






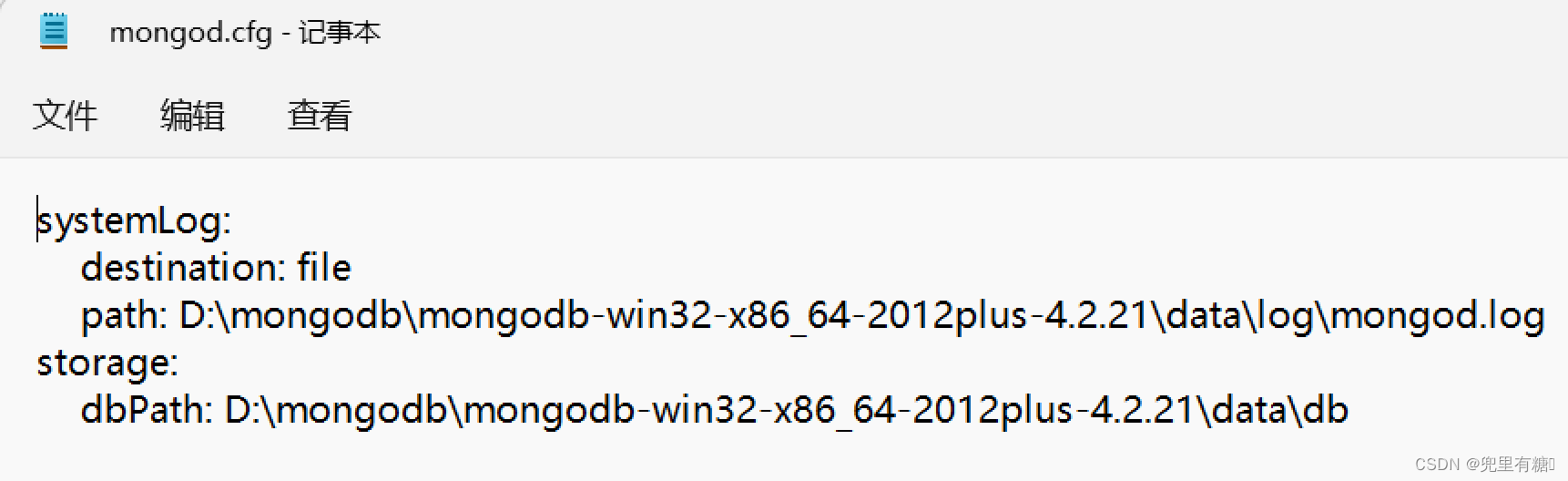
编辑配置文件mongod.cfg
1. 数据库操作
// 创建数据库 mydyh
use mydyh //如果数据库不存在,则创建数据库,否则切换到指定数据
// 查看所有数据库
show dbs //dbs是databases的简称
// db:表示当前数据库对象
// 执行“db”命令,查看当前数据库,需要先切换到指定数据库
// 查看某个数据库的具体统计信息
db.stats( ) //对某个数据库进行操作之前,一定要用use切换至数据库
// 删除当前数据库
db.dropDatabase()2. 集合操作
// 创建集合myCollection
db.createCollection("myCollection")
// 查看是否成功创建集合
show collections
// 创建一个固定集合newcollection,整个集合空间大小5000000KB,文档最大个数为1000个
db.createCollection("newcollection",{capped:true,size:5000000,max:1000})
// 对集合进行重命名
db.myCollection.renameCollection("newcollcetion") // 对集合myCollection重命名为 newcollection
// 删除集合
db.myCollection.drop()
3. 文档的插入、更新与删除操作
文档的插入
// 单文档插入
db.myCollection.insert(document)
db.myCollection.save(document)
// 注意: insert()和save()方法的区别在于,若使用insert()方法插入文档时,集合中已存在该文档,则会报错。若使用save()方法插入文档时,集合中已存在该文档,则会覆盖。
// 多文档插入
db.myCollection.insertMany([document1,document2,...]) // ([document1,document2,...])是有多文档组成的数组。文档的更新
db.myCollection.update(
<query>,
<update>,
{
upsert:<boolean>,
multi:<boolean>
writeConcern:<document>
}
)
//such as
// 将_id为6的contect的值由“123456”更新为“666”,具体命令如下。
db.myCollection.update({“_id":“6"}, {$set:{"content":"666"}})
// 查看集合中所有文档,验证是否更新成功
db.myCollection.find()
// 多个文档更新
// 将userid为“1005” 的nickname修改为“朱丽叶”
db.myCollection.update({userid:"1005"},{$set:{nickname:"朱丽叶"}},{multi:true})
// 插入字段
// 将userid为“1005” 的文档中插入字段QQ
db.myCollection.update({userid:"1005"},{$set:{QQ:"11111111"}},{multi:true})
// 删除字段
// 将userid为“1005” 的文档中的字段QQ删除。
db.myCollection.update({userid:"1005"},{$unset:{QQ:1}},{multi:true})
// 内嵌文档更新
// 将userid为“1006” 的文档中的mobilePhone修改为“1234567890”
db.myCollection.update({userid:"1006"},{$set:{"phone.mobilePhone":"1234567890"}})
// 数组更新
// 修改userid为“1006”的第二个爱好为“看电影”
db.myCollection.update({"userid":"1006"},{$set:{"hobby.1":"movie"}})

文档的删除
db.myCollection名.deleteMany({}) //删除所有文档
db.myCollection名.remove({})
// 删除集合comment中键nickname为“爱德华”的文档
db.myCollection.remove({"nickname":"爱德华"})
// 查看集合中所有文档,验证文档是否删除成功
db.myCollection.find()
// 删除集合comment中全部文档
db.myCollection.remove({})
4. 文档的简单查询
// 查看集合myCollection中所有文档
db.myCollection.find() 或 db.myCollection.find({})
// 以格式化的方式查看集合comment中所有文档
db.myCollection.find().pretty()
1) 与操作符($and)
