







文章目录
1.集合的继承结构图
1.1Collection接口的继承结构图
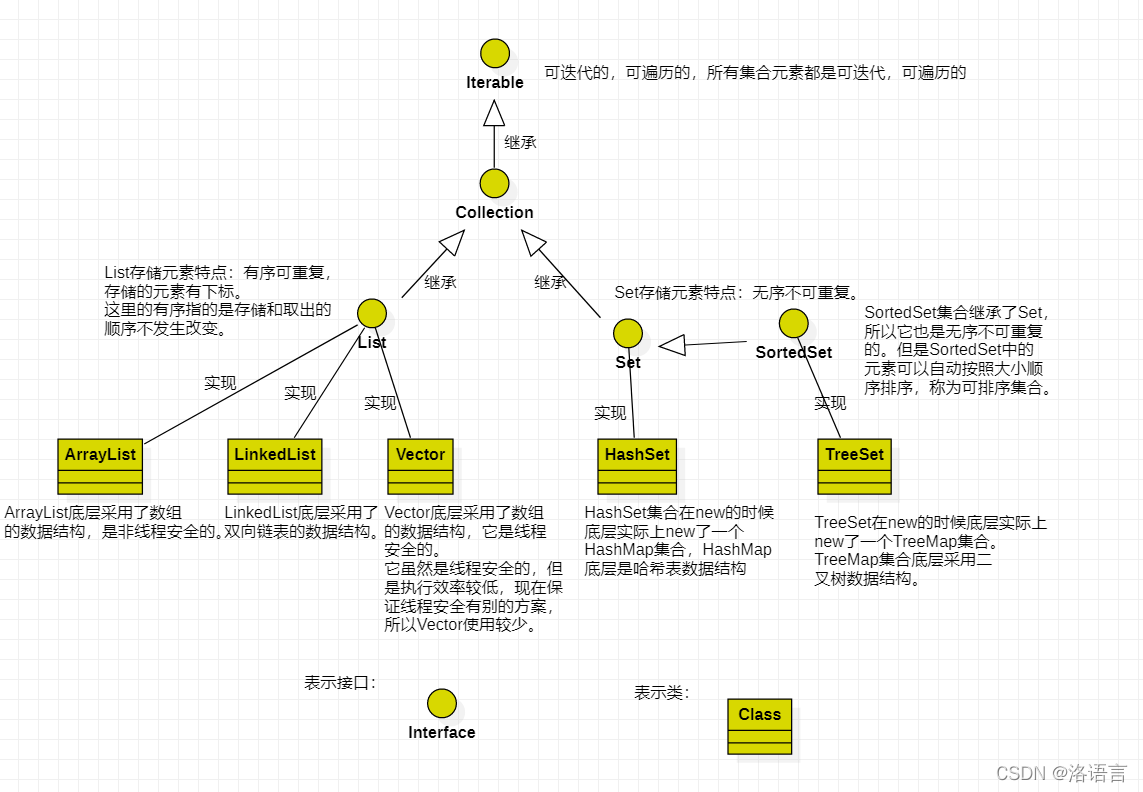
1.2Map接口的继承结构图
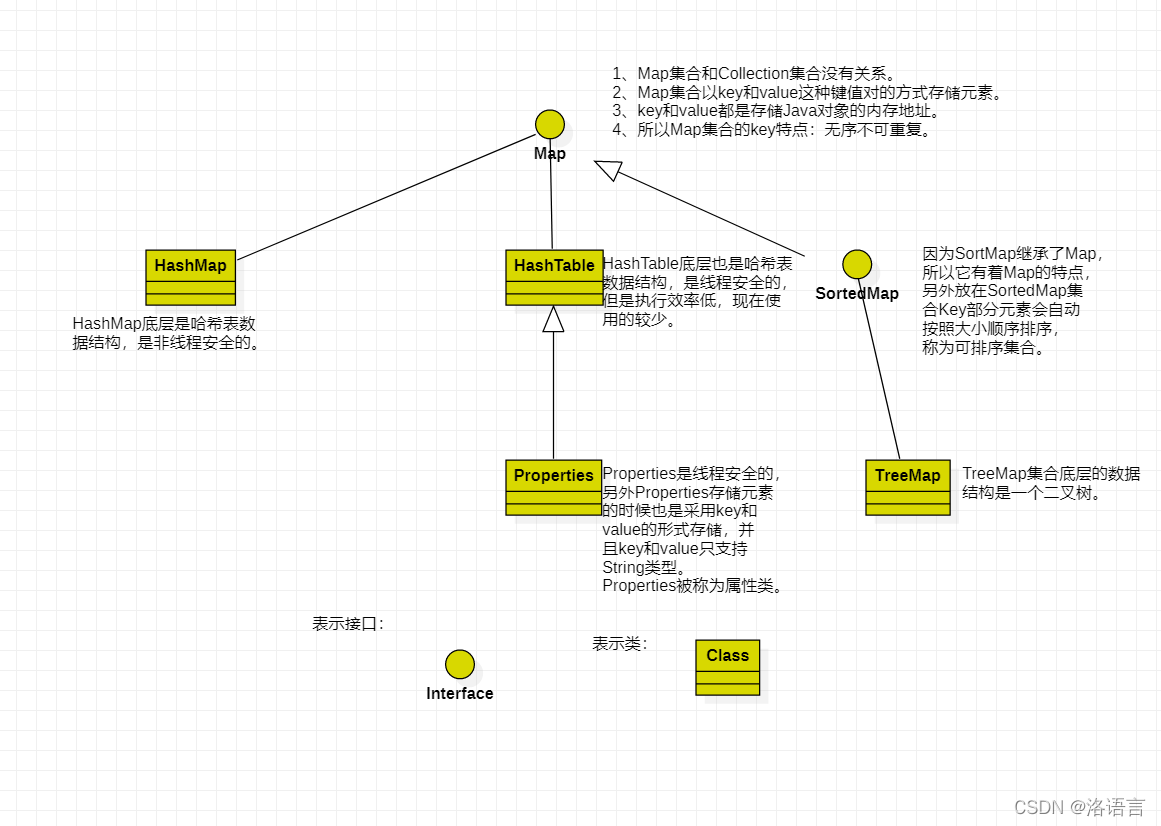
2.Collection接口中常用方法

2.1contains()方法详解
contains()方法的用法很简单,如下:
ArrayList c = new ArrayList();
String s1 = "abc";
//将s1加入集合
c.add(s1);
System.out.println(c.contains(s1));
上面程序编译结果为:true,这里不做过多解释。
ArrayList c = new ArrayList();
String s1 = "abc";
c.add(s1);
String s2 = new String("abc");
System.out.println(c.contains(s2));
我们分析以上代码: String s1 = "abc",s1保存的是"abc"在字符串常量池中的内存地址, String s2 = new String("abc"),s2保存的是堆内存中String对象的地址,s1并不等于s2。集合中存储的是对象地址,所以我们推断集合中并不包含s2,这段代码运行结果是:false。
但是这段代码运行结果是:true。
我们可以看一下contains()的源码:
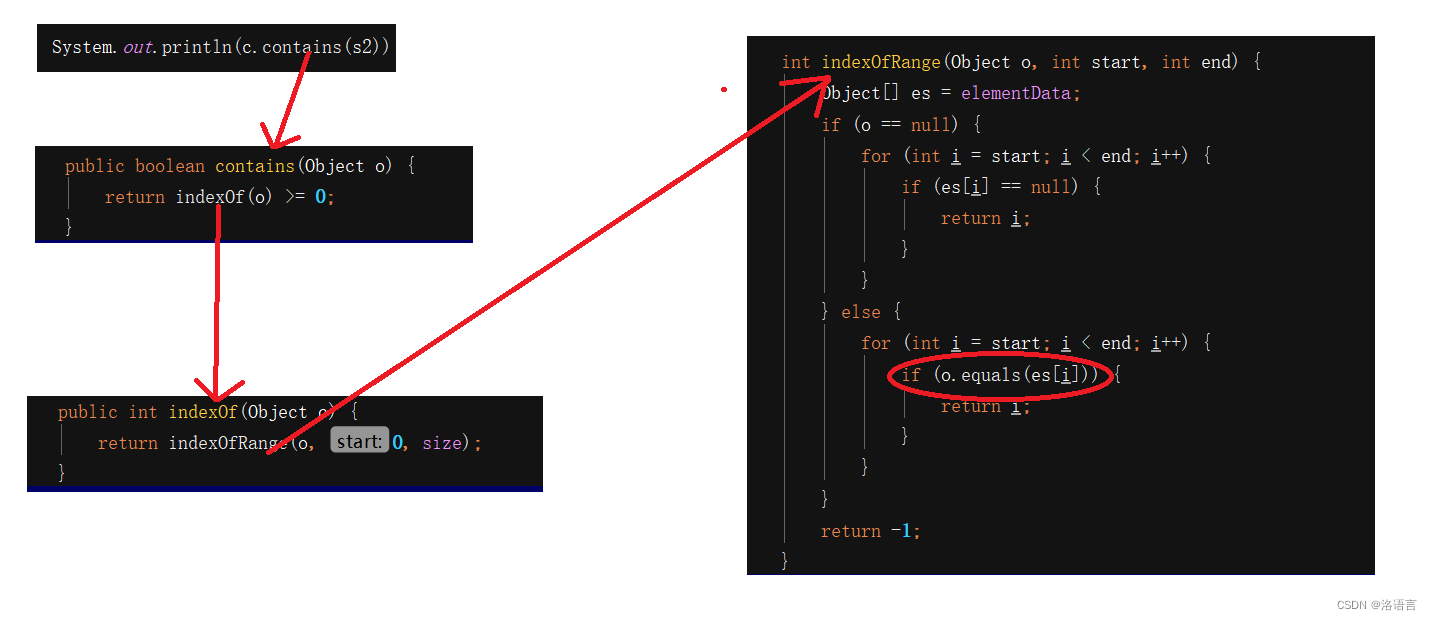
