







目录
一.泛型
泛型:可以在编译阶段约束操作的数据类型并且进行检查,只能写引用数据类型。 编译的时候会检查泛型,但是转换成class字节码就不会有泛型。 泛型可以写在类,方法,接口后面
1.泛型类
1.如何定义泛型类? 2.在什么情况下使用泛型类? 3.泛型中一般传入什么字符? 案例:定义一个简单的List集合,实现add方法与get方法
public class Demo231 {
public static void main(String[] args) {
System.out.println("1.在定义类的时候,如果类里面有成员不确定的时候,就能在类后面接上泛型");
System.out.println("2.如果类里面的方法中要传递的变量数据类型,要返回的变量数据类型不确定就可以定义带有泛型的类");
System.out.println("3.public class ArrayList<E>{},一般写Type,Element,Key,Value。");
MyArrayList<String> arrayList = new MyArrayList<>();
arrayList.add("aaa");
System.out.println(arrayList.get(0));
}
}
class MyArrayList<E> {
Object[] obj = new Object[10];
int size;
public boolean add(E e) {
obj[size] = e;
size++;
return true;
}
public E get(int index) {
return (E) obj[index];
}
@Override
public String toString() {
return Arrays.toString(obj);
}
}
2.泛型方法
一样可以在返回类型上与返回传入参数上做限制 如果传入两个参数,这两个参数的类型也可以限制成一样的 泛型声明<>位置在返回类型前 案例:定义工具类,实现方法使得: 1.两个List集合添加到一起 2.list集合添加不确定数量的元素
public class Demo232 {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<>();
ArrayList<Integer> list2 = new ArrayList<>();
list1.add(1);
list1.add(2);
list2.add(3);
list2.add(4);
System.out.println(ListUtils.addAll2(ListUtils.addAll1(list1,list2),5,6,7,8,9,10));;
}
}
class ListUtils{
private ListUtils(){}
//定义静态方法addAll,用来添加两个集合的元素
public static <E> ArrayList<E> addAll1(ArrayList<E> list1, ArrayList<E> list2){
System.out.println("1.泛型声明<>位置在返回类型前");
System.out.println("2.如果泛型方法中传入两个参数,这两个参数的类型都可以被泛型限制");
Iterator<E> iterator = list2.iterator();
while (iterator.hasNext()){
list1.add(iterator.next());
}
return list1;
}
public static <E> ArrayList<E> addAll2(ArrayList<E> list1, E...e){
System.out.println("3.传递:元素类型...变量名 即可传入不定量的元素底层就是数组");
for (E element:e){
list1.add(element);
}
return list1;
}
}
3.泛型接口
1.如何定义泛型接口? 2.接口的实现类必须要指定泛型吗? 案例:定义泛型接口与两个不同的实现类
public class Demo233 {
public static void main(String[] args) {
System.out.println("1.在接口后限定<>即可定义泛型接口");
System.out.println("2.实现类能够给出具体类型,或者是继续延续泛型");
System.out.println(new MyImplement1<String>().method("aaa"));
System.out.println(new MyImplement2<Integer>().method(666));
}
}
//这个类的方法返回与传参只能使用String类型
class MyImplement1<String> implements Inter<String>{
@Override
public String method(String str){
return str;
}
}
//这个类的方法返回与传参能使用任意引用数据类型
class MyImplement2<E> implements Inter<E>{
@Override
public E method(E e) {
return e;
}
}
interface Inter<E>{
E method(E e);
}

4.泛型的继承性与泛型通配符
1.方法里面的变量用什么泛型声明的,那么传递进去的变量能用别的泛型声明吗? 2.用这个泛型的对象可以使用其泛型的子类的对象传递数据吗? 3.泛型通配符?有什么作用? 4.具体该如何使用泛型通配符?
