






基于游盛平台交易数据的离线计算,统计分析交易数据
背景
大部分饰品倒货玩家都通过一个平台进货,虽然该平台在圈内较火,但并没有统计数据的流出,故通过平台交易数据做统计,再基于大数据框架分析,可以挖掘部分商业信息。
项目概述
数据来源
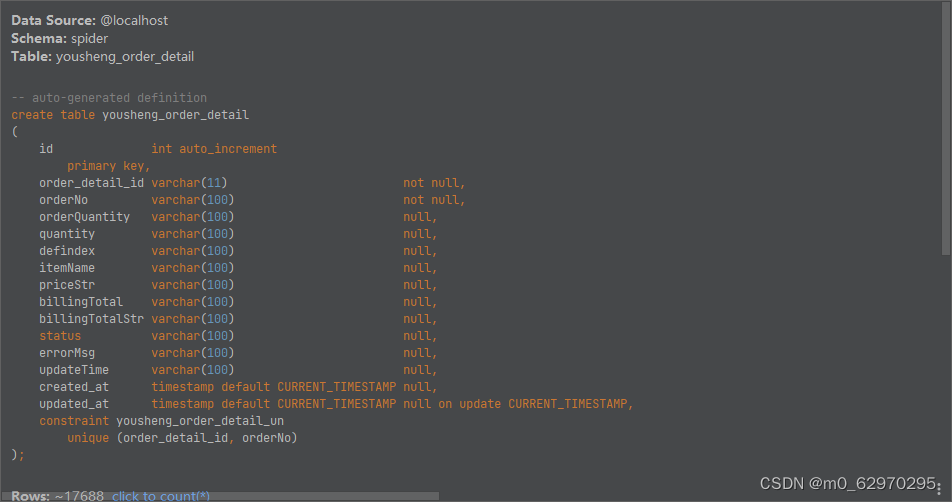
平台提供的交易数据有订单列表和订单详情如下,
订单列表
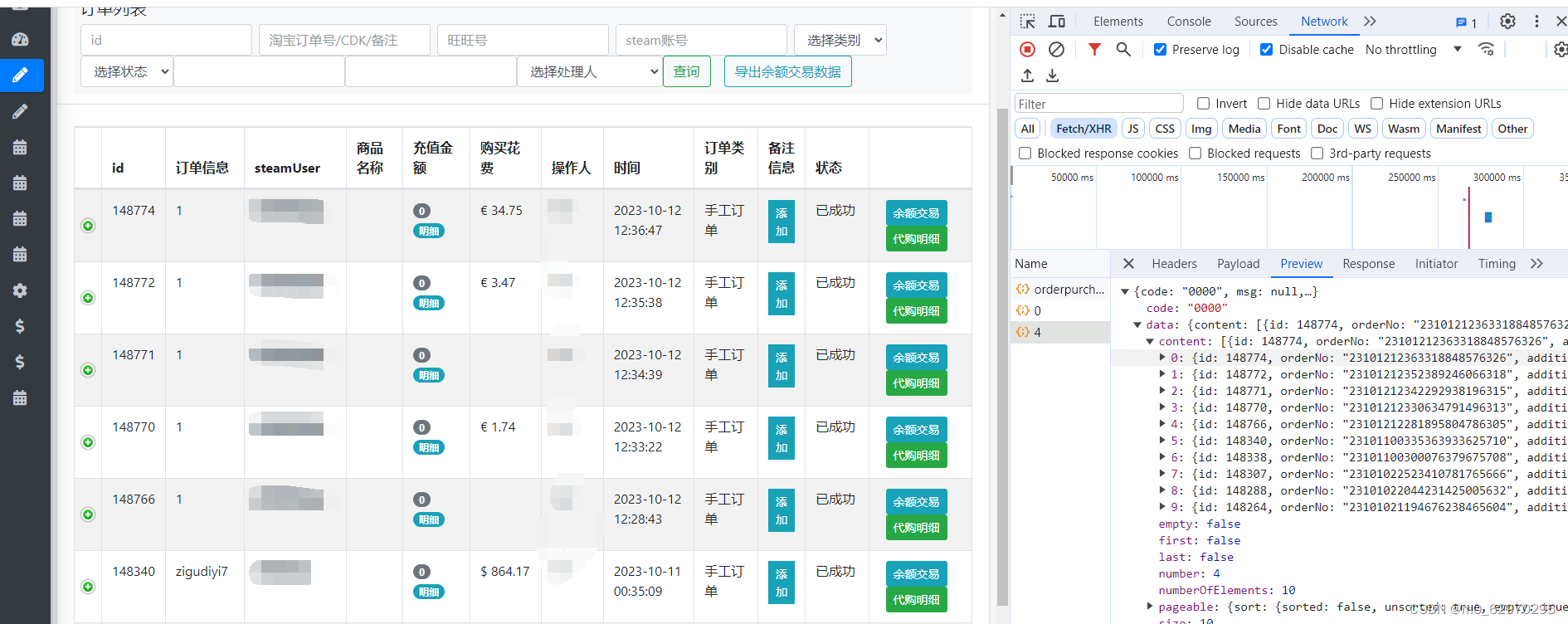
订单详情
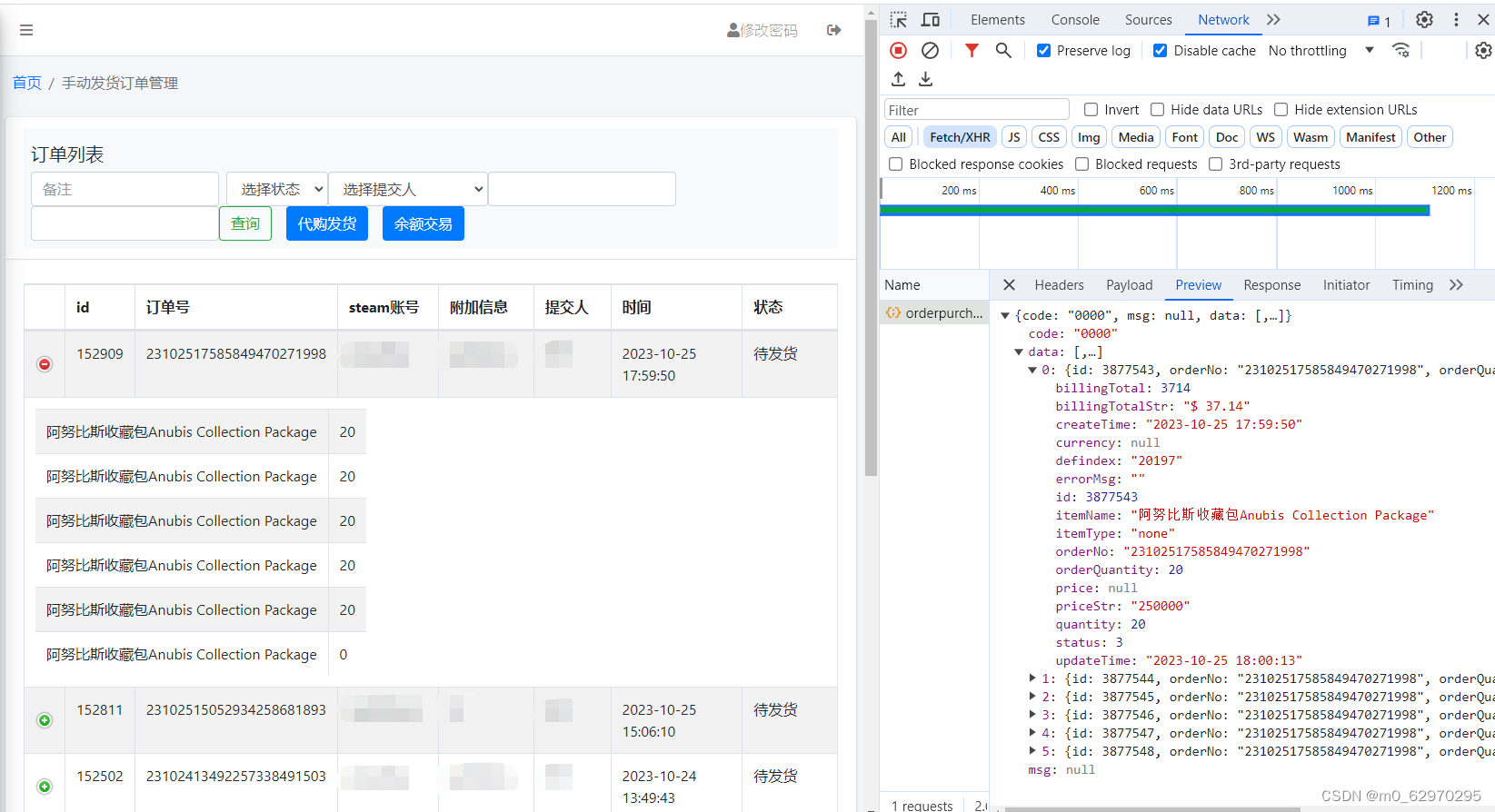
预实现指标
通过爬虫技术爬取,并根据平台数据完成如下指标
1. 统计出每月每周每天热售的饰品
2. 笼统统计饰品存世量
3. 最大的倒钩有哪些
4. 倒钩进货时间分布情况
5. 一些比较有特点的倒钩的进货习惯
6. 那些时间段进货频率会增加
7. 统计进货价的价格走势
数仓建模流程图
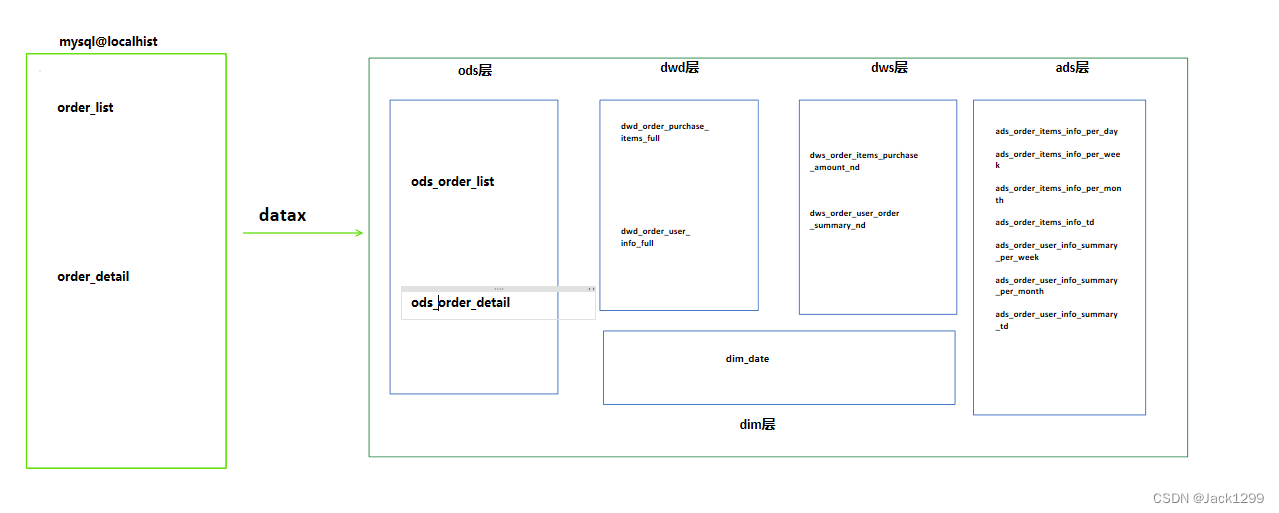
具体实现
1. 数据采集和存储
本文不重点介绍数据采集过程,数据采集结果和存储细节如下
通过列表页接口,获取订单信息和订单id
获取的信息存储到MySQL中order_list表中
order-list
从2023年4月25日的数据到10月17日的数据
实际交易记录2963
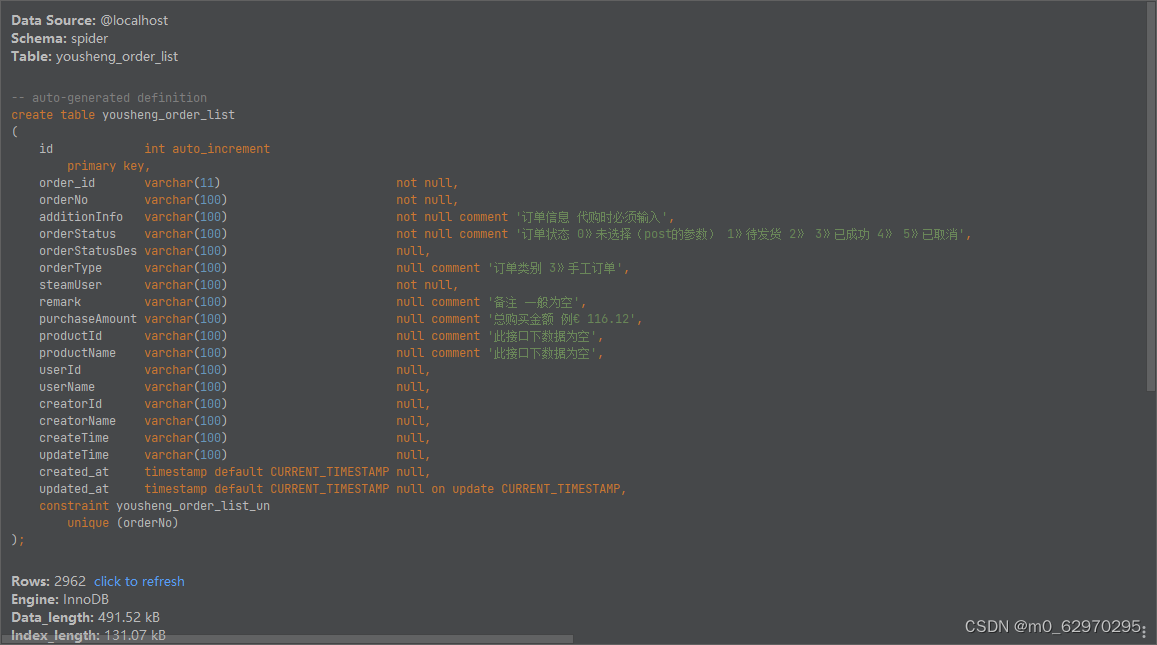
部分数据展示
根据订单id获取订单购买内容
爬取的订单信息存储到order_detail中
order-detail
从2023年4月25日的数据到10月17日的数据
实际交易项17688
采集思路中的小亮点:
利用订单id去获取详情,采用的不是迭代,才不是直接从mysql中获取
采用redis进行数据调度
通过shelduler模块读取mysql中id的值,在将获取的内容存储到redis中
缺点是实现过程相对复杂一些
优点是方便查看和管理redis中内容,并且对爬取失败的记录可以记录到
从而保证不会漏爬数据
2. 数据提取至HDFS
采用datax实现本地mysql数据到hdfs
job.json如下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"order_id",
"orderNo",
"additionInfo",
"orderStatus",
"orderStatusDes",
"orderType",
"steamUser",
"remark",
"purchaseAmount",
"productId",
"productName",
"userId",
"userName",
"creatorId",
"creatorName",
"createTime",
"updateTime",
"created_at",
"updated_at"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.145.1:3306/spider"],
"table": [
"yousheng_order_list"
]
}
],
"password": "1234",
"username": "lijiale",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "order_id",
"type": "INT"
},
{
"name": "orderNo",
"type": "STRING"
},
{
"name": "additionInfo",
"type": "STRING"
},
{
"name": "orderStatus",
"type": "STRING"
},
{
"name": "orderStatusDes",
"type": "STRING"
},
{
"name": "orderType",
"type": "STRING"
},
{
"name": "steamUser",
"type": "STRING"
},
{
"name": "remark",
"type": "STRING"
},
{
"name": "purchaseAmount",
"type": "STRING"
},
{
"name": "productId",
"type": "STRING"
},
{
"name": "productName",
"type": "STRING"
},
{
"name": "userId",
"type": "STRING"
},
{
"name": "userName",
"type": "STRING"
},
{
"name": "creatorId",
"type": "STRING"
},
{
"name": "creatorName",
"type": "STRING"
},
{
"name": "createTime",
"type": "DATE"
},
{
"name": "updateTime",
"type": "DATE"
},
{
"name": "created_at",
"type": "DATE"
},
{
"name": "updated_at",
"type": "DATE"
}
],
"compress": "",
"defaultFS": "hdfs://node1:8020",
"fieldDelimiter": "\t",
"fileName": "ods_yousheng_order_list",
