







集合
与数组区别
集合在数组的基础上,可变长度,存储类容可以不同类型(一般只用一种),但只能是引用类型。
三者关系
- List、Set实现Collection接口, Map是个顶级接口
- List、Set存储单列数据,Map存储键值对
- List有序可重复; Set不可重复并且最多只能存一个Null;Map键值对存储并且键不可重复,值可以重复
1.1List(列表,清单)
有序的可以存放相同类型的的糖果盒

特点
- 有序:List集合中的元素有下标
- 从0开始,以1递增
- 可重复:存储一个1,还可以再存储1
- 相比set较慢。
- List突出有序的含义。
定义
List list = new ArrayList();
// 向列表的尾部追加指定的元素
list.add("lwc");
// 在列表的指定位置插入指定元素
list.add(1, "nxj");
// 追加指定 collection 中的所有元素到此列表的结尾
list.addAll(new ArrayList());
// 从列表中移除所有元素
list.clear();
// 如果列表包含指定的元素,则返回true
list.contains("nxj");
// 如果列表包含指定 collection 的所有元素,则返回 true
list.containsAll(new ArrayList());
// 比较指定的对象与列表是否相等
list.equals(new ArrayList());
// 返回列表中指定位置的元素
list.get(0);
// 返回列表的哈希码值
list.hashCode();
// 返回列表中首次出现指定元素的索引,如果列表不包含此元素,则返回 -1
list.indexOf("lwc");
// 返回列表中最后出现指定元素的索引,如果列表不包含此元素,则返回 -1
list.lastIndexOf("lwc");
// 如果列表不包含元素,则返回 true
list.isEmpty();
// 移除列表中指定位置的元素
list.remove(0);
// 移除列表中出现的首个指定元素
list.remove("lwc");
// 从列表中移除指定 collection 中包含的所有元素
list.removeAll(new ArrayList());
// 用指定元素替换列表中指定位置的元素
list.set(0, "lp");
// 返回列表中的元素数
list.size();
// 返回列表中指定的fromIndex(包括)和toIndex(不包括)之间的部分视图
list.subList(1, 2);
// 返回以正确顺序包含列表中的所有元素的数组
list.toArray();
// 返回以正确顺序包含列表中所有元素的数组
list.toArray(new String[] { "a", "b" });
1.2ArrayList
public interface List<E> extends Collection<E>
底层的数据结构使用的是数组结构(数组长度是可变的百分之五十延长)(特点是查询很快,但增删较慢)线程不同步。
增删查改
public class LIST {
public static void main(String[] args) {
//创建List类型集合
List myList = new ArrayList();
//添加元素
myList.add("A"); //默认都是向集合末尾添加元素
myList.add("B");
myList.add("C");
myList.add("D");
//1. 在列表的指定位置插入元素(第一个参数是下标)
//这个方法使用不多,因为对于ArrayList集合来说效率比较低
myList.add(1, "king");
//迭代
Iterator it = myList.iterator();
while (it.hasNext()){
Object elt = it.next();
System.out.println(elt); //A B C D
}
//2. 根据下标获取元素
Object firstObj = myList.get(0);
System.out.println(firstObj);
//因为有下标,所以List集合有自己比较特殊的遍历方式
//通过下标遍历,(List集合特有的方法)
for (int i = 0; i < myList.size(); i++) {
Object obj = myList.get(i);
System.out.println(obj);
}
//3. 获取指定对象第一次出现处的索引
System.out.println(myList.indexOf("king")); // 1
//4. 获取指定对象最后一次出现处的索引
System.out.println(myList.lastIndexOf("C")); //3
//5. 删除指定下标位置的元素
myList.remove(0);
System.out.println(myList.size());
System.out.println("=====================");
//6. 修改指定位置的元素
myList.set(2,"Soft");
//遍历集合
for (int i = 0; i < myList.size(); i++) {
Object obj = myList.get(i);
System.out.println(obj); //king B Soft D
}
}
}
1.3 LinkedList(双向链表)
底层的数据结构是链表结构(特点是查询较慢,增删较快)
优缺点
1,由于链表上的元素空间存储内存地址不连续所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高
2.在以后的开发中,如果遇到随机增删集合中元素的业务比较多,建议使用LinkedList
3.缺点:不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头结点开始遍历,直到找到为止,所以LinkedList集合检索/查找效率较低
实例
package com.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedListTest01 {
public static void main(String[] args) {
//LinkedList集合底层也是有下标的
//注意:ArrayList之所以检索效率比较高,不是单纯因为下标的原因,是因为底层数组发挥的作用
//LinkedList集合照样有下标,但是检索/查找某个元素的时候效率比较低,因为只能从节点开始一个一个遍历
List list = new LinkedList();
list.add("a");
list.add("b");
list.add("c");
for (int i = 0; i < list.size(); i++) {
Object obj = list.get(i);
System.out.println(obj);
}
//LinkList集合有初始化容量吗?
