






这里写自定义目录标题
- HPL测试:求解稠密线性方程组
- HPL安装
- MPICH
- GOTOBLAS
- HPL
- HPL定义
- HPL算法概述
- HPL Frequently
- HPL的优化
- N设置大一些
- 打开HPL的配置文件HPL.dat进行调参优化
- 第三方数学库的选择
- 编译器优化
- 进程与节点的对应关系
- 优化任务分配(CPU、GPU任务的分配)
- 散热
- 机器模型方面优化
- 改变节点顺序
HPL测试:求解稠密线性方程组
-
Linpack是测试高性能计算机系统浮点性能的基准测试,通过对高性能计算机采用高斯消元法求解一元N次稠密线程代数方程组的测试,评价高性能计算机的浮点计算性能。
-
计算机计算峰值是指计算机每秒钟能完成的浮点计算最大次数,是衡量计算机性能的一个重要指标。它包括理论浮点峰值和实测浮点峰值。
-
理论浮点峰值是该计算机理论上能达到的每秒钟能完成浮点计算最大次数,它主要是由 CPU的主频决定的。计算公式如下:
理 论 浮 点 峰 值 = C P U 主 频 × C P U 每 个 时 钟 周 期 执 行 浮 点 运 算 次 数 × C P U 数 量 理论浮点峰值=CPU主频×CPU每个时钟周期执行浮点运算次数×CPU数量 理论浮点峰值=CPU主频×CPU每个时钟周期执行浮点运算次数×CPU数量 -
实测浮点峰值是指 Linpack 测试值。也就是说在这台机器上运行 Linpack 测试程序,通过各种调优方法得到的最优的测试结果。
-
HPL安装
MPICH
MPICH是MPI(Message-Passing Interface)的应用实现,支持最新的MPI-2接口标准,是用于并行运算的工具,在程序设计语言上支持C/C++和Fortran。
sudo apt-get install gcc
sudo apt-get install gfortran
tar -zxvf mpich-xxx.tar.gz
cd mpich.xxx
//进行软件配置与检查:
//configure文件是一个可执行的脚本文件,它有很多选项
// --prefix指的是安装路径
./configure --prefix=/usr/local/mpich-3.4.2
make
make install
//!配置环境变量
//bashrc包含专用于某个用户的bash shell的信息
sudo vim ~/.bashrc
//最下面一行插入
export PATH=/usr/local/mpich-3.4.2/bin:$PATH
//更新配置文件
source ~/.bashrc
//!用which来检验下配置的环境变量是否正确。
which mpicc
which mpif90
GOTOBLAS
BLAS 库(Basic Linear Algebra Subprograms)即基础线性代数子程序库,里面拥有大量已经编写好的关于线性代数运算的程序。常见的BLAS有GOTO、Atlas、ACML、MKL。其中GotoBlas的性能最好,因此采用GotoBlas
https://www.tacc.utexas.edu/research-development/tacc-software/gotoblas2
tar -zxvf GotoBLAS2-1.13\ tar.gz
cd GotoBLAS2
vim f_check

sudo apt-get install lapack
cp /home/linpack/lapack-3.1.1.tgz ./
#复制lapack到GOTOBLAS目录
make clean
make TARGET=NEHALEM
HPL
www.netlib.org/benchmark/hpl
tar -xzvf hpl-2.2
mv hpl-2.2 hpl
cd hpl
cp ./setup/Make.Linux_PII_FBLAS ./
//此时打开LinPack的配置私房菜
//注意CCFLAGS参数改一下(增添-fuse-ld=gold -pthread -lm)
make arch=Linux_PLL_PBLAS
如果编译成功:
/hpl/bin文件下会产生一个新文件,里面有HPL.dat xhpl两个文件
mpirun -np 4 ./xhpl 没有出错的话,就是安装成功了
HPL定义
HPL是指用于分布式内存计算机的高性能 Linpack 基准测试的可移植实现。它主要由下面几个特点组成:
- 二维块循环数据分布
- 具有多个前瞻深度的行部分主元的 LU 分解的右视变体
- 具有主元搜索和列广播的递归面板分解组合
- 各种虚拟面板广播拓扑
- 带宽减少交换广播算法
- 具有深度 1 的前瞻的反向替换。
HPL自由度很大,使用者可以根据需要选择矩阵的规模,分块大小与分解方法。
HPL算法概述
求解N维线性方程组Ax=b的解,首先通过局部列主元的方法对N*(N+1)的[A b]系数矩阵进行LU分解为:[A,b]=[[LU],y]。由于下三角矩阵L因子所作的变换在分解的过程中也逐步应用到b上,所以最后方程组的解α就可以由转化为求解上三角矩阵U作为系数矩阵的线性方程组Ux=y从而得到.
