







文章目录
引言
Transformer是一种深度学习模型,最初是由Vaswani等人在2017年的论文《Attention Is All You Need》中提出的。这种模型在自然语言处理(NLP)领域特别流行,它引入了一种新的机制——自注意力(self-attention),使得模型能够更加高效和有效地处理序列数据。
Transformer完全基于注意力机制,没有使用循环神经网络(RNN)或卷积神经网络(CNN)。核心概念是:
-
自注意力机制:这允许模型在序列内的任意位置间直接建立依赖,从而更好地理解数据的上下文关系。自注意力机制可以并行处理所有位置的数据,这提高了计算效率。
-
多头注意力:模型会同时学习数据的不同表示,每个“头”关注序列的不同部分。这种机制可以捕获序列中多种不同级别的依赖关系。
-
位置编码:由于Transformer不使用基于顺序的结构,因此需要通过位置编码来给模型提供关于单词在序列中位置的信息。
1. Transformer架构详解
transformer与传统模型存在较大差别,主要体现在:
1. 处理数据的方式
- RNN:RNN(特别是其变种如LSTM和GRU)通过递归地处理序列数据,每个时间步的输出依赖于前一个时间步。这使得RNN特别适合处理时间序列数据或任何顺序敏感的数据。
- CNN:CNN通过卷积层提取空间特征,广泛应用于图像处理。在NLP中,CNN可以用来捕捉局部依赖,如单词和短语级别的模式。
- Transformer:Transformer使用自注意力机制,允许模型同时处理整个序列的所有元素,有效地捕捉全局依赖。这种并行处理能力使得它在处理长序列时比RNN更高效。
2. 结构和复杂性
- RNN:RNN的递归结构使得它在理论上能够处理任意长度的序列,但在实践中,由于梯度消失或爆炸的问题,它往往难以捕捉长期依赖。
- CNN:CNN结构简单,易于训练,但主要适用于捕捉局部特征。在处理全局上下文或长距离依赖时可能不够有效。
- Transformer:Transformer通过堆叠多个自注意力和前馈层,能有效地处理长距离依赖。但这也使得它的模型参数通常比RNN和CNN多,需要更多的计算资源和数据来训练。
3. 应用场景
- RNN:理想的应用场景包括语音识别、机器翻译等时间序列相关任务。
- CNN:主要用于图像处理、图像识别等领域。在NLP中,CNN可以用于文本分类、情感分析等任务。
- Transformer:Transformer在NLP领域取得了显著的成功,如BERT、GPT等,广泛应用于文本理解、生成等任务。Vision Transformer(ViT)则将其应用于计算机视觉领域。
1.1 编码器与解码器
transformer的本质就是由编码器(encoder)和解码器(decoder)组成。
1.1.1 编码器(Encoder)
事实上,编码器包括两个子层:self-attention 和 feed-forward,我们只需搞清楚这两个子层,那么理解编码器就不是什么问题了。
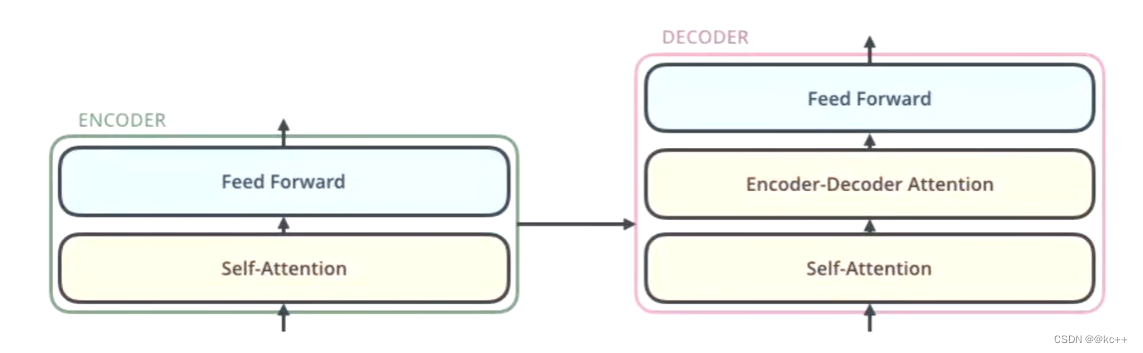
在每一个子层的传输过程中,都会有一个(残差网络 + 归一化),意思就是 self-attention 的输出会通过一个残差网络 + 归一化之后才会传给 feed-forward 。
编码器详解图
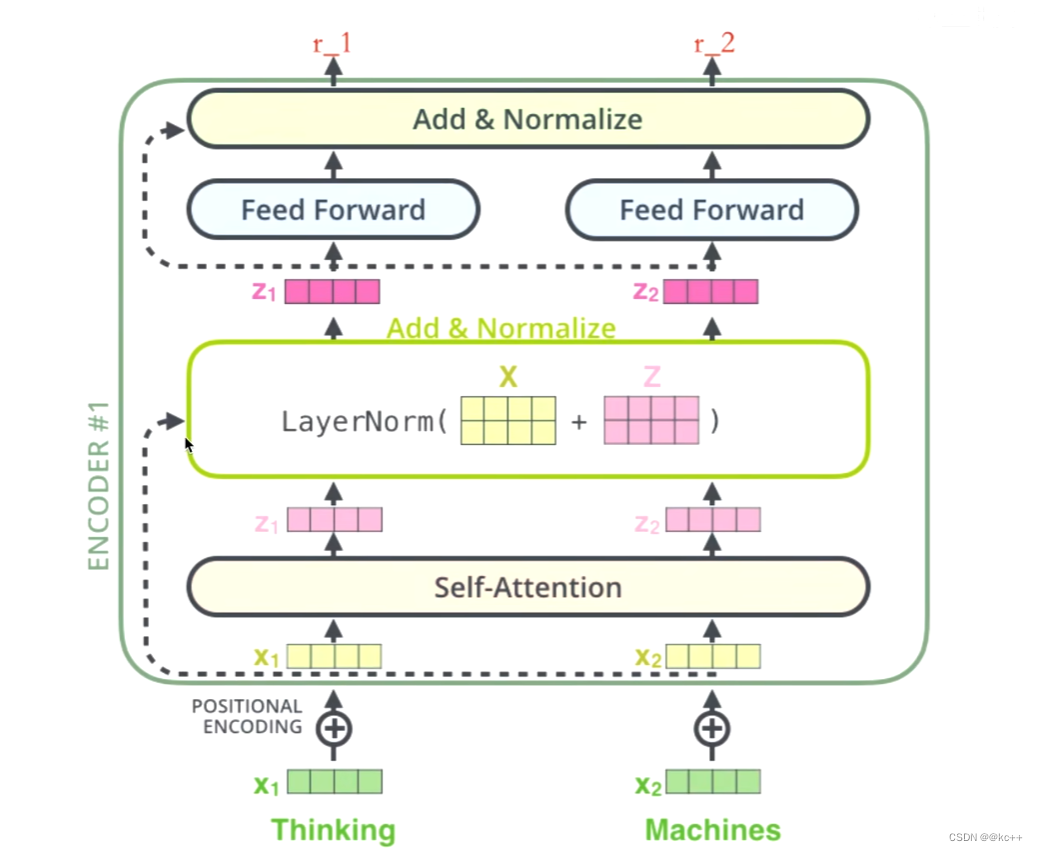
