






要点知识回顾
- 周转时间:从作业被提交给系统开始,到作业完成为止的这段时间间隔称为作业周转时间。(周转时间=作业完成时间-作业提交时间)
- 平均周转时间:作业周转总时间 / 作业个数(平均周转时间=(作业1周转时间+作业2周转时间+……作业n周转时间)/n)
- 服务时间:进程在CPU中运行的时间
- 带权周转时间:周转时间 / 服务时间
- 平均带权周转时间:带权周转总时间 / 作业个数(平均带权周转时间=(作业1带权周转时间+作业2带权周转时间……+作业n带权周转时间)/n)
先来先服务算法(FCFS)
算法思想
先来先服务算法指的是按照作业/进程到达的先后顺序进行服务的,主要从“公平”的角度考虑。用于作业调度时,考虑的是哪个作业先到达后备队列;用于进程调度时,考虑的是哪个进程先到达就绪队列,是非抢占式算法,不会导致饥饿(某进程/作业长时间得不到服务)
优缺点
- 优点:
公平、算法实现简单- 缺点:
排在长作业(进程)后面的短作业需要等待很长时间,带权周转时间很大,对短作业来说用户体验不好,即FCFS算法对长作业有利,对短作业不利
例题
各进程到达就绪队列的时间,需要的运行时间如下表所示。使用先来先服务调度算法,计算各进程的等待时间,平均等待时间,周转时间,平均周转时间,带权周转时间,平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
先来先服务算法即是按到达的先后顺序调度。所以调度顺序为P1->P2->P3->P4
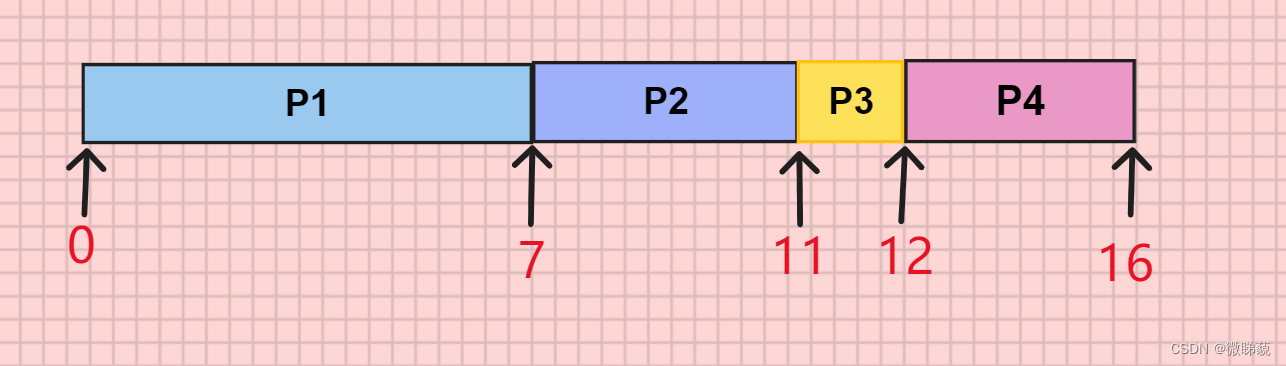
周转时间=完成时间-到达时间
P1=7-0=7; P2=11-2=9; P3=12-4=8; P4=16-5=11;
带权周转时间=周转时间/运行时间
P1=7/7=1;P2=9/4=2.25;P3=8/1=8;P4=11/4=2.75;
等待时间=周转时间-运行时间
P2=7-7=0;P2=9-4=5;P3=8-1=7;P4=11-4=7;
平均周转时间=作业总周转时间/作业个数
平均周转时间=(7+9+8+11)/4=8.75
平均带权周转时间=总带权周转时间/作业个数
平均带权周转时间=(1+2.25+8+2.75)/4=3.5