为了保证良好的负载平衡和算法的可扩展性,数据是以循环块的方式分布到一个P×Q的由所有进程组成的2维网格中。NX(N+1)的系数矩阵首先在逻辑上被分成许多NBXNB大小的数据块,然后循环的分配到PXQ进程网格上去处理。这个分配的工作在矩阵的行、列两个方向同时进行。如图1所示。

图1a:一个矩阵被分成8×8个小块,要将它们分配到一个2×3的进程阵上,相同颜色的块被分配到同一个进程中去;图1b:为分配之后各个数据块在进程中的分布情况。前面所提到的N,NB,P,Q都是可以根据集群的具体配置和用户的需要而随时可以修改的。

HPL Frequently
- 我应该运行什么大小的问题?
- 为了找出系统的最佳性能,您应该瞄准内存中最大的问题大小。 HPL 使用的内存量本质上是系数矩阵的大小。例如,如果您有 4 个节点,每个节点有 256 Mb 的内存,这对应于 1 Gb 的总数,即 125 M 双精度(8 字节)元素。这个数字的平方根是 11585。肯定需要为操作系统和其他东西留下一些内存,所以 10000 的问题大小可能适合。根据经验,内存总量的 80% 是一个不错的猜测。如果您选择的问题大小太大,则会发生交换,并且性能会下降。如果在每个节点上生成多个进程(假设每个节点有 2 个处理器),那么重要的是每个进程的可用内存量。
- 我应该使用什么块大小的 NB ?
- HPL 使用块大小 NB 来进行数据分布以及计算粒度。从数据分布来看,NB越小,负载均衡越好。从计算的角度来看,NB 的值太小可能会在很大程度上限制计算性能,因为在内存层次结构的最高级别几乎不会发生数据重用。消息的数量也会增加。高效的矩阵乘法程序通常在内部被阻塞。该块因子的小倍数可能是 HPL 的良好块大小。底线是“好的”块大小几乎总是在 [32 … 256] 区间内。最佳值取决于系统的计算/通信性能比。在较小程度上,问题的大小也很重要。例如,您根据经验发现 44 块大小在性能方面是一个不错的选择。由于翻牌率略高,88 或 132 可能会为大型问题提供稍好的结果。
- 我应该使用什么工艺网格比 P x Q ?
- 这取决于您拥有的物理互连网络。假设网格或开关 HPL “喜欢” [1…3] 中的 k 比率为 1:k。换句话说,P 和 Q 应该近似相等,Q 略大于 P。示例:2 x 2、2 x 4、2 x 5、3 x 4、4 x 4、4 x 6、5 x 6、4 x 8 … 如果您在一个简单的以太网网络上运行,则只有一根线可以交换所有消息。在这样的网络上,HPL 的性能和可扩展性受到极大限制,非常平坦的过程网格可能是最佳选择:1 x 4、1 x 8、2 x 4 …
- 一个处理器机箱呢?
- HPL 旨在为数百个节点及更多节点上的大型问题提供良好的性能。该软件可在一个节点上运行,对于较大的问题规模,通常也可以在单个处理器上实现相当好的性能。然而,对于较小的问题规模,由于消息传递、本地索引等造成的开销可能很大。
- 为什么 HPL.dat 中有这么多选项?