- 首先输入一个单词thinking - > 得到词向量X1(可以通过one-hot,word2vec得到)
- 然后进行positional encoding,因为self-attention的缺点在于它是没有位置信息的,所以叠加一个位置编码,给X1赋予位置属性,得到黄色的X1。也就是说,黄色的X1是拥有位置属性的one-hot编码词向量。
- 输入到 self-attention 子层中,做注意力机制(X1和X2拼接起来的一句话做注意力机制),得到,Z1(X1 与 X1,X2拼接起来的句子做了自注意力机制的词向量,表征的仍然是thinking),也就是说Z1拥有了位置特征,句法特征。语义特征的词向量。
- 残差网络(避免梯度消失),归一化(避免梯度爆炸),得到深粉色的Z1,
- feed-forward (前面每一步都在做线性变换,wx+b,线性变换的叠加永远都是线性变换,通过feed-forward 添加激活函数做非线性变换,这样空间变换可以无限拟合任何一种状态了) ,得到r1(thinking的新的表征)。
总结
事实上transformer就是在做词向量。所有的工作都是为了让这个词向量变得更加优秀,让这个词向量能够更加精准地表达这个词,这句话。总而言之,编码器就是让计算机能够合理地认识人类世界客观存在的一些东西
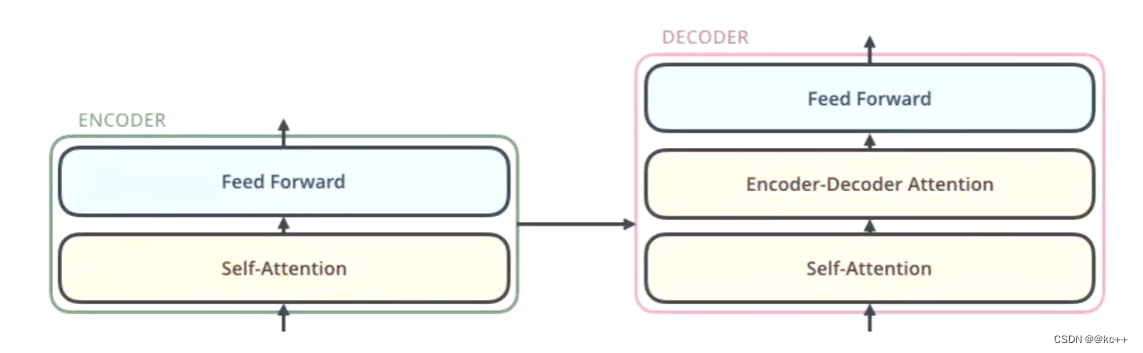
1.1.2 解码器(Decoder)
解码器由三部分构成,
掩码自注意力(Masked Self-Attention)
编码器-解码器注意力(Encoder-Decoder Attention)
前馈神经网络(Feed-Forward Neural Network)
解码器会接收编码器生成的词向量,然后通过这个词向量去生成翻译的结果。
解码器详解图
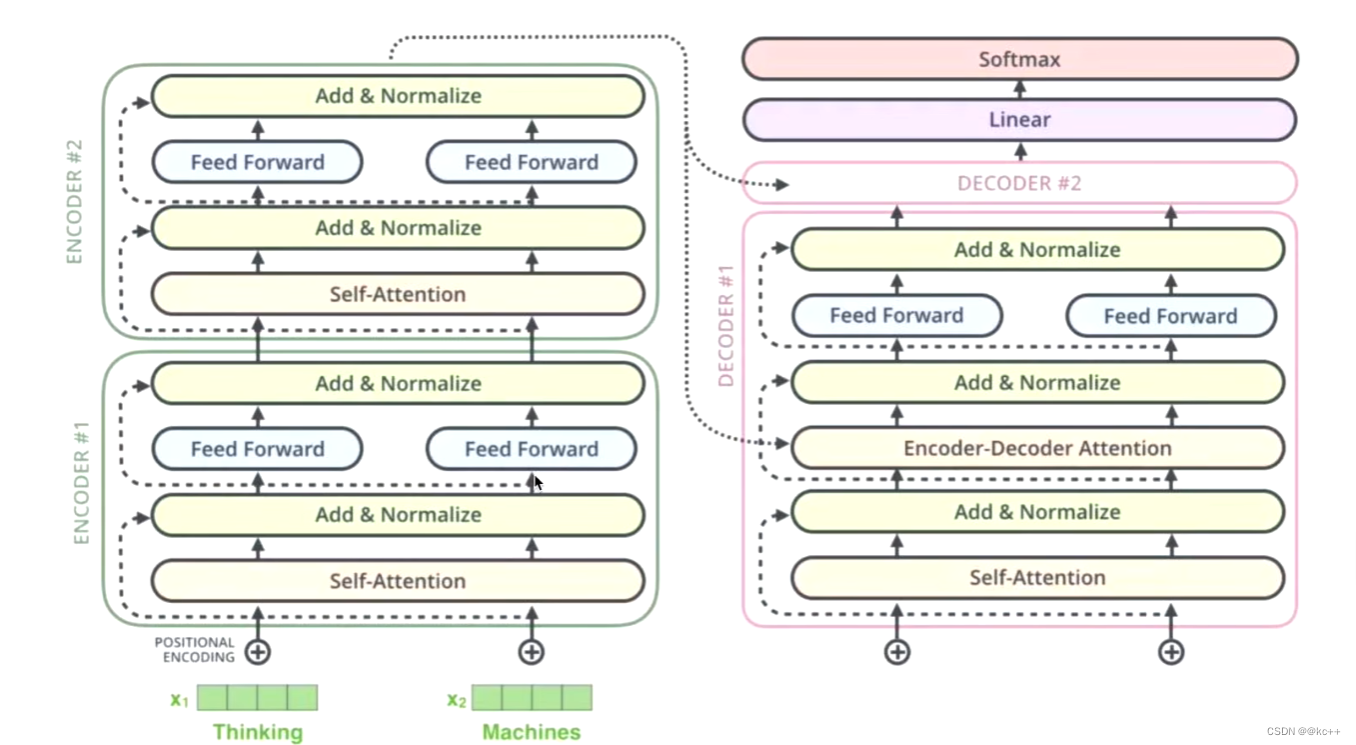
Self-Attention
- 解码器的 Self-Attention 在编码已经生成的单词
- 假如目标词 “我是一个学生” --> masked Self-Attention
- 训练阶段:目标词 “我是一个学生” 是已知的,然后 Self-Attention 是对 “我是一个学生” 做计算。如果不做masked,每次训练阶段,都会获得全部的信息
- 测试阶段:目标词未知,假设目标词是 “我是一个老师”,Self-Attention 第一次对 “我” 做计算,第二次对 “我是” 做计算,…。而测试阶段,每生成一点,获得一点
这一部分与编码器中的自注意力机制相似,但有一个关键区别:它使用掩码来防止位置 i 的注意力机制查看在位置 i 之后的输出。这种“掩码”操作确保了解码器在生成第 i 个词时只能依赖于前 i−1 个词,保持了解码过程的自回归特性。
控制信息流向的这种方法是必要的,因为在训练时模型同时看到整个目标序列,如果没有掩码,模型就可以直接“看到”正确的输出,而不是学习如何生成它。
Encoder-Decoder Attention
在这个子层中,解码器从编码器中获取信息。这里的注意力机制使得解码器的每个位置都能考虑到编码器输出的所有位置。这种机制对于将输入序列中的相关信息与输出序列正确对齐至关重要。
前馈神经网络(Feed-Forward Neural Network)
