







Undo Segment
Undo Segment是Oracle数据库中用来存储Undo数据的一个数据结构。Undo数据主要用于支持事务回滚、MVCC(多版本并发控制)、Flashback查询等功能。
当一个事务执行修改操作时,它会在Undo Segment中生成相应的Undo记录,记录数据修改前的值。这些Undo记录存储在Undo Segments中,创建事务的Undo Segments会为该事务预先分配Undo空间,用于存储这些Undo记录。
当需要回滚该事务时,Oracle数据库将通过Undo Segment中的Undo记录把数据恢复到事务开始之前的状态。
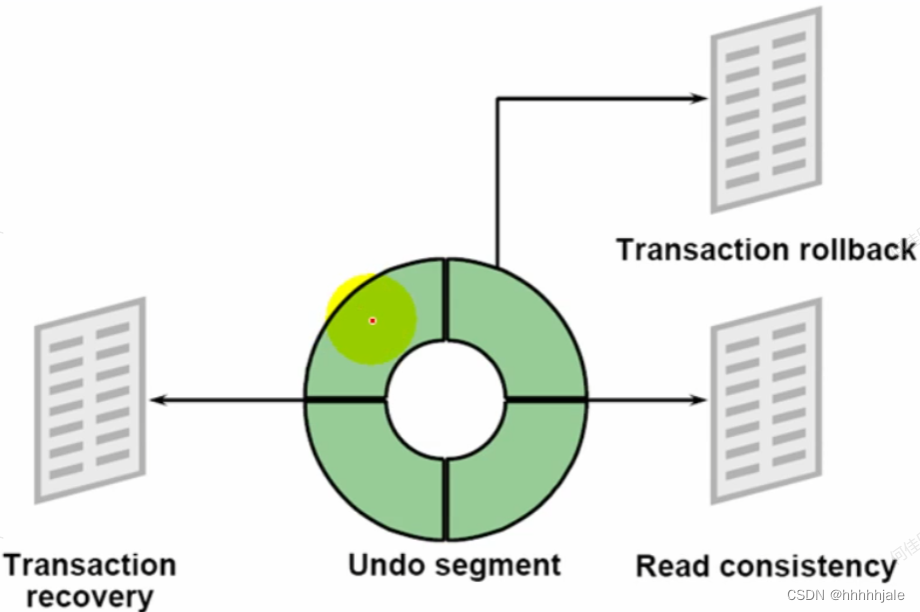
另外,Undo Segment还用于数据库高级功能的实现,例如Flashback查询和恢复,和Supplemental Logging等。
总的来说,Undo Segment是Oracle数据库中一个重要的数据结构,对于数据库的稳定性和性能都非常重要。
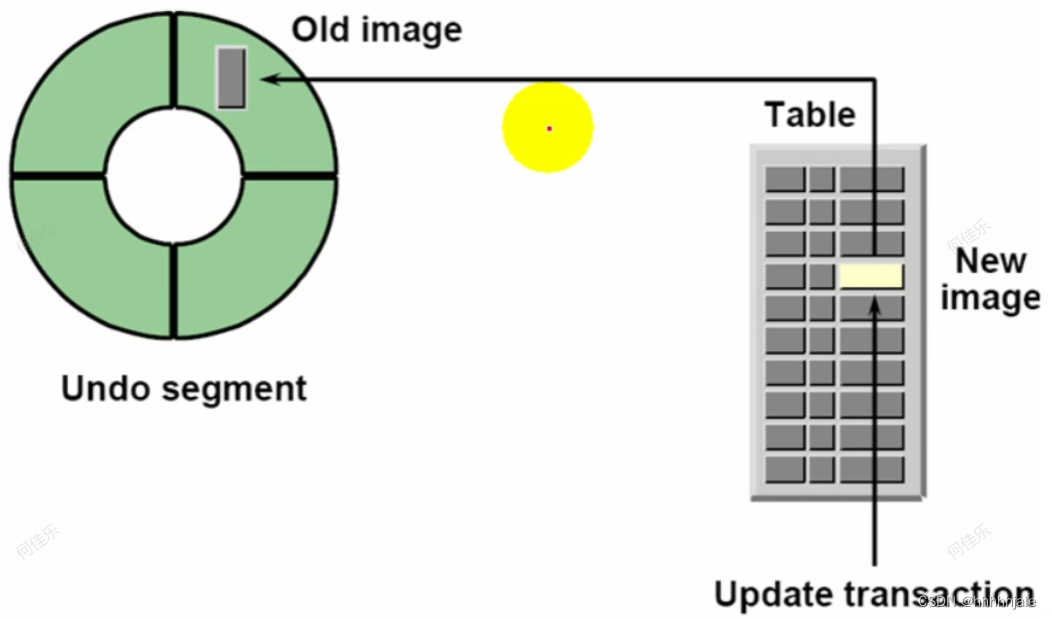
Undo Segments:目的
Undo Segment的主要目的是支持Oracle数据库的事务处理和多版本并发控制(MVCC)。当事务执行数据修改时,它会在Undo Segment中生成相应的Undo记录。这些Undo记录用于记录数据修改前的值,以便在需要回滚事务时将数据恢复到之前的状态。
此外,Undo Segment还支持Oracle数据库的高级功能,例如Flashback查询和数据恢复。Flashback查询是一种能够查询数据库的历史版本的功能,使用Undo Segment中的Undo记录来实现,而数据恢复是一种能够在数据损坏或出现故障时将数据恢复到之前的状态的功能,也需要使用Undo Segments中的Undo记录。
因此,Undo Segment对于Oracle数据库的稳定性和性能都非常重要。它能够确保数据库执行事务时的一致性,并提供一些高级功能来支持数据恢复和查询。
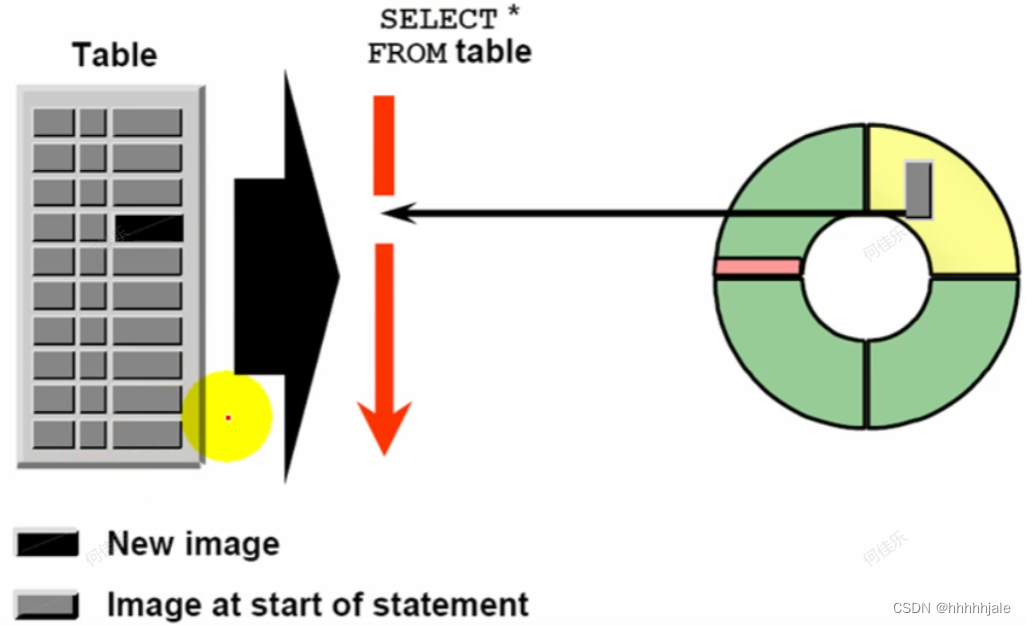
读一致性
在Oracle数据库中,Undo数据的读一致性是指在任何给定的时间点,读取Undo数据应该能够反映出对应事务的数据快照状态,即读取的数据应该与在事务开始时读取的数据一致。也就是说,当一个事务开始执行时,Oracle会为该事务分配一个Undo Segment,在该事务中修改操作所对应的Undo记录都会被写入这个Undo Segment中。当其他事务需要查询该事务修改之前的数据时,它们会从Undo Segment中读取数据。
Oracle使用Undo Segment来实现多版本并发控制(MVCC),MVCC可以确保多个事务之间的读写操作不会相互影响,从而提高了数据库的并发性能。在MVCC中,每个事务都可以看到自己的数据快照,即使其他并发事务在相同的时间同时修改了相同的数据。而这些数据快照就保存在Undo Segment中,当需要读取Undo中的数据时,只会读取相应的事务的数据快照,避免了读到其他事务未提交的数据。