//最初这个链表中没有任何元素,first和last引用都是null
//不管是LinkedList还是ArrayList,以后写代码时不需要关心具体是哪个集合
//因为我们要面向接口编程,调用的方法都是接口中的方法
//List list2 = new ArrayList(); 这样写底层用了数组
List list2 = new LinkedList(); //这样写底层用来双向链表
list2.add("123");
list2.add("456");
list2.add("789");
for (int i = 0; i < list2.size(); i++) {
System.out.println(list2.get(i));
}
}
}
1.4Vector集合
底层是数组数据结构 线程同步(数组长度是可变的百分之百延长)(无论查询还是增删都很慢,被ArrayList替代了)
Vector在所有的方法都是线程同步的,都带有synchronized关键字,是线程安全的,效率较低,使用较少
实例
package com.collection;
import java.util.*;
public class VectorTest {
public static void main(String[] args) {
//创建一个Vector集合
//Vector vector = new Vector();
List vector = new Vector();
//添加元素
//默认容量10个
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
vector.add(5);
vector.add(5);
vector.add(6);
vector.add(7);
vector.add(8);
vector.add(9);
vector.add(10);
//满了之后扩容(扩容是)
vector.add(11);
Iterator it = vector.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
//这个可能以后要使用
List mylist = new ArrayList(); //非线程安全
//变成线程安全
Collections.synchronizedList(mylist);
//mylist集合就是线程安全的
mylist.add("111");
mylist.add("222");
mylist.add("333");
}
}
2.1Set
一个只能存放不同糖果而且无序的糖果罐

2.2HashSet集合
特点:快,无序。
实际生成了哈希表,方便快熟查找。
从而可以自由增加HashCode的长度。
存储时顺序和取出的顺序不同,不可重复放到HashSet集合中的元素实际上是放到HashMap集合的key部分了
创建
public static void main(String[] args) {
// 创建存储字符串的HashSet集合
Set<String> objects = new HashSet<>();
}
| 方法名 | 方法说明 |
| add() | 往集合中添加元素 |
| contains() | 判断集合中是否存在某元素 |
| remove() | 从集合中删除指定的元素 |
| clear() | 清除集合中所有元素 |
| size() | 获取集合中元素个数 |
| isEmpty() | 判断集合元素是否为空 |
| Iterator() | 返回元素的迭代器 |
public static void main(String[] args) {
// 创建存储字符串的HashSet集合
Set<String> objects = new HashSet<>();
// 往集合中添加元素
objects.add("123");
objects.add("456");
objects.add("789");
// 判断集合是否为空
boolean empty = objects.isEmpty();
System.out.println(empty);
// 判断集合是否包含元素123
boolean contains = objects.contains("123");
System.out.println(contains);
// 移除集合元素123
objects.remove("123");
System.out.println(objects);
// 获取迭代器,遍历集合所有元素
Iterator<String> iterator = objects.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
HashSet 的无序性
public static void main(String[] args) {
// 创建存储字符串的HashSet集合
Set<String> objects = new HashSet<>();
// 往集合中添加元素
objects.add("123");
objects.add("aa");
objects.add("a");
// 获取迭代器,遍历集合所有元素
Iterator<String> iterator = objects.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
HashSet 的唯一性
public static void main(String[] args) {
// 创建存储字符串的HashSet集合
Set<String> objects = new HashSet<>();
// 往集合中添加元素
objects.add("ss");
objects.add("ss");
objects.add("how");
// 获取迭代器,遍历集合所有元素
Iterator<String> iterator = objects.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
2.3LinkedHashSet类
HashSet还有一个子类LinkedList、LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
2.4TreeSet集合(大小排序的糖果罐)
-
无序不可重复的,但是存储的元素可以自动按照大小顺序排序(无序指的是:存进去的顺序和取出来的顺序不同。并且没有下标)
-
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet<Integer> nums = new TreeSet<>();
//向集合中添加元素
nums.add(5);
nums.add(2);
nums.add(15);
nums.add(-4);
//输出集合,可以看到元素已经处于排序状态
System.out.println(nums);//[-4, 2, 5, 15]
System.out.println("集合中的第一个元素:"+nums.first());//集合中的第一个元素:-4
System.out.println("集合中的最后一个元素:"+nums.last());//集合中的最后一个元素:15
System.out.println("集合小于4的子集,不包含4:"+nums.headSet(4));//集合小于4的子集,不包含4:[-4, 2]
System.out.println("集合大于5的子集:"+nums.tailSet(2));//集合大于5的子集:[2, 5, 15]
System.out.println("集合中大于等于-3,小于4的子集:"+nums.subSet(-3,4));//集合中大于等于-3,小于4的子集:[2]
}
额外方法
Comparator comparator():如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的Comparator,如果TreeSet采用自然排序,则返回null;
Object first():返回集合中的第一个元素;
Object last():返回集合中的最后一个元素;
Object lower(Object e):返回指定元素之前的元素。
Object higher(Object e):返回指定元素之后的元素。
SortedSet subSet(Object fromElement,Object toElement):返回此Set的子集合,含头不含尾;
SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成;
SortedSet tailSet(Object fromElement):返回此Set的子集,由大于fromElement的元素组成;
————————————————
版权声明:本文为CSDN博主「Mrkang1314」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mashaokang1314/article/details/83721792
}
```java