每个解码器层还包含一个前馈神经网络,这与编码器中的网络相同。它独立地处理每个位置的表示,然后将其传递到下一个层。
这个网络通常包含两个线性变换和一个激活函数。
生成词
总结
解码器的核心功能是结合编码器的输出和自身的历史输出(即迄今为止已生成的部分序列)来生成下一个输出元素。在每个时间步,解码器都会更新其关注点,既考虑到编码器的输出,也考虑到自身之前生成的输出。这种结构使得Transformer解码器能够高效地生成精确且上下文相关的序列。
2. 核心代码
2.1 自注意力(Self-Attention)机制
def scaled_dot_product_attention(query, key, value, mask):
"""计算注意力权重。"""
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 缩放 matmul_qk
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 添加掩码以避免看到未来信息
if mask is not None:
logits += (mask * -1e9)
# softmax 在最后一个轴(seq_len_k)上归一化,因此分数相加等于1。
attention_weights = tf.nn.softmax(logits, axis=-1)
output = tf.matmul(attention_weights, value)
return output
2.2 多头注意力(Multi-Head Attention)
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
# 省略了细节代码
2.3 位置编码(Positional Encoding)
def positional_encoding(position, d_model):
angle_rates = 1 / np.power(10000, (2 * (np.arange(d_model)[np.newaxis, :] // 2)) / np.float32(d_model))
angle_rads = np.arange(position)[:, np.newaxis] * angle_rates
# 将sine应用于数组中的偶数索引(indices); 2i
sines = np.sin(angle_rads[:, 0::2])
# 将cosine应用于数组中的奇数索引; 2i+1
cosines = np.cos(angle_rads[:, 1::2])
pos_encoding = np.concatenate([sines, cosines], axis=-1)
pos_encoding = pos_encoding[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
2.4 前馈网络(Feed-Forward Network)
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
2.5 编码器和解码器层
编码器
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, dff, dropout_rate):
super(EncoderLayer, self).__init__()
