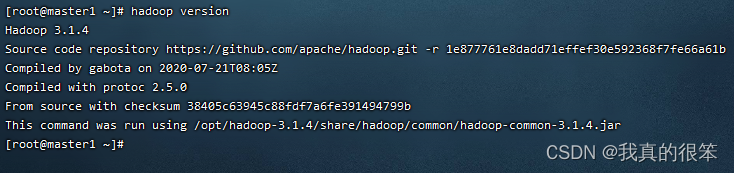
之后就是进行环境变量配置
在配置之前先设置一下免密钥登录
第一步设置密钥
ssh-keygen -t rsa (这里是三次回车)
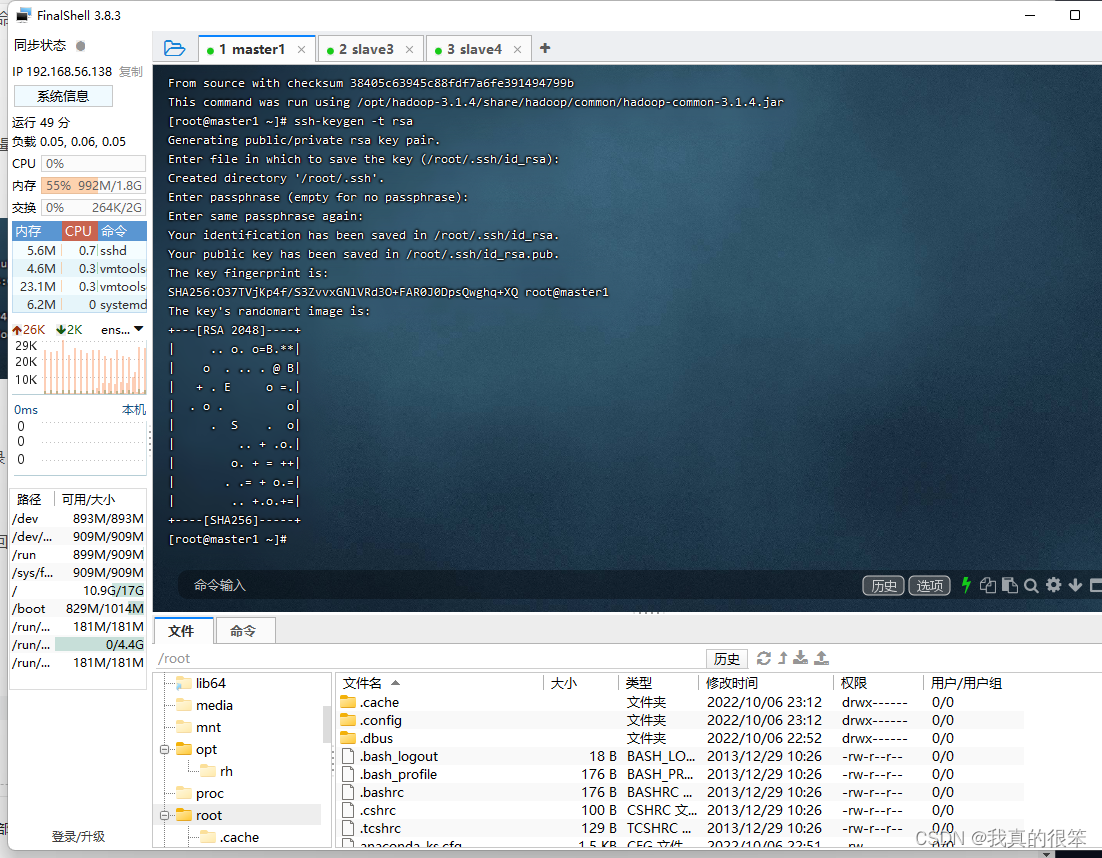
完成后将密钥发送个另外这三台虚拟机
这里直接打上yes
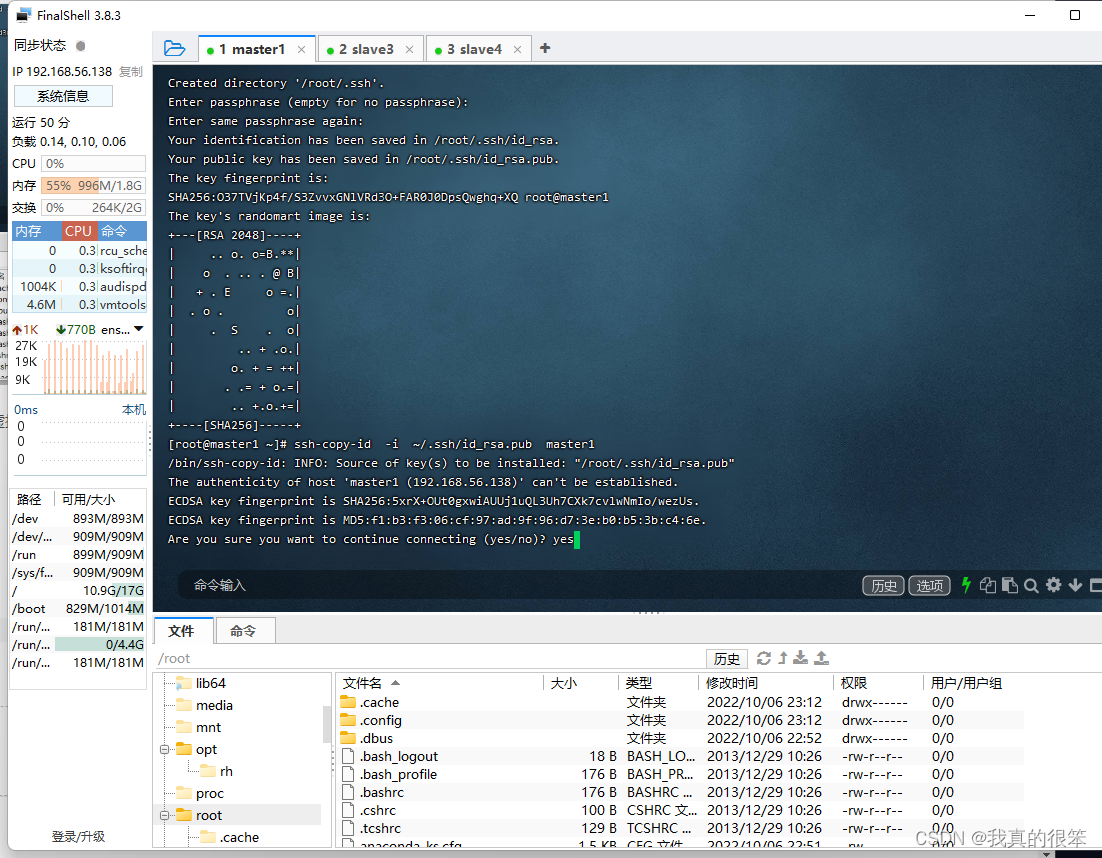
这里的密码就是我们root用户的密码注意这里不会显示
这个就完成了
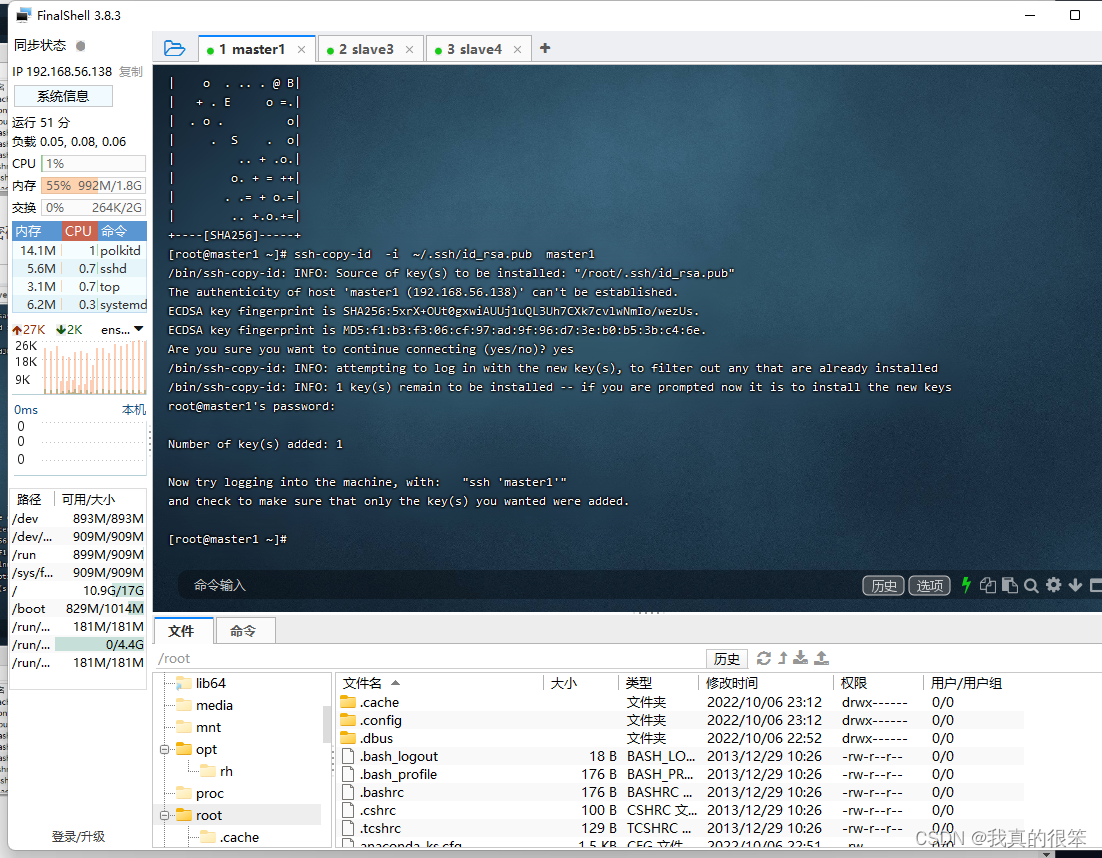
之后使用命令
ssh-copy-id -i ~/.ssh/id_rsa.pub slave3
ssh-copy-id -i ~/.ssh/id_rsa.pub slave4
将密钥发送给slave3和slave4