因此,Undo数据的读一致性非常重要,它可以保证读取Undo数据时返回的是修改事务开始时的数据快照,避免读到其他事务未提交的数据,从而确保任何查询都返回正确的结果。
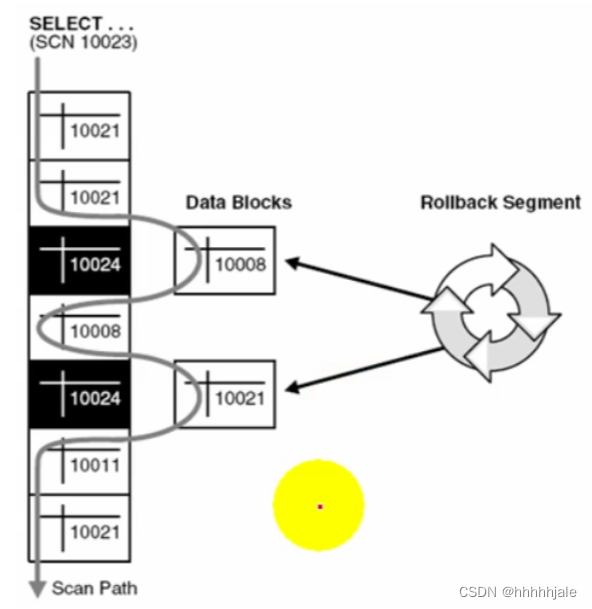
Redo & Undo
Redo和Undo是Oracle数据库中的重要概念,它们分别用于支持数据库的持久性和事务的一致性。
-
Redo(重做):Redo是用来回复或重放数据库中发生的修改操作的记录。当一个事务提交后,Oracle会将该事务对数据库的修改操作记录到Redo日志文件中。Redo日志记录了数据块的物理更改,包括对表、索引和其他数据库对象的插入、更新和删除操作。它们用于在数据库发生故障时恢复数据,并确保数据库的持久性。Redo日志是通过异步地写入磁盘来保证性能,因为它们不直接参与事务的提交过程。
-
Undo(撤销):Undo是用于实现事务的一致性和回滚操作的机制。当一个事务对数据库进行修改时,Oracle会在Undo段(Undo Segment)中创建Undo记录,记录了修改前的数据值。这些Undo记录用于在需要回滚事务或者支持多版本并发控制(MVCC)时恢复数据到之前的状态。Undo记录保持了事务的逻辑一致性,并提供了读取一致性。当一个事务需要读取数据时,如果其他事务对数据进行了修改但尚未提交,可以通过Undo记录提供读取一致性,即读取的是开始事务之前的数据。
因此,Redo和Undo在Oracle数据库中起着不可或缺的作用。Redo确保了数据的持久性和可恢复性,而Undo则保证了事务的一致性和读取一致性。这两个机制共同保障了数据库的安全性和可靠性。
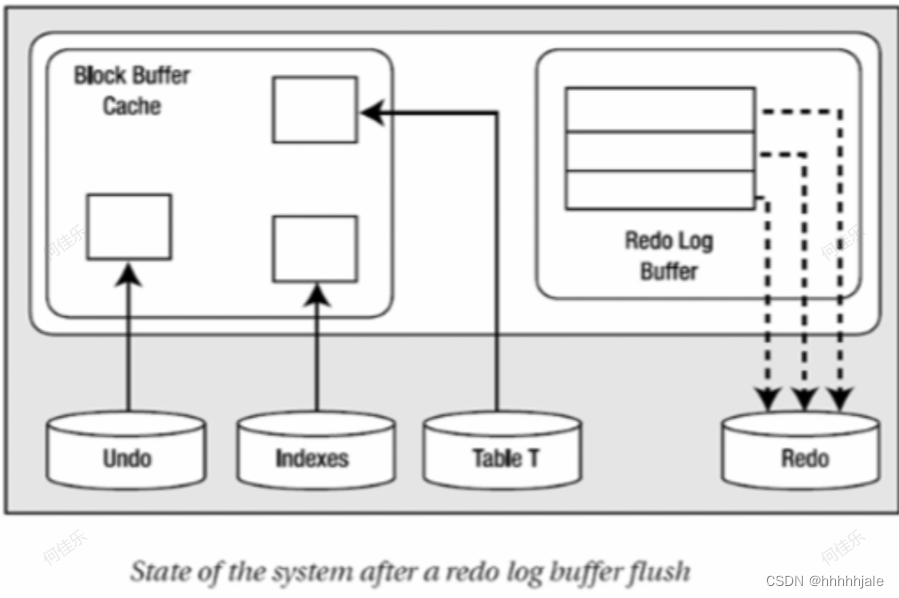
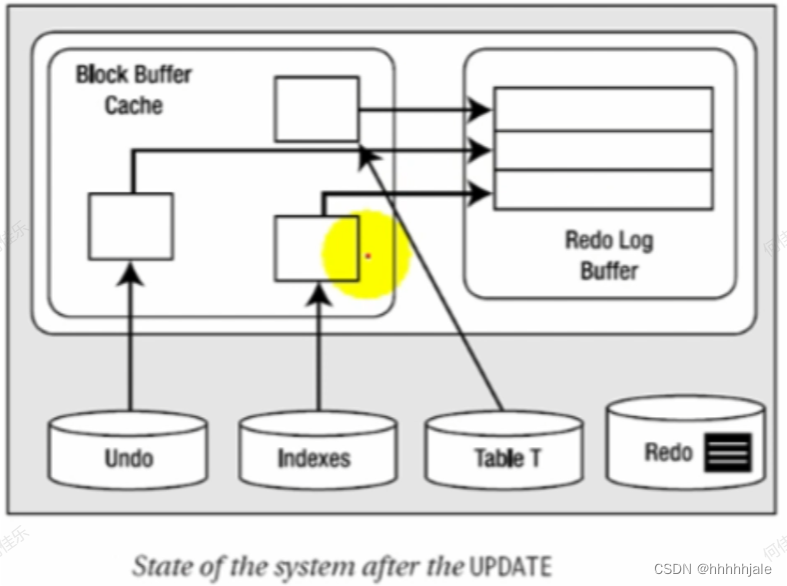
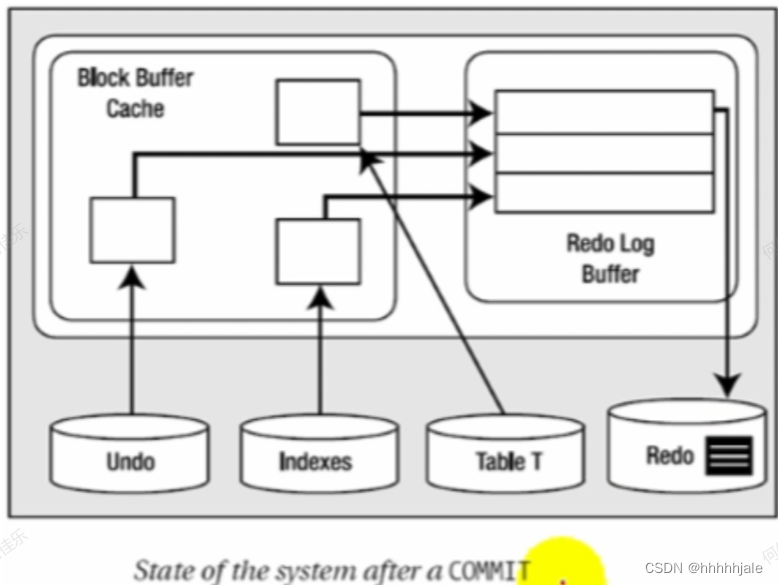
Undo Swgments的类型
SYSTEM:用于SYSTEM表空间中的对象。
非SYSTEM:用于其他表空间中的对象。
Auto模式:
- 需要一个UNDO表空间
手动模式:
- 私人:由单个实例获得
- Public:由任何实例获取
Deferred:当表空间被立即、临时或恢复脱机时使用
Auto Undo Mgmt:概念
Undo数据使用Undo表空间管理。
为每个实例分配一个UNDO表空间,为实例的工作负载提供足够的空间。
Oracle服务器在UNDO表空间中自动维护undo数据。
Auto Undo Mgmt:配置
在初始化文件中配置两个参数:
- UNDO_MANAGEMENT
- UNDO_TABLESPACE
至少创建一个UNDO表空间。

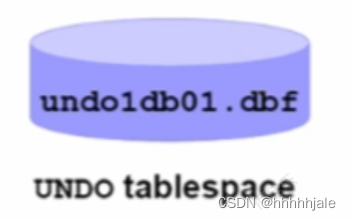
AUM:初始化参数
UNDO_MANAGEMENT:指定系统应该使用AUTO还是MANUAL模式
UNDO_TABLESPACE:指定要使用的特定UNDO表空间
UNDO_MANAGEMENT=AUTO
UNDO_TABLESPACE=UNDOTBSAUM:UNDO Tablespace
使用CREATEDATABASE命令创建UNDO表空间:
CREATE DATABASE db01
...
