






0.引子:
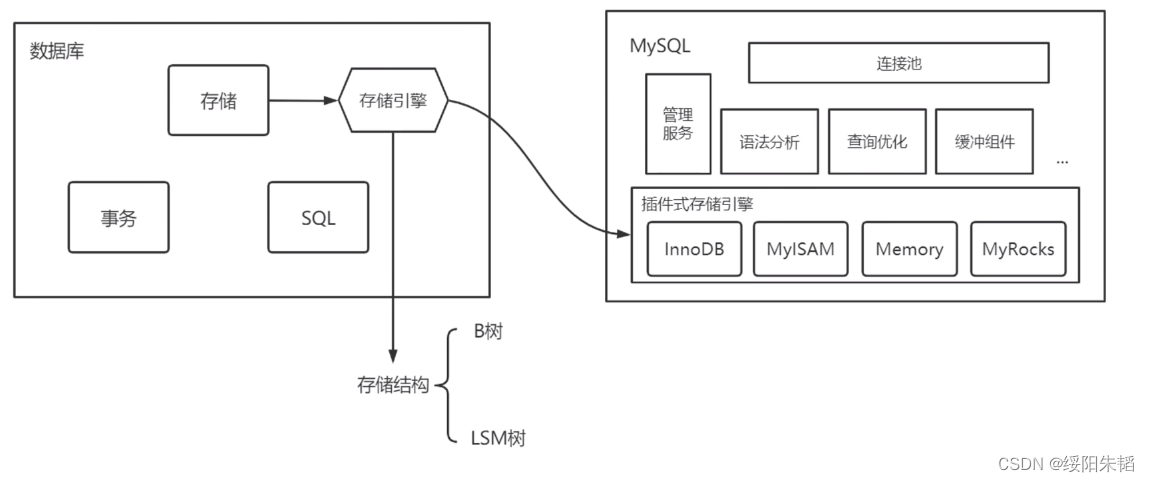
我们知道数据库有三大模块:存储,事务,SQL
因为存储和其他模块耦合较少,我们可以把它具象成一个专用的数据库组件,称为存储引擎。
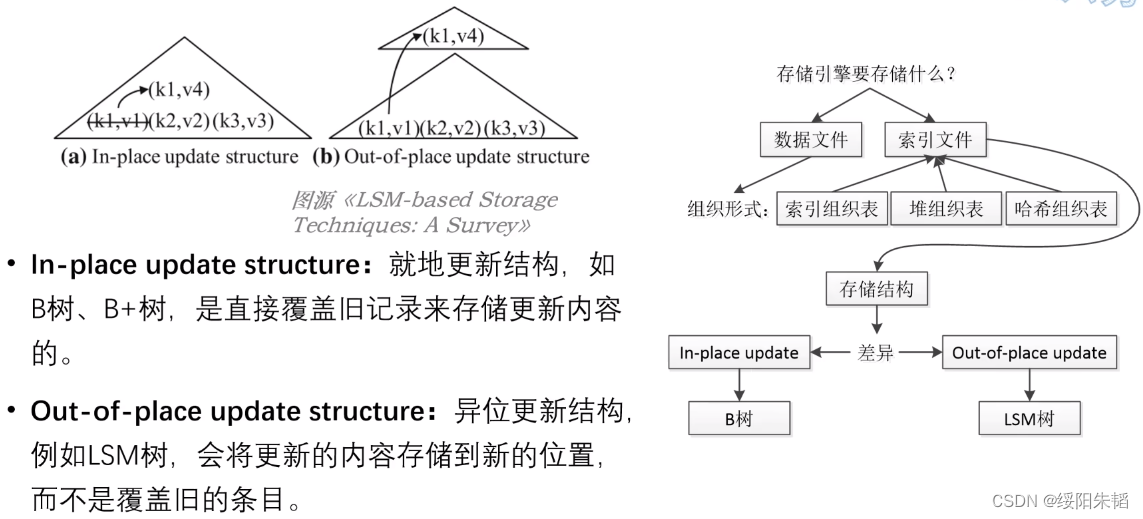
存储结构对存储引擎十分重要,B树就是非常重要的一个存储结构,随着分布式的火热和固态硬盘的发展,LSM树也愈加火热
1存储引擎和存储结构的概念:
抽象的一条条数据转化为文件,存储引擎基于文件系统,存储数据文件,比如linux就是一个单机文件系统
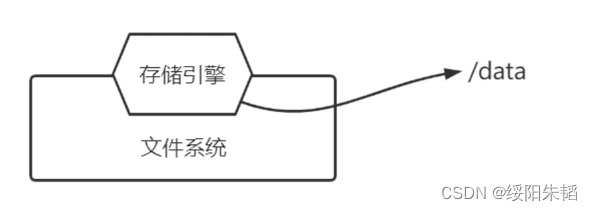
查询文件需要索引,索引也要组织成文件来存储。由此,存储引擎存储数据文件和索引文件
转换的细节:数据文件的组织形式

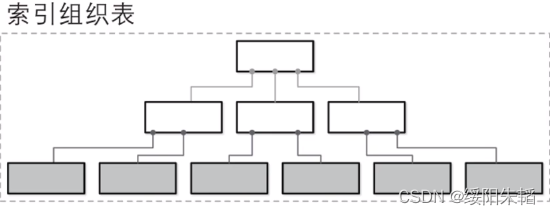
索引组织表:把数据文件和索引文件合并在一起,把数据记录存储在索引文件内部
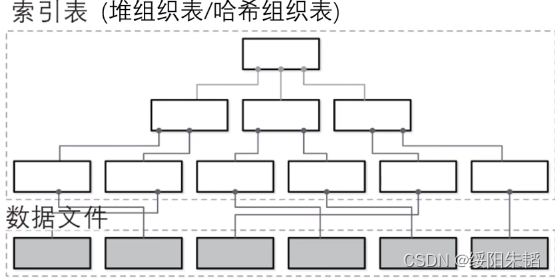