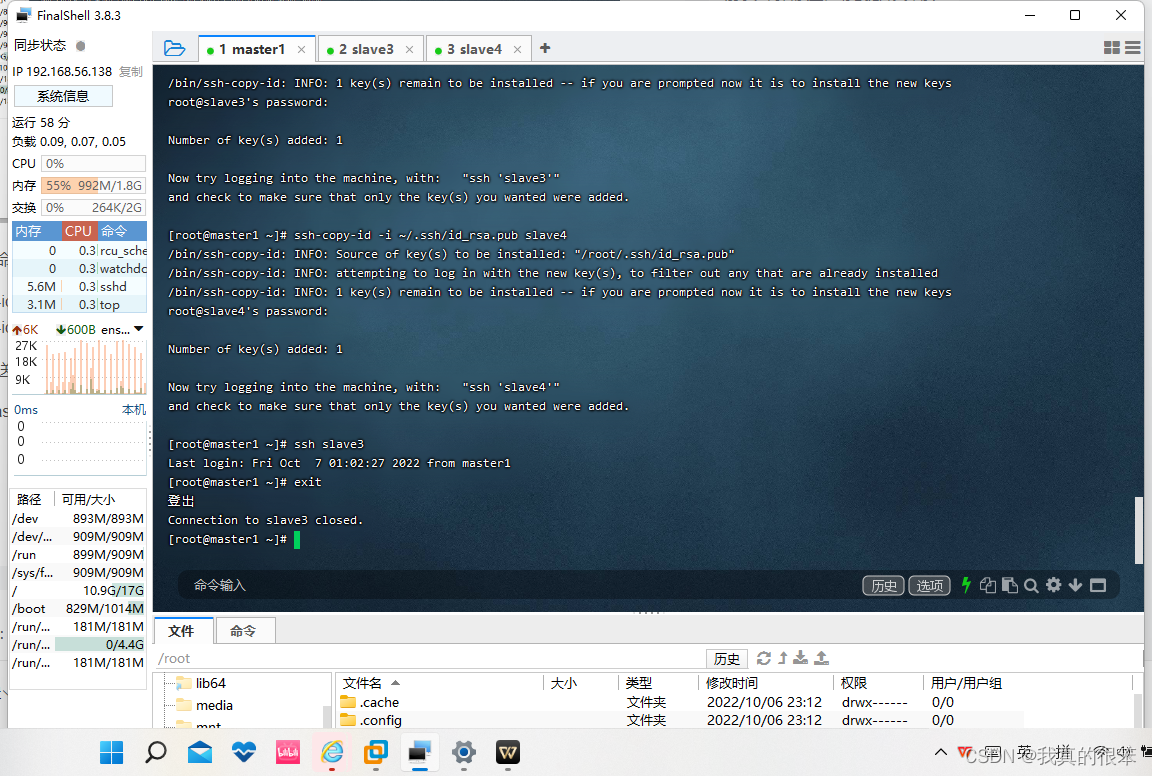
然后用master1虚拟机连接slave3和slave4时只需要在初次连接时输入密码之后就都不需要了
(这里我们看的连接上slave3后他的名称是master1这里其实是因为我为了方便并没有重启虚拟机如果大家害怕自己搞混了可以在更改完名称后重启一下自己的虚拟机)
下面就开始配置hadoop变量
首先进入/opt/hadoop-3.1.4/etc/hadoop目录下
第一步配置 hadoop-env.sh 变量 命令为 vi hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
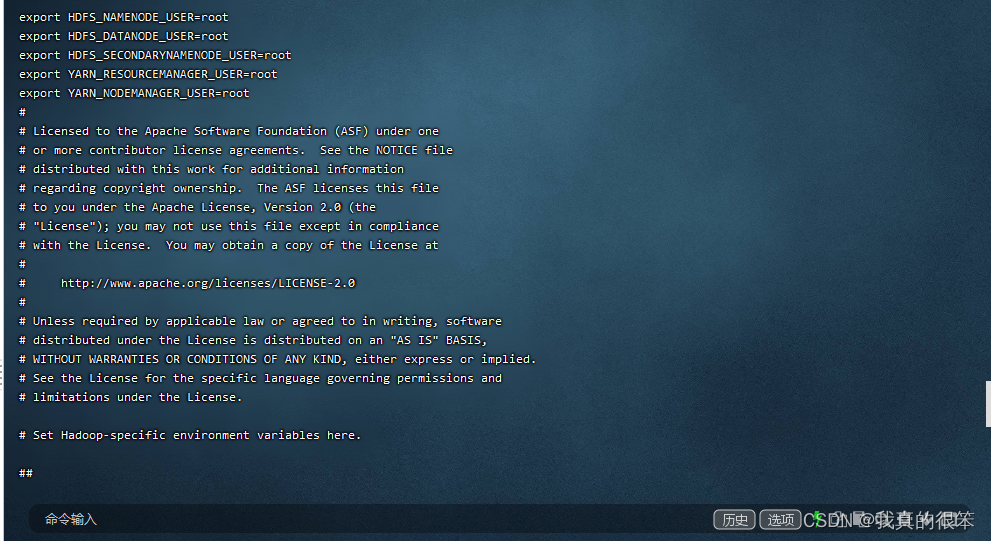
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