看完源码就能很清楚的知道,contains()最底层调用的是equals(),字符串的equals()是被重写过的,它比较的并不是内存地址,比较的是内存地址所指向的内容。
知道了contains()最底层调用的是equals()方法,下面程序的结果很容易推出:
class A{
String name;
public A(){
}
public A(String name){
this.name = name;
}
}
public class ContainsTest01 {
public static void main(String[] args) {
Collection c = new ArrayList();
A a1 = new A("张三");
A a2 = new A("张三");
c.add(a1);
System.out.println(c.contains(a2));
}
}
运行结果是:false,因为A类中并没用重写equals方法,它比较时仍然比较的内存地址。
所以,自己写的类注意要重写equals()方法。
2.2 remove()方法详解
boolean remove(Object o) —— 删除集合中的元素o,删除成功返回true
用法很简单,如下:
public class RemoveTest01 {
public static void main(String[] args) {
Collection c = new ArrayList();
String s1 = new String("abc");
c.add(s1);
c.remove(s1);
System.out.println(c.size());
}
}
编译结果:0,这里不做过多解释。
阅读以下代码:
public class RemoveTest01 {
public static void main(String[] args) {
Collection c = new ArrayList();
String s1 = new String("abc");
String s2 = new String("abc");
c.add(s1);
c.remove(s2);
System.out.println(c.size());
}
}
编译结果:0,s1与s2存的是两个不同地址,但是 c.remove(s2)仍然将集合中的s1删掉了,不难猜出remove()底层仍然调用的是equals()方法。
remove()源代码如下:
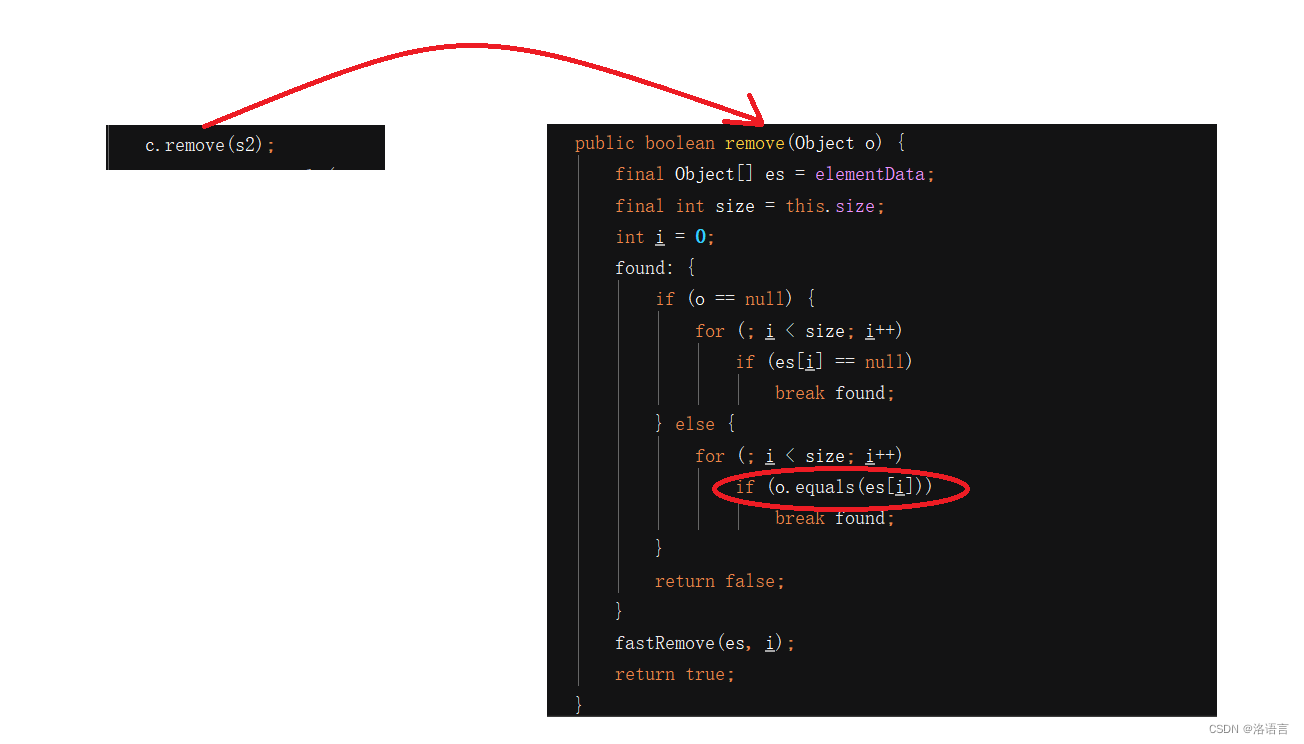
这里同样告诉我们,equals()方法的重要性。
3.集合的遍历
3.1通过迭代器遍历集合
集合对象调用 iterator()方法会返回一个迭代器对象:
Iterator it = c.iterator();
迭代器中常用方法:
- boolean hasNext() —— 判断集合中是否还有可迭代元素,如果有返回true。
- E next() —— 将集合迭代的下一个元素返回,并且迭代器指向迭代的下一个元素,不使用“泛型”时,均返Object类引用,但是对象类型不会改变。
- default void remove() —— 删除迭代器指向的当前元素。
c.add(2);
c.add(3)
c.add(4);
c.add(5);
Iterator it = c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
编译结果如下:

-
注意一:迭代器最开始并没有指向集合中的第一个元素,而是指向第一个元素的前面。
-
注意二:获取迭代器对象后不能直接调用迭代器中的
remove()方法,因为此时迭代器并未指向集合中元素,否则会出现异常:java.lang.IllegalStateException。
Collection c = new HashSet();
c.add(1);
Iterator it = c.iterator();
it.remove();
编译结果:

- 注意三:迭代器所指向对象被删除后,不能继续调用迭代器的
remove()方法,否则会出现异常:java.lang.IllegalStateException。
Collection c = new HashSet();
c.add(1);
c.add(2);
Iterator it = c.iterator();
c.next();
it.remove();//将1删除,但是迭代器的指向并未往后移
it.remove();
编译结果:

- 注意四:调用集合对象中方法使集合结构发生改变,迭代器必须重新获取,继续使用以前的迭代器会出现异常:
java.util.ConcurrentModificationException
Collection c = new HashSet();
c.add(2);
Iterator it = c.iterator();
c.add(3)
c.add(4);
c.add(5);
while(it.hasNext()){
System.out.println(it.next());
}
编译结果:

迭代器的原理:
为什么获取迭代器后,不可以调用集合对象的方法来改变集合,但是可以调用迭代器的方法来改变集合?