UNDO TABLESPACE undo1
DATAFILE '/u01/oradata/undo1db01.dbf' SIZE 20M
AUTOEXTEND ON或者稍后使用create UNDO TABLESPACE命令创建:
CREATE KUNDO TABLESPACE undo1
DATAFILE '/u01/oradata/undo01.dbf'
SIZE 20M;AUM:修改UNDO TABLESPACE
ALTER TABLESPACE命令可以修改UNDO表空间。
在UNDO表空间中添加另一个数据文件的示例如下:
ALTER TABLESPACE undotbs
ADD DATAFILE '/u01/oradata/undotbs2.dbf'
SIZE 30M
AUTOEXTEND ON;AUM:切换UNDO TS
您可以从使用一个UNDO表空间切换到另一个。
一个数据库一次只能被分配一个UNDO表空间。
一个实例中可以存在多个UNDO表空间,但只能有一个是活动的。
使用ALTER SYSTEM命令在UNDO表空间之间进行动态切换。
ALTER SYSTEM SET undo_tablespace=undotbs2AUM:删除一个UNDO TS
DROP TABLESPACE命令用来删除UNDO表空间。
DROP TABLESPACE UNDOTBS2;只有当UNDO表空间当前没有被任何实例使用时,它才能被删除。
删除一个活动的UNDO表空间。
- 切换到一个新的UNDO表空间。
- 在所有当前事务完成后删除表空间。
AUM: UNDO Tablespace
使用Create database命令创建UNDO表空间。
CREATE DATABASE db01
...
UNDO TABLESPACE undo1
DATAFILE '/u01/oradata/undo1db01.dbf' SIZE 20M
AUTOEXTEND ON或者稍后使用create UNDO TABLESPACE命令创建:
CREATE UNDO TABLESPACRE undo1
DATAFILE '/u01/oradata/undo1db01.dbf'
SIZE 20M;AUM:其他参数
UNDO_SUPPRESS_ERRORS参数:
- 设置为TRUE,此参数在试图在AUTO模式下执行手动操作时抑制错误。
UNDO_RETENTION参数:
- 该参数控制为了一致性读而保留的undo数据量。
Undo Data 统计
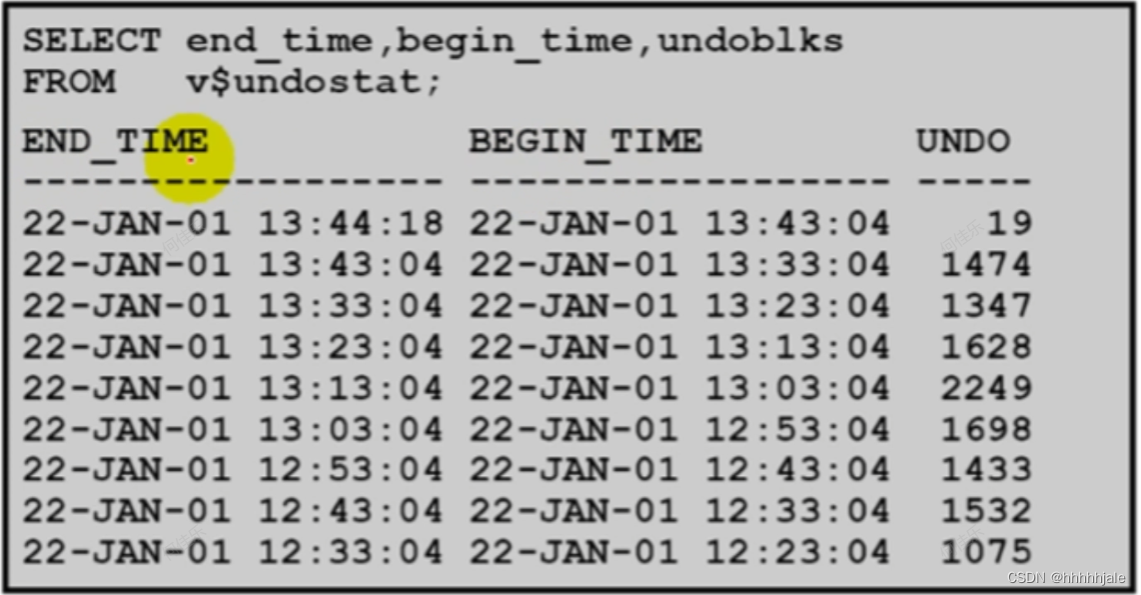
AUM:调整UNDO TS的大小
确定UNDo表空间的大小需要三个信息:
(UR) UNDO_RETENTION,单位为秒
(UPS)每秒产生的撤消数据块数量
(DBS)开销根据扩展和文件大小而变化(db_block_size)

AUM:Undo 配额
- 长事务和不正确编写的事务会消耗宝贵的资源。
- 使用undo配额,可以对用户进行分组,并为组分配最大的undo空间限制。
- UNDO_POOL,一个资源管理器指令,定义资源组允许的空间量。
- 当一个组超过其限制时,该组不可能有新的事务,直到撤消空间被正在完成或中止的当前事务释放。
获取Undo段信息
可以通过以下视图查询undo段的信息:
- DBA_ROLLBACK_SEGS
动态性能视图
- V$ROLLNAME
- V$ROLLSTAT
- V$UNDOSTAT
- V$SESSION
- V$TRANSACTION
存储用户数据
Regular table

在Oracle数据库中,"Regular table"指的是普通的数据表,即不是特殊类型(如视图、临时表等)的普通表。这些表可以通过SQL语句进行创建、修改、删除和查询等数据库操作,也是存储用户数据的主要方式之一。
通常情况下,创建一个普通表需要指定表名、列名、列类型等基本信息,并可以设置各种约束(如主键、唯一约束、外键等)。在表中存储的数据以行的形式呈现,每一行对应于表中的一个数据项,每一列表示一个属性。
例如,可以使用以下语句在Oracle数据库中创建一个名为"employees"的普通表:
CREATE TABLE employees (
employee_id NUMBER(6) PRIMARY KEY,
first_name VARCHAR2(20) NOT NULL,
last_name VARCHAR2(25) NOT NULL,
email VARCHAR2(25),
phone_number VARCHAR2(20),
hire_date DATE NOT NULL,
job_id VARCHAR2(10) NOT NULL,
salary NUMBER(8,2),
commission_pct NUMBER(2,2),
manager_id NUMBER(6)
);该语句定义了一个名为“employees”的表,包括11个列,其中第一个(employee_id)为主键列,其他列中包含非空约束、数据类型等信息。这个表可以用于存储员工信息。
Partitioned table

分区表(Partitioned table)是 Oracle 数据库中的一种特殊类型的表,它将数据水平分割成多个逻辑分区,每个分区可以独立进行管理和维护。
分区表具有以下特点和优势:
-
数据划分:分区表可以将数据划分成多个分区,每个分区可以基于某个列的值范围、列表、哈希等方式进行划分,从而将大规模数据集细分成更小的子集,提高查询效率和数据管理的灵活性。
-
查询性能优化:通过使用分区键进行查询,可以只访问涉及特定分区的数据,从而减少全表扫描的开销,提高查询性能。
-
管理灵活性:可以针对不同的分区应用不同的管理策略,比如备份和恢复、数据压缩、索引维护等,从而更加灵活地管理和维护数据。
-
冗余数据控制:可以通过分区表将数据按照时间进行分割,可以轻松实现数据的定期删除或归档,从而减少冗余数据,提高存储效率。