// 查询集合comment中同时满足userid为1005和likenum为2000的文档
db.comment.find({"userid":"1005","likenum":2000})
或
db.comment.find({$and:[{"userid":"1005“},{"likenum":2000}]})
2) 或操作符($or)
// 查询集合comment中userid为1002或userid为1003的文档
db.comment.find({$or:[{"userid":"1002"},{"userid":"1003"}]})
3) 包含操作符($in)
// 查询集合comment中userid为1002或userid为1003的文档
db.comment.find({"userid":{$in:["1002","1003"]}})
4) 不包含操作符($nin)
// 查询集合comment中userid不为1002和1003的文档
db.comment.find({"userid":{$nin:["1002","1003"]}})
5) Null类型查询:用于查询集合中字段值为Null的文档
db.comment.find({<key>:null})
// 查询集合comment中字段state为null的文档
db.comment.find({state:null})
6) 正则表达式查询:用于查询集合中符合某个规则的文档
db.comment.find({<key>:/正则表达式/})
// 查询集合comment中评论内容content值包含“夏天” 的文档
db.comment.find({“content”:/夏天/}).pretty()
// 查询集合comment中评论内容content值以“夏天”开头 的文档
db.comment.find({“content”:/^夏天/}).pretty()
// 查询集合comment中评论内容content值以“开水”结尾 的文档
db.comment.find({“content”:/开水$/}).pretty()
7) 嵌套文档查询之精确查询:用于集合中指定子文档,查询符合的文档
db.comment.find({<key>:{<key1>:<value1>,<key2>:<value2>}})
// 查询集合comment中包含子文档homePhone和mobilePhone且值分别为123456、654321的文档
db.comment.find({"phone":{"homePhone":"123456","mobilePhone":"654321"}}).pretty()
8) 嵌套文档查询之点查询:用于集合中指定子文档中一个字段,查询包含该字段的文档
db.comment.find({<key>.<key1>:<value1>})
// 查询集合comment中包含子文档homePhone且值为1234的文档
db.comment.find({"phone.homePhone":"1234"}).pretty()
9) 数组查询
// 查询兴趣是“reading”,“movie”,“swimming” 的用户的userid及nikename
db.comment.find({hobby:["reading","movie","swimming"]},{userid:1,nickname:1})
// 查询兴趣中有“movie”这一项的用户的userid及nikename
db.comment.find({hobby:"movie"},{userid:1,nickname:1})
// 查询喜欢“reading”和“movie”的用户的userid及nikename
db.comment.find({hobby:{$all:["reading","movie"]}},{userid:1,nickname:1})
// 查询喜欢“reading”或“movie”的用户的userid及nikename
db.comment.find({hobby:{$in:["reading","movie"]}},{userid:1,nickname:1})
// 查询兴趣爱好有三个的用户的userid及nikename
db.comment.find({hobby:{$size:3}},{userid:1,nickname:1}) 
5. 聚会操作
聚合管道操作 : 聚合管道操作是将文档在一个管道处理完毕后,把处理的结果传递给下一个管道进行再次处理。聚合管道是使用不同的管道阶段操作器进行不同聚合操作,管道阶段操作器也可称为管道操作符。
db.COLLECTION_NAME.aggregate([{ },{ },{ }…{ }])
// db:当前数据库对象;
// COLLECTION_NAME:当前集合对象;
// aggregate([{ },{ }…]):用户聚合查询所有文档的方法,该方法中的数据参数表示管道操作,数组中的每个文档都表示一种管道操作
常见管道操作符如下表:
// 使用$limit操作符,展示集合comment中前三个文档
db.comment.aggregate([{$limit:3}]).pretty()