Comparator comparator():如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的Comparator,如果TreeSet采用自然排序,则返回null;
Object first():返回集合中的第一个元素;
Object last():返回集合中的最后一个元素;
Object lower(Object e):返回指定元素之前的元素。
Object higher(Object e):返回指定元素之后的元素。
SortedSet subSet(Object fromElement,Object toElement):返回此Set的子集合,含头不含尾;
SortedSet headSet(Object toElement):返回此Set的子集,由小于toElement的元素组成;
SortedSet tailSet(Object fromElement):返回此Set的子集,由大于fromElement的元素组成;
3.1Map接口
-
java.util.Map接口中常用的方法:
-
Map和Collection没有继承关系
-
Map集合以key和value的方式存储数据:键值对
-
key和value都是引用数据类型
-
key和value都是存储对象的内存地址
-
key起到主导地位,value是key的一个附属品
-
HashMap允许key部分为null
Map集合中常用的方法
package com.collection;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/*
Map集合中常用的方法
V put(K key, V value)向Map集合中添加键值对
V get(Object key)通过key获取value
void clear() 清空Map集合
boolean containsKey(Object key) 判断Map中是否包含某个key
boolean containsValue(Object value) 判断Map中是否包含某个Value
boolean isEmpty() 判断Map集合中元素个数是否为0
V remove(Object key)通过key删除键值对
int size() 获取Map集合中键值对的个数
Collection<V> values() 获取Map集合中所有的value,返回一个Collection
Set<K> keySet() 获取Map集合所有的key(所有的键是一个Set集合)
Set<Map.Entry<K,V>> entrySet() 将Map集合转换为Set集合
假设现在有一个Map集合,如下所示:
map1集合对象
key value
-------------------
1 zhangsan
2 lisi
3 wangwu
4 zhaoliu
Set set = map1.entrySet();
set集合对象
1=zhangsan
2=lisi
3=wangwu
4=zhaoliu
【注意:Map集合通过entrySet()方法转换成的这个Set集合,Set集合中元素的类型是Map.Entry<K,V>】
Map.Entry和String一样,都是一种类型的名字,只不过:Map.Entry是静态内部类,是Map中的静态内部类
*/
public class MapTest01 {
public static void main(String[] args) {
//创建Map集合对象
Map<Integer,String> map = new HashMap<>();
//向Map集合中添加键值对
map.put(1,"zhangsan"); //1在这里进行了自动装箱
map.put(2,"lisi");
map.put(3,"wangwu");
map.put(4,"zhaoliu");
//通过key获取value
String value = map.get(2);
System.out.println(value);
//获取键值对的数量
System.out.println("键值对的数量:" + map.size()); //4
//通过key删除key-value
map.remove(2);
System.out.println("键值对的数量:" + map.size()); //3
//判断是否包含某个key
//contains方法底层调用的都是equals进行比对的,所以自定义的类型需要重写equals方法
System.out.println(map.containsKey(4)); //true
//判断是否包含某个value
System.out.println(map.containsValue("wangwu")); //true
//获取所有的value
Collection<String> values = map.values();
for (String s:values){
System.out.println(s);
}
//清空map集合
map.clear();
System.out.println("键值对的数量:" + map.size()); //0
//判断是否为空
System.out.println(map.isEmpty()); //true
}
}
Map遍历方式案例演示
package www.xz.map_;
import java.util.*;
/**
* @author 许正
* @version 1.0
*/
@SuppressWarnings({"all"})
public class MapFor {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("邓超", new Book("", 100));
map.put("邓超", "孙丽");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("秋山帅豪", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//第一组:先取出所有的 Key ,通过Key 取出对应的Value
Set keySet = map.keySet();
//(1) 增强for
System.out.println("===第一种方式===");
for (Object key : keySet) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("===第二种方式===");
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next + "-" + map.get(next));
}
//第二组:把所有的Value 取出
Collection values = map.values();
//这里可以使用所有的ColLections使用的遍历方法
System.out.println("---取出所有的Value 增强for---");
for (Object value : values) {
System.out.println(value);
}
System.out.println("---取出所有的Value 迭代器---");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object next = iterator2.next();
System.out.println(next);
}
//第三组:通过EntrySet 来获取k-v
Set entrySet = map.entrySet();
System.out.println("---使用EntrySet的 增强for(第三种)---");
for (Object o : entrySet) {
Map.Entry entry = (Map.Entry) o;
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("---使用EntrySet的 迭代器(第四种)---");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object next = iterator3.next();
Map.Entry next1 = (Map.Entry) next;
System.out.println(next1.getKey() + "-" + next1.getValue());
}
}
}
HashMap
HashMap集合:
-
Map接口的常用实现类: HashMap、Hashtable和Properties.
-
HashMap是Map接口使用频率最高的实现类。
-
HashMap是以key-val对的方式来存储数据[案例Entry]
-
key不能重复,但是值可以重复,允许使用null键和null值。
-
如果添加相同的key ,则会覆盖原来的key-val等同于修改.(key不会替换,val会替换)
-
与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的.