"fileType": "text",
"path": "/yousheng/ods_yousheng_order_list",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
小插曲
显示的值为null
自己对metastore,datax理解不足
3. 数仓建模
指标体系构建
原始指标如下
1. 统计出每月每周每天热售的饰品
2. 笼统统计饰品存世量
3. 最大的倒钩有哪些
4. 倒钩进货时间分布情况
5. 一些比较有特点的倒钩的进货习惯
6. 那些时间段进货频率会增加
7. 统计进货价的价格走势
先进行指标分析和拆解
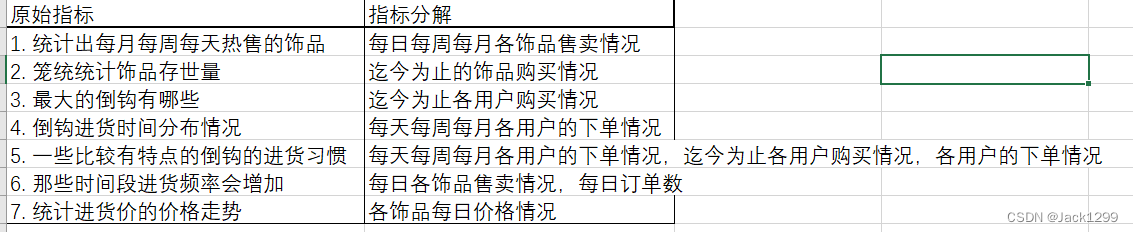
分解成派生指标后,在对派生指标进行分析

其中,颜色相同是因为数据主要来源和统计粒度相同
后续在dws层建表时,颜色相同的一组指标对应一个dws表
udf编写
hive_unify_currency
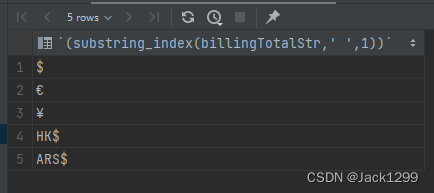
函数简介:订单中购买总额的格式如下€ 168.04,HK$ 58.28 该函数用于货币的统一,统一成美元USD
首先确定数据库中共有几种货币类型,使用如下sql语句实现
select distinct (substring_index(billingTotalStr,' ',1))
from yousheng_order_detail
where billingTotalStr != '0';
得到的结果
因为设计的货币较少,货币种类和货币兑换率直接写在python代码中
import sys
# 货币兑换成美元的换算比例
exchange_rates = {
'$': 1,
'€': 1.06,
'¥': 0.14,
'HK$': 0.13,
'ARS$': 0.0029,
}
def main(n: int):
"""
将系统输入的货币值字符串进行统一
输出换算后的货币值
n 需要修改的行数
输入示例
$ 270.3
€ 19.11
:return:
"""
try:
for line in sys.stdin:
if not line:
continue
cols = line.strip().split('\t')
cols[n] = str(unify_currency(cols[n]))
# currency 加在最后一列
cols.append('USD')
output_string = '\t'.join(cols)
print(output_string)
except Exception as e:
print(e)
def unify_currency(input_str: str):
if len(input_str) < 2:
return input_str
symbol, value = input_str.split(' ')
unified_value = float(value) * exchange_rates.get(symbol, 1)
unified_value = round(unified_value, 2)
return unified_value
if __name__ == '__main__':
main(9)
dim层
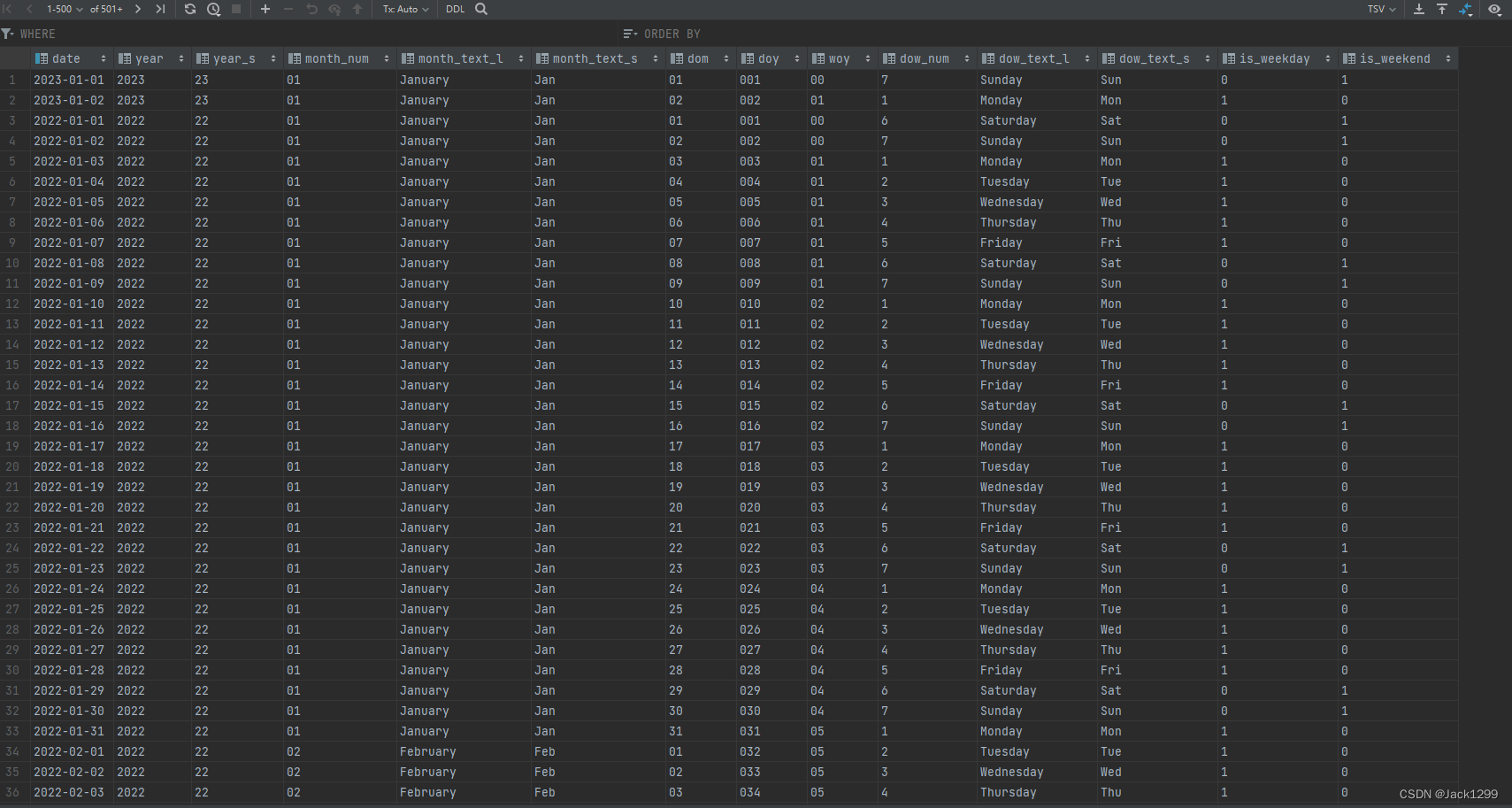
使用python生成dim_date表
生成dim_data的python程序如下
其中initializer.Initializer().init_mysql()是自己封装的代码,目的是连接mysql,不再展示此代码具体细节
import re
import sys
import pandas as pd
import datetime
from pandas import DataFrame
from utils.initializer import initializer
mysql_cli = initializer.Initializer().init_mysql()
def gen_datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.datetime.strftime(x, '%Y-%m-%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def process_date(input_str: str) -> {}:
"""Processes and engineers simple features for date strings
Parameters:
input_str (str): Date string of format '2021-07-14'
Returns:
dict: Dictionary of processed date features
"""
# Validate date string input
regex = re.compile(r'\d{4}-\d{2}-\d{2}')
if not re.match(regex, input_str):
print("Invalid date format")
sys.exit(1)
# Process date features
my_date = datetime.datetime.strptime(input_str, '%Y-%m-%d').date()
now = datetime.datetime.now().date()