堆组织表:数据文件是一个“无序堆”数据结构,其中数据记录一般无需特定顺序,“堆”可以理解成一堆数据
哈希组织表:把记录分散存储在一个个桶中,每条记录主键的哈希值来确定 记录属于哪个桶,记录哈希值的部分就是索引文件,记录哈希结果部分就是数据文件
2.存储结构分类和发展历程:
 `
`
` 3.存储结构的共性特点:
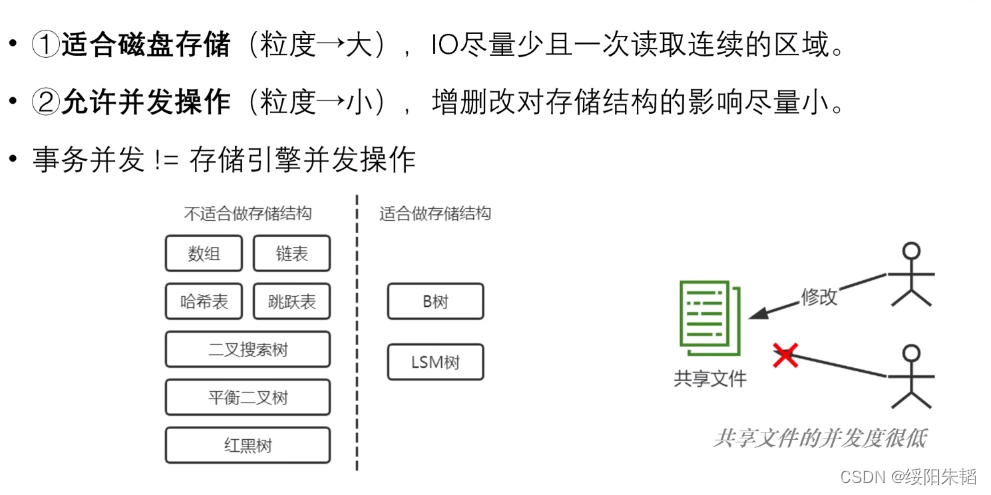
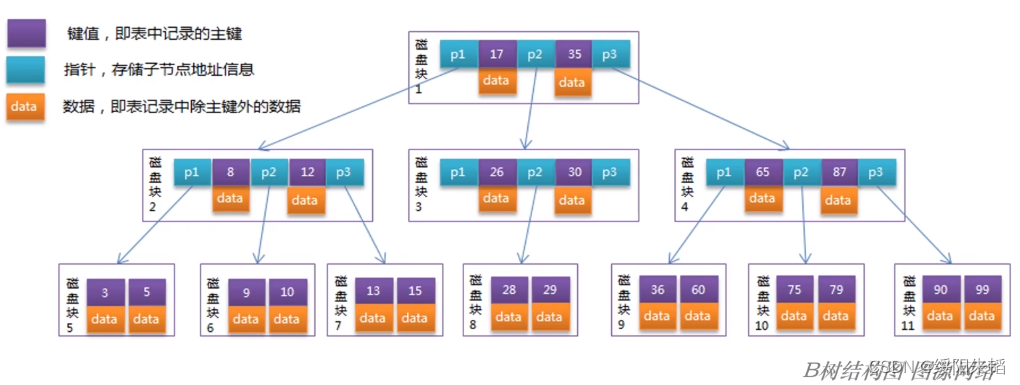
符合12条件的就是B树,下图为B树的结构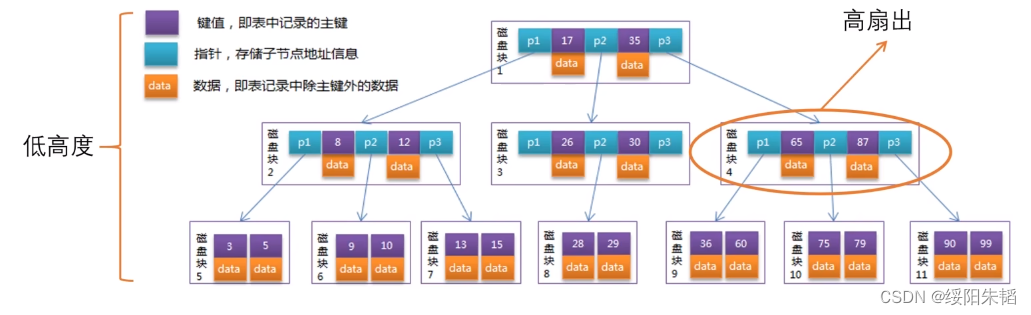
B树是以页为单位组织的,innoDB存储引擎中页的大小为16K,符合特性1,但增删改可能造成节点的分裂或合并,也就是SMO操作,要对有可能受SMO操作影响的节点加锁,导致并发能力不理想,勉强满足特性2,但还有很大的优化空间。
存储引擎并发操作和事务并发操作的不同:
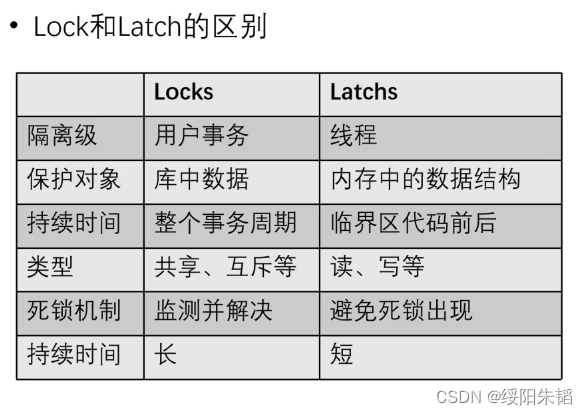
加载页到内存中并上latch,修改完成过后就释放