-
HashMap没有实现同步,因此是线程不安全的
-
HashMap集合底层是哈希表/散列表的数据结构, 哈希表是一个数组和单向链表的结合体
-
数组:在查询方面效率很高,随机增删方面效率很低
-
单向链表:在随机增删方法效率较高,在查询方法效率较低
-
哈希表将以上两种数据结构融合在一起
package www.xz.map_;
import java.util.HashMap;
/**
* @author 许正
* @version 1.0
*/
@SuppressWarnings({"all"})
public class HashMapSource01 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替换value
System.out.println("map=" + map);
}
}
package com.collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapTest01 {
public static void main(String[] args) {
//测试HashMap集合key部分的元素特点
//Integer是key,它的hashCode和equals都重写了
Map<Integer,String> map = new HashMap<>();
map.put(1111,"zhangsan");
map.put(6666,"lisi");
map.put(7777,"wangwu");
map.put(2222,"zhaoliu");
map.put(2222,"king"); //key重复的时候value会自动覆盖
System.out.println(map.size()); //4
//遍历Map集合
Set<Map.Entry<Integer,String>> set = map.entrySet();
for (Map.Entry<Integer,String> entry : set){
//验证结果:HashMap集合key部分元素:无序不可重复
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
}
package com.bean;
import java.util.HashSet;
import java.util.Set;
/*
1. 向Map集合中存,以及从Map集合中取,都是县调用key的hashCode方法,然后在调用equals方法
equals方法有可能调用,也有可能不会调用
2. 注意:如果一个类的equals方法重写了,那么hashCode()方法必须重写,
并且equals方法返回如果是true,hashCode()方法返回的值必须一样
equals方法返回true表示两个对象相同,在同一个单向链表上比较
那么对于同一个单向链表上的节点来说,他们的哈希值都是相同的
所有hashCode()方法的返回值也应该是相同的
3. 放在hashCode集合key部分,以及放在hashSet集合中的元素,需要同时重写hashCode方法和equals方法
*/
public class HashMapTest02 {
public static void main(String[] args) {
Student s1 = new Student("zhangsan");
Student s2 = new Student("zhangsan");
//重写equals方法之前是false
System.out.println(s1.equals(s2)); //false
//重写equals方法之后是true
System.out.println(s1.equals(s2));
System.out.println("s1的hashCode="+s1.hashCode()); //22307196
System.out.println("s2的hashCode="+s2.hashCode()); //10568834
//s1.equals(s2)已经是true了,表示s1和s2是一样的,那么王hashCode集合中方法的话,
//按说只能放进去一个(HashSet集合特点无序不可重复)
Set<Student> students = new HashSet<>();
students.add(s1);
students.add(s2);
System.out.println(students.size()); //这个结果按说应该是1,但是结果为2
//重写equals和hashCode之后hashCode都为-1432604525
}
}
package com.bean;
import java.util.Objects;
public class Student {
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//重写equals (如果名字一样,表示同一个学生)
/*public boolean equals(Object object){
if (object == null || !(object instanceof Student)) return false;
if (object == this) return true;
Student student = (Student)object;
if (this.name.equals(student.name)) return true;
return false;
}*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
Hashtable类
存放的元素是键值对:即K-V
hashtable的键和值都不能为null,否则会抛出NullPointerException
hashTable使用方法基本上和HashMap一样
hashTable是线程安全的,hashMap是线程不安全的
简单看下底层结构
扩容
package www.xz.map_;
import java.util.Hashtable;
/**
* @author 许正
* @version 1.0
*/
@SuppressWarnings({"all"})
public class HashTableExercise {
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
hashtable.put("john",100);
// hashtable.put(null,100);
// hashtable.put("john",null);
hashtable.put("lucy",100);
hashtable.put("lic",100);
hashtable.put("lic",80);
hashtable.put("hello1",1);
hashtable.put("hello2",1);
hashtable.put("hello3",1);
hashtable.put("hello4",1);
hashtable.put("hello5",1);
hashtable.put("hello6",1);
System.out.println(hashtable);
}
}

TreeSet集合
- TreeSet集合底层实际上是一个TreeMap
- TreeMap集合底层是一个二叉树
- 放到TreeSet集合中的元素,等同于放到TreeMap集合key部分
- TreeSet集合中的元素:无序不可重复,但是可以按照元素的大小顺序自动排序。称为可排序集合
package www.xz.map_;
import java.util.Comparator;
import java.util.TreeMap;
/**
* @author 许正
* @version 1.0
*/
@SuppressWarnings({"all"})
public class TreeMap_ {
public static void main(String[] args) {
// TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照首字母倒序
// return ((String)o2).compareTo((String)o1);
//按照字符串长度
return ((String)o1).length()-((String)o2).length();
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("kristina", "克雷丝缇娜");
treeMap.put("smith", "史密斯");
System.out.println(treeMap);
}
}
Properties
package www.xz.map_;
import java.util.Properties;
/**
* @author 许正
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Properties_ {
public static void main(String[] args) {
Properties properties = new Properties();
//1. Properties 继承Hashtable
//2. 可以通过k-v存放数据,当然key和value不能为null
properties.put("john", 100);
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//替换
//通过key 获取对应值
System.out.println(properties.get("lic"));
//删除
properties.remove("lic");
System.out.println(properties);
//修改(直接覆盖)
properties.put("john","jack");
System.out.println(properties);
//查找
System.out.println(properties.getProperty("john"));
}
}
总结-开发中如何选择集合实现类
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行
选择,分析如下:
先判断存储的类型(一组对象或一组键值对)
一组对象: Collection接口
允许重复: List
增删多: LinkedList [底层维护了一个双向链表]
改查多: ArrayList [底层维护Object类型的可变数组]
不允许重复: Set
无序: HashSet [底层是HashMap ,维护了一个哈希表即(数组+链表+红黑树)]
排序: TreeSet
插入和取出顺序一致: LinkedHashSet , 维护数组+双向链表
