






根据题目意思就是输出一个排列的全排列
例如
123的全排列又6个
123 132 213 231 312 321
这是根据字典序列,每一次都是先输出小得排列,再输出大的排列
原理:
原理是递归输出,而且是在循环里面嵌套递归输出

void Xu(int* n1, int k, int m)//递归主函数
{
if (k == m)
{
for (int j = 0; j <= m; j++)
printf("%d", n1[j]);
printf("\n");
}
else
{
for (int j = k; j <= m; j++)
{
upswap(&n1[j], &n1[k], j - k);
Xu(n1, k + 1, m);
dwswap(&n1[k], &n1[j], j - k);
}
}
}
上面是实现递归输出的主题函数,upswap和dwswap是两个自定义函数,都是用来交换,只不过交换的方向不一致。因为题目要求字典序输出,所以要将交换的过程更复杂一点。
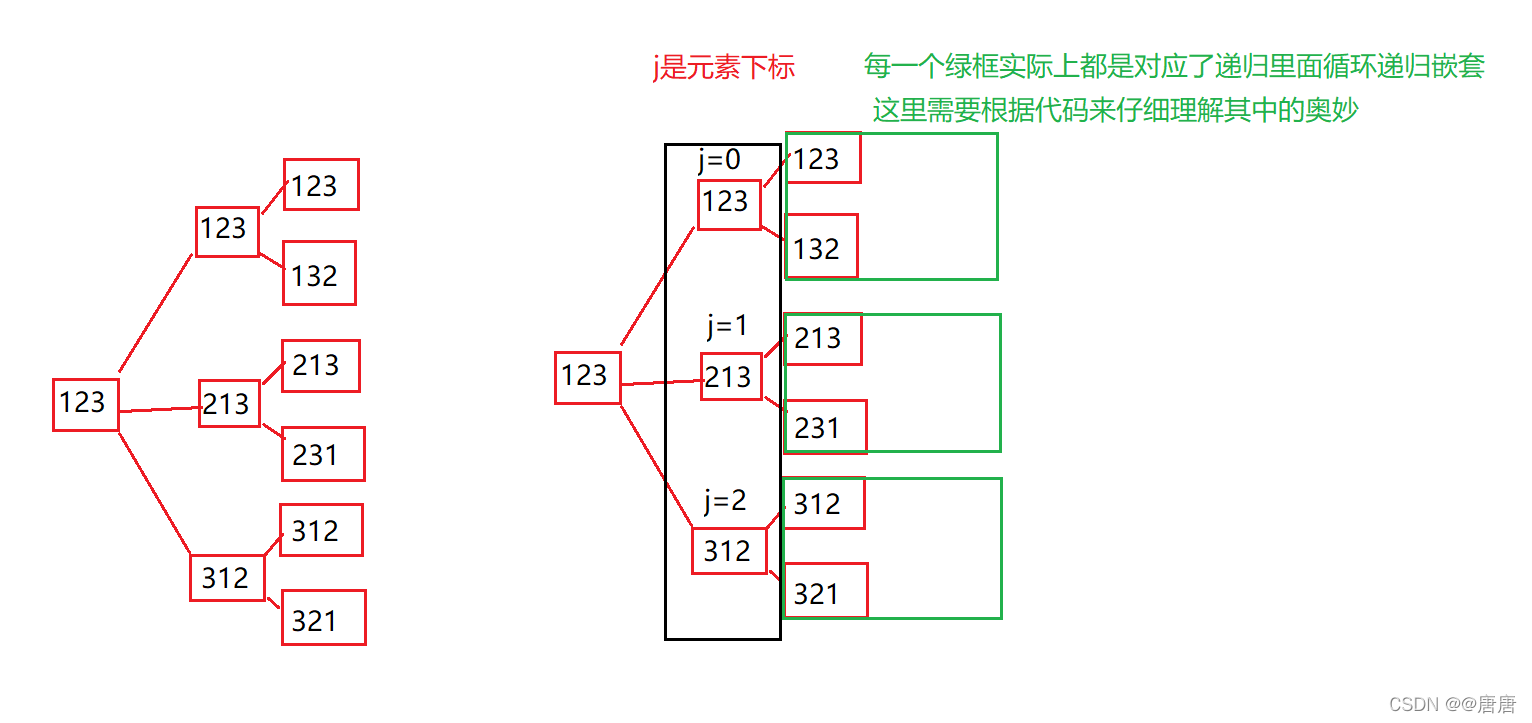
else下的for循环中嵌套了递归调用,目的就是让每一层for循环都能输出某一个数字放在整个排列的第一个时,与他对应的全排列。
例如
123,此时就是1在第一的位置,他对应的全排列
123 132
再举个例子
213,此时就是2在第一的位置,它对应的全排列
213 231
所以每一层for循环下来就能输出一种数字再第一个位置对应的全排列
总体思路就是,第一次函数调用此时确定的是第一个位置放什么数,然后递归掉调用,去确定下一个位置的数是什么,一直到最后一个位置位置。
总体来看就是,一趟for循环就能输出某个元素在第一个位置对应的全排列,详细一点就是,确定第一个位置之后,就去确定第二个位置,然后确定第三个位置,一直到确定最后一个位置,但是每一层递归都会涉及到一个for循环,这个for循环就可以控制输出多次。
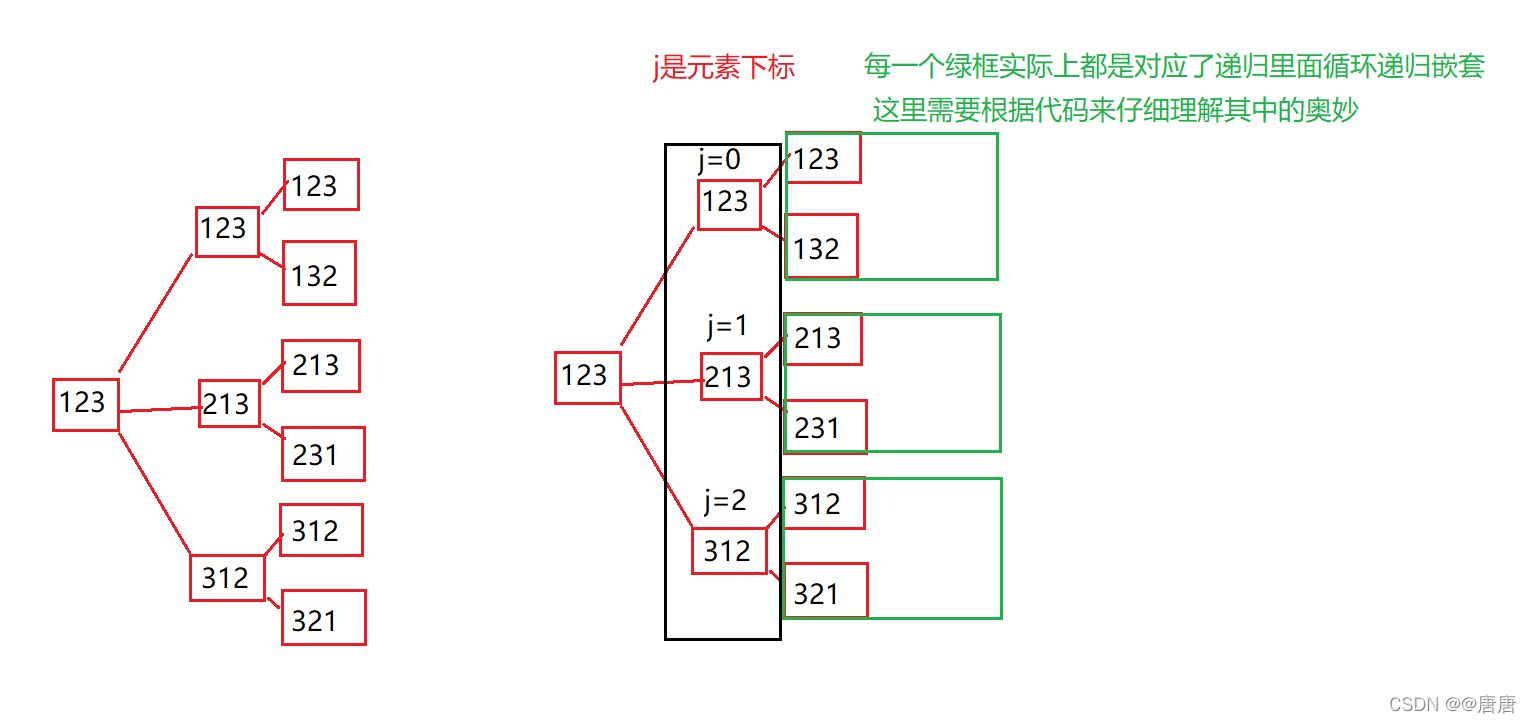
因为这里仅仅只是三位数,只需要对两个位置进行确定就行了,如果是4位数,那么就将会有4
的阶乘个排列,建议每一位读者都不要去轻易尝试,理解才是最重要的。
如果对上面的代码有大致了解了,接下来解释upswap和dwswap的区别。
