






目录
第二章
1、Spark支持的语言:
scala,java,python,R
2、各个语言的特点
1) scala,由Java开发,基于JVM运行,计算速度快(比Python快近10倍),可无缝调用Java API,完美兼容Hadoop生态组件(由Java开发)。类型系统较复杂,语法简洁,支持函数式编程(FP)
2)Java,性能和兼容性与Scala一致,强类型语言,语法规(si)范(ban) ,对FP支持不太好。
3)Python,弱类型语言,语法简洁,支持FP;解释型语言,运行速度慢;对Hadoop的兼容性差(大多数Spark分布式生产环境都基于Hadoop YARN搭建),难以应用在生产环境。
3、函数式编程
是一种使用函数编程的编程范式
建立在函数的Lambda演算(Lambda Calculus)的基础之上
4、Lambda演算
函数可视为一种数据类型
函数的参数和返回值均可为函数类型,即函数能以参数形式传入另一个函数,也能以返回值形式作为另一个函数的运算结果。
5、Java与Scala
java:
1)语法规范、复杂
2)强类型语言,编程时须随时考虑类型转换问题(类型安全问题突出)
3)对函数式编程(特别是Lambda语句)支持不太好 非常垃圾,基本写了就会各种报错
4)重在复杂系统和业务系统构建
scala:
1)语法简洁
2)支持类型推断
3)支持函数式编程
4)重在数据计算程序构建
6、Python/R与Scala
python主要用作数据分析,语法简洁,有众多的算法库,便于快速搭建算法;用于算法研究;大量的科研人员和算法设计师使用。
scala重在大,速度快,语法简洁,能完美融入大数据生态圈,用于大数据生产环境,大量的大数据工程师使用。
R也是用作数据分析,但是Python更流行。
7、Scala运行、开发环境
JDK,必须先安装,运行在JDK上
Scala,支持Windows、Mac OS、Unix、Linux
开发环境可以用idea,Eclipse
8、编程方式
交互式编程:
类似Python命令的执行
静态编程
编写源代码为.scala文件
编译成java字节码文件,.class
9、Scala和Spark的编程架构
动态类声明:class
静态类声明:object
动态类可有多个实例/对象
通过反复调用实例化语句创建多个实例/对象
由于有多个实例/对象,故须赋值到不同的实例名中区分
静态类只有一个实例/对象
首次使用静态类时自动创建实例/对象
由于只有一个实例/对象,故调用时用类名即可
第二章(2)
1、变量/常量
var,val
2、循环语句
遍历数值范围(x to y,包含y)
var i = 0
var array =(1 to 10)
for(i <-array){ //1 to 10为1~10的数组
println("loop " + i) //循环体
}
遍历数值范围(x until y,不包含y)
var i = 0
for(i <- 1 until 10){ //1 until 10为1~9的数组
println("loop " + i) //循环体
}
遍历整个序列
val numList = List(1,2,3,4,5,6)
var i = 0
for(i <- numList){
println("loop " + i) //循环体
}
3、breakable
// 2、采用Scala自带的函数,退出循环
Breaks.breakable(
for (e <- 1 to 5) {
println(e)
if (e > 4) {
Breaks.break()
}
}
)
// 3、对break进行省略
breakable {
for (e <- 1 to 10) {
if (e > 9) {
break
}
}
}
————————————————
版权声明:本文为CSDN博主「ha_lydms」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lydms/article/details/1332199004、数组
var z:Array[String] = new Array[String](3)
5、函数和方法
方法是对象的一部分
函数是一个完整的对象,可作为参数(函数类型参数)传值给任何其他的函数或方法——函数式编程的基本规则
使用类中的def 语句定义方法
使用=>运算符(lambda运算符)定义函数
6、函数声明

7、函数调用

8、高阶函数
函数的参数或返回值类型为函数对象类型

9、柯里化


10、闭包


11、Lambda表达式
(参数表) => {
函数体
返回值
}
12、常用容器方法
与spark core很相似







与sortBy算子有区别,算子用一个boolean值区分顺序




第三章
1、Spark主从架构
主节点:master
从节点:worker,管理Executor和Driver
2、Spark运行架构


补充:在spark-shell中,分别记为sc和spark
Executor运行在Worker上,Driver的位置根据作业提交模式决定。
3、提交模式
本地模式(Local):worker和master在本地进程
standalone:需要配置集群并启动守护进程
yarn:单机安装
local:单线程模式,只有一个Worker线程
local[n]: 多线程模式,使用n个Worker线程
local[*]: 多线程模式,Worker线程数=CPU核数
1)standalone-client: Driver运行在Client
standalone-cluster: Driver运行在Worker守护进程

2)yarn-client: Driver运行在Client
yarn-cluster: Driver运行在NodeManager(AM)

4、Spark环境搭建

5、执行Spark程序



6、RDD


7、RDD调度执行过程

8、RDD的输入、输出、常用算子
输入:
1)val rdd01 = sc.parallelize(List(1,2,3,4,5,6), 2)
2)val rdd03 = sc.makeRDD(List(1,2,3,4,5,6))
3)val rdd01 = sc.textFile("file://root/tempFiles")
val rdd02 = sc.textFile("/root/tempFiles/1.txt")
val rdd03 = sc.textFile("hdfs://node1:9000/tmps")
输出:
rdd.saveAsTextFile("/root/wcresult")
rdd.saveAsTextFile("hdfs://node1:9000/wcresult")
9、规约算法:平均数