第二步配置 core-site.xml 变量命令为 vi core-site.xml (这里的master1记得改成自己的虚拟机主机名)
<!--hdfs临时路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!--hdfs的默认地址、端口访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:8020</value>
</property>
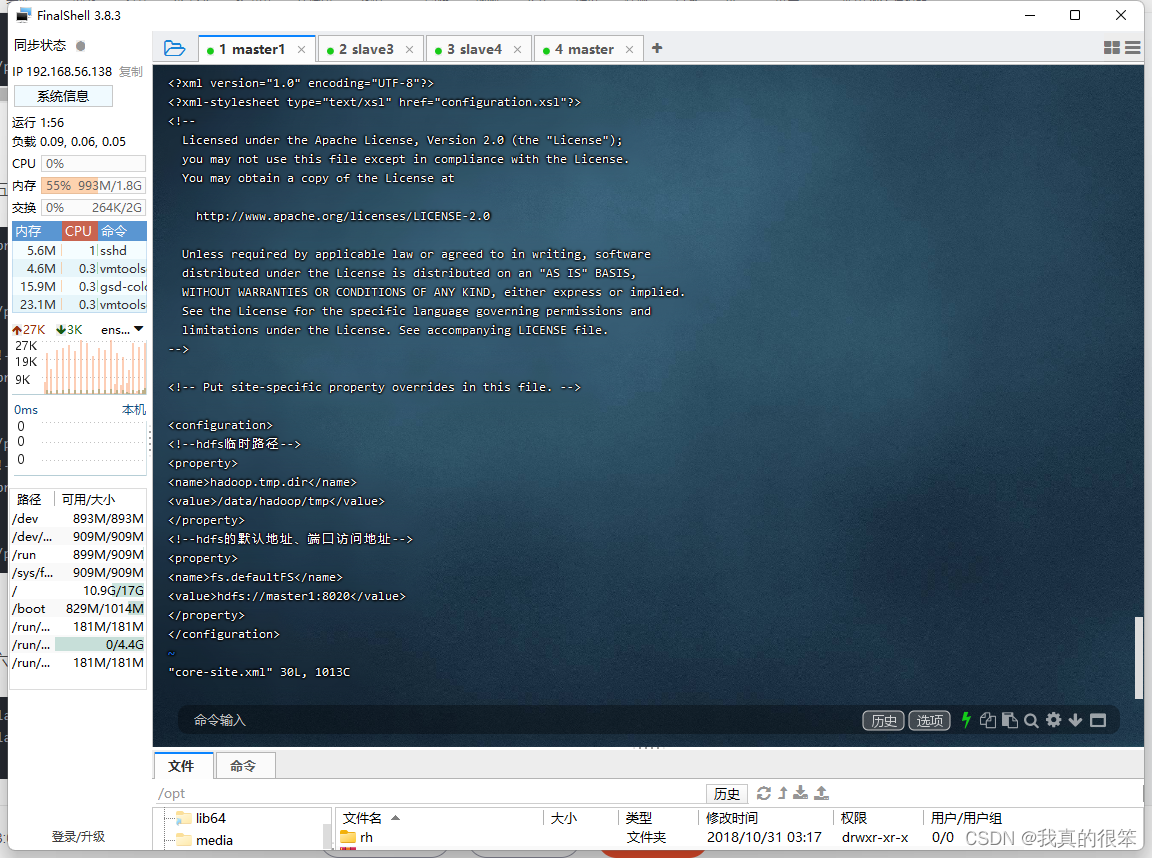
第三步配置 hdfs-site.xml 变量 命令为 vi hdfs-site.xml (这里的master1记得改成自己的虚拟机主机名)
<property>
<name>dfs.namenode.http-address</name>