- 有很多原因。首先,这些选项有助于确定系统上哪些重要,哪些不重要。其次,HPL 经常用于新系统的早期评估。在这种情况下,一切通常都不太正常,无需重新编译即可更改这些参数很方便。最后,每个系统都有自己的特点,并且可能愿意根据经验确定最佳参数集。在任何情况下,始终可以遵循本文档调整部分中提供的建议,而不必担心输入文件的复杂性。
HPL的优化
N设置大一些
打开HPL的配置文件HPL.dat进行调参优化
HPL.dat应与可执行文件 hpl/bin//xhpl 位于同一目录中。默认情况下会提供一个示例 HPL.dat 文件。该文件包含有关问题大小、机器配置和可执行文件要使用的算法特征的信息。它有 31 行长。所有选定的参数都将打印在可执行文件生成的输出中。 。

-
第 1 行:通常人们会出于自身利益使用此行。例如,它可以用来总结输入文件的内容。默认情况下,该行显示为: HPL Linpack benchmark input file
-
第 2 行:与第 1 行相同。默认情况下,此行显示为: 田纳西大学创新计算实验室
-
第 3 行:用户可以选择将输出重定向到的位置。在文件的情况下,名称是必需的,这是要指定它的行。只有这一行中的名字很重要。默认情况下,该行显示为: HPL.out 输出文件名(如果有) 这意味着如果选择将输出重定向到文件,该文件将被称为“HPL.out”。该行的其余部分未使用,并且此空间用于对该行的含义进行一些信息性注释。
-
第 4 行:此行指定输出的位置。该行已格式化,必须以正整数开头,其余无意义。正整数可以有 3 种选择,6 表示输出将进入标准输出,7 表示输出将进入标准错误。任何其他整数意味着输出应该被重定向到一个文件,该文件的名称已在上面的行中指定。此行默认为: 6 设备输出(6=stdout,7=stderr,文件) 这意味着可执行文件生成的输出应重定向到标准输出。
-
!!第 5 行:此行指定要执行的问题大小的数量。这个数字应该小于或等于 20。第一个整数是有效的,其余的被忽略。如果该行显示:
3 # of problems sizes(N) 这意味着用户愿意运行将在下一行中指定的 3 个问题大小。- 求解矩阵的大小N(第5、6行)
矩阵的规模N越大,有效计算所占的比例也越大,系统浮点处理性能也就越高;但与此同时,矩阵规模N的增加会导致内存消耗量的增加,一旦系统实际内存空间不足,使用缓存,性能会大幅度降低。因此,对于一般系统而言,要尽量增大矩阵规模 N 的同时,又要保证不使用系统缓存。
考虑到操作系统本身需要占用一定的内存,除了矩阵 A(N×N)之外,HPL 还有其它的内存开销,另外通信也需要占用一些缓存(具体占用的大小视不同的MPI而定)。一般来说,矩阵 A 占用系统总内存的80%左右为最佳,即 N×N×8=系统总内存×80%。
- 求解矩阵的大小N(第5、6行)
-
第 6 行:这一行指定了要运行的问题大小。假设上面的行以 3 开头,前 3 个正整数是有效的,其余的被忽略。例如: 3000 6000 10000 纳秒,表示希望 xhpl 运行 3 个(在第 5 行中指定)问题大小,即 3000、6000 和 10000。
-
第 7 行:此行指定要运行的块数量。这个数字应该小于或等于 20。第一个整数是有效的,其余的被忽略。如果该行显示: 5 # 个 NB 这意味着用户愿意在下一行中指定的 5 个块大小。
-
求解矩阵分块的大小 NB(第7、8行)
为提高数据的局部性,从而提高整体性能,HPL 采用分块矩阵的算法。分块的大小对性能有很大的影响,NB 的选择和软硬件许多因数密切相关。NB 值的选择主要是通过实际测试得到最优值。经验:NB不可太大或太小,一般在512以下,一般为64的倍数。 -
第 8 行:这一行指定要运行的块大小。假设上面的行以 5 开头,前 5 个正整数是有效的,其余的被忽略。例如: 80 100 120 140 160 NB 表示希望 xhpl 使用 5 个(在第 7 行中指定)块大小,即 80、100、120、140 和 160。
-
第 9 行:此行指定 MPI 进程应如何映射到平台的节点上。目前有两种可能的映射,即行优先和列优先。当这些节点本身是多处理器计算机时,此功能主要有用。建议使用行优先映射。