平均等待时间=总等待时间/作业个数
平均等待时间=(0+5+7+7)/4=4.75
ps:本例题中的进程都是纯计算型的进程,一个进程到达后要么在等待,要么在运行,如果是又有计算又有I/O操作的进程,其等待时间就是周转时间-运行时间-I/O操作的时间
短作业优先算法(SJF)
算法思想
短作业优先算法追求最少的平均等待时间,最少的平均周转时间,最少的平均带权周转时间,即让最短的作业/进程得到服务(最短为服务时间最短),既可用于作业调度,也可用于进程调度。用于进程调度时称为“短进程优先”(SPF)算法。SJF和SPF是非抢占式得算法,但是也有抢占式的版本——最短剩余时间优先法。会产生“饥饿”现象(如果源源不断的有短作业/进程到来),可能使长作业/进程长时间得不到服务,产生“饥饿”现象。如果一直得不到服务,则称为“饿死”。
优缺点
- 优点
“最短的”平均等待时间,平均周转时间- 缺点
不公平。对短作业有利,对长作业不利。可能产生饥饿现象。另外,作业/进程的运行时间是用户提供的,并不一定真实,不一定能做到真正的短作业优先
例题1
各进程到达就绪队列的时间,需要的运行时间如下表所示。使用非抢占式的短作业优先调度算法,计算各进程的等待时间,平均等待时间,周转时间,平均周转时间,带权周转时间,平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
短作业/进程优先调度算法:每次调度时选择当前已到达且运行时间最短的作业/进程。
调度顺序为:P1->P3->P2->P4
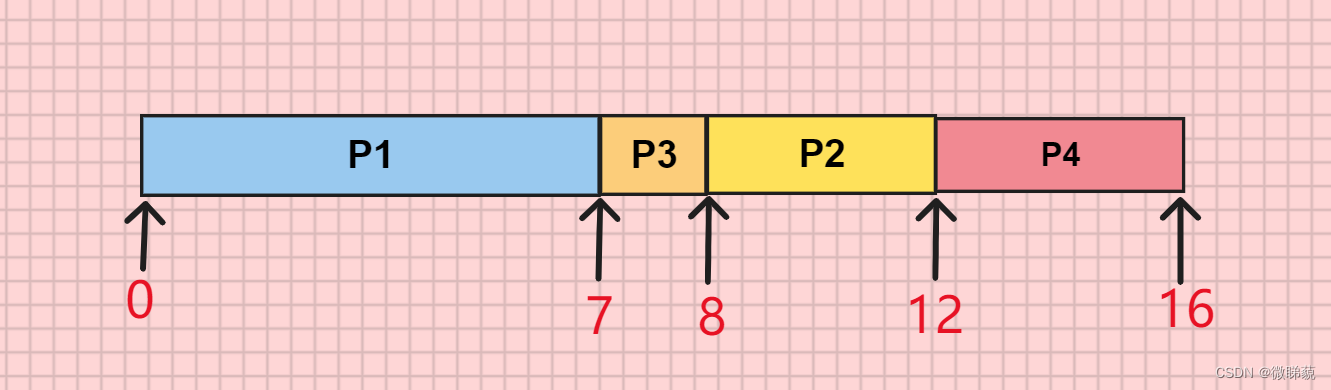
周转时间=完成时间-到达时间
P1=7-0=7; P3=8-4=4; P2=12-2=10; P4=16-5=11;
带权周转时间=周转时间/运行时间
P1=7/7=1;P3=4/1=4.25;P2=10/4=2.5;P4=11/4=2.75;
等待时间=周转时间-运行时间
P1=7-7=0;P3=4-1=3;P2=10-4=6;P4=11-4=7;
平均周转时间=作业总周转时间/作业个数
平均周转时间=(7+4+10+11)/4=8
平均带权周转时间=总带权周转时间/作业个数