一组键值对: Map
键无序: HashMap [底层是:哈希表jdk7: 数组+链表,jdk8: 数组+链表+红黑树]
键排序: TreeMap
键插入和取出顺序一致: LinkedHashMap
读取文件Properties
常用类
System类
System类包含一些有用的字段和方法。这些字段和类都被static修饰了,说明他们都不能被实例化。
在System类提供的设施中,有标准输入、标准输出和错误输出流;对外部定义的属性和环境变量的访问;加载文件和库的方法;还有快速复制数组的一部分的使用方法。
字段摘要
| static | PrintStream | err | ”标准“输入错误流 |
|---|---|---|---|
| static | InputStream | in | ”标准“输入流 |
| static | PrintStream | out | ”标准“输出流 |
这里仅介绍几个常用的:
– static long currentTimeMillis()
// 返回以毫秒为单位的当前时间。 1970 年 1 月 1
– arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
–exit(int status)
//终止当前正在运行的 Java 虚拟机,非 0 的状态码表示异常终止。
–gc(); //唤起垃圾回收器
–static Map<String,String> getenv()
代码实例:
public class Test6 {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();// 取得计算开始时的时间
@SuppressWarnings("unused")
int sum = 0;// 声明变量并初始化
for (int i = 0; i < 1000000000; i++) { // 进行累加
sum+=i;
}
long endTime = System.currentTimeMillis();// 取得计算结束时间
// 计算所花费的时间
System.out.println("累加所花费的时间" + (endTime - startTime) + "毫秒");
}
}
除此之外还有很多有用的方法,应用代码如下:
import java.util.Properties;
import java.util.Set;
public class Test1 {
public static void main(String[] args) {
Properties p = System.getProperties();//列出系统全部属性
Set<Object> set = p.keySet();
for (Object key : set) { //利用增强for遍历
System.out.println(key + ":" + p.get(key));
}
System.out.println("=====分割线1=====");
String p2 = System.getProperty("os.name");//查找
System.out.println(p2);
System.out.println("=====分割线2=====");
System.setProperty("Mykey", "zhouzhou的系统");//自定义系统名称属性
System.out.println("Mykey");
}
}
打印结果:
java.runtime.name:Java(TM) SE Runtime Environment
sun.boot.library.path:C:\Program Files\Java\jdk1.7.0_75\jre\bin
java.vm.version:24.75-b04
java.vm.vendor:Oracle Corporation
java.vendor.url:http://java.oracle.com/
path.separator:;
java.vm.name:Java HotSpot(TM) Client VM
file.encoding.pkg:sun.io
user.country:CN
user.script:
sun.java.launcher:SUN_STANDARD
sun.os.patch.level:
java.vm.specification.name:Java Virtual Machine Specification
user.dir:E:\ClassC
java.runtime.version:1.7.0_75-b13
java.awt.graphicsenv:sun.awt.Win32GraphicsEnvironment
java.endorsed.dirs:C:\Program Files\Java\jdk1.7.0_75\jre\lib\endorsed
os.arch:x86
java.io.tmpdir:C:\Users\win7\AppData\Local\Temp\
line.separator:
可以看出,System类本身提供的静态属性都是与IO操作有关。比如,gc();
代码实例:
public class Test7 {
private String name;
private int age;
public Test7(String name, int age) {
this.age = age;
this.name = name;
}
public String toString() {
return "姓名:" + this.name + " 年龄:" + this.age;
}
public void finalize() throws Throwable { // 释放空间
System.out.println("对象被释放==" + this);
}
}
object
用法
Java 中的 Object 方法在面试中是一个非常高频的点,毕竟 Object 是所有类的“老祖宗”。Java 中所有的类都有一个共同的祖先 Object 类,子类都会继承所有 Object 类中的 public 方法。
- clone()
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
- getClass()
final方法,返回Class类型的对象,反射来获取对象。
- toString()
该方法用得比较多,一般子类都有覆盖,来获取对象的信息。
- finalize()
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
- equals()
比较对象的内容是否相等
- hashCode()
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
- wait()
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
其他线程调用了该对象的notify方法。
其他线程调用了该对象的notifyAll方法。
其他线程调用了interrupt中断该线程。
时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
实例
package 常用类;
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.age = age;
this.name = name;
}
}
public class object
{
public static void main(String[] args) {
Person per =new Person("zhonghua",43);
System.out.println(per);
}
}
输出:常用类.Person@1b6d3586
加toString后
package 常用类;
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.age = age;
this.name = name;
}//在类中添加此方法后,可以正常输出。
public String toString()
{
return "名字为"+this.name+"年龄为"+this.age;
}
}
public class object
{
public static void main(String[] args) {
Person per =new Person("zhonghua",43);
System.out.println(per);
}
}
//输出:名字为zhonghua年龄为43
}
equals
package 常用类;
class Person1 {
private String name;
private int age;
public Person1(String name, int age) {
this.age = age;
this.name = name;
}//在类中添加此方法后,可以正常输出。
public String toString()
{
return "名字为"+this.name+"年龄为"+this.age;
}
}
public class equals
{
public static void main(String[] args) {
//常用类.Person per =new 常用类.Person("zhonghua",43);
// System.out.println(per);
Person1 per1=new Person1("md",18);
Person1 per2=new Person1("md",18);
//调用比较方法
System.out.println(per1.equals(per2));
}
}
两个对象per1和per2的内容明明相等,应该是true呀?怎么会是false?
因为此时直接调用equals()方法默认进行比较的是两个对象的地址。
在源码中,传递来的Object对象和当前对象比较地址值,返回布尔值。
故要重写equals();
string
1、String表示字符串类型,属于 引用数据类型,不属于基本数据类型。
2、在java中随便使用 双引号括起来 的都是String对象。
3、java中规定,双引号括起来的字符串,是 不可变 的,也就是说"abc"自出生到最终死亡,不可变,不能变成"abcd",也不能变成"ab"
- String底层是通过char类型的数据实现的,当字符串进行拼接时,也不会在原来的内存地址进行修改,而是重新分配新的内存地址进行赋值。
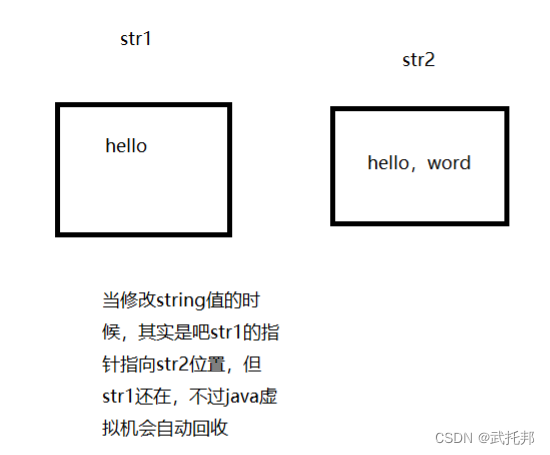
4、在JDK当中双引号括起来的字符串,例如:“abc” "def"都是直接存储在“方法区”的“字符串常量池”当中的。
5、为什么SUN公司把字符串存储在一个“字符串常量池”当中呢?