date_feats = {}
date_feats['date'] = input_str
date_feats['year'] = my_date.strftime('%Y')
date_feats['year_s'] = my_date.strftime('%y')
date_feats['month_num'] = my_date.strftime('%m')
date_feats['month_text_l'] = my_date.strftime('%B')
date_feats['month_text_s'] = my_date.strftime('%b')
date_feats['dom'] = my_date.strftime('%d')
date_feats['doy'] = my_date.strftime('%j')
date_feats['woy'] = my_date.strftime('%W')
# Fixing day of week to start on Mon (1), end on Sun (7)
dow = my_date.strftime('%w')
if dow == '0':
dow = '7'
date_feats['dow_num'] = dow
if dow == '1':
date_feats['dow_text_l'] = 'Monday'
date_feats['dow_text_s'] = 'Mon'
date_feats['dow_num'] = dow
if dow == '2':
date_feats['dow_text_l'] = 'Tuesday'
date_feats['dow_text_s'] = 'Tue'
date_feats['dow_num'] = dow
if dow == '3':
date_feats['dow_text_l'] = 'Wednesday'
date_feats['dow_text_s'] = 'Wed'
date_feats['dow_num'] = dow
if dow == '4':
date_feats['dow_text_l'] = 'Thursday'
date_feats['dow_text_s'] = 'Thu'
date_feats['dow_num'] = dow
if dow == '5':
date_feats['dow_text_l'] = 'Friday'
date_feats['dow_text_s'] = 'Fri'
date_feats['dow_num'] = dow
if dow == '6':
date_feats['dow_text_l'] = 'Saturday'
date_feats['dow_text_s'] = 'Sat'
date_feats['dow_num'] = dow
if dow == '7':
date_feats['dow_text_l'] = 'Sunday'
date_feats['dow_text_s'] = 'Sun'
date_feats['dow_num'] = dow
if int(dow) > 5:
date_feats['is_weekday'] = 0
date_feats['is_weekend'] = 1
else:
date_feats['is_weekday'] = 1
date_feats['is_weekend'] = 0
return date_feats
def insert_or_update(table_name: str, data_list=None, not_update_field: list = list(),
insert_key: str = 'into'):
mysql_client = None or mysql_cli
if not data_list:
return data_list
if not isinstance(data_list, (list, dict)):
print('insert data must be list or dict.')
return False
if isinstance(data_list, list) and not data_list[0]:
return data_list[0]
datas = data_list
if isinstance(datas, dict):
# 字典转列表
datas = [datas]
try:
# data_df = DataFrame(data_list)
data_df = DataFrame(datas).where((pd.notnull(DataFrame(datas))), None) # 处理字段是NULL的情况
column_str = ','.join(f'`{field}`' for field in data_df.columns)
value_str = ','.join(['%s'] * len(data_df.columns))
update_list = list()
for column in data_df.columns:
if column in not_update_field:
continue
update_list.append('`{field}`=VALUES(`{field}`)'.format(field=column))
update_str = ','.join(update_list)
if '.' in table_name:
