









目录
正文:
1.算法效率
一般情况下衡量一个算法的好坏是从时间和空间两个维度来衡量的。
时间复杂度主要衡量一个算法的运行快慢,空间复杂度主要衡量一个算法运行需要的额外空间。
2.时间复杂度
2.1 时间复杂度的概念
在计算机科学中算法的时间复杂度是一个函数,一个算法所花费的时间与其中语句的执行次数成比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
同时请注意,我们不能直接用运行时间来定义一个算法的时间复杂度,是因为一个算法的运行时间与硬件的配置存在联系,同样一个算法是没有办法算出准确时间的。
示例:
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}在上述代码中,F(N)=N*N+2*N+10,这是准确的时间复杂度函数式,计算的结果是算法运行的准确次数,然而意义并不大,我们在及计算时间复杂度时,并不一定要计算出准确的执行次数,只需要大概执行次数,故而引进大O的渐进表示法。
2.2 大O的渐进表示法
当不方便在算法之间比较准确时间复杂度函数式时,使用大O的渐进表示法。
简单而言,大O渐进表示法是估算一个算法的数量级而非准确数值。
具体而言,推导大0阶方法:
(1)用常数1取代运行时间中的所有加法常数;
(2)在修改后的运行次数函数中,只保留最高阶项;
(3)如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
示例1:
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}该算法的时间复杂度的准确函数式为F(N)=2*N+10,O(N)=N;
示例2:
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}当N、M大小未知时,时间复杂度表示为O(N+M);
当N远大于M时,时间复杂度表示为O(N);
当M远大于N时,时间复杂度表示为O(M);
当N、M属于一个量级时,时间复杂度表示为O(M)或O(N)均可;
示例3:
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}时间复杂度表示为O(1);
示例4:
const char * strchr ( const char * str, int character );PS:strchr的功能是在字符串中查找一个字符,如下:
while(*str)
{
if(*str==character)
return str;
else
++str;
}
return NULL;示例4小结:
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}冒泡排序的时间复杂度准确函数式式F(N)=N-1+N-2+...+2+1=((N-1+1)*(N-1))/2=(N*(N-1))/2;
故而时间复杂度是O(N^2);
注意计算时间复杂度不能数循环,一定要看算法思想。
示例6:
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n-1;
while (begin < end)
{
int mid = begin + ((end-begin)>>1);
if (a[mid] < x)
begin = mid+1;
else if (a[mid] > x)
end = mid;
else
return mid;
}
return -1;
}二分查找的时间复杂度最好O(1),最坏O(log N)
注:在文本中写对数不方便,在时间复杂度中log N经常出现,故而简写为log N,然而在部分博客与教材中会简写为lg N,这其实并不准确,但一般情况下,都会将其默认为log N,底数为2。
(查找了多少次就除了多少次2,假设找了x次,2^x=N)
示例7:
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}可以观察到该函数的功能是求阶乘。时间复杂度为O(N);
示例8:
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}复杂度具体函数可以近似为F(N)=2^0+2^1+2^2+......+2^(N-2)=2^(N-1)-1,时间复杂度为O(2^N);
总结:按数量级递增排列,常见的时间复杂度有:O(1)<=O(log N)<=O(N)<=O(Nlog N)<=O(n^2)<=O(n^3)<=...<=n^k<=O(2^n)
随着问题规模N的不断增大,上述时间复杂度不断增大,算法的执行效率越低,若复杂度超过O(2^n),此算法效率已经非常低,没有运行的必要。
例题1:数组nums包含从0到n的所有整数,但其中缺了一个,请编写代码找出那个缺失的整数,有办法在O(N)时间内完成吗
思路一:一一对应:
step1:开辟一个额外的n+1个数字的数组,并将数组的每一个元素赋值为-1;
step2:遍历所有数字,这个数字是多少,就放置在对影数组下标的位置;
step3:遍历一遍数组,哪个位置是-1则这个位置所对应的数组元素下标就是缺失的数字;
思路二:异或(相同为0 相异为1):
step1:用x=0与数组中所有的数据都异或一遍;
step2:所得结果再与0——N之间的数字异或一遍;
因为异或与顺序无关,存在的数字都异或了两次,最终结果都是1,只有那个0——N之间存在然而数组中不存在的数字经过两次异或后结果为0,这个数就是缺失的数字。
思路三:排序+二分查找:
冒泡排序O(N)+二分查找log N和快排O(N)+二分查找log N二者均不满足复杂度要求,故不做详细解释。
思路四:公式计算:
0——N利用求和公式计算总和,再减去数组中的所有元素的值,得到的差值就是缺失的元素。
3.空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度。同时间复杂度一样,具体占用了多少bytes的空间大小没有意义,也使用大O渐进表示法。
注意函数运行时所需要的栈空间(存储参数、局部变量以及一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时显示申请的额外空间来确定。
示例一:
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}开辟了常数个额外空间,故而空间复杂度是O(1);
示例二:
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}空间复杂度是O(N);
示例三:
long long Fac(size_t N)
{
if(N == 0)
return 1;
return Fac(N-1)*N;
}空间复杂度是O(N);
示例四:
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}(时间是累积的;空间不累积,可以重复利用)空间复杂度是O(N);
注:对空间可以重复利用的理解: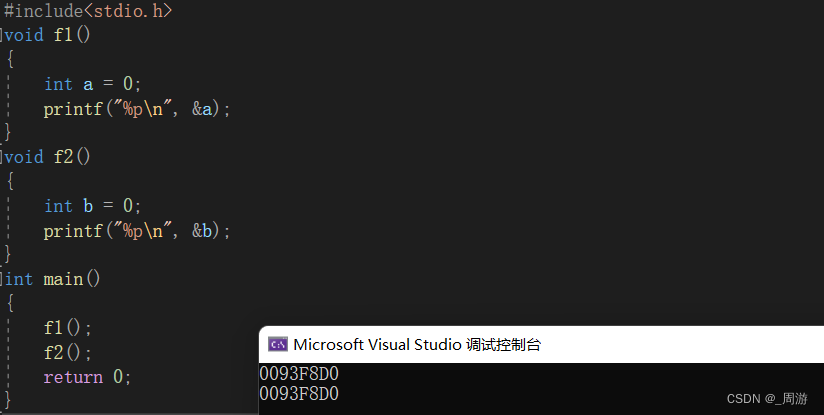
两个函数地址相同,说明调用的是同一个区域,即空间重复利用。















 5131
5131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









