







1、基础准备
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
# 导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于SparkXConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#打印PySpark的运行版本
print(sc.version)
#停止SparkContext对象的运行(停止pySpark程序)
sc.stop()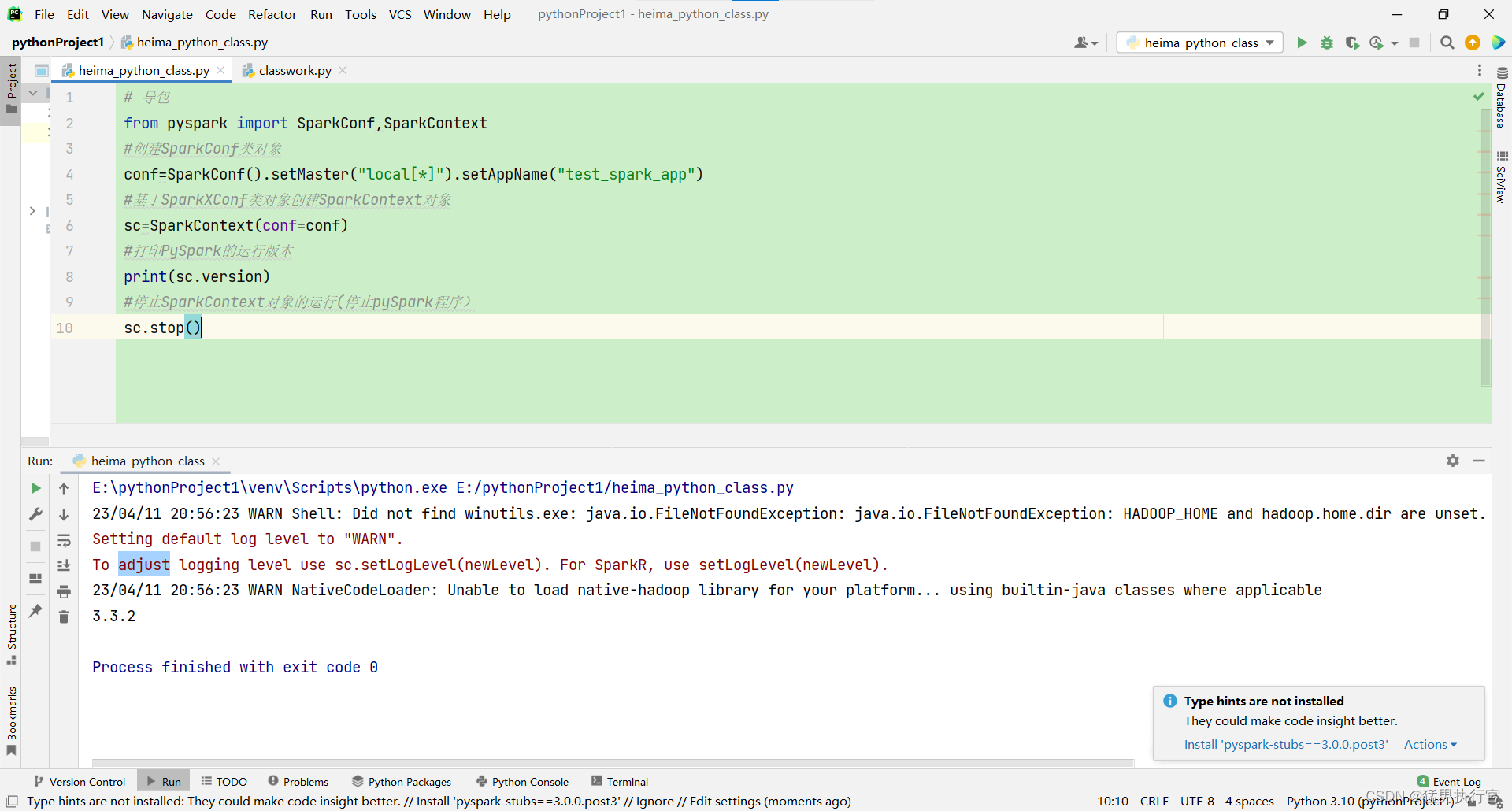
2、数据输入
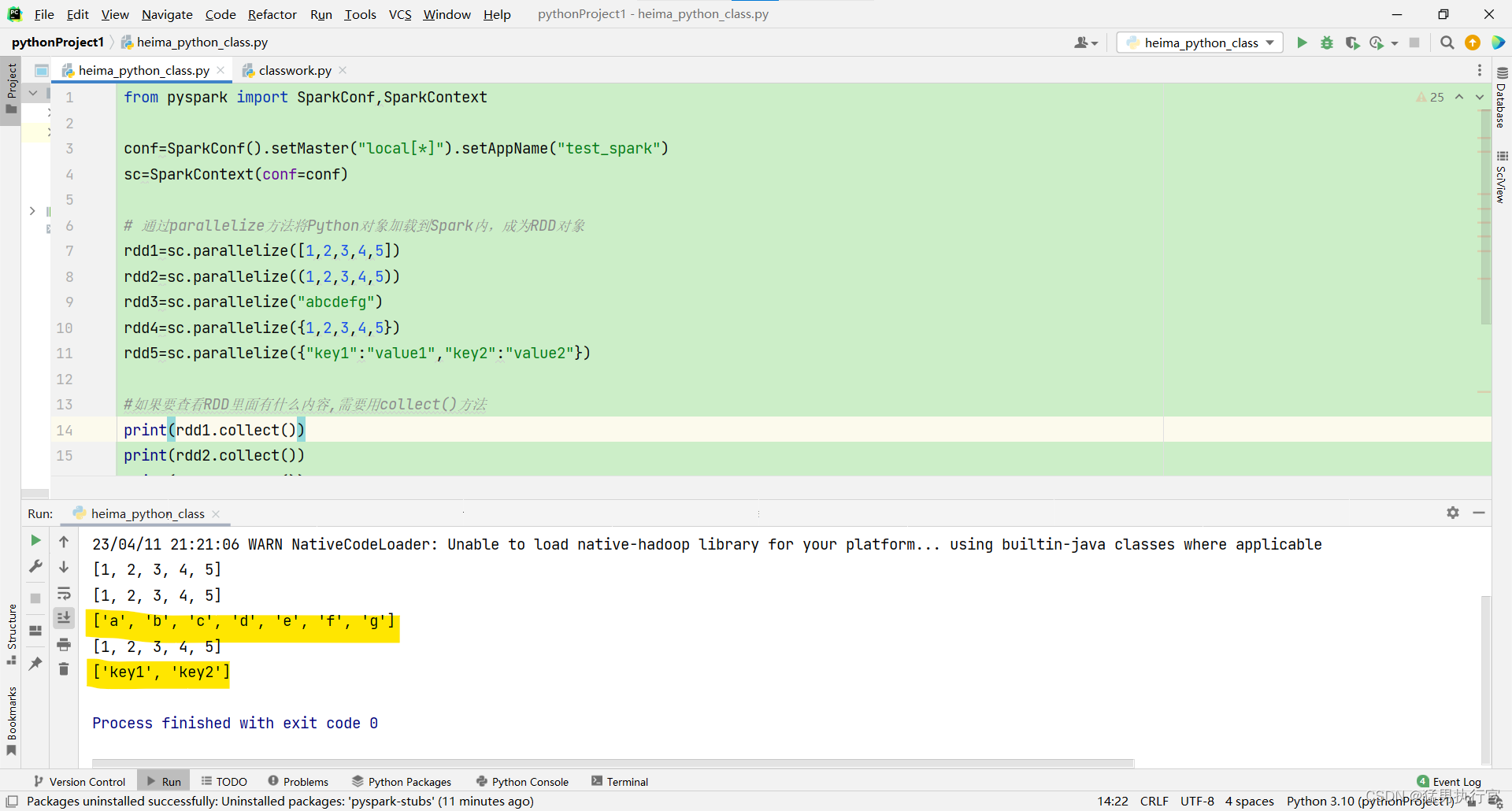
from pyspark import SparkConf,SparkContext
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize((1,2,3,4,5))
rdd3=sc.parallelize("abcdefg")
rdd4=sc.parallelize({1,2,3,4,5})
rdd5=sc.parallelize({"key1":"value1","key2":"value2"})
#如果要查看RDD里面有什么内容,需要用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
sc.stop()注意:字符串返回的是['a','b','c','d','e','f','g'] 字典返回的是['key1','key2']
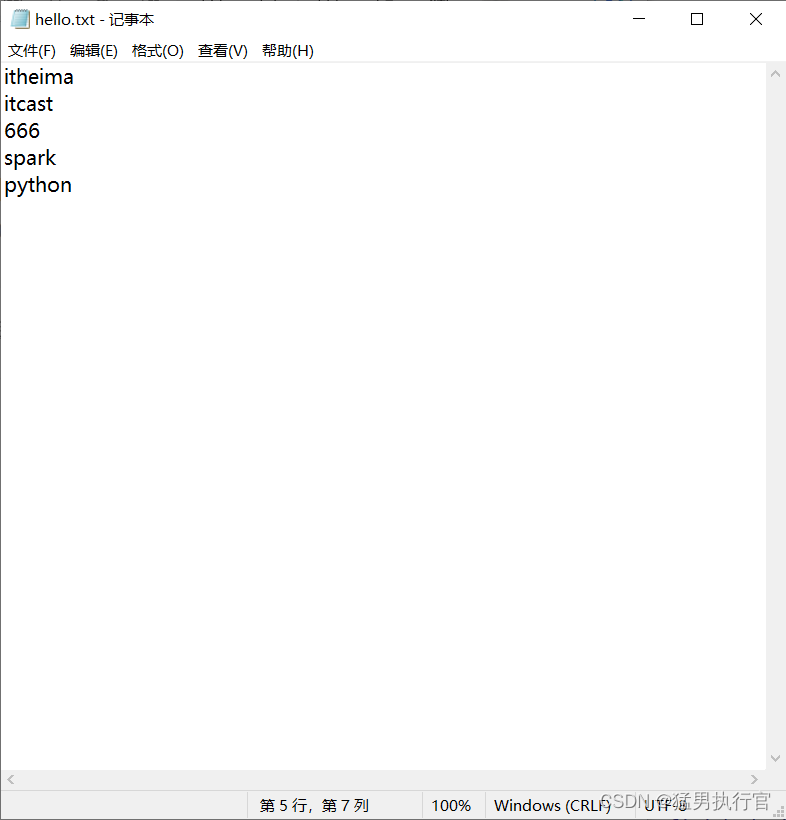
读取hello.txt的内容:
from pyspark import SparkConf,SparkContext
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# # 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