table_name = table_name.split('.')
table_name = f"`{table_name[0].replace('`', '')}`.`{table_name[1].replace('`', '')}`"
else:
table_name = f"`{table_name}`"
if insert_key.upper() == 'IGNORE':
sql = f"INSERT IGNORE {table_name} ({column_str}) VALUES({value_str})"
else:
sql = f"INSERT INTO {table_name} ({column_str}) VALUES({value_str}) " \
f"ON DUPLICATE KEY UPDATE {update_str}"
result = mysql_client.write_many(sql, data_df.values.tolist())
return result
except Exception as e:
print(e)
return False
if __name__ == '__main__':
start_date = '20220101'
end_date = '20231231'
date_list = gen_datelist(start_date, end_date)
date_info_list = []
for date in date_list:
date_info_list.append(process_date(date))
table_name = 'dim_date'
res = insert_or_update(table_name,date_info_list)
print(f'Insert result : {res}')
生成的dim_data数据如下
dwd层
数据明细层
dwd_order_purchase_items_full
订单域下的购买物品明细,是个全量快照表
– 建表语句
drop table if exists dwd_order_purchase_items_full;
create external table dwd_order_purchase_items_full
(
id int,
order_detail_id int,
orderno string,
orderquantity int,
quantity int,
defindex int,
itemname string,
pricestr string,
billingtotal string,
exchangedbillingtotal string comment '经过换算过的货币值',
status int,
errormsg string,
updatetime date,
created_at date,
updated_at date,
currency string
)
partitioned by (dt string)
row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/dwd_order_purchase_items_full';
– 数据装载
add file /export/server/hive/udfs/hive_unify_currency.py; -- 汇率转换
insert into dwd_order_purchase_items_full partition (dt = '2023-11-3')(select transform ( * ) using 'python3.10 hive_unify_currency.py' as (id,
order_detail_id,
orderNo,
orderQuantity,
quantity,
defindex,
itemName,
priceStr,
billingTotal,
exchangedbillingtotal,
status,
errorMsg,
updateTime,
created_at,
updated_at,
currency
)
from ods_yousheng_order_detail
where billingTotalStr != '0'
and status != 4);
部分数据展示
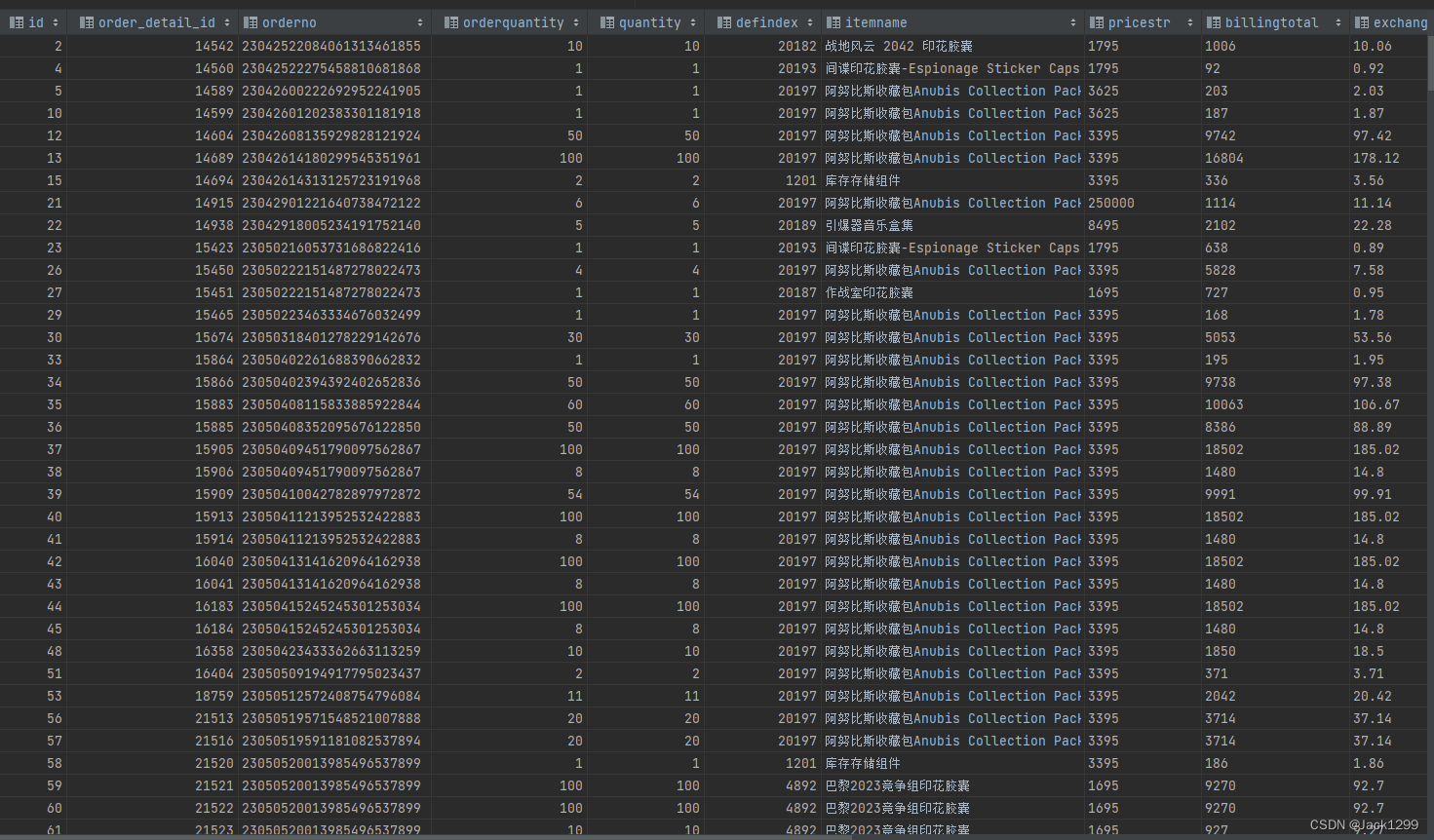
dwd_order_user_info_full
订单域下的用户信息,涉及用户名的hash值,购买的物品数量,金额,是个全量快照表
drop table if exists dwd_order_user_info_full;
create external table dwd_order_user_info_full
(
orderno string,
additioninfo string,
orderstatus string,
orderstatusdes string,
hashed_steamuser string,
remark string,
creatorid string,
creatorname string,
createtime date,
purchaseamount decimal(16, 2),
quantity int,
updatetime date
) row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/dwd_order_user_info_full';
