 Java实现文本余弦相似度计算工具类
Java实现文本余弦相似度计算工具类




 本文介绍了一个使用Java和jieba库计算文本间余弦相似度的工具类,通过Jieba分词并构建词汇表,计算两个文本向量的相似度,提供了一个简单的测试示例。
本文介绍了一个使用Java和jieba库计算文本间余弦相似度的工具类,通过Jieba分词并构建词汇表,计算两个文本向量的相似度,提供了一个简单的测试示例。
package com.easybbs.utils;
import com.huaban.analysis.jieba.JiebaSegmenter;
import com.huaban.analysis.jieba.SegToken;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class CosineSimilarityUtils {
private static JiebaSegmenter segmenter = new JiebaSegmenter();
public static double calculateCosineSimilarity(String text1, String text2) {
List<String> words1 = tokenize(text1);
List<String> words2 = tokenize(text2);
Set<String> vocabulary = buildVocabulary(words1, words2);
double[] vector1 = calculateVector(words1, vocabulary);
double[] vector2 = calculateVector(words2, vocabulary);
return calculateCosineSimilarity(vector1, vector2);
}
private static List<String> tokenize(String text) {
List<String> tokens = new ArrayList<>();
List<SegToken> segTokens = segmenter.process(text, JiebaSegmenter.SegMode.INDEX);
for (SegToken segToken : segTokens) {
tokens.add(segToken.word);
}
return tokens;
}
private static Set<String> buildVocabulary(List<String>... wordLists) {
Set<String> vocabulary = new HashSet<>();
for (List<String> wordList : wordLists) {
vocabulary.addAll(wordList);
}
return vocabulary;
}
private static double[] calculateVector(List<String> words, Set<String> vocabulary) {
int vocabSize = vocabulary.size();
double[] vector = new double[vocabSize];
for (String word : words) {
if (vocabulary.contains(word)) {
int index = getIndex(word, vocabulary);
vector[index]++;
}
}
return vector;
}
private static double calculateCosineSimilarity(double[] vector1, double[] vector2) {
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
norm1 += Math.pow(vector1[i], 2);
norm2 += Math.pow(vector2[i], 2);
}
double similarity = dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
return similarity;
}
private static int getIndex(String word, Set<String> vocabulary) {
List<String> vocabList = new ArrayList<>(vocabulary);
return vocabList.indexOf(word);
}
}
上面是计算文本的余弦相似度的工具类
需要先在pom.xml文件中引入以下依赖
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
下面是使用的简单例子
package com.easybbs.test;
import com.easybbs.utils.CosineSimilarityUtils;
public class CSTest {
public static void main(String[] args) {
String text1 = "我喜欢吃梨子";
String text2 = "我喜欢吃苹果";
double similarity = CosineSimilarityUtils.calculateCosineSimilarity(text1, text2);
System.out.println("Cosine Similarity: " + similarity);
}
}
运行结果如下:
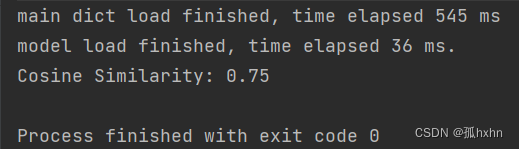

















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