# rdd1=sc.parallelize([1,2,3,4,5])
# rdd2=sc.parallelize((1,2,3,4,5))
# rdd3=sc.parallelize("abcdefg")
# rdd4=sc.parallelize({1,2,3,4,5})
# rdd5=sc.parallelize({"key1":"value1","key2":"value2"})
#
# #如果要查看RDD里面有什么内容,需要用collect()方法
# print(rdd1.collect())
# print(rdd2.collect())
# print(rdd3.collect())
# print(rdd4.collect())
# print(rdd5.collect())
#用textFile方法,读取文件数据加载到Spark内,成为RDD对象
rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/hello.txt")
print(rdd.collect())
sc.stop()
3、数据计算-map方法
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# 准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#通过map方法将全部数据都乘以10
def func(data):
return data*10
rdd2=rdd.map(func) #(T) -> U
#(T) -> T
print(rdd2.collect())
#链式调用
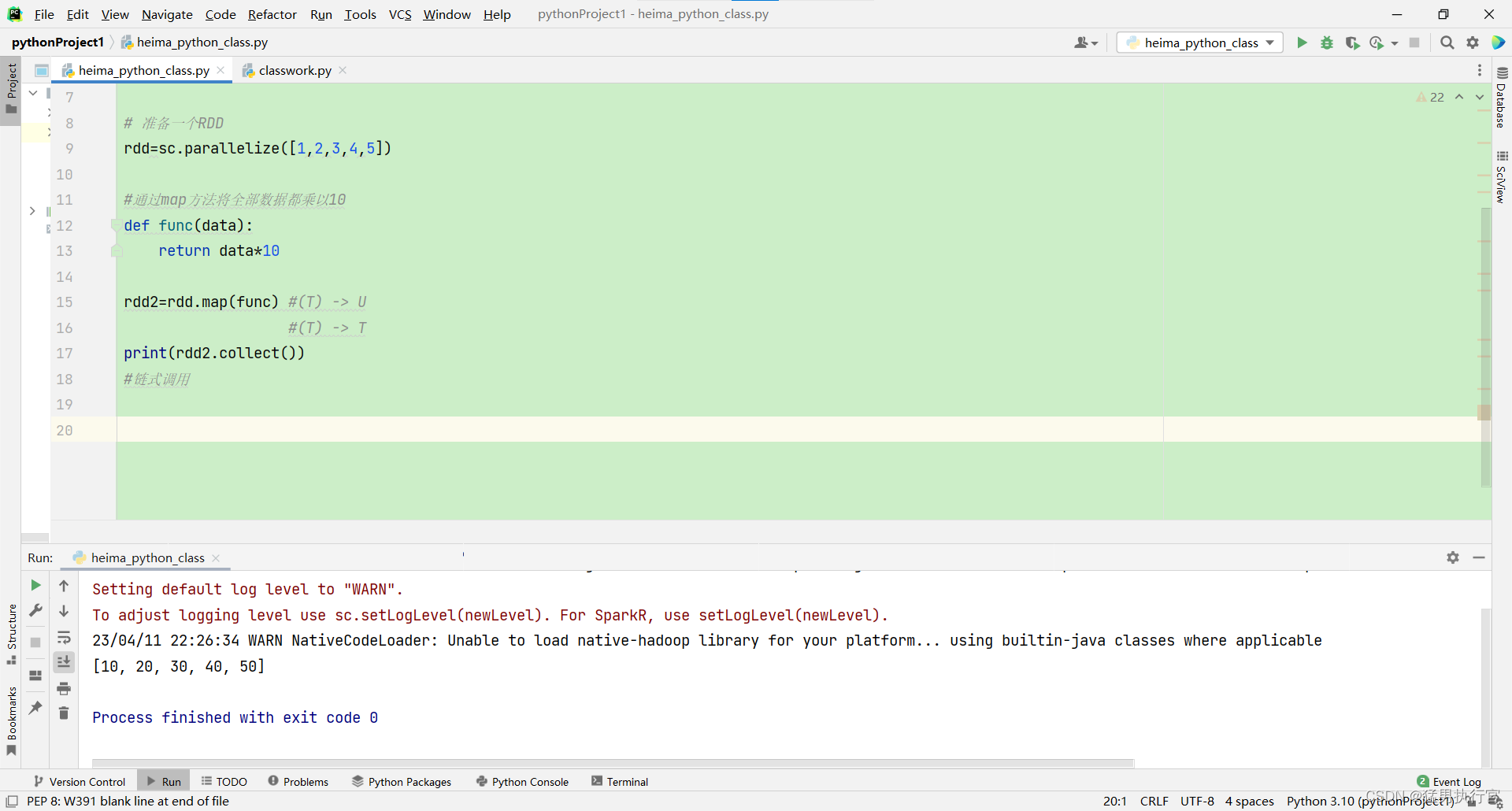
注意:
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置如果没有添加上行代码程序会报出错误!
Caused by: org.apache.spark.SparkException: Python worker failed to connect back.

