






目录
一.简介

-
HDFS作为Hadoop三大核心组件之一,主要的功能就是负责数据文件的存储,简单来说HDFS就是Hadoop的文件系统,与传统计算的文件存储方式不同,HDFS采用分布式存储,即在多台计算机上存储文件。
-
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
二、重要特性
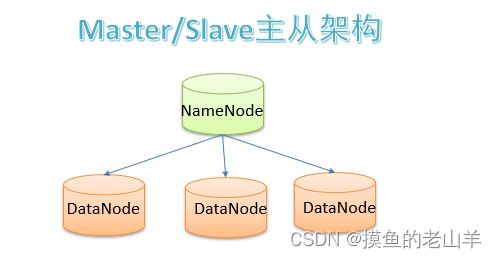
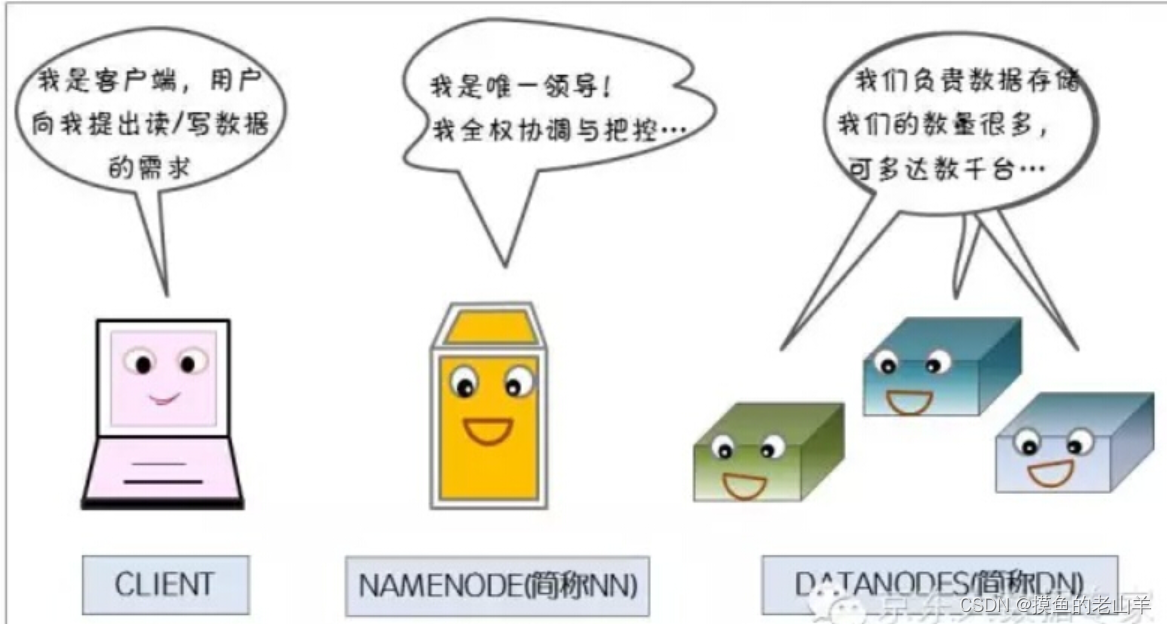
2.1 主从架构
-
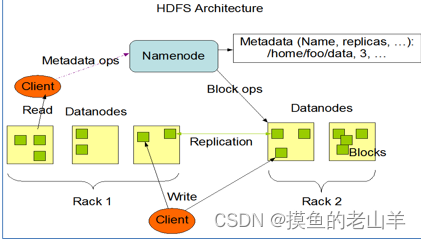
HDFS采用了Master/Slave主从架构。由一个NameNode(大哥)管理一定数量的DataNode(小弟)。NameNode不存储数据,只存储Metadata(描述数据的数据),听起来有点难懂,后面会具体介绍元数据的概念,而存储数据的工作是由DataNode来承担的。
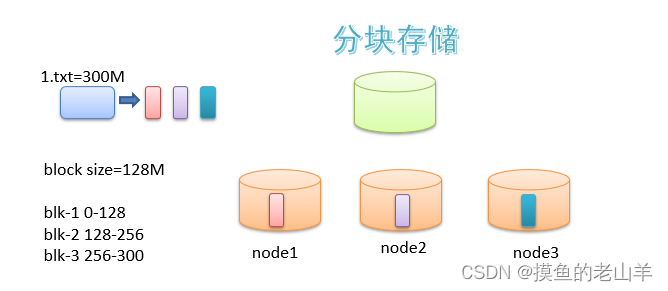
2.2 分块存储
-
分布式存储最主要的特征就是多机存储,HDFS将一个文件分成多个block(块),再将这些block分别存储再不同的DataNode上,block的大小可以通过配置文件修改,默认是128M
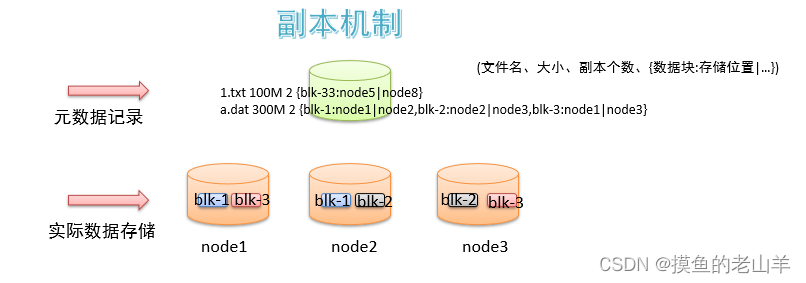
2.3 副本机制
-
HDFS考虑到文件的安全性,在存储文件时,默认会采用副本机制,就是说一个文件的所有block都具有副本,并存在不同的DataNode上,避免一台机器挂了,文件就找不到的情况,副本的个数也可以通过配置参数来改变,默认是3副本(1个原文件+2个副本文件)
2.4 namespace
-
HDFS也具有类似window和linux操作系统一样的目录结构,用户可以创建删除目录,创建删除和移动文件...
2.5 元数据管理
前面说到了NameNode不存储数据,只存储元数据,元数据一共具有两种类型。
文件自身属性

-
文件名、文件大小、权限、副本数、block多大、属于哪个用户
文件块映射位置

-
文件块分别在哪几个DataNode上
2.6 DataNode存储数据块
-
文件的多个block可分别存储在不同的DataNode上,不需要都存在一个DataNode上
-
需要区别的是,副本中相同的block是必需存储在不同的DataNode上的















 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