以下是一个创建分区表的示例:
CREATE TABLE sales (
sales_id NUMBER,
sales_date DATE,
sales_amount NUMBER,
region VARCHAR2(50)
)
PARTITION BY RANGE (sales_date)
(
PARTITION sales_q1 VALUES LESS THAN (TO_DATE('2023-04-01', 'YYYY-MM-DD')),
PARTITION sales_q2 VALUES LESS THAN (TO_DATE('2023-07-01', 'YYYY-MM-DD')),
PARTITION sales_q3 VALUES LESS THAN (TO_DATE('2023-10-01', 'YYYY-MM-DD')),
PARTITION sales_q4 VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);以上示例创建了一个名为"sales"的分区表,按照"sales_date"列的值范围进行划分,分为四个季度的分区。根据具体的业务需求,您可以根据不同的列或条件进行不同类型的分区,以适应您的数据处理和查询需求。
Index-Organized Table

索引组织表(Index-Organized Table,简称为IOT)是 Oracle 数据库中的一种特殊类型的表,它将数据组织成一个索引结构以提高查询性能。
与传统的堆表(Heap table)不同,索引组织表的数据行直接按照主键顺序存储在表的索引结构中,称为主索引(Primary Index)。主索引的叶子节点中存储着数据行。因此,实际上索引组织表和主索引是同一对象。
索引组织表具有以下特点和优势:
-
查询性能:索引组织表排列的数据行直接按照主键顺序存储,因此等值条件查询的性能较高,可以减少磁盘访问次数,提高查询效率。
-
索引结构:索引组织表和主索引是同一对象,不需要再次创建单独的索引,可以节省磁盘空间和维护成本。
-
主键顺序维护:在大多数情况下,索引组织表中的数据行会按照主键值的顺序存储,因此可以很方便地使用主键值进行范围查询,避免全表扫描。
以下是一个创建索引组织表的示例:
CREATE TABLE employees (
employee_id NUMBER(6),
first_name VARCHAR2(20),
last_name VARCHAR2(25),
hire_date DATE,
salary NUMBER(8,2),
department_id NUMBER(4),
CONSTRAINT pk_employee PRIMARY KEY (employee_id)
)
ORGANIZATION INDEX;以上示例创建了一个名为"employees"的索引组织表,它的主键是"employee_id"列。ORGNIZATION INDEX语句指定这个表使用索引组织方式组织数据,并将主键作为索引结构的关键字段。当我们使用等值查询或按照主键顺序查询时,查询将直接在主索引中进行,从而提高查询速度。
Cluster

在数据库中,聚簇(Cluster)是一种物理存储结构,用于将具有相似特征的行存储在物理上相邻的位置,以提高查询性能和减少磁盘访问次数。
聚簇使用相同或相关列的值来组织数据,并且这些列通常是常用于联接或经常一起查询的列。通过将相关数据行存储在物理上相邻的位置,聚簇可以减少磁盘的随机读取,从而提高查询效率。
以下是一些关于聚簇的重要要点:
-
聚簇表(Clustered table):聚簇表是通过聚簇来组织数据的表。聚簇键(Cluster Key)是用于确定聚簇中行存储位置的属性或列。
-
聚簇索引(Clustered index):聚簇索引是聚簇表的索引结构,用于加速对聚簇表的访问。聚簇索引与聚簇键是一一对应的,它定义了数据在聚簇表中的物理存储顺序。
-
聚簇与非聚簇索引:与聚簇索引不同的是,非聚簇索引(Non-clustered index)是独立于数据行的索引结构,它包含索引键及其对应的行指针。查询时,可以通过非聚簇索引快速定位到对应的行。
-
聚簇表的创建与维护:在创建聚簇表时,需要指定聚簇键并选择适当的索引选项。维护聚簇表时,插入、更新或删除操作可能导致聚簇键的变化,从而需要重新组织或重建聚簇表。
聚簇在数据库中的使用需要根据具体情况和业务需求进行评估和决策。它适用于那些经常需要联接或同时访问相关数据的场景,可以显著提高查询性能和响应时间。然而,过度或不正确使用聚簇可能会导致额外的维护成本和资源消耗。因此,在设计和实施聚簇时,需要充分考虑数据库的负载、查询模式和预期的性能收益。
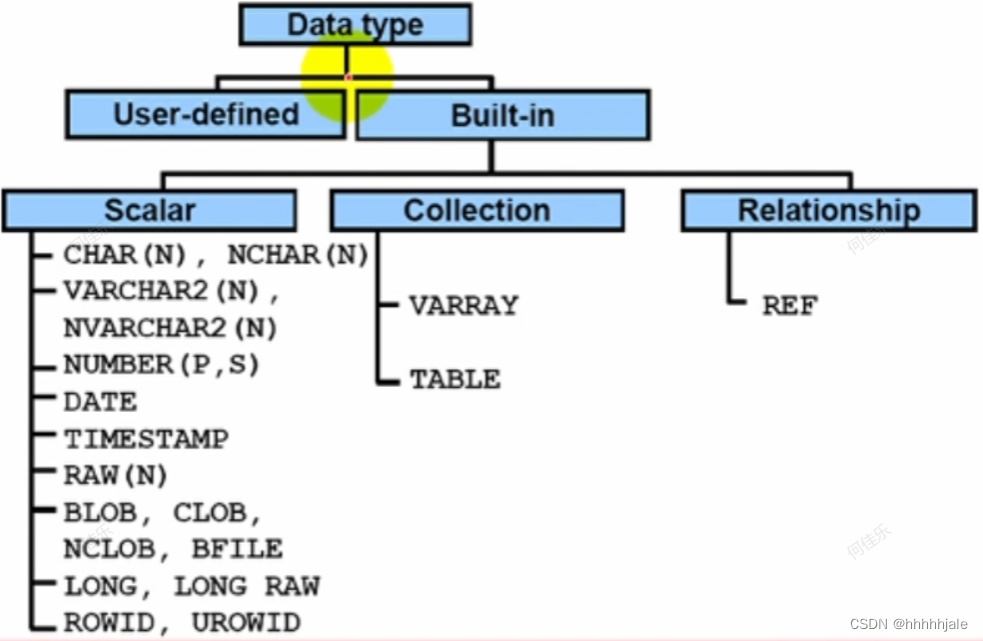
Oracle内置数据类型
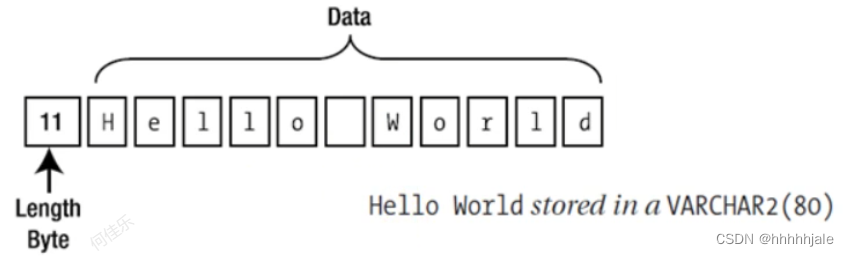
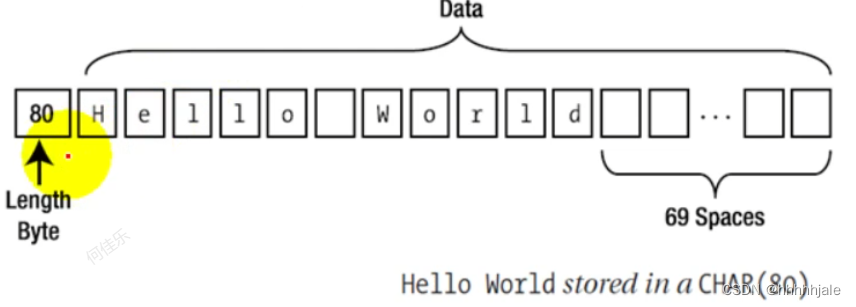
char&varchar2
表的一般信息
下面是一些关于表的一般信息,不管它们的类型是什么:
- 一个表最多可以有1000列,尽管我不建议使用包含最大列数的设计,除非有一些迫切的需要。如果表的列数远远少于1000列,则效率最高。Oracle内部会将超过254列的行存储在彼此指向的单独行块中,并且必须重新组装以产生整个行映像。
- 一个表实际上可以有无限的行数,尽管你会遇到其他限制来阻止这种情况的发生。例如,通常一个表空间最多可以有1,022个文件(尽管在Oracle 10g中有新的BIGFILE表空间,也可以使您超过这些文件大小限制)。假设你有32GB的文件——也就是说,每个表空间有32,704GB。这将是2,143,289,344个块,每个块的大小为16KB。你可能能够容纳160行,每个块的大小在80到100字节之间。这将给你342,926,295,040行。但是,如果对表进行分区,您可以轻松地将这个数字乘以许多次。例如,考虑一个有1,024个哈希分区的表——这将是1024 × 342,926,295,040行。这是有限制的,但在接近这些数字之前,您会遇到其他实际限制。