解释器的位置: (是在电脑中安装的位置)
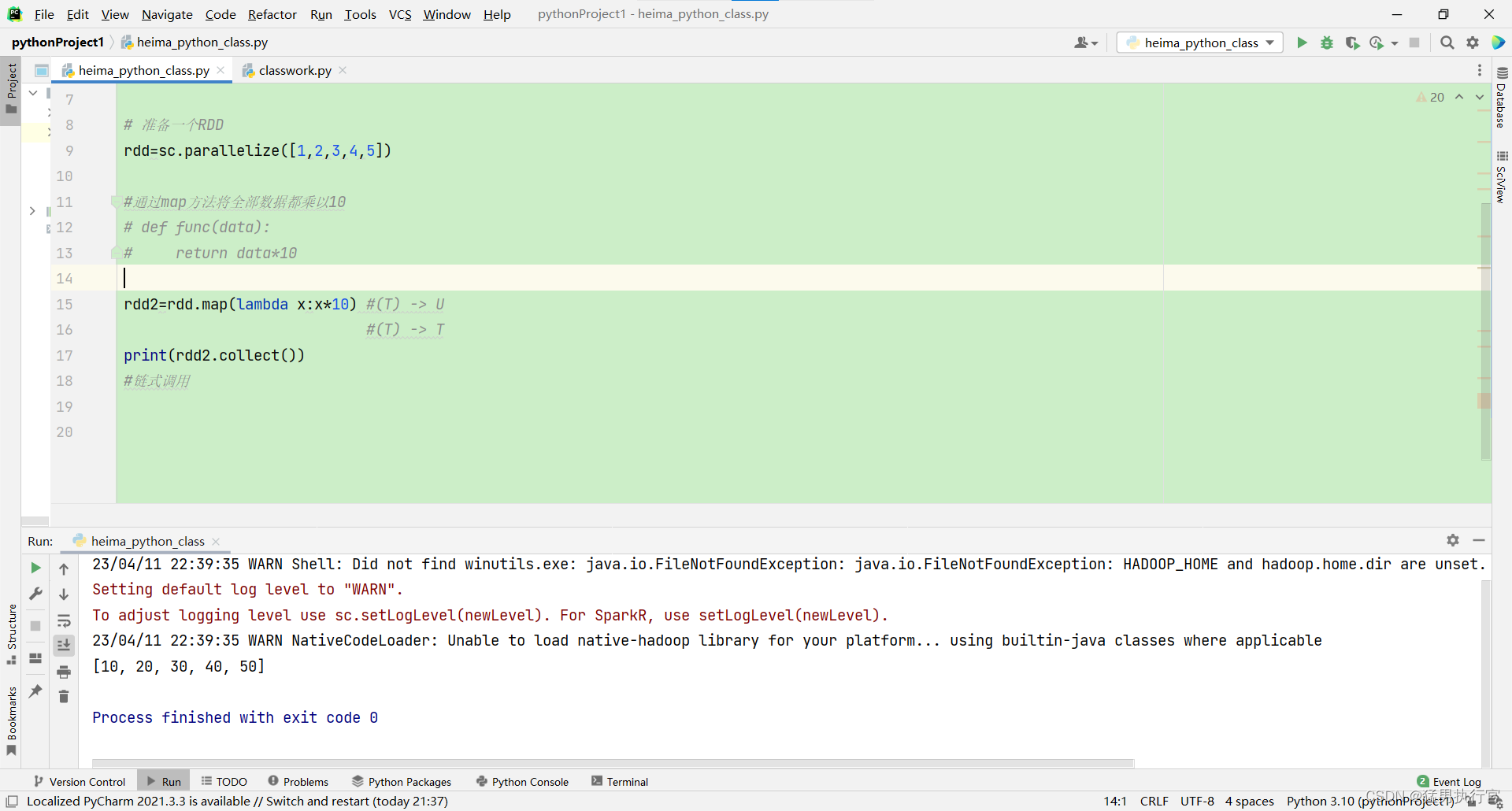
代码中:
def func(data):
return data*10可以替换成lambda
rdd2=rdd.map(lambda x:x*10)完整代码:
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# 准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#通过map方法将全部数据都乘以10
# def func(data):
# return data*10
rdd2=rdd.map(lambda x:x*10) #(T) -> U
#(T) -> T
print(rdd2.collect())
#链式调用
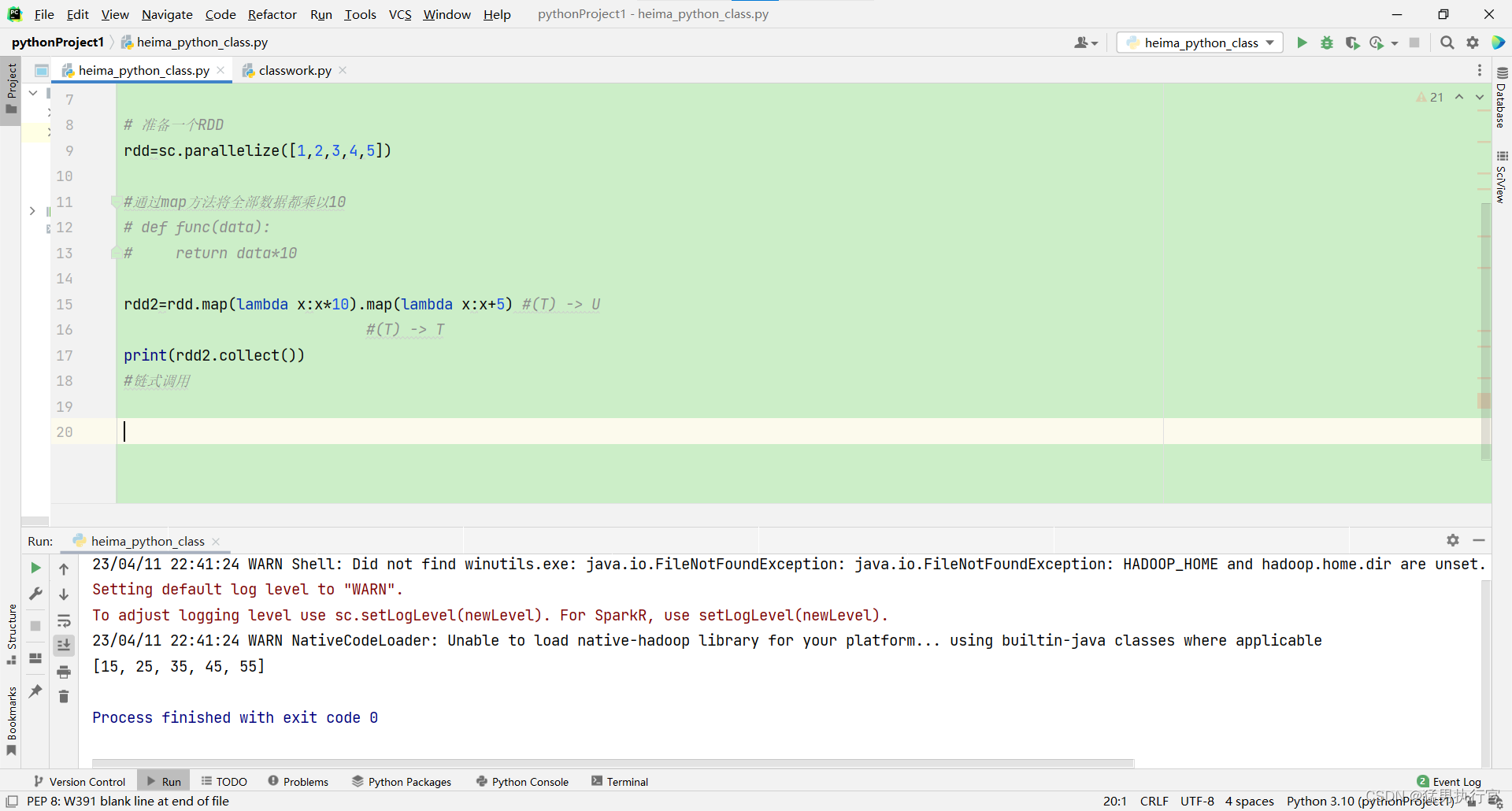
链式调用 可以直接使用.的方式
rdd2=rdd.map(lambda x:x*10).map(lambda x:x+5)完整代码:
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# 准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#通过map方法将全部数据都乘以10
# def func(data):
# return data*10
rdd2=rdd.map(lambda x:x*10).map(lambda x:x+5) #(T) -> U
#(T) -> T
print(rdd2.collect())
#链式调用
5、flatMap方法
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# 准备一个RDD
rdd=sc.parallelize(["itheima itcast 666","itheima itheima it cast","python itheima"])
#需求,将RDD数据里面的一个个单词提取出来
rdd2=rdd.map(lambda x:x.split(" "))
rdd1=rdd.flatMap(lambda x:x.split(" "))
print(rdd1.collect())
print(rdd2.collect())flatMap算子
计算逻辑和map一样
可以比map多出,接触一层嵌套的功能

6、 reduceByKey算子
reduceBeKey中的聚合逻辑是:
[1,2,3,4,5] 然后聚合函数:lambda a,b:a+b
a b
1+2=3
3+3=6
6+4=10
10+5=15