– 数据装载
add file /export/server/hive/udfs/hive_unify_currency.py; -- 汇率转换
insert into dwd_order_user_info_full
select transform ( * ) using 'python3.10 hive_unify_currency.py' as (
orderno,
additioninfo,
orderstatus,
orderstatusdes,
hashed_name,
remark,
creatorid,
creatorname,
createtime ,
purchaseamount,
quantity,
updatetime
)
from (select t.orderno,
additioninfo,
orderstatus,
orderstatusdes,
hash(steamuser) hashed_name,
remark,
creatorid,
creatorname,
createtime,
purchaseamount,
quantity,
updatetime
from (select * from ods_yousheng_order_list
where purchaseamount != '') t
left join
(select orderno,
sum(quantity) quantity
from ods_yousheng_order_detail order_detail
group by orderno) detail
on t.orderno = detail.orderno) tar_table;
部分数据展示
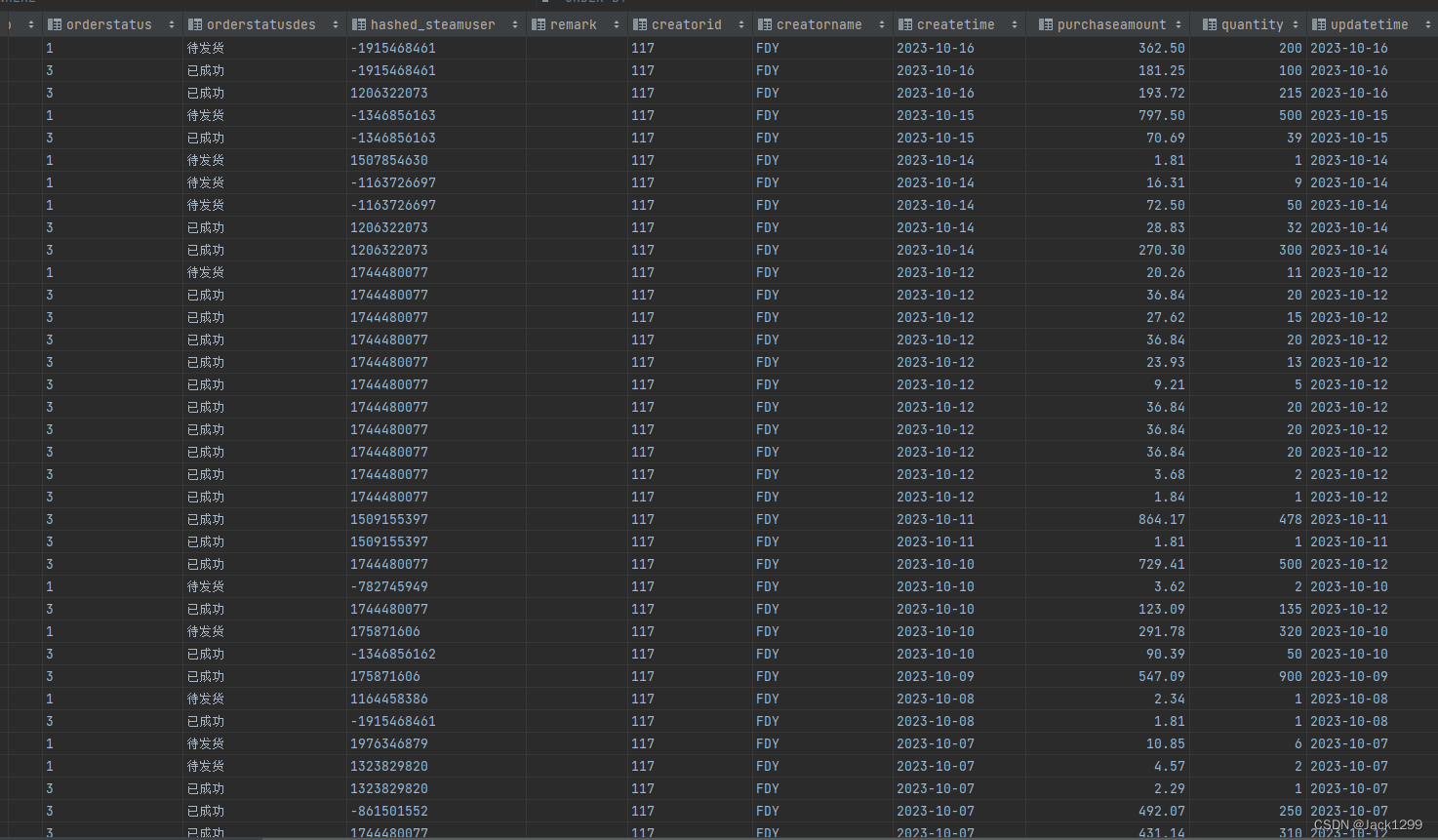
dws层
根据指标体系建模,数据主要来源dwd,对dwd层数据汇总
dws_order_items_purchase_amount_nd
– 统计每天每周每月每年各饰品购买数量和购买金额
drop table if exists dws_order_items_purchase_amount_nd;
create external table dws_order_items_purchase_amount_nd
(
defindex string comment 'code of items',
itemname string comment '',
order_amount string comment 'num of orders',
quantity_amount string comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment',
updatetime date,
year_num string,
month_num string,
day_of_month string,
day_of_year string,
week_of_year string,
is_weekday string
) row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/dws_order_items_purchase_amount_nd';
– 数据装载
with items as
(select defindex,
itemname,
count(1) as order_amount,
sum(quantity) quantity_amount,
sum(exchangedbillingtotal) pay_amount,
updatetime
from dwd_order_purchase_items_full
group by defindex, itemname, updatetime)
insert into dws_order_items_purchase_amount_nd
select
defindex,
itemname,
order_amount,
quantity_amount,
pay_amount,
updatetime,
year,
month_num,
dom day_of_month,
doy day_of_year,
woy week_of_year,
is_weekday
from items
left join dim_date d
on updatetime = d.`date`;
部分数据展示·
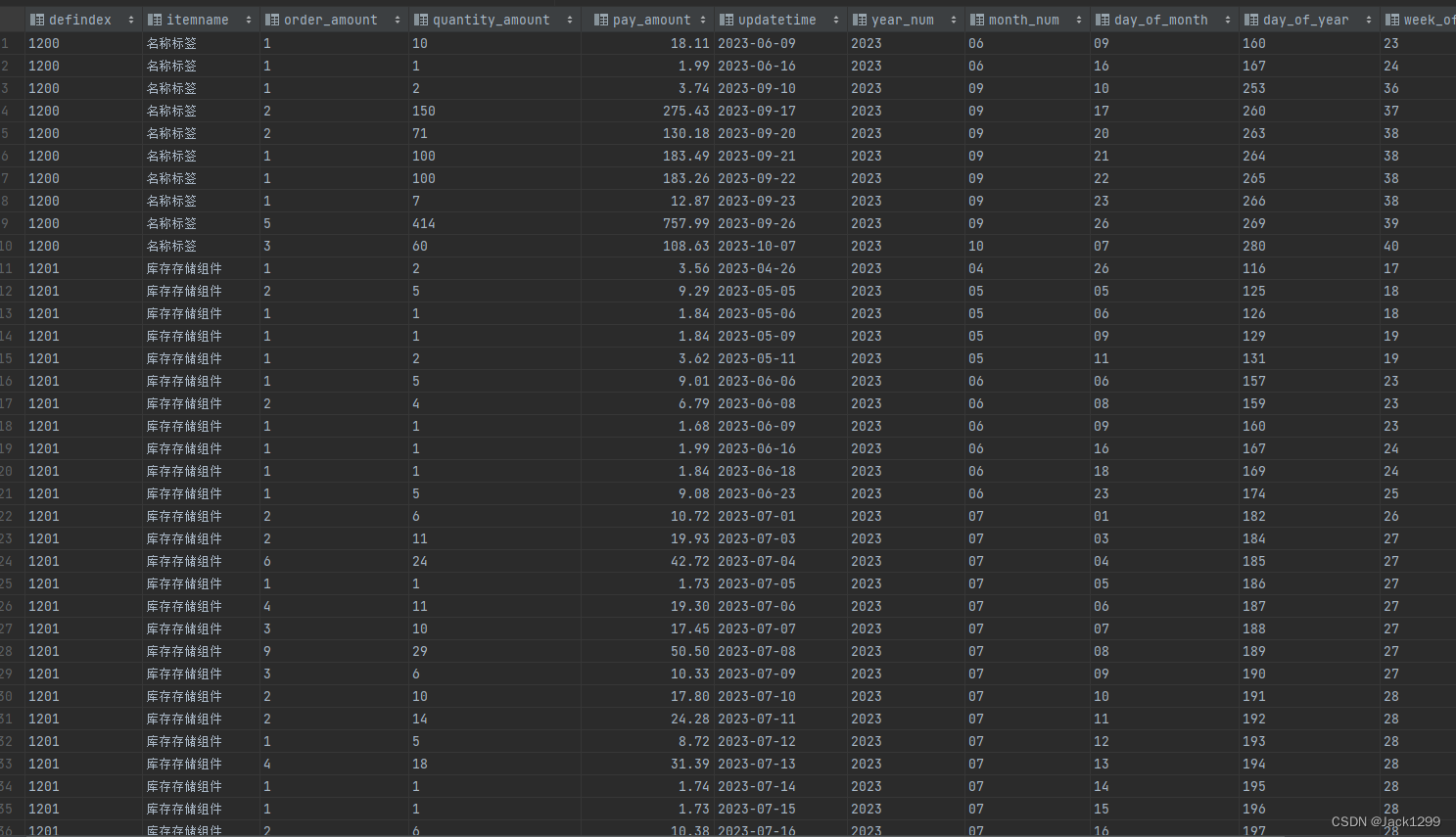
dws_order_user_order_summary_nd
– 统计每个用户在每天的下单情况
drop table if exists dws_order_user_order_summary_nd;
create external table dws_order_user_order_summary_nd
(
hashed_username string,
order_amount string comment 'num of orders',
quantity_amount string comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment',
updatetime date,
year_num string,
month_num string,