10、RDD缓存


11、序列化

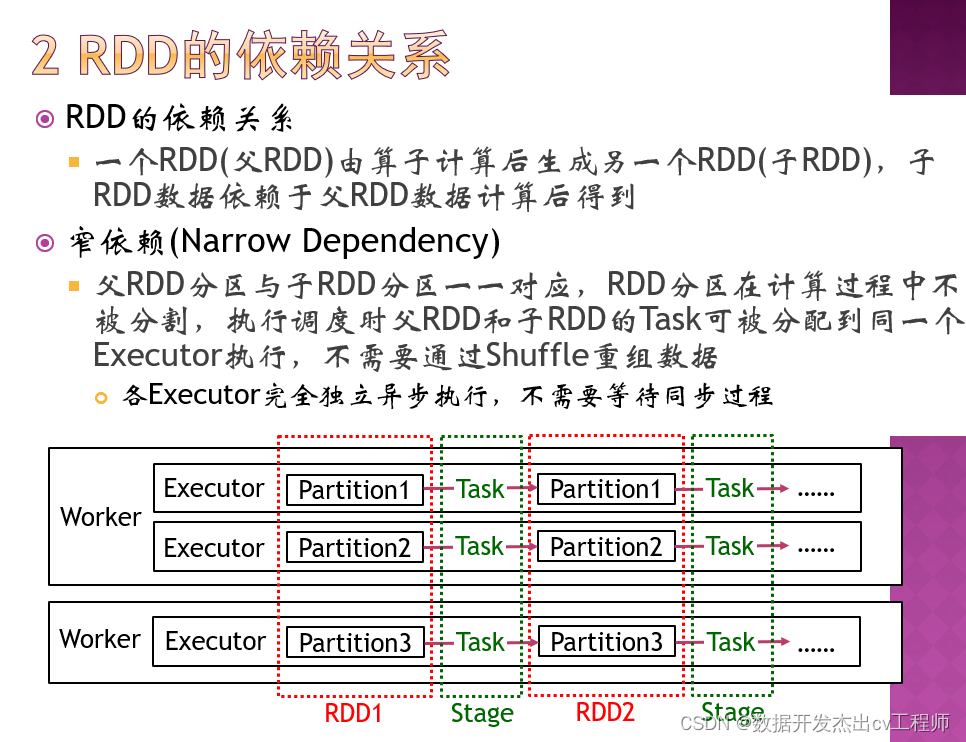
12、RDD的依赖关系


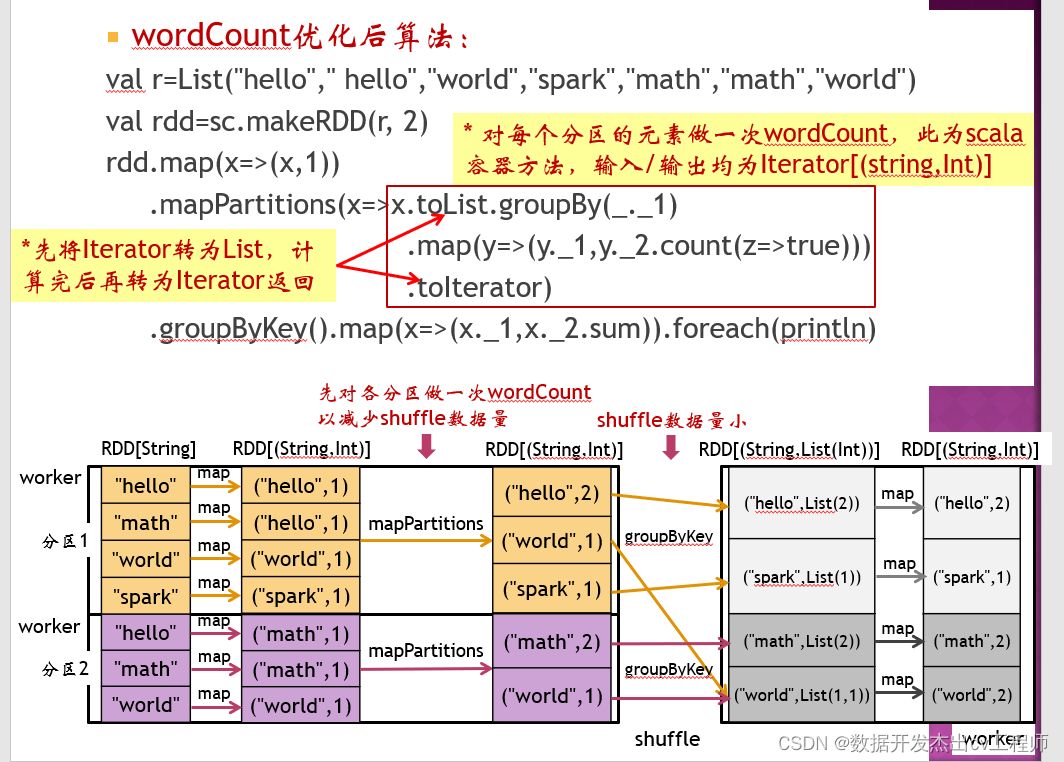
13、分区映射类算子,wordCount优化后算法



14、重分区 repartition
HashPartitioner,RangePartitioner


15、RDD计算优化

第五章 df,ds
1、创建DataFrame/DataSet



ds


2、使用SQL语句或DataFrame算子做查询


3、RDD和DataFrame相互转换

















 2677
2677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