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd =sc.parallelize([('男',99),('男',88),('女',99),('女',66)])
# 求男生和女生两组的成绩之和
rdd2=rdd.reduceByKey(lambda a,b:a+b)
print(rdd2.collect())
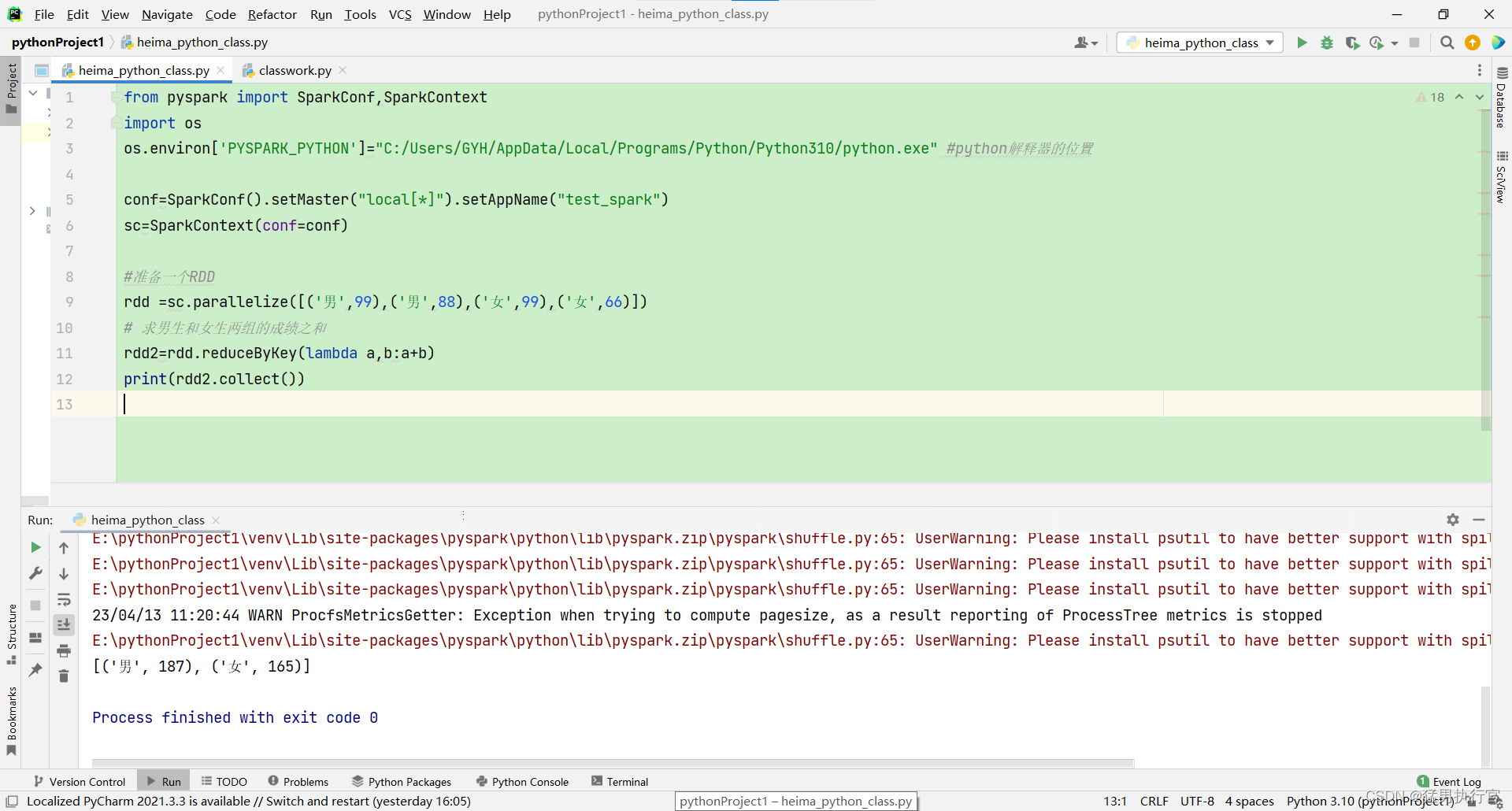
出现: UserWarning: Please install psutil to have better support with spilling
在cmd中 pip install psutil 即可
7、数据计算练习案例
要求:
# 完成单词计数统计 # 1.构建执行环境入口对象 # 2.读取数据文件 # 3.取出全部单词 # 4.将所有单词都转换为二元元组,单词为Key value 设置为1 # 5.分组并求和 # 6.打印输出
# 完成单词计数统计
# 1.构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#2.读取数据文件
rdd=sc.textFile("C:/Users/GYH\Desktop/data/pyspark_heima/hello.txt")
#3.取出全部单词
word_rdd=rdd.flatMap(lambda x:x.split(" "))
# print(word_rdd.collect())
#4.将所有单词都转换为二元元组,单词为Key value 设置为1
word_with_one_rdd=word_rdd.map(lambda word:(word,1))
# print(word_with_one_rdd.collect())
#5.分组并求和
result=word_with_one_rdd.reduceByKey(lambda a,b:a+b)
#6打印输出
print(result.collect())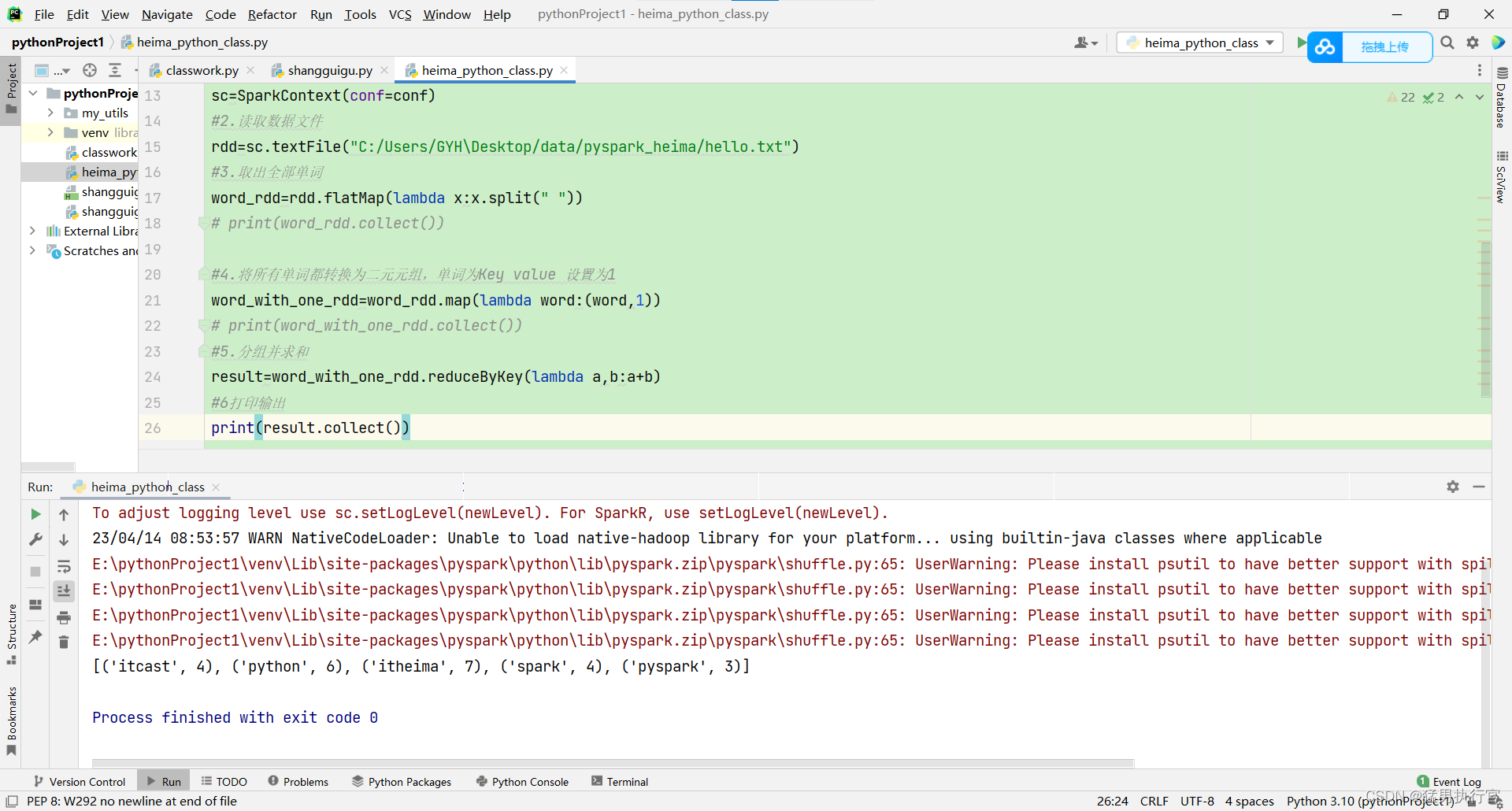
8、filter方法
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
# 对RDD的数据进行过滤
rdd2=rdd.filter(lambda num:num%2==0)
print(rdd2.collect())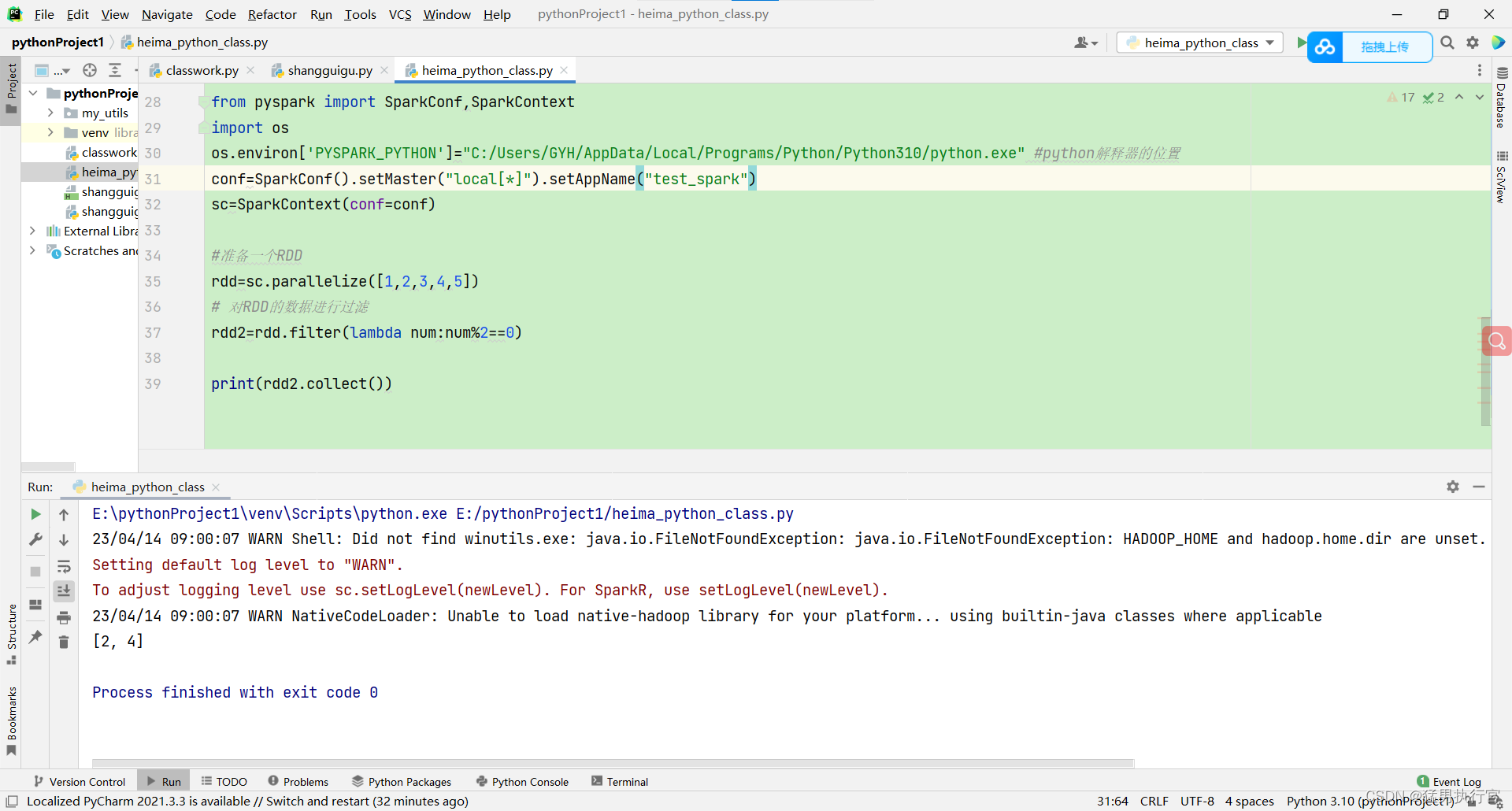
9、distinct方法
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd=sc.parallelize([1,1,3,3,5,5,7,8,8,9,10])
#对RDD的数据进行去重
rdd2=rdd.distinct()