对要修改的数据上lock,事务提交后释放
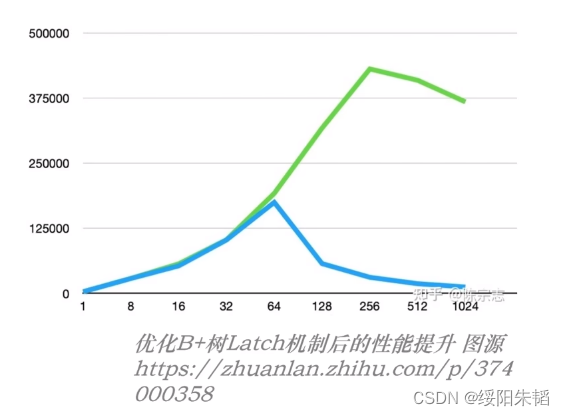
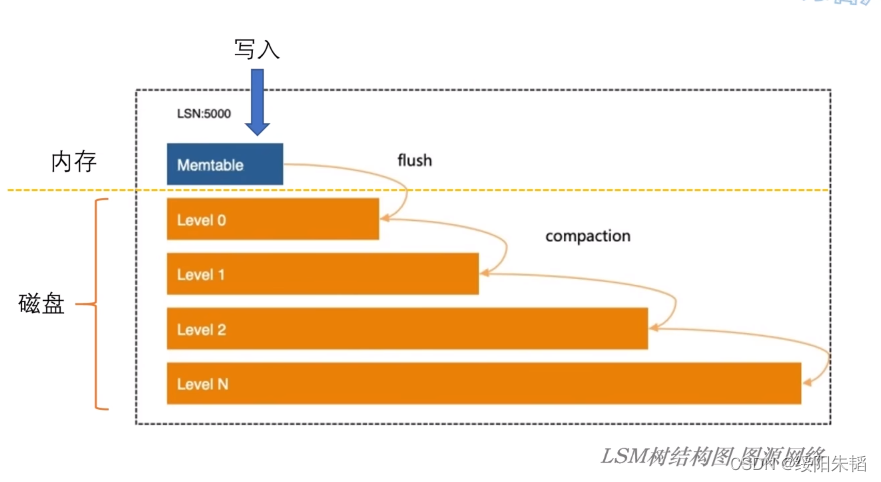
compaction:所有写入操作直接写入内存,内存满了存入磁盘,磁盘满了就这层和下一层合并,排序,去重,整理后的数据放在下层,这样数据冗余去除了,磁盘就装下了捏。
就这样一层层compaction,越下层数据越多,最终形成lsm树的整体结构
因为out- of-place update的特点,没有SMO过程,所以并发能力很强,因为lsm树每层数据比较多,所以在特性1上表现不好,可以靠compaction操作整理数据,减少读IO的次数,解析优化特性1,而compaction也是一种smo操作,需要优化。
in-place update和out-of-place update方案的差异:in-place update要把磁盘中的结构加载到内存中,再修改,并写回磁盘,所以免不了latch的机制来做并发控制,而out-of-place update因为所有写入都是追加,就不用采用基于latch的机制做控制,本来这点无所谓,但多核处理器的发展,NUMA模式逐渐模式逐渐成为主流,多核处理器在面对latch的频繁获取和释放时会多损耗很多代价。