public class Demo234 {
public static void main(String[] args) {
ArrayList<Father> list1 = new ArrayList<>();
ArrayList<Son> list2 = new ArrayList<>();
System.out.println("1.方法里面的变量用什么泛型声明的,那么传递进去的变量也必须使用这个泛型声明");
//不能传递这种参数:method(list2);
method(list1);
method3(list2);
}
//在这个地方void前加泛型<Father>声明,会让arrayList的add对象的时候需要把对象变成Father类型(Java对泛型检查保护)
public static void method(ArrayList<Father> arrayList) {
System.out.println("2.用这个泛型的对象可以使用其泛型的子类的对象传递数据");
Son son = new Son();
arrayList.add(son);
}
public static <E> void method2(ArrayList<E> arrayList) {
Son son = new Son();
arrayList.add((E) son);
}
//在此处无法让集合加入元素,过不了编译
public static void method3(ArrayList<? extends Father> arrayList) {
System.out.println("3.使用泛型通配符来限定泛型类型在某一个范围,可以限制某个继承体系的传递的参数");
System.out.println("4.<?extends E> 表示可以传递E或者E的所有子类");
System.out.println("<?super E>表示可以传递E或者E的所有父类");
}
}
class Father {}
class Son extends Father {}
二.树
1.度:每个子节点的数量
2.二叉树:每个节点的度<=2
3.其他概念:树高,根节点,左子节点,右子节点,左子树,右子树
4.二叉查找||排序||搜索树:左子节点比自己小,右子节点比自己大
5.二叉查找树的存储:小的存左边,大的存右边,一样的不存!(最后一点牢记!)
二叉查找树的查找也是同样的流程
6.二叉树的遍历:记忆的话就看当前节点的位置
前序遍历:当前节点-左子节点-右子节点
中序遍历:左子节点-当前节点-右子节点,在遍历二叉查找树,是按照从小到大的顺序去查找的
后序遍历:左子节点-右子节-当前节点,
层序遍历:这个就不解释了
7.二叉查找树的弊端:
如果数据有序,存储只存储在右节点,那么存储的数据就会一边倒,存储效率很快就会变低
要是存储的时候能够旋转一下平衡平衡就好了:如此引入平衡二叉树
二叉平衡树
8.平衡二叉树:在二叉查找树的基础上新增规则:任意节点的左右子树高度叉不能超过一
9.通过左右旋转保证平衡(添加一个节点之后,该树不再是二叉树)
确定支点是从添加的节点开始不断找不平衡的父节点
10.假设不平衡的节点为A
(1)左旋:把A降级为其左子节点,把A原本的右子节点晋升,取代A
(2)如果这个时候晋升的节点有左子树,丢掉。把它给A,变成A的右子树(因为原本A的右子树所有节点都比它大)
(3)右旋:把A降级为其右子节点,把A原本的右子节点晋升,取代A
(4)如果这个时候晋升的节点有右子树,把它给A,变成A的左子树
11.需要旋转的四种情况:
(1)左左:根节点左子树的左子树有节点插入,一次右旋就能解决
(2)左右:根节点左子树的右子树右节点插入,要先左旋再右旋:
如果和左左一样,那么你就会发现A得到的新的左子树还是在原本的层级,树的长度并没有减少,直接右旋是无效的
所以要先在根节点的左子节点进行左旋,把情况变得和左左一样,再到根节点右旋
(3)右左:和左右一样,直接左旋不行,需要先在根节点的右子节点进行右旋,再到根节点进行左旋
(4)右右:直接左旋。
红黑树(B树)
红黑树:自平衡的二叉查找树,也叫二叉B树
红黑树每个节点都有存储位表示节点的颜色,每一个节点可以是黑或者红,不是高度平衡,而是红黑规则实现!!!!
