






零宽字符
简要描述
零宽字符(Zero-Width Characters)是一组在文本中不占用显示空间的特殊字符。以下是一些常见的零宽字符及其简要描述:
零宽度空格(Zero Width Space):
Unicode码:U+200B
常见于文本处理、格式化和布局中,用于插入间隔或边界,而不影响可见布局。
零宽度非断空格(Zero Width No-Break Space):
Unicode码:U+FEFF
这是一个特殊的空格字符,用于阻止特定位置的换行分隔。
零宽度连字符(Zero-Width Joiner):
Unicode码:U+200D
用于阿拉伯语、印度语系等文字中,使不会发生连字的字符间产生连字效果。
零宽度断字符(Zero-Width Non-Joiner):
Unicode码:U+200C
用于阻止会发生连字的字符间的连字效果。
左至右标记(Left-to-Right Mark):
Unicode码:U+200E
用于在混合文字方向的多种语言文本中(如混合左至右书写的英语与右至左书写的阿拉伯语)指示文本从左到右显示。
右至左标记(Right-to-Left Mark):
Unicode码:U+200F
与左至右标记相反,它指示文本从右到左显示。
这些只是零宽字符中的一部分
表达形式
<0x200b> 是 8203 零宽字符的十六进制表示,也就是说这个表示方法和直接使用 U+200B 是等价的。在一些字符处理软件或编程语言中,可能会使用这种十六进制表示方法来操作或表示这个字符。例如,在 Python 中,可以使用 "\u200b" 或 "\u200B" 来表示 8203 零宽字符。
列如:
码点:U+200B
Python:\u200b或\u200B
十六进制表示:<0x200b>
十进制:8203
解码原理

