







子串的定位操作通常称做申的模式匹配(其中T称为模式串),是各种串处理系统中
最重要的操作之一,字符串匹配的过程就是输入两个字符串,判断第二个字符串T(又称为模式串)是否为第一个字符串S的子串,若是,返回子串在S中的下标(以下均由C语言实现)
BF算法:
基本思想:
BF算法,又称Brute Force暴力算法,从主串S的第一个字符开始和模式T的第一个字符进行比较,若相等,则继续比较两者的后续宇符;否则,从主串S的第二个宇符开始和模式T的第一个字符进行比较,重复上述过程,直到T中的字符全部比较完毕,则说明本趟匹配成功;或S中字符全部比较完,则说明匹配失败。
可以参考下下图:(参考懒猫老师《数据结构》相关课程笔记)

即每一次匹配失败以后,指向主串的i向后移动一位,而指向模式串T的j总是回到串首,重新进行判断
代码实现:
(这里我用了两种有些区别的方法实现了BF算法)
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int isSubstring_BF(char*S,char*T){//这是BF算法的第一种实现
int i,j,temp;
if(strlen(S)<strlen(T))//子串长于主串
return -1;
for(i=0;i<strlen(S);i++){
temp=i;
for(j=0;j<strlen(T);j++){
if(S[temp]!=T[j]||temp>=strlen(S))//不相等或主串剩余长度小于子串
break;
else{
temp++;
}
}
if(j==strlen(T))
return temp;
}
return -1;
}
int isSubstring_BF1(char*S,char*T){//这是BF算法的第二种实现
int i=0,j=0,start=0;
while(S[i]!='\0'&&T[j]!='\0'){
if(S[i]==T[j]){
i++;
j++;
}else{
start++;
i=start;
j=0;
}
}
if(T[j]=='\0')
return start;
else
return -1;
}
main(){
char S[50],T[50];
// while(1){
printf("请输入第一个字符串S:");
scanf("%s",S);
printf("请输入第二个字符串T:");
scanf("%s",T);
if(isSubstring_BF1(S,T)!=-1)
printf("T是S的子串!\n");
else
printf("T不是S的子串!\n");
//}
}KMP算法:
基本思想:
KMP算法为了减少匹配的次数,采用了一种新的思路。先简单的来说,在KMP算法中,当匹配失败时,i不会移动,只将j进行移动,j移动的方法在下面会解释;i唯一移动的方法是,发现i指向的元素和j指向的首元素都不相同,则将i向后移动一位。
过程简述:
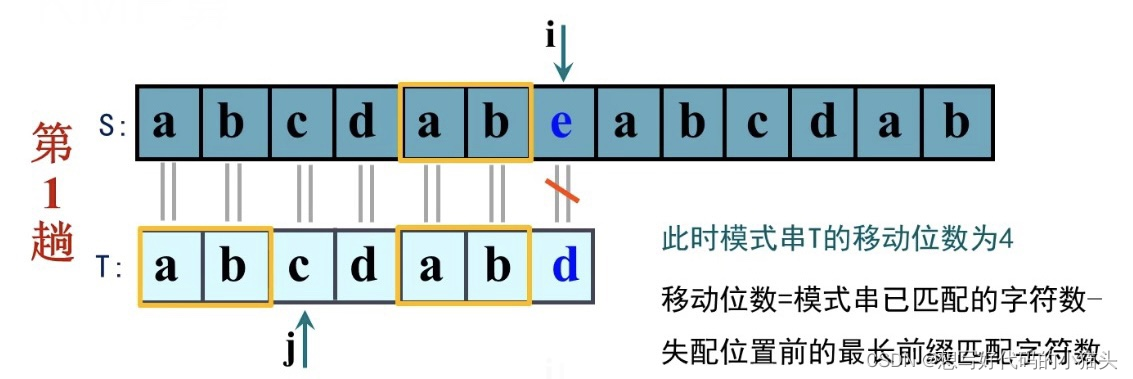
由下面可以发现,匹配成功时,i,j均移动;匹配失败时,例如主串S和模式串T在下标6号位失配,那下一步要怎么移动呢?
通过观察可以发现模式串T中前缀和后缀存在一个长度为2的相同的部分
对于D主串来说,已经验证过了黄框中的ab和T串中后缀的ab相同,而T前缀中也含有相同部分,那么,下一步,可以直接跳过T中相同的前缀部分,直接向后寻找
这里补充一下:
前缀:包含首字母,不包含尾字母的所有子串
后缀:包含尾字母,不包含首字母的所有子串
与BF算法的做法不同,KMP算法跳过T中相同的前缀部分,则下一步是:
移动位数 = 模式串T已匹配的字符数 - 失配位置前的最长前缀匹配字符数
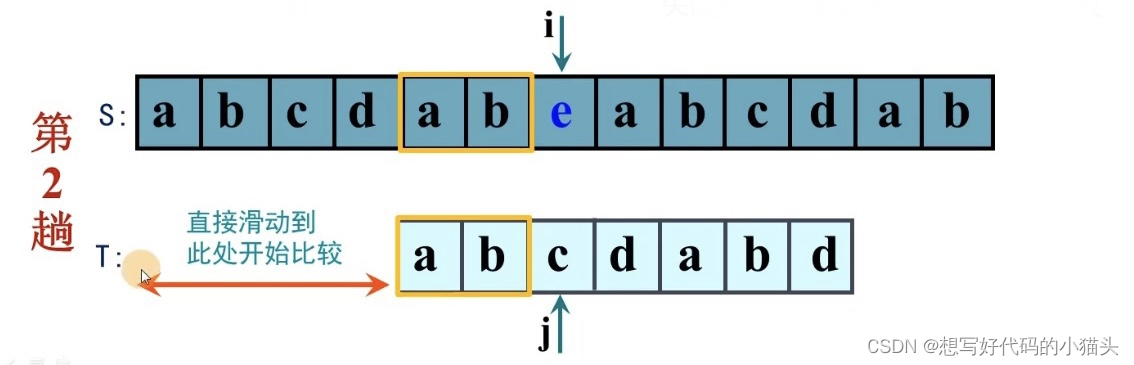
当然,如果模式串D中没有相同的前后缀,那寻找的方式就和BF相同了
那么,怎么让模式串T中的j准确的找到该回溯到的位置呢?这里引入一个新的数组,叫前缀表,即next[]:
下标与模式串T下标一致,数组中的元素是该位置之前最长的匹配前缀,(匹配指的是前后缀相同)
计算next数组的方法:

可以这样理解,因为next[]仅仅是基于模式串T形成的数组,所以并不知道在哪个位置会和S失配,所以要计算出在每一个位置失配时,j要返回的位置
以下图为例: (下划线为相同的对应前后缀)

next数组生成函数:
void getNext(char*T,int*next){//前缀表
int j=-1;//前缀
int i=0;//后缀
next[0]=-1;
int len=strlen(T);
while(i<len){
if(j==-1||T[i]==T[j]){
i++;
j++;//都移动
next[i]=j;//保存当前位置的最长相同序列串长
}
else{
j=next[j];//前缀回溯,原理也是找到相同的前后缀,直接从他们后面开始找
}
}
printf("前缀表为:");
for(int k=0;k<len;k++)
printf("%d ",next[k]);
printf("\n");
}和上面应用的是一个原理
完整代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int isSubstring_KMP(char*S,char*T){
int i=0,j=0,start=0;
int len1=strlen(S);
int len2=strlen(T);
int next[len2];
getNext(T,next);//给前缀表赋值
// printf("%d %d\n",strlen(S),strlen(T));
while(i<len1&&j<len2){//不能用S[i]!='\0'&&T[j]!='\0',因为j==-1时会越界
if(S[i]==T[j]||j==-1){//if(j==-1)即两字符串开头第一个元素就不一样
i++;
j++;
start=i;
}else{
j=next[j];//滑动到子串的下一个和开头相同序列的判准位置,i位置不变
}
// printf("现在i和j的值分别是:%d %d\n",i,j);
}
if(j==strlen(T))
return start;
else
return -1;
}
void getNext(char*T,int*next){//前缀表
int j=-1;//前缀
int i=0;//后缀
next[0]=-1;
int len=strlen(T);
while(i<len){
if(j==-1||T[i]==T[j]){
i++;
j++;
next[i]=j;//保存当前位置的最长相同序列串长
}
else{
j=next[j];//回溯
}
}
printf("前缀表为:");
for(int k=0;k<len;k++)
printf("%d ",next[k]);
printf("\n");
}
main(){
char S[50],T[50];
// while(1){
printf("请输入第一个字符串S:");
scanf("%s",S);
printf("请输入第二个字符串T:");
scanf("%s",T);
if(isSubstring_KMP(S,T)!=-1)
printf("T是S的子串!\n");
else
printf("T不是S的子串!\n");
//}
}补充:这里可以对next[]前缀表进行优化,例如:
S串:aaabaaaab
T串:aaaab
前缀表next:-1 0 1 2 3
优化后nextval:-1 -1 -1 -1 3
按照上面的next函数求得前缀表后,当比较T和S串时,在第四个位置a和b失配,由next[j]的指示还需进行i=4,j=2;i=4,j=1;i=4,j=0这三次比较,实际上,因为模式串T中1,2,3个字符和第4个字符都相等,因此不需要再和主串中第4个字符相比较,可以直接滑动4个字符。
那该如何实现呢?
如果在前缀表函数中加一个判断,如果串中有连续的元素,就把上一个字符位置找到的最长前缀值再赋一遍就可以了
代码实现:
void get_nextval(char*T,int*nextval){//前缀表
int j=-1;//前缀
int i=0;//后缀
nextval[0]=-1;
int len=strlen(T);
while(i<len){
if(j==-1||T[i]==T[j]){
i++;
j++;
if(T[i]!=T[j])
nextval[i]=j;//保存当前位置的最长相同序列串长
else{
nextval[i]=nextval[j];
}//防止重复再判断一次
}
else{
j=nextval[j];//回溯
}
}
printf("前缀表为:");
for(int k=0;k<len;k++)
printf("%d ",nextval[k]);
printf("\n");
}初学小白,有错误欢迎指正喔!~















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