// 使用$match操作符,将集合comment中键nickname的值为罗密欧的文档查询出来
db.comment.aggregate({$match:{nickname:"罗密欧"}}).pretty()
// 使用$sort操作符,将集合comment中的文档按照键age的值进行降序排序
db.comment.aggregate([{$sort:{age:-1}}]).pretty() // -1表示降序,1表示升序。
// 使用$project操作符,展示集合comment中的文档,并且文档均不包含字段_id
db.comment.aggregate([{$project:{_id:0}}]).pretty()
// 使用$project操作符,展示集合comment中的文档,将文档中的字段phone修改为contact
db.comment.aggregate({$project:{contact:"$phone"}}).pretty()
// 使用$skip操作符,展示集合comment中的_id为5、6的文档 (comment中一共六个文档)
db.comment.aggregate([{$skip:4}]).pretty()
// 使用$group操作符,将集合comment中的文档按userid进行分组
db.comment.aggregate([{$group:{_id:"$userid"}}]).pretty()
管道阶段操作器的值被称为管道表达式,并且每个管道表达式都是一个文档结构,由字段名称、字段值和管道表达式组成。常见的管道表达式如下表

// 使用$sum表达式,将集合product中的文档按类型type进行分组并计算各个分组的价格price总和
db.product.aggregate({$group:{_id:"$type",pricesum:{$sum:"$price"}}}).pretty()
// 使用$avg表达式,将集合product中的文档按类型type进行分组,并计算各个分组的价格price平均值
db.product.aggregate({$group:{_id:"$type",priceavg:{$avg:"$price"}}}).pretty()
//使用$min表达式,将集合product中的文档按类型type进行分组,并计算各个分组中价格price最小值
db.product.aggregate({$group:{_id:"$type",pricemin:{$min:"$price"}}}).pretty()
// 使用$max表达式,将集合product中的文档按类型type进行分组,并计算各个分组中价格price最大值
使用$max表达式,将集合product中的文档按类型type进行分组,并计算各个分组中价格price最大值
// 使用$push表达式,将集合product中的文档按类型type进行分组,并将各个分组的产品插入到一个数组tags中
db.product.aggregate({$group:{_id:"$type",tags:{$push:"$name"}}}).pretty()
// 使用$first表达式,将集合product中的文档按类型type进行分组,并获取各个分组中第一个产品
db.product.aggregate({$group:{_id:"$type",product:{$first:"$name"}}}).pretty()
// 使用$last表达式,将集合product中的文档按类型type进行分组,并获取各个分组中最后一个产品
db.product.aggregate({$group:{_id:"$type",product:{$last:"$name"}}}).pretty()
6. 索引操作
// 查询数据库中集合comment的索引
db.comment.getIndexes()
// 查询数据库中集合comment的索引大小
db.comment.totalIndexSize()
// 在集合comment的字段userid上创建单字段索引,并指定顺序为升序
db.comment.createIndex({userid:1})
// 在集合comment的字段articleid和字段userid上创建复合索引,指定字段articleid 为升序,字段userid为降序。
db.comment.createIndex({articleid:1, userid:-1})
// 查询集合comment中的索引。
db.comment.getIndexes()
// 删除单个索引
db.COLLECTION_NAME.dropIndex(index) // 参数index,其数据类型为字符串或文档,可用于指定要删除的索引。
// 删除集合comment字段userid上的单字段索引。
db.comment.dropIndex({userid:1})
// 删除所有索引
db.COLLECTION_NAME.dropIndexes()















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