我们可以这样来理解迭代器:获取迭代器相当于对集合拍了一张’‘照片’‘,这张照片是和集合一一对应的,我们可以按照这张’‘照片’‘来遍历集合。如果调用了集合对象中的方法增加或者删除某一个元素,那么此时’‘照片’‘与集合并不在是一一对应的关系,迭代器并不在继续适用。如果调用迭代器的方法来删除集合中的某一个元素,可以在’‘照片’‘和集合中同时找到该元素,并且删除,此时’‘照片’'与集合仍然一一对应,迭代器依然适用。
3.2增强for循环遍历集合
格式如下:
for (元素的数据类型 变量名: Collection集合or数组) {
// 写操作代码
}
注意:这里的元素数据类型指的是可以存入集合中的元素数据类型,在集合不使用泛型前,默认时Object类型。
Collection c = new HashSet();
c.add(2);
c.add(3)
c.add(4);
c.add(5);
for(Object i : c){
System.out.println(i);
}
其实增强for循环内部原理其实是一个Iterator迭代器,所以在遍历的过程中,不能对集合中的的元素进行操作。
3.3通过下标来遍历集合
对于有下标的集合(List集合),我们也可以通过下标来遍历集合。
Collection c = new HashSet();
c.add(2);
c.add(3)
c.add(4);
c.add(5);
for(int i = 0; i < c.size(); i++){
System.out.println(c.get(i));
}
其中get()方法是List集合中的方法:
E get(int index) —— 返回指定下标位置的元素。
4.List集合
4.1List集合存储特点
- 有序可重复,这里的有序指的是存储和取出的顺序不发生改变。
- 存储的元素有下标。
4.2List接口中常用的特有方法

4.3ArrayList集合
-
ArrayList默认初始容量为10。 -
ArrayList底层是一个Object类型的数组,是非线程安全的。 -
ArrayList构造方法可以指定初始化容量。 -
当
ArrayList容量不够时,会自动扩容:
int newCapacity = oldCapacity + (oldCapacity >> 1);
扩容后容量是原容量的1.5倍 -
数组扩容的效率较低,所以在创建
ArrayList时要给定一个合适的初始化容量 -
优点: 数组的检索效率很高 缺点: 1. 数组元素随机的增删效率较低(数组末尾的增删除外),数组扩容效率较低。 2. 数组存不了大量数据,因为数组在内存中是连续的,很难找到一块很大的连续空间。 3. ArrayList是非线程安全的。
ArrayList的构造方法:

4.4Vector集合
- Vector底层采用了数组的数据结构,它是线程安全的。
- 它虽然是线程安全的,但是执行效率较低,现在保证线程安全有别的方案,所以Vector使用较少。
- Vector初始化容量为10,扩容时,扩容后容量是扩容前的2倍。
Vector集合与ArrayList基本一致,这里不做过多讲解。
5.TreeSet集合
-
TreeSet底层是TreeMap,放进TreeSet中的元素相当于将元素放进了TreeMap的key部分。
-
TreeSet集合元素特点:无序不可重复,但是可以将元素自动排序。
-
对于自定义的类型,TreeSet并不能直接排序,所以无法正常的放入TreeSet集合。要想将自定义类型放入TreeSet集合中,需要让该类实现Comparable接口,并且实现该接口中的compareTo方法(在该方法中指定比较规则)。(Sting、包装类都已经实现了该接口)
class Student implements Comparable<Student>{
int age;
public Student(){
}
public Student(int age){
this.age = age;
}
public int compareTo(Student s){
/*
按年龄升序排序
this.age > s.age 返回大于0的数
this.age = s.age 返回0
this.age < s.age 返回小于0的数
*/
return age - s.age;
}
}
此时,就可以将Student类对象加到TreeSet集合中了。
Student s1 = new Student(13);
Student s2 = new Student(12);
Student s3 = new Student(15);
Student s4 = new Student(11);
t.add(s1);
t.add(s2);
t.add(s3);
t.add(s4);
for(Object s :t) {
Student stu = (Student) s;
System.out.println(stu.age);
}
- 除了让自己写的类实现Comparable接口外,还可以在创建TreeSet集合时传一个比较器对象()的方式。 比较器可以在外部实现,也可以采用匿名内部类的方式。
创建比较器类:
class Studentcomparator implements Comparator<Student>{
public int compare(Student o1, Student o2){
return o1.age - o2.age;
}
}
将比较器对象传给TreeSet的构造方法:
TreeSet t = new TreeSet(new Studentcomparator());
Student s1 = new Student(13);
Student s2 = new Student(12);
Student s3 = new Student(15);
Student s4 = new Student(11);
t.add(s1);
t.add(s2);
t.add(s3);
t.add(s4);
for(Object s :t) {
Student stu = (Student) s;
System.out.println(stu.age);
}
我们也可以采用匿名内部类的方法将比较器对象传给TreeSet的构造方法:
TreeSet t = new TreeSet(new Comparator<Student>() {
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
});
- 两种方式如何选择?