因为字符串在实际的开发中使用太频繁。为了执行效率,所以把字符串放到了方法区的字符串常量池当中。
6. 如果不赋值,string不赋值,那么等于“”。不等于null;
//通过字面量方式为字符串赋值时,此时的字符串存储在方法区的字符串常量池中
String s1="hello";
String s2="hello";
//通过new+构造器方式实例化字符串时,字符串对象存储在堆中,但是字符串的值仍然存储在方法区的常量池中。
String s3=new String("hello");
String s4=new String("hello");
System.out.println(s1==s2);//true
System.out.println(s1==s3);//false
System.out.println(s1==s4);//false
System.out.println(s3==s4);//false
当字符串比较时,会比较内存地址。
public class StringTest02 {
public static void main(String[] args) {
String s1 = "hello";
// "hello"是存储在方法区的字符串常量池当中
// 所以这个"hello"不会新建。(因为这个对象已经存在了!)
String s2 = "hello";
// == 双等号比较的是变量中保存的内存地址
System.out.println(s1 == s2); // true
String x = new String("xyz");
String y = new String("xyz");
// == 双等号比较的是变量中保存的内存地址
System.out.println(x == y); //false
}
}
字符串对象之间的比较不能使用“== ”,"=="不保险。应该调用String类的equals方法
String k = new String("testString");
//String k = null;
// "testString"这个字符串可以后面加"."呢?
// 因为"testString"是一个String字符串对象。只要是对象都能调用方法。
System.out.println("testString".equals(k)); // 建议使用这种方式,因为这个可以避免空指针异常。
System.out.println(k.equals("testString")); // 存在空指针异常的风险。不建议这样写。
**
构造方法
**
二、构造方法
构造方法名 eg.
-
String s = “xxx” 最常用
-
String(String original) String(“xxx”)
-
String(char数组)
-
String(char数组,起始下标,长度)
-
String(byte数组)
-
String(byte数组,起始下标,长度)
-
String(StringBuffer buffer)
-
String(StringBuilder builder)
class StringTest{
public static void main(String[] args) {
//最常用的方式
String s1 = "我是中国人";
System.out.println(s1);//我是中果人
String s2 = new String("我是中国人");
System.out.println(s2);//我是中果人
char[] c = {'我' , '是', '中', '果', '人'};
String s3 = new String(c);
System.out.println(s3);//我是中果人
String s4 = new String(c, 2, 3);
System.out.println(s4);//中果人
byte[] b = {65, 66 ,67, 68};
String s5 = new String(b);
System.out.println(s5);//ABCD
String s6 = new String(b, 1, 2);
System.out.println(s6);//BC
StringBuffer sb1 = new StringBuffer("我是福建人");
String s7 = new String(sb1);
System.out.println(s7);//我是福建人
StringBuilder sb2 = new StringBuilder("我是厦门人");
String s8 = new String(sb2);
System.out.println(s8);//我是厦门人
}
}
方法
| 方法名 | 作用 |
| char charAt(int index) | 返回指定位置的字符 |
| int compareTo(String anotherString) | 比较两个字符串。相等返回0;前大后小返回1;前小后大返回-1 |
| boolean contains(CharSequence s) | 判断字符串是否包含s |
| boolean endsWith(String suffix) | 判断字符串是否以suffix结尾 |
| boolean equals(Object anObject) | 判断两个串是否相等 |
| boolean equalsIgnoreCase(String anotherString) | 忽略大小写判断两个串是否相等 |
| byte[] getBytes() | 将字符串串变成字节数组返回 |
| int indexOf(String str) | 返回str在字符串第一次出现的位置 |
| boolean isEmpty() | 字符串是否为空 |
| int length() | 字符串长度 |
| int lastIndexOf(String str) | 返回str最后一次出现的位置 |
| String replace(CharSequence target, CharSequence replacement) | 用replacement替换字符串target的字符 |
| String[] split(String regex) | 将字符串以regex分割 |
| boolean startsWith(String prefix) | 判断字符串是否以prefix开始 |
| String substring(int beginIndex) | 从beginIndex开始截取字串 |
| String substring(int beginIndex, int endIndex) | 截取beginIndex到endIndex - 1的字符串 |
| char[] toCharArray() | 将字符串转换乘char数组 |
| String toLowerCase() | 字符串转小写 |
| String toUpperCase() | 字符串转大写 |
| String trim() | 去除字符串两边空格 |
| 静态方法 | static String valueOf(int i) 将 i 转换成字符串 |
class StringTest{
public static void main(String[] args) {
String s1 = "hello world";
System.out.println(s1.charAt(6));//w
String s2 = "abc";
String s3 = "xyz";
String s4 = "xyz";
System.out.println(s2.compareTo(s3));//-23
System.out.println(s3.compareTo(s4));//0
System.out.println(s4.compareTo(s1));//16
System.out.println(s2.equals(s3));//false
System.out.println(s1.endsWith("world"));//true
System.out.println(s1.endsWith("t"));//false
String s5 = "HELLO worLD";
System.out.println(s1.equalsIgnoreCase(s5));//true
byte[] b = s1.getBytes();
System.out.println(Arrays.toString(b));//[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(s1.indexOf("world"));//6
System.out.println(s1.indexOf("h"));//0
System.out.println(s1.isEmpty());//false
System.out.println(s1.length());//11
String s6 = "javapythonc++cphpjavapython";