平均带权周转时间=(1+4+2.5+2.75)/4=2.56
平均等待时间=总等待时间/作业个数
平均等待时间=(0+3+6+7)/4=4
对比FCFS算法的结果,显然SPF算法的平均等待/周转/带权周转时间都要更低
例题2
各进程到达就绪队列的时间,需要的运行时间如下表所示。使用抢占式的短作业优先调度算法,计算各进程的等待时间,平均等待时间,周转时间,平均周转时间,带权周转时间,平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
最短剩余时间优先算法:每当有进程加入就绪队列改变时就需要调度,如果新到达的进程剩余时间比当前运行的进程剩余时间更短,则有新进程抢占处理机,当前运行进程重新回到就绪队列。另外,当一个进程完成是也需要调度。
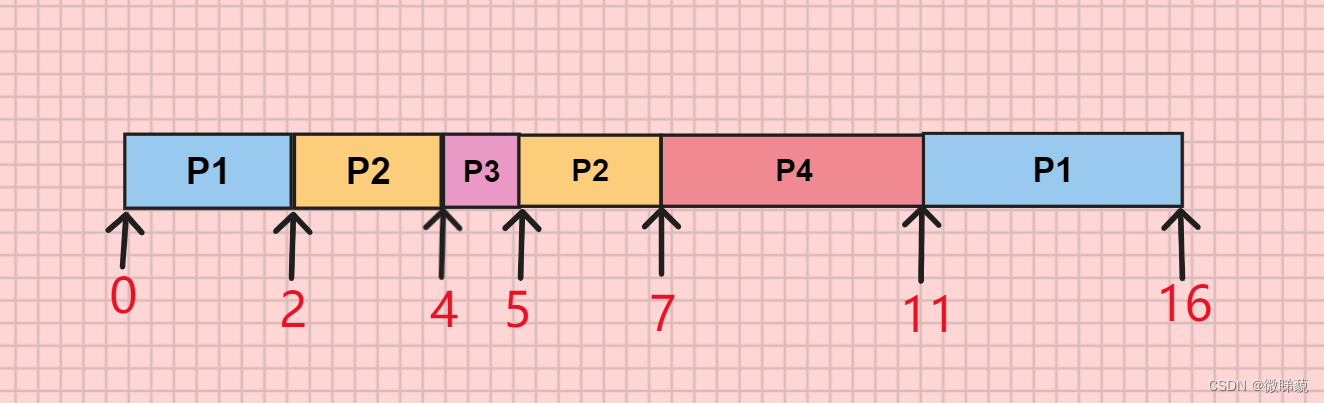
周转时间=完成时间-到达时间
P1=16-0=16; P2=7-2=5; P3=5-4=1; P4=11-5=6;
带权周转时间=周转时间/运行时间
P1=16/7=2.28;P2=5/4=1.25;P3=1/1=1;P4=6/4=1.5;
等待时间=周转时间-运行时间
P1=16-7=9;P2=5-4=1;P3=1-1=0;P4=6-4=2;
平均周转时间=作业总周转时间/作业个数
平均周转时间=(16+5+1+6)/4=7
平均带权周转时间=总带权周转时间/作业个数
平均带权周转时间=(2.28+1.25+1+1.5)/4=1.50
平均等待时间=总等待时间/作业个数
平均等待时间=(9+1+0+2)/4=3
PS:对比非抢占式的短作业优先算法,显然抢占式的这几个指标要更低
高响应比优先调度算法(HRRN)
前言
FCFS算法在每次调度的时候选择一个等待时间最长的作业(进程)为其服务,但是没有考虑到作业的运行时间,因此导致了对短作业不友好的问题。
SJF算法是选择一个执行时间最短的作业为其服务。但是又完全不考虑各个作业的等待时间,因此导致了对长作业不友好的问题,甚至还会造成饥饿问题
高响应比优先调度算法既考虑到各个作业的等待时间,也兼顾了运行时间
算法思想
要综合考虑作业/进程的等待时间和要求服务的时间。在每次调度时先计算各个作业/进程的响应比,选择响应比最高的作业/进程为其服务