使用读取python读取零宽节字符时,python会自动将字符转变为unicode编码
而在此编码中使用的零宽节字符unicode编码有:
\u200b,\u200c,\u200d
经过观察可以得知是使用了摩尔斯电码
对应:<0x200b>,<0x200c>,<0x200d>
替换:<0x200b>替换”空格”
<0x200c>替换”.”
<0x200d>替换“-”
经摩斯密码解密后为?u6211
此编码格式为unicode编码的十进制形式6211
解码后得到明文:我
解码程序
import re
def replace_unicode_chars(text):
# 定义要替换的Unicode字符及其替换字符
replacements = {
'\u200b': ' ', # ZERO WIDTH SPACE
'\u200c': '.', # ZERO WIDTH NON-JOINER
'\u200d': '-' # ZERO WIDTH JOINER
}
# 使用translate方法替换Unicode字符
trans_table = str.maketrans(replacements)
return text.translate(trans_table)
# 示例使用(这里我们假设text_with_unicode包含实际的Unicode字符)
with open('put.txt','r',encoding='utf-8') as file:
string=file.read()
text_with_unicode = string
replaced_text = replace_unicode_chars(text_with_unicode)
print(replaced_text)
MORSE_CODE_DICT = {
'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E',
'..-.': 'F', '--.': 'G', '....': 'H', '..': 'I', '.---': 'J',
'-.-': 'K', '.-..': 'L', '--': 'M', '-.': 'N', '---': 'O',
'.--.': 'P', '--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T',
'..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X', '-.--': 'Y',
'--..': 'Z',
'.----': '1', '..---': '2', '...--': '3', '....-': '4',
'.....': '5', '-....': '6', '--...': '7', '---..': '8', '----.': '9',
'-----': '0',
'.-': 'a', '-...': 'b', '-.-.': 'c', '-..': 'd', '.': 'e',
'..-.': 'f', '--.': 'g', '....': 'h', '..': 'i', '.---': 'j',
'-.-': 'k', '.-..': 'l', '--': 'm', '-.': 'n', '---': 'o',
'.--.': 'p', '--.-': 'q', '.-.': 'r', '...': 's', '-': 't',
'..-': 'u', '...-': 'v', '.--': 'w', '-..-': 'x', '-.--': 'y',
'--..': 'z',
'.--.-': '?' # 摩尔斯电码中的问号
}
def decode_morse(morse_code):
words = morse_code.split() # 假设单词之间用空格分隔
decoded_words = []
for word in words:
# 假设字符之间也是用空格分隔的
chars = word.split()
# 过滤掉空字符串和不在字典中的字符
decoded_chars = [MORSE_CODE_DICT[char] for char in chars if char and char in MORSE_CODE_DICT]
# 如果decoded_chars不为空,则将其加入decoded_words列表
if decoded_chars:
decoded_words.append(''.join(decoded_chars))
return ''.join(decoded_words)
def unicode1(s):
# 使用正则表达式查找所有形如?uXXXX的字符串
matches = re.findall(r'\?u([0-9a-fA-F]{4})', s)
finsh=''
for hex_code in matches:
# 将十六进制数字转换为整数(Unicode码点)
unicode_code_point = int(hex_code, 16)
# 使用chr()函数将整数(Unicode码点)转换为对应的Unicode字符
a = chr(unicode_code_point)
finsh=finsh+a
print(finsh) # 输出对应的Unicode字符
morse_message = replaced_text
decoded_message = decode_morse(morse_message)
print(decoded_message)
unicode1(decoded_message)put.txt
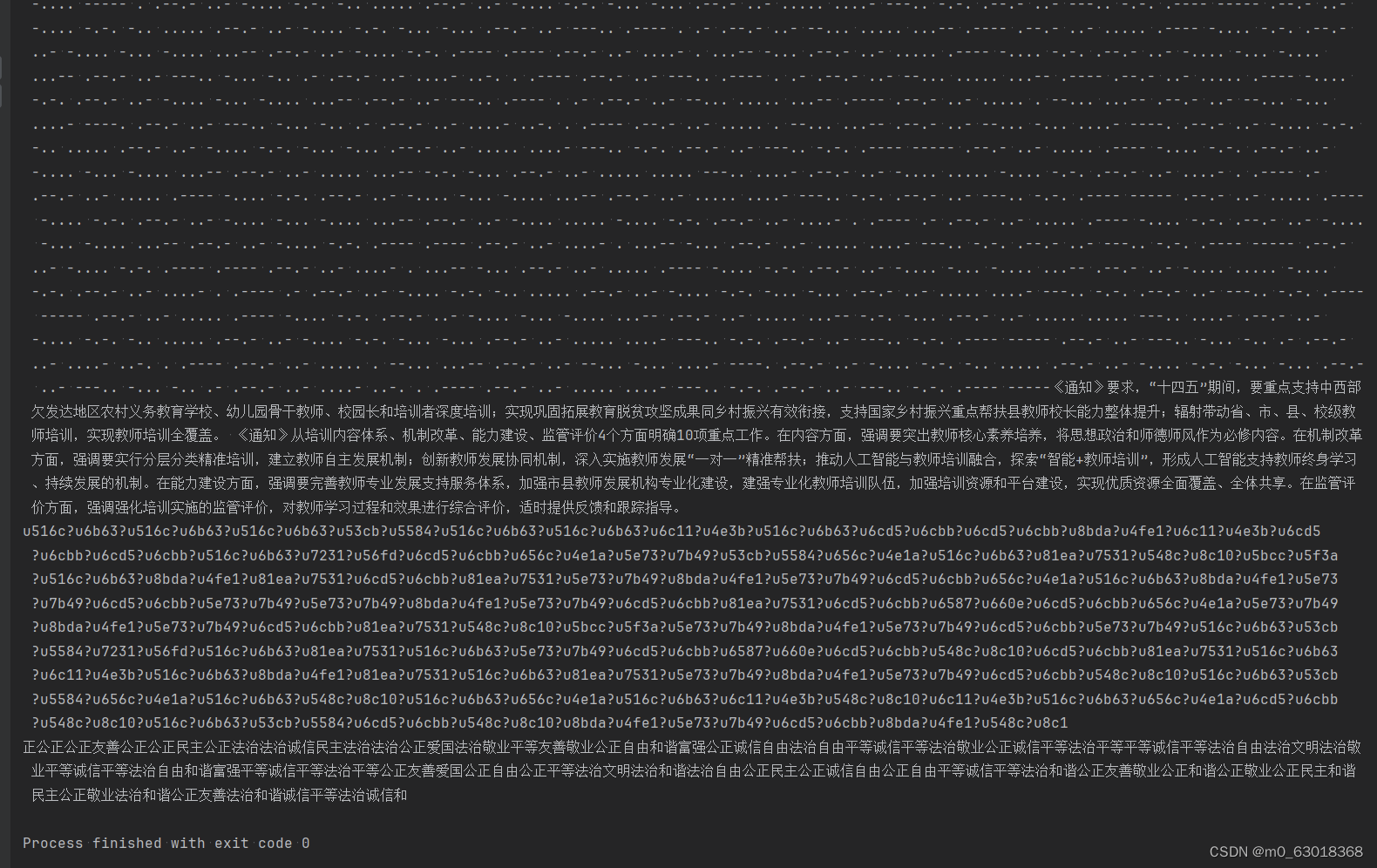
开头结尾分别少了一个 公 字和 谐 字

社会主义核心价值观解码得到flag,


















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