System.out.println(s6.lastIndexOf("java"));//17
System.out.println(s6.lastIndexOf("h"));//24
String s7 = "name=zhangsan&age=18&sex=男";
String newS7 = s7.replace("&", ";");
System.out.println(newS7);//name=zhangsan;age=18;sex=男
String[] splitS7 = s7.split("&");
System.out.println(Arrays.toString(splitS7));//[name=zhangsan, age=18, sex=男]
System.out.println(s6.startsWith("java"));//true
System.out.println(s6.startsWith("python"));//false
System.out.println(s6.substring(10));//c++cphpjavapython
System.out.println(s6.substring(10, 13));//c++
char[] charS6 = s6.toCharArray();
System.out.println(Arrays.toString(charS6));//[j, a, v, a, p, y, t, h, o, n, c, +, +, c, p, h, p, j, a, v, a, p, y, t, h, o, n]
System.out.println(s6.toUpperCase());//JAVAPYTHONC++CPHPJAVAPYTHON
System.out.println(s5.toLowerCase());//hello world
String s8 = " 你 好 世 界 ";
System.out.println(s8.trim());//你 好 世 界
System.out.println("------------------------------");
System.out.println(String.valueOf(123));//123
System.out.println(String.valueOf(3.14));//3.14
System.out.println(String.valueOf(true));//true
System.out.println(String.valueOf(new Object()));//java.lang.Object@4554617c
//valueOf会自动调用toString()方法
}
}
StringBuilder
StringBuilder builder = new StringBuilder();
StringBuilder builder = new StringBuilder("abc");
StringBuilder builder = new StringBuilder(初始长度);
StringBuilder对象的方法
实例
- 通过append向字符串的末尾添加字符串,可以连续append添加
public class Main {
public static void main(String[] args) {
StringBuilder s = new StringBuilder();
s.append("nimabi").append("草拟吗").append("over");
System.out.println(s);
}
}
- insert
通过insert向指定位置添加指定元素
public class Main {
public static void main(String[] args) {
StringBuilder s = new StringBuilder("helloWorld");
s.insert(2,"ttt");//向索引为2的位置添加ttt字符串
System.out.println(s);
}
}
- 删
delete(int x, int y)删除区间[x,y)的元素
deleteCharAt(int index )删除指定位置的元素
4. 改
replace(start,end, string) 将[start, end) 的元素修改为string
- 查
charAt(index)查找index位置的元素
indexOf(String) 查找字符串在该字符串出现的第一次位置
stringbuffer
构造
public StringBuffer() 构造一个其中不带字符的字符串缓冲区,其初始容量为 16 个字符。
public StringBuffer(int capacity) 指定容量的字符串缓冲区对象
public StringBuffer(String str) 指定字符串内容的字符串缓冲区对象
初始化
StringBuffer a=new StringBuffer("abc");
a.append("b");
例子
String a="acd";
StringBuffer b= new StringBuffer(a);
b.insert(1,"b");
System.out.println(b);
输出: cad
总结:
tringBuffer和StringBuilder中常用的方法
StringBuffer append(xxx):拼接字符串
StringBuffer delete(int start,int end):删除指定范围的内容,左开右闭
StringBuffer replace(int start, int end, String str):替换指定范围的内容
StringBuffer insert(int offset, xxx):在指定位置插入指定的内容
StringBuffer reverse() :把当前字符序列逆转
public int indexOf(String str) : 返回指定子字符串在当前字符串中第一次出现处的索引
public String substring(int start,int end) :返回指定范围的子字符串
public int length() : 返回字符串的长度
public char charAt(int n ) : 获取指定索引处的字符
public void setCharAt(int n ,char ch) : 设置指定索引处的字符
相同点:底层都是通过char数组实现的
不同点:
String对象一旦创建,其值是不能修改的,如果要修改,会重新开辟内存空间来存储修改之后的对象;而StringBuffer和StringBuilder对象的值是可以被修改的;
StringBuffer几乎所有的方法都使用synchronized实现了同步,线程比较安全,在多线程系统中可以保证数据同步,但是效率比较低;而StringBuilder 没有实现同步,线程不安全,在多线程系统中不能使用 StringBuilder,但是效率比较高。
如果我们在实际开发过程中需要对字符串进行频繁的修改,不要使用String,否则会造成内存空间的浪费;当需要考虑线程安全的场景下使用 StringBuffer,如果不需要考虑线程安全,追求效率的场景下可以使用 StringBuilder。
StringBuilde非线程安全,StringBuffer是线程安全的,。
速度:StringBuilder>StringBuffer>String
data
概述
java.util.Data类,表示特定的瞬间。精确到毫秒。
常用方法:
- public Date():分配Data对象并初始化此对象。以表示分配它的时间(精确到毫秒)。
- public Data(Long data):分配Data对象并初始化此对象,以表示自从基准时间(成为“历元”(epoch)),即1970年1月1日00:00:00 GTM)以来的指定毫秒数。
- Tips:由于我们处于东八区,所以我们的基准时间为1970年1月1日8时0分0秒。
简单来说:使用无参构造,可以自动设置当前系统时间的毫秒时刻;指定Long类型的构造参数。可以自定义毫秒时刻。例如:
System.out.println(new Date());——>当前时间
System.out.println(new Data(0L));——>把当前的毫秒值转成日期对象。
Tips:在使用println方法的时候,会自动调用Data类中的toString方法。Data类对Object类中的toString方法进行了覆盖重写,所以结果为指定格式的字符串。
常用方法
public Long getTime():把日期对象转换成对应的时间毫秒值。
DataFromat类
java.text.DateFromat是日期/时间格式化子类的抽象类。我们可以通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Data对象与String对象之间进行来回转换。
格式化:按照指定的格式。从Data对象转换为String对象。
解析:按照指定的格式,从String对象转换为Data对象。