<value>master1:50070</value>
</property>
<!-- 副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 块大小,默认字节, 可使用 k m g t p e-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/data/hadoop/datanode</value>
</property>
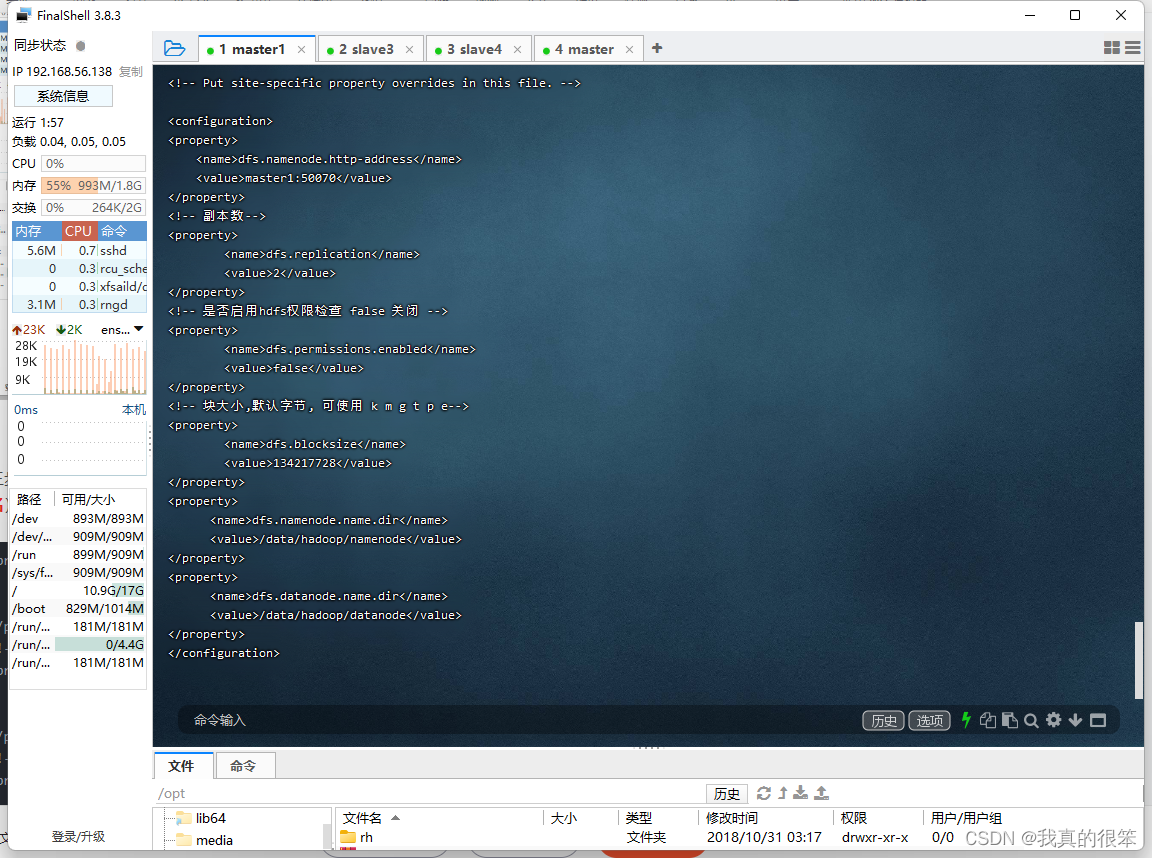
第四步配置 mapred-site.xml 变量,命令为 vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.4</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