day_of_month string,
day_of_year string,
week_of_year string,
is_weekday string
) row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/dws_order_user_order_summary_nd';
– 数据装载
with user_info as
(select hashed_steamuser,
count(1) as order_amount,
sum(quantity) quantity_amount,
sum(purchaseamount) pay_amount,
updatetime
from dwd_order_user_info_full
group by hashed_steamuser, updatetime)
insert into dws_order_user_order_summary_nd
select
hashed_steamuser,
order_amount,
quantity_amount,
pay_amount,
updatetime,
year,
month_num,
dom day_of_month,
doy day_of_year,
woy week_of_year,
is_weekday
from user_info
left join dim_date d
on updatetime = d.`date`;
部分数据展示
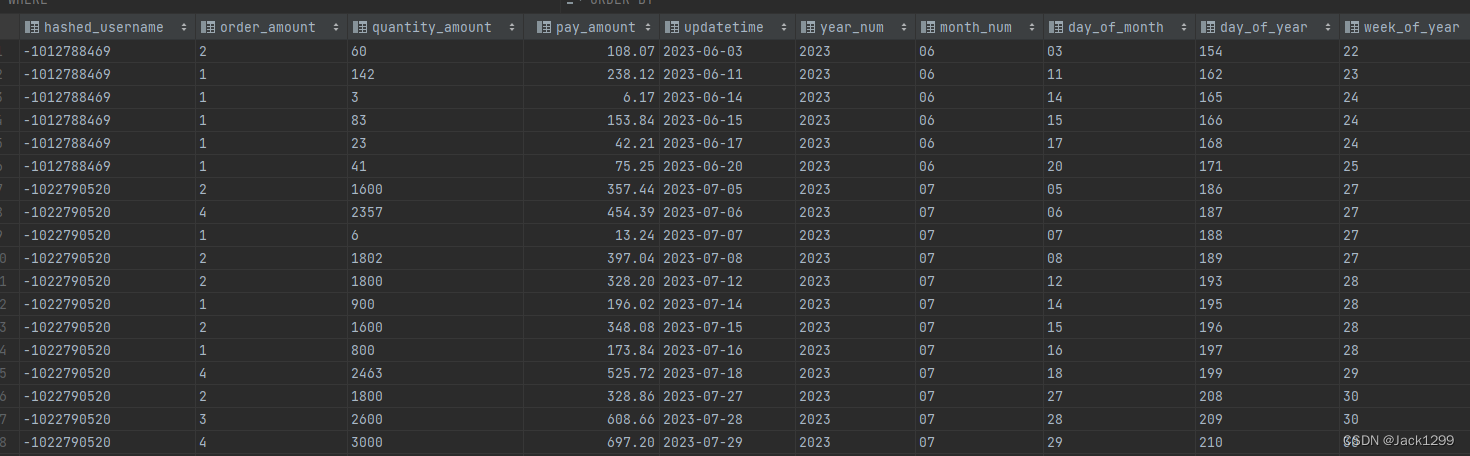
ads层
数据服务层
– 根据具体指标生成对应的表,数据来源dws
ads_order_items_info_per_day
– 各个饰品每日的购买情况
drop table if exists ads_order_items_info_per_day;
create external table ads_order_items_info_per_day(
defindex string,
itemname string,
order_amount int,
quantity_amount int,
pay_amount string,
updatetime string
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_items_info_per_day';
– 数据装载
insert into ads_order_items_info_per_day
select defindex,
itemname,
order_amount,
quantity_amount,
pay_amount,
updatetime
from dws_order_items_purchase_amount_nd info;
ads_order_items_info_per_week
– 各个饰品每周的购买情况
drop table if exists ads_order_items_info_per_week;
create external table ads_order_items_info_per_week(
defindex string,
itemname string,
order_amount int,
quantity_amount int,
pay_amount string,
week_of_year string,
year string
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_items_info_per_week';
– 数据装载
insert into ads_order_items_info_per_week
select defindex,
itemname,
sum(order_amount),
sum(quantity_amount),
sum(pay_amount),
week_of_year,
year_num
from dws_order_items_purchase_amount_nd info
group by defindex,itemname,week_of_year,year_num;
ads_order_items_info_per_month
– 各个饰品每月的购买情况,数据样式及其类似dws_order_item_…nd
drop table if exists ads_order_items_info_per_month;
create external table ads_order_items_info_per_month(
defindex string,
itemname string,
order_amount int,
quantity_amount int,
pay_amount decimal(16,2),
month_of_year string,
year string
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_items_info_per_month';
ads_order_items_info_td
– 统计迄今为止各饰品购买数量和购买金额
drop table if exists ads_order_items_info_td;
create external table ads_order_items_info_td
(
defindex string comment 'code of items',
