







克隆三个节点,master, slave1,slave2
修改主机名 sudo vim /etc/hostname
为什么要设置主机名呢?这是因为在根据master主机克隆的同时把主机名也克隆了,这就导致slave1主机和slave2主机的主机名也为master,因此要进行配置,在slave1,slave2上分别执行
sudo vim /etc/hostname命令并修改master为slave1,slave2
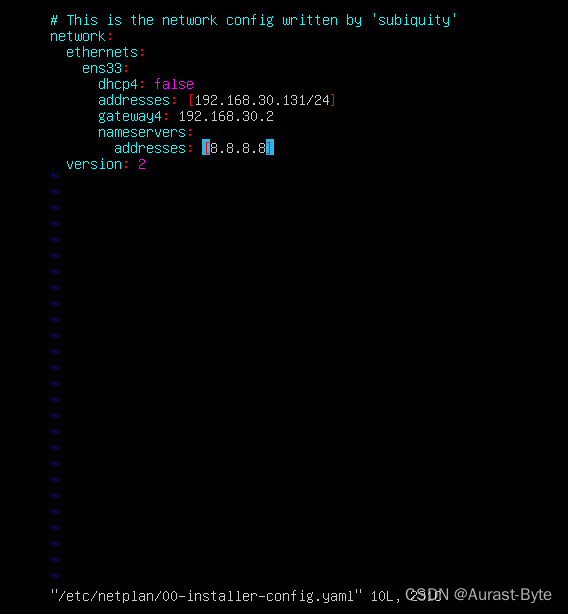
修改IP地址
修改映射 sudo vim /etc/hosts
添加
192.168.30.131 master
192.168.30.132 slave1
192.168.30.133 slave2
为了以后操作方便,我们也为宿主系统配置主机名映射,使用文本编辑器打开 C:\Windows\System32\drivers\etc\host 文件并在文件末尾添加以下配置并保存退出
192.168.30.131 master
192.168.30.132 slave1
192.168.30.133 slave2
修改完主机名和映射以后就可以使用xshell通过ssh协议远程连接linux主机
Xshell中新建三个连接分别命名为master,slave1,slave2,登录用户名为spark000,密码为123456。
下一步就可以在xshell中配置集群内三台主机之间的免密登录。
免密ssh
三个节点分别 生成秘钥ssh-keygen -t rsa
分别在三个节点运行 ssh-copy-id master 全部拷贝至master
进入.ssh 目录 cd .ssh
scp ~/.ssh/authorized_keys slave1:~/.ssh
scp ~/.ssh/authorized_keys slave2:~/.ssh
与此同时系统会让输入slave1主机和slave2主机hadoop用户的密码,这样ssh免密功能就配置好啦,可以在master上尝试 s s h s l a v e 1 命令 和 ssh slave1 命令 和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5293
5293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