- 一个表可以有多少个索引,就有多少列的排列(以及这些列上的函数的排列)。随着基于函数的索引的出现,理论上可以创建的索引的真实数量变得无限!然而,再一次,实际的限制将限制您将创建和维护的索引的实际数量。
- 即使在单个数据库中,您可能拥有的表的数量也没有限制。然而,实际的限制将使这个数字保持在合理的范围内。您不会有数百万个表(创建和管理这么多表是不切实际的),但您可能有数千个表。
ROWID格式
扩展ROWID格式

受限ROWID格式(不考虑)

使用ROWID定位行
ROWID是一种数据类型,可以与表中的其他列一起查询。它具有以下特点:
- ROWID是数据库中每一行的唯一标识符。
- ROWID没有显式地存储为列值。
- 虽然ROWID不直接给出行的物理地址,但它可以用来定位行。
- ROWID提供了访问表中行的最快方法。
- rowid存储在索引中,以指定具有给定键值集的行。
由于一个段只能驻留在一个表空间中,因此Oracle服务器可以通过使用数据对象号来确定包含一行的表空间。
表空间中的相对文件号用于定位文件,块号用于定位包含该行的块,行号用于定位该行所在的行目录项。
行目录条目可用于定位行开头。因此,ROWID可用于定位数据库中的任何行。
一行的结构
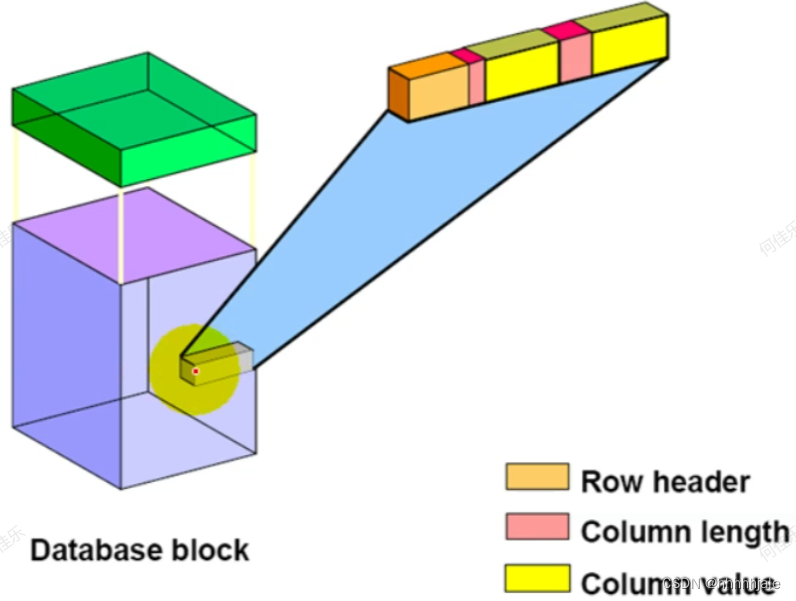
行数据作为变长记录存储在数据库块中。一行的列通常按照定义的顺序存储,任何末尾的NULL列都不存储。
注意:对于非尾空列,列长度需要单个字节。表中的每一行都有:
- 行头:用于存储该行的列数、链接信息和行锁状态
- 行数据:对于每个列,Oracle服务器存储列长度和值(如果列需要超过250字节的存储空间,则需要一个字节来存储列长度,在这种情况下,将使用三个字节来存储列长度)。列值紧跟在列长度字节之后存储。)
相邻行之间不需要任何空格。块中的每一行在行目录中都有一个槽。目录槽指向该行的开头。
创建一个表
CREATE TABLE hr.employees(
employee_id NUMBER(6),
first_name VARCHAR2(20),
LAST_NAME VARCHAR2(25),
email VARCHAR2(25)
phone_number VARCHAR2(20),
hire_data DATA DFFAULT SYSDATE,
job_id VARCHAR2(10),
salary NUMBER(8,2),
commission_pct NUMBER(2,2),
manager_id NUMBER(6),
department_id NUMBER(4))
TABLESPACE USERS;现在您已经知道了如何查看给定CREATE TABLE语句中可用的大多数选项,那么对于堆表来说,哪些选项是需要注意的重要选项呢?在我看来,用ASSM的有两个,用MSSM的有四个:
- FREELISTS:仅限MSSM。每个表在一个自由列表上管理它在堆中分配的块。一个表可以有多个自由链表。如果您预计许多并发用户将大量插入到表中,那么配置多个自由列表可以对性能产生重大的积极影响(以可能的额外存储为代价)。参考前面的讨论和“FREELISTS”一节中的示例,了解这种设置对性能的影响。(不太需要)
- PCTFREE:包括ASSM和MSSM。在INSERT过程中,一个块可以被填满多少的度量。如前所述,这用于根据块当前的满程度来控制是否可以将一行添加到块中。此选项还用于控制后续更新导致的行迁移,需要根据表的使用方式进行设置。
- PCTUSED:仅MSSM。衡量一个块必须空到什么程度才能再次成为插入的候选对象。使用的空间小于PCTUSED的块是插入新行的候选块。同样,与PCTFREE一样,您必须考虑如何使用表来适当地设置此选项。(不用)
- initran:包括ASSM和MSSM。初始分配给一个块的事务槽数。如果设置过低(默认值为2,并且最小值为2),此选项可能会导致被许多用户访问的块中的并发问题。如果一个数据库块几乎满了,事务列表不能动态扩展,会话将排队等待这个块,因为每个并发事务需要一个事务槽。如果你相信你会有很多对相同块的并发更新,你应该考虑增加这个值
创建表的原则
- 将表放置在单独的表空间中。
- 使用本地管理的(locally-managed)表空间来避免碎片。
- 为表使用少量标准区段大小以减少表空间碎片。
创建临时表
- 使用GLOBAL TEMPORARY子句创建:
CREATE GLOBAL TEMPORARY TABLE
hr.employees_temp
AS SELECT * FROM hr.employees;- 表仅在事务或会话期间保留数据。
- 不从数据上获取DML锁。
- 您可以在临时表上创建索引、视图和触发器。
临时表
临时表用于在事务或会话期间保存中间结果集。保存在临时表中的数据只对当前会话可见——其他会话不会看到任何其他会话的数据,即使当前会话提交了数据。对于临时表来说,多用户并发性也不是问题,因为一个会话永远不能通过使用临时表来阻塞另一个会话。即使我们“锁定”临时表,它也不会阻止其他会话使用它们的临时表。临时表比普通表产生的重做要少得多。然而,由于它们必须为它们所包含的数据生成撤销信息,因此它们将生成一定数量的重做。UPDATEs和DELETEs将产生最大的量;INSERTs和SELECTs产生的量最少。
临时表将从当前登录用户的临时表空间分配存储空间,或者如果从定义器权限过程访问临时表空间,则将使用该过程所有者的临时表空间。全局临时表实际上只是表本身的模板。创建临时表的行为不涉及存储分配;不像普通表那样分配初始区。相反,在运行时,当会话第一次将数据放入临时表时,将为该会话创建一个临时段。由于每个会话都有自己的临时段(而不仅仅是现有段的范围),每个用户可能会在不同的表空间中为她的临时表分配空间。USER1可能把他的临时表空间设置为TEMP1,所以他的临时表将从这个空间分配。USER2可能有TEMP2作为她的临时表空间,她的临时表将被分配到那里。