itemname string comment '',
order_amount int comment 'num of orders',
quantity_amount int comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment'
) row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_items_info_td';
– 数据装载
insert into ads_order_items_info_td
select defindex,
itemname,
sum(order_amount),
sum(quantity_amount),
sum(pay_amount)
from dws_order_items_purchase_amount_nd
group by defindex,itemname;
部分数据展示
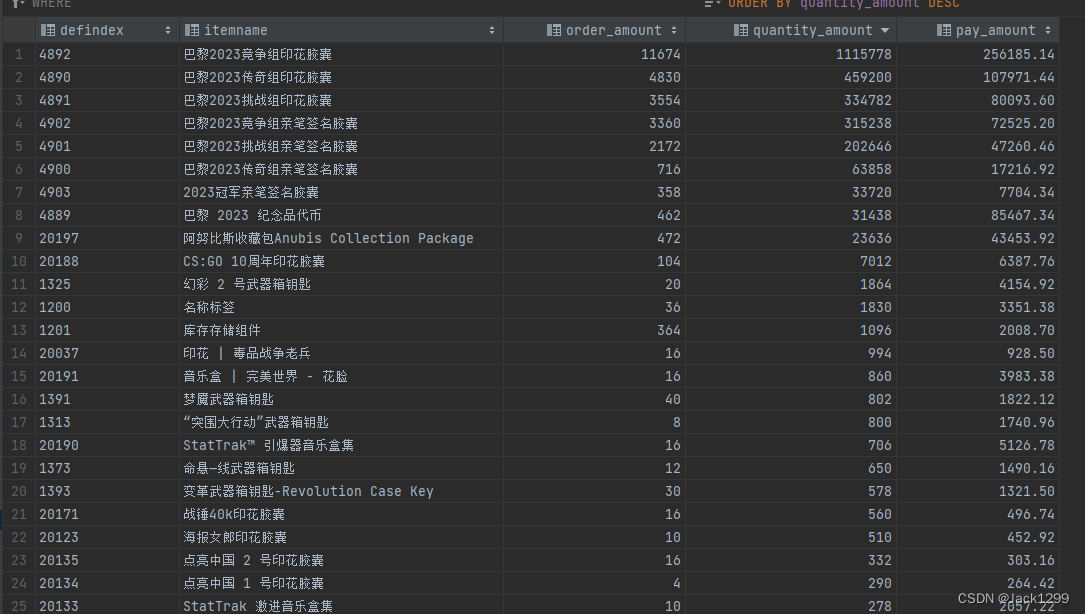
ads_order_user_info_summary_per_week
– 各个用户每周的购买情况
drop table if exists ads_order_user_info_summary_per_week;
create external table ads_order_user_info_summary_per_week(
hashed_username string,
order_amount int comment 'num of orders',
quantity_amount int comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment',
week_of_year string,
year_num string
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_user_info_summary_per_week';
– 数据装载.
insert into ads_order_user_info_summary_per_week
select
hashed_username,
sum(order_amount),
sum(quantity_amount),
sum(pay_amount),
week_of_year,
year_num
from dws_order_user_order_summary_nd
group by hashed_username,week_of_year,year_num;
ads_order_user_info_summary_per_month
– 各个用户每月的购买情况
drop table if exists ads_order_user_info_summary_per_month;
create external table ads_order_user_info_summary_per_month(
hashed_username string,
order_amount int comment 'num of orders',
quantity_amount int comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment',
month_num string,
year_num string
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_user_info_summary_per_month';
– 数据装载
insert into ads_order_user_info_summary_per_month
select
hashed_username,
sum(order_amount),
sum(quantity_amount),
sum(pay_amount),
month_num,
year_num
from dws_order_user_order_summary_nd
group by hashed_username,month_num,year_num;
ads_order_user_info_summary_td
– 迄今为止各个用户的购买情况
drop table if exists ads_order_user_info_summary_td;
create external table ads_order_user_info_summary_td(
hashed_username string,
order_amount int comment 'num of orders',
quantity_amount int comment 'num of quantity',
pay_amount decimal(16, 2) comment 'num of payment'
)row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/yousheng/ads_order_user_info_summary_td';
– 数据装载
insert into ads_order_user_info_summary_td
select
hashed_username,
sum(order_amount),
sum(quantity_amount),
sum(pay_amount)