.1.4/share/hadoop/mapreduce/*:/opt/hadoop-3.1.4/share/hadoop/mapreduce/lib/*</value>
</property>
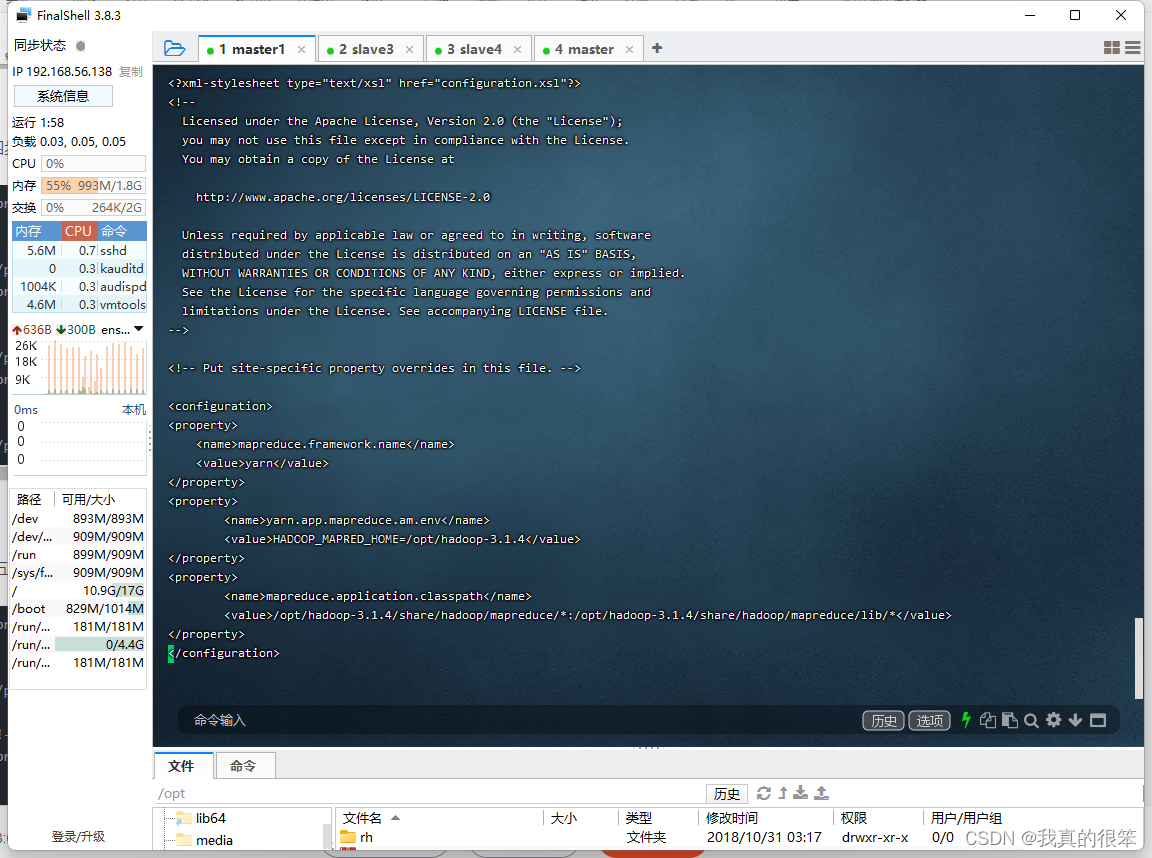
第五步配置 yarn-site.xml 变量,命令为vi yarn-site.xml (这里的master1记得改成自己的虚拟机主机名)
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master1</value>
</property>
<!-- NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭内存检测-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