4.B树和LSM树的变种和优化:
B树变种:

原始B树:每个数据只存储一份,中序遍历会产生IO
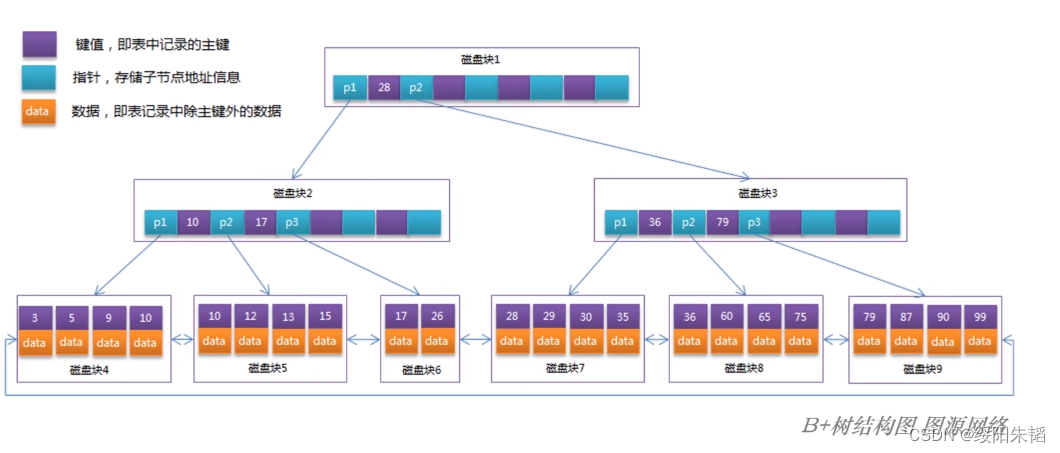
B+树:数据按键值大小顺序存放在同一层的叶子节点中,各叶子节点按指针连接,组成一个双向链表,也就是说,B树的非子叶节点中的数据是全部数据的一部分,而B+树仅作为查找路径的判断依据,一个key值可能在B+树中存在两份,这种结构解决了B树中序遍历扫描的痛点,在一定程度上也能降低层数,所以B+树最广泛
B*树:其把节点的最低空间利用率从B书和B+树的1/2提高到2/3,并由此改变了节点数据满时的处理逻辑,B和B+的1/2来源:它们叶子节点满而分裂时,默认状态次啊会分裂成两个各占一半数据的节点。B*树的2/3的来源:一个节点满了有新数据要插入进来时,他会把其部分数据搬迁到下一个兄弟节点,直到两个空间都满了,就在中间生成一个节点,三个节点平分原来两个节点的数据,但增加了写入的复杂度,搬迁过程也是一种SMO,所哟B*没有被大量使用,但其被优化成了B-link树突破了并发控制能力瓶颈。