平衡二叉树虽然查找的时间快,但是添加的时候就有点麻烦
红黑树是一颗二叉查找树,不是高度平衡,满足红黑规则(没有二叉平衡树那么严格)
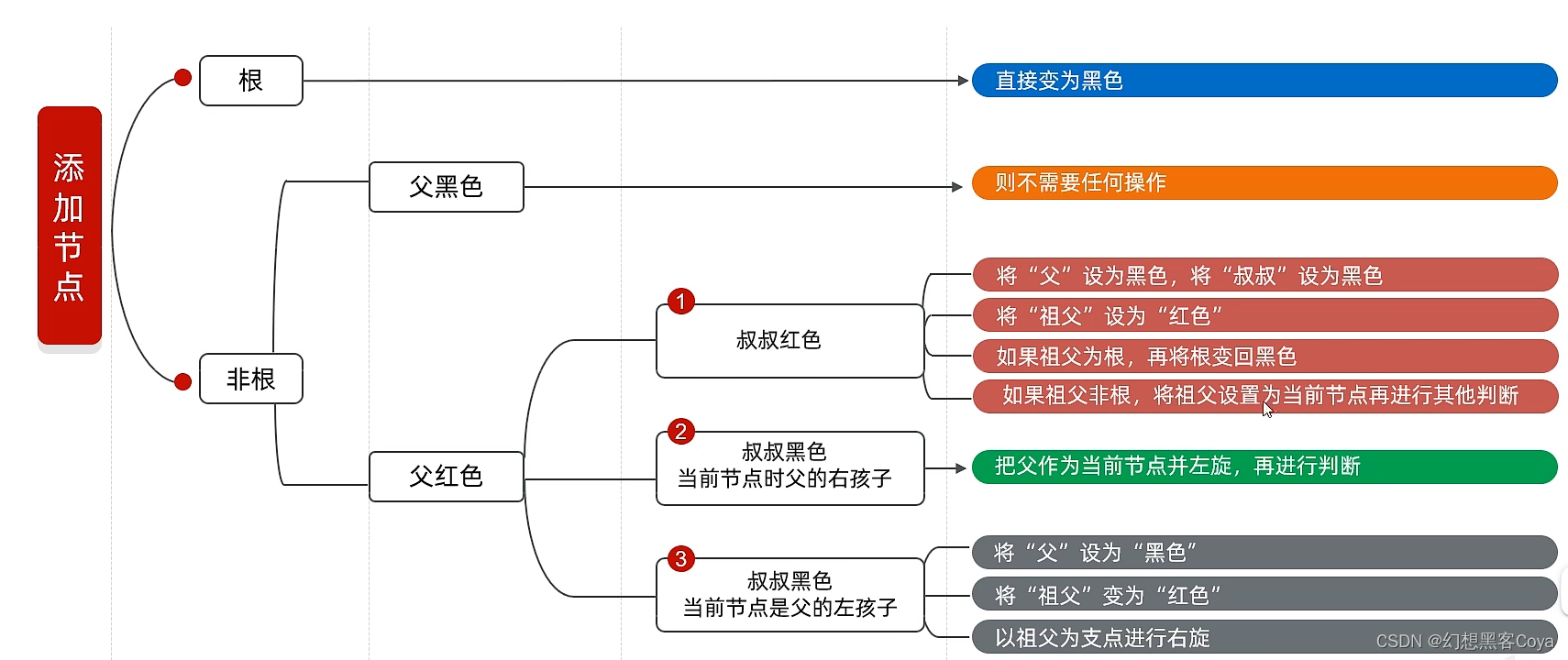
红黑规则:
1.节点必须是红色或者是黑色
2.根节点为黑色
3.如果一个节点缺失了左节点或者右节点,这个节点会记录空的黑色节点Nil代表叶子节点
4.红色节点的子节点必须是黑色
5.每个节点到叶节点的所有路径中:经过的黑色节点是相等的