-
第 10 行:此行指定要运行的进程网格的数量。这个数字应该小于或等于 20。第一个整数是有效的,其余的被忽略。如果该行显示:
-
2 # 进程网格 (P x Q) 这意味着您愿意尝试将在下一行中指定的 2 个进程网格大小。
-
进程阵列(P×Q)(第10-12行)
P x Q=进程数
如果仅使用GPU完成HPL异构,P x Q=GPU的数量 P<=Q -
- :
-
第 13 行:此行指定应与残差进行比较的阈值。残差应为1 阶,但实际上略小于此值,通常为 0.001。这条线是一个实数,其余的都不重要。
- 例如: 16.0 门槛 实际上,16.0 的值将涵盖大多数情况。由于各种原因,一些残差可能会稍微变大,例如 35.6。 xhpl 会将这些运行标记为失败,但是它们可以被认为是正确的。如果残差比 1 大几个数量级,例如 10^6 或更多,则应将运行视为失败。注意:如果将阈值指定为 0.0,则所有测试都将被标记为失败,即使答案可能是正确的。允许为此阈值指定负值,在这种情况下,无论阈值是什么,只要它为负值,就会绕过检查。此功能可以在执行大量实验时节省时间,例如在调整阶段。例子: -16.0 阈值 剩余线允许指定算法特征。 xhpl 将为每个问题大小、块大小、进程网格组合运行所有可能的组合。当人们寻找一组“最佳”参数时,这很方便。为了更好地理解,让我们先说几句关于在 HPL 中实现的算法。基本上,这是一个带有行部分旋转的外观正确的版本。面板分解是基于矩阵-矩阵运算的递归式,在每一步将面板划分为 NDIV 子面板。面板分解的这一部分在下面用“递归面板事实(RFACT)”表示。当当前面板由小于或等于 NBMIN 列组成时,递归停止。此时,xhpl 使用基于矩阵向量运算的分解,下面用“PFACTs”表示。然后经典递归将使用 NDIV=2,NBMIN=1。基本上有 3 种数值等效的 LU 分解算法变体(左视、Crout 和右视)。在 HPL 中,可以为 RFACT 和 PFACT 选择每一项。 HPL.dat 的以下几行允许您设置这些参数。
-
第 14-21 行:
-
(示例 1) 3 # 面板事实 0 1 2 PFACT(0=左,1=Crout,2=右) 4 # 递归停止条件 1 2 4 8 NBMIN (>= 1) 3 # 递归面板 2 3 4 NDIV 3 # 递归面板事实。 0 1 2 RFACT(0=左,1=Crout,2=右) 此示例将尝试 PFACT 的所有变体,NBMIN 的 4 个值,即 1、2、4 和 8,NDIV 的 3 个值,即 2、3 和 4,以及 RFACT 的所有变体。
-
(示例 2) 2 # 面板事实 2 0 PFACT(0=左,1=Crout,2=右) 2 # 递归停止条件 4 8 NBMIN (>= 1) 1 # 递归面板 2 NDIV 1 # 递归面板事实。 2 个 RFACT(0=左,1=Crout,2=右) 此示例将尝试 PFACT 的 2 个变体,即右视和左视,NBMIN 的 2 个值,即 4 和 8,NDIV 的 1 个值,即 2,以及 RFACT 的一个变体。 在算法的主循环中,列的当前面板使用虚拟环拓扑在进程行中广播。 HPL 提供了多种选择,最有可能希望使用编码为 1 的递增环修改。3 和 4 也是不错的选择。
-
第 22-23 行:
-
(示例 1) 1#广播 1 BCAST (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 这将导致 HPL 使用增加的环修改拓扑来广播当前面板。
-
(示例 2) 2#广播 0 4 BCAST (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 这将导致 HPL 使用递增的环形虚拟拓扑和长消息算法来广播当前面板。
-
第 24-25 行允许指定 HPL 使用的前瞻深度。
-
深度为 0 表示在当前面板的更新完全完成后分解下一个面板。
-
深度为 1 意味着下一个面板在更新后立即被分解。当前面板的更新即告完成。 k 的深度意味着 k 下一个面板在更新后立即被分解。当前面板的更新即告完成。事实证明,深度 1 似乎给出了最好的结果,但可能需要较大的问题规模才能看到性能提升。所以使用 1,如果你不知道更好,否则你可能想尝试 0。深度 3 和更大的前瞻可能不会给你更好的结果。
