







大家好,我是 Enovo飞鱼,今天分享一个爬虫小案例,小白或者爬虫入门的小伙伴推荐阅读,加油💪。
目录
后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇
前言
入门爬虫很容易,几行代码就可以,可以说是学习 Python 最简单的途径。
刚开始动手写爬虫,你只需要关注最核心的部分,也就是先成功抓到数据,其他的诸如:下载速度、存储方式、代码条理性等先不管,这样的代码简短易懂、容易上手,能够增强信心。
基本环境配置
-
版本:Python3
-
系统:Windows
-
相关模块:pandas、csv
爬取目标网站
爬取内容

实现代码
配置好所需环境后,直接复制即可
import pandas as pd
for i in range(1,178): # 爬取全部页
tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)运行代码结束,至此,3000+ 上市公司的信息,安安静静地躺在 Excel 中
A. Pycharm内打开

B. 根据路径打开excel

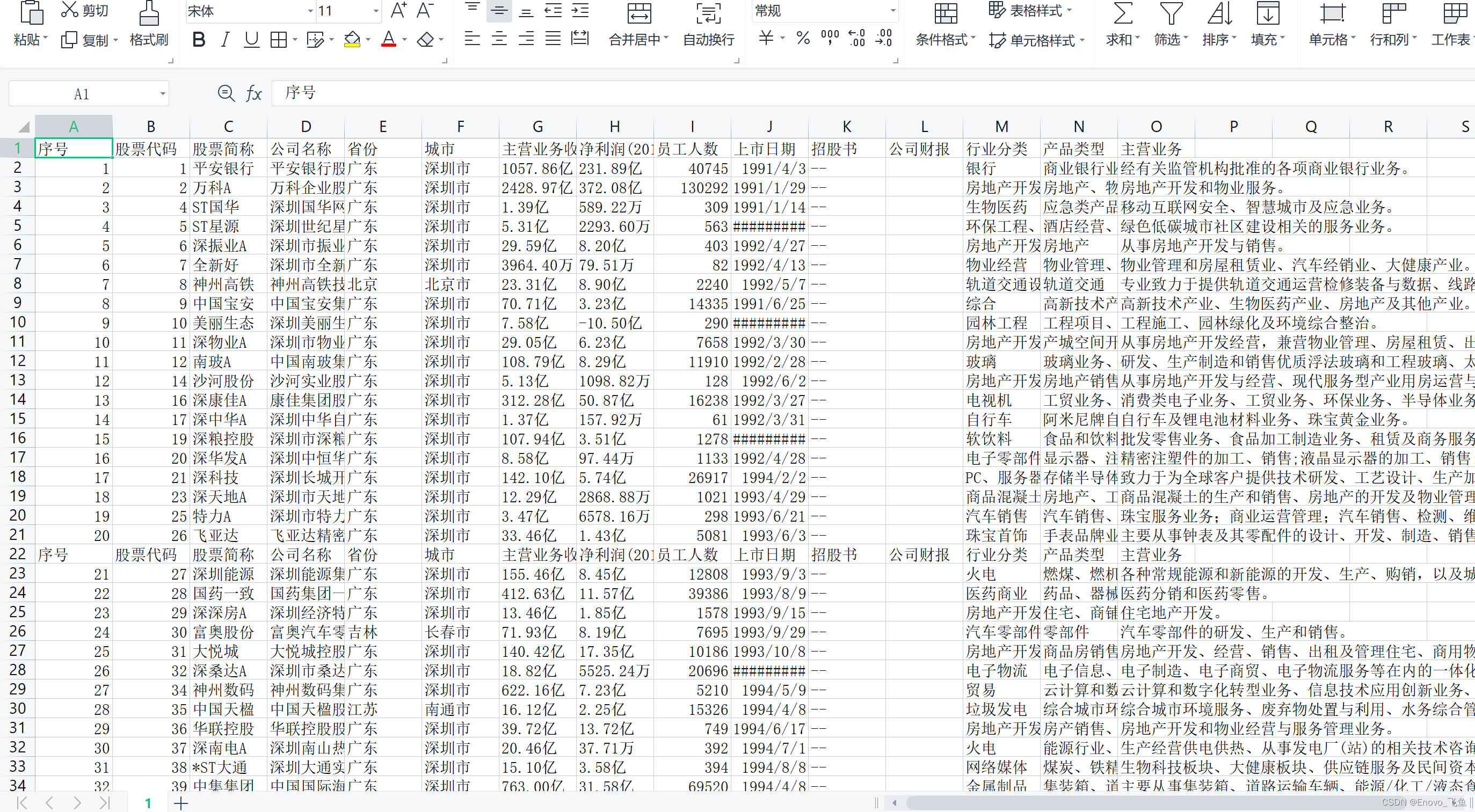
当然,如果你对 Excel 很熟悉的话 ,在 excel 内部也可以很简单的完成爬取上市公司企业数据。即,目前所被讨论的excel自动化,在这篇文章中,就不再讲述其他问题了,多多学习爬虫知识就好!💪
后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