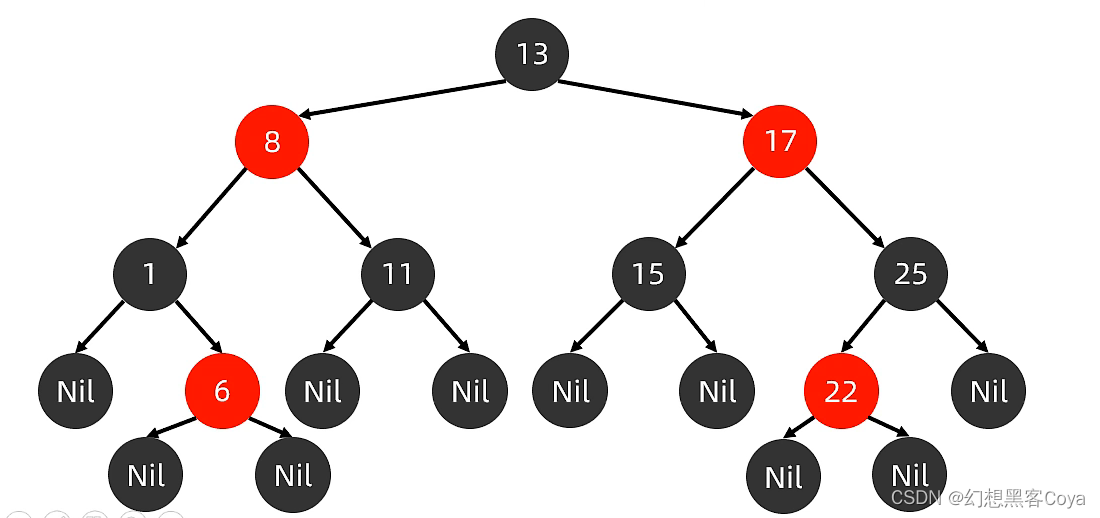
对于每一个节点:多出颜色属性记录颜色
添加红黑树默认添加红色会更快,添加过程:
1.根节点是黑色
2.如果父亲是黑色,加入红色节点不会右任何影响
3.如果父亲是红色,就要看叔叔
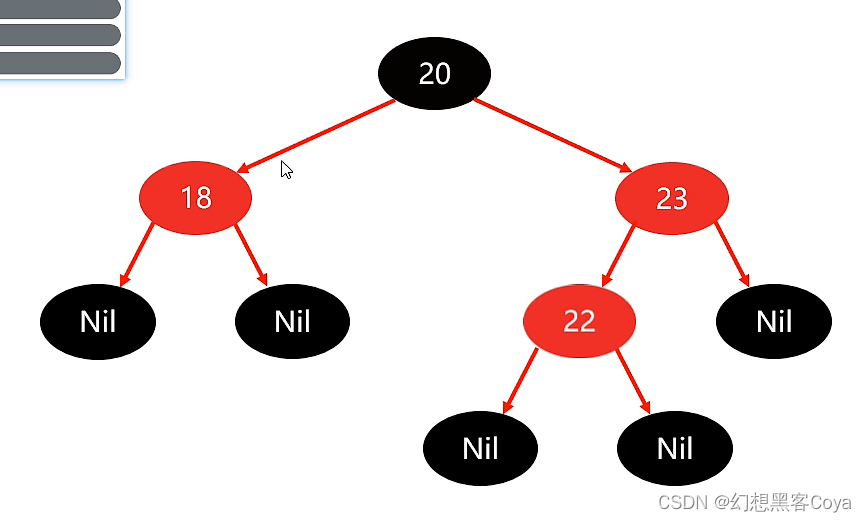
(1)如果叔叔和父亲全是红色,那么就把他们两个全部变为黑色·,祖父变成红色
如果祖父为根,就变回黑,不是根就把祖父设置成为当前的节点在进行判断