print(rdd2.collect()) 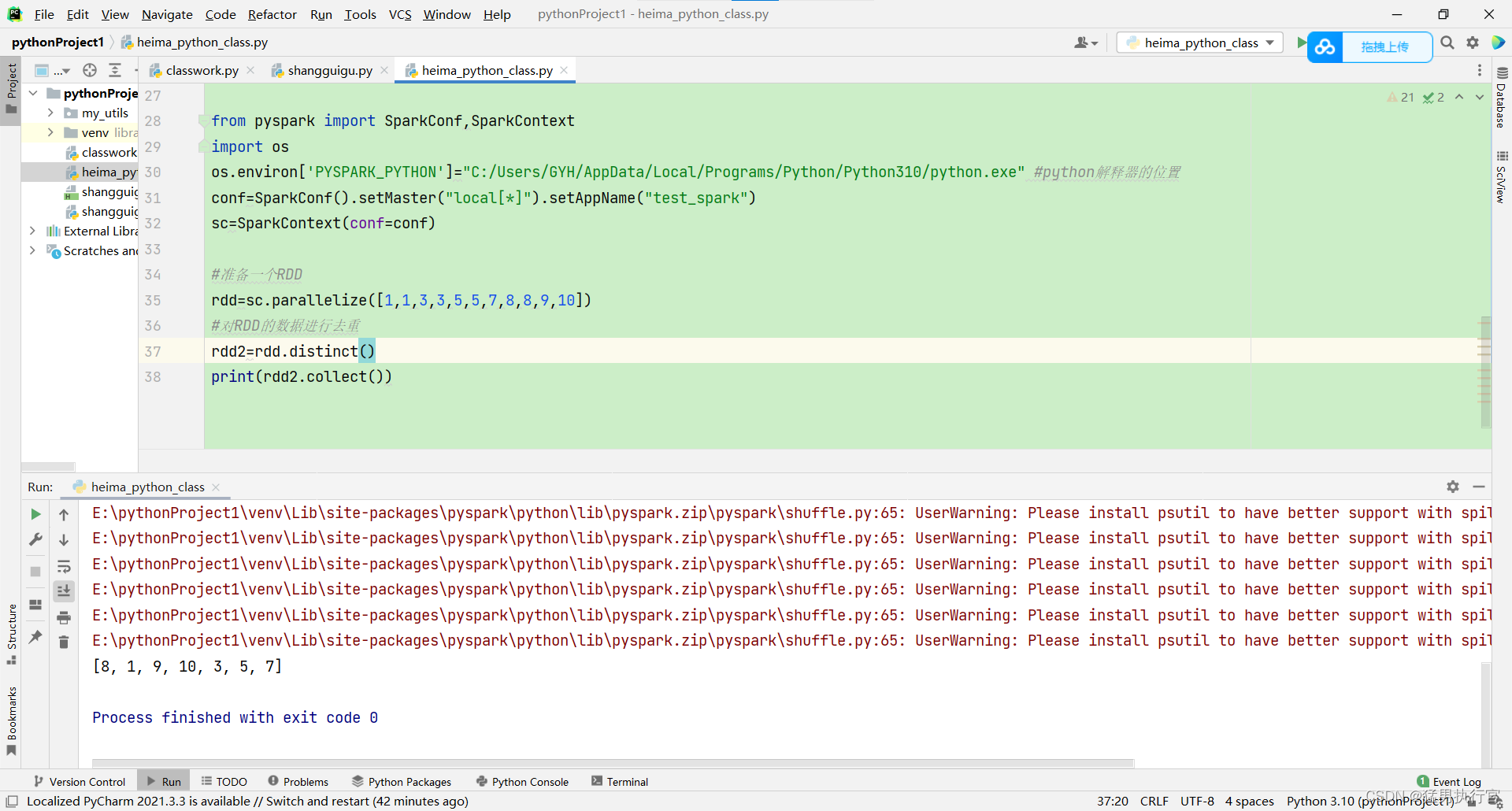
10、sortBy方法
rdd.sortBy(func,ascending=Flase,numPartition=1)
#func(T)-->U:告知按照rdd中的哪一个数据进行排序,比如lambda x:x[1]表示按照rdd中的第二列元素进行排序
#ascending True升序 Flase降序
#numPartitions:用多少分区排序
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#1.读取文件
rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/hello.txt")
#2.取出全部单词
word_rdd=rdd.flatMap(lambda x:x.split(" "))
#3.将所有单词都转换为二元元组,单词为Key,value设置为1
word_with_one_rdd=word_rdd.map(lambda word:(word,1))
#4.分组并求和
ressult_rdd=word_with_one_rdd.reduceByKey(lambda a,b:a+b)
print(ressult_rdd.collect())
#5.对结果进行排序
final_rdd=ressult_rdd.sortBy(lambda x:x[1],ascending=False,numPartitions=1)
print(final_rdd.collect())
11、数据计算-练习案例2
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
# TODO 需求1 城市销售额排名
# 1.1 读取文件到RDD
file_rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/orders.txt")
# 1.2 取出一个JSON字符串
json_str_rdd=file_rdd.flatMap(lambda x:x.split("|"))
# print(json_str_rdd)
# 1.3 将一个个JSON字符串转换为字典
dict_rdd=json_str_rdd.map(lambda x:json.loads(x))
print(dict_rdd.collect())
# 1.4 取出城市和销售数据
# (城市,销售额)
city_with_money_rdd=dict_rdd.map(lambda x:(x['areaName'],int(x['money'])))
# 1.5 按城市分组按销售聚合
city_result_edd=city_with_money_rdd.reduceByKey(lambda a,b:a+b)