-
(示例 1): 1 # 前瞻深度 1 深度 (>=0) 这将导致 HPL 使用深度 1 的预读。 第 24-25 行:
-
(示例 2): 2 # 前瞻深度 0 1 深度 (>=0) 这将导致 HPL 使用深度 0 和 1 的预读。
-
第 26-27 行允许指定 HPL 用于所有测试的交换算法。
- 一种基于“二进制交换”,另一种基于“spread-roll”过程(以下也称为“long”)。对于大型问题,最后一个可能更有效。用户还可以选择混合这两种变体,即对小于阈值的列数进行“二进制交换”,然后是“展开滚动”算法。然后在第 27 行指定此阈值。
- (示例 1): 1 SWAP (0=bin-exch,1=long,2=mix) 60 交换阈值 这将导致 HPL 使用“长”或“展卷”交换算法。请注意,该示例中指定了阈值,但 HPL 未使用该阈值。 第
- (示例 2): 2 SWAP (0=bin-exch,1=long,2=mix) 60 交换阈值 一旦行面板中有超过 60 列,这将导致 HPL 使用“长”或“展卷”交换算法。否则,将使用“二进制交换”算法。
-
第 28 行允许指定列面板的上三角形是否应以非转置或转置形式存储。
- 例子: 0 L1(0=转置,1=无转置)形式
-
第 29 行允许指定 U 行的面板是否应以非转置或转置形式存储。
- 例子: 0 U in (0=transposed,1=no-transposed) 形式
-
第 30 行启用/禁用平衡阶段。除非您在第 26 行中选择了 1 或 2,否则不会使用此选项。示例: 1 平衡(0=否,1=是)
-
第 31 行允许为 HPL 分配的内存空间指定内存中的对齐方式。在现代机器上,可能想要使用 4、8 或 16。这可能会导致少量内存浪费。例子: 8 双倍内存对齐(> 0)
NOTE:
(1)如果您的平台节点是单处理器计算机,则进程映射应该无关紧要。如果这些节点是多处理器,建议使用行优先映射.
(2)HPL 喜欢“方形”或略微扁平的处理网格。除非您使用非常小的流程网格,否则请远离 1-by-Q 和 P-by-1 流程网格。
(3)14-21行指的是面板分解参数,22-23行是广播参数,24-25行是预测深度,26-27是交换参数,28-29行是本地存储。
第三方数学库的选择
HPL 实际上包含各种操作的许多可能变体。可以选择默认值,甚至可以在执行期间选择变体。由于性能要求,决定让用户有选择的机会,以便可以很容易地通过实验确定给定机器配置的“最佳”参数集。从数值精度的角度来看,所有可能的组合都严格等价,即使结果可能略有不同(按位)https://netlib.org/benchmark/hpl/algorithm.html
编译器优化
进程与节点的对应关系
优化任务分配(CPU、GPU任务的分配)
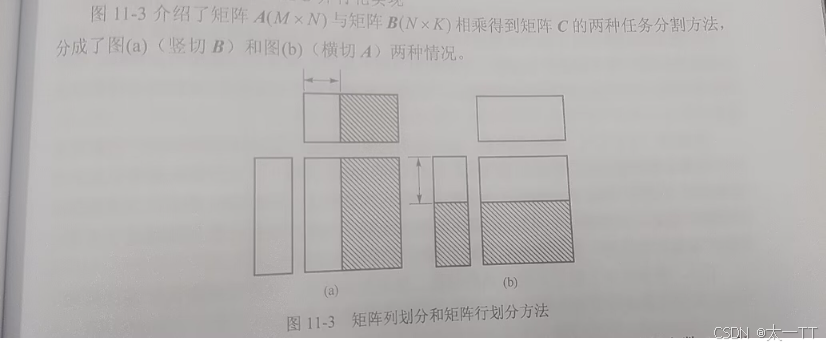
- K较小,M和N较大则B会有较好性能
- K较大,M和N较小则A会有更好性能
- 我们可以调节比例因子R从而达到CPU与GPU的负载均衡,最佳情况CPU计算时间=数据从CPU到GPU的时间+GPU计算时间+GPU上计算时间,可以实验调节R去进行改变
- 当M为64的整数倍,N和K为16的整数倍时性能最佳
散热
机器模型方面优化
首先描述用于分析的机器模型,然后使用这个粗略的模型首先估计算法各个阶段的并行运行时间,即面板分解和广播,尾随子矩阵更新向后替代。 最后根据该机器模型估计整个算法的并行效率。我们表明,对于给定的一组参数,HPL 不仅在计算量方面是可扩展的,而且在通信量方面也是可扩展的。
-
机器模型分布式内存计算机由使用消息传递互连网络连接的处理器组成。每个处理器都有自己的内存,称为本地内存,只能由该处理器访问。由于访问远程内存的时间比访问本地内存的时间长,因此此类计算机通常被称为非统一内存访问 (NUMA) 机器。
-