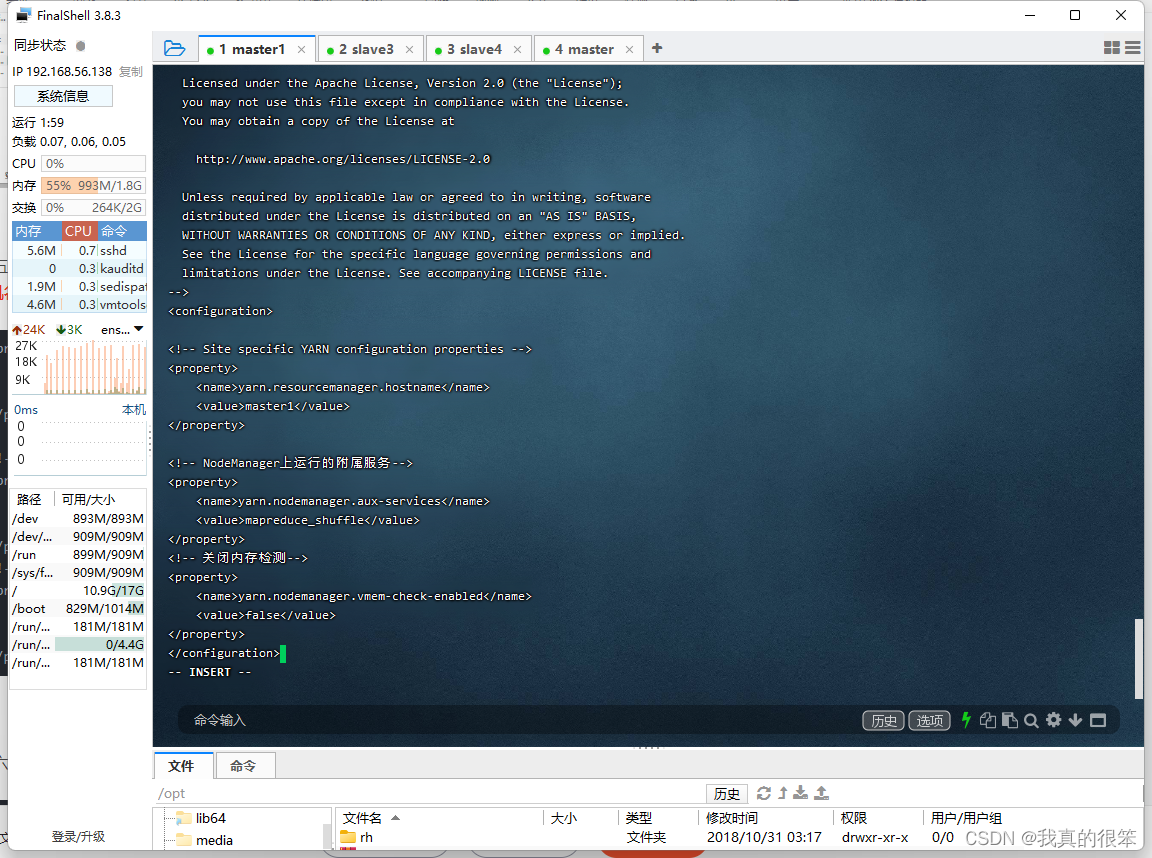
第六步设置workers 变量 命令为 vi workers (这里的slave3和slave4记得改成自己创建的名称)
slave3
slave4
配置完成后将配置好的hadoop拷贝到slave3和slave4上
命令为
scp -r /opt/hadoop-3.1.4/ slave3:/opt/
scp -r /opt/hadoop-3.1.4/ slave4:/opt/
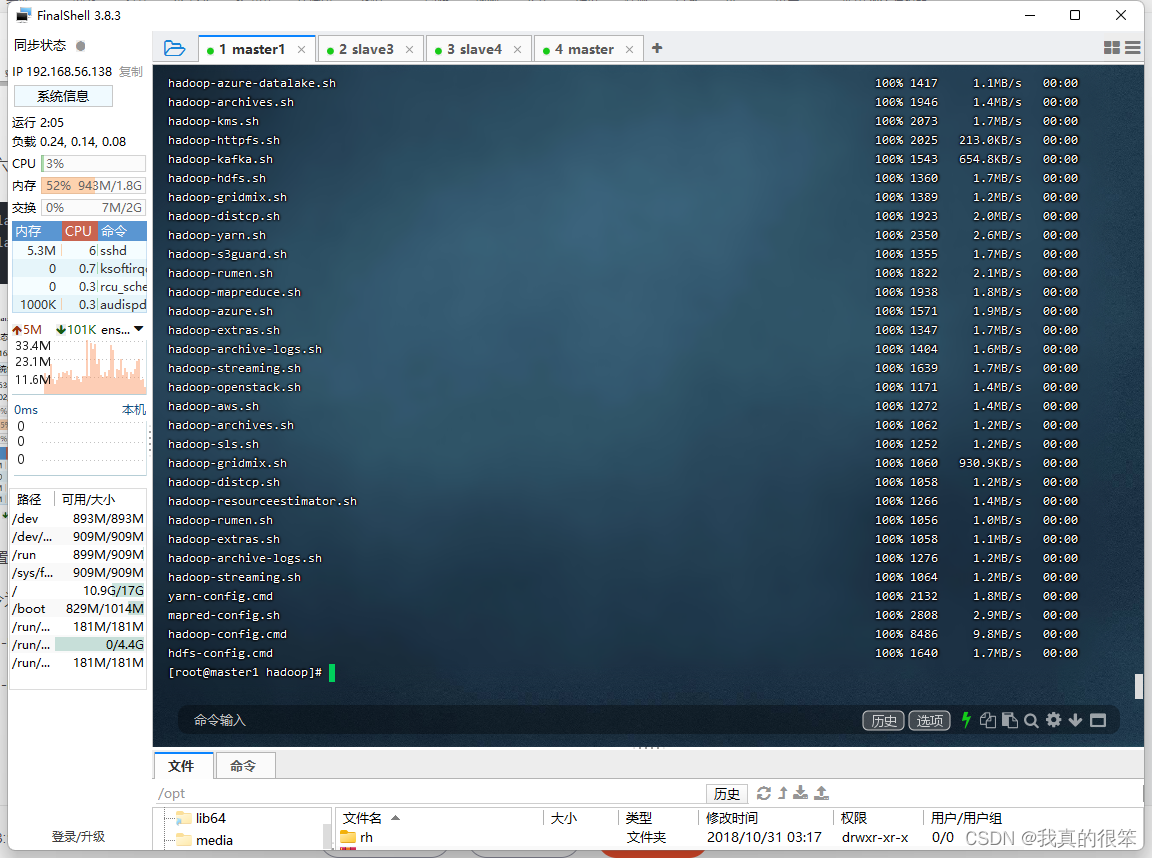
拷贝完成后下一步就要进行格式化了 (格式化尽量保证一次正确,多次格式化会报错)
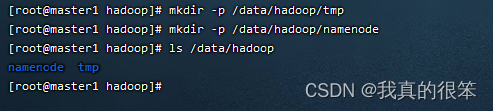
首先先来新建几个文件夹