若比较规则不会发生改变,就选择实现Comparable接口,例:String类和Integer类都实现了Comparable接口。
若比较方式会发生改变,那么就建议采用比较器的方式,
6.Map接口
-
Map和Collection没有关系。
-
Map集合以key和value的方式存储(键值对)
key和value都属于引用数据类型。
key和value都存储对象的内存地址。
key起主导的地位,value是key的一个附属品。 -
Map接口中的常用方法:
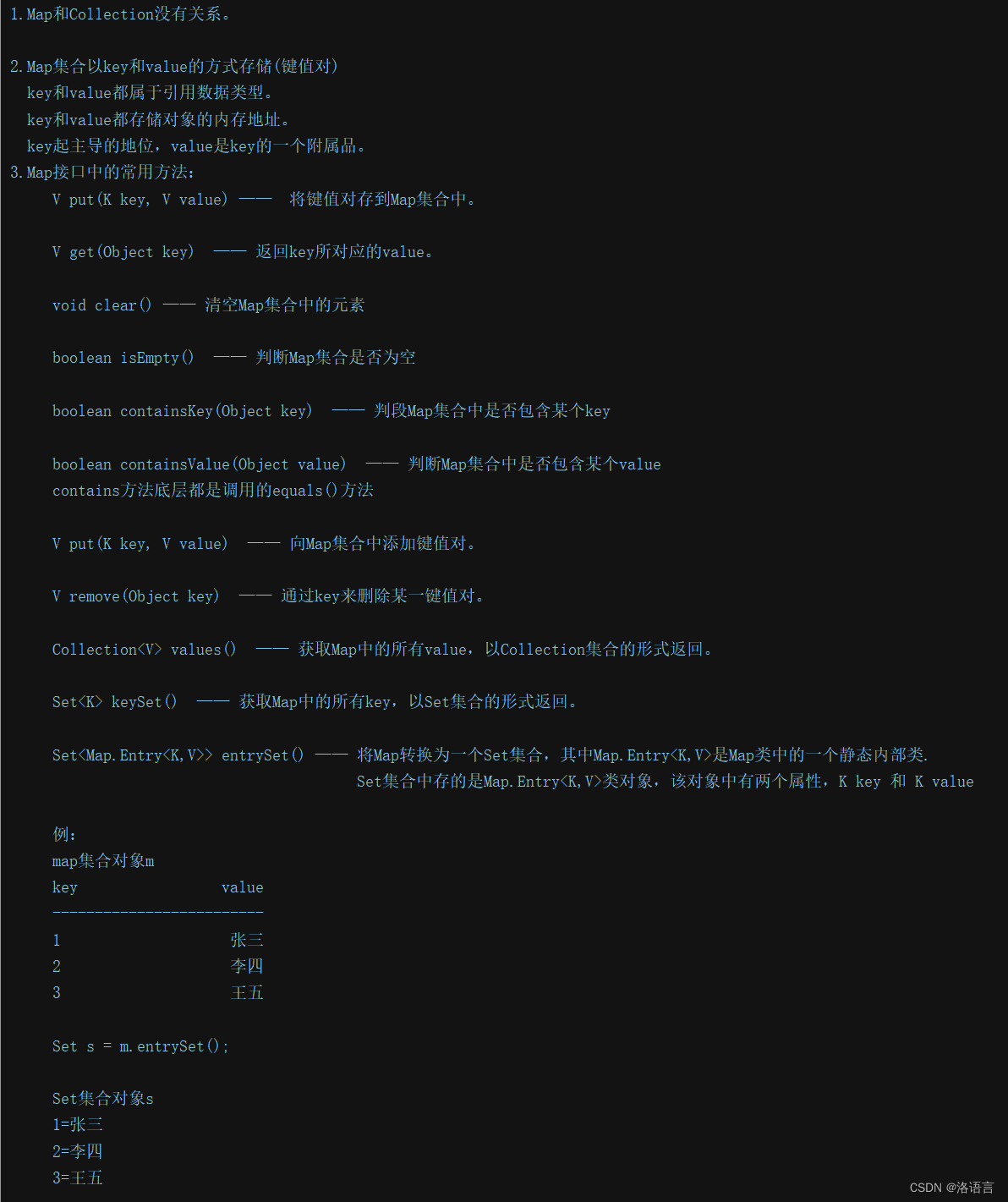
Map集合的遍历
创建集合:
HashMap<Integer,String> m = new HashMap<>();
m.put(1,"张三");
m.put(2,"李四");
m.put(3,"王五");
方法一:通过keySet()方法获得key的集合,通过values()方法获得value()集合。
Set<Integer> s1 = m.keySet();
Collection<String> c1 = m.values();
Iterator<Integer> it1 = s1.iterator();
Iterator<String> it2 = c1.iterator();
while(it1.hasNext() && it2.hasNext()){
System.out.println(it1.next() + " " + it2.next());
}
方法二:通过entrySet()方法获得key和value的Set集合
Set<Map.Entry<Integer,String>> set = m.entrySet();