self.multi_head_attention = nn.MultiheadAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model)
self.layernorm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout_rate)
self.dropout2 = nn.Dropout(dropout_rate)
def forward(self, x, mask):
attn_output, _ = self.multi_head_attention(x, x, x, attn_mask=mask)
out1 = self.layernorm1(x + self.dropout1(attn_output))
ff_output = self.feed_forward(out1)
out2 = self.layernorm2(out1 + self.dropout2(ff_output))
return out2
解码器
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, dff, dropout_rate):
super(DecoderLayer, self).__init__()
self.masked_attention = nn.MultiheadAttention(d_model, num_heads)
self.multi_head_attention = nn.MultiheadAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model)
self.layernorm2 = nn.LayerNorm(d_model)
self.layernorm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout_rate)
self.dropout2 = nn.Dropout(dropout_rate)
self.dropout3 = nn.Dropout(dropout_rate)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output, _ = self.masked_attention(x, x, x, attn_mask=tgt_mask)
out1 = self.layernorm1(x + self.dropout1(attn_output))
attn_output, _ = self.multi_head_attention(out1, enc_output, enc_output, attn_mask=src_mask)
out2 = self.layernorm2(out1 + self.dropout2(attn_output))
ff_output = self.feed_forward(out2)
out3 = self.layernorm3(out2 + self.dropout3(ff_output))
return out3

















 3217
3217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