归根结底是B+树自上而下的搜索模式造成的
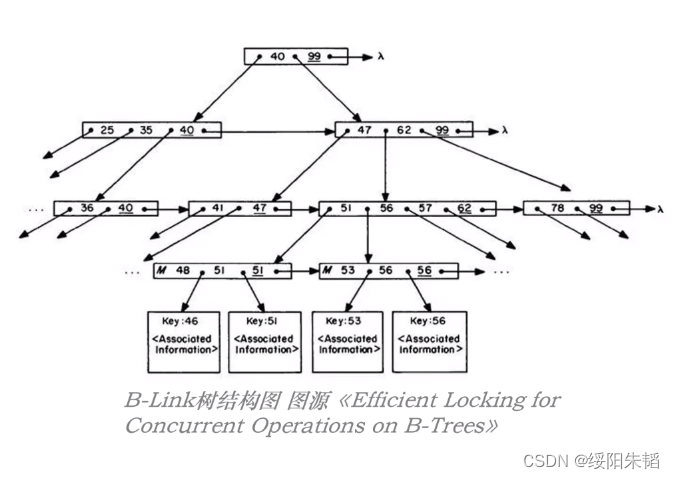
B-link树:相比B+树有三点区别,1.非叶子节点也都有指向右兄弟节点的指针。2.分裂模式上采用B+树类似的做法。3.每个节点都增加一个high key值,记录当前节点的最大key,所以其smo操作可以自底向上加锁。
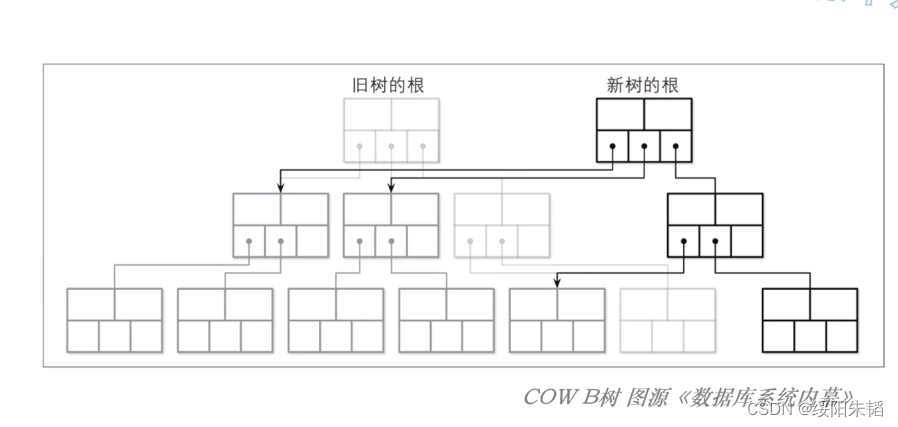
COW B树(写时复制B树):采用copy-on-write技术保证并发操作时的数据完整性,从而避免使用latch,当页要被修改时,就先复制这个页,在复制出来的页上进行修改,再复制并修改父节点和父节点,直至根节点
惰性B树:为每个页都设置了一个更新缓冲区,更新内容放入其中,读取时将原始页中的内容和更新缓冲区进行合并来返回正确数据
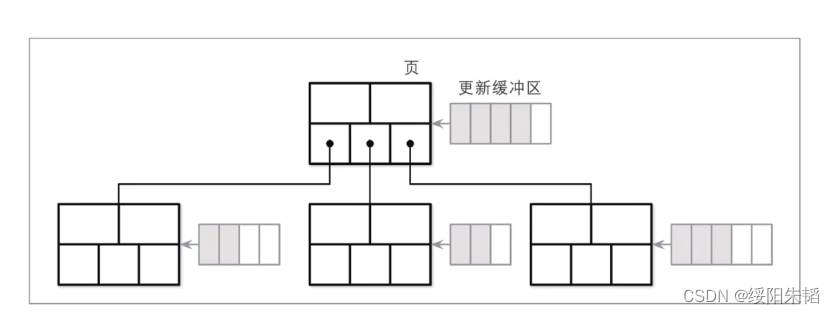
惰性自适应树lazy-Adaptive tree(LA树):更新缓冲区的对象换成子树,用来进一步减少写放大