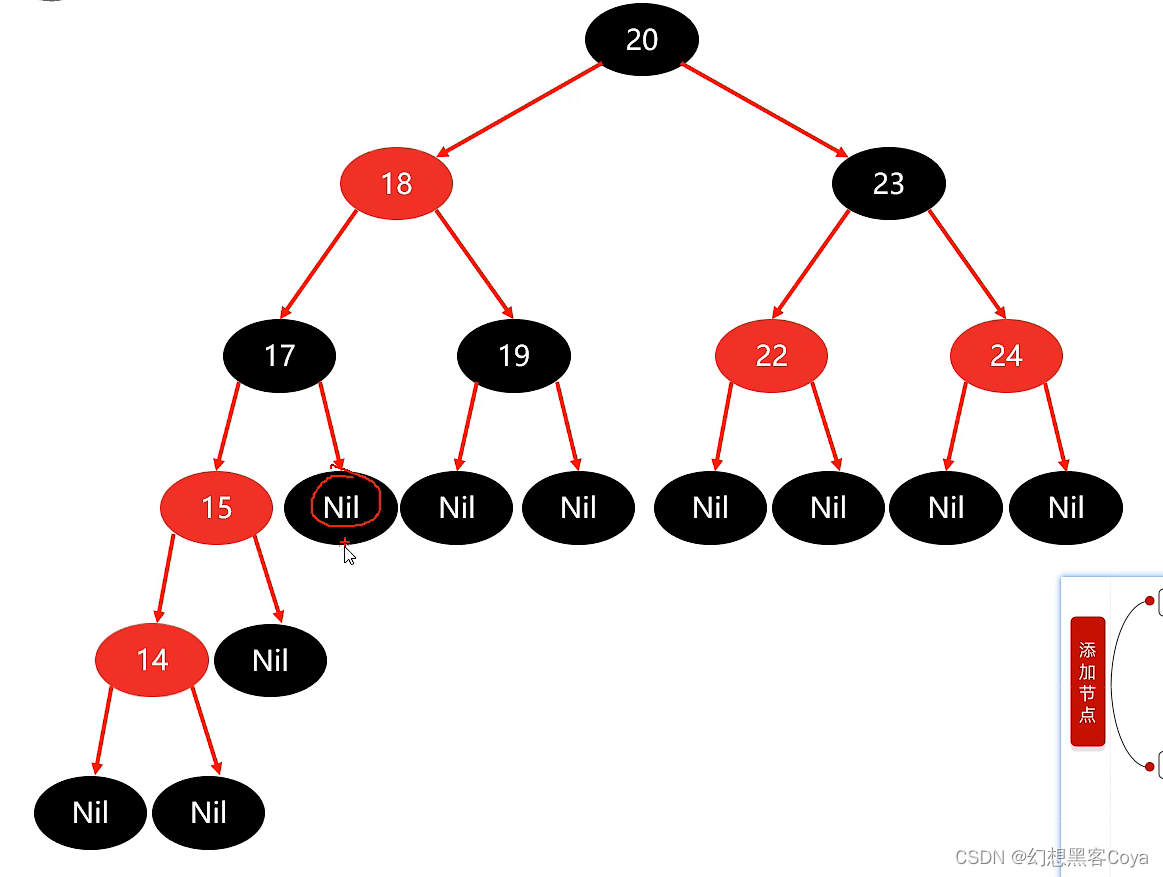
(2)如果叔叔是黑色,自己是左孩子,就需要把父亲变为黑色(和叔叔一样),再把祖父设置为红色,再把祖父右旋
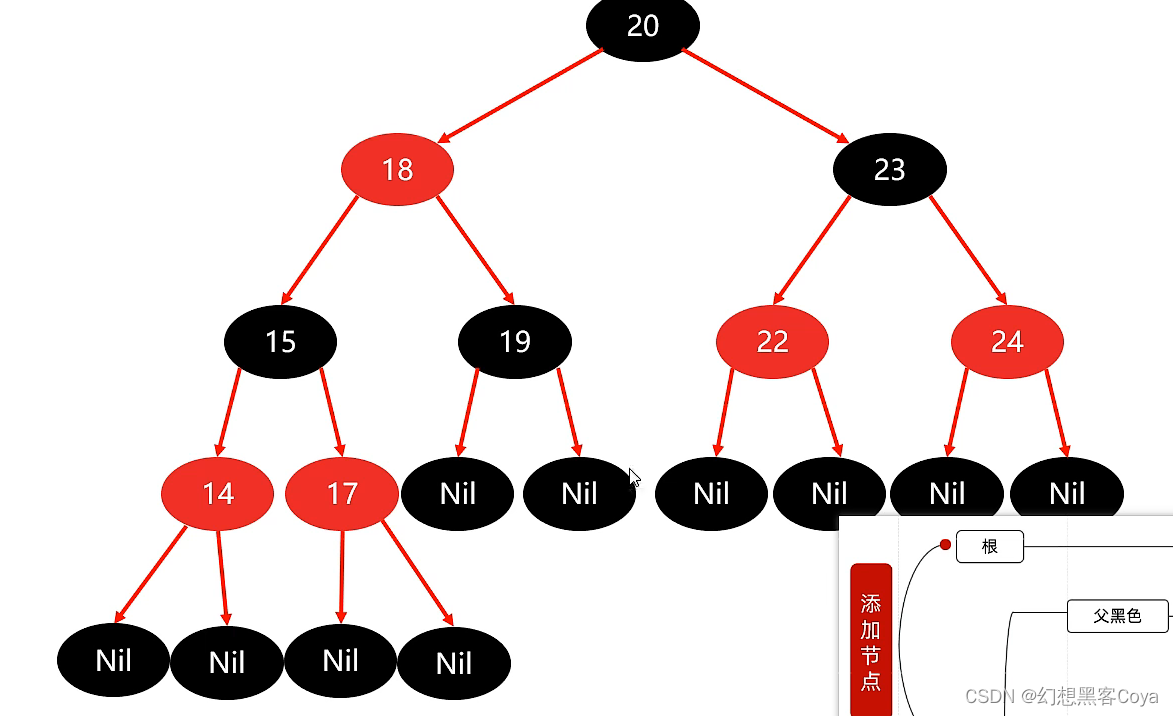
(3)如果叔叔是黑色,自己是右孩子,先左旋父亲,变成(2)情况,再进行判断
三.Set系列集合
对于Set系列:HashSet,LinkedHashSet,TreeSet,底层是用Map创建 Set系列中的方法和collection类似,可以使用迭代器,增强for,foreach方法遍历 HashSet:无序,不重复无索引 LinkedHashSet:有序,不重复无索引 TreeSet:可排序,不重复无索引
1.HashSet
Hash值:对象的整数表现形式 1.用什么方法获取Hash值? 2.获取自定义对象的时候默认获取到Hash值是什么? 3.什么是Hash碰撞? 4.一般情况下如何获取自定义对象的Hash值?
