






前言:目前,利用爬虫爬取信息变得越来越常见,为满足大家学术需求或者是兴趣探索地需求,写这一篇文章来帮助大家解决实际问题
目录
3.1 分析网页结构(打开目标网页,点击F12,打开开发工具)
一.需求分析
根据学习需求我们在猪八戒网上需要爬取什么信息,并将爬取到的信息保存到navicat数据库中,这篇文章以爬取商家名称,综合评分,服务内容以及价格等信息为例
二.环境搭建
首先根据已学的知识导入pymysql,lxml,如果导入报错,那么使用pip install的命令进行下载即可
import requests
from lxml import etree
import pymysql
其次需要navicat16.0版本,MySQL,为方便建数据库和数据表做存储信息使用
创建数据库sql命令(根据自己需求进行删改)
create database if not exists shop default charset utf8 collate utf8_general_ci ;创建数据表sql命令(根据自己需求进行删改)
1.mysql> CREATE TABLE 数据表
2. -> (
3. -> id INT (12) PRIMARY key not null,
4. -> shop VARCHAR (12) not null,
5. -> servename VARCHAR (50) not null,
6. -> );
三.项目实现
3.1 分析网页结构(打开目标网页,点击F12,打开开发工具)
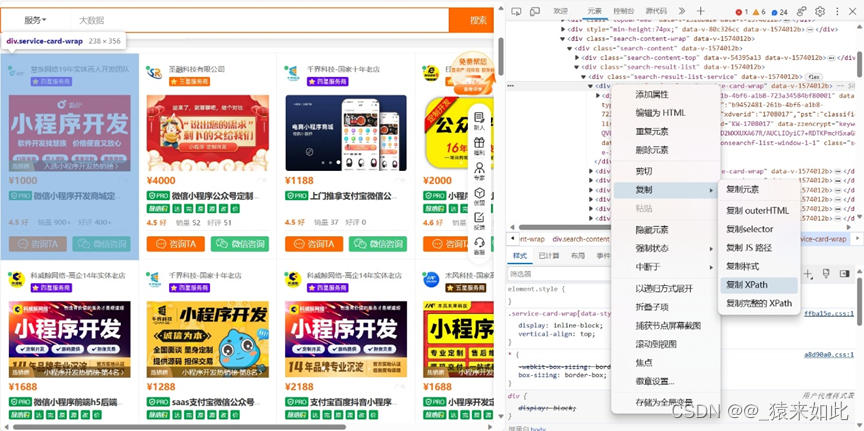
在网页源代码中可以看出每个商家的信息都是并列的关系而且结构是一样的,用普通的爬取方法是行不通的,选中一个商家,包含该商家的全部信息,然后复制xpath的地址,层级减一就可以获取到整个页面所有商家的div。
divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[4]/div/div[2]/div[1]/div')# 定位到第一家商铺
依次类推,选中名称层次减一就可以获取所有商家的商铺名。注意获取元素值要在地址后面加上 /text(),循序递进,因为上面获取到每个服务商的div就可以用相对路径表示它们的子元素。
name = (div.xpath("./div/a/div[2]/div[1]/div/text()"))#子路径依次类推把其他的xpath路径找出来,如;
shop = (div.xpath("./div/a/div[2]/div[1]/div/text()"))#子路径
score= div.xpath("./div/div[3]/div[4]/div[1]/span[1]/span/text()")
servename = div.xpath("./div/div[3]/div[2]/a/text()")
price = div.xpath("./div/div[3]/div[1]/span/text()")
3.2 发送GET请求,解析url
要想爬取多个页面信息,使用列表+循环的方法
# 页面 URL 列表
list = ["https://www.zbj.com/fw/?k=%E7%BD%91%E7%AB%99%E5%BC%80%E5%8F%91",
"https://www.zbj.com/fw/?k=%E7%BD%91%E7%AB%99%E5%BC%80%E5%8F%91&p=2&osStr=ad-21,np-1,rf-0,sr-41,mb-0",
"https://www.zbj.com/fw/?k=%E7%BD%91%E7%AB%99%E5%BC%80%E5%8F%91&p=3&osStr=ad-21,np-1,rf-0,sr-101,mb-0",
"https://www.zbj.com/fw/?k=%E7%BD%91%E7%AB%99%E5%BC%80%E5%8F%91&p=4&osStr=ad-21,np-1,rf-0,sr-161,mb-0",
"https://www.zbj.com/fw/?k=%E7%BD%91%E7%AB%99%E5%BC%80%E5%8F%91&p=5&osStr=ad-21,np-1,rf-0,sr-221,mb-0"]
# 遍历 URL 列表,爬取并解析页面数据
for url in list:
resp = requests.get(url) # 发送GET请求
html = etree.HTML(resp.text) #HTML()作用为加载html源码3.3 连接数据库
注意前面建立的数据库和数据表要和这个地方一致
配置数据库
conn = pymysql.Connect(host='localhost', port=XXXX, user='root', password='XXXXXX', database='XXXX') # 创建连接
cursor = conn.cursor()
for i in range(len(servename)): # 循环次数由evaluate决定
sql = f"insert into data(shop,score,servename,price) values(%s,%s,%s,%s);"
cursor.execute(sql, (shop[i],score[i],servename[i],price[i].strip('¥')))#每个字段
conn.commit()
cursor.close()
conn.close()
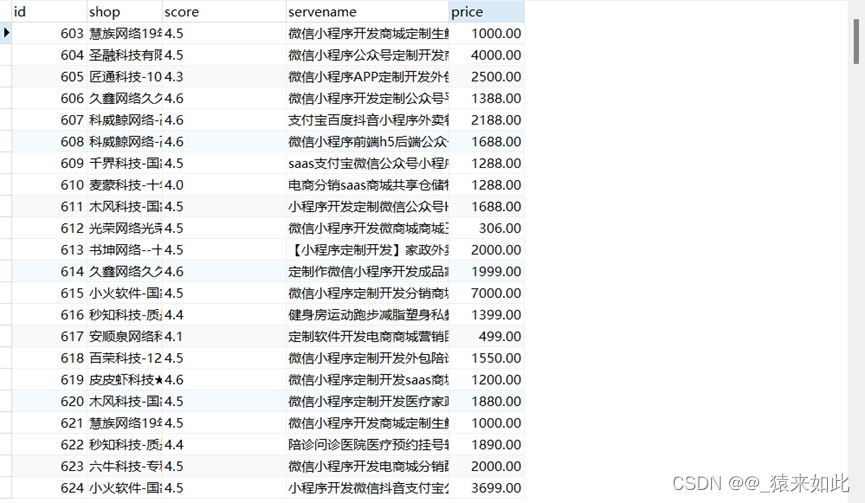
四. 运行截图
结尾:看到这里你是否受益了呢?你的支持就是我创作的动力,点赞+收藏+关注,学习不迷路,评论区留下你的疑问,可私信。


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