# 1.6 按销售额聚合结果进行排序
result1_rdd=city_result_edd.sortBy(lambda x:x[1],ascending=False,numPartitions=1)
print(f"需求1的结果是{result1_rdd.collect()}")
# TODO 需求2:取出城市有哪些商品类别在销售
# 2.1 取出全部的商品类别
category_rdd=dict_rdd.map(lambda x:x['category']).distinct()
print(f"需求2的结果{category_rdd.collect()}")
#2.2 对全部商品类别进行去重
# TODO 需求3
# 3.1过滤北京市的数据
beijing_data_rdd=dict_rdd.filter(lambda x:x['areaName']=='北京')
# 3.2 取出全部商品类别
result3_rdd=beijing_data_rdd.map(lambda x:x['category']).distinct()
print(f"需求3的结果:{result3_rdd.collect()}")
# 3.3 进行商品类别去重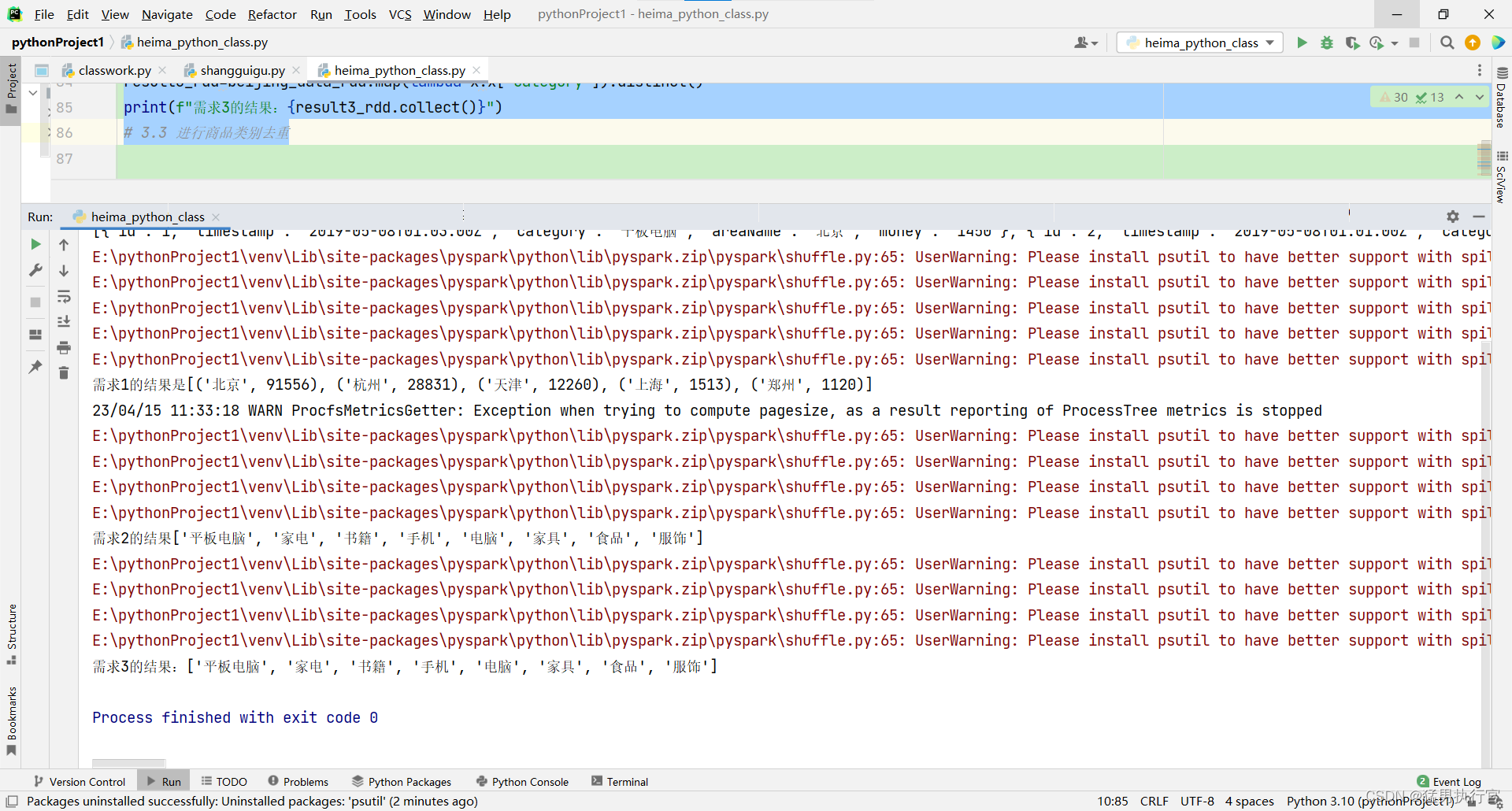
#12、输出为Python对象
数据输出的方法
collect 将RDD内容转换为list
reduce 对RDD内容进行自定义聚合
take 取出RDD的前N个元素组成list
count 统计RDD元素个数
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备RDD
rdd=sc.parallelize([1,2,3,4,5])
# collect算子,输出RDD为list的对象
rdd_list:list=rdd.collect()
print(rdd_list)
print(type(rdd_list))
# reduce 算子,对RDD进行两两聚合
num=rdd.reduce(lambda a,b:a+b)
print(num)
# take算子,取出RDD前N个元素,组成list返回
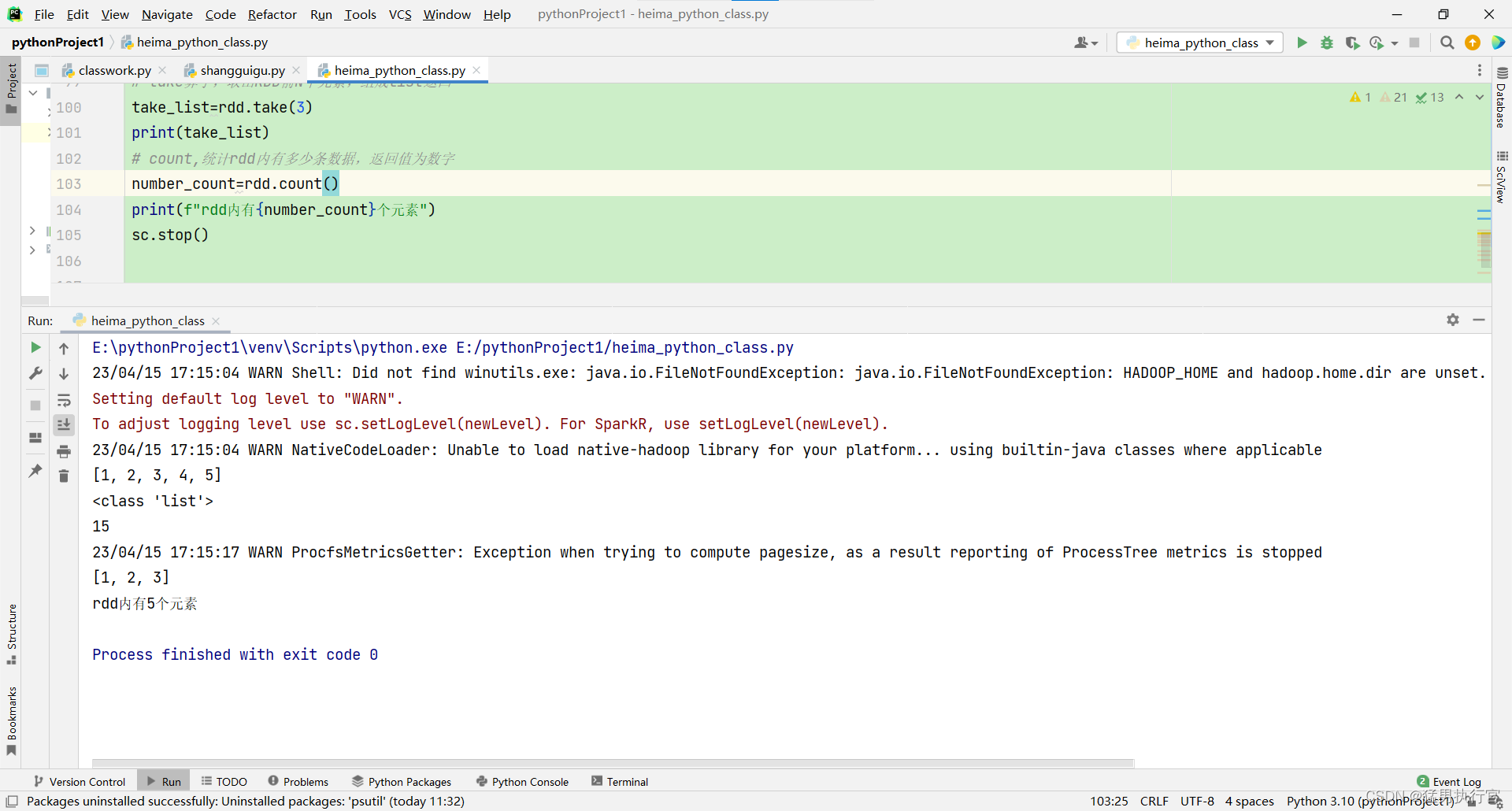
take_list=rdd.take(3)
print(take_list)
# count,统计rdd内有多少条数据,返回值为数字
number_count=rdd.count()
print(f"rdd内有{number_count}个元素")
sc.stop()
#13、数据输出到文件中
1、下载hadoop3.3.0压缩包
百度网盘:链接:https://pan.baidu.com/s/1y4a2w4D8zCzYKEDY9aPWtw