首先使用命令建立tmp和namenode文件夹
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
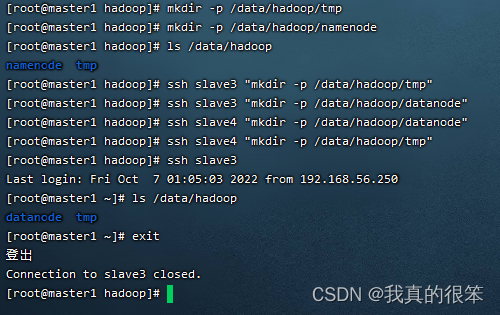
下一步使用命令在slave3和slave4虚拟机里面建立tmp和datanode文件夹
命令为
ssh slave3 "mkdir -p /data/hadoop/tmp"
ssh slave3 "mkdir -p /data/hadoop/datanode"
ssh slave4 "mkdir -p /data/hadoop/datanode"
ssh slave4 "mkdir -p /data/hadoop/tmp"
然后切换目录到hadoop安转目录的bin里输入命令
./hdfs namenode -format 进行格式化
格式化完成后转会到hadoop的sbin目录下
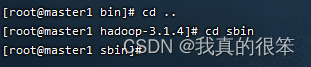
开启进程命令为
./start-dfs.sh
./start-yarn.sh
开启后使用 jps 查看进程是否正常启动
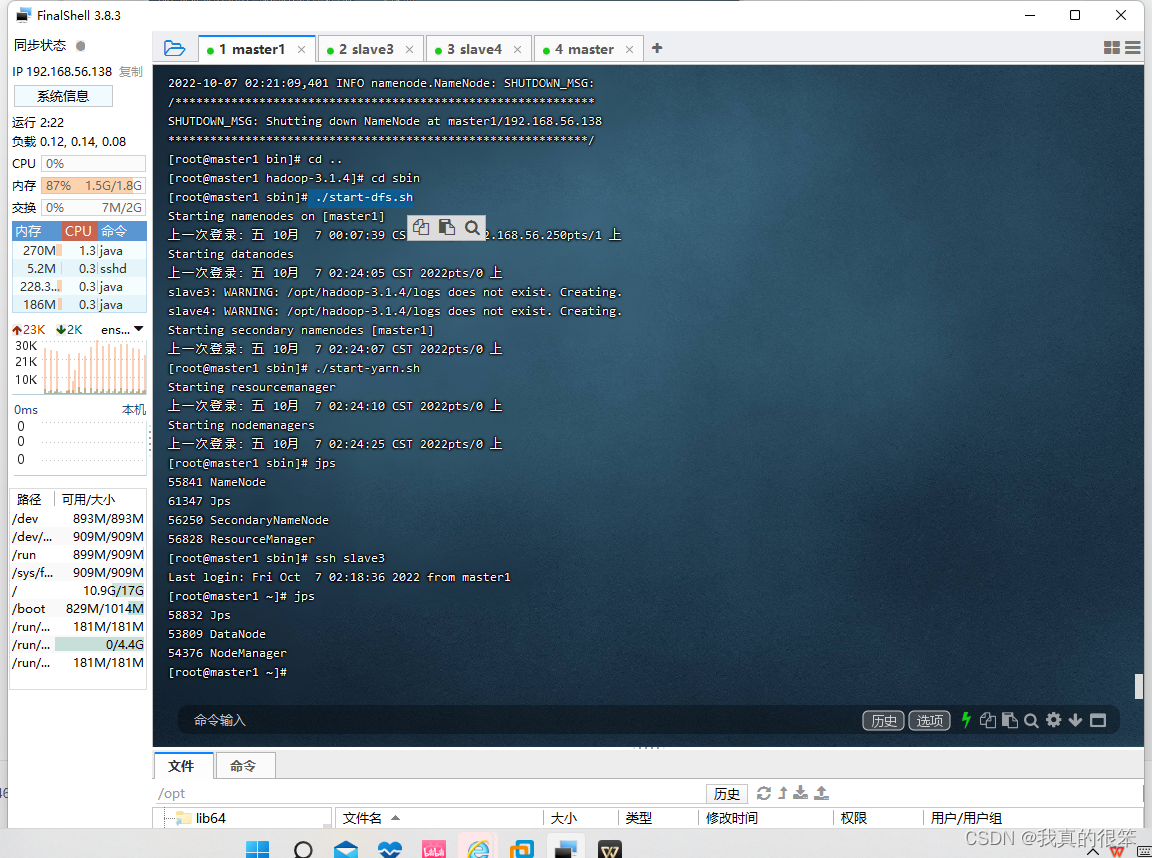
最后就是开启日志进行50070连接
开启命令为
./mr-jobhistory-daemon.sh start historyserver
注意这里为主节点ip
(此次学习主节点为master1,分节点为slave3和slave4)
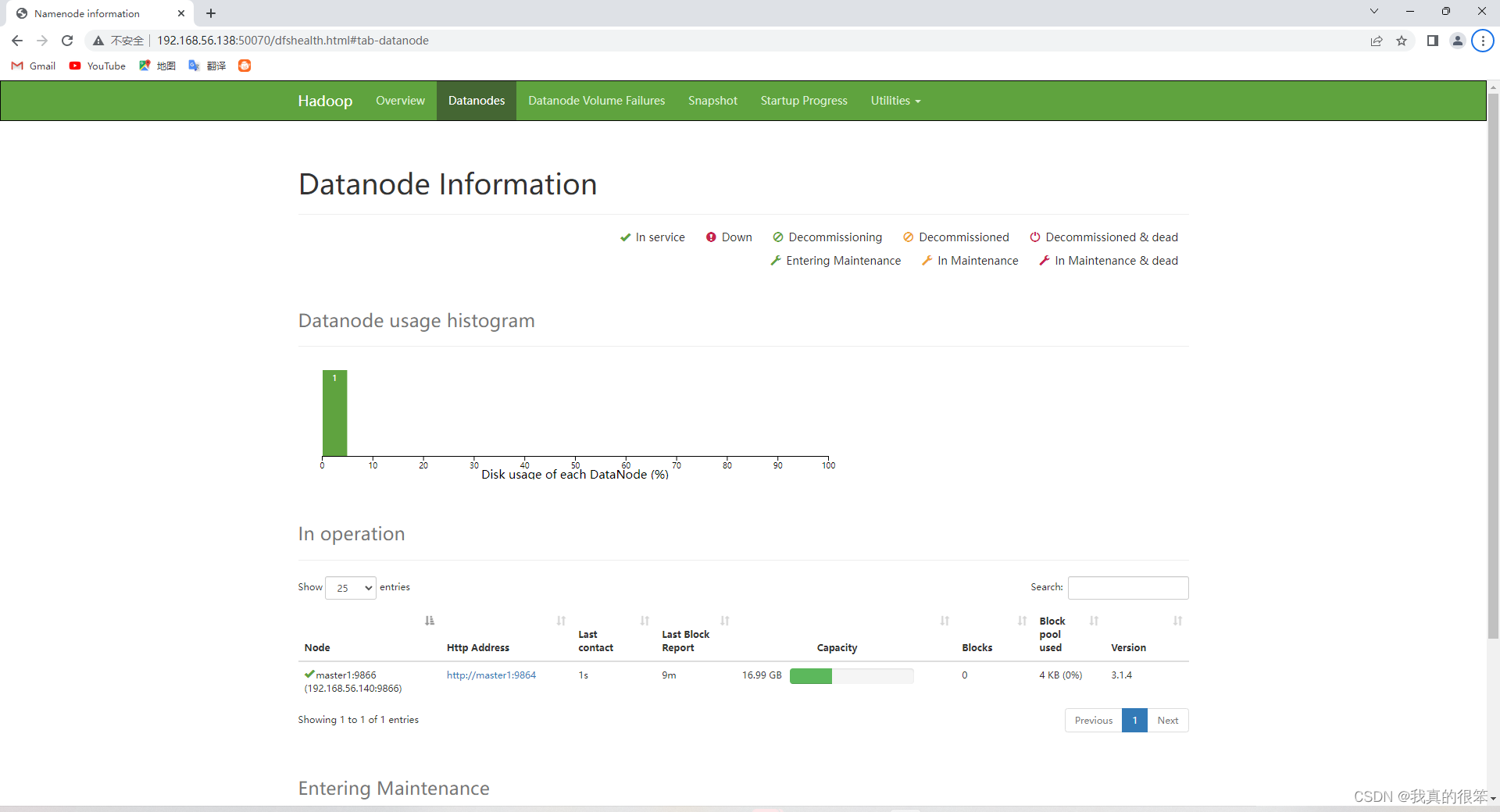
好了,这样我们的完全分布式环境搭建就完成了。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