Iterator<Map.Entry<Integer,String>> it = set.iterator();
while(it.hasNext()){
Map.Entry<Integer,String> node = it.next();
System.out.println(node.getKey() + " " + node.getValue());
}
6.1HashMap集合
-
HashMap底层是哈希表,哈希表是一种将数组和链表两种数据结构融合一起的数据结构,能够充分发挥二者的优点。
-
hashMap底层源代码分析(简化版):
public class HashMap{
//hashMap底层是一个一维数组,数组存的是单向链表
Node<K,V>[] table;
//匿名内部类
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//哈希值(是key的hashCode()方法执行后,通过哈希算法可以将哈希值转换为数组下标)
final K key;//存储到Map集合中的key
V value;//存储到Map集合中的value
Node<K,V> next;//下一个节点的内存地址
}
}
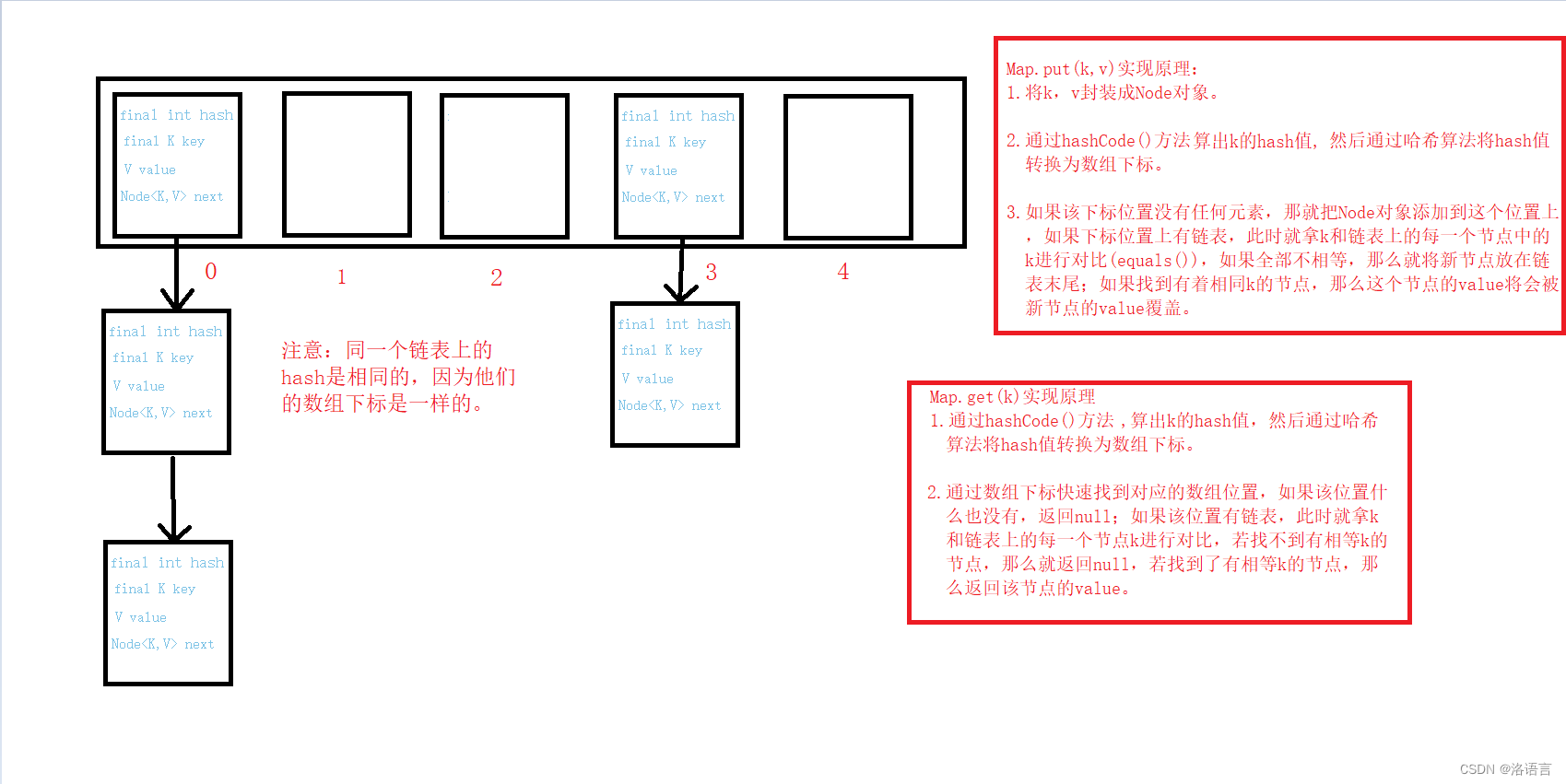
-
通过
get和put两个方法的实现原理可知,key的equals()方法是需要重写的, 同时,如果所有元素的hash值都相同,那么哈希表就变成一个单向链表,如果所有元素的hash值都不相同,HashMap就会变成一个一维数组(不考虑哈希碰撞)。
所以要使哈希表更好的发挥它的性能,需要让哈希表散列分布均匀,所以我们需要重写key的hashCode()方法。 -
HashMap默认初始容量为16,默认加载因子为0.75(当底层数组容量占用75%时,数组开始扩容,扩容后容量是原容量的二倍)。 -
源代码中注释:
The default initial capacity - MUST be a power of two.
HashMap自定义初始化容量必须是2的幂,因为这样才能达到散列分布均匀,提高HashMap的存取效率。 -
HashMap源代码中有这两行代码:
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
JDK8之后当HashMap中单链表上的节点个数大于8个时,单向链表的数据结构就会变成红黑树数据结构,当红黑树上节点个数小于6个时,又会变成单向链表。 -
HashMap允许key和value是
null。
6.2Hashtable集合
-
Hashtable底层是哈希表,是线程安全的。 -
Hashtable集合初始化容量为11,加载因子0.75,每次扩容新容量是原容量的2倍再加1(保证为奇数)。 -
Hashtable集合的key和value都不允许为null(不同于HashSet)。
6.3Properties集合
-
Properties是一个Map集合,继承Hashtable;Properties集合的key和value都是String类型。 -
Properties对象被称为属性类对象。 -
Properties是线程安全的。 -
Properties中的常用方法
















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