响应比
=
等待时间
+
要求服务时间
要求服务时间
(响应比
>
=
1
)
响应比= \frac{等待时间+要求服务时间}{要求服务时间}(响应比>=1)
响应比=要求服务时间等待时间+要求服务时间(响应比>=1)
既可用于作业调度,也可用于进程调度。属于非抢占式的算法。因此只有当前运行的作业/进程主动放弃处理机时,才需要调度,才需要计算响应比。不会导致饥饿。
优缺点
优点
综合考虑了等待时间和运行时间(要求服务时间)
等待时间相同时,要求服务时间短的优先(SJF 的优点)
要求服务时间相同时,等待时间长的优先(FCFS 的优点)
对于长作业来说,随着等待时间越来越久,其响应比也会越来越大,从而避免了长作业饥饿的问题
缺点
由于做响应比计算故增加了系统开销
例题
各进程到达就绪队列的时间、需要的运行时间如下表所示。使用高响应比优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
| 进程 | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
高响应比优先算法:非抢占式的调度算法,只有当前运行的进程主动放弃CPU时(正常/异常完成,或主动阻塞),才需要进行调度,调度时计算所有就绪进程的响应比,选响应比最高的进程上处理机。
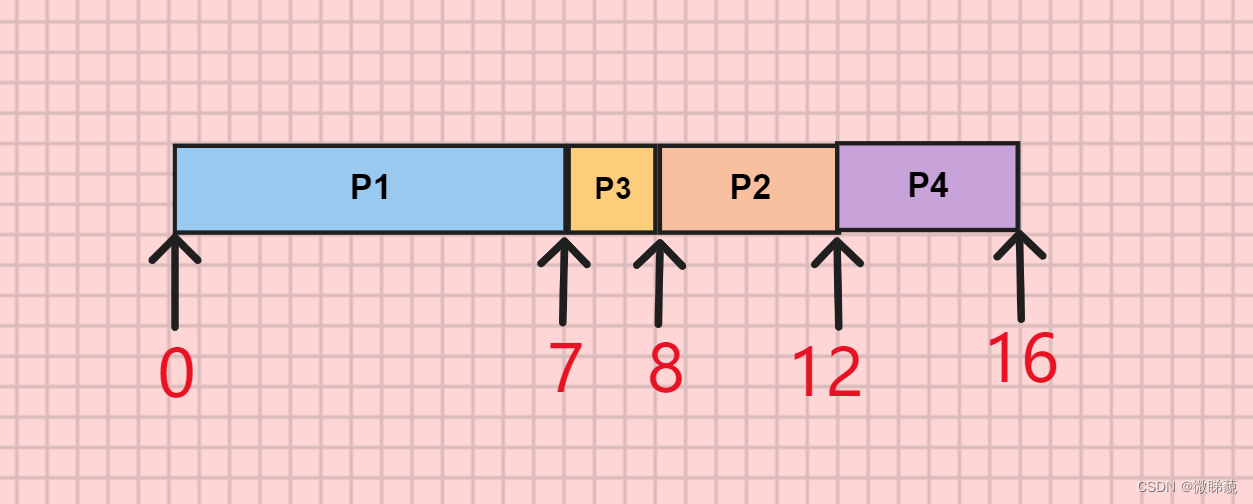
0时刻:只有P到达就绪队列,
P
1
P_1
P1上处理机
7时刻(
P
1
P_1
P1主动放弃CPU):就绪队列中有
P
2
P_2
P2(响应比=(5+4)/4=2.25)、
P
3
P_3
P3(响应比=(3+1)/1=3)、
P
4
P_4
P4(响应比=(2+4)/4=1.5),
8时刻(
P
3
P_3
P3完成):
P
2
P_2
P2(2.5)、
P
4
P_4
P4(1.75)
12时刻(
P
2
P_2
P2完成):就绪队列中只剩下
P
4
P_4
P4


















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