Oracle的临时表与其他关系数据库中的临时表类似,主要的区别是它们是“静态”定义的。每个数据库创建一次临时表,而不是数据库中的每个存储过程创建一次。它们始终存在——它们将作为对象存在于数据字典中,但在会话将数据放入它们之前,它们始终显示为空。它们是静态定义的事实允许您创建引用的视图临时表,创建使用静态SQL引用它们的存储过程,等等。
临时表会产生最少的重做,但它们仍然会产生一些重做,并且没有办法禁用它。重做是为回滚数据生成的,在大多数典型的使用中,它可以忽略不计。如果你只对临时表进行INSERT和SELECT操作,那么重做产生的量是不明显的。只有当你大量地删除或更新临时表时,你才会看到大量的重做产生。CBO使用的统计数据可以谨慎地在临时表上生成;但是,可以使用DBMS_STATS包在临时表上设置更好的统计数据猜测集,或者由优化器在硬解析时使用动态采样动态收集。
设置PCTFREE和PCTUSED
计算PCTFREE

计算PCTUSED

行迁移和链接
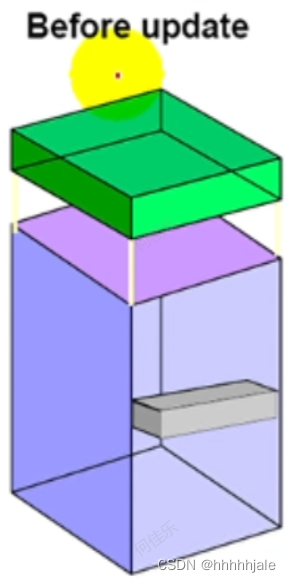
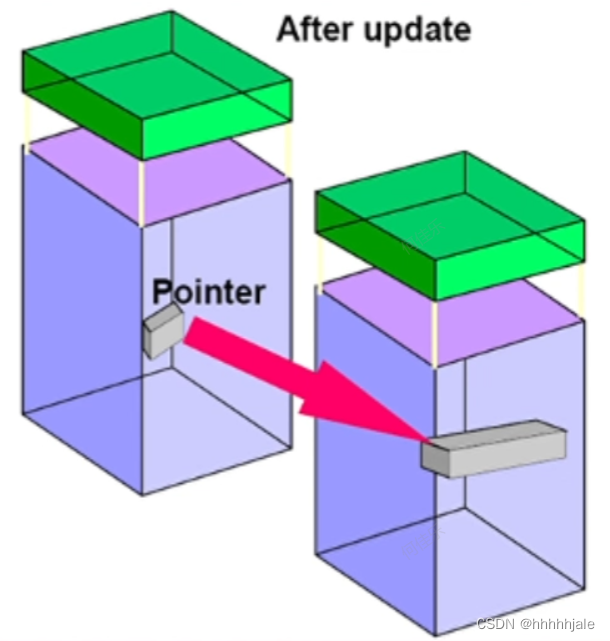
行迁移(Row Migration)
如果PCTFREE设置为较低的值,则块中可能没有足够的空间来容纳由于更新而增长的行。当这种情况发生时,Oracle服务器将整个行移动到一个新的块,并留下一个从原始块到新位置的指针。这个过程被称为行迁移。当一行被迁移时,与该行相关的输入/输出(I/O)性能会下降,因为Oracle服务器必须扫描两个数据块来检索数据。
行链接(Row Chaining)
当行太大而无法放入任何块时,就会发生行链接。当行包含非常长的列时,可能会发生这种情况。在这种情况下,Oracle服务器将行分成更小的块,称为行块。每个行块都存储在一个块中,以及检索和组装整行所需的指针。如果可能的话,可以通过选择更大的块大小或将表分成多个列更少的表来最小化行链。
存储和块参数
ALTER TABLE hr.employees
PCTFREE 30
PCTUSED 50
STORAGE(NEXT 500K
MINEXTENTS 2
MAXEXTENTS 100);改变SP的影响
可修改的参数及修改的影响如下:
- 下一步:当Oracle服务器为表分配另一个区段时,将使用新的值。后续的区段大小将增加PCTINCREASE。
- PCTINCREASE:在数据字典中注册PCTINCREASE的更改。它用于在Oracle服务器分配下一个区段时重新计算NEXT。考虑一个有两个区段的表,其中NEXT=10K, PCTINCREASE=0。如果将PCTINCREASE更改为100,则分配的第三个区段将是10 KB,第四个区段将是20 KB,第五个区段将是40 KB,以此类推。
- MINEXTENTS: MINEXTENTS的值可以修改为小于或等于表中当前区段数的任何值。它不会立即对表产生影响,但会在表被截断时使用。
- MAXEXTENTS: MAXEXTENTS的值可以设置为等于或大于表当前区段数的任何值。该值也可以设置为UNLIMITED。
手动分配区段
ALTER TABLE hr.employees
ALLOCATE EXTENT(SIZE 500K
DATAFILE '/DISK3/DATA01.DBF');可能需要手动分配区段:
- 控制表的区段跨文件的分布
- 在批量加载数据之前,以避免表的动态扩展
如果省略SIZE, Oracle服务器将使用DBA_TABLES中的NEXT_EXTENT大小来分配区段。
DATAFILE子句中指定的文件必须属于该表所属的表空间。否则,语句会产生错误。如果不使用DATAFILE子句,Oracle服务器将在包含表的表空间中的一个文件中分配区段。
注意:DBA_TABLES中的NEXT_EXTENT值不会受到手动extentX分配的影响。执行此命令时,Oracle服务器不会重新计算下一个extent的大小。
非分区表重组
ALTER TABLE hr.employees
MOVE TABLESPACE data1;- 重组非分区表时,保留其结构,但不保留其内容。
- 它用于将表移动到不同的表空间或重新组织区段。
无需运行Export或Import实用程序就可以移动非分区表。此外,它还允许更改存储参数。这在以下情况下很有用:
- 将表从一个表空间移动到另一个表空间
- 重新组织表以消除行迁移
截断表
TRUNCATE TABLE hr.employees;- 截断表将删除表中的所有行并释放已使用的空间。
- 相应的索引被截断。
使用该命令的效果如下:
- 删除表中的所有行。
- 由于TRUNCATE TABLE是一个DDL命令,因此不会生成undo数据,并且隐式地提交命令。
- 相应的索引也被截断。
- 被外键引用的表不能被截断。
- 使用此命令时,删除触发器不会触发。
使用TRUNCATE语句从表或集群中删除所有行。默认情况下,Oracle数据库还会执行以下任务:
- 释放被删除的行使用的所有空间,除了NINEXTENTS存储参数指定的空间
- 将NEXT存储参数设置为连接进程从段中删除的最后一个区段的大小
使用TRUNCATE语句删除行可能比删除并重新创建表更有效。删除和重新创建表会使表的依赖对象失效,需要您重新授予表上的对象权限,并且需要您重新创建表上的索引,完整性约束和触发器并重新指定其存储参数。截断没有这些影响。
使用TRUNCATE语句删除行可能比使用DELETE语句删除所有行更快,特别是如果表具有numerous触发器、索引和其他依赖项。
删除表
DROP TABLE hr.departments