提取码:1234
hadoop3.3.0解压到任意位置即可
2、将haoop3.3.0的bin文件夹下的 hadoop.dll 复制到C:\Windows\System32中
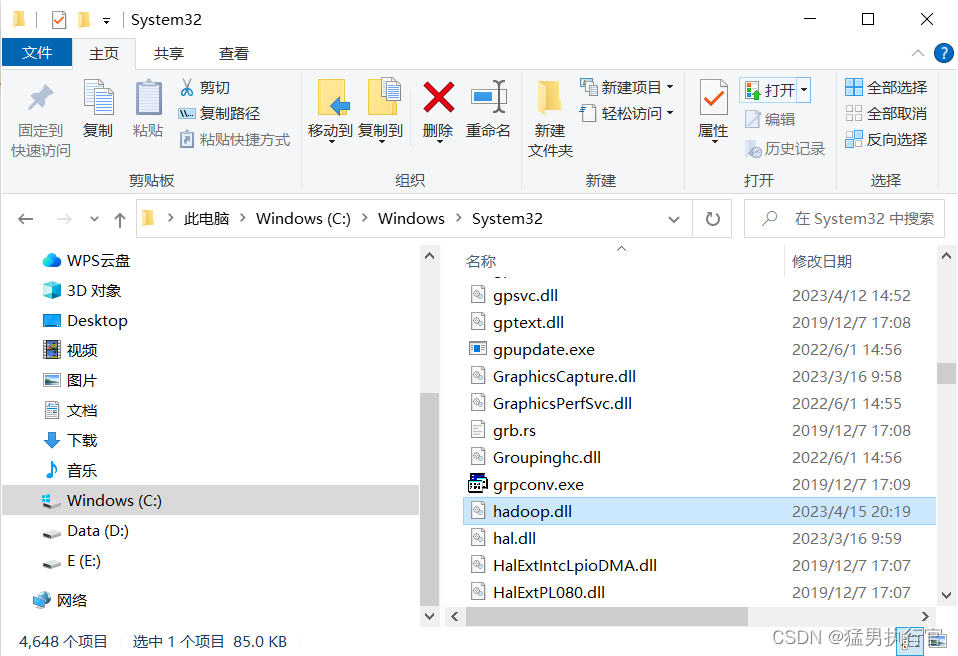
在pycharm中添加如下代码
os.environ['HADOOP_HOME']="E:/spark/hadoop-3.3.0"运行后成功写入:
14、综合案例
读取文件转换成RDD,并完成:
打印输出:热门搜索时间段(小时精度)Top3
打印输出:统计黑马程序员关键字在哪个时段被搜索最多
将数据转换为JSON格式,写出文件
1、热门搜索时间段(小时精度)Top3
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON']="C:/Users/GYH/AppData/Local/Programs/Python/Python310/python.exe" #python解释器的位置
os.environ['HADOOP_HOME']="E:/spark/hadoop-3.3.0"
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set("spark.default.parallelism","1")
sc=SparkContext(conf=conf)
# 读取文件转换成RDD
# TODO 需求1:热门城市时间段TOP3(小时精度)
file_rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/SogouQ.txt")
#1.1取出全部时间并转换为小时
#1.2转换为(小时,1)的二元元组
#1.3Key分组聚合Value
#1.4排序(降序)
#1.5取前3
result1=file_rdd.map(lambda x:x.split("\t")).\
map(lambda x:x[0][:2]).\
map(lambda x:(x,1)).\
reduceByKey(lambda a,b:a+b).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(3)
print(f"需求1的结果:{result1}")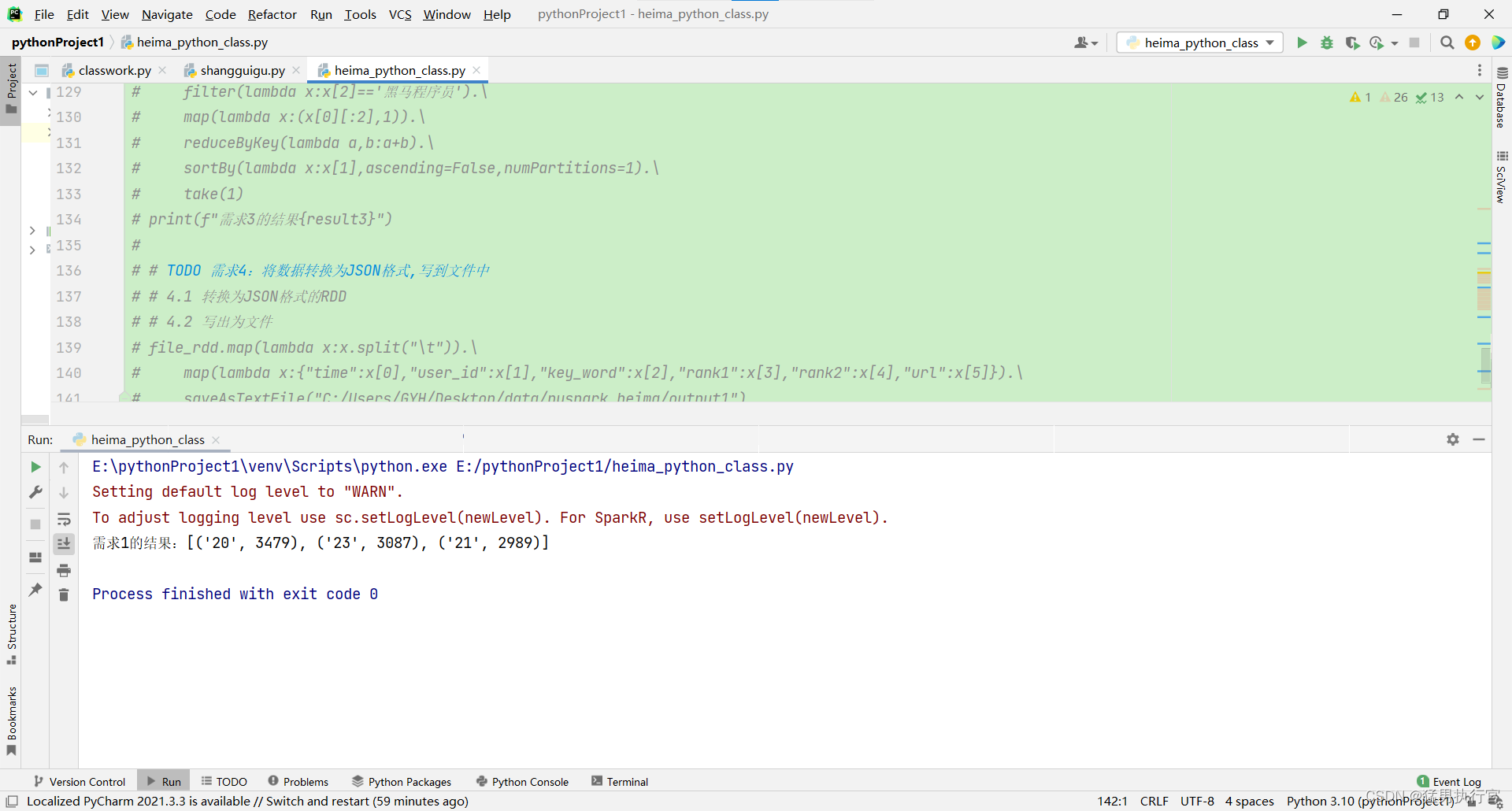
# TODO 需求2:热门搜索词TOP3
# TODO 需求2:热门搜索词TOP3
# 2.1 取出全部搜索词
# 2.2 (词,1) 二元元组
# 2.3 分组聚合
# 2.4 排序
# 2.5 TOP3
file_rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/SogouQ.txt")