我们机器模型的互连网络是静态的,这意味着它由处理器之间的点对点通信链路组成。这种类型的网络也称为直接网络,而不是动态网络。后者由交换机和通信链路构成。这些链路通过开关元件动态地相互连接,以在运行时建立处理器存储器之间的路径。 这里考虑的二维机器模型的互连网络是一个静态的、全连接的物理拓扑。还假设在本地性能方面可以平等对待处理器,并且两个处理器之间的通信速率取决于所考虑的处理器。
-
我们的模型假设处理器一次只能在其一个通信端口上发送或接收数据(假设它有多个)。在文献中,这种假设也被称为单端口通信模型。 在两个给定处理器之间传递消息所花费的时间称为通信时间 Tc。在我们的机器模型中,Tc 近似为所通信的双精度(64 位)项目数量 L 的线性函数。 Tc 是准备传输消息的时间 (alpha) 和长度为 L 的消息穿过网络到达其目的地所花费的时间 (beta * L) 之和,即, Tc = α + β L。
-
最后,模型假设通信链路是双向的,即两个处理器相互发送长度为 L 的消息的时间也是 Tc。处理器一次只能在其一个通信链路上发送和/或接收消息。特别是,处理器可以在发送消息的同时从它正在发送的处理器接收另一条消息。
-
同样,该模型不对每个节点的物理内存量做出任何假设。假设如果在处理器上产生了一个进程,则可以确保该处理器上有足够的内存可用。换句话说,在建模计算期间不会发生交换。 该机器模型是一个非常粗略的近似值,专门用于说明我们特定案例的主要因素的成本。
-
面板分解和广播。让我们考虑一个分布在 P 工艺柱上的 M×N 面板。由于面板分解的递归公式,考虑浮点运算将以矩阵-矩阵乘法“速度”执行是合理的。对于面板中的每一列,对 2N 数据项执行二进制交换。当这个面板被广播时,重要的是下一个进程列将花费在这个通信操作中的时间。假设一个选择增加环(修改)变体,只需要考虑一条消息。因此,面板分解和广播的执行时间可以近似为
-
T p f a c t ( M , N ) = ( M / P − N / 3 ) N 2 g a m 3 + N l o g ( P ) ( a l p h a + b e t a 2 N ) + a l p h a + b e t a M N / P 。 Tpfact( M, N ) = (M/P - N/3) N^2 gam3 + N log(P)( alpha + beta 2 N ) + alpha + beta M N / P。 Tpfact(M,N)=(M/P−N/3)N2gam3+Nlog(P)(alpha+beta2N)+alpha+betaMN/P。
-
尾随子矩阵更新 让我们考虑分布在 P-by-Q 过程网格上的 N-by-N 尾随子矩阵的更新阶段。从计算的角度来看,必须(三角形)求解 N 个右手边,并对这个尾随子矩阵执行局部秩-NB 更新。假设选择长变量,更新操作的执行时间可以近似为
-
T u p d a t e ( N , N B ) = g a m 3 ( N N B 2 / Q + 2 N 2 N B / ( P Q ) ) + a l p h a ( l o g ( P ) + P − 1 ) + 3 b e t a N N B / Q 。 Tupdate( N, NB ) = gam3 ( N NB^2 / Q + 2 N^2 NB / ( P Q ) ) + alpha ( log( P ) + P - 1 ) + 3 beta N NB / Q。 Tupdate(N,NB)=gam3(NNB2/Q+2N2NB/(PQ))+alpha(log(P)+P−1)+3betaNNB/Q。
改变节点顺序
mpirun -np 3 -hosts node1 node2 node3
MPI默认按照命令行中节点的输入顺序去分配进程,使用上面的命令会把进程0,进程1,进程2分别分配到三个节点。但在测试的时候改变输入顺序可能会提高集群性能。
- 注意不要把共享文件夹主节点作为0号进程,因为它本身已经承担共享文件夹的管理。
- 当性能未达到预期的时候可以尝试改变俩个性能均不佳的节点顺序
- HPL的每个进程对应的任务不同,因此可以通过进程任务量的大小进行节点分配


















 4539
4539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