CASCADE CONSTRAINTS;- 删除表时,表所使用的区段将被释放。如果它们是连续的,它们可以在稍后的阶段自动或手动合并。
- 如果表是外键关系中的父表,则CASCADECONSTRAINTS选项是必需的。
删除一列(不常用)
从表中删除一列:
ALTER TABLE hr.employees
DROP COLUMN comments
CASCADE CONSTRAINTS CHECKPOINT 1000;- 从每行删除列长度和数据,从而释放数据块中的空间。
- 在大型表中删除列需要花费相当多的时间。
Oracle服务器允许从表的行中删除列。删除列可以清除未使用的和可能需要空间的列,而无需导出或导入数据,并重新创建索引和约束。
删除列可能会花费大量时间,因为该列的所有数据都将从表中删除。
在Oracle8i之前,不可能从表中删除列。
删除列可能非常耗时,并且需要大量的撤消空间。在从大型表中删除列时,可以指定检查点来最小化使用撤销空间。在幻灯片中的示例中,检查点每1000行出现一次。的表被标记为INVALID,直到操作完成。参考中的STATUS列DBA_OBJECTS视图。如果实例在操作过程中失败,表仍然存在启动时INVALID,必须完成操作。
使用以下语句恢复中断的删除操作:SQL> ALTER TABLE hr. SQLdelete COLUMNS CONTINUE;使用这个会在表处于VALID状态时产生错误。
表中重命名列
代码:
ALTER TABLE hr.employees
RENAME COLUMN hire_date
TO start_date;在Oracle9i Database Release 2中,对于属于关系表的列,可以使用重命名列的功能。带连接索引的表不能重命名列,在允许重命名之前必须先删除索引。
重命名列后,函数索引和检查约束仍然有效,但是视图、触发器、域索引、函数、过程和包将失效。如果由于列名更改而导致上述重新验证失败,则必须使用新名称解决问题。
允许重命名具有物化视图的表和涉及复制的表。如果随后出现物化视图中的错误,则必须修改物化视图以解决问题。语法为:
ALTER TABLE [schema.]table_name RENAME COLUMN old_column_name RO new_column_name;
使用UNUSED标签
- 可以将列标记为未使用,然后再将其删除,而不是从表中删除列。这样做的优点是相对较快,因为它不会因为数据没有被删除而回收磁盘空间。标记为未使用的列可以在以后系统活动较少的时候从表中删除。
- 未使用的列就像它们不是表的一部分一样。查询无法看到未使用列中的数据。此外,当执行DESCRIBE命令时,不会显示这些列的名称和数据类型。用户可以添加一个与未使用的列同名的新列。
- 在删除列之前将其设置为未使用的一个示例是,当您想要删除同一表中的两个列时。当你删除两列时,表中的所有行都会被更新两次。但是,当您将这些列设置为未使用,然后删除这些列时,这些行只更新一次。
将列标记为未使用:
ALTER TABLE hr.employees
SEET UNUSED COLUMN comments CASCADE
CONSTRAINTS;删除未使用的列:
ALTER TABLE hr.employees
DROP UNUSED COLUMNS CHECKPOINT 1000;继续删除列操作:
ALTER TABLE hr.employees
DROP COLUMNS CONTINUE CHECKPOINT 1000;获取表信息
可以通过查询以下视图获取表的信息:
- DBA_TABLES
- DBA_OBJECTS
指标分类
逻辑:
- 单列或串联
- 唯一或非唯一
- 基于函数的
- 域
物理:
- 分区或非分区
- B-tree:正反键
- 位图
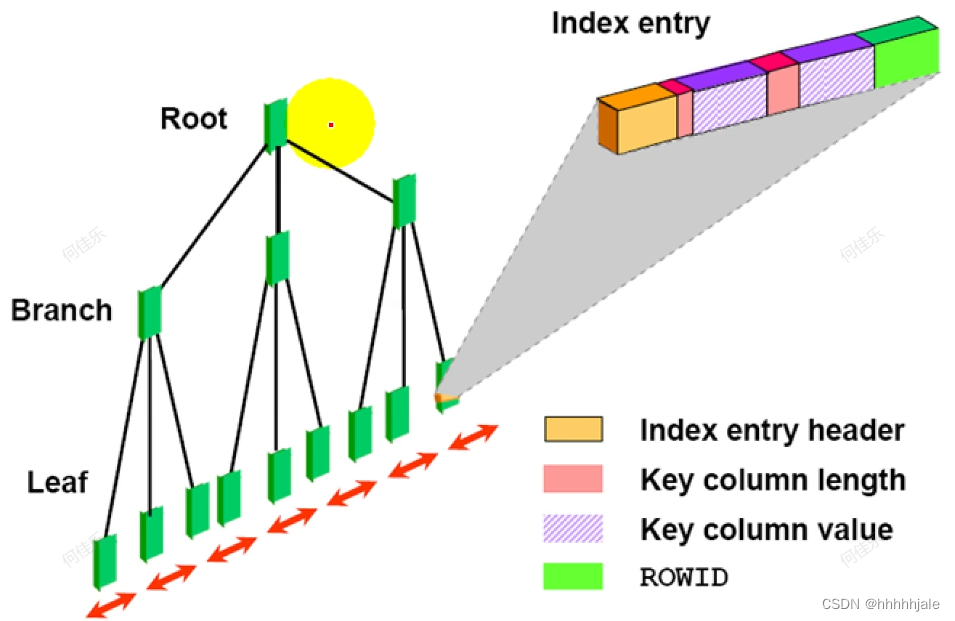
b-tree 索引
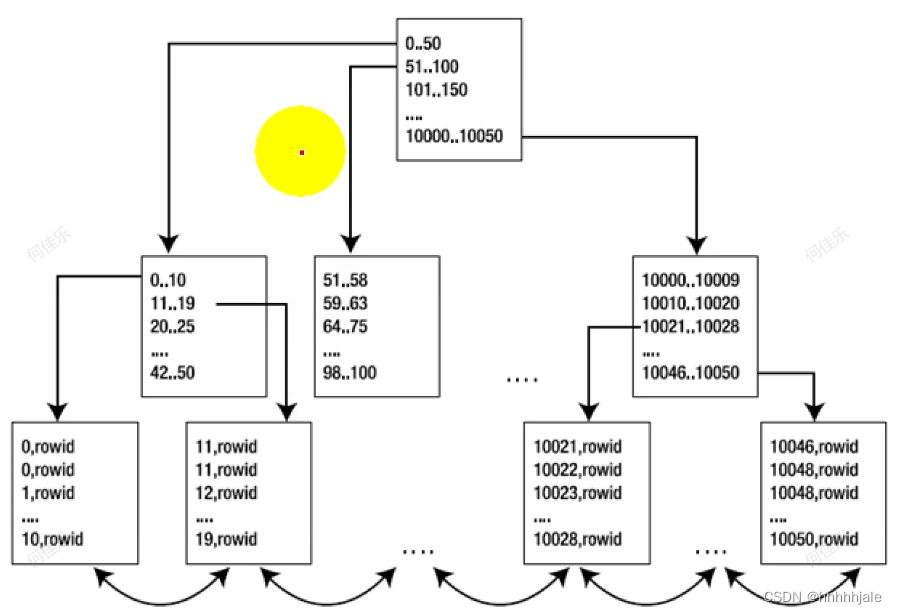
B-tree(或平衡树)是一种常用的数据结构,用于在数据库和文件系统中实现索引。B-tree 索引是一种多叉树,它在每个节点上存储键值和指向子节点的指针。
B-tree 索引具有以下特点:
- 平衡性:B-tree 索引是平衡树,即各级子树的高度差不超过 1,这保证了检索的高效性。
- 自平衡:当插入或删除数据时,B-tree 会自动重新平衡和调整节点,以维持平衡树的结构和性能。
- 多级节点:B-tree 索引由多级节点构成,每个节点可以包含多个关键字。这样可以减少磁盘读取次数,提高数据访问效率。
- 范围查询:B-tree 索引支持范围查询,可以快速定位到符合查询条件的数据范围。
- 顺序访问:B-tree 索引中的数据是按键值顺序存储的,所以可以支持顺序访问,适合于排序和范围查询操作。
B-tree 索引在数据库中被广泛应用,尤其是在处理大量数据和频繁更新的场景下,可以提高数据库的性能和查询效率。它是现代数据库管理系统中的重要组成部分之一。
创建B-Tree索引
CREATE INDEX hr.employees_last_name_idx
ON hr.employees(last_name)
PCTFREE 30
STORAGE(INITIAL 200K NEXT 200K
PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx;创建索引:指南
- 平衡查询和DML需求。
- 放置在单独的表空间中。
- 使用统一的范围大小:5块的倍数或最小extent大小。
- 考虑对大索引使用NOLOGGING。
- 索引上的INITRANS通常应该高于相应表上的INITRANS。
创建索引实例
CREATE UNIQUE INDEX IND2_ORDERS
ON ORDERS (ORDER_NUM)
TABLESPACE USER_INDEX