JDK8以前的底层:在JDK8之后采用数组+链表+红黑树 1.创建一个长度为16,默认加载因子为0.75(hashSet扩容时机)的数组,数组名为table 2.加入元素时:根据hash值与数组长度计算index:index=(arr.length()-1)&hash值,这里的值由于&,会使得计算的结果一定会小于数组长度 3.如果加入的元素hash值一样,而属性值不一样,那就挂在新元素下面(JDK8以前是头插法,与JDK8以后相反) 4.当链表长度大于8,数组长度大于64,就会把链表自动转成红黑树
public class Demo235 {
public static void main(String[] args) {
Student student1 = new Student("张三", 23);
Student student2 = new Student("张三", 23);
Student student3 = new Student("李四", 24);
Student student4 = new Student("王五", 25);
System.out.println("1根据hashCode方法计算出来的整数,定义在Object类中,所有对象都可以调用");
System.out.println("2.获取Hash值,默认使用地址值计算,但是一般情况下会重写HashCode方法,利用它对象内部属性计算哈希值");
int hash1 = student1.hashCode();
int hash2 = student2.hashCode();
System.out.println(hash1+" "+hash2);
System.out.println("3.在小部分情况下,会出现Hash碰撞:不同对象不同属性的对象计算出来的hash值一样");
System.out.println("abd".hashCode()+" "+"acD".hashCode());
System.out.println("4.当hashSet中存储自定义对象的时候请重写hashCode(得到哈希值以索引位置)与equals(比较对象属性,相同则不加入表)方法");
HashSet<Student> hashSet = new HashSet<>();
hashSet.add(student4);
hashSet.add(student3);
hashSet.add(student2);
hashSet.add(student1);
System.out.println(hashSet);
}
}

public class Student implements Comparable<Student> {
private String name;
private int age;
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int compareTo(Student o) {
return this.getAge() - o.getAge();
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
2.与运算的特殊情况
//与运算中的特殊情况:某一位数的后段全是1
public class Demo236 {
public static void main(String[] args) {
System.out.println("对于求index = hash*(arr.length()-1):当arr的长度是2的整数倍的时候");
System.out.println("arr.length()-1的补码就全是1,这个是时候求a&b就相当于大数除以小数留下来的余数");
//00000000 00000000 00000000 00001111
//00000000 00000000 00000000 01010000
int a = 15;
int b = 67;
System.out.println((a&b));
}
}3.LinkedHashSet与TreeSet
1.LinkedHashSet与HashSet有什么关系? 2.相比于HashSet有声明特点? 3.底层如何实现? 4.Tree与HashSet有什么关系? 5.相比于HashSet有声明特点? 6.底层用什么实现?
public class Demo237 {
public static void main(String[] args) {
System.out.println("1.LinkedHashSet是HashSet的子类");
System.out.println("2.相比于HashSet,其存取是有序的");
System.out.println("3.底层的节点能够形成双向链表");
Student student1 = new Student("张三", 23);
Student student2 = new Student("张三", 23);
Student student3 = new Student("李四", 24);
Student student4 = new Student("王五", 25);
LinkedHashSet<Student> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add(student4);
linkedHashSet.add(student3);
linkedHashSet.add(student2);
linkedHashSet.add(student1);
System.out.println(linkedHashSet);
System.out.println("4.Tree与HashSet同级");
System.out.println("5.相比于HashSet,它是可排序的,默认按照从小到大排序");
System.out.println("6.TreeSet底层基于红黑树实现,增删改查性能良好(注意这里就没有Hash表了!!)");
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(5);
treeSet.add(6);
treeSet.add(4);
treeSet.add(1);
System.out.println(treeSet);
}
}
4.TreeSet加入元素的两种方式
public class Demo238 {
public static void main(String[] args) {
System.out.println("方法一:在自定义类中实现comparable接口");
Student student1 = new Student("李四",24);
Student student2 = new Student("王五",26);
Student student3 = new Student("赵六",25);
Student student4 = new Student("张三",23);
TreeSet<Student> treeSet = new TreeSet<>();
treeSet.add(student1);
treeSet.add(student2);
treeSet.add(student3);
treeSet.add(student4);
System.out.println(treeSet);
System.out.println("方法二:创建TreeSet对象的时候,传递Comparator指定规则,这个方法优先级更高");
TreeSet<String> treeSet1 = new TreeSet<>();
TreeSet<String> treeSet2 = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int result = o1.length() - o2.length();
if (result == 0) result = o1.compareTo(o2);
return result;
}
});
treeSet1.add("c");
treeSet1.add("ab");
treeSet1.add("bcd");
treeSet1.add("qwqwq");
treeSet2.add("c");
treeSet2.add("ab");
treeSet2.add("bcd");
treeSet2.add("qwqwq");
System.out.println(treeSet1);
System.out.println(treeSet2);
}
}















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