result2=file_rdd.map(lambda x:x.split('\t')).\
map(lambda x:x[2]).\
map(lambda x:(x,1)).\
reduceByKey(lambda a,b:a+b).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(3)
print(f"需求2的结果:{result2}")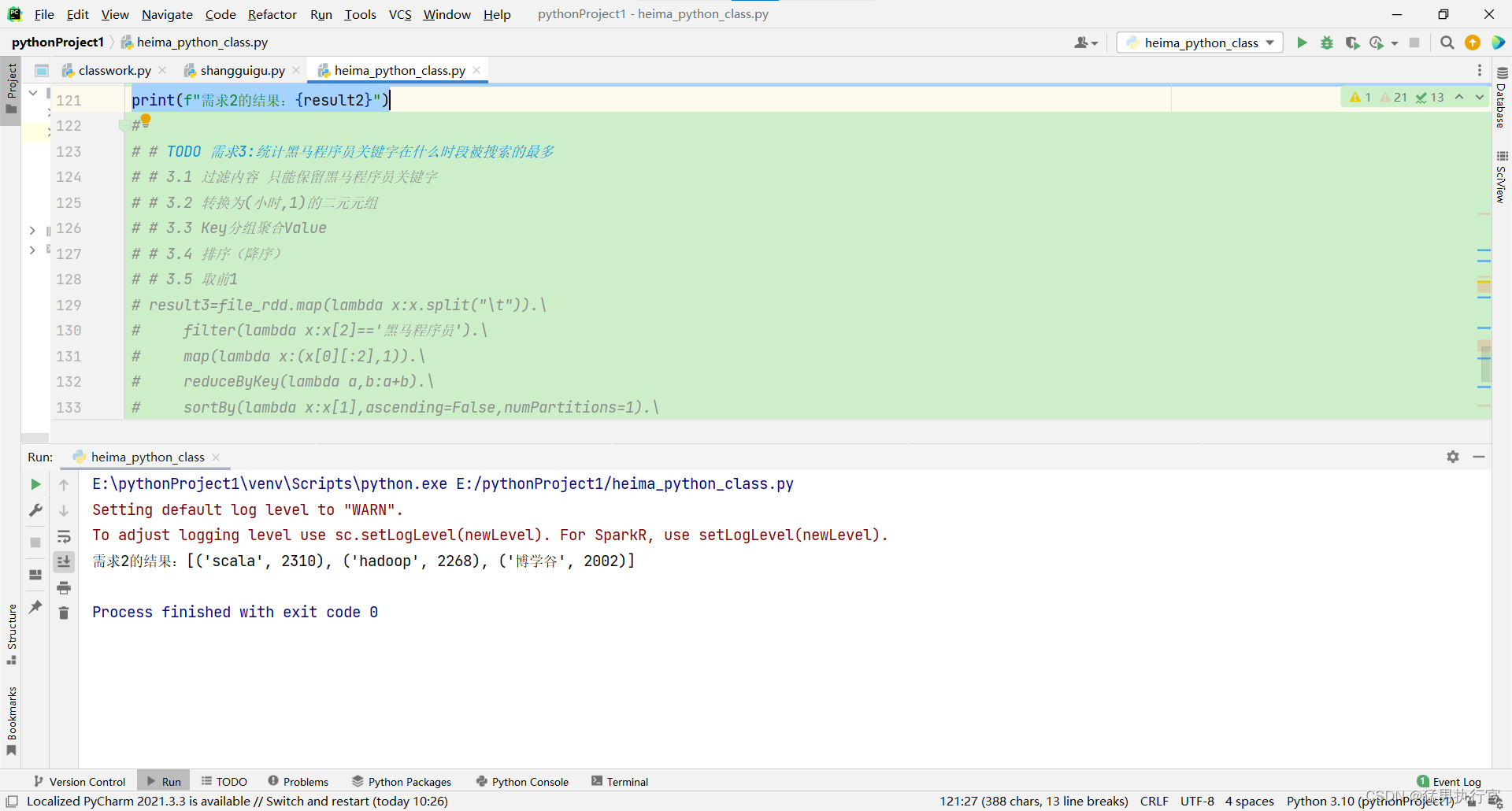
# TODO 需求3:统计黑马程序员关键字在什么时段被搜索的最多
# TODO 需求3:统计黑马程序员关键字在什么时段被搜索的最多
# 3.1 过滤内容 只能保留黑马程序员关键字
# 3.2 转换为(小时,1)的二元元组
# 3.3 Key分组聚合Value
# 3.4 排序(降序)
# 3.5 取前1
file_rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/SogouQ.txt")
result3=file_rdd.map(lambda x:x.split("\t")).\
filter(lambda x:x[2]=='黑马程序员').\
map(lambda x:(x[0][:2],1)).\
reduceByKey(lambda a,b:a+b).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(1)
print(f"需求3的结果{result3}")# TODO 需求4:将数据转换为JSON格式,写到文件中
# TODO 需求4:将数据转换为JSON格式,写到文件中
file_rdd=sc.textFile("C:/Users/GYH/Desktop/data/pyspark_heima/SogouQ.txt")
# 4.1 转换为JSON格式的RDD
# 4.2 写出为文件
file_rdd.map(lambda x:x.split("\t")).\
map(lambda x:{"time":x[0],"user_id":x[1],"key_word":x[2],"rank1":x[3],"rank2":x[4],"url":x[5]}).\
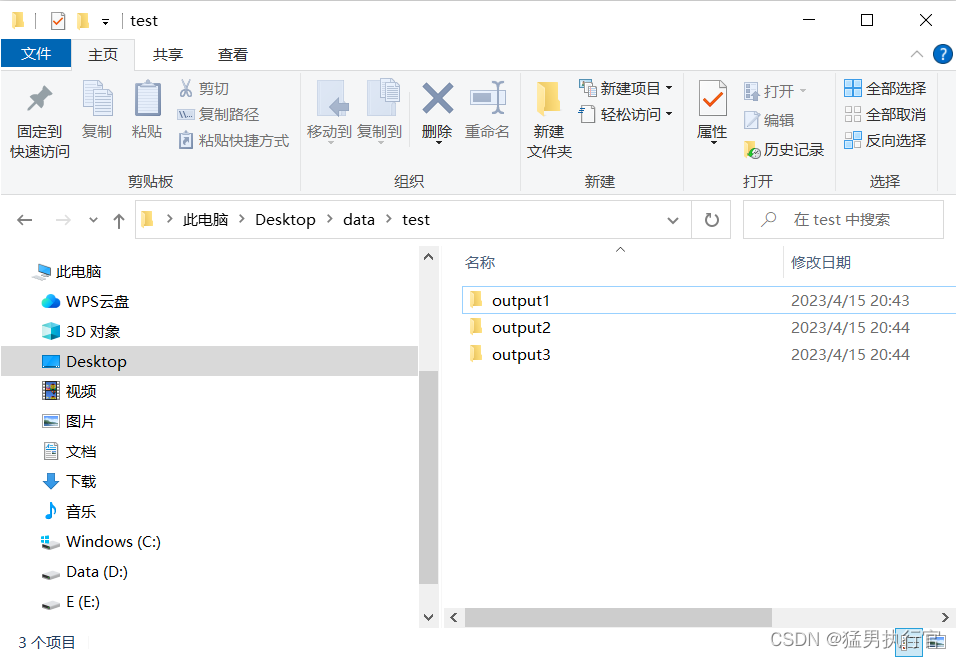
saveAsTextFile("C:/Users/GYH/Desktop/data/pyspark_heima/output1_JSON")打开output1_JSON文件夹下的part_00000
成功写入:
















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