from dws_order_user_order_summary_nd
group by hashed_username;
部分数据展示
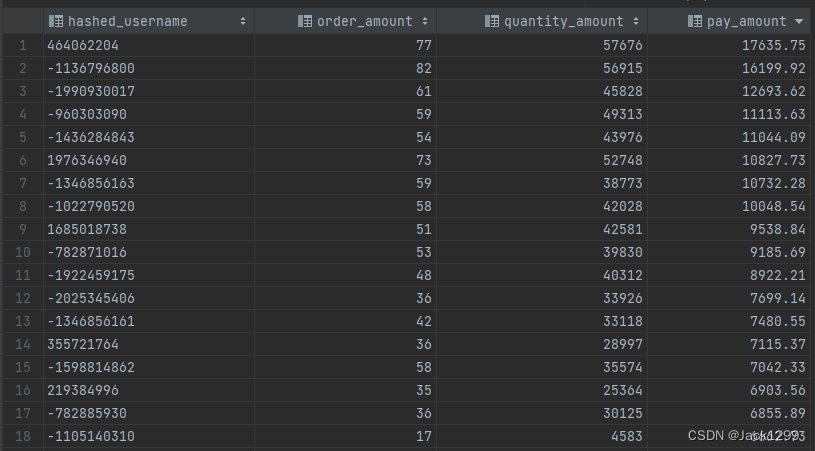
项目过程中遇到的难题:
因为节点环境不一致导致python脚本无法正常执行
在给 dwd_order_purchase_items_full进行数据装载时,hive报错

报错信息不全,先通过yarn application UI http://192.168.145.101:8088/cluster 页面找到applicationId
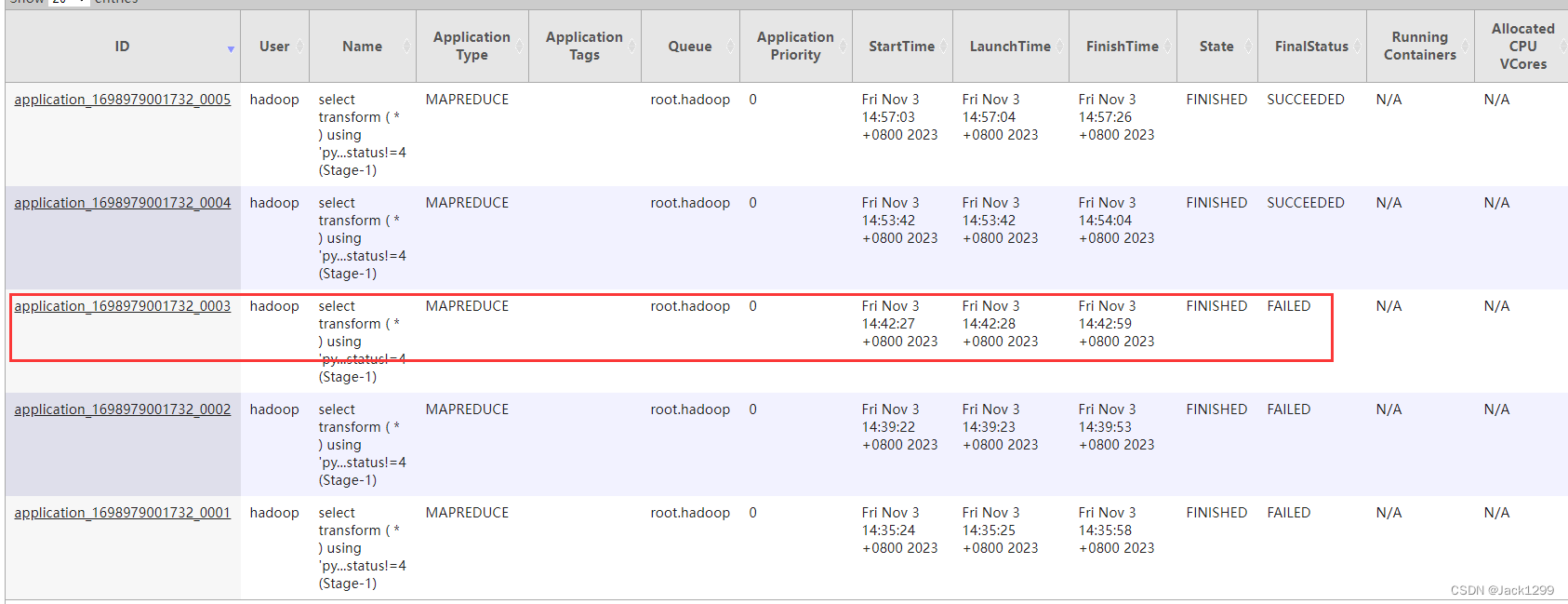
在虚拟机上查看:yarn logs -applicationId
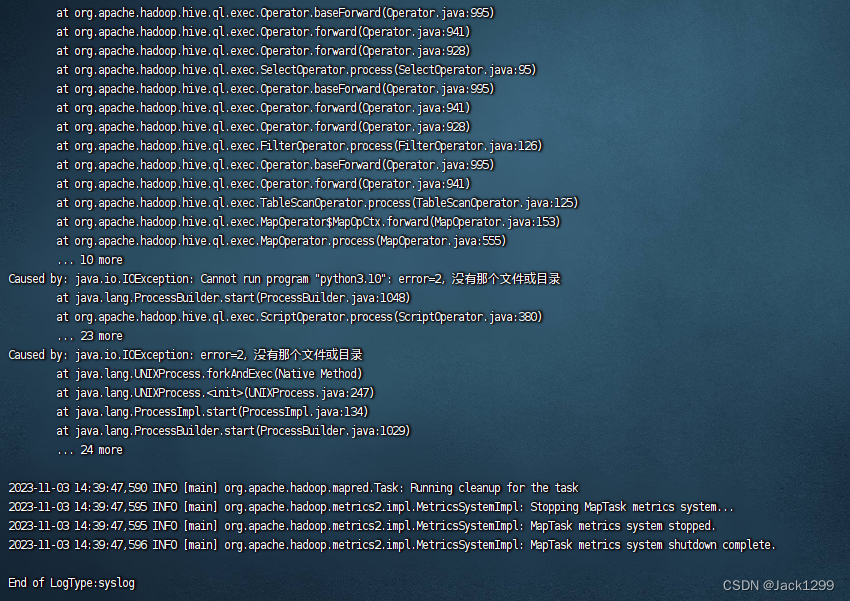
推测是因为只在主节点是安装python3,忘了在其他节点上安装python3.10
在统一各节点的python环境后,问题解决
对此次错误的总结:
hive中报错信息有限,通过yarn的logs系统查看相信报错信息
以后节点变更环境要考虑整个集群是否需要更新
(尚未解决)复杂数据类型嵌套后不能转换
在dwd_order_user_info_full进行数据装载时遇到数据转换问题
考虑到未来指标可能需要购买详细信息,为了避免表结构的修改,提前使用array嵌套struct存储购买详情
先将ods_yousheng_order_detail order_detail表每一行数据封装成一个struct结构体,然后通过orderno聚合并且将一个orderon下的所有记录封装成一个array,实现代码如下
with detail as
(select
orderno,
collect_set(named_struct('defindex',defindex,'name',itemname,'quantity',quantity,'payamount',billingtotalstr)) details_arry
from ods_yousheng_order_detail order_detail
group by orderno)
但是最终通过orderno和ods_yousheng_order_list表关联后的数据并不能正常导入表中
报错信息如下
Cannot convert column 7 from array<structdefindex:int,name:string,quantity:int,payamount:string> to array<structdefinex:int,name:string,quantity:int,payamount:string>.
目前网上找到最类似的问题链接如下
https://stackoverflow.com/questions/44607351/how-to-cast-complex-datatype-in-hive?r=SearchResults
但是并没有解决问题
项目的总结和反思
项目的局限性:
此项目涉及的业务数据较少,结构也简单,所以更多的是数仓建模基础知识的实现,
像全量表增量表拉链表的实现,数据每日同步和装载实现步骤都不涉及,因为没有复杂的数据处理需求,sql也较为简单,不涉及开窗函数和爆炸函数等,大数据的其他组件例如kafaka,flume,dophine scheduler也不涉及
目前数据量小,且订单信息只涉及增加和修改,而且修改内容较少,后续最好使用增量表或者拉链表同步数据,并且采取一定的压缩方法
指标体系的构建不够完善,导致dws层和ads层表较多,此项待优化,并且因为自己对项目背后的业务的熟悉程度不高,很多指标的实现可能存在误解
自己的局限性
因为使用python实现的udf,必须使用transform函数,导致代码看起来臃肿,稳定性也并不高,并且脚本复用率低,导致针对不同的需求需要调整代码和新增脚本,后续应该继续学习,可以采用java实现udf,或者sparksql实现
而且自己现阶段对hive自带的函数了解并不多,很多功能其实都已经内嵌了,或者通过调用多个自带的函数就能实现功能,比如hive自带hash加密函数
项目的积极意义:
检验了自己对数仓的理解
从分析指标出发,分解指标并统计各个派生指标之间共有的统计周期,统计粒度,从而在dws层,可以实现一个dws表对应多个ads表,提升数据复用率,并且设计dws表时考虑到表结构将来的变化,刻意根据dwd层数据在dws层表中引入了一些现在用不到数据
认识到了自己的局限性,也了解到了数仓学习的未来方向,首先应该继续学习sql,巩固基础知识的前提下学习sql的进阶语法例如开窗函数,学习用sql实现较复杂的数据处理场景;其次继续加深对数仓建设的理解,我目前的想法是要多看多想,看别人怎么建设数仓,再结合别人的数仓经验总结出自己的思考
对数仓开发的底层知识点进行检验
建模过程并不是一帆风顺,尤其遇到报错,hive中报错信息并不全,通过对yarn的日志查看,提示了自己对hadoop生态下日志系统的熟悉,当然,看了日志信息也不一定就代表知道哪错了,怎么改,在知错到改错的过程中锻炼了信息检索和分析能力,也累计了数仓中一些常见的错误经验
加深了对元数据的认知,理解了外部表内部表的区别和存在的意义
此项目让我知道了其他大数据组件的作用,后续也应该多思考这些组件的意义并且学习怎么用
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