PCTFREE 25
INITRANS 2
MAXTRANS 255
STORAGE (INITIAL 128K NEXT 128K PCTINCREASE 0
MINEXTENTS 1 MAXEXTENTS 100
FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL KEEP);位图索引
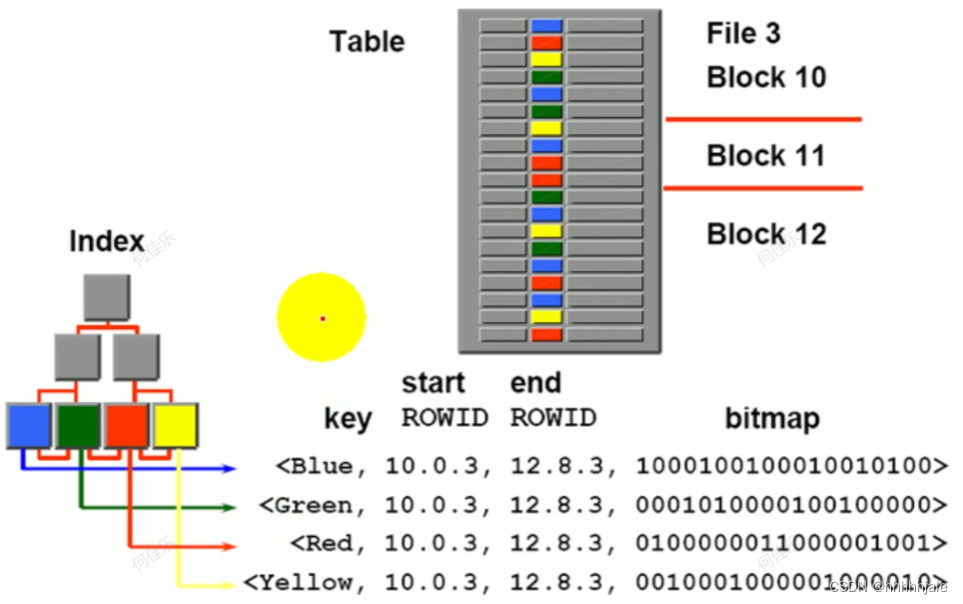
位图索引是一种用于高效查询布尔值类型数据的索引技术,可以用于快速处理数据的聚合、过滤、计数和分析等操作。位图索引的原理是将每个数据值映射为一个二进制位,并将相同数据值的位图合并成一个整数数组。
例如,在一个包含100万条记录的表中,有一列性别(男、女),如果使用位图索引,则可以将每个性别映射为一个二进制位,0表示男性,1表示女性。对于每个性别,使用一个整数数组来存储对应的位图,数组中每个元素表示一段连续的数据块,每个块大小通常为几千到几万个数据项。
使用位图索引可以快速地进行布尔查询和模式匹配,例如快速找到所有男性或女性的记录,或在某些情况下,找到满足复杂查询条件的记录集合,例如性别为男,年龄在18到24岁之间,并且居住在某个市区的人。此外,位图索引还可以用于数据压缩和空间优化,可以减少索引的物理空间占用,并提高查询性能。
但是,在使用位图索引时需要考虑到它的限制,例如它只适用于离散值数据类型,而不适用于连续值或字符串类型。此外,由于数据映射为二进制位,所以位图索引不适合处理高基数(基数指不同取值的个数)列,因为它会导致位图过大,占用大量空间。
创建位图索引
CREATE BITMAP INDEX orders_region_id_idx
ON orders(region_id)
PCTFREE 30
STORAGE(INITIAL 200K NEXT 200K
PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx;索引的存储参数
ALTER INDEX employees_last_name_idx
STORAGE (NEXT 400K
MAXEXTENTS 100);分配& Dealloc索引空间
ALTER INDEX orders_region_id_idx
ALLOCATE EXTENT (SIZE 200K
DATAFILE '/DISK6/indx01.dbf');ALTER INDEX orders_id_idx
DEALLOCATE UNUSED:重建索引
使用ALTER INDEX命令:
- 将索引移动到不同的表空间
- 通过删除已删除的条目来提高空间利用率
ALTER INDEX orders_region_id_idx REBUILD
TABLESPACE indx02;离线索引重建
- 锁住表。
- 通过读取现有索引的内容来创建一个新的临时索引。
- 删除原始索引。
- 重命名临时索引,使其看起来像原始索引。
- 移除表锁。
重建索引的场合
在下列情况下重建索引:
- 必须将现有索引移动到不同的表空间。如果索引与表在同一个表空间中,或者对象需要跨磁盘重新分布,则可能需要这样做。
- 索引包含许多已删除的条目。这是滑动索引的典型问题,例如订单表的订单号索引,其中已完成的订单被删除,而编号更高的新订单被添加到表中。如果有几个旧订单未完成,则可能存在几个索引叶块,其中除了几个删除的条目外,其他条目都被删除了。
- 已存在的正常索引必须转换为反向键索引。从较早版本的Oracle服务器迁移应用程序时可能会出现这种情况。
- 使用ALTER TABLE…MOVE TABLESPACE命令将索引所在的表移到另一个表空间。
在线索引重建
- 锁住表。
- 创建一个新的、临时的空索引和一个IOT来存储正在进行的DML。
- 释放表锁。
- 通过读取现有索引的内容来填充临时索引。
- 将IOT的内容与新索引合并。
- 锁住表。
- 最终从IOT中合并并删除原始索引。
- 重命名临时索引,使其看起来是。
- 拆下表锁。
索引可以用最小的表锁定来重建。
ALTER INDEX orders_id_idx REBUILD ONLINE;一些限制仍然适用。
合并索引
- 沿着索引的底部扫描。
- 在相邻节点可以合并成单个节点的情况下,这样做。
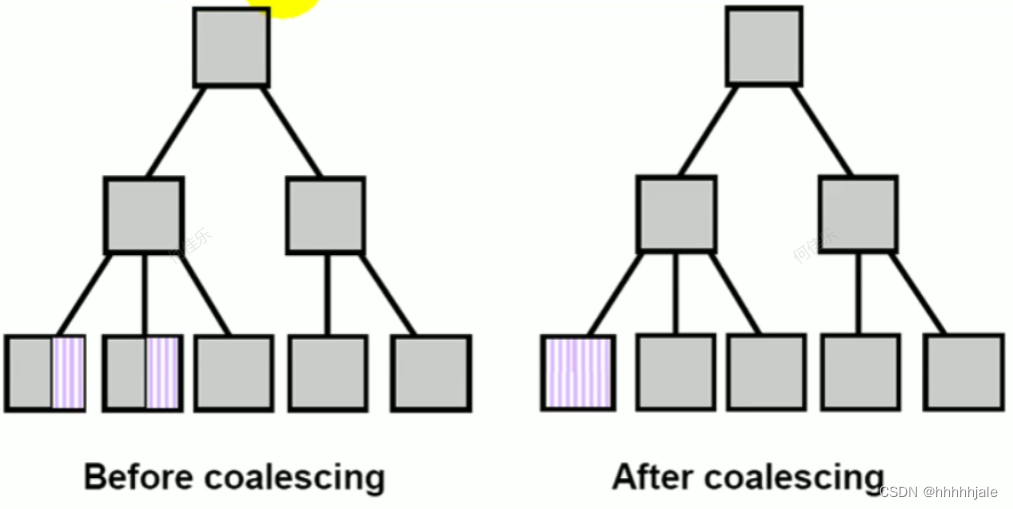
ALTER INDEX orders_id_idx COALESCE;检查索引有效性
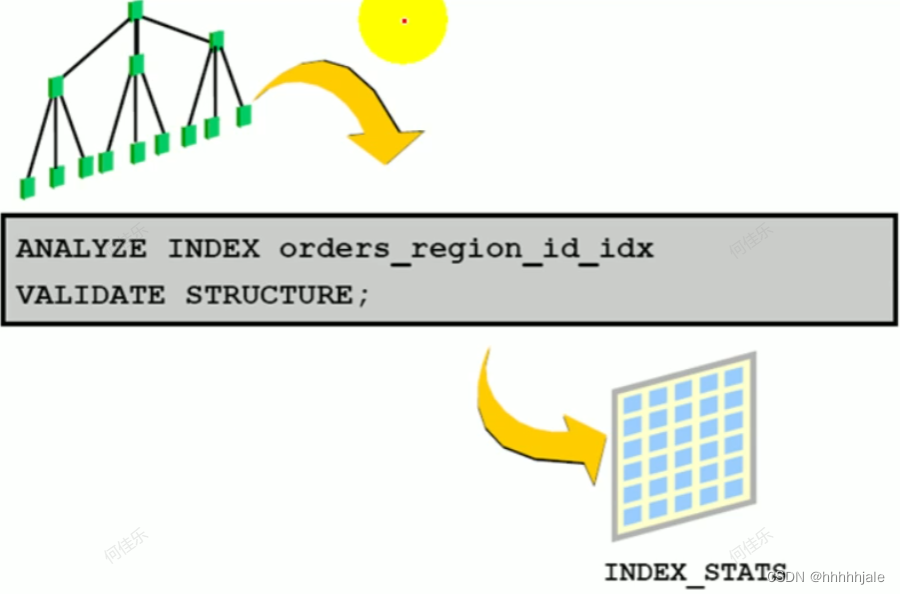
ANALYZE INDEX orders_region_id_idx
VALIDATE STRUCTURE;删除索引
在批量加载之前删除并重新创建索引。
删除不经常需要的索引,并在必要时构建索引。
删除并重新创建无效索引。
DROP INDEX hr.departments_name_idx;识别未使用的索引
开始监控索引的使用情况。
ALTER INDEX hr.dept_id_idx
MONITORING USAGE停止监视索引的使用情况。
ALTER INDEX hr.dept_id_idx
NOMONITORING USAGE获取索引信息
可以通过查询以下视图获取索引信息:可以通过查询以下视图获取索引信息:
- DBA_INDEXES:提供有关索引的信息
- DBA_IND_COLUMNS:提供有关已索引的列的信息
- VSOBJECT_USAGE:提供索引使用情况的信息
B-tree索引和位图索引比较
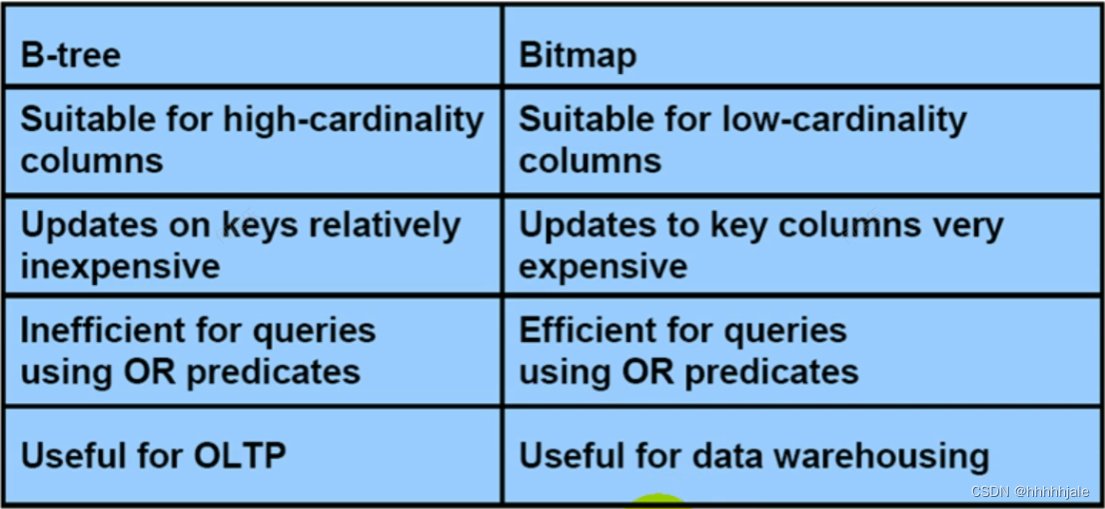
B-tree索引用在OLTP系统,位图索引用在数据仓库。















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