构造方法
由于DataFromat为抽象类,不能直接使用,所以需要常用的子类。
java.text.SimpleDataFormat。这个类需要一个模式(格式),来指定格式化或解析的标准。构造方法为:
public SimpleDataFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造SimpleDataFormat。
参数pattern是一个字符串,代表日期时间的自定义格式、
格式规则
常用的格式规则为:
| 标识字母(区分大小写) | 含义 |
|---|---|
| y | 年 |
| M | 月 |
| d | 日 |
| H | 时 |
| m | 分 |
| s | 秒 |
获取当前时间(毫秒级)
package 常用类;
import java.util.Date;
public class data {
public static void main(String[] args) { //
// Get the system date/time 获取系统时间
Date date = new Date();
System.out.println(date.getTime());
}
}
创建SimpleDataFormat对象的代码如:
DataFormat format=new SimpleDataFormat(“yyyy-MM-dd HH:mm:ss”);
常用方法
public String format(Data data):将Data对象格式化为字符串。
public Data parse(String source):将字符串解析为Data对象。
format方法
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
把Date对象转换成String
*/
public class Demo03DateFormatMethod {
public static void main(String[] args) {
Date date = new Date();
// 创建日期格式化对象,在获取格式化对象时可以指定风格
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = df.format(date);
System.out.println(str); // 2008年1月23日
}
}
parse方法
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;//**可以只有转化想要的格式(年,月,日,星期)**
import java.util.Date;
/*
把String转换成Date对象
*/
public class Demo04DateFormatMethod {
public static void main(String[] args) throws ParseException {
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = "2018年12月11日";
Date date = df.parse(str);
System.out.println(date); // Tue Dec 11 00:00:00 CST 2018
}
}
距离某日期天数
package 常用类;
import java.util.Date;
public class data {
public static void main(String[] args) { //
// Get the system date/time 获取系统时间
Date date = new Date();
System.out.println(date.getTime());
int day=(int)(date.getTime()/1000/60/60/24);
System.out.println(day);//输出天数
int hours=(int)(date.getTime()/1000/60/60);
System.out.println(hours);//小时
}
}
Calendar类
java.util.Calendar类是日历类,在Date后出现,替换掉了血多Date的方法。该类将所有可能用到的时间信息封装为静态成员变量,方便获取。日历类就是方便获取各个时间属性的。
获取方法
Calender类为抽象类,由于语言敏感性,Calendar类在创建对象时并非直接创建,而是通过静态方法创建。返回子类对象,如下:
public static Calendar getInstance():使用默认时区和语言环境获得一个一个日历
import java.util.Calendar;
public class Demo06CalendarInit {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
}
}
常用方法
- public int get(int field):返回给定日历字段的值。
- public void set (int field,int value):将给定的日历字段设置为给定值。
- public abstract void add(int field,int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。
- pubic Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。
字段值 含义
YEAR 年
MONTH 月(从0开始,可以+1使用)
DAY_OF_MONTH 月中的天(几号)
HOUR 时(12小时制)
HOUR_OF_DAT 时(24小时制)
MINUTE 分
SECOND 秒
DAY_OF_WEEK 周中的天(周几,周日为1,可以-1使用)
get/set方法
get方法用来获取指定字段的值,set方法用来设置指定字段的值:
import java.util.Calendar;
public class CalendarUtil {
public static void main(String[] args) {
// 创建Calendar对象
Calendar cal = Calendar.getInstance();
// 设置年
int year = cal.get(Calendar.YEAR);
// 设置月
int month = cal.get(Calendar.MONTH) + 1;
// 设置日
int dayOfMonth = cal.get(Calendar.DAY_OF_MONTH);
System.out.print(year + "年" + month + "月" + dayOfMonth + "日");
}
}
import java.util.Calendar;
public class Demo07CalendarMethod {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, 2020);
System.out.print(year + "年" + month + "月" + dayOfMonth + "日"); // 2020年1月17日
}
}
add方法
add方法可以对指定日历字段的值进行加减操作,如果第二个参数为整数则加上偏移量,如果为负数则减去偏移量。
import java.util.Calendar;
public class Demo08CalendarMethod {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
System.out.print(year + "年" + month + "月" + dayOfMonth + "日"); // 2018年1月17日
// 使用add方法
cal.add(Calendar.DAY_OF_MONTH, 2); // 加2天
cal.add(Calendar.YEAR, -3); // 减3年
System.out.print(year + "年" + month + "月" + dayOfMonth + "日"); // 2015年1月18日;
}
}
getTime方法
Calendar中的getTime方法并不是获取毫秒时刻,而是拿到对应的Date对象。
import java.util.Calendar;
import java.util.Date;
public class Demo09CalendarMethod {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
Date date = cal.getTime();
System.out.println(date); // Tue Jan 16 16:03:09 CST 2018
}
}















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