upswap就是第 j 个数和第 k 个数交换,但是不是直接交换,而是两两交换,即保证他们之间的元素的排列顺序不变,将他们两个进行交换,或者说是保持字典序进行交换。
举个例子
123,交换1,3
结果:321,打乱了 1 和 2 之间的顺序,
如果用upswap进行交换
结果:312,没有打乱 1 和 2 之间的顺序
同样的dwswap就是将交换过后的还原到交换之前去,远离也是一样,只不过是,一个从后往前,
一个从前往后。

源.c
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void swap(int* n1, int* n2)//两个两个之间的交换
{
int temp;
temp = *n1;
*n1 = *n2;
*n2 = temp;
}
// j k j-k
void upswap(const int* s1, int* s2, int n)//从后往前交换
{
int* p = s1 - 1;
int temp;
for (int i = 0; i < n; i++)
{
swap(s1, p);
s1--;
p--;
}
}
void dwswap(const int* s1, int* s2, int n)//从前往后交换,也是两个两个交换
{
int* p = s1+1;
int temp;
for (int i = 0; i < n; i++)
{
swap(s1, p);
s1++;
p++;
}
}
void Xu(int* n1, int k, int m)//递归主函数
{
if (k == m)
{
for (int j = 0; j <= m; j++)
printf("%d", n1[j]);
printf("\n");
}
else
{
for (int j = k; j <= m; j++)
{
upswap(&n1[j], &n1[k], j - k);
Xu(n1, k + 1, m);
dwswap(&n1[k], &n1[j], j - k);
}
}
}
int main()
{
int n1[9] = { 1,2,3,4,5,6,7,8,9 };
int n;
scanf("%d", &n);
Xu(n1, 0, n - 1);
}


















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