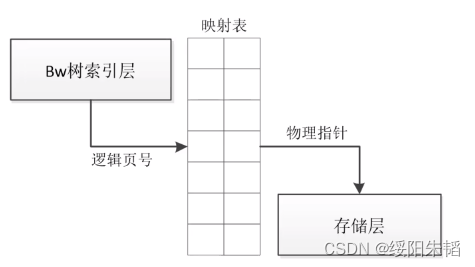
BW树:分为三层,从上而下是
BW树索引层:逻辑上的类B树结构,对外提供操作这个索引结构的API,无latch
缓冲层:把索引层和存储层连接起来,通过一份映射表,记录逻辑页号到物理指针的映射,实现了无锁追加的特性
存储层:
BW树像是B-link和LSM的结合,无latch又有读优势
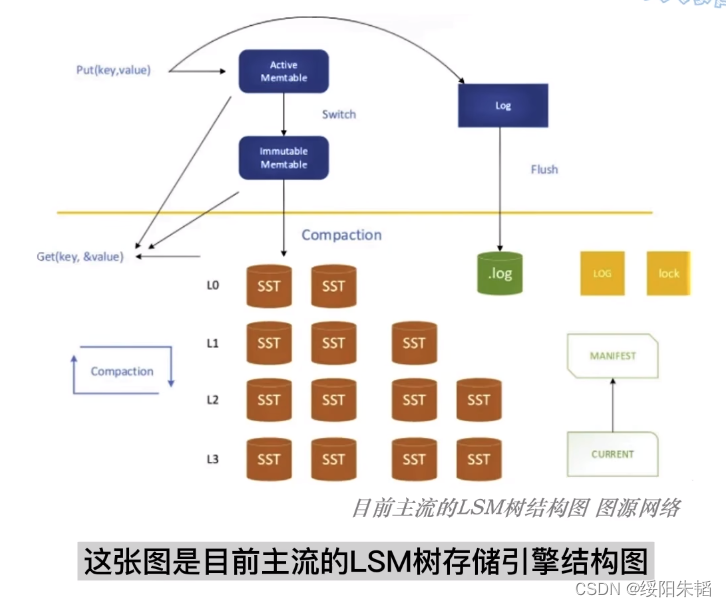
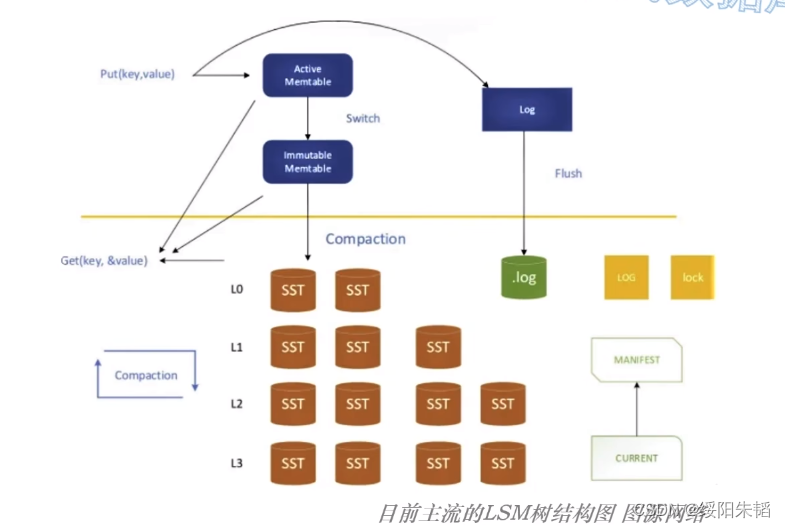
LSM树: rocksDB已经成为lsm 树领域的一个事实标准,数据有序地写入active Memtable中,也是唯一可变的结构,写满后转换为immutable memtable,两类都在内存中,使用的数据结构基本是跳跃表,immutable memtable达到指定数量后,就落盘到磁盘的L0层,这步操作叫minor merge,通常不做整理,直接刷入磁盘,所以L0层可能有重复的数据,满后会触发minor merge,也就是关键的compaction操作,把L0和L1数据合并,全整理为固定大小,不可变的数据块,称之为SSTable,在L1层。SSTable是LevelDB最初实现的一种数据格式,称为有序字符串表,sorted string Table,一个SST通常由两部分组成,索引文件和数据文件,数据文件就是要存储的KV数据,索引文件可以是B树或哈希表,可以把SST理解成一个小型的聚簇索引结构,除了L0之外磁盘中每一层都由一个个SST组成。 compaction操作一层层向下,如果遇到更下层的同key数据,就会合并;如果遇到更高层来的同key新的数据,就被合并
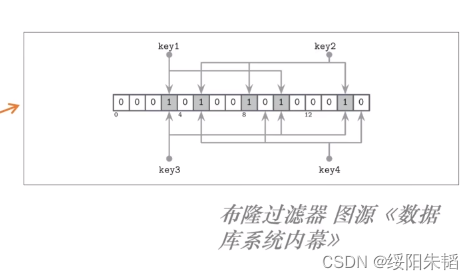
布隆过滤器可以加速筛选,可以筛选一层中是否包含我们要查找的数据,可能返回假阳性结果,不会返回假阴性结果,原理基于是对每个key做哈希,做成一个比特映射数组,对要查找的key也进行哈希,和比特映射数组比对,只有一个哈希函数偶然性高,可设置多个。
















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









